- The paper reveals that inherent linguistic properties cause crosslingual disparities in token counts despite controlled training settings.
- It demonstrates that optimized BPE and SuperBPE tokenizers with language-specific vocabulary sizing significantly reduce token premium effects and variance.
- The study highlights that pre-tokenization choices, such as whitespace splitting, are major factors driving inequities, urging a language-aware approach to tokenizer design.
Explaining and Mitigating Crosslingual Tokenizer Inequities
Introduction
This paper presents a comprehensive empirical investigation into crosslingual inequities in subword tokenization, specifically focusing on the phenomenon of "token premiums"—the variable number of tokens required to encode parallel text across different languages. The authors systematically train and evaluate approximately 7,000 monolingual tokenizers for 97 languages, controlling for dataset size, vocabulary size, and tokenization algorithm. The study identifies key factors driving token premium effects and proposes interventions to mitigate these inequities, with implications for the design of more equitable multilingual LLMs.
Token Premiums: Measurement and Manifestation
Token premiums are operationalized via corpus token count (CTC), which quantifies the total number of tokens required to encode a fixed corpus of parallel text. The authors demonstrate that even when controlling for training data size, vocabulary size, and tokenization algorithm, monolingual tokenizers exhibit substantial crosslingual variation in CTCs.
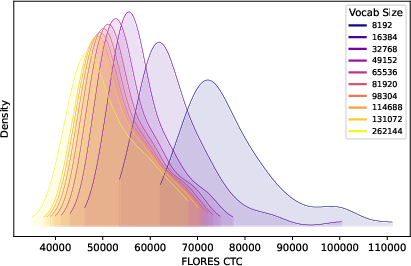
Figure 1: Distribution of corpus token counts (CTCs) for all languages in our sample as a density plot over CTC scores, for the BP-unscaled BPE tokenizers. Higher CTCs indicate worse compression. The distribution for each vocabulary size is plotted separately. As vocabulary size increases, the distribution shifts left and becomes more compressed, and the right tail becomes less extreme.
This result contradicts the assumption that token premium effects are solely a consequence of multilingual tokenizers' uneven data or vocabulary allocation. The observed inequities persist in strictly monolingual settings, indicating that inherent linguistic and script-specific properties interact with tokenizer design to produce compression disparities.
Experimental Design: Tokenizer Training and Evaluation
The authors train tokenizers using the Hugging Face tokenizers package, employing both BPE and Unigram algorithms across seven vocabulary sizes (16,384 to 114,688), with and without byte-premium scaling of training data. FLORES-200 serves as the evaluation corpus, ensuring content-matched parallelism across languages. The study finds that BPE tokenizers consistently yield lower CTCs and less variance than Unigram or SentencePiece implementations, confirming BPE's superior compression in crosslinguistic contexts.
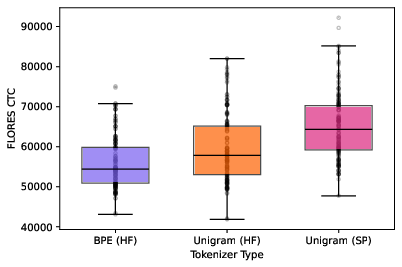
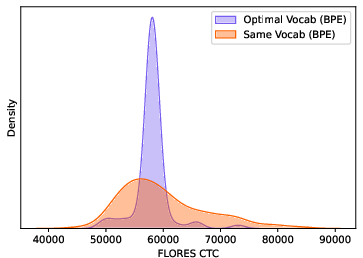
Figure 2: Left: the distribution of CTCs for BPE and Unigram tokenizers using Hugging Face (HF) or SentencePiece (SP) implementations, all with vocabulary sizes of approximately 50000. Right: the distribution of CTCs for same-vocabulary and optimal-vocabulary BPE tokenizers. The optimal-vocabulary tokenizers have target CTCs of 56000. The same-vocabulary tokenizers have a vocabulary size of 32768.
Byte-premium scaling of training data does not significantly affect CTCs, and increasing vocabulary size alone does not eliminate token premium effects.
Explaining Crosslingual Token Premiums
The study systematically analyzes potential predictors of token premium effects, including:
- Train-eval data similarity: Measured as normalized token overlap between training and evaluation corpora. While it explains the most variance in CTCs, training on parallel data yields only marginal improvements.
- Mean token length: Compression is more closely linked to the mean length of tokens actually used in the evaluation corpus, rather than the vocabulary-wide mean.
- Proportion of whitespaces: Languages with higher whitespace frequency (e.g., those with shorter words) are more affected by whitespace-based pre-tokenization, resulting in higher CTCs.
Script type and other linguistic features (e.g., phoneme inventory, character entropy) are also evaluated, but whitespace proportion and data similarity remain the strongest predictors.
Mitigation Strategies
Training on Parallel Data
Training tokenizers on parallel data slightly reduces token premium effects, but the improvement is negligible (mean reduction ~1% in CTC), and the effect is concentrated at the smallest vocabulary sizes.
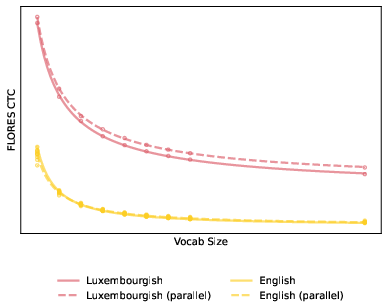
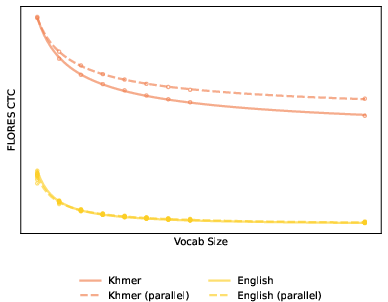
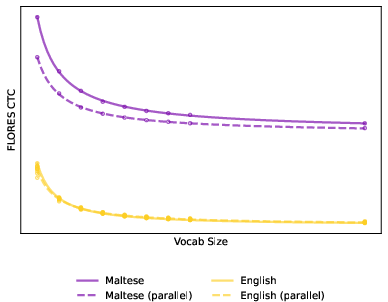
Figure 3: Comparison of CTCs for tokenizers trained on non-parallel (solid lines) versus parallel (dashed lines) data for three languages: Luxembourgish, Khmer, Maltese.
Vocabulary Size Optimization
Rather than using a fixed vocabulary size across languages, the authors fit power law curves to the CTC-vocabulary size relationship for each language and identify "optimal" vocabulary sizes that minimize CTC variance across languages. This approach significantly reduces token premium effects.
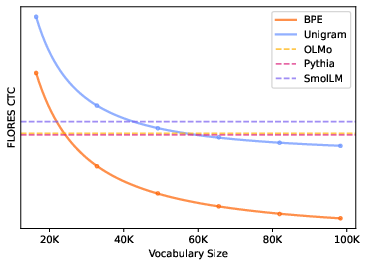
Figure 4: The solid curves, fit using a power law, represent the measured CTCs for each vocabulary size, plotted as points along the curve. The horizontal dashed lines indicate the CTCs of the OLMo, Pythia, and SmolLM tokenizers.
Superword Tokenization (SuperBPE)
Allowing merges over whitespace boundaries (SuperBPE) further reduces both mean CTC and variance across languages, outperforming standard BPE at all tested vocabulary sizes. SuperBPE tokenizers trained with language-specific optimal vocabulary sizes achieve near-uniform compression across diverse languages.
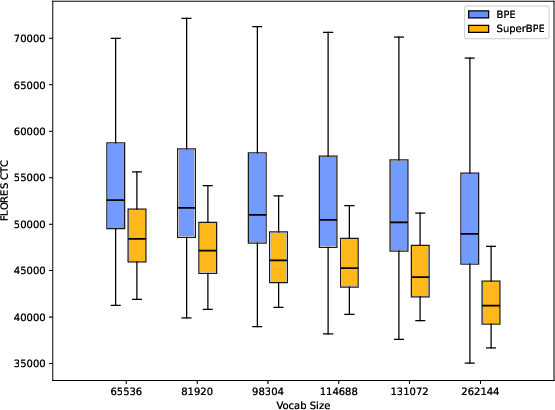
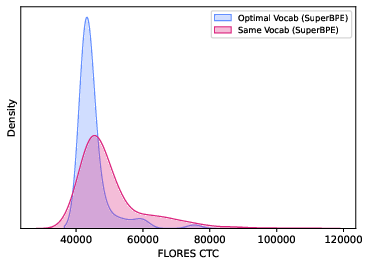
Figure 5: Left: the distribution of CTCs for BPE and SuperBPE tokenizers for each vocabulary size. Right: the distribution of CTCs for same-vocabulary and predicted CTCs for the optimal-vocabulary SuperBPE tokenizers. The optimal-vocabulary tokenizers have target CTCs of 43000. The same-vocabulary tokenizers have a vocabulary size of 49152.
Remaining Variance and Limitations
Even after these interventions, residual variance in CTCs is attributable to intrinsic language properties such as length ratio and bytes-per-character, which are determined by script and Unicode encoding. The authors note that recent work on script-agnostic encoding schemes may further address these inequities, but length ratio effects remain unresolved.
Implications for Multilingual Model Design
The findings have direct implications for the design of multilingual tokenizers and LLMs:
- Pre-tokenization choices (especially whitespace splitting) are a major source of crosslingual inequity.
- Vocabulary size should be language-specific, not globally fixed, to ensure equitable compression.
- Superword tokenization is a robust method for mitigating token premium effects, especially in languages with high whitespace frequency.
- Compression improvements directly reduce training and inference costs, even if not always correlated with downstream model performance.
The results challenge the practice of using a single tokenizer configuration for all languages and suggest that equitable multilingual modeling requires careful, language-aware tokenizer design.
Future Directions
Further research is needed to:
- Develop encoding schemes that neutralize script and Unicode-induced compression disparities.
- Investigate the relationship between compression and downstream model performance in non-English and morphologically complex languages.
- Explore the trade-offs between compression and linguistic alignment in tokenization, especially for languages with rich morphology.
Conclusion
This work provides a rigorous empirical foundation for understanding and mitigating crosslingual tokenizer inequities. By identifying the key drivers of token premium effects and demonstrating effective interventions—optimal vocabulary sizing and superword tokenization—the study offers actionable guidance for the development of fairer, more efficient multilingual LLMs. The results underscore the necessity of language-specific tokenizer design and highlight the critical role of pre-tokenization in shaping crosslingual model behavior.

