WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
Abstract: Dynamical systems theory and reinforcement learning view world evolution as latent-state dynamics driven by actions, with visual observations providing partial information about the state. Recent video world models attempt to learn this action-conditioned dynamics from data. However, existing datasets rarely match the requirement: they typically lack diverse and semantically meaningful action spaces, and actions are directly tied to visual observations rather than mediated by underlying states. As a result, actions are often entangled with pixel-level changes, making it difficult for models to learn structured world dynamics and maintain consistent evolution over long horizons. In this paper, we propose WildWorld, a large-scale action-conditioned world modeling dataset with explicit state annotations, automatically collected from a photorealistic AAA action role-playing game (Monster Hunter: Wilds). WildWorld contains over 108 million frames and features more than 450 actions, including movement, attacks, and skill casting, together with synchronized per-frame annotations of character skeletons, world states, camera poses, and depth maps. We further derive WildBench to evaluate models through Action Following and State Alignment. Extensive experiments reveal persistent challenges in modeling semantically rich actions and maintaining long-horizon state consistency, highlighting the need for state-aware video generation. The project page is https://shandaai.github.io/wildworld-project/.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces WildWorld, a huge collection of game videos and data taken from a realistic action role‑playing game (Monster Hunter: Wilds). It’s designed to help AI systems learn how a world changes over time when a player (or an agent) performs actions. Unlike most video datasets, WildWorld doesn’t just store what you see on the screen. It also records the “hidden” game information, like a character’s exact pose, health, and where the camera is. The authors also create WildBench, a set of tests to check whether AI models can follow actions and keep the world’s state consistent over time.
Key goals and questions
The researchers wanted to answer simple but important questions:
- How can we give AI the right kind of data so it can learn cause-and-effect in a world, not just copy pixels?
- Can AI models learn to produce videos where characters’ actions match the commands they’re given?
- Can those models keep the world’s “state” consistent over longer periods (for example, not showing a character shooting when they’ve run out of arrows)?
- What measurements (benchmarks) best test whether an AI is truly controlling and understanding a world, not just making pretty videos?
How they built it (methods explained simply)
Think of a video game as a virtual world where you press buttons (actions) and the world changes (state), and you see the result (video). Most datasets only save the video. WildWorld saves all three.
- Actions: What the player or AI chose to do—like “move,” “attack,” or “dodge.” WildWorld includes over 450 different actions.
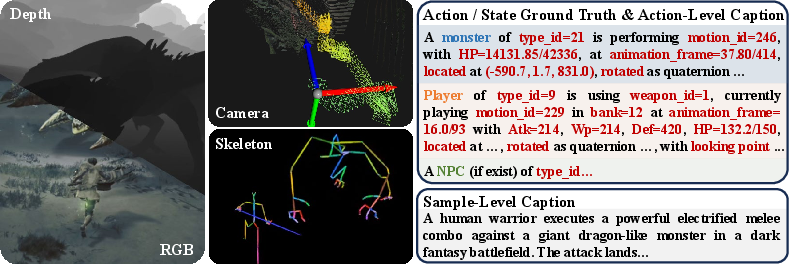
- State: The game’s internal facts—like a character’s exact 3D body pose (skeleton), health, weapon type, positions and speeds, and where the camera is in the world.
- Observations: What you see—regular color video frames, plus “depth maps” (how far each pixel is from the camera, like a built-in distance sensor), and the camera pose (where the camera is and where it’s looking).
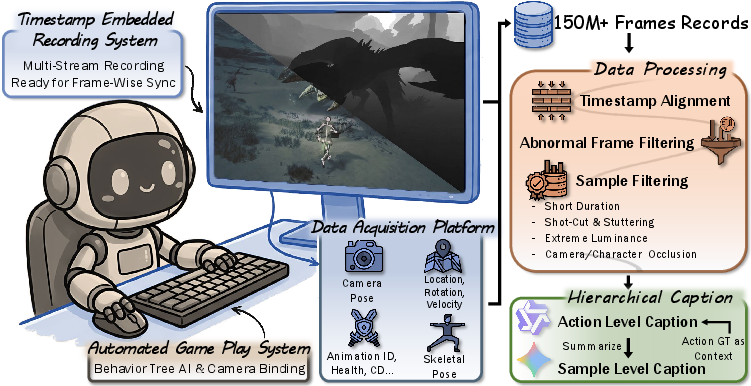
To collect so much data, the team:
- Automated gameplay using built-in game logic so characters could fight and explore without a human constantly playing.
- Recorded more than 108 million frames, carefully syncing videos with the matching states and actions every frame.
- Filtered out low-quality parts (like cutscenes or heavy occlusions) to keep the data clean.
- Added captions that describe actions at a fine level, so models can also be trained or tested with text descriptions.
They also made WildBench, a way to check how good models are at:
- Action Following: Does the video show the right behavior when told to do something (for example, if the input action is “roll left,” does the character actually roll left)?
- State Alignment: Do the character’s poses and movements in the generated video match the ground-truth poses over time?
To test what works, they trained different types of models on WildWorld:
- Camera-controlled model (CamCtrl): Given the true camera path, can it generate the right video?
- Skeleton-controlled model (SkelCtrl): Given the character’s 2D skeleton animation, can it produce a matching video?
- State-aware model (StateCtrl): Given the game’s explicit states (like positions, health, weapon), can it generate videos that stay consistent over time?
- Autoregressive StateCtrl (StateCtrl-AR): Starts with the first frame’s state and then predicts the next states step by step as it generates the video—like planning ahead one move at a time.
Technical terms in everyday language:
- Latent state: The “behind-the-scenes” facts the game knows (like health or ammo), which aren’t always obvious from a single picture.
- Depth map: An image that stores how far away things are from the camera—like a grayscale “distance picture.”
- Camera pose: The camera’s position and the direction it is pointing—like where your head is and where you’re looking.
- Skeleton: The set of 3D points and bones that define how a character’s body is posed.
Main findings and why they matter
Here are the most important results, with a brief reason they matter:
- Models do better when given the right signals:
- Feeding the true camera path (CamCtrl) helped the model keep the camera under control, reducing drift and errors.
- Giving a skeleton guide (SkelCtrl) helped the model strongly improve Action Following and State Alignment—meaning characters move more like they’re supposed to.
- Using explicit game states (StateCtrl) improved both action following and long-term consistency without needing extra visual guides.
- Trade-offs exist:
- Skeleton-controlled models followed actions best but slightly reduced “image quality” scores. In plain terms, strict control can make the picture a bit less polished.
- State-aware models produced cleaner-looking frames but didn’t always match the exact visual effects as well as skeleton control.
- Long-term prediction is still hard:
- The autoregressive version (StateCtrl-AR), which predicts future states step by step, suffered from small mistakes piling up over time. This lowered action-following performance, showing that keeping consistency across long videos remains challenging.
- Existing “video quality” scores can be misleading:
- Many models scored very high on general video smoothness/quality metrics, even when they failed at following actions or keeping states aligned. This shows why specialized tests like Action Following and State Alignment are needed.
Why this matters: If you want AI to behave sensibly in a world—whether it’s a game, a robot’s workspace, or a simulation—you need it to understand both actions and hidden state. WildWorld shows that giving models explicit state information and better controls makes them more reliable and more consistent over time.
What this could lead to (implications)
- Smarter, more controllable game AIs: AI that can follow complex actions, remember internal states (like stamina or ammo), and keep stories or battles consistent over long periods.
- Better training grounds for world models: Researchers can use WildWorld to build AIs that plan, react, and stay stable in dynamic environments.
- Improved evaluation standards: WildBench’s Action Following and State Alignment offer clearer ways to tell whether a model is truly “understanding and controlling a world,” not just generating pretty videos.
- Foundations for AI-native games and simulations: With explicit actions and states, it becomes easier to build interactive experiences where AI can co-create realistic, long-running scenes with players.
Simple takeaway
Teaching AI to understand and control a world requires more than just videos—it needs actions and the hidden states that those actions change. WildWorld provides that complete package at a massive scale, and WildBench gives fair tests to measure real-world control and consistency. This moves us closer to AI that can truly act, plan, and stay coherent in complex, living worlds.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper and dataset/benchmark, to guide future research.
- Generalization beyond a single title and genre: The dataset is sourced entirely from one ARPG (Monster Hunter: Wilds). It is unclear how state-aware models trained on WildWorld transfer to other games (first-person, strategy, racing), different camera conventions, or real-world videos. Evaluate cross-domain transfer and identify which state/action abstractions are portable.
- Sim2real transfer and photorealism gap: Despite photorealistic rendering, it remains unknown how models and metrics trained on WildWorld behave on real-world data with different textures, lighting, and sensor noise. Assess sim2real performance and design domain adaptation strategies.
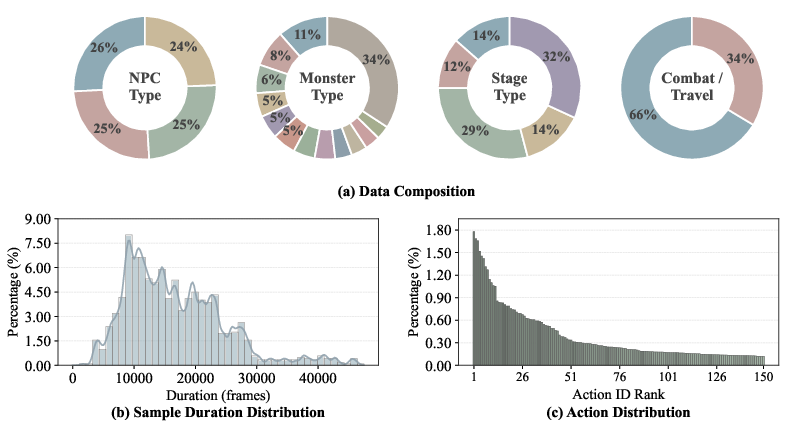
- Coverage and balance of action/state distributions: The action space exhibits long-tail distributions dominated by a few frequent actions/monsters. Quantify and mitigate class imbalance effects on model learning (e.g., reweighting, curriculum, targeted sampling) and report per-class performance.
- Semantic alignment and normalization of actions across entities: The action encoding (weapon type, bank ID, motion ID) is game-specific. Provide a standardized, ontology-level mapping of semantically equivalent actions across characters/monsters and evaluate models’ ability to generalize across that ontology.
- Completeness of state annotations: The paper lists health and stamina but does not specify coverage of other critical latent variables (e.g., ammo, cooldowns, status effects, inventory, buffs/debuffs, quest states, monster aggression phases). Enumerate and release a full state schema; analyze which states most strongly influence future observations.
- Loss of explicit UI cues: HUD was removed to simplify visuals, but this suppresses observable state channels (health, stamina, ammo). Study how the absence of HUD affects learning state-to-appearance mappings and provide an optional HUD-on subset for research on text/icon/state grounding.
- Causal structure and action-effect latency: The dataset does not expose causal graphs or consistent temporal lags between actions and resulting state/visual changes. Quantify action-to-effect delays and provide event-level annotations (e.g., “attack connected,” “damage applied”) for causal evaluation.
- Interaction realism and input policy bias: Automated gameplay relies on rule-based companion AI and target-lock cameras. Audit and report policy-induced biases (move usage, spacing, camera behavior) and introduce human-controlled sessions or diverse AI policies to broaden behavioral coverage.
- Multi-agent interaction richness: Scenarios include the player, NPCs, and monsters, but the dataset lacks explicit labels for interaction types (e.g., coordination, aggro switching, interrupts). Add interaction/event annotations to study cooperative/competitive multi-agent dynamics.
- Environmental dynamics and persistence: Weather/time-of-day are mentioned but not clearly tied to states or transitions; destructibility and long-term world persistence are not discussed. Provide explicit environment-state tokens and evaluate whether models learn environment-conditioned dynamics.
- Long-horizon evaluation and drift: Training uses 81-frame clips and evaluation emphasizes segment-level metrics. Introduce standardized long-horizon tests (minutes-long) with drift/consistency metrics (e.g., cumulative pose error over thousands of frames) and measure failure modes over time.
- Metric validity and scope:
- Action Following via Gemini 3 Flash shows 85% agreement with humans and only covers three coarse categories (movement, fast displacement, attack). Extend to more action types (defense, items, skills) and add timing/intensity/alignment scores instead of binary labels.
- State Alignment relies on 2D keypoints and TAPNext tracking; even on ground-truth videos, it attains 43.23% coordinate accuracy, indicating tracking/metric noise. Incorporate 3D metrics leveraging engine ground truth; quantify tracker failure rates and occlusion sensitivity.
- Evaluation of stochasticity and multimodality: The benchmark penalizes deviation from a single ground-truth trajectory despite inherently stochastic dynamics. Add multi-reference or distributional metrics (e.g., likelihood under a learned state-transition model, diversity under identical actions) to avoid over-penalizing valid alternative futures.
- Camera trajectory estimation reliability: Camera control evaluation depends on SfM-derived camera trajectories from generated videos, which can be unstable under blur/low texture/occlusions. Report failure rates, confidence measures, and consider camera-aware renderings or additional proxies for more robust camera assessments.
- Compression and resolution artifacts: RGB frames are HEVC-compressed and sub-windowed to ~720p before training downsampling to 544×960 at 16 FPS. Quantify the impact of compression/temporal subsampling on motion fidelity, and consider providing a high-fidelity subset for benchmarking fine motion and subtle effects.
- Filtering-induced distribution shift: Luminance and occlusion filters remove challenging conditions (e.g., night scenes, heavy effects), potentially biasing training data toward “clean” scenarios. Release “hard cases” splits and report performance under these conditions.
- Dataset accessibility and reproducibility: With 108M frames and potential IP constraints, practical access may be limited. Clarify licensing, provide lighter subsets, and supply detailed instrumentation tools or recipes to replicate data collection on other titles/engines.
- Standardized schema and cross-game portability: The “119 columns per frame” schema is not fully documented in the paper. Publish a formal, engine-agnostic schema and conversion tools to help other communities contribute new games and to enable cross-dataset training.
- Quality and reliability of auto-generated captions: Hierarchical captions are produced by Qwen/Gemini with game-state prompts but without reported human validation. Quantify caption accuracy, report error types, and offer cleaned/verified subsets for prompt-conditioned evaluations.
- Autoregressive state modeling limitations: StateCtrl-AR exhibits degradation due to error accumulation but the paper lacks ablations on mitigation strategies. Evaluate scheduled sampling, noise-aware training, diffusion-based state predictors, or uncertainty-aware state rollouts to curb compounding errors.
- Per-component state ablations: It is unclear which state components (pose, health, positions, environment) drive the largest gains. Provide ablations removing/adding state subsets to guide minimal sufficient state design for controllable generation.
- Learning from rare events: Critical but infrequent events (e.g., knockdowns, deaths, critical hits) are said to be in the benchmark but are scarce in the full dataset. Construct targeted rare-event subsets and assess few-shot or reweighting strategies to improve performance on tails.
- Interaction transition modeling: Action segments are evaluated per constant-action spans, but fidelity of transitions (enter/exit timing, anticipation, follow-through) is not measured. Introduce transition-focused metrics and labels to capture the realism of action boundaries.
- Physical plausibility and contact correctness: No metric checks for collisions, foot sliding, limb interpenetration, or contact consistency during attacks/hits. Add physics- and contact-aware metrics based on 3D states and collision proxies.
- Audio modality absence: Many game states and action cues are audio-correlated (e.g., hit confirmation, charged attacks). Consider adding synchronized audio and evaluating audio-visual consistency and control.
- Real-time interactivity and latency: The paper does not measure inference latency or closed-loop responsiveness. Provide a real-time benchmark setting with latency budgets and action-to-visual-lag measurements relevant to interactive applications.
- Closed-loop evaluation environment: The dataset supports offline evaluation only. Build an interactive playback/simulation harness (e.g., a lightweight engine or learned simulator) to test agents issuing actions and receiving model-generated observations in the loop.
- Robustness to camera conventions: The target-lock camera and spring-arm logic impose a specific viewpoint regime. Add splits with varied camera behaviors (free cam, first-person, static cams) and test model robustness to camera policy shifts.
- Safety and ethics considerations: The paper does not discuss the legal/ethical implications of releasing large-scale instrumented game footage and internal state streams. Clarify permissions, redistribution rights, and any constraints for commercial/research use.
Practical Applications
Immediate Applications
The paper’s dataset, benchmark, and reference models enable several deployable use cases today across gaming, software/AI, academia, and creator tooling.
- Gaming (production): Camera-following and virtual cinematography for in-engine capture
- Use case: Generate shots that follow designer-specified camera paths for trailers, cutscenes, and marketing capture while maintaining motion continuity.
- Tools/workflows: Fine-tune or use CamCtrl (camera-conditioned Wan2.2 variant); evaluate with ATE/RPE (via ViPE) and VBench; integrate camera trajectories from the game/editor into model inputs.
- Assumptions/dependencies: Access to model weights and WildWorld examples for fine-tuning; integration into Unreal/Unity or proprietary engine pipelines; GPU capacity for inference.
- Gaming (QA/DevOps): Automated regression tests for action responsiveness and motion consistency
- Use case: Detect gameplay regressions by comparing action execution in nightly builds against expected “Action Following” and “State Alignment” scores.
- Tools/workflows: WildBench metrics; scripted action segments; LLM-based action matching (Gemini 3 Flash prompts) and keypoint tracking (TAPNext); dashboards tracking ATE/RPE and pose accuracy.
- Assumptions/dependencies: Stable LLM/VLM APIs (Gemini/Qwen) or on-prem alternatives; test harnesses for repeatable action sequences; acceptance of automated judgments in QA pipelines.
- Gaming/Content creation: Skeleton-to-video generation for rapid previs and machinima
- Use case: Turn curated skeleton sequences into stylized videos for pitch, previs, or community content without full animation/VFX passes.
- Tools/workflows: SkelCtrl (skeleton-conditioned Wan2.2); render per-frame 3D skeletons to control videos; prompt-based style adjustments using hierarchical captions.
- Assumptions/dependencies: Brand/IP approvals for generated assets; compute for long clips; aesthetic trade-off (slightly lower AQ/IQ vs. state-conditioned).
- Software/AI tooling: Benchmarking interactive video models beyond generic perceptual scores
- Use case: Evaluate new world models with explicit “Action Following” and “State Alignment” to avoid VBench saturation and measure control fidelity.
- Tools/workflows: WildBench protocol; reproducible metrics code; curated 200-sample test set with diverse scenarios; ViPE for camera trajectory estimation.
- Assumptions/dependencies: Consistency of metric implementations across teams; cost of LLM/VLM-based scoring; repeatable seeds for generation.
- Data engineering for simulators: Multi-source, timestamped capture pattern for state–action–observation datasets
- Use case: Build WildWorld-like datasets in other engines (Unreal, Unity) or sims (driving, robotics) with synchronized RGB, depth, camera, actions, and states.
- Tools/workflows: OBS + Reshade multi-stream capture, JSON state logs with per-tick timestamps, filtering (continuity, luminance, occlusion), auto gameplay via behavior trees.
- Assumptions/dependencies: Engine access for instrumentation; performance headroom to run capture; encoder settings to balance storage and fidelity.
- Academia (courses and labs): Teaching modules on state-aware world models and evaluation
- Use case: Course assignments comparing latent-only vs. explicit-state conditioning; experiments on long-horizon consistency and autoregression errors.
- Tools/workflows: WildWorld subsets; reference models (CamCtrl/SkelCtrl/StateCtrl, StateCtrl-AR); ablations on state encoders/decoders and predictor losses.
- Assumptions/dependencies: Compute quotas for students; redistribution rights for dataset subsets; reproducible seeds and environments.
- XR demos and interaction prototyping: Prompt-switching combined with action control for interactive scenes
- Use case: Create demos where user actions and prompt changes steer an interactive scene with reliable camera control and visible state updates.
- Tools/workflows: Hierarchical action captions for prompt switching; CamCtrl/SkelCtrl for control; run-time gauges for Action Following to adjust UX.
- Assumptions/dependencies: Real-time constraints (latency, frame rate); simplified scenes or shorter clips to meet device capabilities.
- Creator tools (daily life for prosumers): Guided highlight/animation generation from action tags
- Use case: Auto-generate highlight reels or stylized replays based on recognized action segments (e.g., “knockdown,” “combo,” “dodge”).
- Tools/workflows: Action segment extraction; LLM-generated captions; camera-conditioned generation for dynamic cuts.
- Assumptions/dependencies: Consumer-grade GPUs or cloud access; acceptance of generative aesthetics; platform policies for derivative content.
Long-Term Applications
With further R&D, scaling, and domain adaptation, the paper’s state-aware approach and tooling can unlock broader applications across gaming, robotics, XR, healthcare, and policy.
- Gaming (live service): AI-native generative ARPG gameplay and “AI director”
- Use case: An AI director plans encounters, orchestrates cameras, and composes cutscenes in real time, conditioned on player actions and evolving world states.
- Tools/products: StateCtrl-AR integrated with engine state graphs; online state predictors with uncertainty estimates; editor plugins for “Action Following”/“State Alignment” gating.
- Assumptions/dependencies: Real-time inference at scale; robust guardrails for content safety/ratings; reliability under player unpredictability; production asset integration.
- Procedural content generation (PCG) for animations/VFX tied to semantics
- Use case: Generate or retarget attacks, evasions, and transitions from high-level action/state specs; auto-adapt effects to resource/health/weapon state.
- Tools/products: State-to-asset generators; skeleton-conditioned stylization; asset validation via pose/trajectory metrics.
- Assumptions/dependencies: Data coverage for long-tail actions; style/rig compatibility across characters; automatic QA with physical plausibility checks.
- Robotics and autonomy: Interactive world models for multi-agent planning and control
- Use case: Train agents with explicit state-conditioned video models that anticipate environment reactions to actions (e.g., tool use, human–robot interaction).
- Tools/workflows: Re-implement WildWorld pipeline in physics-grounded simulators (Isaac Gym, Habitat); evaluate with “Action Following” on affordance actions and “State Alignment” on task-relevant keypoints.
- Assumptions/dependencies: Domain gap from fantasy to real physics; richer physical states (contact forces, friction); sim-to-real transfer; safety validation.
- XR/Metaverse: Real-time state-aware agents and camera control for mixed reality
- Use case: Agents that act and respond to user inputs within AR scenes, maintaining camera and pose consistency over long interactions.
- Tools/products: Edge-deployable StateCtrl-AR; SLAM-informed camera conditioning; latency-aware schedulers that trade off look-ahead vs. responsiveness.
- Assumptions/dependencies: On-device acceleration; robust tracking in dynamic environments; privacy constraints for sensor data.
- Virtual production and previs: Automatic multi-character blocking and camera planning
- Use case: Generate previs with accurate blocking for multiple actors and evolving scene states; directors iterate via action/state edits rather than keyframing.
- Tools/products: Multi-entity state encoders; action libraries with hierarchical captions; evaluation gates for pose continuity and camera drift.
- Assumptions/dependencies: Integration with DCC tools (Unreal, Maya); acceptance of generative previs in studio workflows; IP and union considerations.
- Education and training simulators: Interactive labs with state-aware what-if experimentation
- Use case: Students manipulate actions/states to see long-horizon outcomes, studying error accumulation and stabilization strategies.
- Tools/workflows: Lightweight world models; visualization dashboards for state transitions; curriculum-aligned scenarios.
- Assumptions/dependencies: Cost-effective deployment for classrooms; accessible UIs; measured fidelity sufficient for pedagogical goals.
- Healthcare/biomechanics: Skeleton-conditioned visualization for rehab and coaching
- Use case: Personalized motion-to-video feedback that reflects intended pose changes and constraints, improving patient engagement and adherence.
- Tools/products: Human-skeleton analogs of SkelCtrl; clinician dashboards showing pose accuracy (State Alignment) over sessions.
- Assumptions/dependencies: Domain-specific datasets with human subjects; clinical validation; privacy and HIPAA/GDPR compliance.
- Safety and policy: Standards for certifying interactive generative systems
- Use case: Regulatory or industry standards that include “Action Following” and “State Alignment” as control-fidelity criteria for agentic media systems.
- Tools/workflows: Open benchmarks and reference implementations; audit trails linking actions to generated outcomes; threshold policies for deployment readiness.
- Assumptions/dependencies: Cross-industry consensus; open, reproducible test sets; mitigation strategies for LLM/VLM evaluation variability.
- Engine and middleware products: “World Model SDK” for state-conditioned generation
- Use case: A middleware plugin that ingests per-frame states/actions from engines and returns controlled generative video or camera paths with evaluation hooks.
- Tools/products: Standardized schemas for states (discrete/continuous), entity graphs, and timestamps; adapters for Unreal/Unity/custom engines.
- Assumptions/dependencies: Vendor buy-in; performance budgets; versioning and backward compatibility.
- Open data ecosystems: Domain-specific, state-annotated dataset hubs
- Use case: Community-curated datasets for sports, driving, household tasks, each with synchronized actions, states, camera, and depth for world modeling research.
- Tools/workflows: Reproducible capture pipelines; quality filters (continuity, occlusion); captioning with VLMs; license frameworks for synthetic data.
- Assumptions/dependencies: Legal clarity for engine- or content-derived data; funding for hosting/curation; governance to ensure diversity and fairness.
Notes on cross-cutting assumptions and feasibility:
- Licensing/IP: Using a commercial game as a data source may restrict redistribution and commercial use; similar datasets should be built in engines or sims where rights are clear.
- Compute and latency: Training on 108M frames and running 5B-parameter models can be resource-intensive; real-time applications depend on model compression/acceleration.
- Evaluation dependencies: Some metrics rely on proprietary LLM/VLMs (Gemini 3 Flash, Qwen3-VL); reproducibility may require open-source substitutes or cached judgments.
- Domain transfer: Applying methods to real-world domains requires additional physics-rich states, sensor models, and careful sim-to-real validation.
- Reliability and safety: Long-horizon, autoregressive control introduces drift; production systems need monitoring, fallback strategies, and human-in-the-loop controls.
Glossary
- Absolute Trajectory Error (ATE): A metric that measures the absolute deviation between an estimated camera trajectory and the ground-truth trajectory over time. "Absolute Trajectory Error (ATE) and Relative Pose Error (RPE) for both translation and rotation"
- Action Following: An evaluation metric that assesses whether generated videos reflect the intended input actions. "Action Following measures the agreement between generated videos and the ground-truth sub-actions."
- Action-conditioned dynamics: World or video dynamics that evolve based on input actions, used to model how actions drive future states or frames. "Recent video world models attempt to learn this action-conditioned dynamics from data."
- Aesthetic Quality (AQ): A perceptual metric estimating the artistic/visual appeal of generated video frames. "Aesthetic Quality (AQ) reflects the perceived artistic and visual appeal of the generated content"
- Autoregressive: A modeling approach that predicts the next element (e.g., state or frame) conditioned on previous predictions. "Using only the first-frame state and autoregressively predicting subsequent states as control inputs"
- B frames: Bidirectionally predicted frames in video codecs that reference both previous and future frames to improve compression efficiency. "we use the HEVC encoder with B frames enabled"
- Behavior trees: Hierarchical decision-making structures commonly used in game AI to choose actions based on conditions. "we leverage the behavior trees that drive NPC companions to fight autonomously"
- Compositional action sequences: Sequences formed by combining multiple primitive actions into longer, structured behaviors. "long-horizon compositional action sequences and their effects on evolving world states"
- DiT: Diffusion Transformer; a neural architecture combining diffusion models with transformer backbones for generative tasks. "injected into the intermediate layers of DiT as a conditioning signal"
- Dynamic Degree (DD): A metric that measures the amount of motion in generated videos to penalize overly static results. "Dynamic Degree (DD) measures the magnitude of motion to penalize overly static videos"
- Dynamical systems theory: A mathematical framework for modeling systems that evolve over time according to state transition rules. "Both dynamical systems theory and reinforcement learning"
- Heads-Up Display (HUD): The on-screen interface elements in games that display information like health or ammo. "We further remove the HUD by disabling the corresponding late stage shaders."
- HEVC: High Efficiency Video Coding (H.265), a video compression standard for high-quality, low-bitrate encoding. "RGB is recorded with lossy HEVC compression under variable bitrate control"
- Image Quality (IQ): A metric for low-level visual fidelity, assessing artifacts like noise, blur, and exposure. "Image Quality (IQ) evaluates low-level visual distortions, such as over-exposure, noise, and blur."
- Intrinsic and extrinsic camera parameters: Intrinsic parameters define the camera’s internal calibration; extrinsic parameters define its position and orientation in space. "the intrinsic and extrinsic parameters of the in-game camera"
- Joint-tree structure: The hierarchical connectivity of skeletal joints used to represent articulated bodies. "their joint-tree structure annotated in the WildWorld dataset"
- Latent variable: A hidden variable not directly observed but inferred from data, often used to represent underlying state. "represent the world state as an implicit latent variable learned from visual observations."
- Latent-state dynamical process: A model where an unobserved (latent) state evolves over time via action-driven transitions. "model the world as a latent-state dynamical process, where the environment evolves through state transitions driven by actions."
- Luma channel: The luminance component of a color space that encodes brightness, separate from color. "a simple filter based on the luma channel in YUV color space of the RGB frames"
- Motion Smoothness (MS): A metric assessing how physically plausible and smooth the motion is in generated videos. "Motion Smoothness (MS) assesses the smoothness and physical plausibility of generated motion;"
- Plücker embeddings: Representations based on Plücker coordinates that encode 3D lines (e.g., rays) for geometric conditioning. "computes Plücker embeddings for each frame"
- Relative Pose Error (RPE): A metric measuring inconsistency in relative motion between successive poses, sensitive to drift. "Relative Pose Error (RPE) for both translation and rotation"
- Skeletal keypoints: Specific joint locations (e.g., elbows, knees) used to represent and track articulated poses. "by tracking skeletal keypoints in the generated videos"
- Spring-arm: A third-person camera mechanism that adjusts the camera’s distance from the character to avoid occlusions. "using the spring-arm behavior of the third-person camera"
- State Alignment: An evaluation metric quantifying how well generated states (e.g., poses) match ground-truth state trajectories. "WildBench introduces two key evaluation metrics: Action Following and State Alignment."
- State-aware video generation: Video synthesis that conditions on explicit state representations, not just pixels or text. "we focus on state-aware video generation via action control"
- Structure from motion: A method to estimate 3D structure and camera trajectories from 2D video frames. "using a structure from motion model following CameraCtrl"
- Target-lock system: A gameplay camera mode that keeps a target (e.g., a monster) centered in the view during combat. "the game's native target-lock system"
- Variable bitrate control: Encoding strategy where the bitrate adapts to content complexity to balance quality and file size. "variable bitrate control"
- Vision-LLMs: Models jointly trained on visual and textual data to understand and reason across modalities. "large vision-LLMs"
- YUV color space: A color representation that separates luminance (Y) from chrominance (U and V) components. "YUV color space"
Collections
Sign up for free to add this paper to one or more collections.