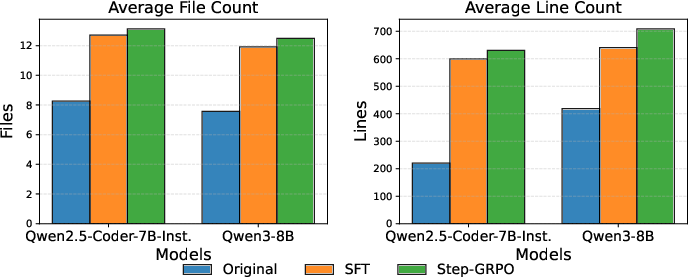
- The paper introduces WebGen-Agent, which integrates multi-level feedback and step-level RL to enhance website generation from natural language instructions.
- It employs a novel Step-GRPO paradigm that leverages dense rewards from screenshot assessments and GUI-agent testing to improve both accuracy and visual appeal.
- Empirical results demonstrate significant performance gains for both proprietary and open-source models, with robust error recovery and optimal state selection mechanisms.
WebGen-Agent: Multi-Level Feedback and Step-Level RL for Interactive Website Generation
Introduction
WebGen-Agent introduces a specialized code agent architecture for end-to-end website generation from natural language instructions, targeting both functional correctness and visual quality. The system addresses the limitations of prior code agents, which predominantly rely on code execution feedback and thus fail to capture visual and interactive deficiencies in generated web applications. WebGen-Agent integrates multi-level feedback—specifically, screenshot-based visual assessment and GUI-agent-based functional testing—into an iterative code generation and refinement loop. Furthermore, the paper proposes a novel Step-GRPO (Generalized Reinforced Policy Optimization) training paradigm that leverages dense, step-level rewards derived from these feedback signals, enabling effective reinforcement learning for open-source LLMs in this domain.
WebGen-Agent Workflow
The WebGen-Agent workflow is an iterative, multi-stage process, where each step consists of code generation, code execution, and feedback gathering. The agent receives a natural language website specification and maintains a trajectory of edits, execution outputs, and feedback. The core workflow is as follows:
- Code Generation: The agent, powered by a coding LLM, generates code edits to the current codebase.
- Code Execution: The codebase is executed in a sandboxed environment. If errors occur, the agent receives the error output and attempts to fix the issue in the next step. After five consecutive errors, a backtracking mechanism restores the codebase to the last known good state.
- Screenshot Feedback: Upon successful execution, a screenshot of the landing page is captured. A visual LLM (VLM) provides a structured description, an appearance score, and improvement suggestions.
- GUI-Agent Testing: If the appearance is deemed satisfactory, a GUI-agent is triggered to test the website’s interactive functionalities, guided by a synthesized instruction that covers all requirements. The GUI-agent returns a functional score and suggestions.
- Best-Step Selection: At the end of the trajectory, the codebase state with the highest combined functional and appearance scores is selected as the final output.

Figure 1: Iterative website generation with screenshot- and GUI-agent-based feedback. A backtracking and best-step-selection mechanism is applied on the basis of the screenshot and GUI-agent testing scores.
This design ensures that both visual and functional requirements are enforced throughout the generation process, with explicit mechanisms to recover from regressions and select optimal intermediate states.
Step-GRPO: Step-Level Reinforcement Learning with Multi-Level Feedback
To address the performance gap between proprietary and open-source LLMs in website code generation, the paper introduces Step-GRPO, a reinforcement learning framework that utilizes dense, step-level rewards derived from the WebGen-Agent workflow. The key innovations are:
This approach enables open-source models (e.g., Qwen2.5-Coder-7B-Instruct, Qwen3-8B) to achieve substantial improvements in both accuracy and visual quality, as measured on the WebGen-Bench benchmark.
Empirical Results
WebGen-Agent is evaluated on WebGen-Bench, a comprehensive benchmark for interactive website generation. The system is tested with both proprietary and open-source LLMs as the coding engine, and with Qwen2.5-VL-32B-Instruct as the feedback VLM. Key findings include:
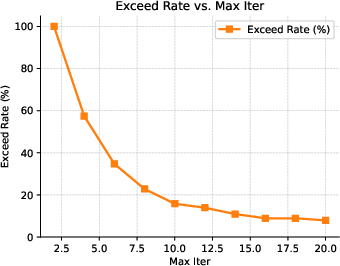
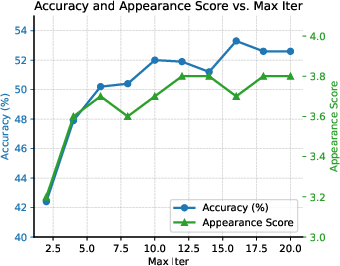
Figure 4: Accuracy (\%) and Appearance Score as a function of the maximum number of iterations.
Qualitative Analysis
Qualitative examples demonstrate that supervised fine-tuning and Step-GRPO training progressively reduce malformed outputs and improve adherence to both appearance and functional requirements. The agent is shown to iteratively refine websites, addressing both visual and interactive deficiencies based on structured feedback.
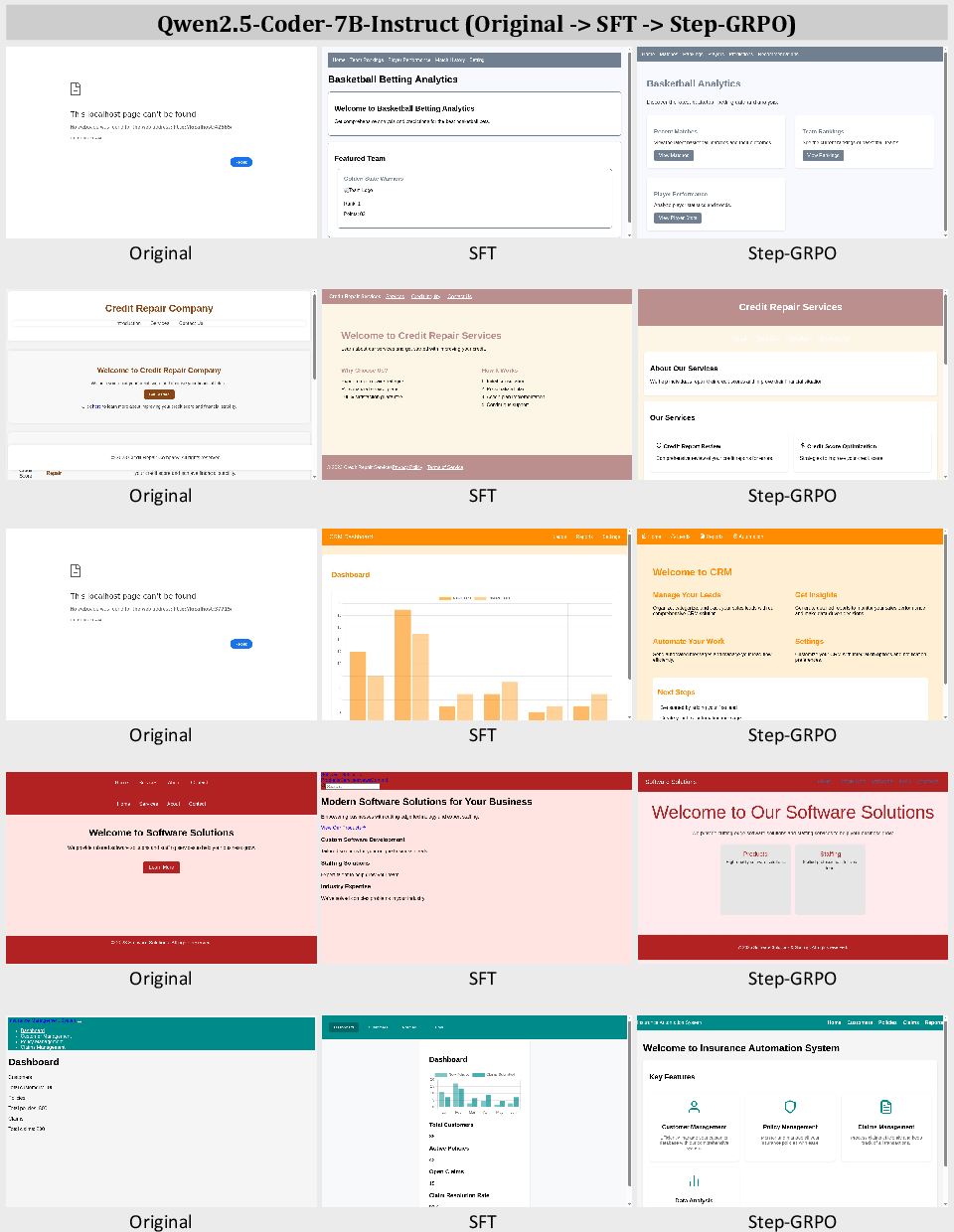
Figure 5: Screenshots of websites created by Qwen2.5-Coder-7B-Instruct, WebGenAgent-LM-7B-SFT, and WebGenAgent-LM-7B-Step-GRPO.
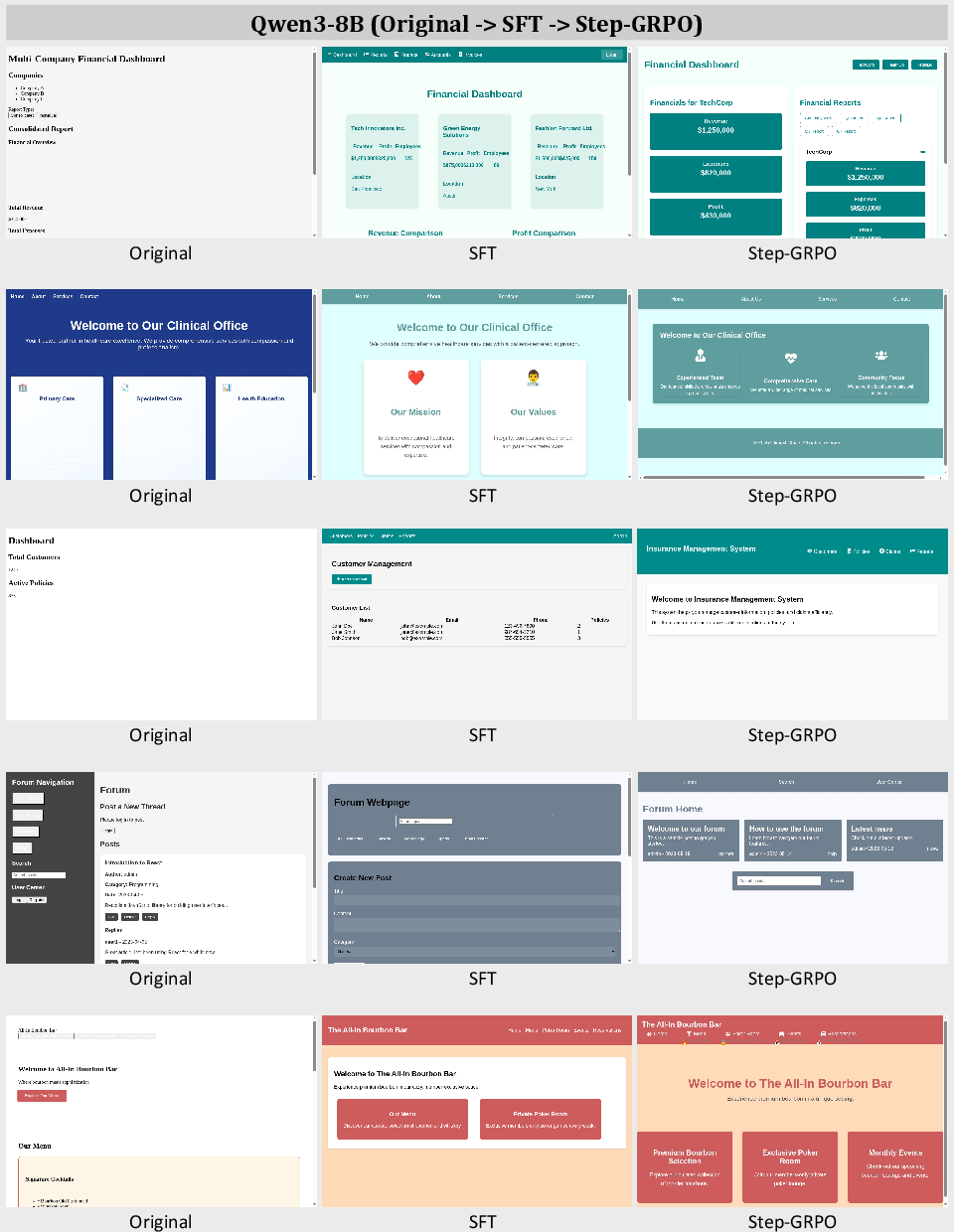
Figure 6: Screenshots of websites created by Qwen3-8B, WebGenAgent-LM-8B-SFT, and WebGenAgent-LM-8B-Step-GRPO.
Implementation Considerations
- Agent Architecture: The decoupling of the coding LLM and feedback VLM is critical for cost efficiency and scalability. The feedback VLM can be a smaller, open-source model, while the coding LLM should be as strong as possible within resource constraints.
- Backtracking and Best-Step Selection: These mechanisms are essential for robustness, preventing error accumulation and ensuring that the final output is the best observed during the trajectory.
- Training Data: High-quality, step-annotated trajectories are required for effective SFT and Step-GRPO. The paper demonstrates that a relatively small number of such trajectories suffice due to the dense supervision.
- Resource Requirements: Step-GRPO training for 7B/8B models requires significant GPU resources (e.g., >24 hours on 16 A800 GPUs), and scaling to larger models is currently limited by hardware availability.
Limitations and Future Directions
- Scalability: Step-GRPO training is currently demonstrated only on 7B/8B models due to computational constraints. Scaling to 30B–72B models is a natural next step.
- Evaluation Scope: The current evaluation does not consider website response speed or network conditions.
- Generalization: While the system is tailored for website generation, the multi-level feedback and step-level RL paradigm could be extended to other domains requiring both functional and visual/interactive quality.
Implications and Future Developments
WebGen-Agent establishes a new paradigm for code agents in domains where both visual and interactive quality are critical. The integration of multi-level feedback and dense, step-level RL supervision enables open-source models to close the gap with proprietary LLMs. This approach is likely to generalize to other agentic tasks involving multimodal outputs and complex user requirements. Future work should focus on scaling the approach to larger models, extending the feedback modalities, and exploring applications beyond website generation.
Conclusion
WebGen-Agent demonstrates that integrating screenshot and GUI-agent feedback into an iterative code agent workflow, combined with step-level RL via Step-GRPO, yields substantial improvements in both the functional and visual quality of generated websites. The approach is effective across both proprietary and open-source LLMs, with strong empirical results and robust ablation analyses. The methodology provides a blueprint for future agentic systems in domains requiring multimodal quality assurance and dense process supervision.