Critique-RL: Training Language Models for Critiquing through Two-Stage Reinforcement Learning
Abstract: Training critiquing LLMs to assess and provide feedback on model outputs is a promising way to improve LLMs for complex reasoning tasks. However, existing approaches typically rely on stronger supervisors for annotating critique data. To address this, we propose Critique-RL, an online RL approach for developing critiquing LLMs without stronger supervision. Our approach operates on a two-player paradigm: the actor generates a response, the critic provides feedback, and the actor refines the response accordingly. We first reveal that relying solely on indirect reward signals from the actor's outputs for RL optimization often leads to unsatisfactory critics: while their helpfulness (i.e., providing constructive feedback) improves, the discriminability (i.e., determining whether a response is high-quality or not) remains poor, resulting in marginal performance gains. To overcome this, Critique-RL adopts a two-stage optimization strategy. In stage I, it reinforces the discriminability of the critic with direct rule-based reward signals; in stage II, it introduces indirect rewards based on actor refinement to improve the critic's helpfulness, while maintaining its discriminability via appropriate regularization. Extensive experiments across various tasks and models show that Critique-RL delivers substantial performance improvements. For example, it achieves a 9.02% gain on in-domain tasks and a 5.70% gain on out-of-domain tasks for Qwen2.5-7B, highlighting its potential.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Clear, Simple Explanation of “Critique-RL: Training LLMs for Critiquing through Two-Stage Reinforcement Learning”
What is this paper about?
This paper is about teaching AI models to be good critics. A “critic” model reads another model’s answer, decides if it’s right or wrong, and gives helpful feedback so the original model (the “actor”) can fix its mistakes. The authors introduce a new training method, called Critique-RL, that makes these critic models both good judges and good helpers.
What questions does the paper try to answer?
The authors focus on two simple questions:
- How can we train an AI critic to accurately tell whether an answer is correct or not? (They call this skill “discriminability.”)
- How can we train the critic to give feedback that actually helps fix mistakes without making correct answers worse? (They call this “helpfulness.”)
They also want to do this without relying on a stronger, more expensive AI to label lots of training data, and without needing a perfect answer-checker during testing.
How did they do it? (Methods in everyday language)
Think of this like a two-player study session:
- The actor is a student who tries to solve a problem.
- The critic is a tutor who checks the student’s work and gives advice.
- The student then tries again, using the critic’s feedback.
The authors tried a straightforward idea first: reward the critic only when the student’s second attempt becomes correct. That seems sensible—but it didn’t work well. The critic either:
- became too cautious (rarely suggested changes, so it didn’t fix many mistakes), or
- became too aggressive (suggested too many changes, and sometimes made correct answers worse).
To fix this, they trained the critic in two stages:
- Stage I: Train the critic to be a good judge.
- Give the critic direct rewards for correctly identifying whether the student’s first answer is right or wrong.
- In simple terms: “Learn to spot correct vs. incorrect answers reliably first.”
- Stage II: Train the critic to be a helpful coach—without losing judging skills.
- Now the critic gets rewarded when its feedback helps the student’s second attempt become correct.
- At the same time, a “stay-on-track” reminder keeps the critic close to the good judging habits it learned in Stage I (think of it like a gentle leash so it doesn’t drift into being reckless or timid).
In AI terms, this uses reinforcement learning (RL): the critic gets “points” (rewards) for doing useful things. Direct rewards in Stage I teach solid judging; indirect rewards in Stage II teach helpful coaching while keeping judging strong.
What did they find, and why does it matter?
Here’s what they observed:
- Training with indirect rewards alone (just checking if the student’s second try is right) wasn’t enough. It improved helpfulness a bit but hurt judging accuracy, leading to poor overall performance.
- Their two-stage Critique-RL worked much better:
- Stage I made the critic much better at telling correct from incorrect.
- Stage II made feedback more useful without breaking judging skills.
- Across several math and reasoning tests (like MATH, GSM8K, and AQuA), their method clearly beat other approaches. For one model size (Qwen2.5-7B), it improved accuracy by about 9% on familiar tasks and about 6% on new, unseen tasks.
- The trained critics also helped when you try multiple solutions and pick the best (like asking several classmates and going with the most common answer). Their method raised the “ceiling” (highest achievable score) and used compute more efficiently.
Why this matters:
- A critic that can both judge well and give useful feedback helps AI solve harder problems more reliably.
- It reduces the need for expensive human or super-strong AI labeling and still works on new kinds of problems.
What’s the bigger impact?
- Better oversight for AI: This method is a step toward “scalable oversight,” where AIs help train other AIs safely and effectively, even on complex tasks like reasoning and coding.
- More general and robust: The trained critics help not just on the tasks they saw during training, but also on different, new tasks (good generalization).
- Practical and efficient: It avoids relying on very strong supervisors and improves performance without huge extra costs at test time.
In short: The paper shows a smart training plan for AI critics—first teach them to judge accurately, then teach them to help effectively while keeping their judging sharp. This two-step approach leads to more reliable, helpful AI systems that can improve other AIs’ answers in a stable and scalable way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of specific gaps and open questions that remain unresolved and could guide future research.
- Dependence on oracle verifiers during training
- The approach requires a task-level oracle (e.g., exact answer match) to compute both Stage I (discriminability) and Stage II (refinement) rewards. How can Critique-RL be adapted to settings without reliable verifiers (open-ended generation, multi-correct answers, subjective tasks)?
- Sensitivity to imperfect verifiers is not studied. What is the robustness of the method to noisy, biased, or partial verifiers (e.g., unit errors, formatting differences, synonymy)?
- Generalization beyond math-style tasks
- Experiments focus primarily on math reasoning with clear correctness signals. How well does the method transfer to domains with weak or delayed rewards (long-form QA, safety-critical reasoning, tool use, multi-step decision-making)?
- The paper mentions a summarization exploration in the appendix where rule-based verifiers do not directly apply, but provides no clear recipe for extending Stage I/II rewards in such settings.
- Transfer across actors and architectures
- The critic is trained and evaluated mostly with the same or closely related actor architectures (often the same base family). Will a trained critic generalize to different actor models (sizes, families, decoding behaviors) without re-training?
- How robust is the critic to post-training changes in the actor (e.g., if the actor is improved via separate RL or SFT after the critic is trained)?
- Fixed-actor assumption and co-evolution
- The actor is fixed during critic RL; joint optimization or alternating updates are not explored. Does co-evolving actor and critic improve or destabilize training, and how should curricula or regularizers be designed to avoid degenerate equilibria?
- Reward design and sparsity
- Stage I uses a binary indicator reward for discriminability; no exploration of richer, denser, or calibrated signals (e.g., per-step agreement, margin-based rewards, calibrated probabilities).
- Stage II uses refinement correctness as reward. Alternatives (e.g., shaped rewards for partial improvement, edit distance in reasoning traces, or answer margin) are not assessed.
- Helpfulness measurement lacks direct human evaluation
- Helpfulness is evaluated indirectly via actor performance improvements. Do humans rate the critiques as more precise, actionable, and faithful? Is there a trade-off between critique length/verbosity and actionability?
- Critic calibration and confidence
- Acc@Dis is binary; no assessment of calibration (e.g., Brier score, ECE) or thresholding schemes to balance aggressive vs conservative behavior. How to produce reliably calibrated correctness judgments?
- Faithfulness and causal impact of critiques
- It is assumed the actor “faithfully” incorporates critique content. Are critiques actually the causal driver of improvements, or do generic refinements suffice? Can we instrument and measure which critique components the actor uses?
- Robustness to adversarial or degenerate behaviors
- The critic might learn reward-hacking patterns (e.g., generic “don’t change” advice to avoid c→i errors) or produce overconfident incorrect assessments. How to detect and prevent such modes (adversarial evaluation, uncertainty penalties, diversity constraints)?
- Hyperparameter sensitivity and training stability
- The method introduces multiple regularization strengths (KL to SFT in Stage I; KL to Stage I and β1 for r_dis in Stage II), but no sensitivity or ablation over these is provided. What ranges are safe across datasets and models?
- Variance across random seeds, run-to-run stability, and sample efficiency are not quantified.
- Cost, latency, and token-efficiency
- The approach adds critique and refinement loops; although some compute-scaling results are shown, there is no breakdown of token and latency overheads, or optimization of critique length vs performance trade-offs.
- Multi-round critique depth and diminishing returns
- Iterative critique-refinement shows improvements for a few rounds, but the limits and failure modes of deeper iterations are not characterized (e.g., plateauing, oscillations, or regressions after many rounds).
- Step-level vs final-answer discriminability
- While the prompt collects step-level judgments, the reward and metrics focus on final correctness. Does optimizing step-level error localization improve downstream refinement more than final-only signals?
- Out-of-domain generalization boundaries
- OOD evaluations are still within math-style tasks. How well does the critic generalize to qualitatively different tasks (coding, planning, safety audits, tool-use agents) without domain-specific reward engineering?
- Actor dependency and distribution shift
- The SFT critique data are generated with a specific model and filtered via refinement outcomes, potentially entangling the critic with the actor’s idiosyncrasies. How does the critic perform under actor distribution shift (different decoding temperatures, sampling strategies, or prompt formats)?
- Choice of RL algorithm
- The method uses RLOO; comparisons to alternative RL algorithms (PPO, GRPO, advantage-weighted objectives, off-policy RL) are absent. Which algorithms are most stable/effective for critic training?
- Theoretical understanding and guarantees
- There is no formal analysis of convergence, optimality, or conditions under which discriminability and helpfulness jointly improve. Can we characterize when two-stage training avoids conservative/aggressive collapse?
- Mixed-supervision and hybrid oversight
- The method does not explore combining weak verifiers with small amounts of human feedback to train critics in domains without reliable oracles. What is the best way to integrate sparse human labels or preference data?
- Safety and misuse considerations
- The impact of critiques on safety (e.g., reducing harmful reasoning, hallucinations, or biased judgments) is not assessed. Can critics be trained to prioritize safety-oriented assessments and interventions?
- Evaluation breadth and statistical rigor
- Main results emphasize point estimates; confidence intervals, statistical significance across multiple seeds, and variance analyses are missing, limiting conclusions about robustness.
- Scaling laws and model size trends
- Beyond 3B/7B (and limited appendix results), systematic scaling relationships (training compute vs gains, critic size vs benefit) are not characterized. Do larger critics yield diminishing or increasing returns?
- Interoperability with external verifiers at test time
- The paper shows improvements with an oracle at test time but does not study principled strategies for combining critic judgments with verifiers (e.g., adaptive routing, fallback policies, trust calibration).
- Contamination and multi-answer phenomena
- Exact-match oracles can misjudge semantically correct but formatted-differently answers, or tasks with multiple valid solutions. How do such misalignments affect critic learning and downstream behavior?
- Reproducibility details
- Critical training details (e.g., seeds, sampling variance, exact prompts, failure case statistics) are not fully specified, which may hinder fair comparison and replication across labs.
Practical Applications
Overview
The paper introduces Critique-RL, a two-stage reinforcement learning method to train critiquing LLMs (critics) that both (a) discriminate whether an answer is correct and (b) provide helpful natural language feedback that improves an actor model’s refinement. Stage I optimizes discriminability using direct, rule-based rewards; Stage II improves helpfulness using indirect rewards from actor refinements while regularizing to preserve discriminability. The approach delivers consistent gains on reasoning tasks (e.g., MATH, GSM8K, AQuA) and generalizes to out-of-domain tasks, without relying on stronger supervisors at training time and without an oracle at test time.
Below are practical applications, grouped by deployment horizon. Each item highlights the sector, potential tools/workflows, and key assumptions/dependencies.
Immediate Applications
These are deployable now in domains with reliable verifiers (unit tests, schema/format validators, numeric answer checkers) and with existing LLM infrastructure.
- Math tutoring and automated grading (Education)
- What: Use the critic to judge step-level correctness and provide targeted feedback on student solutions; auto-grade quizzes/homework with explanations.
- Tools/Workflows: “TutorCritic” API integrated into LMS; response–critique–refine loop for hints; batch grading with Acc@Dis gating and human escalation for low-confidence cases.
- Assumptions/Dependencies: Availability of ground-truth answers or robust math checkers; configurable rubrics; bias/fairness review for diverse solution styles.
- CI “fixer” bots and test-driven code refinement (Software)
- What: In CI pipelines, when unit/integration tests fail, run an actor to propose patches and a Critique-RL critic to assess patches and guide refinements.
- Tools/Workflows: GitHub/GitLab app “CI-Critic” that hooks into test reports; Stage I discriminability trained via test pass/fail; Stage II helpfulness for actionable fix suggestions.
- Assumptions/Dependencies: Adequate test coverage; guardrails to avoid insecure code; repo-specific style and policy constraints.
- Structured output QA and auto-correction (Software, Data/Analytics)
- What: Validate and improve LLM-generated SQL/JSON/XML or regex via schema and execution checks; critic explains failures and proposes fixes.
- Tools/Workflows: “OutputGuard + Critique” middleware; schema validator + dry-run executor + critic feedback; iterative refine until passes.
- Assumptions/Dependencies: Reliable validators/executors; safe sandboxes; performance budgets for multi-iteration refinement.
- Customer support and knowledge-base Q&A with citation checks (Enterprise software)
- What: Critic verifies that answers cite required KB passages and flags/suggests revisions when unsupported.
- Tools/Workflows: RAG pipeline with citation verifier; critic-driven rewrite if citations are missing/mismatched; human escalation for ambiguous cases.
- Assumptions/Dependencies: Access to authoritative KB; citation or entailment checkers; content governance policies.
- Dataset curation and scalable oversight for model outputs (Academia and Industry MLOps)
- What: Filter, accept/reject, and correct model-generated labels/rationales to build high-quality training/eval sets with less human effort.
- Tools/Workflows: “Critique-RL Curation” job that runs Acc@Dis to classify outputs, emits actionable feedback for correction, and logs uncertainty for human sampling.
- Assumptions/Dependencies: Verifiers or spot-check protocols; reproducible pipelines; bias and coverage audits.
- Human-in-the-loop triage and routing (Operations, Support)
- What: Use the critic’s discriminability to route uncertain or likely-incorrect outputs to humans and auto-approve high-confidence ones.
- Tools/Workflows: Triage service exposing Δc→i/Δi→c metrics; policy-based routing; SLA-aware re-try/refine loops before escalation.
- Assumptions/Dependencies: Calibrated thresholds; audit trails; privacy/security controls.
- Compute-efficient inference scaling (Platform/Infra)
- What: Replace large-k naive sampling with fewer response–critique–refine cycles to achieve higher accuracy per unit compute.
- Tools/Workflows: MV@K scheduler that prioritizes K cycles of critique-refine over 3K raw samples; per-task K tuning dashboards.
- Assumptions/Dependencies: Access to both actor and critic; inference budget management; monitoring for diminishing returns.
- Autonomous web/task agents with verifiable goals (Agents for shopping, booking, form-filling)
- What: Critic evaluates whether intermediate steps meet goal constraints (e.g., price/availability) and suggests plan corrections.
- Tools/Workflows: Web agent loop with embedded “PlanCritic”; stage checks (state validators) + critic feedback + replanning.
- Assumptions/Dependencies: Clear, checkable success criteria; environment simulators or headless browsers; rate-limit handling.
- “Train-your-own-critic” kit for researchers and teams (Academia, Developer tooling)
- What: Apply Critique-RL to train domain-specific critics without GPT-4-level supervision; rapid reproduction on math/coding benchmarks.
- Tools/Workflows: Open-source repo + config templates; Stage I with task verifiers; Stage II with refinement rewards; example notebooks.
- Assumptions/Dependencies: GPU access; per-domain reward shapers; seed actor capable of following critiques.
Long-Term Applications
These require further research, robust verifiers or learned reward models in open-ended domains, larger-scale validation, and/or regulatory approvals.
- General-purpose open-ended critics for summarization, legal, and scientific writing (Software, Academia, Legal)
- What: Critic that evaluates factuality, citation integrity, and logical consistency in unconstrained text, with helpful revisions.
- Tools/Workflows: Learned verifiers (reward models) for factuality and source attribution; retrieval-grounded critique; multi-pass refinement.
- Assumptions/Dependencies: High-quality reward models; reliable retrieval/citation tools; domain expert validation; risk controls for hallucinations.
- Clinical decision support and guideline adherence checking (Healthcare)
- What: Critic evaluates stepwise reasoning against clinical guidelines and flags inconsistencies; suggests safer alternatives.
- Tools/Workflows: EHR-integrated agent with guideline checkers; clinician-in-the-loop review; explanation tracking.
- Assumptions/Dependencies: Rigorous medical verifiers/guideline encodings; auditability; regulatory compliance (HIPAA, CE/FDA); extensive prospective validation.
- Financial analysis, compliance, and reporting assurance (Finance)
- What: Critic audits model-produced analyses for consistency with filings and policies; proposes corrections; flags risk.
- Tools/Workflows: Rule engines for GAAP/IFRS/policy checks; factuality and reconciliation verifiers; lineage tracking.
- Assumptions/Dependencies: Access to reliable data sources; formalized compliance rules; human oversight; governance sign-off.
- Policy compliance and AI governance automation (Policy, Enterprise risk)
- What: Use critics as automated oversight to verify adherence to redaction rules, safety policies, and jurisdictional requirements across LLM workflows.
- Tools/Workflows: “CriticOps” governance layer; policy DSL + verifiers; continuous monitoring and retraining loops; audit dashboards.
- Assumptions/Dependencies: Formalized policies; explainability and evidencing; third-party audits; standardization.
- Long-horizon planning and safety in robotics and autonomous systems (Robotics)
- What: Critic evaluates plan steps against safety invariants and task constraints; guides replanning with interpretable feedback.
- Tools/Workflows: Simulation-based verifiers; formal methods for constraint checks; critic-informed MPC or task planners.
- Assumptions/Dependencies: High-fidelity simulators; safe sim-to-real transfer; certification for safety-critical use.
- Large-scale adaptive tutoring across subjects (Education)
- What: Critics provide individualized, step-aware feedback across math, physics, languages, and more, while maintaining fairness and pedagogical soundness.
- Tools/Workflows: Subject-specific verifiers/reward models; learner modeling; fairness and accessibility monitoring.
- Assumptions/Dependencies: Broad-coverage verifiers; diverse, high-quality training data; educator oversight and curriculum alignment.
- Scientific discovery assistants and lab protocol verification (Academia, Biotech)
- What: Critic checks experimental reasoning, units, and methodological consistency; suggests corrections to protocols or analyses.
- Tools/Workflows: Domain ontologies; units/dimension verifiers; data-quality checks; provenance capture.
- Assumptions/Dependencies: Encoded domain rules; validation with wet-lab results; responsible use policies.
- Multi-domain Critique-as-a-Service platforms (Software platforms)
- What: Managed services offering critics, reward models, and training pipelines for enterprises to bolt onto LLM apps.
- Tools/Workflows: API for Stage I/II training; per-domain verifier catalogs; MLOps integrations; SLAs and monitoring.
- Assumptions/Dependencies: Sustainable business model; interoperability across model vendors; privacy/security assurances.
- Automated red teaming and hallucination forensics (AI Safety)
- What: Critics probe and explain failure modes, quantify risks (Δi→c, Δc→i), and propose mitigations.
- Tools/Workflows: Scenario generators; safety verifiers; postmortem analyzers; mitigation playbooks.
- Assumptions/Dependencies: Diverse stress-test corpora; accepted safety metrics; human review loops.
- Data governance and privacy enforcement (Enterprise, Policy)
- What: Critic verifies PII redaction, consent compliance, and residency constraints in model outputs and logs; suggests compliant rewrites.
- Tools/Workflows: PII/PHI detectors as verifiers; policy rules; compliance audits; remediation workflows.
- Assumptions/Dependencies: Accurate detectors; legal interpretations encoded as rules; organizational acceptance and audits.
Cross-cutting assumptions and dependencies
- Verifier availability: Immediate success hinges on rule-based or programmatic verifiers (e.g., unit tests, schemas, answer matchers). Open-ended domains will need learned reward models or hybrid heuristics.
- Actor capability: The actor must reliably follow critiques; an SFT step to teach refinement is typically required.
- Compute and engineering: GPU resources for training; orchestration for multi-iteration inference; monitoring for conservative/aggressive failure modes if Stage I/II balance drifts.
- Data and distribution shift: Critics trained on one distribution may overfit; periodic re-training and OOD checks are needed.
- Risk, compliance, and human oversight: High-stakes domains require human review, auditability, and regulatory alignment.
- Licensing and ecosystem: Base model and data licenses; integration with existing MLOps/CI stacks; privacy/security guardrails.
Glossary
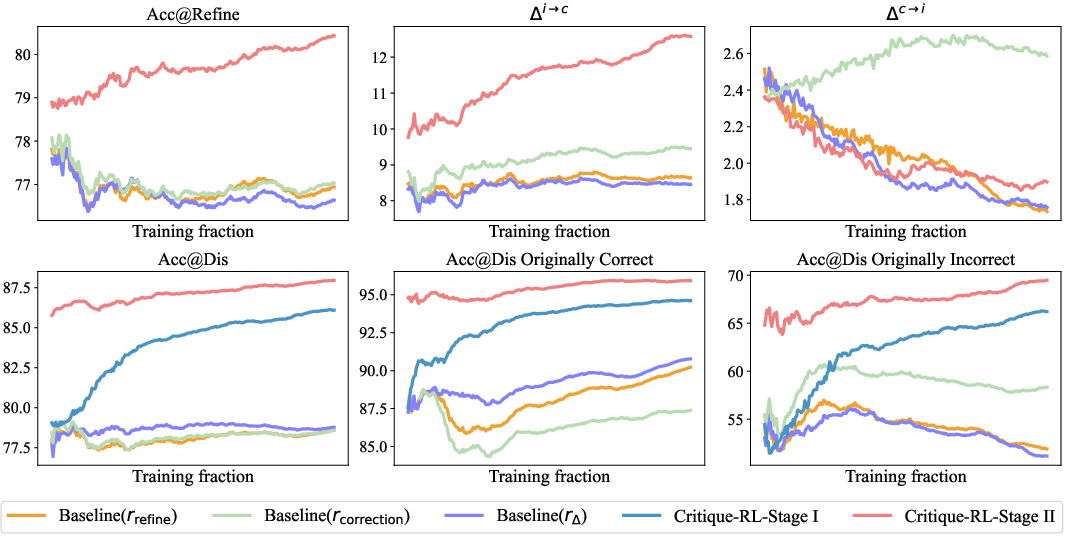
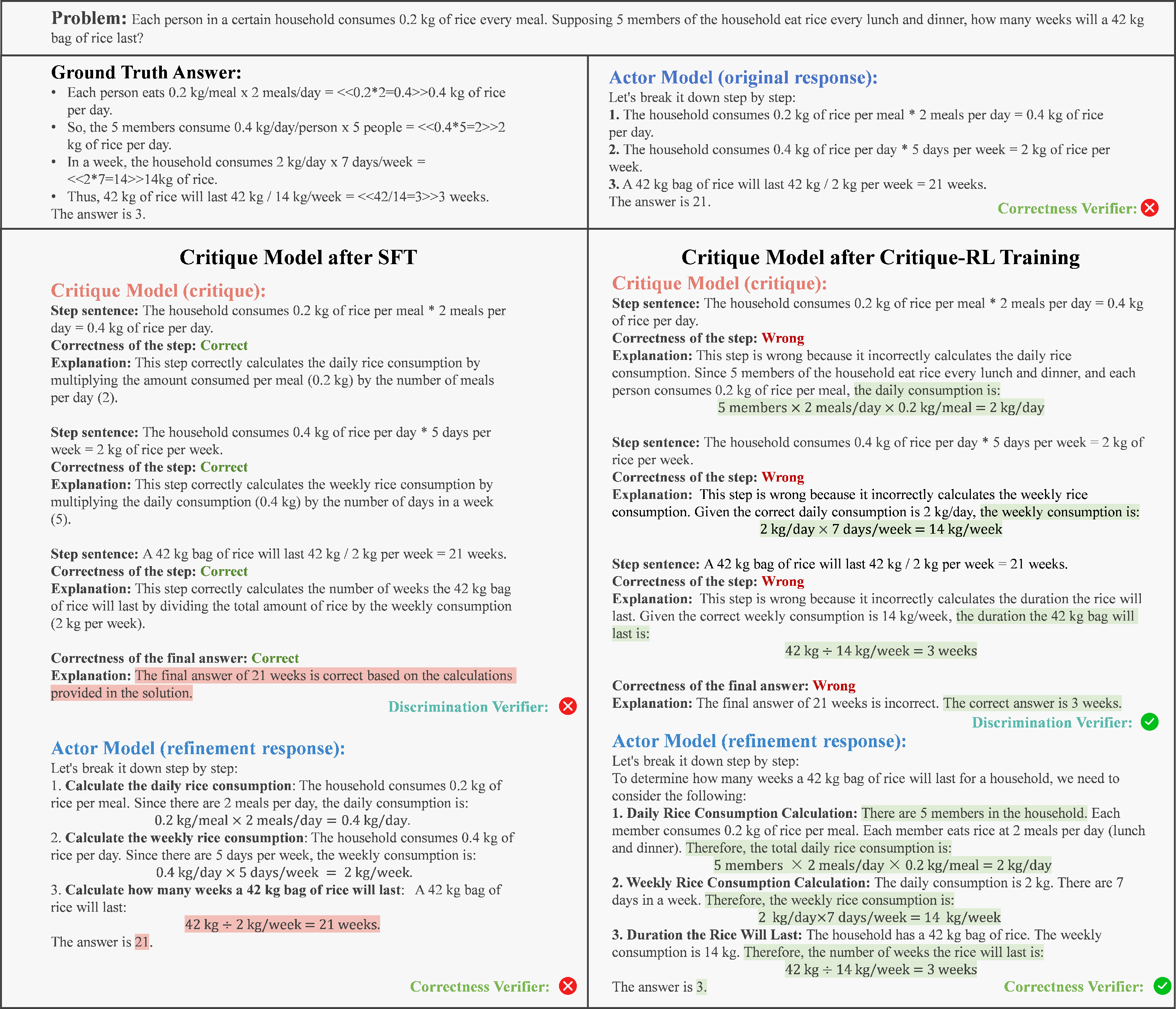
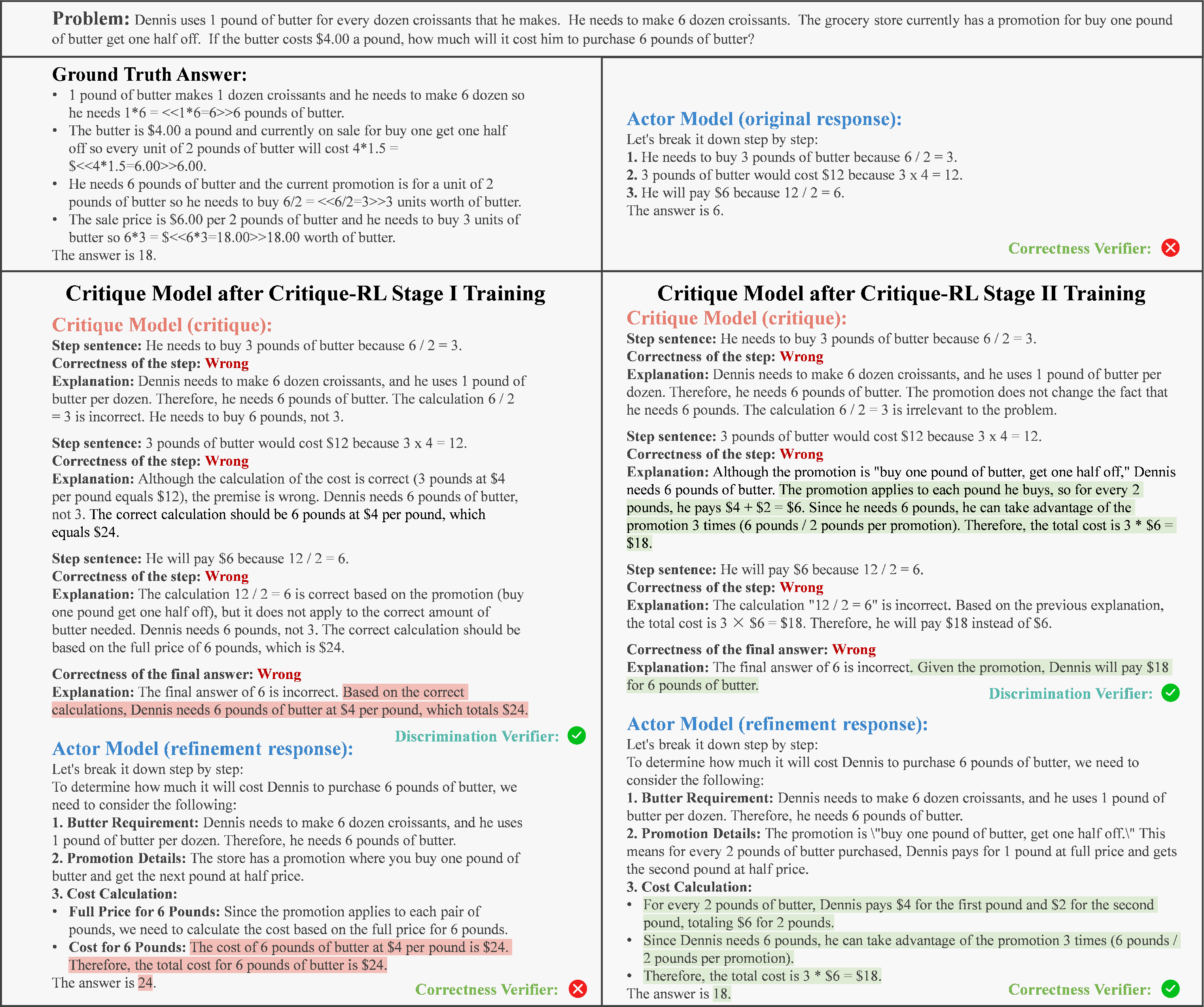
- Acc@Dis: A metric quantifying a critic’s ability to correctly judge the correctness of an original response. "(5) Acc@Dis: a direct metric to measure the discriminability of the critique model, which quantifies the accuracy of whether the correctness accessed by the critic aligns with the true correctness of the original response."
- Acc@Refine: The accuracy of the actor’s response after incorporating the critic’s feedback. "(1) Acc@Refine: the accuracy of the actor model's refinement response;"
- Ablation: An analysis technique where components are removed or altered to assess their contribution to performance. "We perform in-depth experiments, ablation and analysis to show the effectiveness and stability of our method."
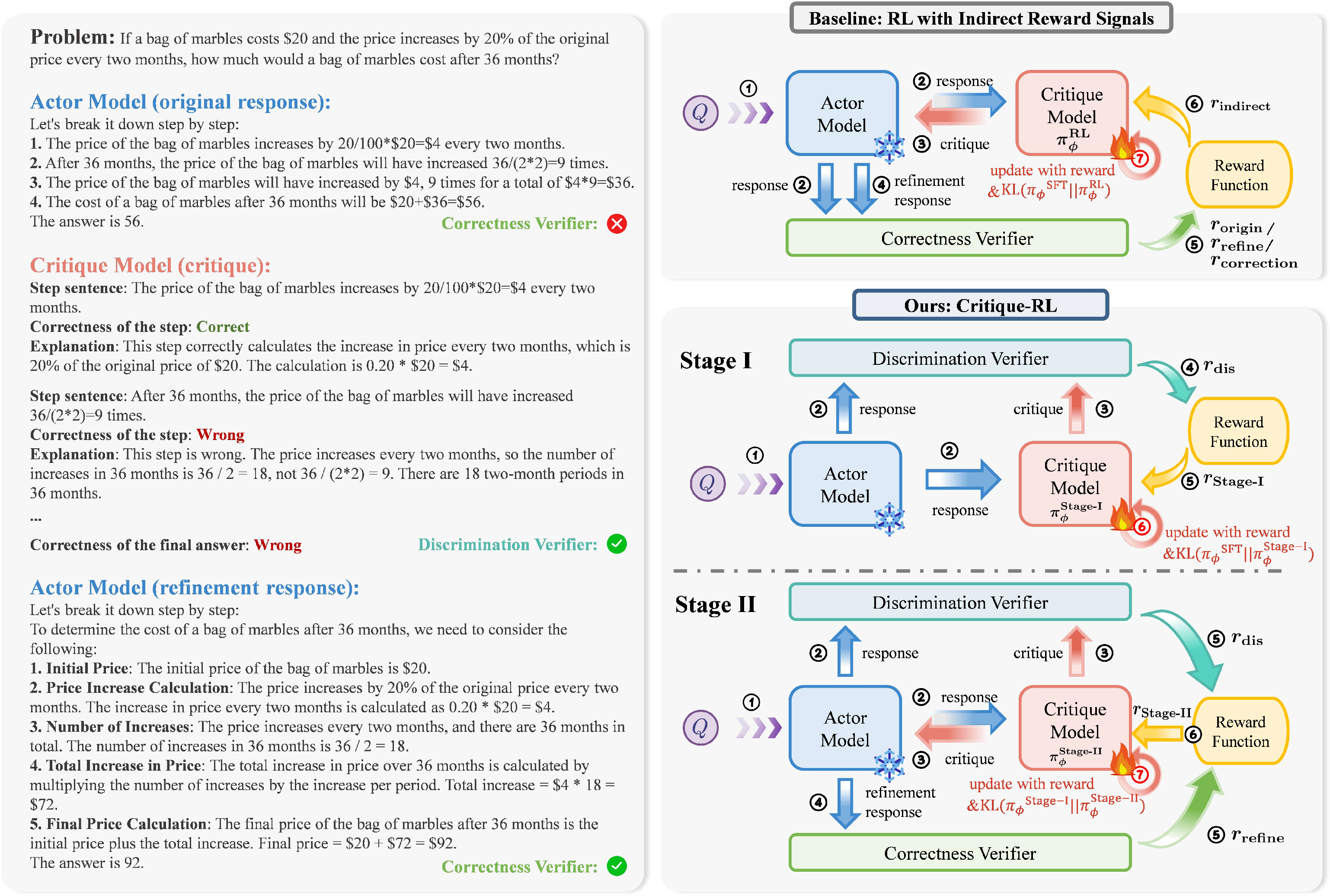
- Actor-critic interaction: A paradigm where an actor generates outputs and a critic evaluates them and provides feedback to guide refinement. "we propose Critique-RL, an online RL approach based on two-player actor-critic interaction \citep{DBLP:conf/iclr/YaoHNLFXNC0AXMW24, DBLP:journals/corr/abs-2411-16579} for developing critique models."
- AQUA: A multiple-choice math word problem dataset used for training and evaluation. "AQUA \citep{DBLP:conf/acl/LingYDB17}."
- CNN/DailyMail: A news summarization dataset commonly used to evaluate open-ended generation tasks. "We conduct experiments on summarization tasks using CNN/DailyMail \citep{DBLP:conf/nips/HermannKGEKSB15} dataset to investigate our method's generalization ability on open-ended tasks where rule-based verifier cannot be directly applied, the results are in Appendix \ref{appendix:summarization}."
- Critique-RL: The proposed two-stage reinforcement learning method for training LLM critics that both judge and improve model outputs. "To address this, we propose Critique-RL, an online RL approach for developing critiquing LLMs without stronger supervision."
- CTRL: An RL baseline that trains critics using GRPO, originally targeted at coding tasks. "CTRL \citep{DBLP:journals/corr/abs-2502-03492} which uses GRPO."
- Delta (Δ): The improvement in accuracy between the actor’s original and refined responses, measuring critique effectiveness. "(2) : the improvement in the actor model's accuracy between the original and refinement response, which measures the effectiveness of the critique model;"
- Delta{c→i} (Δ{c→i}): The rate at which originally correct responses become incorrect after refinement; lower is better. "(3) $\boldsymbol{\Delta^{c\to i}$: the change rate from an originally correct response to an incorrect refinement response. A lower value is better;"
- Delta{i→c} (Δ{i→c}): The rate at which originally incorrect responses become correct after refinement; higher is better. "(4) $\boldsymbol{\Delta^{i\to c}$: the change rate from an originally incorrect response to a correct refinement response. A higher value is better;"
- Discriminability: A critic’s capability to determine whether a response is correct or high quality. "It optimize discriminability of critique models in Stage I, and optimize helpfulness while maintaining discriminability in Stage II."
- GRPO: Group Relative Policy Optimization, a reinforcement learning algorithm used for training policies without explicit value functions. "CTRL \citep{DBLP:journals/corr/abs-2502-03492} which uses GRPO."
- GSM8K: A benchmark dataset of grade-school math problems used to evaluate mathematical reasoning. "Our preliminary experiments are on GSM8K \citep{DBLP:journals/corr/abs-2110-14168},"
- Helpfulness: The critic’s ability to provide constructive natural language feedback that improves the actor’s output. "helpfulness (i.e., providing constructive feedback)"
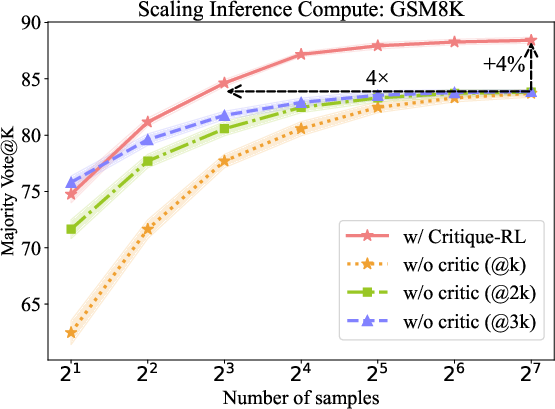
- Inference compute scaling: A test-time strategy that increases sampling or computational budget to boost accuracy. "Inference compute scaling for Critique-RL, with @2k and @3k indicating sampling amounts that are 2 times and 3 times the x-axis value, respectively."
- KL divergence: Kullback–Leibler divergence; a measure of distance between probability distributions used as a regularizer in RL training. "KL-divergence which constrains the distance between the RL model and the SFT model,"
- Majority vote (MV@K): An evaluation method that checks if the most frequent answer among K samples is correct. "majority vote (MV@) \citep{DBLP:conf/iclr/0002WSLCNCZ23} which evaluates whether the most frequent answer among samples is correct."
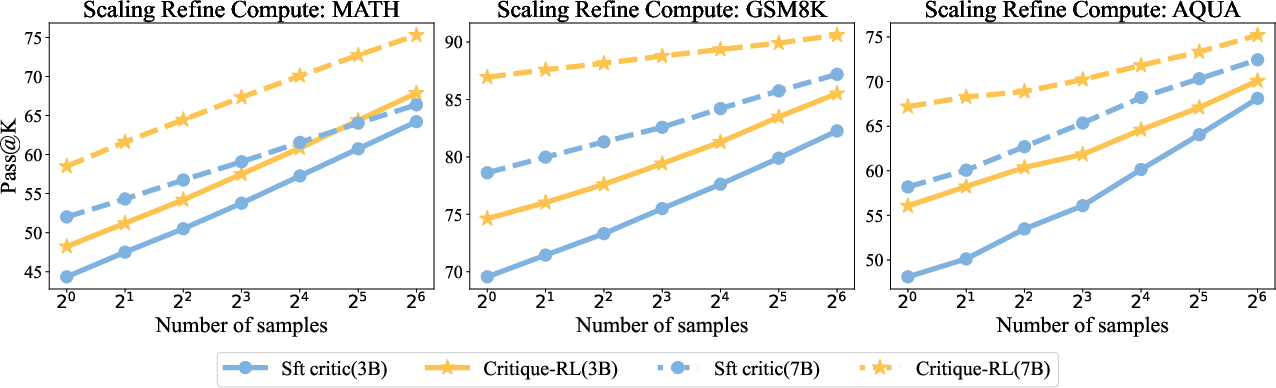
- MATH: A competition-level mathematics dataset used for training and evaluation of reasoning and critique models. "Left: Critique-RL achieves better performance and discrimination on MATH."
- Oracle reward function: An ideal function that returns the ground-truth correctness of a response, used to shape RL rewards. "without relying on stronger supervision or an oracle reward function during testing."
- Oracle verifier: An external correctness checker assumed available at test time to evaluate answers. "such methods typically assume an oracle verifier during testing,"
- Out-of-domain (OOD): Test sets drawn from distributions different from the training tasks to assess generalization. "are used as our OOD (out-of-domain) testset."
- Pass@K: A metric indicating whether any of K generated samples contain a correct solution. "For inference-compute scaling and Pass@, we set temperature to $0.7$."
- Policy gradient: A class of reinforcement learning methods that optimize policies directly via gradients of expected reward. "Policy gradient methods \citep{DBLP:conf/nips/SuttonMSM99}, e.g., REINFORCE \citep{DBLP:conf/acl/AhmadianCGFKPUH24, DBLP:journals/corr/abs-2409-12917}, are common techniques to perform RL on LLMs"
- PPO: Proximal Policy Optimization, a popular policy gradient algorithm. "Retroformer \citep{DBLP:conf/iclr/YaoHNLFXNC0AXMW24} which uses PPO"
- REINFORCE: A Monte Carlo policy gradient algorithm for optimizing stochastic policies. "e.g., REINFORCE \citep{DBLP:conf/acl/AhmadianCGFKPUH24, DBLP:journals/corr/abs-2409-12917}"
- Response-critique-refinement: The three-step interaction where the actor responds, the critic critiques, and the actor refines. "It operates through a response-critique-refinement process."
- Reward shaping: Designing reward functions to guide learning dynamics and encourage desired behaviors. "We explore several reward shaping approaches, demonstrate their failure modes, and investigate why they fail to incentivize satisfactory critiquing ability."
- RLHF: Reinforcement Learning from Human Feedback, used for aligning LLM behavior. "such as RLHF for alignment \citep{DBLP:conf/nips/Ouyang0JAWMZASR22, DBLP:journals/corr/abs-2307-04964, DBLP:journals/corr/abs-2401-06080, DBLP:journals/corr/abs-2402-03300}."
- RLOO: REINFORCE Leave-One-Out; a policy gradient variant that avoids training a value model. "In Critique-RL, we use RLOO as our base algorithm as it performs well and does not require a value model."
- Scalable oversight: Approaches to supervise and evaluate complex model behaviors without relying on costly strong supervisors. "This problem is often referred to as scalable oversight \citep{DBLP:journals/corr/abs-2211-03540}."
- STaR: Self-Taught Reasoner; an iterative fine-tuning method using self-generated and filtered data. "STaR \citep{DBLP:conf/nips/ZelikmanWMG22} which iteratively fine-tunes critique models on self-generated data and filtered based on the refinement correctness of the actor."
- Supervised fine-tuning (SFT): Training a model on labeled critique data to initialize a critic. "SFT which fine-tunes models with critique data."
- Two-stage RL: An RL training approach with separate phases for optimizing discriminability and then helpfulness. "Critique-RL adopts a two-stage optimization strategy."
- Value model: A model estimating expected returns used in some RL algorithms; RLOO avoids needing one. "does not require a value model."
Collections
Sign up for free to add this paper to one or more collections.