- The paper introduces SCRIPT, a structured encoding scheme that leverages Unicode script properties to reduce bias in multilingual tokenization.
- The methodology replaces complex regex-based pretokenization with script-based grouping and constrained BPE merging, enhancing token integrity.
- Empirical results demonstrate that SCRIPT achieves competitive compression rates while eliminating partial UTF-8 sequences across diverse languages.
"BPE Stays on SCRIPT: Structured Encoding for Robust Multilingual Pretokenization"
Introduction
The paper "BPE Stays on SCRIPT: Structured Encoding for Robust Multilingual Pretokenization" (2505.24689) introduces a novel encoding scheme named SCRIPT, which addresses the limitations of traditional Byte Pair Encoding (BPE) in multilingual contexts. Existing BPE systems often rely on pretokenization strategies that are based on complex regular expressions, leading to inconsistencies and biases, especially against non-Western scripts. This paper proposes a robust alternative that leverages Unicode script and category properties, drastically improving the handling of multilingual text tokenization.
Motivation
Traditional BPE tokenizers suffer from several limitations. The reliance on UTF-8 encoding introduces bias due to variable byte-length representations, which disadvantage non-Latin scripts by penalizing them with higher byte overheads. Furthermore, the pretokenization step, often dependent on handcrafted regular expressions, introduces edge cases and suboptimal segmentation. The authors highlight these inefficiencies, especially in diverse multilingual applications.
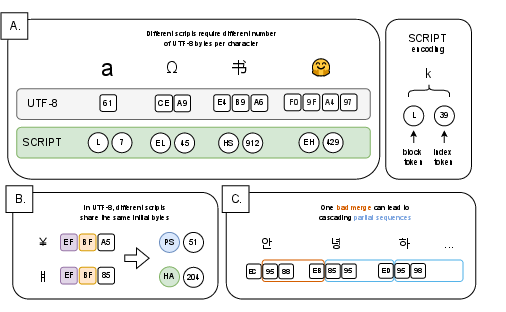
Figure 1: A: Illustration of variable encoding length in UTF-8 encoding compared to consistent encoding length for SCRIPT encoding. B: In UTF-8, the same initial byte sequences may be used for characters in different scripts, however SCRIPT encoding uses consistent block tokens to represent characters from the same script block. C: Byte-based BPE can allow merges that create partial UTF-8 sequences, which then cascade through the rest of the sequence.
SCRIPT Encoding Scheme
SCRIPT encoding introduces a structured representation of text by mapping each Unicode character to a pair of tokens: a block token and an index token. This mapping is determined based on the Unicode script and supercategory properties. By assigning tokens in this manner, SCRIPT minimizes cross-linguistic bias and addresses the byte premium effect that unfairly penalizes certain scripts.
The encoding operates by organizing characters into blocks defined by their script and supercategory, with large blocks further split to maintain manageable vocabulary sizes. This approach ensures a consistent and linguistically meaningful representation across diverse languages.
Enhancements in Pretokenization
SCRIPT's structured encoding simplifies pretokenization by eliminating the need for complex regular expressions. Pretokenization groups characters by shared script properties, applying simple merging rules for spaces and inherited script characters, which aligns closely with natural language properties.
Constrained BPE merging within SCRIPT further enhances text tokenization by preventing the problematic merging of partial character representations, a common issue in byte-level BPE, which improves the integrity and meaning of the generated tokens.
Empirical Results
The empirical evaluation demonstrates that the SCRIPT encoding scheme greatly reduces the number of partial UTF-8 sequence tokens while offering competitive compression rates compared to traditional byte-level BPE. The results highlight the robustness of SCRIPT across various multilingual datasets, showing universal improvements in compression ratios when constrained merging is applied, thus eliminating mixed full and partial character tokens.
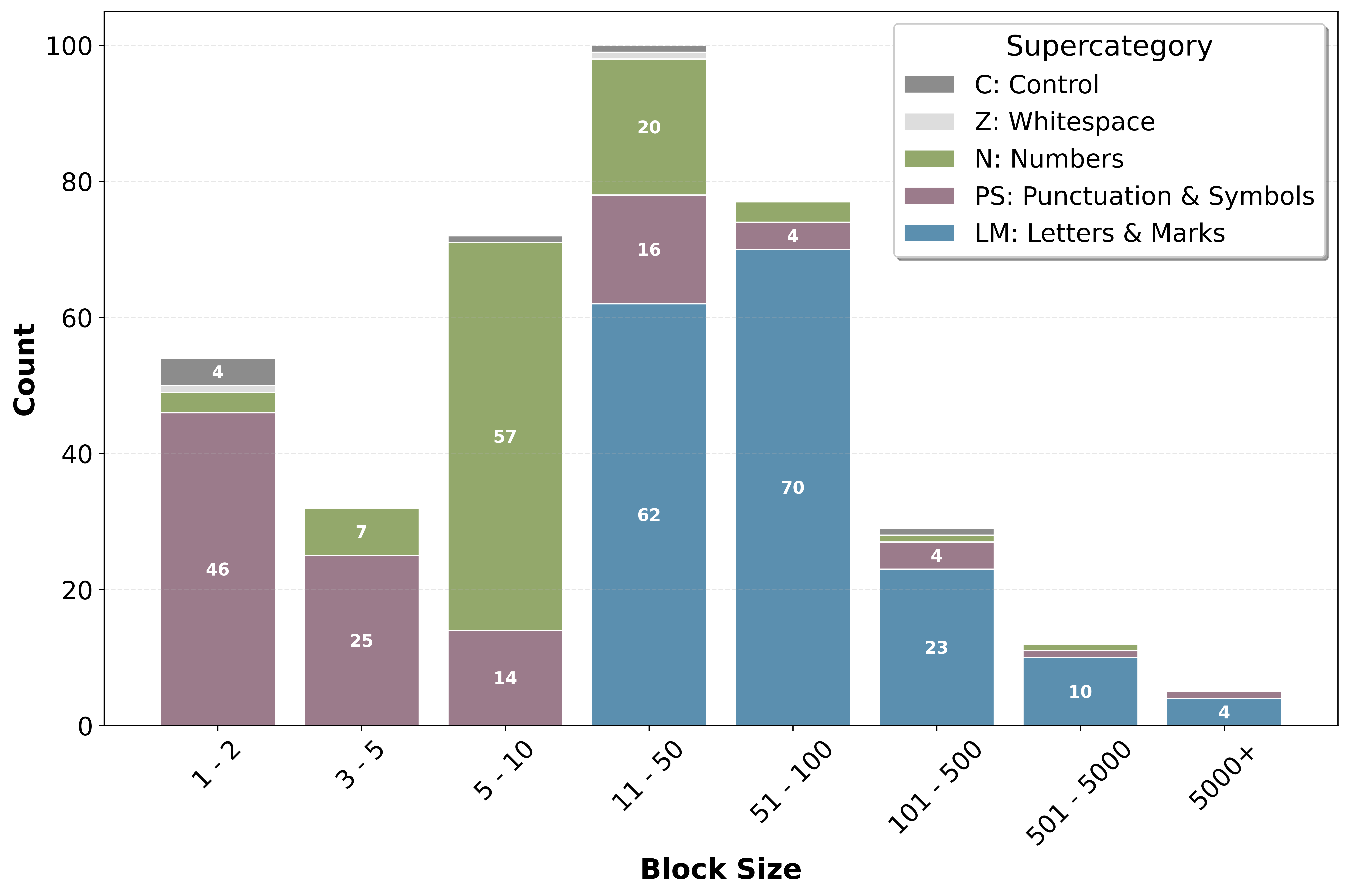
Figure 2: Distribution of block sizes in SCRIPT encoding, before splitting large blocks into sub-blocks.
SCRIPT's computational efficiency is notable. While constrained merges add complexity by requiring additional boundary checks during the BPE process, the overall training time is not significantly affected, and in some cases, it even reduces due to the restricted search space. The methodology ensures that efficiency is maintained even in extensive multilingual contexts, making it suitable for large-scale applications.
Conclusion
SCRIPT provides a significant advancement in text tokenization for multilingual LLMs, reducing biases inherent in traditional systems and simplifying the tokenization process. The adoption of SCRIPT and constrained merging is recommended to achieve better linguistic parity and robustness.
Future research directions include evaluating the impact of SCRIPT on downstream model performance and exploring further optimizations in pretokenization and merging strategies. The potential for implementing modular, script-specific tokenizers as needed for specific applications also presents an intriguing avenue for exploration. Overall, SCRIPT represents a step forward in creating more equitable and effective LLMs.

