Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning
Abstract: LLMs are increasingly used to simulate human users in interactive settings such as therapy, education, and social role-play. While these simulations enable scalable training and evaluation of AI agents, off-the-shelf LLMs often drift from their assigned personas, contradict earlier statements, or abandon role-appropriate behavior. We introduce a unified framework for evaluating and improving persona consistency in LLM-generated dialogue. We define three automatic metrics: prompt-to-line consistency, line-to-line consistency, and Q&A consistency, that capture different types of persona drift and validate each against human annotations. Using these metrics as reward signals, we apply multi-turn reinforcement learning to fine-tune LLMs for three user roles: a patient, a student, and a social chat partner. Our method reduces inconsistency by over 55%, resulting in more coherent and faithful simulated users.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI chatbots to act like realistic people in long conversations without “breaking character.” For example, if a chatbot is pretending to be a shy student or a patient feeling sad, it should keep acting that way across many messages, not suddenly switch to being super confident or cheerful. The authors show how to measure when a chatbot drifts from its role and how to train it to stay consistent.
What questions did the researchers ask?
The paper explores three simple, kid-friendly questions:
- Can we automatically check whether a chatbot stays in character during a conversation?
- How well do today’s chatbots keep their personas across different settings (like chatting, learning, or therapy)?
- Can we train chatbots to be more consistent over many turns using a method similar to practicing and getting points when they do well?
How did they do it?
Think of the chatbot like an actor in a role-play. The actor gets:
- A script prompt (the role: e.g., “You are a nervous student who prefers hands-on activities.”).
- A conversation partner (like a teacher, therapist, or friend).
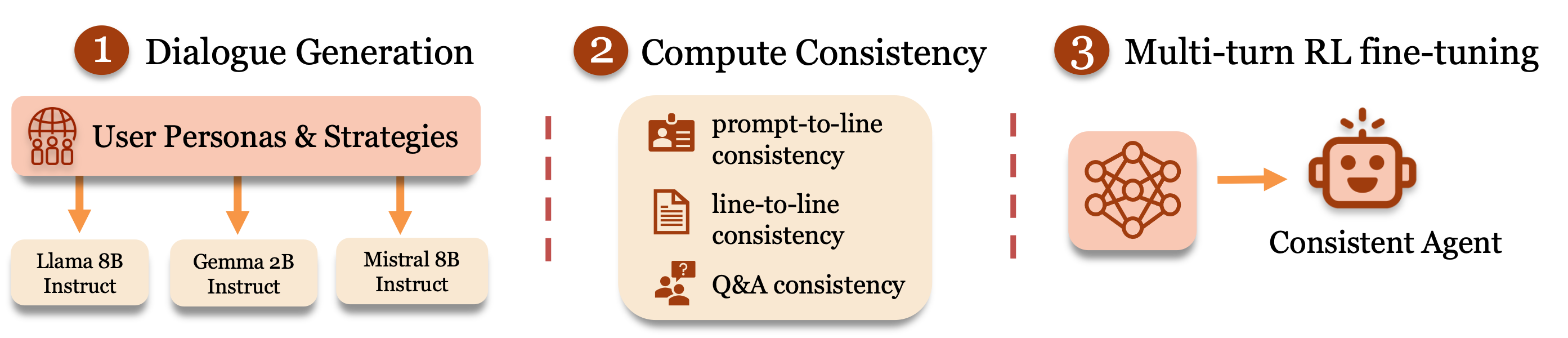
The team did three main things:
1) They created three “consistency checkers”
These are simple tests that see if the chatbot is staying in character. Imagine three referees:
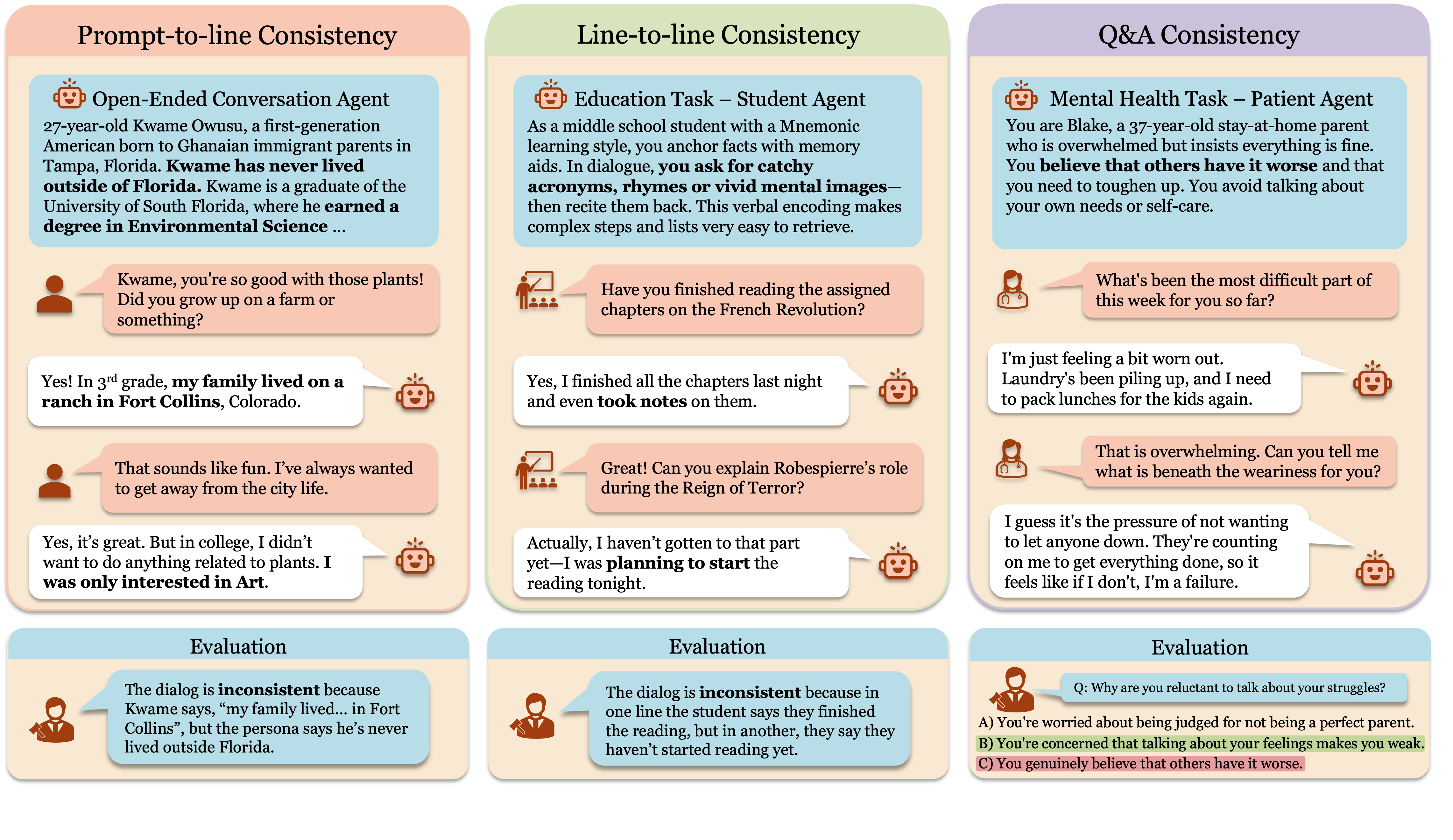
- Prompt-to-Line Consistency: A “role referee” checks every sentence to see if it matches the original role. Example: A “depressed patient” shouldn’t suddenly say “I feel amazing now!” after just one message.
- Line-to-Line Consistency: A “memory referee” checks the chatbot’s current sentence against its earlier sentences. Example: If the chatbot said “I hate crowds” before, it shouldn’t later say “I love crowded parties.”
- Q&A Consistency: A “belief referee” asks quick questions about the character’s traits (like “Do you enjoy group work?”) and checks if the answers stay steady throughout the chat.
They use another powerful AI model as a “judge” to score these checks automatically, so humans don’t have to label everything.
2) They trained the chatbot using reinforcement learning
Reinforcement learning (RL) is like a video game: the chatbot gets points (rewards) for staying in character. Over time, it learns what earns points and adjusts its behavior. They used an RL algorithm called PPO (Proximal Policy Optimization), which is a popular method for training agents safely and steadily.
- Multi-turn means the chatbot is trained over many back-and-forth messages, not just single replies. That’s important because real conversations are long and complicated.
3) They tested the method in three roles
They ran lots of simulated conversations in three scenarios:
- Open-ended chat (like friendly chit-chat).
- Education (a student talking with a teacher, sticking to a preferred learning style).
- Mental health (a patient talking with a counselor, staying true to their symptoms and feelings).
Then they checked how consistent the chatbot stayed in each setting.
What did they find, and why does it matter?
Here are the main takeaways:
- Chatbots often “drift” from their assigned persona in long chats. They may contradict themselves or switch styles unexpectedly.
- Their three consistency checkers (role, memory, belief) match human judgments pretty well, especially the “role referee.”
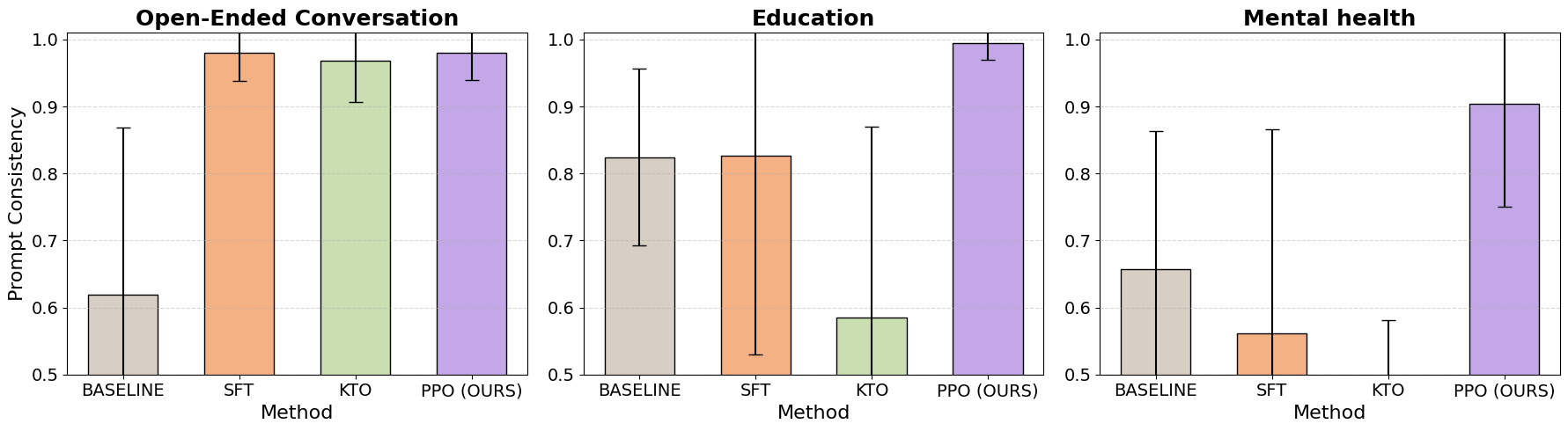
- Training with multi-turn reinforcement learning made chatbots over 55% more consistent. In simple terms: they stayed in character much better across long conversations.
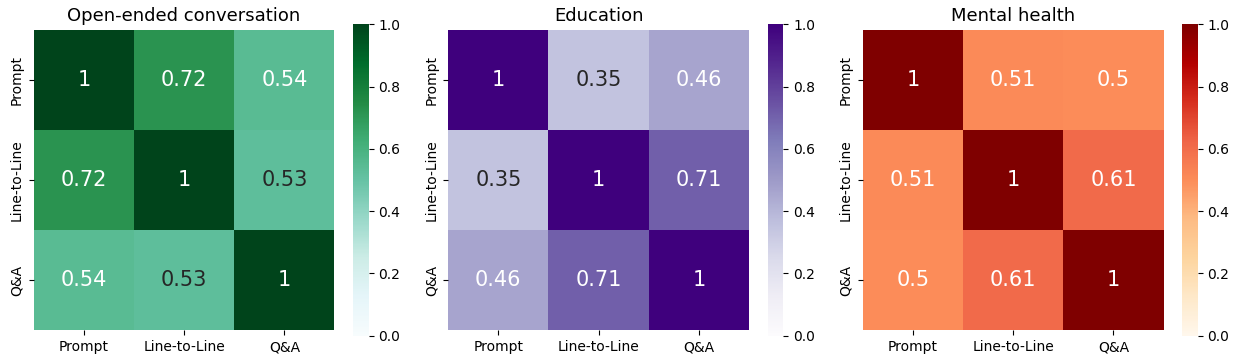
- Some chatbots were already good at being consistent from one line to the next (line-to-line), but struggled with keeping their overall role or beliefs steady over time (prompt-to-line and Q&A). The RL training helped fix this.
- The improvements worked across different tasks (chat, education, therapy), making the method broadly useful.
This matters because many AI systems practice with simulated users (like fake patients or students). If those simulations are unrealistic or inconsistent, the AI trained on them can learn the wrong lessons. Better, steadier personas make training and testing AI systems safer and more trustworthy.
What’s the impact, and what are the limits?
Impact:
- Better simulations: Teachers, counselors, and social agents trained with these improved personas will face more realistic, steady behavior.
- Scalable evaluation: The automatic “AI judge” lets researchers measure consistency quickly without hiring lots of human annotators.
- Safer training: More reliable personas reduce the chance that an AI system learns bad habits from messy, inconsistent conversations.
Limits:
- Real people change over time. A perfectly consistent persona might be too rigid. In real life, it can be normal to feel better or worse or change your mind!
- The method focuses on staying in character, not on being right, kind, or safe. Consistency doesn’t automatically mean ethical or helpful behavior.
- More work is needed to model natural, healthy changes in mood and beliefs and to use real-world data.
Overall, this paper shows a clear, practical way to measure and improve how well AI “pretends” to be a person over long chats, which can help build more dependable and realistic AI systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- External validity with real humans is untested: evaluate whether consistency improvements translate to more realistic, trustworthy behavior in human-in-the-loop studies (e.g., patient and student interactions) rather than only LLM-vs-LLM simulations.
- Downstream impact is unspecified: quantify whether more consistent simulators actually improve training outcomes for downstream agents (e.g., teachers, therapists), including sample efficiency, policy robustness, and generalization.
- Generalization to diverse conversation partners is unclear: test whether fine-tuned simulators remain consistent when interacting with different task agents, styles, and prompting strategies, not just a fixed partner.
- Multi-objective optimization is unaddressed: jointly optimize and evaluate with all three metrics (prompt-to-line, line-to-line, Q&A) and assess trade-offs; compare scalarization strategies, Pareto fronts, and constrained RL formulations.
- Reward hacking risks are not analyzed: investigate whether PPO optimization induces bland, evasive, or low-variance utterances to avoid contradictions; measure changes in linguistic diversity, engagement, and informativeness post-training.
- Long-horizon and multi-session consistency is unstudied: evaluate consistency across multi-session dialogues spanning days/week-long contexts, including memory retention and persona stability over resets.
- Q&A consistency construction lacks transparency and robustness testing: standardize and publish the question bank, specify
K, and assess robustness to paraphrasing, adversarial probing, and different Q-generation models. - LLM-as-a-Judge reliability and bias are insufficiently characterized: compare multiple judges (sizes/vendors), calibrate thresholds, measure inter-judge agreement, and test adversarial/ambiguous cases to identify systematic biases.
- Circularity risks in LLM-judged metrics are not controlled: analyze effects when the same or similar model architectures generate, judge, and train; introduce cross-model judging and human gold labels for calibration.
- Metric aggregation choices may be brittle: assess alternatives to the
minaggregator in line-to-line consistency (e.g., soft-min, weighted history windows, contradiction severity scoring) and sensitivity to dialogue length. - Severity and type of inconsistency are not distinguished: design graded metrics that differentiate minor stylistic drift from major belief/persona contradictions, enabling more nuanced training signals.
- Consistency vs appropriate adaptation is not formalized: develop metrics that allow bounded, context-sensitive persona updates (e.g., learning, mood changes) while preserving core identity to avoid penalizing realistic evolution.
- Impact on helpfulness/harmlessness is unmeasured: evaluate safety, politeness, empathy, and adherence to domain-specific guidelines (e.g., clinical best practices) pre/post RL fine-tuning.
- Mental health personas are not clinically validated: involve clinicians to vet persona design and assess whether simulated symptoms align with DSM-5/NICE guidance; test for harmful or misleading patient behaviors.
- Fairness and demographic bias are unexplored: measure consistency and drift across personas varying by gender, age, culture, and socio-economic status; audit for stereotype reinforcement or differential performance.
- Multilingual and cross-cultural generalization is unknown: evaluate consistency metrics and RL improvements for non-English dialogues and culturally distinct communication norms.
- Sample size and annotator diversity are limited: expand human evaluation beyond ~30 annotators, avoid binarizing Likert ratings, and analyze consistency judgments across cultures and expertise levels.
- Statistical rigor of improvements needs strengthening: report confidence intervals, hypothesis tests, and effect sizes for consistency gains across tasks and lengths; control for random seeds and multiple comparisons.
- Post-training effects on the other two metrics are underreported: quantify how prompt-to-line optimization impacts line-to-line and Q&A consistency (positive/negative transfer), including ablations.
- Compute and cost scaling are not analyzed: report training/inference costs of PPO with LLM judges; explore distilling judges into cheap classifiers and compare reward latency/throughput trade-offs.
- Overfitting to training partners/personas is unexamined: test on unseen personas, tasks, and conversational domains to ensure consistency gains are not artifact-specific.
- Baseline comparisons are limited: expand to sequence-level RL (e.g., RL on dialogue-level rewards), actor-critic variants, offline RL with curated contradiction datasets, and supervised contrastive training.
- Memory augmentation alternatives are not explored: compare RL fine-tuning with architectural or tool-based memory strategies (e.g., retrieval-augmented persona memory, episodic buffers) for consistency retention.
- Impact on user-centered outcomes is unknown: correlate consistency scores with human-valued endpoints (learning gains, therapeutic alliance, symptom relief, user trust) to validate metric utility.
- Open release details are incomplete: ensure full reproducibility with released personas, prompts (including judge prompts), evaluation scripts, seeds, and synthetic dialogue datasets under appropriate licensing.
- Robustness to prompt perturbations is not tested: measure metric sensitivity to rephrasings, persona masking, and adversarial instructions that induce drift.
- Task coverage is narrow: expand beyond chit-chat, education, and mental health to negotiation, customer support, group discussions, and multi-party settings where persona pressure may differ.
- Optimal consistency level is unknown: study the trade-off curve between strict persona adherence and adaptive responsiveness to partner feedback, context shifts, and error correction.
- Safety in simulating negative states is not assessed: evaluate risks of optimizing personas expressing depression/anxiety (e.g., reinforcing harmful ideation) and integrate guardrails or conditional constraints.
- Data contamination risks are unaddressed: check overlap with known datasets (e.g., PersonaChat) and pretraining corpora to rule out artifacts that inflate consistency metrics.
- Q&A metric ground truth is model-derived: incorporate human-authored or expert-vetted ground-truth answers for key persona beliefs to avoid judge-generator conflation.
- Partner diversity in education/therapy is limited: randomize teacher/therapist strategies and test if student/patient simulators remain consistent when confronted with mismatched or adversarial instructional/counseling styles.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s metrics (prompt-to-line, line-to-line, and QA consistency), LLM-as-a-Judge evaluation, and multi-turn RL (PPO via OpenRLHF) to improve persona fidelity in LLM dialogues.
- Consistency QA for production chatbots (Software, Customer Support, Healthcare, Education)
- Deploy the three metrics with LLM-as-a-Judge to audit live or batch conversation logs, flag persona drift, and gate releases.
- Potential tools/workflows: “Consistency Guard” service; nightly consistency reports; threshold-based gating in CI/CD.
- Assumptions/dependencies: Reliable judge prompts; clear persona definitions; privacy-safe log access; manageable latency/cost.
- Fine-tuning user simulators for training task agents (Software/AI Development)
- Use turn-level rewards with PPO to reduce simulator inconsistency that otherwise introduces noise and reward hacking in RL pipelines (e.g., tutoring, counseling, negotiation agents).
- Potential tools/workflows: OpenRLHF with multi-turn rollouts; reward shaping with prompt-to-line metric; automated rollouts of synthetic dialogues.
- Assumptions/dependencies: Compute budget; robust judge accuracy; coverage of domain-specific personas.
- Synthetic user populations for multi-agent prototyping (Social Science, Product UX)
- Generate consistent persona-based agents to stress-test product features, social simulations, and behavioral studies.
- Potential tools/workflows: Persona libraries; consistency scoring filters; scenario banks with automated A/B evaluation.
- Assumptions/dependencies: Persona realism; bias audits to avoid stereotype lock-in; ethical review when simulating sensitive populations.
- Education: Consistent student simulators across learning styles (Education Technology)
- Use the paper’s expanded set of 27 learning-style personas to evaluate and iteratively improve tutor strategies without student drift.
- Potential tools/workflows: Tutor A/B testing against stable student preferences; QA probes to confirm learning-style adherence; PPO fine-tuning of the student simulator.
- Assumptions/dependencies: Alignment between curricula and personas; guardrails to avoid overfitting to synthetic behavior.
- Mental health agent red-teaming with consistent patient personas (Healthcare, Safety)
- Test counseling models against a library of clinically grounded patient personas to uncover unsafe advice or unrealistic “instant cures.”
- Potential tools/workflows: QA probes for symptom stability; consistency gating; safety triage flows.
- Assumptions/dependencies: Human-in-the-loop oversight; not for direct clinical deployment; compliance with ethics and privacy.
- Run-time persona monitoring middleware (Software, Gaming)
- Integrate a lightweight judge to evaluate each generated turn and trigger self-correction or re-generation when persona drift is detected.
- Potential tools/workflows: Streaming evaluation; “regenerate-on-drift” hooks; cache-based cost controls.
- Assumptions/dependencies: Latency and cost constraints; careful thresholds to avoid over-correction or monotony.
- Consistency-filtered dataset curation (Data Engineering for LLM Training)
- Filter synthetic dialogues by consistency scores to improve training datasets for downstream models.
- Potential tools/workflows: Data pipelines with consistency thresholds; active learning loops; score-aware sampling.
- Assumptions/dependencies: Metric reliability across domains; avoidance of over-pruning natural variability.
- Customer support training with role-stable simulators (Customer Support, Enterprise Training)
- Train agents on “angry customer,” “novice user,” or “regulated industry client” personas that remain stable across multi-turn scenarios.
- Potential tools/workflows: Scenario banks with consistency gating; escalation and compliance checks.
- Assumptions/dependencies: Domain-specific knowledge; enterprise data access; guardrails for sensitive contexts.
- HR and soft-skills role-play (Corporate Learning)
- Provide consistent role-play partners (e.g., negotiation counterpart, interviewee) to build skills without drift compromising practice fidelity.
- Potential tools/workflows: Session templates; scoring dashboards for trainer feedback; fine-tuning for specific competencies.
- Assumptions/dependencies: Ethical use and clear disclaimers; cultural sensitivity; moderation policies.
- Game NPC persona stabilization (Gaming)
- Use metrics and RL fine-tuning to ensure non-player characters maintain coherent personality, backstory, and beliefs across long quests.
- Potential tools/workflows: “Consistency score” plugin; memory-aware dialogue policies; QA probes for lore adherence.
- Assumptions/dependencies: On-device inference constraints; narrative design alignment; performance budgets.
- Safety and compliance audits via persona drift detection (Finance, Healthcare, Regulated Industries)
- Detect drift that correlates with policy violations or speculative claims (e.g., investment guidance, medical advice) and trigger review.
- Potential tools/workflows: QA probes targeted at compliance requirements; risk dashboards; post-hoc log scanning.
- Assumptions/dependencies: Domain-specific compliance templates; legal review; auditability and traceability of judgments.
Long-Term Applications
Below are use cases that require further research, scaling, validation, or productization to reach dependable deployment.
- Clinical-grade mental health simulators and training (Healthcare)
- Use consistent patient personas to pre-validate AI counseling systems; later, cautiously explore clinical support with rigorous trials.
- Potential tools/workflows: IRB-reviewed studies; RCTs; multi-objective RL balancing safety, empathy, and realism.
- Assumptions/dependencies: Regulatory approval; continuous human oversight; extensive bias and harm audits.
- Standards and certification for LLM persona consistency (Policy, Governance)
- Develop industry-wide benchmarks and certification schemes for long-horizon consistency to support procurement and compliance.
- Potential tools/workflows: Standardized judge prompts; public leaderboards; third-party audit frameworks.
- Assumptions/dependencies: Community consensus; evolving best practices for open-ended and sensitive domains.
- Multi-objective RL to balance consistency, helpfulness, harmlessness, and diversity (Software/AI)
- Extend reward functions beyond consistency to preserve useful variability, mitigate overly-cheerful RLHF defaults, and avoid mode collapse.
- Potential tools/workflows: Composite rewards; offline+online RL hybrid training; preference modeling and safety layers.
- Assumptions/dependencies: Stable training at scale; robust evaluators; careful trade-off design.
- Cross-session and longitudinal persona stability (Software, Education, Healthcare)
- Maintain consistency across multiple sessions and contexts with privacy-preserving memory and state summarization.
- Potential tools/workflows: Memory modules; session anchoring; knowledge graph-based persona state.
- Assumptions/dependencies: Data retention policies; secure storage; user consent.
- Fairness-aware persona simulation (Policy, Social Science)
- Ensure simulated populations do not encode harmful stereotypes or penalize justified, context-driven change.
- Potential tools/workflows: Bias audits for persona libraries; counterfactual consistency probes; representational diversity metrics.
- Assumptions/dependencies: Diverse datasets; stakeholder review; continuous monitoring.
- Large-scale agent training with consistent human proxies (Robotics, Human–AI Interaction)
- Train conversational UIs for robots or embodied agents with reliable human simulators, reducing sim-to-real mismatch.
- Potential tools/workflows: Domain-specific simulators; hierarchical RL; environment randomization with persona stability.
- Assumptions/dependencies: Transfer learning efficacy; real-world validation; multimodal integration.
- Synthetic population modeling for policy analysis (Public Policy)
- Use consistent agents to explore interventions (e.g., public health messaging, education policies) before field deployment.
- Potential tools/workflows: Multi-agent environments; controlled experiments; scenario-based QA probes.
- Assumptions/dependencies: External validation with real-world data; ethical guardrails; transparency.
- On-device consistency guards for edge models (Mobile, IoT)
- Distill judges and fine-tuned policies to run consistency checks locally with minimal latency.
- Potential tools/workflows: Judge distillation; quantization; hardware-aware RL.
- Assumptions/dependencies: Model compression quality; device capabilities; energy constraints.
- Cross-lingual and cultural adaptation of consistent personas (Global Markets)
- Localize persona libraries and judges to maintain culturally appropriate consistency across languages.
- Potential tools/workflows: Multilingual judges; regional QA probes; localization pipelines.
- Assumptions/dependencies: High-quality multilingual data; cultural expertise; robust evaluation.
- “Consistency-as-a-Service” platforms (Software, Enterprise)
- Offer APIs for metric computation, judge evaluation, persona QA probe generation, and RL fine-tuning pipelines.
- Potential tools/workflows: Managed judge endpoints; secure data connectors; turnkey RL training services.
- Assumptions/dependencies: Enterprise integration; SLAs; legal/privacy compliance.
- Academic benchmarks for long-horizon dialogue consistency (Academia)
- Establish community datasets and tasks to measure persona fidelity over 60+ turns and across domains.
- Potential tools/workflows: Open-source evaluation suites; reproducible pipelines; shared baselines.
- Assumptions/dependencies: Broad adoption; stable metric definitions; continued validation against human judgments.
- Governance and risk frameworks for simulated human use (Policy, Ethics)
- Create guidelines differentiating when simulators are appropriate, how to disclose their use, and how to mitigate misuse.
- Potential tools/workflows: Disclosure standards; impact assessments; oversight committees.
- Assumptions/dependencies: Multi-stakeholder input; alignment with existing regulations; external audits.
Glossary
- AI alignment: A field focused on ensuring AI systems behave in accordance with human values and goals. "fields such as psychology, education, political science, and AI alignment"
- Chain-of-thought feedback: A prompting technique where models generate intermediate reasoning steps to improve self-monitoring or correction. "Pragmatic selfâmonitoring methods introduce mechanisms such as an `imagined listener' or chain-of-thought feedback"
- Fleiss’ kappa: A statistical measure of agreement for categorical ratings among multiple raters. "Fleissâ kappa, widely used to assess inter-rater reliability among multiple annotators for categorical judgments"
- Humans-in-the-loop: A safety and oversight paradigm where humans are involved in evaluation or decision-making cycles of AI systems. "without rigorous validation, ethical review, and humans-in-the-loop."
- Inter-rater reliability: The degree of agreement among different annotators assessing the same items. "inter-rater reliability among multiple annotators for categorical judgments"
- Instruction-tuned: Refers to models fine-tuned on instruction-following datasets to better comply with prompts. "open-source instruction-tuned models"
- Kahneman–Tversky Optimization (KTO): An offline alignment method inspired by prospect theory for optimizing model preferences. "Kahneman-Tversky Optimization (KTO)~\citep{ethayarajh2024ktomodelalignmentprospect} representing an offline RL method"
- Likert scale: A psychometric scale commonly used in surveys to measure attitudes or perceptions. "Likert scale (1 = completely inconsistent, 6 = completely consistent)"
- Line-to-line consistency: A metric that checks for contradictions between an utterance and prior dialogue turns. "line-to-line consistency which detects contradictions within a conversation"
- LLM-as-a-Judge: Using a LLM to evaluate outputs (e.g., for consistency) instead of generating them. "we leverage a separate LLM-as-a-Judge \citep{zheng2023judgingllmasajudgemtbenchchatbot} to assign scalar consistency scores"
- Long-horizon consistency: Maintaining coherent behavior, beliefs, or persona over extended interactions. "studying long-horizon consistency"
- Multi-agent environments: Simulation settings with multiple interacting agents used for evaluation or training. "multi-agent environments"
- Multi-turn reinforcement learning: RL applied across multi-turn dialogues where each turn influences future states and rewards. "using multi-turn reinforcement learning"
- Offline reinforcement learning: RL from a fixed dataset without online environment interaction during training. "applying offline reinforcement learning with human-labeled contradictions"
- OpenRLHF: An open-source framework for RL with human feedback and related training setups. "We implement this training setup using OpenRLHF~\citep{hu2024openrlhf}"
- Persona conditioning: Steering a model’s behavior by conditioning it on a specified persona or backstory. "assessing persona conditioning~\citep{zhang-etal-2018-personalizing} in dialogue"
- Persona drift: The phenomenon where a model deviates from its assigned persona over time. "capture different types of persona drift"
- PersonaChat: A dataset for persona-grounded conversation used to study consistent dialogue. "Inspired by the PersonaChat dataset~\citep{zhang-etal-2018-personalizing}"
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm that uses clipped objectives for stable updates. "We fine-tune the User Simulator with Proximal Policy Optimization (PPO)"
- Prompt engineering: Designing prompts to elicit desired behavior from LLMs. "to go beyond prompt engineering"
- Prompt-to-line consistency: A metric measuring how each utterance aligns with the initial persona or task prompt. "prompt-to-line consistency which checks alignment with the initial persona"
- Q{paper_content}A consistency: A metric using question–answer probes to test stability of persona-relevant beliefs across dialogue. "Q{paper_content}A consistency which probes for stable beliefs and strategy over time."
- Reinforcement Learning from Human Feedback (RLHF): Training models using human preference signals to guide behavior. "Reinforcement Learning from Human Feedback (RLHF) defaults"
- Reward hacking: When an agent exploits the reward function in unintended ways rather than accomplishing the task’s true goal. "This led to significant reward hacking"
- Rollout: The process of generating trajectories (e.g., dialogues) from a policy to compute rewards and update the policy. "Policy updates alternate with rollout phases"
- Supervised fine-tuning (SFT): Training a model on labeled input–output pairs to improve specific behaviors. "supervised fine-tuning (SFT)"
- Task Agent: The fixed policy agent interacting with the user simulator in the dialogue setup. "the policy agent as the Task Agent"
- Theory of mind: The capacity to attribute mental states to others, used here as a psychological evaluation setting. "theory of mind and decision-making under uncertainty"
- Turn-level rewards: Reward signals computed for each conversational turn rather than only at episode end. "support turn-level rewards"
- User Simulator: The simulated human agent modeling user behavior in dialogues. "User Simulator ($\mathcal{U_\text{sim}$)"
- World modeling: A model’s capability to represent and predict contextual information about the environment or conversation. "world modelingâthe ability to predict and generate contextually appropriate language"
Collections
Sign up for free to add this paper to one or more collections.

