- The paper presents WWHO, which separates script-specific linguistic rules from statistical compression to achieve lossless syllable tokenization in Abugida scripts.
- It employs a layered architecture including DFA-based syllabification and syllable-aware BPE (SGPE) to maintain atomic token integrity and reduce inference cost.
- Empirical results demonstrate up to 77.2% token reduction and a context window increase of 4.38× for Sinhala and Hindi, enhancing multilingual LLM performance.
Separate Before You Compress: The WWHO Tokenization Architecture
Introduction
The paper "Separate Before You Compress: The WWHO Tokenization Architecture" (2603.25309) addresses the inefficacies of current BPE-based tokenization approaches for complex Abugida scripts, particularly Sinhala and Devanagari. These scripts, widely used in South and Southeast Asia, present unique orthographic structures—syllables (atomic grapheme clusters)—which are fragmented by conventional BPE tokenizers into meaningless sub-character units, severely hindering LLM reasoning and drastically inflating inference cost (“Token Tax”). The WWHO (Where-What-How Often) architecture explicitly separates script-dependent linguistic rules from language-agnostic statistical compression and introduces the SGPE (Syllable-aware Grapheme Pair Encoding) algorithm, advancing the state-of-the-art in linguistic and statistical tokenization for complex scripts.
A major theoretical contribution is the regular-language formalization of syllable segmentation in Abugida scripts. Using explicitly defined character classes and a table-driven DFA, the paper establishes that syllabification in both Sinhala and Devanagari can be accurately and deterministically achieved with a regular grammar, capturing the orthographic consistency and atomicity of syllables.
The formal syllable regular expressions for Sinhala and Devanagari ensure that every valid syllable—composed of core consonants, diacritics, viramas, joiners (e.g. ZWJ), modifiers, and, in Devanagari, the nukta—is tokenized as a complete, uninterpretable unit. This approach satisfies the "Zero-Breakage Guarantee," ensuring no valid syllable is ever split across tokens and that round-trip reconstruction is lossless excepting [UNK] substitutions.
Architecture of WWHO
The WWHO framework leverages a three-layer architecture focused on (1) script segmentation, (2) maximal-munch DFA-based syllabification, and (3) statistically robust syllable-level BPE merging (SGPE).
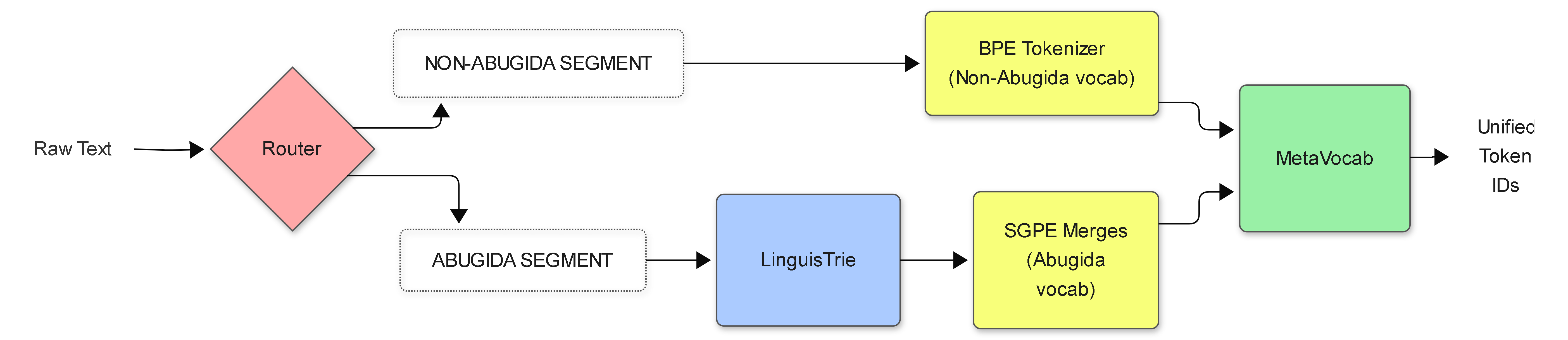
Figure 1: Overview of the WWHO architecture with separate Router, LinguisTrie, and SGPE layers enabling orthographically and computationally optimal tokenization across mixed scripts.
Layer 1 (Router): Utilizes Unicode block scanning and explicit handling of control characters (ZWJ/ZWNJ) to segment multilingual, code-switched text into script-specific regions. This layer operates in linear time and ensures hard boundaries, preserving linguistic context and preventing mis-routed joins.
Layer 2 (LinguisTrie): Employs a DFA compiled from the provided language schema (dynamically specifiable via JSON) to extract maximal orthographic syllables consistent with formal grammar. Its greedy maximal-munch ensures composite conjuncts and extended grapheme clusters remain intact, and all non-conforming (“orphan” or “other”) codepoints are emitted as atomic passthroughs.
Layer 3 (SGPE + Meta-Vocabulary): SGPE performs statistical token merging analogously to classical BPE—but at the syllable rather than byte or grapheme-cluster level. It leverages explicit word and script boundary awareness and frequency-based vocabulary pruning to avoid “glitch tokens.” A unified meta-vocabulary schema concatenates BPE and SGPE token ID spaces, precluding ID collision and enabling seamless code-mixed detokenization.
Empirical Results
The experimental evaluation is conducted on an extensive 30-million-sentence corpus comprised predominantly of Sinhala, Hindi (Devanagari), and English, encompassing authentic code-switched content. Results are benchmarked against OpenAI’s o200k_base, Meta’s Llama 4 Scout, and DeepSeek V3 tokenizers.
- Sinhala:
- SGPE TWR = 1.274; 4.83 characters/token
- Token reduction: 61.7% (OpenAI o200k), 63.4% (Llama 4 Scout), 77.2% (DeepSeek V3)
- Hindi (Devanagari):
- SGPE TWR = 1.181; 4.29 characters/token
- Token reduction: 27.0% (OpenAI), 31.3% (Llama 4 Scout), 57.6% (DeepSeek V3)
- Overall mixed (35% Sinhala/45% Hindi/20% English):
- SGPE TWR = 1.24; token reduction 36.7-60.2%
- Context window multiplier: Up to 4.38× (DeepSeek V3 baseline)
Tokenization of monolingual English (pure ASCII) yields identical results to baseline BPE, with all detected improvements attributable to correct handling of code-mixed Abugida spans, confirming the isolation of routing effects.
SGPE produces zero glitch tokens in the vocabulary, while all atomic orthographic syllables are either utilized or pruned according to frequency, confirming vocabulary efficiency. Empirical round-trip validation on 122 million mixed-script characters shows 100% consistency (with a negligible 0.08% [UNK]-related loss rate), substantiating the theoretical Zero-Breakage Guarantee.
Implications and Future Work
WWHO and SGPE fundamentally realign tokenization for Abugida languages from byte- or grapheme-cluster-centric paradigms to linguistically atomic, computationally optimal syllabification. The demonstrated reduction of inference cost and expansion of usable context window directly mitigate the Token Tax, facilitating equitable LLM access for over a billion users of complex scripts. The formal separation of schema and algorithm guarantees extensibility to other regular-language scripts without code modification, supporting cross-lingual and code-switched deployments in multilingual LLM production.
Practically, these advances enable larger working contexts and more semantically accurate encoding, which, according to prior correlations [goldman2024unpacking], should manifest as improved downstream generative and comprehension capabilities in LLMs for Abugida scripts.
Further research directions include downstream NLU and NLG task benchmarking, release of expanded schema libraries for additional Indo-Aryan and Dravidian scripts, and comprehensive ablation/integration studies with multi-embedding architectures. Pretrained tokenizers, vocabularies, and source code are open-sourced, facilitating reproducibility and adoption.
Conclusion
The WWHO architecture, implemented together with the SGPE algorithm, achieves linguistically faithful, statistically efficient tokenization of complex Abugida scripts, obviating the fragmentation of syllable structure endemic to BPE-based approaches. By guaranteeing atomicity and lossless round-tripping, SGPE reduces the Token Tax by more than 60% on average for Sinhala and Hindi, and expands LLM context windows by up to 4.4× without loss of modeling power on Latin scripts. WWHO’s modularity and schema-driven design enable robust multilingual and code-switched tokenization, establishing a new benchmark for fair, context-efficient Abugida text processing in large-scale LLMs.
Reference: "Separate Before You Compress: The WWHO Tokenization Architecture" (2603.25309).

