- The paper demonstrates an innovative asymmetric actor-critic framework that uses a lightweight, open-source critic to supervise fixed proprietary LLM actors during multi-turn interactions.
- It proposes a critic-centric data generation pipeline that identifies hard tasks through self-play, leading to measurable improvements in task success rates and average rewards.
- The framework effectively bridges the generation–verification gap, offering robust policy enforcement and dynamic user preference tracking without requiring actor retraining.
Asymmetric Actor–Critic Framework for Multi-turn LLM Agents: Technical Review
Introduction and Motivation
Open-ended multi-turn conversational agents based on LLMs increasingly underpin real-world applications such as customer service and travel planning. Ensuring reliability—especially in one-shot deployment settings where only the first agent output is exposed—is a persistent challenge due to hallucinations, policy violations, or inconsistent reasoning. Existing reinforcement learning (RL)-style actor–critic architectures are typically symmetric: both actor and critic are trainable and operate in structured action spaces, limiting their applicability to deployments involving proprietary fixed actors and open-ended language interactions.
The paper "Asymmetric Actor-Critic for Multi-turn LLM Agents" (2604.00304) introduces a fundamentally different formulation. It enables robust runtime control over proprietary LLM actors by deploying a lightweight, open-source critic for intervention without actor retraining, action space structuring, or iterative retries. The key insight is the generation–verification gap: while generation capability scales with model size, effective policy and constraint supervision can often be achieved using much smaller models.
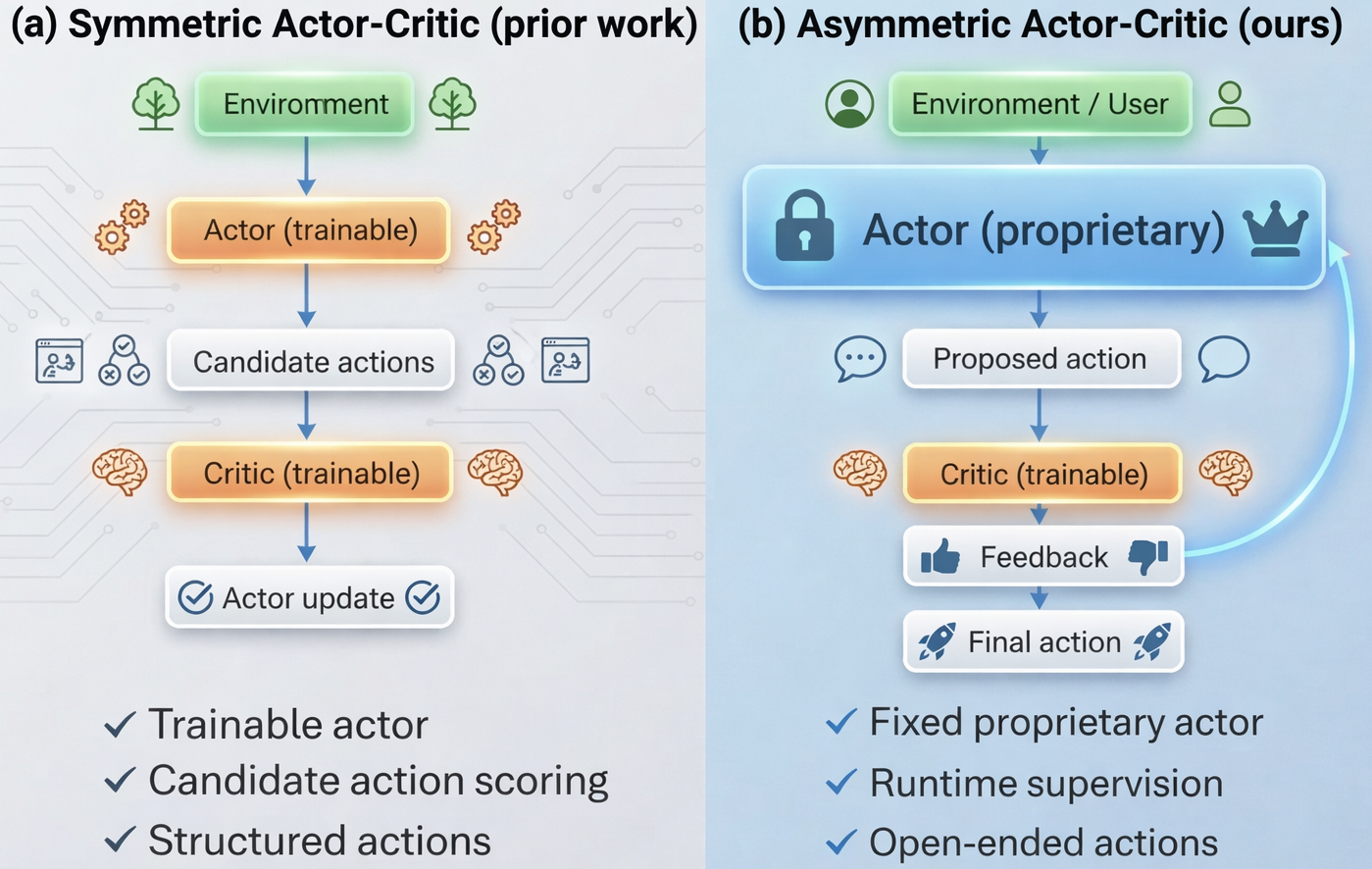
Figure 1: The asymmetric actor–critic framework: a lightweight open-source critic supervises a fixed, potentially proprietary actor at runtime, enabling reliable control for one-shot multi-turn conversational agents.
Methodology
Asymmetric Runtime Supervision
At each turn in the conversational decision process, the fixed actor (proprietary LLM) produces a candidate action given the dialogue history. The critic, typically a smaller finetuned open-source LLM (e.g., Qwen3-8B/32B), is invoked based on task-specific intervention logic (e.g., when an action changes state or makes a recommendation). If intervention is triggered, the critic evaluates the candidate action and produces verbal feedback—approval, requests for revision, or corrective suggestions. The actor then generates a revised action, conditioned on the critic’s feedback; otherwise, the original proposal is executed.
This decoupling respects constraints of real deployments, allowing the most capable proprietary LLMs as actors and granting continuous oversight/adaptability via the open-source critic. The framework generalizes beyond written policies to dynamic user preference satisfaction and tool use.
Critic-centric Data Generation via Self-play
Because critics are not trained to generate actions but to evaluate and guide action proposals, standard conversational SFT datasets are inadequate. The authors introduce a pipeline that (1) replays multi-turn dialogues with the fixed actor, (2) automatically identifies “hard” tasks (on which actor-only systems frequently fail), and (3) collects critic interventions on these for supervised fine-tuning. This training set covers informative intervention cases, efficiently specializing the critic to detect actor mistakes under real target policies and user preferences.
Experimental Evaluation
The framework is evaluated on τ-bench (customer service with explicit policies) and UserBench (travel planning with implicit user-elicited constraints). Both demand strict single-run task success.
Baseline Comparisons
Strong baselines include single-actor execution (Claude-4 Sonnet), reflection-style methods (CRITIC [gou2024CRITIC], ReAct [yao2023ReAct]), and SOTA open-source multi-turn tuning pipelines (APIGen-MT [prabhakar2025apigenmt], IRMA [Mishra2025IRMA]).
Effectiveness of Asymmetric Supervision
Across both benchmarks and multiple domains, the asymmetric actor–critic (Asym-AC) consistently outperforms all single-actor baselines:
- τ-bench: Task success rate increases from 0.5998 (single actor) to 0.6318 (Asym-AC), and further to 0.6546 (Asym-AC-SFT, fine-tuned critic).
- UserBench: Average reward improves from 0.3277 (single actor) to 0.3798 (Asym-AC) and 0.4176 (Asym-AC-SFT).
Notably, lightweight open-source critics (Qwen3-8B/32B) often match or exceed the performance of much larger, proprietary LLMs (Claude-4 Sonnet) in the critic role—even without fine-tuning—demonstrating that strong generative ability is not necessary for effective supervision.
Critic Capacity and Adaptation
Scaling the critic model (within Qwen3 variants) continually improves oversight quality, but even small models such as Qwen3-8B provide substantial gains over larger, non-specialized models. Supervised fine-tuning using the proposed pipeline further increases both reliability and pass@1 scores, outperforming reflection and self-critique methods on these multi-turn, constraint-laden benchmarks.
Empirical Analysis: Error Correction and Control
Detailed qualitative and quantitative analyses indicate that the proposed asymmetric actor–critic mechanism effectively prevents common failure modes in multi-turn agent operation:
- Policy enforcement: The critic intervenes on actor over-permissiveness (approving disallowed actions) or over-blocking (hallucinated constraints), enforcing strict adherence to written or emergent user-driven policies.
- Preference tracking and tool use: In UserBench, the critic prompts the actor to elicit missing preferences before final recommendations, preventing premature or suboptimal actions.
- Cost-sensitive and multi-step reasoning: The critic can redirect the actor to explore alternatives (e.g., cheaper item replacements) rather than terminating on the first blocked path.
These examples show the critic’s capacity to correct both “hard” policy failures and nuanced mistakes such as suboptimally exploiting the decision space.
Implications and Prospects
Practically, the work enables robust post-deployment control and adaptation over otherwise non-trainable proprietary LLM agents. This is essential for organizations deploying advanced LLMs via APIs that prohibit finetuning or agent retraining. Theoretically, the work underlines that LLM supervision tasks (verification, policy enforcement) can be performed at lower model scale than generation, supporting a modular, scalable approach to agent construction and adaptation.
For future AI system design, the asymmetric actor-critic paradigm may serve as a blueprint for leveraging the best available proprietary or closed models while retaining rigorous, domain-specific oversight and control. Further research can examine:
- Extension to non-dialogue sequential decision problems (complex tool use, mixed-initiative interaction).
- Dynamic adaptation of critic intervention policy for latency-reliability trade-offs.
- Application to safety-critical and high-stakes domains with evolving regulatory constraints.
Conclusion
The asymmetric actor–critic framework proposed in "Asymmetric Actor-Critic for Multi-turn LLM Agents" (2604.00304) demonstrates that lightweight, trainable critics can supervise fixed, powerful LLM actors in open-ended conversational environments, improving first-attempt task success and reliability. The generation–verification asymmetry is exploited in a new runtime architecture, operationalizing agentic control without actor access or repeated trials. The approach offers both strong empirical results and new avenues for robustifying LLM-based agent deployments.

