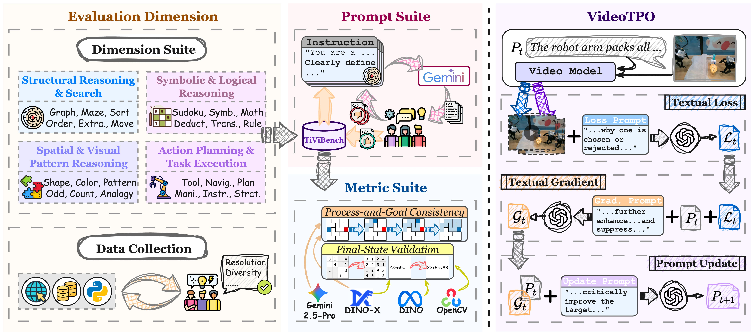
TiViBench: Benchmarking Think-in-Video Reasoning for Video Generative Models
Abstract: The rapid evolution of video generative models has shifted their focus from producing visually plausible outputs to tackling tasks requiring physical plausibility and logical consistency. However, despite recent breakthroughs such as Veo 3's chain-of-frames reasoning, it remains unclear whether these models can exhibit reasoning capabilities similar to LLMs. Existing benchmarks predominantly evaluate visual fidelity and temporal coherence, failing to capture higher-order reasoning abilities. To bridge this gap, we propose TiViBench, a hierarchical benchmark specifically designed to evaluate the reasoning capabilities of image-to-video (I2V) generation models. TiViBench systematically assesses reasoning across four dimensions: i) Structural Reasoning & Search, ii) Spatial & Visual Pattern Reasoning, iii) Symbolic & Logical Reasoning, and iv) Action Planning & Task Execution, spanning 24 diverse task scenarios across 3 difficulty levels. Through extensive evaluations, we show that commercial models (e.g., Sora 2, Veo 3.1) demonstrate stronger reasoning potential, while open-source models reveal untapped potential that remains hindered by limited training scale and data diversity. To further unlock this potential, we introduce VideoTPO, a simple yet effective test-time strategy inspired by preference optimization. By performing LLM self-analysis on generated candidates to identify strengths and weaknesses, VideoTPO significantly enhances reasoning performance without requiring additional training, data, or reward models. Together, TiViBench and VideoTPO pave the way for evaluating and advancing reasoning in video generation models, setting a foundation for future research in this emerging field.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “Benchmarking Think-in-Video Reasoning for Video Generative Models”
1) What is this paper about?
This paper is about teaching and testing video-making AI systems to “think,” not just to make pretty videos. Most video AIs today are great at visuals (smooth motion, nice colors), but they often struggle with problems that need logic, rules, and planning. The authors create a new benchmark (a big, organized test set) to check whether image-to-video models can reason step by step, like how LLMs explain their thinking in text. They also propose a simple way to boost these models’ reasoning at test time without retraining them.
2) What questions did the researchers ask?
The paper focuses on three easy-to-understand questions:
- Do today’s video-generation AIs show signs of real reasoning, beyond making good-looking videos?
- When these AIs fail at reasoning, why do they fail?
- Can we improve their reasoning quickly and cheaply at test time (without collecting new data or retraining the model)?
3) How did they study it?
They built a reasoning-focused benchmark for image-to-video (I2V) models. Think of it like a school exam with subjects, topics, and difficulty levels.
The benchmark covers four “subjects” of visual reasoning:
- Structural Reasoning and Search: Like tracing the right path in a maze, sorting items in order, or moving through a graph without breaking rules.
- Spatial Visual Pattern Reasoning: Recognizing and extending patterns, fitting shapes, matching colors, counting objects, or finding the odd one out.
- Symbolic Logical Reasoning: Using symbols and logic, such as easy Sudoku, arithmetic, or rule-based deduction.
- Action Planning and Task Execution: Planning and doing multiple steps in the right order, like tool-use or following a set of visual instructions over time.
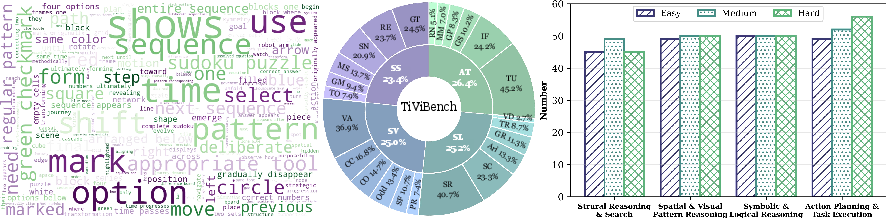
Each subject contains several task types (24 total), and each task has three difficulty levels: easy, medium, hard. Altogether, the benchmark includes hundreds of carefully checked examples.
How the tasks work (in everyday terms):
- The model is given a starting image and a written prompt, and must generate a short video that shows the correct steps and ending.
- Prompts are written to be clear and descriptive but not “spoil” the exact steps (so the model has to figure things out).
- The team used a strong LLM to help craft consistent, fair prompts, then humans reviewed them to ensure quality.
How they scored the models:
- Process-and-goal consistency: Did the video both follow the correct steps and reach the right ending? For example, in a maze, did the dot follow the legal path to the exit?
- Final-state validation: Did the video end at the correct answer, even if the steps weren’t checked closely? For example, did the Sudoku end up solved?
A simple way to understand Pass@k:
- Pass@1 means: if the model gets only one try, does it get it right?
- Pass@5 means: if the model gets five tries, did at least one of them succeed? This is like giving a student multiple attempts at a question and counting it correct if any attempt is right.
Which models they tested:
- Commercial (closed) models like Sora 2 and Veo 3.1.
- Open-source models like Wan and HunyuanVideo. This lets them compare top-tier, big-budget systems with community models.
A test-time boost method (no retraining):
- The authors introduce a “prompt preference optimization” strategy at test time. Here’s the idea:
- The model generates two video candidates from the same prompt.
- A vision-LLM (a smart AI that can look and read) compares the two, writes what’s good and bad (a textual critique), and suggests how to improve the prompt.
- The prompt is then refined using this feedback, and the model tries again.
- Think of it like a coach watching two practice runs, noting what worked and what didn’t, and then giving precise instructions to improve the next try. No model weights are changed; it’s all done by changing the words in the prompt.
4) What did they find, and why is it important?
Key results:
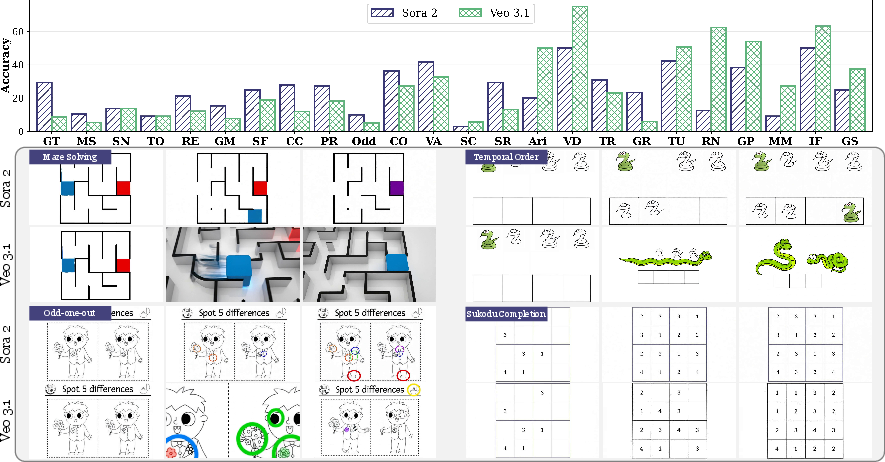
- Commercial models reason better overall. Sora 2 and Veo 3.1 generally outperformed open-source models across subjects and difficulty levels. This suggests that more training data, bigger models, and careful engineering matter a lot for visual reasoning.
- Open-source models show “hidden potential.” Their Pass@5 scores (multiple tries) are noticeably better than Pass@1 (single try). This means they can get the right answer sometimes, but not consistently yet.
- Where models fail: They struggle most when strict rules and fine details matter. Examples include:
- Maze solving (don’t cross walls), temporal ordering (put events in the right time order), odd-one-out, and Sudoku. These tasks require precise logic and careful visual detail reading.
- Two main causes stood out:
- 1) Weak rule-following: The model doesn’t reliably learn or obey problem rules.
- 2) Loss of tiny visual details: Some model parts compress images so much that small but important clues get lost.
Test-time optimization helps a lot:
- The authors’ prompt refinement method improved open-source models significantly without retraining. For example, one open-source model’s overall accuracy roughly doubled (from about 8% to around 18%) using this on-the-fly coaching approach.
- Even simple pre- or post-generation prompt rewriting helps, but their preference-based, multi-candidate method helped the most, likely because it compares outputs directly and gives targeted feedback.
Why this matters:
- It shows that video models can start to “think in frames,” not just “paint frames.” That’s a step toward video AIs that can plan actions, follow rules, and solve visual puzzles.
5) What’s the impact and what could come next?
Implications:
- A new standard for judging “video intelligence”: This benchmark gives the community a clear way to measure whether a video model is just pretty or actually smart. That encourages progress on reasoning, not just visuals.
- Practical improvement without retraining: The test-time prompt optimization is cheap and easy to use. Teams can get better reasoning today, even if they can’t afford huge training runs.
- Roadmap for better models: To truly excel at reasoning, future video models will likely need:
- Better ways to learn and obey rules (for example, training with rule feedback or reinforcement learning).
- Architectures that keep fine visual details (so tiny but important clues aren’t lost).
- More diverse, reasoning-focused training data.
Big picture:
- If video models learn to reason reliably, they could become powerful “visual problem-solvers” for tasks like robot planning, tool use, instruction-following, and educational content. This research lays the groundwork—by providing a rigorous test and a practical method to improve results—so the field can move from “nice-looking videos” to “videos that think.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable future research.
- Scope limited to image-to-video (I2V): it is unknown whether the benchmark and findings transfer to text-to-video (T2V), image-to-animation, video editing, or multimodal (audio+video) generation settings.
- Dataset scale and diversity: 595 samples across 24 tasks may be insufficient for robust statistics and long-tail phenomena; expand task families (e.g., real-world scenes, naturalistic videos) and quantify coverage/bias across domains, styles, and visual complexity.
- Difficulty calibration: task difficulty levels are curated but not formally calibrated; provide quantitative difficulty measures and verify monotonicity of difficulty across tasks and models.
- Metric reliability and robustness: automated validators (tracking, OpenCV, DINO) may fail on stylized outputs, occlusions, motion blur, or high-frequency artifacts; benchmark metric precision/recall per task, stress-test metrics under rendering artifacts, and release validated metric suites with error analyses.
- Human–metric agreement: alignment is reported only in a limited setting (e.g., Wan2.1); extend human–metric agreement studies across all tasks, difficulty levels, and models, and quantify inter-annotator agreement (e.g., Cohen’s κ).
- Fairness and comparability: inputs (resolutions, aspect ratios) are “adjusted per model,” but the fairness impact is unquantified; standardize input protocols and report sensitivity to resolution/aspect ratio and inference parameters (e.g., temperature, guidance scale).
- Commercial model evaluation: only Pass@1 is reported due to black-box constraints; examine multi-sample outputs (Pass@k), sampling variability, and prompt sensitivity in commercial models to ensure fair comparability.
- Prompt generation bias: prompts are produced via Gemini-2.5-Pro; analyze how prompt style, verbosity, and narrative structure influence outcomes; perform cross-prompt ablations and study cross-lingual prompts (non-English) for language bias.
- Leakage and prior exposure: internet-derived content may overlap with pretraining corpora of commercial models; assess data provenance, potential leakage, and its effect on apparent reasoning performance.
- Real-world physics and embodiment: “tool use” and “robot navigation” tasks are synthetic; evaluate physically grounded tasks with measurable dynamics (contacts, forces, constraints) and compare to physics engines or sensor-grounded benchmarks.
- Long-horizon reasoning: video duration, memory limits, and temporal dependencies are not systematically varied; study how reasoning scales with horizon length, frame rate, and temporal complexity.
- Robustness to distribution shifts: test models under occlusions, clutter, camera motion, lighting changes, and adversarial visual noise to assess reasoning stability.
- Failure taxonomy: only illustrative failure cases are shown; build a comprehensive taxonomy of errors (rule violations, symbol misreads, temporal inconsistencies, planning breakdowns) with per-task quantitative breakdowns.
- Scaling laws for reasoning: the paper hypothesizes data/parameter scale helps reasoning but does not measure it; run controlled scaling experiments (data size, parameter count, training steps) to derive reasoning scaling laws.
- Mechanistic understanding: no analysis of whether “chain-of-frames” behavior reflects genuine structured reasoning vs. pattern matching; apply representation probes, causal interventions, and process-level verifiers to distinguish reasoning from heuristics.
- Test-time Prompt Preference Optimization (TPO) details: number of iterations, stopping criteria, and candidate count are not systematically ablated; quantify compute cost, convergence behavior, and sample efficiency across tasks.
- Dependence on external VLM critiques: TPO relies on GPT-4o for pairwise critique; evaluate alternative critics (open-source VLMs), critique quality, and alignment between critic feedback and ground-truth metrics to avoid reward misalignment.
- Generalization of optimized prompts: refined prompts show poor transfer across models; study cross-model and cross-task generalization, and design model-agnostic prompt templates that retain effectiveness.
- Baseline breadth: comparisons are limited to pre-/post-rewriting; add stronger baselines (SFT with curated reasoning data, RL/RFT, DPO-style alignment, beam search with visual verification) and measure sample-efficiency and cost trade-offs.
- Interaction and closed-loop control: benchmark focuses on one-shot visual generation; evaluate interactive or iterative settings where the model must react to intermediate feedback, constraints, or environment changes.
- Symbolic extraction fidelity: tasks requiring precise reading of symbols/grids (e.g., Sudoku) hinge on reliable visual parsing; quantify parsing errors and explore higher-resolution encoders or hybrid symbolic parsers to reduce lossy compression effects.
- Process-level evaluation: several tasks validate only final state; add process verification (e.g., path legality, rule adherence at each step), and incorporate video-time annotations to penalize “shortcut” solutions.
- Reproducibility and transparency: report seeds, inference hyperparameters, and full evaluation scripts; release metric implementations, prompt corpora, and data generation code to facilitate independent replication.
- Ethical and environmental costs: multi-pass video generation for TPO is compute-intensive; measure the energy/time cost, propose budget-aware variants, and discuss practical deployment constraints.
- Naming and specification clarity: the benchmark and method names appear inconsistently or elided in the manuscript; clarify formal names, versioning, and component specifications to avoid ambiguity for adoption.
Practical Applications
Immediate Applications
The following items translate the paper’s benchmark and test-time prompt preference optimization into deployable use cases across sectors. Each bullet lists a concrete use case, potential product/workflow, and key dependencies that impact feasibility.
- [Software/AI Platforms] Reasoning QA gate for video-gen model releases
- What: Use the benchmark’s 24 task scenarios and metrics (process-and-goal consistency, final-state validation) as a CI unit/regression test suite for image-to-video (I2V) model updates.
- Product/Workflow: “VidReason QA” microservice that runs Pass@1/Pass@5 checks per release; dashboards highlighting failure modes (e.g., maze boundary violations, temporal ordering errors).
- Dependencies: Access to candidate models (open-source or commercial APIs), compute budget for multiple seeds/samples, metric implementations (DINO/OpenCV tracking, rule validators).
- [Software/Creative Tools] Drop-in test-time prompt optimizer to boost reasoning without retraining
- What: Wrap existing I2V models with the paper’s multi-pass generation + VLM self-analysis to iteratively refine prompts at inference time.
- Product/Workflow: “PromptPilot-Video” SDK/plugin for creative apps; A/B two-candidate generation, VLM critique (“textual loss”), suggestion synthesis (“textual gradient”), prompt update, re-generate.
- Dependencies: VLM access (e.g., GPT-4o class), latency/cost tolerance for multi-pass sampling, guardrails to avoid prompt drift away from user intent.
- [Advertising/Brand Safety] Constraint adherence validator for brand/safety rules
- What: Reuse maze/graph-style structural tasks to build validators that ensure generated videos stay within “safe areas,” respect color/shape usage, and avoid prohibited regions or elements.
- Product/Workflow: “BrandBoundary Guard” that overlays rule maps, tracks motion/regions over frames, rejects non-compliant creatives automatically.
- Dependencies: Reliable object/region tracking, clear machine-readable rule specs per campaign, threshold tuning to minimize false positives.
- [Education] Automated generation and vetting of worked-example STEM videos
- What: Generate step-by-step visual explanations (arithmetic, pattern completion, transitive reasoning) and auto-grade them using the benchmark’s final-state and process metrics.
- Product/Workflow: “Reasoned Lessons” pipeline that drafts videos, scores them against symbolic/visual ground truths, promotes only those passing thresholds.
- Dependencies: Domain-aligned prompts, symbol extraction reliability (grid parsing, OCR), oversight for pedagogy accuracy.
- [Product Enablement/Support] Procedure walkthrough video generation with correctness gating
- What: Produce “how-to” videos for software or devices (tool use, instruction following) and validate that steps are executed in the correct order and reach the target state.
- Product/Workflow: “AutoGuide” that takes initial/target screenshots or photos, generates intermediate steps, and verifies temporal coherence before publishing.
- Dependencies: Access to initial/goal states, robust temporal validators, ability to detect environment-specific steps.
- [MLOps] Model comparison and procurement due diligence
- What: Use benchmark scores to select vendors (e.g., Sora 2 vs. Veo 3.1 vs. open-source) for reasoning-heavy tasks, with Pass@k and per-dimension profiles.
- Product/Workflow: “ReasoningScore” vendor scorecards; acceptance criteria for RFPs based on dimension-level thresholds (structural, spatial, symbolic, action planning).
- Dependencies: Reproducible runs across models; standardized input resolutions; documented prompt preferences.
- [Safety & Quality] Automated hallucination and rule-violation detection
- What: Flag videos that claim to follow explicit constraints but violate them (e.g., crossing maze boundaries, incorrect Sudoku fills, misordered sequences).
- Product/Workflow: “RuleCheck” service integrated before distribution; triggers re-generation via test-time optimization when violations occur.
- Dependencies: Task-specific validators; tolerance settings; seamless fallback to multi-pass prompt optimization.
- [Research/Academia] Benchmark-driven ablation and curriculum design
- What: Use the hierarchical difficulty and four dimensions to craft curricula, run ablations on encoders/VAEs for fine-grained feature preservation, and test RL/RFT variants.
- Product/Workflow: Experiment suites that isolate feature compression impacts on symbolic reasoning; curriculum that ramps from easy to hard tasks.
- Dependencies: Training/inference compute, access to model internals (for open-source), reproducible seeds and logging.
- [Content Platforms/Media] n-best sampling with self-selection for higher Pass@k
- What: Exploit the Pass@5 lift observed in open-source models by sampling multiple candidates and auto-selecting the best via VLM critique + final-state checks.
- Product/Workflow: “Top-K Selector” front-end for content pipelines that automatically chooses the most reasoning-correct variant.
- Dependencies: Budget for parallel sampling, reliable auto-ranking heuristics, API rate limits.
- [Standards/Policy] Evidence-based claims verification for “reasoning-capable” video models
- What: Use the benchmark as an external audit to substantiate marketing/technical claims about visual reasoning capabilities.
- Product/Workflow: Third-party assessment reports with per-dimension metrics and failure analyses; procurement checklists referencing benchmark thresholds.
- Dependencies: Transparent reporting of test conditions, mitigation plans for low-scoring dimensions, model version pinning.
Long-Term Applications
These applications require further research, scaling, integration, or regulatory clearance before broad deployment.
- [Robotics/Embodied AI] Video-as-plan scaffolds for real-world task execution
- What: Convert chain-of-frames reasoning into executable plans for robot manipulation, navigation, and multi-step tool use; close the loop with vision-language-action systems.
- Product/Workflow: “Frame-to-Policy” bridges that translate validated video plans into action graphs or skills, with process-and-goal validation during sim-to-real transfer.
- Dependencies: Robust perception-action grounding, safety certs, low-level controller integration, strong alignment between visual plan and robot capabilities.
- [Healthcare] Procedure planning and patient education with validated reasoning videos
- What: Generate stepwise pre-op plans, rehab routines, or medication instructions with goal/process verification; personalize by patient context.
- Product/Workflow: “CareSteps” system that drafts and validates visual plans, integrates clinician-in-the-loop review, and logs reasoning verification outcomes.
- Dependencies: Medical accuracy, regulatory approval (FDA/EMA), privacy controls, liability frameworks, clinically validated validators.
- [Education] Adaptive tutors that generate and grade reasoning-through-video assessments
- What: Personalized, stepwise visual problem solving with automated grading of both trajectory and outcome; supports formative assessment in STEM.
- Product/Workflow: “VisReason Tutor” that diagnoses where a learner’s reasoning diverges by aligning their generated steps with ground-truth trajectories.
- Dependencies: Reliable step extraction and alignment, fairness across demographics, curriculum integration, teacher oversight.
- [Enterprise/Manufacturing] SOP authoring and digital twin training from validated video plans
- What: Auto-generate standard operating procedures and simulation training content; verify sequencing, constraints, and end states before deployment.
- Product/Workflow: “SOP Studio” for factories/logistics that turns CAD + constraints into validated instructional videos and action graphs.
- Dependencies: Access to accurate plant/twin data, constraint encodings, integration with MES/PLM systems, safety audits.
- [Software/UX Automation] Video-guided multi-step UI agents
- What: Use visual reasoning to plan and verify UI automation flows (onboarding, settings configuration) and produce explainable walkthrough videos.
- Product/Workflow: “UI Plan & Prove” where agents propose video plans, are validated against target states, and then executed via RPA.
- Dependencies: Stable UI element detection, generalization across app versions, recovery from UI drift, permissioning.
- [Security/Trust & Safety] Procedural fact-checking for generated instructional content
- What: Detect misleading or unsafe procedural claims by validating whether steps logically lead to outcomes under the task’s rules.
- Product/Workflow: “ProcFact” verifier that stress-tests dangerous or policy-sensitive videos (e.g., unsafe tool use) by simulating rule adherence.
- Dependencies: Domain-specific safety rules, robust process validators, escalation to human reviewers for borderline cases.
- [Standards/Regulation] Certification schemes for visual reasoning in generative systems
- What: Establish conformance levels per reasoning dimension; require model cards to report benchmark profiles and failure modes.
- Product/Workflow: “Reasoning Grade” labels akin to energy/star ratings; procurement/government usage contingent on minimum grades in relevant dimensions.
- Dependencies: Broad consensus on tasks/metrics, governance body for test administration, anti-gaming safeguards.
- [Data & Training] Synthetic, verifiable datasets for reasoning-focused training
- What: Use benchmark task generators to produce large-scale, label-rich video datasets with explicit intermediate states to train better encoders and process-aware models.
- Product/Workflow: “Reasoning Data Factory” generating diverse, rule-annotated trajectories with automatic labels for RL/RFT or supervised objectives.
- Dependencies: Content diversity, domain coverage, avoiding overfitting to synthetic styles, compute for large-scale training.
- [Cross-Modal GenAI] Extend test-time preference optimization to 3D, audio, and simulation
- What: Generalize the two-sample, VLM-critique loop to other modalities for stepwise, constraint-aware generation (e.g., 3D assembly animations, narrated procedures).
- Product/Workflow: “Multimodal TPO” layer across content stacks; single orchestration engine that coordinates critics across modalities.
- Dependencies: Strong cross-modal critics, latency/cost budget, coherent multi-modal goal/process validators.
- [Public Sector/Urban Ops] Verified procedure videos for emergency response and civic training
- What: Generate and validate scenario-based training (evacuation routes, equipment use) ensuring strict rule compliance and clear causal logic.
- Product/Workflow: “CivicReason” content packs tailored to local infrastructure and policies, with audit logs of validation outcomes.
- Dependencies: Access to accurate layouts and policies, stakeholder buy-in, periodic audits, multilingual support.
Notable Assumptions and Dependencies (common across many applications)
- Availability and cost of high-quality VLMs to act as reliable critics for textual loss/gradient.
- Latency and compute for multi-pass generation; throughput constraints in production.
- Metric–human alignment holds across new domains; validators remain robust under style diversity.
- Access and licensing for commercial models and datasets; consistent input resolutions (e.g., 720p) and prompt formatting.
- Risk controls to prevent prompt optimization from drifting off user intent; logging and explainability for audits.
- Safety, privacy, and regulatory compliance in sensitive sectors (healthcare, public safety).
- Differences in model prompt preferences; per-model tuning may be required for optimal gains.
These applications leverage the paper’s two core contributions: a hierarchical, reasoning-oriented benchmark that surfaces capability profiles and failure modes; and a practical, training-free test-time optimization loop that measurably boosts reasoning performance in existing I2V systems. Together, they enable immediate improvements in QA and production pipelines while laying the groundwork for longer-term integrations with robotics, education, healthcare, and standards.
Glossary
- black-box nature: A property of proprietary systems where internal architecture and training details are not disclosed. "For commercial models, due to their strong performance and black-box nature, we report only Pass."
- chain-of-frames reasoning: A step-by-step visual reasoning paradigm that unfolds across successive video frames. "by introducing the concept of "chain-of-frames" reasoning in image-to-video (I2V) generation"
- DINO: A self-supervised vision model used to extract robust visual features for evaluation. "sequence completion can be validated by comparing extracted features (e.g., via DINO \citep{caron2021emerging})"
- Final-State Validation: A correctness-focused evaluation that checks only whether the video reaches the intended target state. "Final-State Validation. These tasks assess whether the generated video achieves the correct target state, with no emphasis on intermediate reasoning steps."
- FVD: Fréchet Video Distance; a metric for assessing video generation quality by comparing distributions of features between generated and real videos. "Early evaluations of I2V models relied on metrics like FVD \citep{heusel2017gans} on datasets like UCF101 \citep{soomro2012ucf101}"
- ground-truth: The authoritative reference data (initial, intermediate, and target states) used to verify correctness. "visual reasoning tasks are inherently more verifiable due to explicit ground-truth information, including initial, intermediate, and target states."
- image-to-video (I2V): A generation paradigm that transforms an input image (and prompt) into a video. "by introducing the concept of "chain-of-frames" reasoning in image-to-video (I2V) generation"
- LLMs: High-capacity neural networks trained on vast text corpora that exhibit advanced understanding and reasoning. "The rapid development of LLMs \citep{achiam2023gpt, brown2020language, bai2023qwen, guo2025deepseek} has fundamentally transformed the field of artificial intelligence"
- multi-pass generation: Producing multiple candidate outputs per prompt to enable comparative analysis and refinement. "By leveraging multi-pass generation and aligning candidates through preference alignment, enabling more fine-grained and accurate prompt optimization"
- novel view synthesis: Generating new viewpoints of a scene from limited inputs. "and novel view synthesis \citep{you2025nvssolver, zhou2025stable, voleti2024sv3d}"
- OpenCV: A widely used open-source computer vision library for image and video processing. "Sudoku completion can be validated by comparing the generated grid (e.g., via OpenCV \citep{opencv}) with the ground truth"
- Pass@k: An accuracy metric indicating whether at least one correct result appears within k generated attempts. "Here, Pass indicates the accuracy of the model in producing at least one correct output within the predictions"
- post-inference: A prompt rewriting strategy that modifies prompts after inspecting generated results. "Existing prompt rewriting methods are typically classified as pre-inference \citep{wan2025, wiedemer2025video} (i.e., enriching prompts by hallucinating details) and post-inference \citep{xue2025phyt2v} (i.e., modifying prompts based on the generation result)."
- post-rewriter: A baseline technique that iteratively refines the prompt based on the output video. "alongside two baseline strategies: pre-rewriter based on \citep{vertex-ai-video-gen-prompt-guide}, and post-rewriter based on \citep{madaan2023self}."
- pre-inference: A prompt rewriting strategy that enriches or restructures the prompt before generation. "Existing prompt rewriting methods are typically classified as pre-inference \citep{wan2025, wiedemer2025video} (i.e., enriching prompts by hallucinating details) and post-inference \citep{xue2025phyt2v} (i.e., modifying prompts based on the generation result)."
- pre-rewriter: A baseline technique that augments the prompt prior to running the model. "alongside two baseline strategies: pre-rewriter based on \citep{vertex-ai-video-gen-prompt-guide}, and post-rewriter based on \citep{madaan2023self}."
- pretraining data: Large-scale datasets used to initially train a model before task-specific fine-tuning or inference. "differences in pretraining data and architectures often lead to varying prompt preferences across models."
- preference alignment: Adjusting generation towards preferred behaviors by comparing candidate outputs. "aligning candidates through preference alignment, enabling more fine-grained and accurate prompt optimization"
- preference optimization: Using preference signals to guide or improve generation quality or reasoning without explicit labels. "a simple yet effective test-time strategy inspired by preference optimization."
- Process-and-Goal Consistency: An evaluation that verifies both the correctness of the intermediate trajectory and the final outcome. "Process-and-Goal Consistency. These tasks evaluate both the reasoning process and the final result, ensuring the generated video aligns with the expected trajectory and reaches the correct target state."
- reinforcement fine-tuning (RFT): A training approach that uses reinforcement learning to refine model outputs against reward signals. "While supervised fine-tuning (SFT) \citep{brown2020language} and reinforcement fine-tuning (RFT) \citep{shao2024deepseekmath, rafailov2023direct} enhance specific capabilities, they incur high costs due to additional data and training."
- supervised fine-tuning (SFT): Further training a model on labeled data to improve performance on specific tasks. "While supervised fine-tuning (SFT) \citep{brown2020language} and reinforcement fine-tuning (RFT) \citep{shao2024deepseekmath, rafailov2023direct} enhance specific capabilities, they incur high costs due to additional data and training."
- temporal coherence: The logical consistency of events or patterns across time in generated video. "Existing benchmarks predominantly evaluate visual fidelity and temporal coherence"
- temporal smoothness: The visual continuity and lack of jitter across frames in a video. "Current evaluations predominantly focus on visual fidelity, temporal smoothness, physical plausibility, and adherence to input prompts"
- test-time direct preference optimization (TDPO): A lightweight on-the-fly method using pairwise comparisons and self-analysis to refine prompts without external reward models. "we propose test-time direct preference optimization (TDPO)."
- test-time preference optimization (TPO): Iterative alignment during inference by comparing multiple samples and using feedback to improve prompts. "we introduce the concept of test-time preference optimization (TPO) \citep{li2025testtime} for LLMs, which enables finer-grained optimization by comparing preferences across multiple generated samples."
- test-time scaling: Improving performance by scaling inference-time strategies (e.g., multiple candidates, iterative refinement) rather than training. "we further sought to investigate whether test-time scaling could deliver more efficient inference optimization than large-scale training."
- text-to-video (T2V): Generating video content directly from textual prompts. "image-to-video (I2V) generation enables more personalized outputs compared to text-to-video (T2V) models"
- textual gradient: Actionable, model-generated feedback that specifies prompt changes to improve outcomes. "the VLM generates actionable suggestions as textual gradient \citep{yuksekgonul2025optimizing} to improve the prompt ."
- textual loss: Qualitative feedback produced by a model that describes strengths and weaknesses rather than numeric scores. "where encapsulates qualitative feedback rather than numerical scores, enabling more interpretable optimization."
- vision foundation models: General-purpose vision systems capable of solving diverse tasks beyond narrow domains. "become general-purpose vision foundation models capable of solving complex reasoning tasks"
- Visual LLM (VLM): A multimodal model that understands both visual and textual inputs to provide analysis or guidance. "We then assign a VLM (i.e., GPT-4o \citep{achiam2023gpt}) denoted as to conduct self-analysis"
- visual fidelity: The degree to which generated visuals match high-quality, accurate depictions of the intended content. "Existing benchmarks predominantly evaluate visual fidelity and temporal coherence"
- VAE: Variational Autoencoder; a generative model and encoder-decoder architecture that can compress visual features, sometimes losing fine detail. "symbolic reasoning requires precise visual feature extraction, but encoders like VAE compress features excessively, losing critical details needed for reasoning."
- zero-shot reasoning: Performing reasoning on tasks without task-specific training or examples. "offering a comprehensive and nuanced assessment of zero-shot reasoning capabilities."
Collections
Sign up for free to add this paper to one or more collections.

