- The paper introduces a modular, three-agent pipeline that decomposes UI-to-code generation into grounding, planning, and generation stages.
- It leverages a vision-language model for semantic UI parsing and grid-based heuristics to generate structurally coherent and responsive code.
- The framework employs scalable data generation and dual-stage post-training to achieve high accuracy across both automatic and qualitative benchmarks.
ScreenCoder: Modular Multimodal Agents for Visual-to-Code Front-End Automation
Introduction
ScreenCoder addresses the persistent challenge of automating the transformation of user interface (UI) designs—typically provided as screenshots or design sketches—into executable front-end code. While recent advances in LLMs and multimodal LLMs (MLLMs) have enabled progress in text-to-code and image-to-code generation, these approaches often lack the architectural modularity and domain-specific priors necessary for robust, interpretable, and high-fidelity UI code synthesis. ScreenCoder introduces a modular, multi-agent framework that decomposes the UI-to-code pipeline into three interpretable stages: grounding, planning, and generation. This design not only improves generation quality and interpretability but also enables scalable data generation for model post-training.
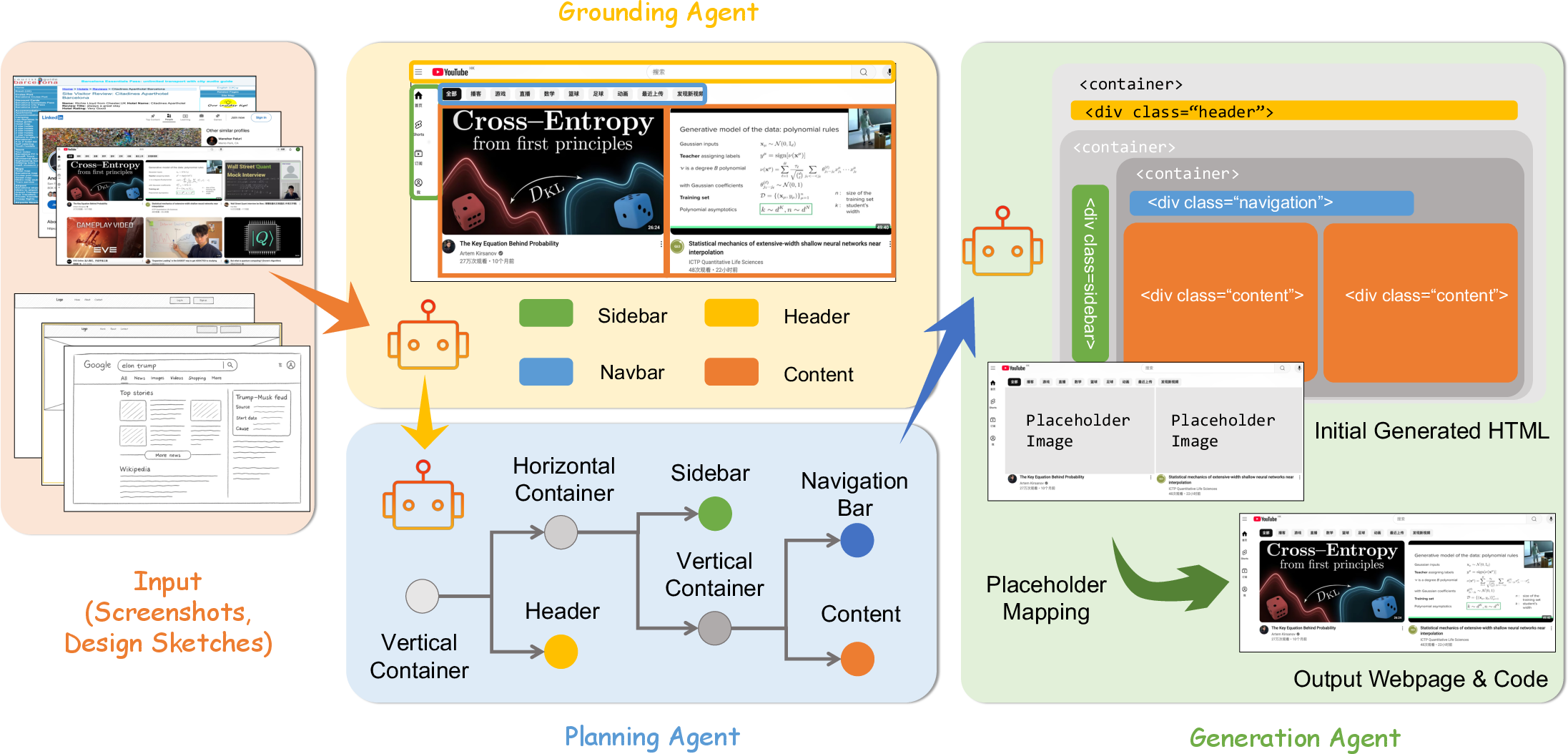
Figure 1: Overview of ScreenCoder’s modular pipeline, illustrating the sequential roles of the Grounding, Planning, and Generation Agents in transforming UI screenshots into structured code.
Modular Multi-Agent Architecture
Grounding Agent
The grounding agent is responsible for perceptual parsing of the input UI image. Leveraging a vision-LLM (VLM), it detects and semantically labels key UI components (e.g., header, sidebar, navigation, main content) via prompt-based region grounding. The agent outputs a layout dictionary mapping each semantic label to its corresponding bounding box in pixel coordinates. This explicit semantic labeling is critical for downstream interpretability and supports interactive, language-driven UI manipulation.
Key technical features include:
- Prompt-driven region detection, extensible to new UI elements.
- Post-processing with class-specific non-maximum suppression and spatial heuristics for deduplication and fallback recovery.
- Main content inference via maximal non-overlapping rectangle extraction.
Planning Agent
The planning agent receives the set of labeled regions and constructs a hierarchical layout tree, T, reflecting spatial adjacency and common web design patterns. The hierarchy is rooted at a viewport-filling container, with child nodes corresponding to detected UI components. The agent applies spatial heuristics and compositional rules to generate a tree structure annotated with grid-template configurations and ordering metadata, directly compatible with CSS Grid and Tailwind CSS utility classes.
This explicit layout representation enables:
- Modular code generation with clear separation of concerns.
- Injection of front-end engineering priors (e.g., grid-based composition, responsive design).
- Support for interactive editing at the structural level.
Generation Agent
The generation agent synthesizes HTML/CSS code by traversing the layout tree and generating code for each component via adaptive, prompt-based language modeling. Prompts are constructed to reflect both the semantic identity and layout context of each region, optionally incorporating user instructions for interactive design. The generated code is assembled according to the tree structure, preserving hierarchy and modularity.
Notable aspects:
- Adaptive prompt construction for context-aware code synthesis.
- Support for user-driven customization via natural language.
- Component-level modularity for downstream refinement.
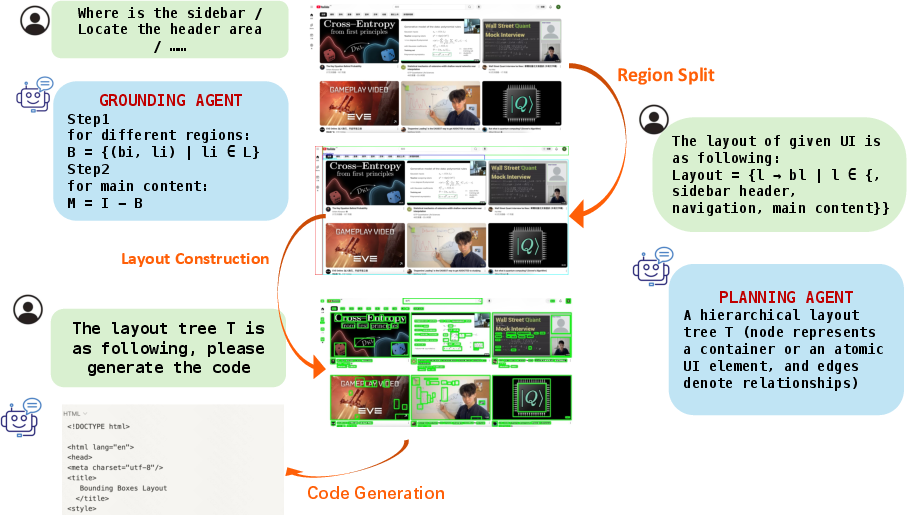
Figure 2: Qualitative example of the UI-to-code pipeline, showing VLM-generated partitions, hierarchical layout tree, and the resulting front-end code.
Component-Level Image Restoration
To address the loss of visual fidelity due to placeholder images, ScreenCoder introduces a component-level image restoration strategy. Detected UI elements are aligned with placeholder regions via affine transformation and bipartite matching (Hungarian algorithm), enabling the restoration of real image crops from the original screenshot into the generated code. This approach improves both the semantic and visual consistency of the rendered UI.
Scalable Data Engine and Model Post-Training
ScreenCoder’s modular pipeline is leveraged as a data engine to generate large-scale, high-quality image-code pairs for model post-training. The authors construct a dataset of 50,000 UI-image/code pairs spanning diverse domains and layout patterns. This dataset is used to fine-tune and reinforce an open-source VLM (Qwen2.5-VL) via a dual-stage process:
- Cold-start supervised fine-tuning (SFT): The model is trained on the generated dataset to align visual layout structure with code syntax.
- Reinforcement learning (RL): The model is further optimized using Group Relative Policy Optimization (GRPO) with a composite reward function integrating block match, text similarity, and position alignment metrics.
This dual-stage post-training yields substantial improvements in UI understanding and code generation quality, as measured by both high-level (CLIP similarity) and low-level (block, text, position, color) metrics.
Experimental Results
ScreenCoder is evaluated on a new benchmark of 3,000 high-quality UI-image/code pairs, with comparisons against state-of-the-art proprietary and open-source VLMs (e.g., GPT-4o, Gemini-2.5-Pro, LLaVA 1.6-7B, DeepSeek-VL-7B, Seed1.5-VL). The evaluation protocol includes both automatic and qualitative assessments:
- Automatic metrics: ScreenCoder achieves the highest scores among open-source models and is competitive with proprietary systems across block match, text similarity, position alignment, color consistency, and CLIP-based visual similarity.
- Qualitative analysis: The modular pipeline produces structurally coherent, visually faithful, and semantically accurate code, with clear improvements in layout fidelity and component recognition.
Implications and Future Directions
ScreenCoder’s modular, interpretable architecture offers several practical and theoretical advantages:
- Robustness and interpretability: Decomposition into grounding, planning, and generation stages enables explicit error analysis, targeted module refinement, and human-in-the-loop feedback.
- Scalability: The data engine facilitates continuous learning and model alignment, addressing the scarcity of high-quality UI-image/code datasets.
- Generality: The framework is readily extensible to other design domains (e.g., mobile, desktop, game UIs) by adapting the grounding vocabulary and planning logic.
- Interactive design: The disentangled pipeline supports real-time, user-driven design iteration and customization.
Potential future developments include:
Conclusion
ScreenCoder advances the state of the art in visual-to-code generation by introducing a modular, multi-agent framework that combines vision-language grounding, hierarchical layout planning, and adaptive code generation. The system demonstrates strong empirical performance, interpretability, and extensibility, and provides a scalable path for dataset creation and model post-training. This work lays a foundation for future research in multimodal program synthesis, interactive design automation, and data-driven model alignment.