- The paper evaluates tokenizer efficiency of 12 LLMs using the Normalized Sequence Length metric across 22 official Indian languages.
- It employs comprehensive methodology with authentic sample texts and detailed token distribution analysis for each language.
- Findings reveal models like SUTRA achieve superior multilingual processing, while others face challenges with diverse Indian scripts.
This essay explores the tokenizer performance of 12 LLMs across the 22 official languages of India, focusing particularly on the efficiency and capability of these tokenizers. The analysis centers on the Normalized Sequence Length (NSL) metric to quantify tokenizer efficiency. Key results reveal insights into multilingual capabilities, and some models' limitations highlight future directions for research and model improvement.
Introduction to Tokenization in LLMs
Tokenization is a critical preprocessing step for LLMs, particularly in multilingual models that address diverse language sets such as the Indian subcontinent. LLMs like OpenAI’s GPT-4o and Google’s SUTRA require tokenizers that efficiently process complex scripts to optimize model performance. This paper evaluates tokenizers using NSL, focusing on subword fertility methods to assess tokenizer efficiency across 22 languages.
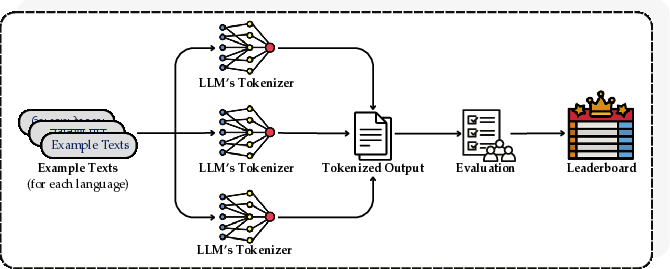
Figure 1: Evaluation pipeline: (1) We collect example texts for all 22 languages. (2) We send the example texts to the LLMs' tokenizer. (3) Evaluate the tokenized outputs. (4) We construct leaderboards using our evaluation.
Methodology
Data Collection
Sample texts were compiled for each language in their primary scripts to ensure authentic tokenization performance. Figure 2 shows the Assamese text example used in this evaluation, reflecting linguistic diversity across the languages analyzed.
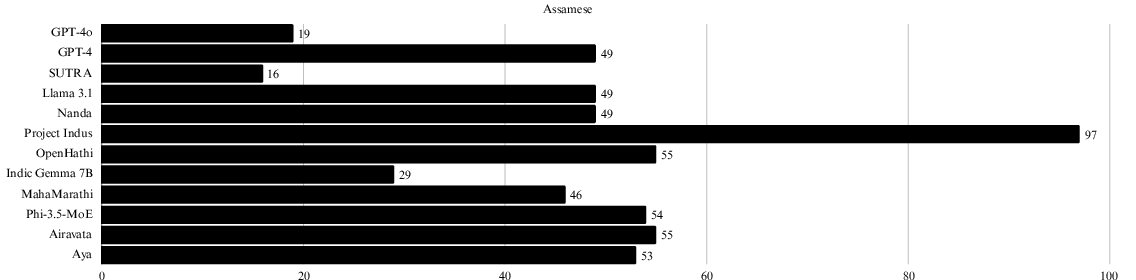
Figure 2: Assamese text used for evaluating tokenizer performance.
Tokenizer Models
Twelve models, both proprietary and open-weight, were selected for evaluation, including OpenAI’s GPT-4o, GPT-4, Microsoft’s Phi-3.5-MoE-instruct, Meta’s Llama 3.1, and several Indic-specific models. Each tokenizer's performance was scrutinized to identify strengths in handling various Indian languages, highlighted in Table 1.
Metric: Normalized Sequence Length (NSL)
The study employs NSL to compare the tokenization efficiency across different models. Lower NSL values indicate better tokenization, signifying that fewer tokens are needed to represent the same text, which equates to more efficient model processing.
Results and Analysis
Results presented in Table 1 show the average NSL scores for each tokenizer across all languages. SUTRA excelled in 14 of the languages, indicating its superior handling of Indic languages.
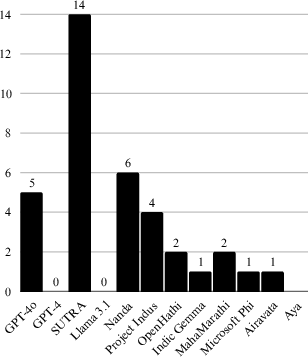
Figure 3: Number of Best Performances Achieved by Each Tokenizer Across 22 Languages.
Individual Language Analysis
Token distribution in specific languages such as Assamese (Figure 4) displays lower token requirements for SUTRA, indicating enhanced efficiency. Each language's token count is visually represented in the appendices to highlight comparative performance.
Figure 4: Number of tokens required for a single example text in Assamese. Lower values are better.
Discussion
Multilingual Model Strengths and Weaknesses
Despite various models being developed as multilingual, only SUTRA and GPT-4o consistently achieved efficient tokenization across languages. Conversely, other models such as Microsoft's Phi and Indic Gemma showed limited performance with specific languages, indicating room for improvement in dialectical and script processing.
The Importance of Efficient Tokenization
Efficient tokenization reduces computational costs and accelerates processing time, contributing significantly to improving LLM efficiency and resource allocation. An effective tokenizer supports better language representation, especially crucial in linguistically diverse regions like India.
Conclusion
This paper underscores the critical role of tokenization in enhancing LLM performance in multidiverse linguistic environments. Future research should focus on advancing tokenizer designs to address the complexities of Indian scripts and dialects, ensuring comprehensive coverage and efficient processing across all languages.

