VGGRPO: Towards World-Consistent Video Generation with 4D Latent Reward
Abstract: Large-scale video diffusion models achieve impressive visual quality, yet often fail to preserve geometric consistency. Prior approaches improve consistency either by augmenting the generator with additional modules or applying geometry-aware alignment. However, architectural modifications can compromise the generalization of internet-scale pretrained models, while existing alignment methods are limited to static scenes and rely on RGB-space rewards that require repeated VAE decoding, incurring substantial compute overhead and failing to generalize to highly dynamic real-world scenes. To preserve the pretrained capacity while improving geometric consistency, we propose VGGRPO (Visual Geometry GRPO), a latent geometry-guided framework for geometry-aware video post-training. VGGRPO introduces a Latent Geometry Model (LGM) that stitches video diffusion latents to geometry foundation models, enabling direct decoding of scene geometry from the latent space. By constructing LGM from a geometry model with 4D reconstruction capability, VGGRPO naturally extends to dynamic scenes, overcoming the static-scene limitations of prior methods. Building on this, we perform latent-space Group Relative Policy Optimization with two complementary rewards: a camera motion smoothness reward that penalizes jittery trajectories, and a geometry reprojection consistency reward that enforces cross-view geometric coherence. Experiments on both static and dynamic benchmarks show that VGGRPO improves camera stability, geometry consistency, and overall quality while eliminating costly VAE decoding, making latent-space geometry-guided reinforcement an efficient and flexible approach to world-consistent video generation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making AI-generated videos look more real and consistent, especially when the camera moves or when there are moving things in the scene. The authors introduce a method called VGGRPO that helps a video-making AI keep the 3D structure of the world steady over time, so objects don’t “bend,” “drift,” or flicker as the video plays.
Goals and Questions
The paper asks:
- Can we improve the 3D consistency of AI-made videos without changing the main model’s design or slowing it down too much?
- Can we use information about 3D geometry directly from the model’s compressed “latent” space (like a blueprint) instead of converting it back to pixels every time (which is slow)?
- Can this work not only for still scenes (like a stationary room) but also for dynamic scenes (like people running or cars moving)?
How They Did It (Methods)
The authors build two main pieces that work together.
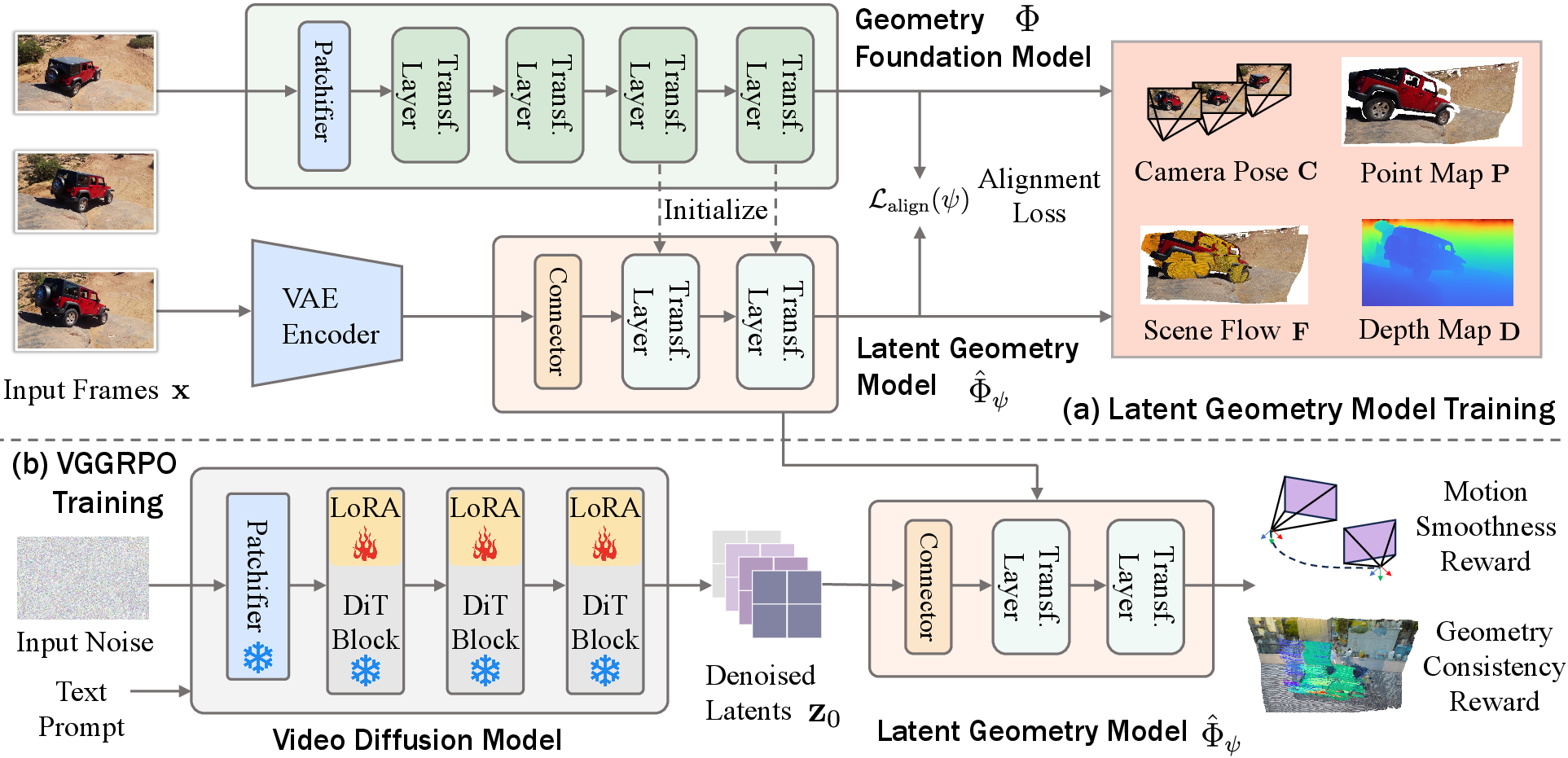
Key idea: Latent Geometry Model (LGM)
- Think of a video generator as a director writing a “recipe” (called latents) for each frame of the video. Normally, you’d turn these recipes into actual pictures (decoding) to check how things look. That step is slow and uses a lot of memory.
- A “geometry foundation model” is like a surveyor who can look at frames and figure out the 3D layout: where the camera is, how far objects are, and how points in the scene line up in 3D.
- The authors add a small connector so the surveyor can read the director’s recipe directly, without turning it into pictures first. This stitched-together system is the Latent Geometry Model.
- Because the surveyor they use can handle 4D (3D over time), the LGM works for moving scenes too. In other words, it understands not just where things are, but how they move.
Training with rewards: VGGRPO
- The model is trained with a reinforcement-learning-like method that compares multiple video samples at once and nudges the model toward better ones. This approach is called Group Relative Policy Optimization (GRPO).
- The crucial part: they compute the “rewards” in the latent space using the LGM, so they don’t need to decode frames back to pixels each time. That saves time and memory.
- They use two simple, complementary rewards to teach the model good habits:
- Camera motion smoothness: encourages steady camera paths without jitter, like holding a camera with a stabilizer.
- Geometry reprojection consistency: makes sure the 3D structure stays consistent across different views and moments, so the same wall or object doesn’t warp or jump when the camera moves.
Main Findings and Why They Matter
- Better stability and consistency:
- Videos have smoother camera motion and more coherent 3D structure over time.
- The method works for both static scenes and dynamic scenes with moving subjects.
- Strong overall quality:
- It improves perceived visual quality and motion quality without hurting the model’s general ability to make nice-looking videos.
- Efficiency gains:
- Because rewards are calculated in the latent space (the recipe), the process is faster and uses less memory than doing it in pixel space. The paper reports about a 25% speed-up in the reward step and lower GPU memory use.
- Flexible and general:
- It doesn’t require redesigning the big video model. Instead, it “post-trains” it, preserving the broad skills the model learned from tons of internet data.
- It can plug into different geometry models, and it even supports a training-free “test-time guidance” trick to improve geometry on the fly.
Implications and Impact
- More reliable AI videos: With steadier camera motion and consistent 3D structure, videos look more realistic and less “wobbly.” This matters for things like virtual reality, robotics, and physics-aware simulations, where the 3D world must make sense.
- Practical for industry: Because it’s efficient and doesn’t need big changes to the base model, it can be adopted more easily in real systems.
- Future-friendly: As geometry models get better, this framework can stitch into them and benefit right away, helping AI video keep up with advances in 3D understanding.
In short, VGGRPO shows a smart way to teach video AIs to respect the 3D world by reading and rewarding their internal “recipes” directly. That leads to smoother, more consistent, and more believable videos without slowing everything down.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions the paper does not fully resolve and that future work could address:
- Dependence on geometry foundation models (GFMs): How do errors, biases, and failure modes of the chosen GFM (e.g., Any4D, VGGT) propagate into rewards and learned policies, and can uncertainty from GFMs be modeled to weight rewards more robustly?
- Stitching design and selection: The procedure for choosing the stitch depth and connector architecture is heuristic; sensitivity to layer choice, connector capacity, calibration set size/coverage, and training stability is not systematically studied.
- Portability across VAEs/backbones: It is unclear how well the Latent Geometry Model (LGM) transfers across different VAEs, latent resolutions, codecs, or text-to-video backbones without retraining the connector.
- Scale and intrinsics ambiguity: The method assumes camera parameters from the GFM but does not clarify intrinsics estimation or scale ambiguity; the reprojection reward’s sensitivity to scale, focal length errors, and zoom/rolling-shutter effects is not analyzed.
- Dynamic-scene filtering: The static/dynamic separation via scene flow is assumed but not validated; how robust is the static-point aggregation under strong non-rigid motion, occlusions, or flow estimation errors?
- Camera motion smoothness reward bias: Penalizing acceleration may oversmooth intentional styles (handheld, rapid moves) or penalize near-static cameras (denominator near zero), suggesting a need for prompt/style-conditional or adaptive smoothness terms and safeguards against division-by-small-velocity artifacts.
- Reprojection reward design: Using the average error over the 3 worst views could be gamed by reducing valid pixels or creating degenerate geometry; occlusion handling, valid-pixel masking, and robustness to sparse projections are only loosely specified.
- Reward scale and normalization: The geometry reprojection reward appears scale-dependent (raw depth L1), while the motion reward is scale-normalized; consistent normalization or alternative scale-invariant formulations are not explored.
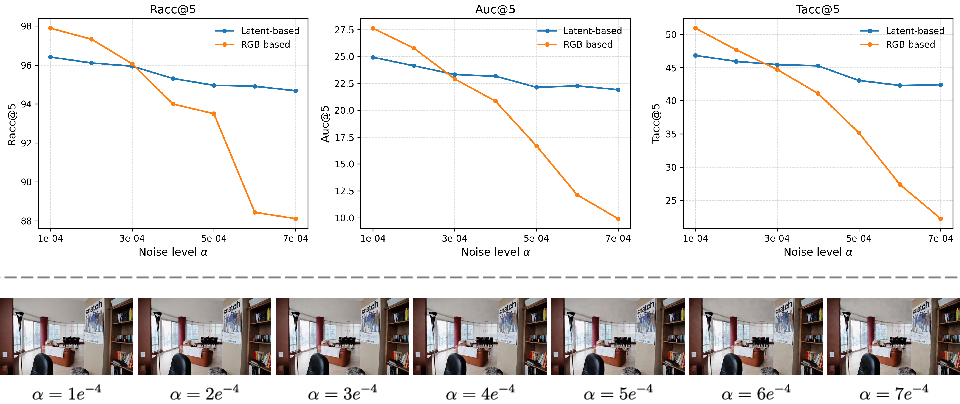
- Latent reward fidelity: It remains unquantified whether latent-space rewards faithfully reflect pixel-space geometry consistency, and under what conditions “reward hacking” in latent space yields unrealistic RGB outputs.
- Theoretical grounding of latent GRPO: The shift from RGB to latent trajectories for importance ratios, KL, and MDP assumptions lacks theoretical guarantees or error bounds regarding policy improvement and distribution matching.
- Uncertainty-aware weighting: The rewards treat GFM outputs as deterministic; integrating per-pixel/pose uncertainty to downweight noisy regions or frames is not investigated.
- Multi-object/motion consistency: The framework primarily enforces camera stability and static-scene coherence; object-centric 4D consistency (articulations, deformables) is not explicitly rewarded or evaluated.
- Prompt-conditional geometry alignment: There is no mechanism to condition rewards on user intent (e.g., “handheld shaky cam”), which could prevent unwanted smoothing or encourage desired motion styles.
- Test-time guidance stability: Differentiable test-time guidance is shown briefly; its stability, interaction with classifier-free guidance, convergence behavior, and artifact risks are not analyzed.
- Long-horizon consistency: The approach is evaluated on relatively short clips; performance for long videos (minutes), looped trajectories, or progressive viewpoint changes is not measured.
- Robustness to challenging imaging conditions: Effects of motion blur, low light, reflective/transparent materials, depth-of-field, extreme FOVs, zooms, and rolling shutter on GFM accuracy and rewards are not studied.
- Evaluation breadth: Human preference studies, absolute camera/pose error against ground truth where available (e.g., RealEstate10K), dynamic-scene metrics beyond epipolar error, and ablations on failure cases are missing.
- Metric choice limitations: The decrease in VBench Dynamic Degree is attributed to reduced optical flow magnitude; better motion-perceptual metrics or human studies to confirm perceived motion quality gains are not provided.
- Efficiency beyond reward step: While reward computation is faster in latent space, the end-to-end training cost (including LGM construction/fine-tuning and GRPO sampling) vs DPO-style baselines is not reported.
- Hyperparameter sensitivity: There is no study of group size K, GRPO clipping ε, KL β, LoRA rank/placement, or reward weighting; guidelines for stable training are absent.
- Connector/LGM maintenance: When the base model or VAE updates, the connector may require retraining; the cost and practicality of maintaining LGMs across model versions is unclear.
- Generalization to non-photorealistic domains: Performance on stylized, cartoon, line-art, or abstract videos—where GFMs may fail—is untested.
- Failure analyses: The paper lacks systematic failure modes (e.g., scenes where geometry collapses or rewards mislead) and diagnostic tools to detect misalignment during training/inference.
- Occlusion-aware reprojection: The reprojection consistency does not explicitly model occlusions/disocclusions or visibility reasoning; differentiable, visibility-aware rendering is not discussed.
- Object- and semantics-preservation: Potential trade-offs between geometry alignment and text adherence, identity preservation, or fine-grained semantics are not measured.
- Release and reproducibility: Details on model/code release, training compute/carbon footprint, and licensing constraints for GFMs/data are not provided.
- Comparisons to pixel-space reward fidelity: The accuracy/quality trade-off of latent vs pixel-space rewards is not quantified; an A/B study of reward signal-to-noise and downstream impact is missing.
- Curriculum learning: The potential benefits of staged training (e.g., motion-first then reprojection) or annealed reward weighting to improve stability are unexplored.
- Extensibility of rewards: Incorporating physics (collisions, gravity), object permanence, or SLAM-style loop-closure rewards to further enforce world consistency is proposed conceptually but not implemented.
- Applicability beyond rectified-flow diffusion: Whether the approach extends to autoregressive video generators or alternative generative families remains untested.
Practical Applications
Immediate Applications
The paper introduces a latent geometry–guided post-training framework (VGGRPO) that improves camera stability and 3D consistency in generated videos—including dynamic scenes—while reducing reward-compute cost by operating in latent space. This enables the following actionable uses today:
- Geometry-aligned post-training for enterprise video generators
- Sectors: software, media/entertainment, cloud AI.
- What: Integrate VGGRPO as a lightweight alignment stage to improve world consistency (smoother camera, coherent 3D) of existing text-to-video diffusion models without architectural changes.
- Tools/products/workflows: “VGGRPO SDK” for LoRA-based post-training; “Latent Geometry API” to compute rewards and metrics; CI/QA hooks that gate model updates on geometry metrics.
- Assumptions/dependencies: Access to a VAE-based diffusion backbone (e.g., rectified-flow models) and a geometry foundation model (Any4D/VGGT); modest on-policy sampling budget; calibration data for stitching.
- Previsualization and virtual production with stable camera trajectories
- Sectors: film/VFX, advertising, gaming.
- What: Generate previsualization shots and storyboards with consistent parallax and minimal jitter, reducing manual stabilization and re-shoots.
- Tools/products/workflows: Geometry-guided sampling/prompting UI with a “camera smoothness” control; batch post-training of studio-specific generators; pipeline node for “world-consistency alignment.”
- Assumptions/dependencies: Prompt distributions similar to calibration data; camera smoothness reward correlates with desired cinematography (may need tuning per show).
- AR/VR content generation with reduced motion sickness risk
- Sectors: AR/VR, immersive media.
- What: Produce headset-friendly clips with smooth camera motion and coherent scene structure, improving comfort and presence.
- Tools/products/workflows: Test-time “geometry guidance” applied every N denoising steps (no retraining) for one-click stabilization; preset profiles (comfort/high-parallax).
- Assumptions/dependencies: Comfort depends on more than camera jitter (e.g., FOV, acceleration limits); might require device-specific constraints and additional filtering.
- Synthetic data for robotics and embodied AI with 4D annotations
- Sectors: robotics, autonomy, academia.
- What: Generate training videos with consistent geometry and export per-frame camera poses, depths, point maps (and static/dynamic segmentation via scene flow) from the Latent Geometry Model for supervision of VO/SLAM, depth, and tracking.
- Tools/products/workflows: “Data factory” that emits video plus 4D labels; curriculum prompts for varied motion; automatic difficulty ramps via motion smoothness targets.
- Assumptions/dependencies: Domain gap remains; geometry accuracy is not the same as full physical realism; dynamic labels depend on the chosen geometry FM’s quality.
- Level flythroughs and environment previews for game development
- Sectors: gaming, interactive media.
- What: Rapidly generate stable flythroughs and concept videos that reflect consistent scene layout and parallax for pitch decks and art direction.
- Tools/products/workflows: Prompt templates for camera paths; smoothness and reprojection-consistency dials; export of approximate depth/pose for blockout.
- Assumptions/dependencies: Not a substitute for engine-ready assets; geometry is approximate and intended for ideation/previews.
- Real estate and e-commerce video tours
- Sectors: real estate, retail/marketing.
- What: Create clearer, less jittery AI tours that maintain room layout consistency and object placement, improving viewer trust and engagement.
- Tools/products/workflows: Turnkey service for “AI staging” with world-consistency alignment; batch refinement of generated tours via test-time geometry guidance.
- Assumptions/dependencies: Disclosure and compliance for synthetic content; layout plausibility does not guarantee factual accuracy.
- Video generation QA and monitoring via latent geometry metrics
- Sectors: MLOps, platform safety/quality.
- What: Score batches using latent reprojection error and camera smoothness without decoding to RGB, enabling faster regression testing during training and deployment.
- Tools/products/workflows: “Geometry scorecard” dashboards; alerting on metric drift; automated triage of prompts that cause high inconsistency.
- Assumptions/dependencies: Metrics reflect geometry/consistency but not aesthetics or content safety; thresholds require calibration per model/version.
- Academic research enablers for geometry-aware alignment
- Sectors: academia, open-source.
- What: Study latent-space reward design, dynamic-scene alignment, and on-policy sampling effects with reduced compute cost.
- Tools/products/workflows: Open-source LGM stitching scripts; latent-GRPO baselines; ablation suites that swap geometry FMs (VGGT vs Any4D).
- Assumptions/dependencies: Availability/licensing of geometry FMs; reproducibility requires sharing calibration datasets or procedures.
Long-Term Applications
The method’s ability to decode 4D geometry from latents and to align generators with on-policy, latent-space rewards opens up higher-impact use cases that need further engineering, scaling, or research:
- Real-time, interactive world-consistent video generation for XR and engines
- Sectors: AR/VR, game engines, live broadcast.
- What: On-the-fly generation with guaranteed camera smoothness and geometry coherence, responsive to user input.
- Tools/products/workflows: Engine plug-ins that expose “world-consistency constraints” at inference; low-latency latent-geometry guidance loops.
- Assumptions/dependencies: Significant inference and guidance optimization; streaming-friendly architectures; robust GPU/edge hardware.
- Text-to-4D scene creation for digital twins and simulation
- Sectors: robotics simulation, digital twins, smart cities.
- What: Generate controllable 4D assets (with static/dynamic separation) for rapid prototyping of environments used in planning, testing, and training.
- Tools/products/workflows: Prompt-to-4D asset pipelines; export to NeRF/mesh formats with pose/depth priors; validation harnesses using reprojection metrics.
- Assumptions/dependencies: Requires stronger geometry fidelity and topology consistency than current models; integration with physics and sensor models.
- Generative data factories for autonomy with richer ground truth
- Sectors: autonomous driving, drones, warehouse robotics.
- What: Mass-produce procedurally varied, geometry-consistent videos with associated 4D labels to train perception stacks.
- Tools/products/workflows: Scenario generators with distribution controls; automatic label export (depth, ego-motion, static/dynamic masks).
- Assumptions/dependencies: Sim-to-real transfer hurdles; need to incorporate physical constraints and multi-sensor effects (LiDAR, IMUs) beyond geometry.
- Standardization and policy for motion comfort and world consistency in synthetic media
- Sectors: policy/regulation, platforms, accessibility.
- What: Define benchmarks and minimum thresholds for camera smoothness and reprojection consistency to mitigate motion sickness and deceptive content risks.
- Tools/products/workflows: Certification tests based on geometry metrics; platform-level gating for immersive ads and experiences.
- Assumptions/dependencies: Consensus on metrics; balancing creative freedom with safety; continual updates as models evolve.
- Accelerated video-to-4D reconstruction services via latent geometry
- Sectors: cloud vision, digital content services.
- What: Speed up reconstruction pipelines (pose/depth estimation, scene flow) by operating in VAE latent space when videos are pre-encoded or generated.
- Tools/products/workflows: “Latent Reconstruction API” that ingests latents and outputs 4D predictions; hybrid pipelines that switch between pixel and latent paths.
- Assumptions/dependencies: Needs standardized latent formats across generators; accuracy parity with pixel-space FMs must be validated for production.
- Cinematography-aware generative controls (“camera linters” and constraints)
- Sectors: creative tooling, education.
- What: Interactive guidance that enforces shot conventions (e.g., max angular acceleration, dolly smoothness) during generation.
- Tools/products/workflows: Rule-based or learned camera profiles; live feedback on trajectory smoothness; automated resampling when constraints are violated.
- Assumptions/dependencies: Domain-specific preference models; UI/UX integration with creative workflows.
- On-device geometry-guided alignment for mobile capture and AR authoring
- Sectors: mobile, creator tools.
- What: Lightweight latent rewards to stabilize and enforce consistency during local generation or authoring, enabling better AR assets on-device.
- Tools/products/workflows: Quantized LGM; sparse guidance steps; hardware-accelerated VAE and transformer kernels.
- Assumptions/dependencies: Tight memory/compute budgets; thermal constraints; efficient calibration of the stitching layer for mobile VAEs.
- Domain-specific simulation and training (e.g., medical/industrial procedures)
- Sectors: healthcare, industrial training, education.
- What: Generate consistent, dynamic procedural videos (e.g., surgical fields, assembly lines) to support training and rehearsal.
- Tools/products/workflows: Specialized prompts and rewards (e.g., tool–tissue geometry); integration with domain ontologies and validation datasets.
- Assumptions/dependencies: High stakes require rigorous validation; incorporation of anatomy/physics priors; regulatory approval for training use.
Each of these applications inherits dependencies from the paper’s method: availability of compatible diffusion backbones and VAEs, access to geometry foundation models (and their licenses), sufficient calibration data for stitching the Latent Geometry Model, and compute for on-policy sampling (though reduced versus RGB-based rewards). For safety- and mission-critical uses, additional physical realism, sensor modeling, and rigorous validation will be necessary beyond geometric consistency alone.
Glossary
- 4D reconstruction: Estimating time-varying 3D structure (geometry over time), producing a dynamic spatiotemporal scene representation. Example: "extend this formulation to dynamic 4D reconstruction"
- Any4D: A geometry foundation model capable of dynamic 4D scene reconstruction used to build the latent geometry model. Example: "stitching to Any4D, a geometry foundation model that supports dynamic 4D reconstruction"
- Camera motion smoothness reward: A reinforcement signal that favors temporally stable camera trajectories by penalizing jitter and abrupt accelerations/rotations. Example: "a camera motion smoothness reward that penalizes jittery trajectories"
- Direct Preference Optimization (DPO): A preference-based alignment method that optimizes a model to prefer outputs favored in pairwise comparisons without explicit reward modeling. Example: "Direct Preference Optimization"
- Epipolar constraints: Geometric relationships between two camera views that restrict corresponding points to lie on epipolar lines, used to enforce multi-view consistency. Example: "sparse epipolar constraints"
- Geometry foundation models: Large-scale, feed-forward models trained to predict dense scene geometry (depth, pose, point maps, etc.) from images or video. Example: "geometry foundation models"
- Geometry reprojection consistency reward: A reward that encourages cross-view geometric coherence by comparing predicted depths with reprojected 3D structure. Example: "a geometry reprojection consistency reward that enforces cross-view geometric coherence"
- Group Relative Policy Optimization (GRPO): An on-policy reinforcement learning algorithm that updates a policy using group-normalized advantages while constraining divergence from a reference policy. Example: "Group Relative Policy Optimization (GRPO)"
- KL regularization: A penalty that constrains the updated policy to stay close to a reference policy via Kullback–Leibler divergence. Example: "with KL regularization toward a reference policy"
- Latent Geometry Model (LGM): A model that maps video diffusion latents directly to geometric predictions by stitching latents into a geometry foundation model. Example: "Latent Geometry Model (LGM)"
- Latent-space GRPO: Applying GRPO directly in the model’s latent space, enabling efficient on-policy updates without decoding to pixels. Example: "latent-space Group Relative Policy Optimization"
- LoRA: Low-Rank Adaptation, a lightweight fine-tuning technique that injects trainable low-rank matrices into frozen model weights. Example: "using LoRA (rank r=32, scaling factor α=64)"
- ODE-to-SDE conversion: Transforming a deterministic flow (ODE) into a stochastic process (SDE) to enable exploration during optimization. Example: "with an ODE-to-SDE conversion for stochastic exploration"
- Point map: A per-pixel prediction of 3D coordinates in a shared frame, representing the scene’s geometry at each pixel. Example: "a 3D point map"
- RAFT optical flow: A state-of-the-art method for dense optical flow estimation used here to compute motion magnitude for evaluation. Example: "RAFT optical flow"
- Rectified flow: A flow-based generative modeling framework that learns a velocity field to transform noise into data along a straightened (rectified) path. Example: "rectified flow models"
- Sampson epipolar error: A first-order approximation of geometric reprojection error measuring point-to-epipolar-line distance, used as a precision metric. Example: "Sampson epipolar error"
- Scene flow: A per-point or per-pixel 3D motion field over time that captures dynamic motion in a scene. Example: "scene flow"
- Stitching layer: The learned connector that maps diffusion latents into the intermediate feature space of a geometry model. Example: "The stitching layer"
- VAE decoding: Converting latents back to pixel space via a variational autoencoder decoder; repeatedly doing this can be computationally expensive. Example: "repeated VAE decoding"
- VBench: A benchmark suite for evaluating multiple aspects of video generation quality, including motion and consistency metrics. Example: "VBench"
- VideoReward: A learned reward model (or evaluator) that provides win-rate comparisons reflecting human preference for visual and motion quality. Example: "VideoReward win rates"
- VGGRPO: The proposed Visual Geometry GRPO framework that aligns video diffusion models using latent-space geometry-guided reinforcement learning. Example: "VGGRPO"
- World-consistent video generation: Producing videos with temporally stable camera motion and coherent 3D structure across frames and views. Example: "world-consistent video generation"
Collections
Sign up for free to add this paper to one or more collections.