- The paper introduces IWR-Bench, a benchmark to assess LVLMs on reconstructing interactive webpages from user interaction videos with dynamic, stateful logic.
- It employs multi-modal temporal reasoning and an agent-as-a-judge protocol, using metrics like IFS and VFS to evaluate both interactive functionality and visual fidelity.
- Results reveal a performance gap between static layout replication and event-driven logic synthesis, underscoring challenges for real-world web automation.
IWR-Bench: Evaluating LVLMs on Interactive Webpage Reconstruction from User Interaction Video
The IWR-Bench benchmark addresses a critical gap in the evaluation of Large Vision-LLMs (LVLMs) for web code generation. While prior benchmarks have focused on static screenshot-to-code tasks, they fail to capture the dynamic, stateful interactions that define real-world web applications. IWR-Bench formalizes the Interactive Webpage Reconstruction (IWR) task: given a user interaction video and all static assets from a live website, a model must generate code that replicates both the visual appearance and interactive behavior observed in the video. This formulation introduces two principal challenges: (1) multi-modal temporal reasoning to infer latent interaction logic from dynamic visual evidence, and (2) advanced code synthesis to implement event-driven, stateful logic.
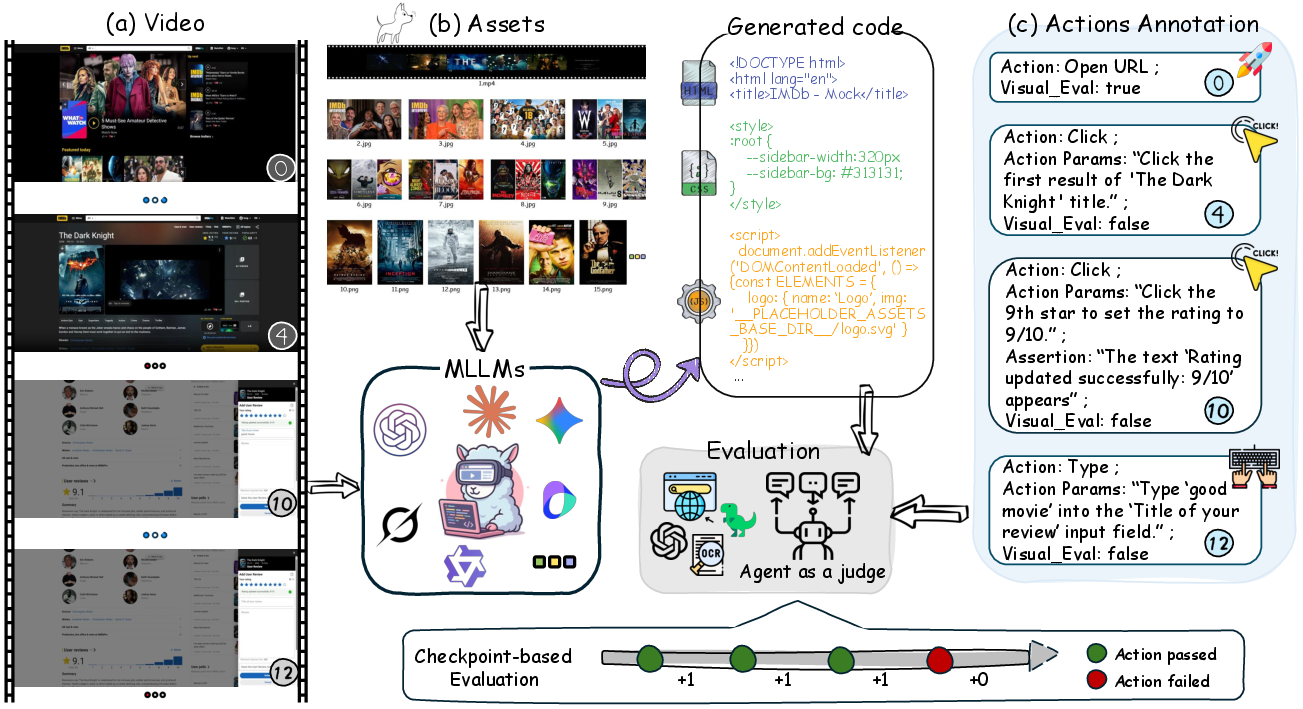
Figure 1: Overview of the IWR-Bench task and evaluation pipeline, including user interaction video, static asset input, and agent-as-judge evaluation.
Benchmark Construction and Taxonomy
IWR-Bench comprises 113 tasks sourced from 100 real-world websites, annotated with 1,001 actions. Each task provides a screen recording of user interactions, a complete set of anonymized static assets, a structured action trajectory, and checkpoint screenshots for evaluation. The benchmark is taxonomized along three orthogonal axes: Application Domain (e.g., e-commerce, productivity, gaming), Visual Complexity (ranging from minimalist to data-dense layouts), and Interaction Logic (from static content to algorithmic/game logic).

Figure 2: IWR-Bench taxonomy, organizing tasks by Domain, Visual Complexity, and Interaction Logic.
The construction pipeline enforces high annotation quality and impartiality through expert curation, multi-stage verification, and cross-annotator review. Asset filenames are anonymized to prevent models from leveraging prior knowledge, forcing reliance on visual matching and reasoning.
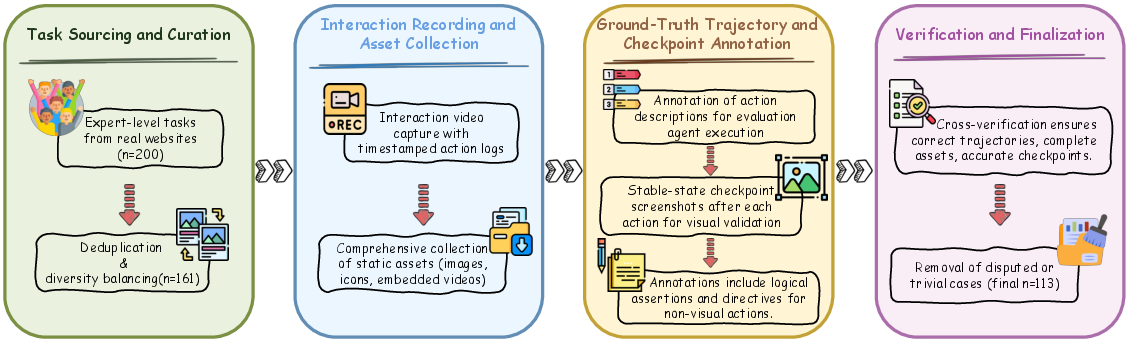
Figure 3: Overview of the benchmark construction process, from task sourcing to annotation and verification.
Evaluation Protocol and Metrics
IWR-Bench employs a robust, automated agent-as-a-judge protocol. For each generated webpage, a deterministic executor sequentially performs the ground-truth action trajectory, verifying operational feasibility and logical assertions at each step. Visual fidelity is assessed at checkpoints using a composite metric: OCR-based text similarity, DINO-based structural similarity, and high-level MLLM-based evaluation. The two primary metrics are:
- Interactive Functionality Score (IFS): Ratio of successfully completed actions to total actions, measuring operational and logical correctness.
- Visual Fidelity Score (VFS): Macro-average of checkpoint visual similarity, combining low-level and high-level assessments.
The Final Score is a weighted combination of IFS and VFS (α=0.7), emphasizing functional correctness.
Experimental Results and Analysis
A comprehensive evaluation of 28 LVLMs (proprietary, open-source, and video-specialized) reveals a pronounced performance hierarchy. Proprietary models (e.g., GPT-5, Claude-Sonnet-4) achieve the highest Final Scores, with GPT-5 reaching 36.35%. Open-source models lag behind, and video-specialized models perform worst, indicating that general multimodal reasoning and code generation are more critical than video-specific architectures for this task.
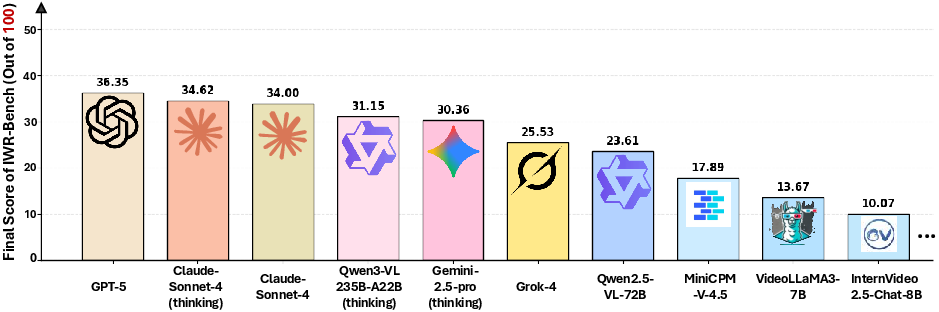
Figure 4: Performance of 10 representative models on IWR-Bench, highlighting the gap between visual fidelity and functional correctness.
A consistent and substantial gap is observed between VFS and IFS across all models. For example, GPT-5 attains 64.25% VFS but only 24.39% IFS, indicating that while static layout replication is moderately successful, event-driven logic synthesis remains severely underdeveloped. Reasoning-enhanced inference ("thinking" variants) provides moderate gains but does not close the gap.
Fine-grained analysis across taxonomy axes shows that performance drops sharply from static (L1) to interactive (L2-L4) tasks, and models struggle with highly structured or data-dense layouts. Domain-wise, models perform best on entertainment/media tasks, suggesting that structured code generation and state management are key bottlenecks.
Case Studies
Representative tasks illustrate the diversity and diagnostic power of IWR-Bench:
- Case 1: Multi-Step E-commerce Workflow ([L2, V2, E-commerce])
Models must replicate filtering, sorting, and cart addition. Claude-Sonnet-4 handles filtering/sorting but fails at cart logic; GPT-5 struggles with initial rendering due to asset overload.
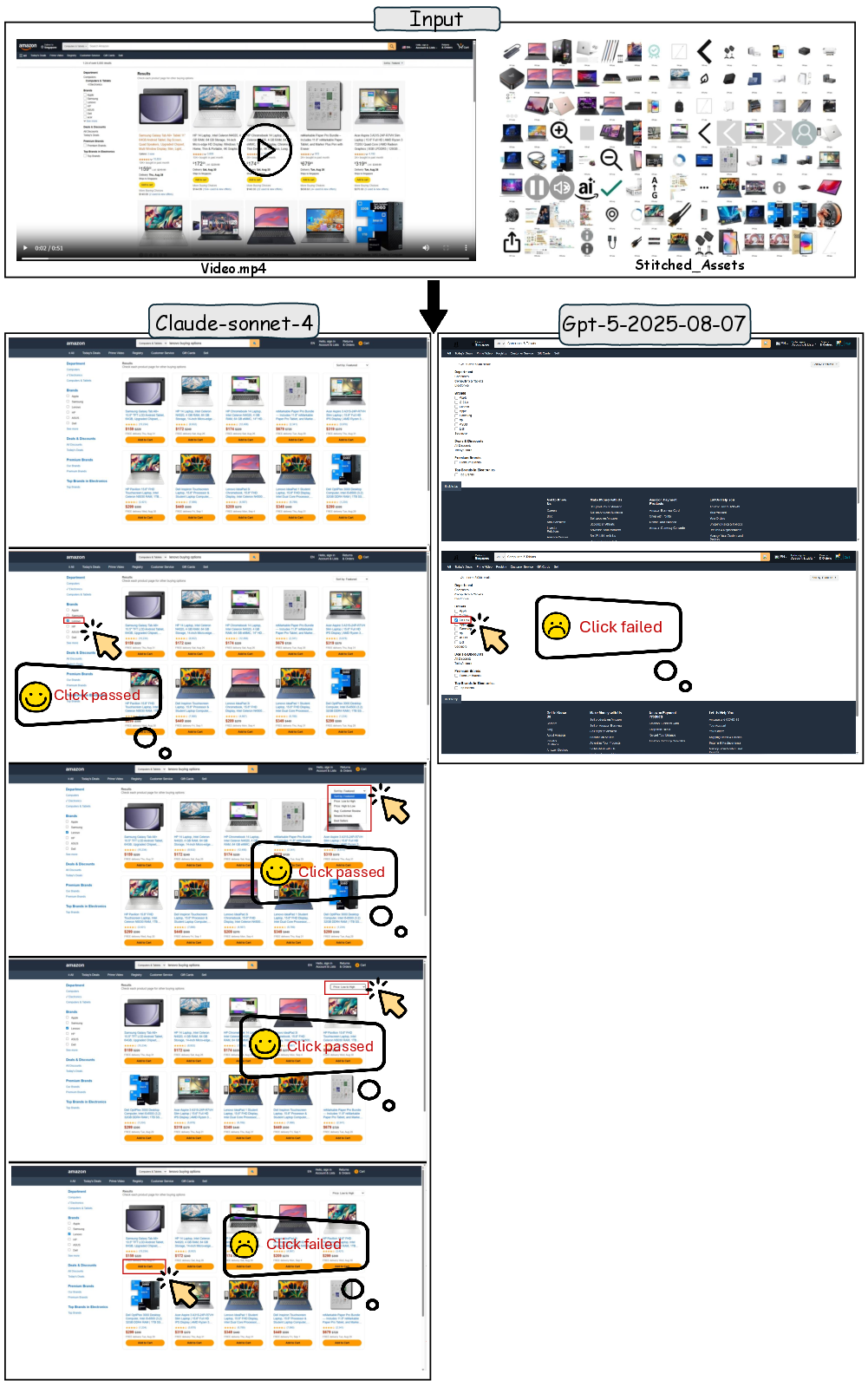
Figure 5: Multi-step e-commerce workflow reconstruction, exposing model failure modes in sequential state manipulation.
- Case 2: Algorithmic Game Logic ([L4, V2, Gaming])
Models must deduce and implement 2048 game logic. Grok-4 succeeds; Qwen2.5-VL-72B fails at block merging, highlighting the challenge of algorithmic reasoning.
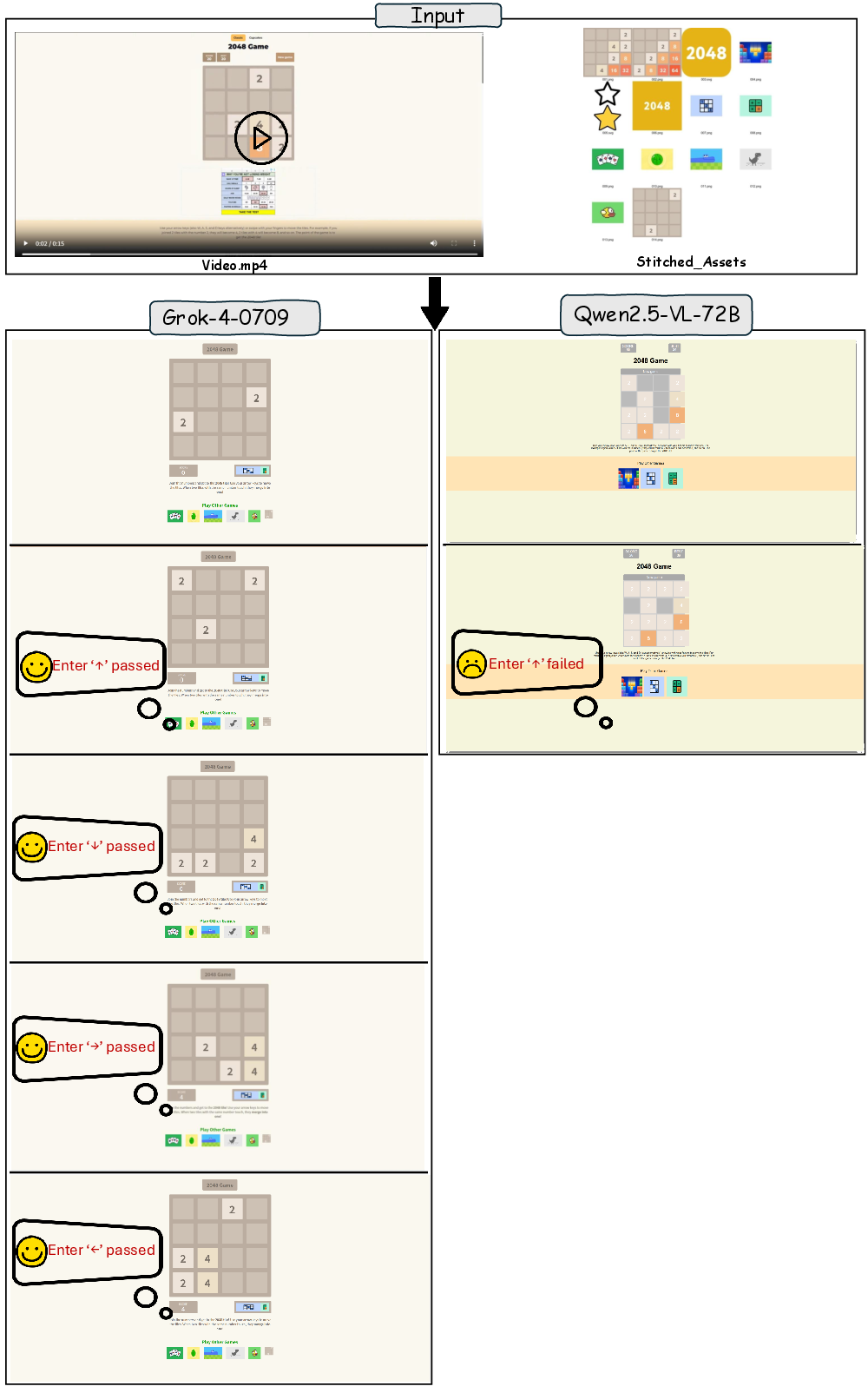
Figure 6: Reconstruction of 2048 game logic, testing algorithmic reasoning and state transition synthesis.
- Case 3: Full-Page Reconstruction with Long Scrolling ([L1, V3, E-commerce])
Models must maintain structural integrity and fine-grained detail across a long, media-rich page. Gemini-2.5-Pro and GPT-5 achieve broad layout fidelity but miss details in icons and product images.
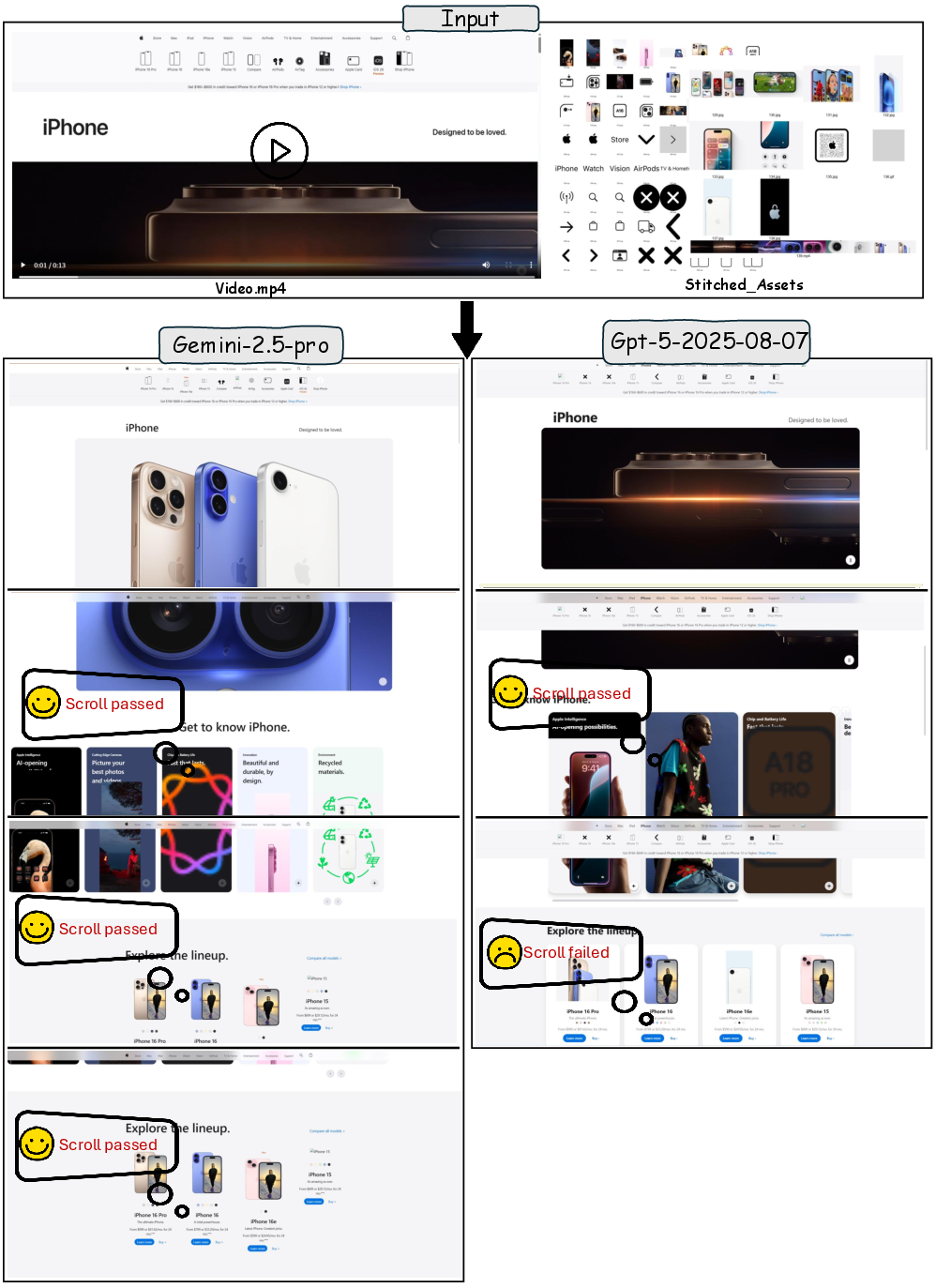
Figure 7: Long-page reconstruction, evaluating visual fidelity and asset matching at scale.
- Case 4: Pomodoro Timer Logic in Mobile Viewport ([L3, V1, Productivity])
Models must implement time-based state transitions in a mobile layout. GLM-4.5V succeeds; Kimi-VL-thinking fails due to missing initial elements.
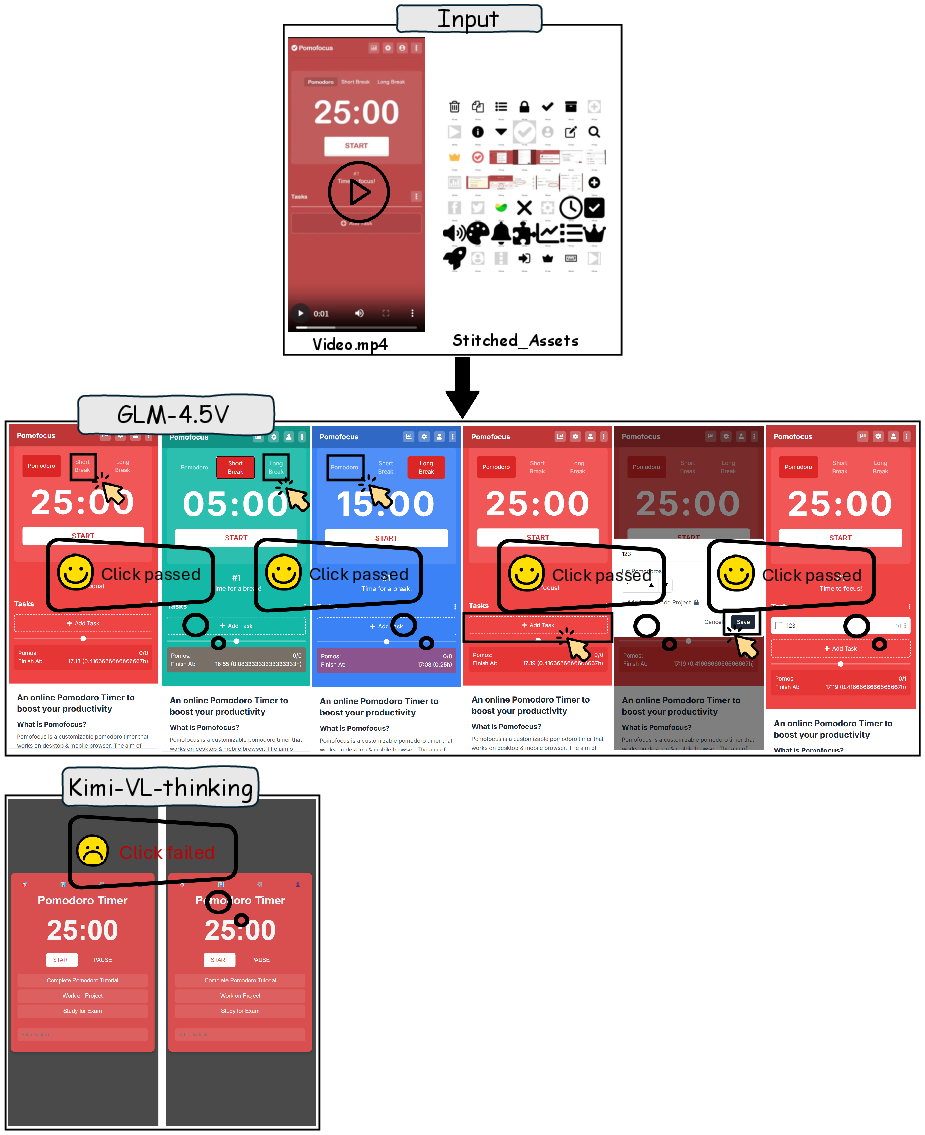
Figure 8: Pomodoro timer reconstruction, testing time-driven state management and mobile layout adaptation.
Implications and Future Directions
IWR-Bench exposes a fundamental limitation in current LVLMs: the synthesis of event-driven, interactive logic from multi-modal temporal evidence is largely unsolved. The stark disparity between visual replication and functional implementation suggests that advances in temporal reasoning, dynamic asset binding, and robust code synthesis are required. The benchmark's agent-as-a-judge protocol and multi-dimensional taxonomy provide a rigorous framework for diagnosing model failure modes and guiding future research.
Practically, IWR-Bench sets a new standard for evaluating LVLMs in web automation, agentic UI understanding, and code generation. The results indicate that models are not yet ready for deployment in autonomous web agents or front-end engineering tasks requiring dynamic interactivity. Theoretically, the benchmark motivates research into multi-modal sequence modeling, causal inference from video, and program synthesis under resource constraints.
Conclusion
IWR-Bench establishes a challenging new frontier for vision-language research, rigorously evaluating LVLMs on interactive webpage reconstruction from user interaction video. The benchmark reveals that while static visual understanding is tractable, functional code generation for dynamic, event-driven logic remains a primary bottleneck. Future work should focus on enhancing temporal reasoning, logic synthesis, and asset binding to enable truly functional web application generation.