V-ReasonBench: Toward Unified Reasoning Benchmark Suite for Video Generation Models
Abstract: Recent progress in generative video models, such as Veo-3, has shown surprising zero-shot reasoning abilities, creating a growing need for systematic and reliable evaluation. We introduce V-ReasonBench, a benchmark designed to assess video reasoning across four key dimensions: structured problem-solving, spatial cognition, pattern-based inference, and physical dynamics. The benchmark is built from both synthetic and real-world image sequences and provides a diverse set of answer-verifiable tasks that are reproducible, scalable, and unambiguous. Evaluations of six state-of-the-art video models reveal clear dimension-wise differences, with strong variation in structured, spatial, pattern-based, and physical reasoning. We further compare video models with strong image models, analyze common hallucination behaviors, and study how video duration affects Chain-of-Frames reasoning. Overall, V-ReasonBench offers a unified and reproducible framework for measuring video reasoning and aims to support the development of models with more reliable, human-aligned reasoning skills.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces V-ReasonBench, a big, organized test (a “benchmark”) that checks how well AI video generators can “reason” about what they see and what they should create next. Instead of only judging whether a video looks pretty, V-ReasonBench measures whether the model can think through problems shown in pictures and produce the correct final result.
Why do we need a new test?
Modern video AIs can sometimes solve puzzles without being explicitly trained to do so. That’s exciting—but it’s hard to measure this kind of thinking in a clear, fair, and repeatable way. The authors created V-ReasonBench to be:
- unified (one place to test many kinds of visual reasoning),
- reproducible (others can repeat the test and get similar results),
- and focused on correct outcomes (not just nice-looking videos).
What questions did the researchers ask?
In simple terms, they asked:
- Can we design a reliable, fair way to measure reasoning in video generation models?
- What kinds of reasoning are these models good or bad at?
- Do video models reason better than image-only models, and when?
- Does making longer videos help reasoning, or not?
- Do automatic AI judges (VLMs) score videos correctly, and do those scores match human opinions?
How did they test the models?
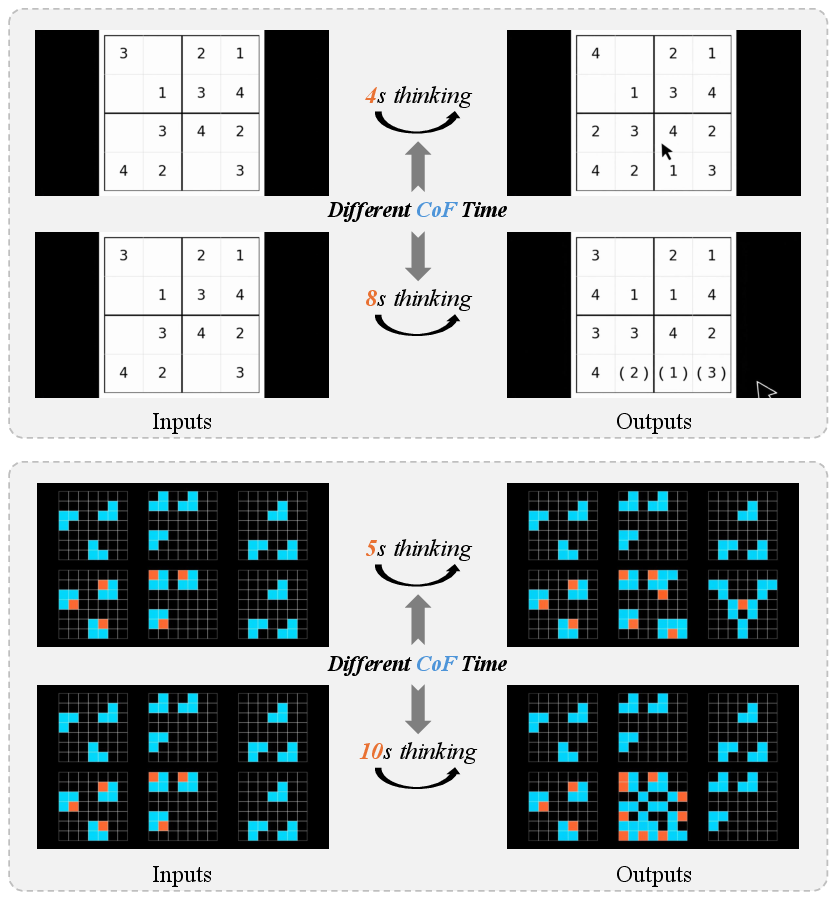
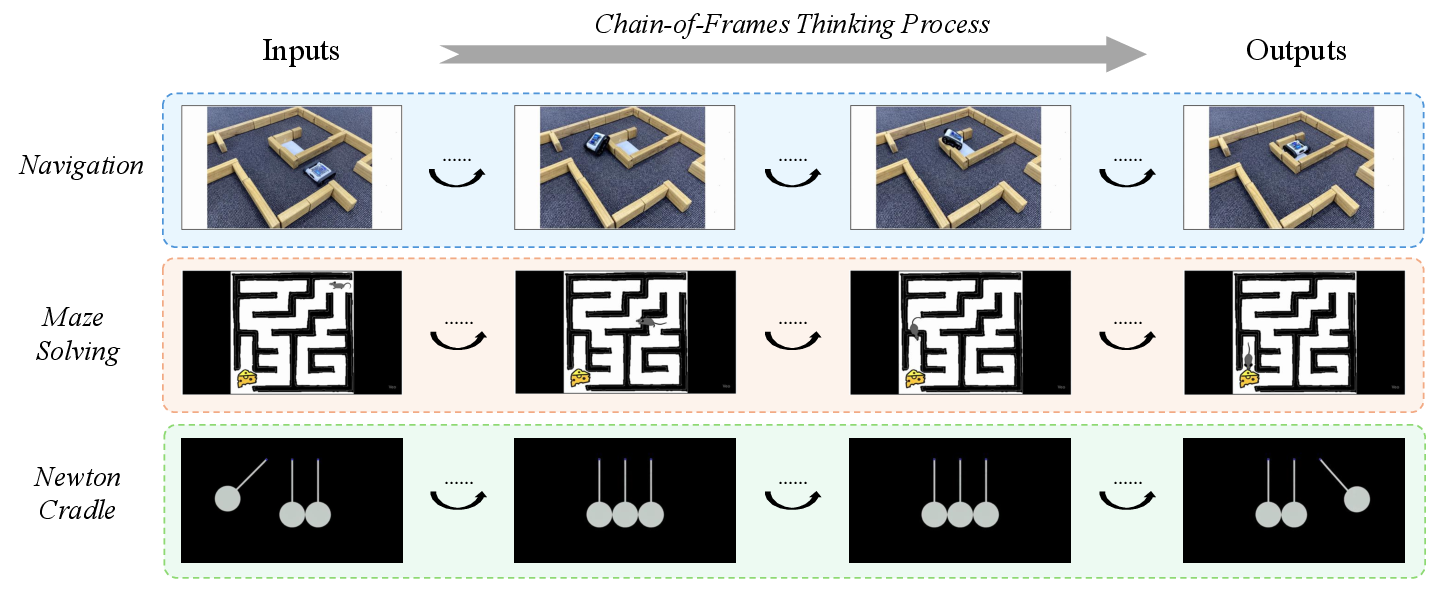
Think of “reasoning in video” as step-by-step thinking with pictures. The paper uses an idea called “Chain-of-Frame” (CoF), similar to “Chain-of-Thought” in language. Here’s the core idea:
- The model is shown a starting image and an instruction (like a puzzle).
- It generates a short video where each frame is like a step in its thinking.
- The final frame is the model’s “answer.” The benchmark judges only this last frame to keep scoring simple and consistent.
To make this work well, the authors created tasks in four reasoning areas and used a mix of evaluation methods.
The four reasoning areas
To make their test well-rounded, the benchmark includes tasks across these dimensions:
- Structured problem-solving: math from pictures, following simple code, Sudoku, and finding the best move in Tic-Tac-Toe.
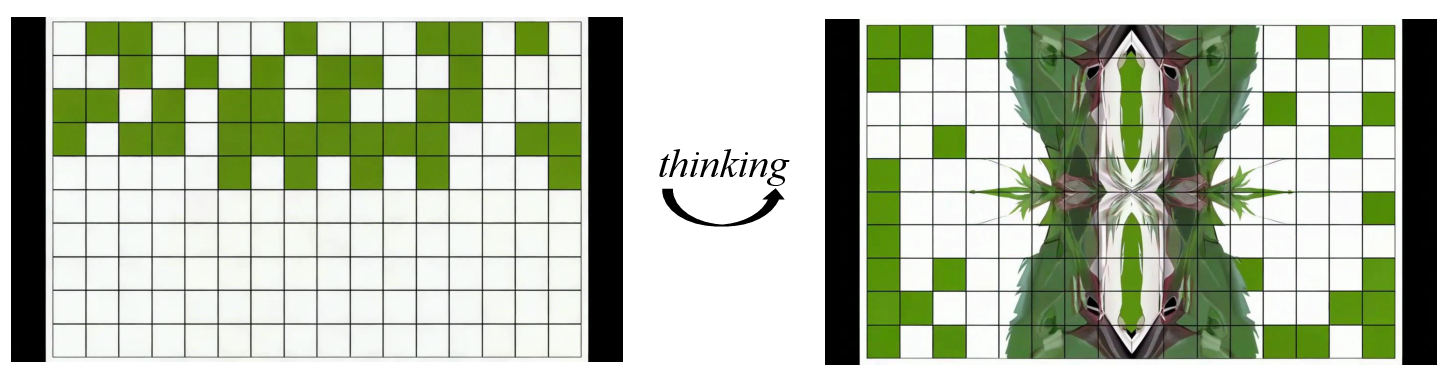
- Spatial cognition: fitting shapes, spotting symmetry, and connecting same-colored items with valid paths.
- Pattern-based inference: finishing sequences, solving analogies (“A is to B as C is to ?”), and following rules learned from examples.
- Physical dynamics: predicting slides on slopes, how water levels change in connected containers, and how temperature affects materials.
How they score the final frame
Because videos can be complex, they use three practical scoring methods—each explained with everyday analogies:
- Mask-based evaluation: Imagine putting a colored overlay on the important parts (like the playing area in Tic-Tac-Toe). The score focuses mostly on these areas, ignoring background changes that don’t matter.
- Grid-based evaluation: Think of the image as a chessboard. The test checks each square for the right piece, color, or shape, so tiny misplacements are caught.
- VLM-based evaluation: A lightweight AI “judge” reads or recognizes simple, clear outputs (like a number in a math problem or the result of a small code snippet). This is used only when it’s dependable.
They also use a simple metric called pass@5: each model gets up to five tries for each task; if any try is correct, it counts as a pass. This makes the test fair, because video generation can be a bit random.
The dataset setup
Most tasks use pairs of images: one “start” image and one “correct final” image. Models must generate a video that ends at the right final image. This design:
- keeps tasks clear and unambiguous,
- makes it easy to scale to many examples,
- and enables consistent scoring.
What did they find?
Here are the main results, explained simply:
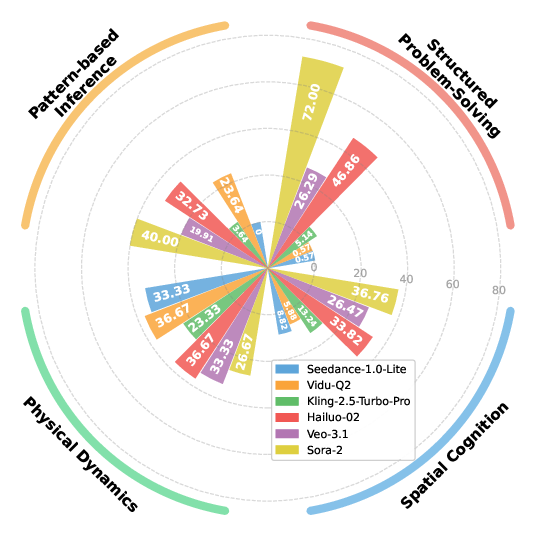
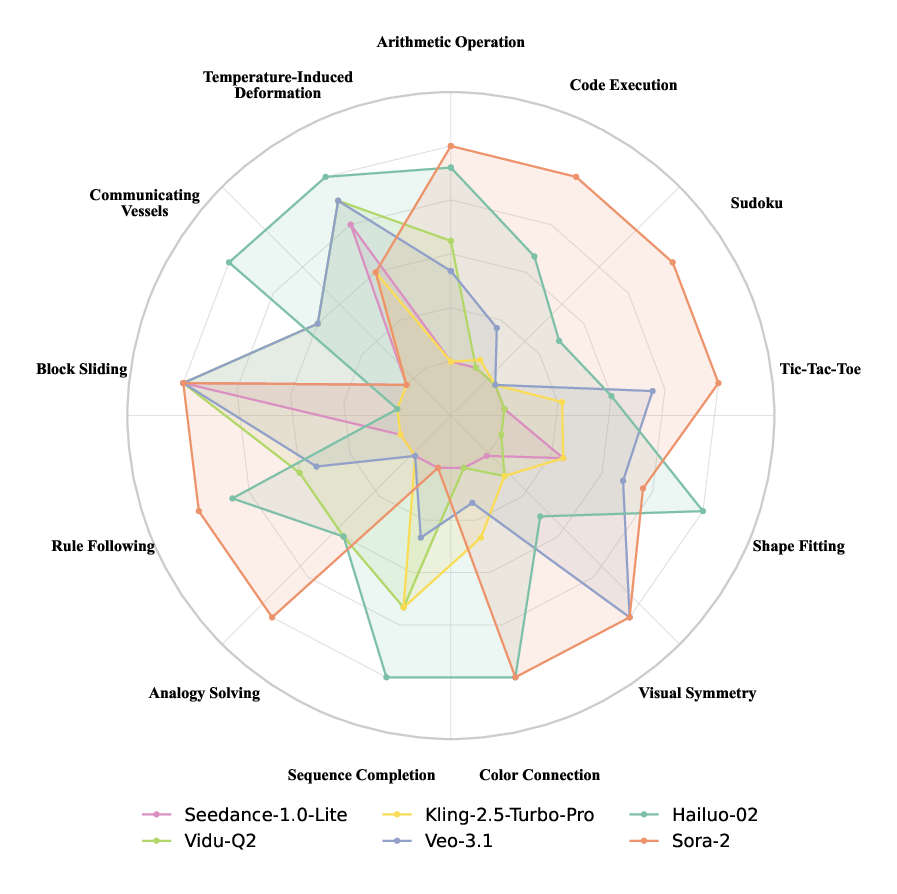
- Different models have different strengths. For example, Sora-2 scored best overall in structured problem-solving, spatial understanding, and pattern-based reasoning. Hailuo-02 also performed strongly, especially in physical tasks. Vidu-Q2 did well in physical dynamics too.
- Physical reasoning is hard. Even good models that handle math or patterns can struggle with understanding forces, motion, and materials.
- Longer videos aren’t always better. Making the video longer (more “thinking frames”) didn’t consistently improve the final answer. Extra frames sometimes added distractions or even caused “hallucinations” (unrealistic or wrong steps).
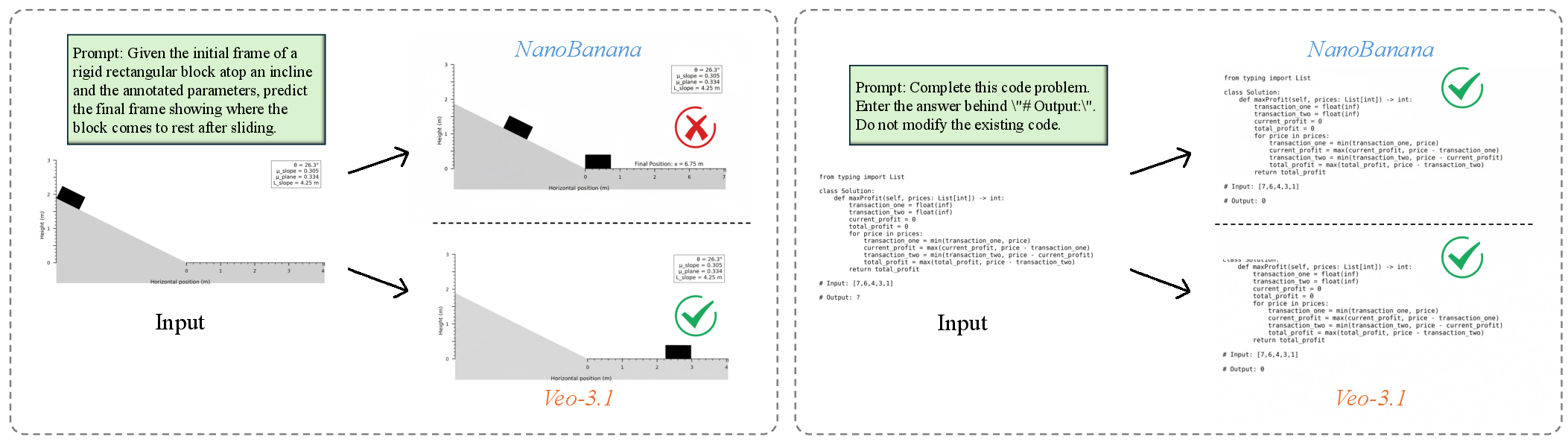
- Video vs. image models: Video models are better at tasks that need simulating changes over time (like physics), because they can “think” frame-by-frame. Image-only models produce cleaner static answers and often do well on text-heavy or code-derived tasks, but they can miss the right physical outcome because there’s no motion to reason over.
- AI judges have limits. Vision-LLMs (VLMs) can misjudge complex, tiny, or grid-based visuals. That’s why V-ReasonBench uses multiple scoring strategies, not just one AI judge.
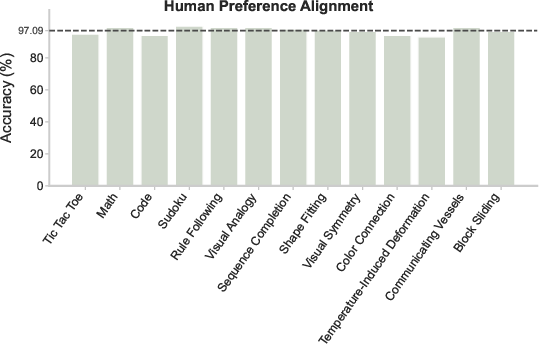
- Humans mostly agree with the benchmark. The automatic pass/fail decisions matched human judgments about 97% of the time, which is very high.
Why does this matter?
This work helps move AI video generation from “looks good” to “thinks well.” The benchmark:
- gives researchers a reliable way to measure reasoning in videos,
- shows where current models struggle (especially physical understanding and staying consistent across frames),
- encourages designs that combine clean static understanding with good temporal reasoning,
- and provides a clear target for building models that are more aligned with how humans reason and judge correctness.
In short, V-ReasonBench is a solid, unified test that can guide the next generation of video AIs toward being not just creative, but also correct and trustworthy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps, limitations, and open questions that remain unresolved and could guide future research:
- Coverage and scale: The benchmark comprises 326 instances with 652 images; how does performance and reliability scale with substantially larger, more diverse task banks, including harder multi-step problems and richer distractor settings?
- Synthetic bias: Approximately 90% of tasks are procedurally generated in minimalist layouts; to what extent do findings generalize to natural, cluttered, camera-moved, or occluded real-world videos where perception noise and context complexity are high?
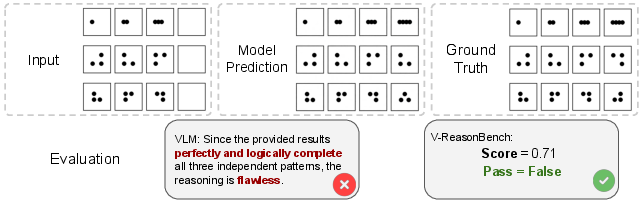
- Last-frame evaluation blind spots: End-state scoring cannot detect “right answer, wrong process” temporal inconsistencies; how can we evaluate causal coherence and physical law adherence across intermediate frames without prohibitive annotation?
- Process-sensitive task design: Can we construct tasks where only a correct causal trajectory produces the correct terminal state (e.g., path-dependent constraints, irreversible transformations) to reduce endpoint-only loopholes?
- VLM judge reliability: For tasks using VLM-based scoring (e.g., Sudoku, code execution, shape fitting), how can we quantify and reduce OCR errors, misreads of small cells, and layout misinterpretations, and benchmark evaluator variance across multiple VLMs?
- Threshold calibration: Task-specific pass/fail thresholds are not systematically validated; what procedures ensure calibrated, robust thresholds across tasks/models, and how sensitive are conclusions to threshold choices?
- Metric robustness: Mask- and grid-based metrics rely on pixel-level comparisons; how can metrics be made invariant to style changes and camera motion while remaining sensitive to structural correctness?
- Segmentation dependencies: Mask-based evaluation uses SAM-2 or templates; what is the impact of segmentation errors on scores, and can ground-truth regions be made robust to visual drift or occlusion?
- Grid granularity: How should grid cell size adapt to object scale and stroke thickness to avoid penalizing minor rendering or antialiasing artifacts?
- Pass@k sensitivity: The evaluation fixes k=5; how do rankings change with k, seed variability, temperature, sampling strategy, and decoding settings, and what is the sample-efficiency curve per model/task?
- Resolution and fps effects: Results are at 720p/768p and ~5s videos; how do resolution, aspect ratio, frame rate, and clip length affect reasoning accuracy and temporal coherence across tasks?
- Duration control for CoF: Longer durations do not consistently improve reasoning; what strategies (frame budgeting, stride, temporal attention, memory mechanisms, self-consistency across runs) effectively translate “more time” into better reasoning?
- Prompts and instruction robustness: How sensitive are outcomes to prompt phrasing, paraphrases, multi-lingual instructions, and noisy or contradictory directives, and can standardized prompt suites reduce bias?
- Physical dynamics breadth: Current physics tasks focus on sliding, communicating vessels, and temperature-induced changes; how do models fare on broader dynamics (collisions, elasticity, friction regimes, fluid turbulence, granular media, deformables) and 3D interactions?
- Causal law verification: Can we formalize automatic checks for conservation laws (momentum, energy), pressure equilibria, and kinematic constraints using physics simulators or symbolic validators aligned to generated trajectories?
- Sub-task granularity: Dimension-wise scores hide task-level failure modes; can we provide per-task breakdowns and error taxonomies (e.g., typical Sudoku mistakes, symmetry misclassification, pathfinding errors) to target model training?
- Human alignment depth: The study reports 97% agreement but does not detail inter-rater reliability (e.g., Cohen’s κ), disagreement sources, and cross-lab reproducibility; can we expand annotator pools and report reliability statistics per task?
- Construct validity: Do V-ReasonBench scores predict performance on downstream video reasoning applications (e.g., robotics planning, sports analytics)? Establishing predictive validity would strengthen claims of “reasoning” measurement.
- Model set and transparency: Evaluations target six commercial models with undisclosed training data; how do results change for open-source models, and can benchmark findings be normalized against known pretraining compositions to assess data contamination or overfitting on diagrammatic tasks?
- Image vs. video baselines: The comparison uses a single image model (NanoBanana); can we include stronger, diverse image reasoning baselines (e.g., OCR-specialized, code-readers, math-visual models) to better isolate temporal advantages?
- Hallucination mitigation: Observed temporal hallucinations are noted but not systematically addressed; which interventions (temporal-aware activations, causal regularizers, step-wise constraints, multi-run self-consistency voting) concretely reduce hallucinations in generative video reasoning?
- Minimalism-induced creativity bias: Models embellish sparse scenes, hurting structural accuracy; can training or decoding methods penalize unnecessary additions, and can “structure-preserving” priors be introduced to respect diagrammatic constraints?
- Task diversity within dimensions: Some dimensions (e.g., pattern-based inference) may underrepresent analogical and inductive reasoning in naturalistic settings; can we expand to cross-domain analogies, visual metasemantics, and rule induction from noisy examples?
- Evaluation reproducibility: API versions and default parameters may change; how can we version-control generation settings, random seeds, and evaluator prompts to ensure longitudinal comparability?
- Licensing and release details: The paper references a project page but does not specify data licensing, evaluator code availability, or reproducibility kits; clear release artifacts are needed for community adoption and extension.
- Adversarial and interactive reasoning: Tasks like Tic-Tac-Toe evaluate a single move rather than multi-turn adversarial planning; can we incorporate interactive environments where models must reason under opponent responses and partial information?
- Multimodal outputs: Some tasks could benefit from textual or symbolic outputs alongside final frames; how can the benchmark incorporate multimodal scoring (vision + text) to reduce reliance on pixel-matching and improve interpretability?
- Bias and fairness: Do models exhibit differential performance across color palettes, font styles, or cultural symbol sets in diagrams? Systematic fairness audits are missing.
- Generalization to long videos: The benchmark focuses on short clips; can we systematically evaluate long-horizon reasoning, temporal credit assignment, and memory fidelity over minutes-long sequences?
Glossary
- Analogy Solving: A pattern-based reasoning task that requires mapping relational structures (e.g., A:B :: C:?); used to test cross-domain correspondence beyond surface similarity. "Analogy Solving tests the understanding of relational structure through problems of the form “A:B as C:?” requiring cross-domain correspondence beyond surface similarity."
- Attention drift: A degradation in focus over longer sequences that harms temporal reasoning quality. "increasing sequence length expands the available causal evidence but also magnifies attention drift and temporal mis-binding"
- Chain-of-Frame (CoF): A paradigm that treats video generation as a sequence of reasoning steps, with intermediate frames reflecting the reasoning process and the final frame encoding the answer. "The “Chain-of-Frame” (CoF) paradigm treats video generation as a sequence of reasoning steps, in direct analogy to “Chain-of-Thought” in LLMs"
- Chain-of-Frames reasoning: Reasoning carried out through sequential frames, emphasizing the process-aware nature of video generation. "study how video duration affects Chain-of-Frames reasoning."
- Chain-of-Thought (CoT): A language-model reasoning approach where intermediate steps are explicitly articulated, analogous to CoF in video. "in direct analogy to “Chain-of-Thought” in LLMs"
- Communicating Vessels (CV): A physics principle involving fluid pressure and equilibrium across connected containers; used to evaluate physical reasoning. "Communicating Vessels (CV) evaluates understanding of fluid pressure and equilibrium"
- Diffusion–transformer models: Generative architectures combining diffusion processes with transformer backbones for scalable, high-quality video synthesis. "Recent advances in video generation have been strongly driven by diffusion–transformer models, which provide scalable architectures for producing high-quality visual content"
- Grid-based evaluation: An assessment method that divides frames into uniform cells and measures cell-wise accuracy to capture structural and geometric correctness. "we employ a grid-based evaluation. Each frame is divided into uniform cells, and cell-wise accuracy is computed by comparing the predicted and ground truth states in corresponding grid locations."
- Human–alignment: The degree to which automated evaluation agrees with human judgments. "Human–alignment validation of our benchmark’s scoring pipeline."
- Last-Frame Dependency: A design principle ensuring tasks can be judged solely from the final frame, enabling unambiguous and scalable evaluation. "Last-Frame Dependency: All tasks are designed such that the final answer can be determined exclusively from the last frame of generated videos"
- Last-frame evaluation pipeline: A methodology that assesses model answers using only the concluding frame rather than all intermediate steps. "CoF enables a last-frame evaluation pipeline: we judge the model on its concluding frame rather than requiring annotation of all intermediate steps."
- Latent motion paths: Implicit trajectories modeled across frames that represent the evolution of motion without explicit annotation. "represent latent motion paths"
- Mask-based evaluation: A comparison strategy that focuses pixel-level metrics on target regions using segmentation masks to reduce background/style influence. "Tasks with clear object boundaries and localized reasoning regions... are evaluated using a mask-based comparison strategy."
- Mental rotation: A cognitive operation of imagining objects rotated in space, used to assess spatial reasoning. "Shape Fitting assesses mental rotation and spatial arrangement skills."
- Pass@k: An evaluation metric measuring the probability that at least one of k generations solves the task. "We employ pass@k as our primary evaluation metric across all reasoning classes"
- Pattern-based Inference: A reasoning dimension probing sequence completion, analogy, and abstract rule induction beyond superficial cues. "Pattern-based Inference probes sequence completion, analogical mapping, and abstract rule induction beyond surface-level visual cues."
- Procedural generation: Programmatic synthesis of data instances to ensure scalability, coverage, and controlled variation. "Procedural generation provides broad coverage across reasoning types while preserving consistent state transitions"
- Process-aware temporal dynamics: Temporal modeling that accounts for multi-step causal processes to solve simulation-heavy problems. "video models leverage process-aware temporal dynamics to handle multi-step, causal, and simulation-heavy problems."
- SAM-2: A segmentation model/tool used to generate masks for region-focused evaluation. "automated segmentation tools such as SAM-2"
- Temporal hallucination: Producing a correct final outcome while the intermediate frames violate causal or physical consistency. "These cases exemplify temporal hallucination, where invented or misordered actions and fabricated transitions preserve the correct endpoint but break causal consistency."
- Temporal mis-binding: Incorrect association or ordering of events across time, leading to reasoning errors. "attention drift and temporal mis-binding"
- Vision-LLMs (VLMs): Models that jointly process visual and textual inputs for tasks like automatic judgment or perception. "vision-LLMs (VLMs) for automatic judgment"
- VLM-based evaluation: Scoring outputs using a lightweight vision-LLM when pixel-based metrics are insufficient. "Tasks composed of simple items that VLMs can easily handle... are scored using a lightweight VLM-based procedure."
- Visual Symmetry: Recognition and assessment of reflective and rotational symmetries in visual patterns. "Visual Symmetry evaluates recognition of reflective and rotational symmetries."
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging V-ReasonBench’s benchmark suite, last-frame evaluation methodology, and dimension-wise diagnostics.
- Model procurement and QA gating for video-generation vendors (software, media/entertainment, edtech)
- Tools/workflows: Integrate pass@5 with dimension-wise scorecards; automate mask/grid/VLM scoring in CI; enforce “reasoning gates” before shipping model updates.
- Assumptions/dependencies: Access to benchmark data and code; standardized prompts; compute to generate multiple videos per instance; mapping task coverage to product needs.
- Safety and reliability audits for consumer-facing video features (software platforms, creative apps)
- Tools/workflows: Use last-frame thresholds as pre-deployment checks; add “creative-bias” checks via geometric/grid tasks; set escalation rules for human review on borderline outputs.
- Assumptions/dependencies: Calibrated task-specific thresholds; defined risk tolerances per product; periodic re-evaluation to avoid benchmark overfitting.
- Autograding of visual reasoning assignments (education)
- Tools/workflows: Adopt grid/mask scoring to grade student-produced diagrams/videos (e.g., shape fitting, Sudoku, arithmetic); use lightweight VLM evaluation where reliable; provide granular feedback by dimension.
- Assumptions/dependencies: Curriculum-aligned task templates; accessibility accommodations; careful rubric and threshold setting to avoid unfair penalties on small visual errors.
- MLOps regression testing with Chain-of-Frame duration sweeps (software/AI development)
- Tools/workflows: Systematically vary video duration; track reasoning accuracy vs. length; detect attention drift and temporal hallucinations; codify “frame budget” heuristics.
- Assumptions/dependencies: Ability to control generation duration and sampling; storage/logging of intermediate frames; internal telemetry for error taxonomy.
- Benchmark-driven dataset curation and augmentation (AI development)
- Tools/workflows: Use observed failure modes (grid misreads, thin boundaries, small-cell perception) to curate diagram-rich data; augment training with spatial/structured tasks to reduce “creative bias.”
- Assumptions/dependencies: Rights to use or synthesize task-like data; guardrails to avoid overfitting to benchmark; monitoring for cross-domain generalization.
- Task routing between video and image pipelines (software/ops)
- Tools/workflows: Based on paper’s findings, route physics/causal, multi-step spatial tasks to video models; route text/code/clean-layout tasks to image models; implement hybrid orchestration.
- Assumptions/dependencies: Reliable model selection criteria; low-latency routing; awareness of domain shift (product prompts vs. benchmark prompts).
- Lightweight evaluator packaging for internal use (software tools)
- Tools/workflows: Wrap mask-based, grid-based, and VLM-based scoring into a reusable library/CLI; include SAM-2 integration; provide reproducible pass@k reporting and per-dimension dashboards.
- Assumptions/dependencies: Stable segmentation APIs; threshold calibration; versioning and governance to keep evaluators aligned with human judgment.
- Visual reasoning puzzle/game content (consumer apps, daily life)
- Tools/workflows: Turn benchmark tasks (sequence completion, symmetry, tic-tac-toe) into playable levels; show Chain-of-Frame “thinking” as hints; auto-validate finales via last-frame scoring.
- Assumptions/dependencies: Licensing for task assets; UX adaptation to mobile; guard against inappropriate model hallucinations in intermediate frames.
Long-Term Applications
The following applications require further research, scaling, domain adaptation, or governance before broad deployment.
- Standards and certification for video reasoning (policy/regulation, industry consortia)
- Tools/workflows: Establish dimension-specific pass@k thresholds; publish compliance labels (e.g., “Video Reasoning Grade A/B”); support third-party audits and reproducible test suites.
- Assumptions/dependencies: Multi-stakeholder governance (academia, industry, regulators); benchmark expansion to real-world tasks; safeguards against “benchmark gaming.”
- CoF-aware training regimes and RL with last-frame rewards (AI development)
- Tools/workflows: Train models with last-frame correctness signals; add intermediate consistency losses to reduce “right answer, wrong process”; include curriculum emphasizing grid/structured scenes.
- Assumptions/dependencies: Significant compute; access to model internals; diverse training data; robust generalization beyond synthetic tasks.
- Domain-adapted healthcare and scientific reasoning benchmarks (healthcare, life sciences)
- Tools/workflows: Extend mask/grid evaluation to ultrasound/endoscopy sequences; tailor physical-dynamics tasks to biomechanical or fluid phenomena; measure human-aligned correctness.
- Assumptions/dependencies: Clinical-grade datasets; privacy/compliance (HIPAA/GDPR); rigorous validation and regulatory approvals.
- Robotics visual planning and simulation via Chain-of-Frame (robotics, industrial automation)
- Tools/workflows: Use CoF to produce plan frames and action previews; evaluate plan endpoints via last-frame correctness; enforce process consistency via intermediate-frame constraints.
- Assumptions/dependencies: Physics fidelity; safe sim-to-real transfer; real-time requirements; integration with perception/control stacks.
- Physics-informed generative simulation for energy/materials (energy, manufacturing, R&D)
- Tools/workflows: Couple CoF generation with physics engines or PINNs; simulate fluid levels (communicating vessels), deformations, block sliding; validate endpoints against numerical solvers.
- Assumptions/dependencies: Physics-grounded training; high-precision evaluation; domain experts for calibration; tolerance analyses for safety-critical use.
- Financial visuotemporal analytics and audit trails (finance)
- Tools/workflows: Generate CoF “what-if” visualizations over market sequences; enforce last-frame correctness for scenario outcomes; maintain visual audit logs for compliance/explainability.
- Assumptions/dependencies: Reliable mapping from visual patterns to financial signals; strict compliance controls; mitigation of hallucinations and attention drift.
- Explainability and legal audit tooling using CoF traces (policy/legal, enterprise governance)
- Tools/workflows: Store intermediate frames as “reasoning records”; verify endpoints with reproducible scoring; support transparency mandates and dispute resolution.
- Assumptions/dependencies: Trusted logging infrastructure; tamper-evident records; evolving legal standards for AI transparency.
- Stepwise visual tutors for math/physics and spatial cognition (education)
- Tools/workflows: Tutor systems that show CoF reasoning steps; auto-check final answers via last-frame evaluation; adapt difficulty by dimension (structured, spatial, pattern, physical).
- Assumptions/dependencies: Improved model reliability; personalization; content safety; empirical studies on learning gains.
Collections
Sign up for free to add this paper to one or more collections.

