Learning Latent Action World Models In The Wild
Abstract: Agents capable of reasoning and planning in the real world require the ability of predicting the consequences of their actions. While world models possess this capability, they most often require action labels, that can be complex to obtain at scale. This motivates the learning of latent action models, that can learn an action space from videos alone. Our work addresses the problem of learning latent actions world models on in-the-wild videos, expanding the scope of existing works that focus on simple robotics simulations, video games, or manipulation data. While this allows us to capture richer actions, it also introduces challenges stemming from the video diversity, such as environmental noise, or the lack of a common embodiment across videos. To address some of the challenges, we discuss properties that actions should follow as well as relevant architectural choices and evaluations. We find that continuous, but constrained, latent actions are able to capture the complexity of actions from in-the-wild videos, something that the common vector quantization does not. We for example find that changes in the environment coming from agents, such as humans entering the room, can be transferred across videos. This highlights the capability of learning actions that are specific to in-the-wild videos. In the absence of a common embodiment across videos, we are mainly able to learn latent actions that become localized in space, relative to the camera. Nonetheless, we are able to train a controller that maps known actions to latent ones, allowing us to use latent actions as a universal interface and solve planning tasks with our world model with similar performance as action-conditioned baselines. Our analyses and experiments provide a step towards scaling latent action models to the real world.
















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computers to understand and predict what will happen next in videos, especially when different people, cameras, and objects are moving around in everyday situations. The twist: the computer doesn’t know the “actions” (like “turn left” or “pick up cup”) ahead of time. Instead, it learns a hidden action language on its own from lots of online videos. The goal is to use this learned action space to plan and control things—like robots or navigation—without needing carefully labeled action data.
What questions did they ask?
The researchers wanted to answer a few big questions in simple terms:
- Can a computer learn a useful “action space” just by watching many ordinary videos, even without labels?
- What kind of hidden actions does it learn—do they describe meaningful changes, like walking into a room or the camera moving?
- How should we design these hidden actions so they don’t “cheat” by copying the whole next frame, but still carry enough information to make good predictions?
- Can these learned actions be reused as a universal control interface to solve real tasks (like robot manipulation or navigation)?
- Does scaling up (more data, bigger models, longer training) help?
How did they study it?
Think of the computer as building a “world model,” like a smart simulator that guesses the next scene in a video based on what it just saw and the action that caused the change.
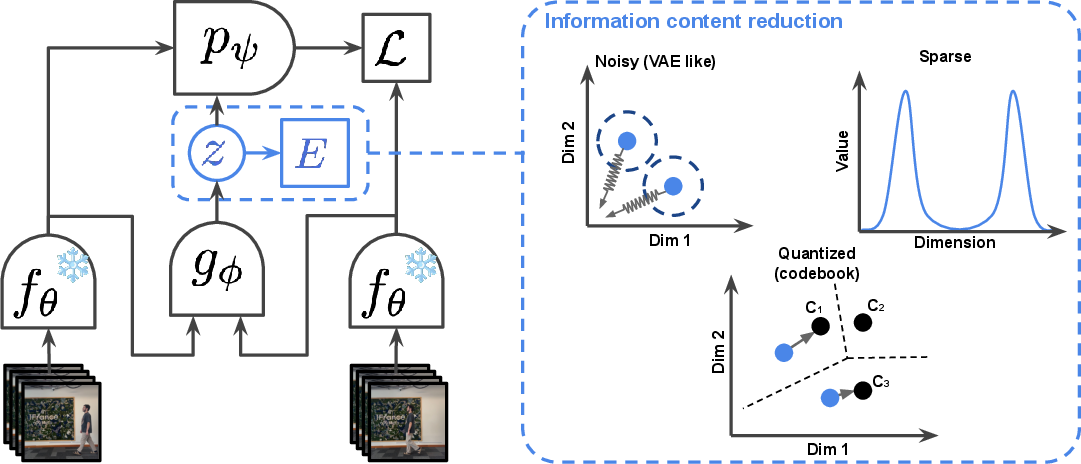
Learning actions without labels
They train two parts together:
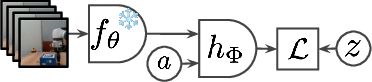
- An inverse dynamics model (IDM): This is like a detective. It looks at the “before” and “after” frames and tries to figure out the “action” that explains the change between them. The action it outputs is “latent,” meaning it’s a hidden code rather than a known label like “move left.”
- A forward model (world model): This is the predictor. It takes the current state and the latent action and tries to predict the next state (the next video frame in a learned representation space).
Analogy: Imagine watching two photos—one of an empty room and one taken a second later with a person stepping in. The detective (IDM) invents a hidden action like “person enters from the right,” and the predictor uses that hidden action to generate the next scene.
Keeping actions “small” and honest
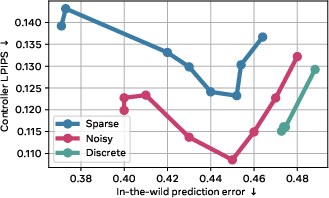
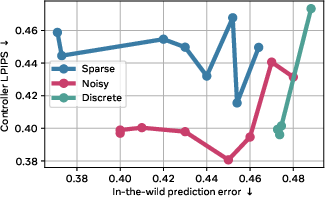
If the hidden action carried too much information, it could “cheat” by simply including the whole next frame and make prediction trivial. To prevent that, they tried three ways to reduce or constrain what the latent action can carry:
- Sparsity: Encourage actions to be simple and use only a few important numbers. Like writing a short note instead of an essay.
- Noise addition: Add a bit of randomness and push the action to look like a simple, standard shape. This makes it harder to pack too much detail in the action.
- Discretization: Force actions to pick from a fixed set of “codes” (like a limited menu of action tokens). This is common in other systems but can be less flexible.
Training and data
They used large, natural “in-the-wild” video collections (such as YouTube-style clips) with lots of variety: different places, people, and camera viewpoints. They learned in a representation space built by a strong vision encoder, then trained the world model and IDM to predict future representations rather than raw pixels. Later, they trained a small “controller” that maps known actions (from robotics or navigation datasets) into the latent action space, so they could test planning.
What did they find?
Here are the main results in simple terms:
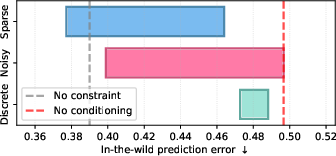
- Continuous but constrained actions work best: The flexible, continuous actions (when made sparse or slightly noisy) captured rich changes in videos—like someone entering a room or objects moving—better than discretized actions. Discrete actions struggled with the complexity of everyday scenes.
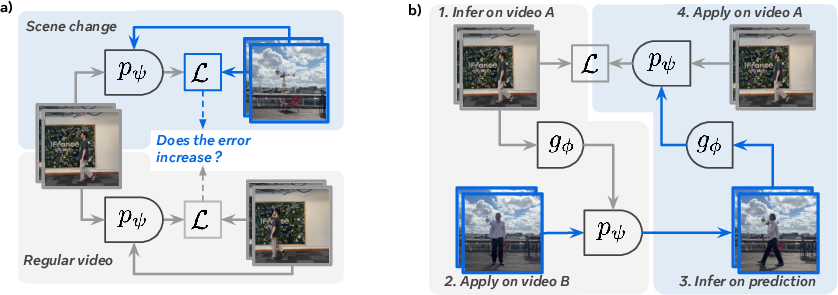
- No cheating: When they tested sudden scene changes (like stitching two different videos together), the models’ errors jumped a lot, which shows the actions weren’t secretly copying the whole next frame. That’s good—it means the action codes really represent causes, not just the answers.
- Transfer across videos: Actions learned from one video could be applied to another. For example, motion inferred from a person walking could be transferred to a flying ball, making it move left. That shows the learned actions generalize beyond a single scenario.
- Camera-relative and localized: Because everyday videos don’t share a common robot body or controller, the actions the model learned tend to be “where and how things move” relative to the camera’s view. They are spatially localized (affecting the area where motion happens) and camera-relative, which helps transfer across many scenes.
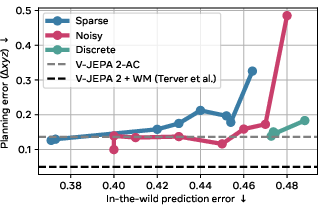
- Universal control via a small controller: By training a small module that maps real actions (like robot commands or navigation steps) to latent actions, they could use the world model for planning. Performance was similar to baselines that had direct access to labeled actions, which is impressive given their model learned only from unlabeled natural videos.
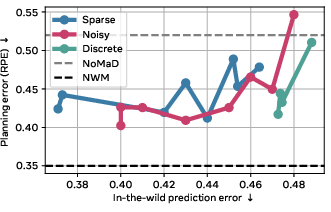
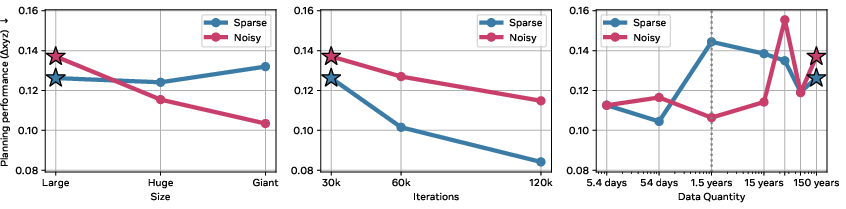
- Capacity sweet spot: Too little latent capacity, and actions don’t carry enough information; too much, and they become harder to identify and control. The best planning often came from a middle ground—actions that are informative but not overloaded.
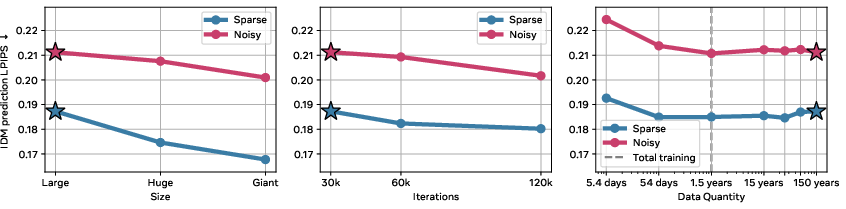
- Scaling helps in a nuanced way: Bigger models, more data, and longer training improved the raw prediction quality. For planning tasks, the biggest win came from training longer, while bigger models and more data helped but not always dramatically.
Why this matters
This work shows a promising path toward world models that learn a general “action language” just by watching videos, without needing costly labels or a single shared robot body. That could make it much easier to build AI systems that plan and act in many environments:
- Cheaper and broader learning: No need for large, carefully labeled datasets for every domain.
- Reusable action interface: The learned latent actions can act like a universal remote. With a small controller, different embodiments (robots, camera navigation) can plug in and use the same world model.
- Better transfer: Since actions are camera-relative and localized, they apply across a wide range of scenes and objects, not just one setup.
Key terms, explained simply
- World model: A system that predicts what will happen next, like a smart simulator for the future.
- Latent action: A hidden code the model invents to describe “what caused the change” between two moments, instead of using human-labeled actions.
- Inverse dynamics model (IDM): The “detective” that looks at before/after and infers the latent action.
- Forward model: The “predictor” that uses the current state plus the latent action to produce the next state.
- Regularization: Ways to keep the latent action simple and honest, so it doesn’t encode too much. Here: sparsity, noise, and discretization.
- Camera-relative, localized actions: Actions that describe how things move in the camera’s view, affecting specific parts of the scene.
Implications and potential impact
If we can learn a general, transferable action space from ordinary videos, we can:
- Reduce dependence on labeled action datasets.
- Build world models that apply across many domains, even when embodiments differ.
- Enable planning and control in robotic tasks or navigation using a shared, learned interface.
- Scale up naturally as more in-the-wild video data becomes available.
Future improvements could include adjusting how much information the latent action carries depending on the scene’s complexity, and planning directly in the latent action space. Overall, this work takes a solid step toward making AI that can watch, understand, and plan in the diverse, messy real world.
Knowledge Gaps
Below is a consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Lack of a principled, testable definition of “action” in in-the-wild videos and corresponding evaluation protocols; develop semantics, disentanglement metrics, mutual information with known controls, and causal intervention tests to validate what latents represent.
- Discrete latent actions are concluded to “struggle,” but the exploration is limited; systematically ablate codebook size/usage, commitment losses, temperature, hierarchical or hybrid discrete–continuous designs, and event-token formulations to fairly assess discrete alternatives.
- Information regularization is globally static; design adaptive, per-sample/per-timestep regularizers (e.g., learned or uncertainty-aware / schedules, curriculum/gating) that tune capacity to action complexity.
- Leakage diagnostics rely on synthetic scene cuts; add stronger tests (e.g., mutual information estimates I(z; s_{t+1}), conditional independence checks, next-frame decoders/classifiers) to quantify and bound future leakage more rigorously.
- Transfer evaluation via cycle consistency is weakly grounded; build standardized, object-centric transfer benchmarks with controlled category/viewpoint/occlusion shifts and metrics based on optical-flow alignment and tracked object displacement.
- Latent actions are camera-relative and spatially localized; develop self-supervised methods to learn agent-centric or object-centric action coordinates (e.g., segmentation/tracking, pose estimation, monocular 3D) to improve downstream control across embodiments.
- The controller collapses when trained on actions-only; investigate architectures/objectives that enable action-only control (e.g., egomotion/camera extrinsics estimators, state observers) and quantify generalization across unseen cameras and robot platforms.
- Planning evaluation is short-horizon (H=3), offline, and limited; test longer horizons, closed-loop MPC, real robot deployments with safety constraints, contact-rich manipulation, and dynamic-scene navigation tasks.
- The forward model is deterministic, teacher-forced, and trained atop frozen V-JEPA 2-L representations; study end-to-end co-training, scheduled sampling, multi-step losses, and stochastic/diffusion forward models to reduce exposure bias and capture multi-modal futures.
- Metrics focus on L1/LPIPS in representation/pixel space; introduce action-aware metrics (e.g., flow-consistency, object/hand trajectory error, 3D pose/trajectory error) and human evaluations of semantic correctness.
- Temporal abstraction is not explored; investigate hierarchical latents (options/macro-actions), variable-duration/event-driven actions, and sensitivity to context window/history length.
- Scaling analysis shows weak coupling between IDM gains and planning; identify bottlenecks (encoder vs IDM vs forward model vs controller), derive scaling laws for planning performance, and perform causal ablations to attribute gains.
- Robustness to distractors/environmental noise is asserted but unquantified; create controlled stress tests (background motion, flicker, clutter) to measure whether latents ignore or encode distractors.
- Multi-agent disentanglement is untested; evaluate the ability to separate simultaneous actions across entities, assign latents to distinct actors, and perform targeted interventions.
- Frame duplication was needed to align action rate and latent conditioning during rollouts; develop principled alignment (continuous-time models, variable-rate conditioning, event-driven latents) that removes this mismatch.
- Interpretability/compositionality of latents is not analyzed; train linear/nonlinear probes to map latents to control primitives (translations/rotations, grasp/open), test linearity/composition, and explore language grounding to enable instruction-conditioned control.
- Cross-domain universality of the interface is only shown for DROID/RECON; evaluate zero-shot transfer and a single universal controller across varied embodiments (manipulation, locomotion, aerial), and study curricula mixing in-domain data with in-the-wild videos.
- Geometry/viewpoint invariance is not modeled explicitly; incorporate 3D scene representations, depth/pose estimation, and camera calibration to normalize actions across viewpoints and improve transfer/consistency.
- Counterfactual validity of latent actions (do they correspond to causal interventions) remains unestablished; use controlled datasets with manipulable factors to test counterfactual predictions under latent interventions.
- Planning directly in latent action space is not implemented; build samplers/optimizers over z_t (with constraints and priors), compare to controller-based planning, and assess efficiency, success rates, and robustness.
- Appearance drift during long rollouts is noted qualitatively; quantify drift and investigate consistency losses, recurrent architectures, stronger video decoders, and augmentation strategies to stabilize long-horizon predictions.
Glossary
- AdaLN-zero: A conditioning mechanism that adapts layer normalization with zero-initialized scales/shifts to inject conditioning signals into a model. "To condition on we use AdaLN-zero~\citep{peebles2023scalable} that we adapt to condition the sequence frame-wise."
- AdamW: An optimizer that decouples weight decay from gradient-based updates to improve generalization. "and AdamW~\citep{loshchilov2018adamw} learning rate of "
- Amortized inference: Learning a network to approximate inference over latent variables, avoiding per-instance optimization at test time. "we can see the IDM as performing amortized inference~\citep{amos2023tutorial}."
- Causal leakage: Unintended flow of future information into variables meant to represent causes (e.g., actions), which can lead to cheating in predictive models. "This introduces a causal leakage in information and a key challenge is to ensure that the latent actions do not capture too much information"
- Codebook: A set of discrete prototype vectors used for vector quantization of continuous representations. "as well as codebook reset for unused codes."
- Codebook reset: Re-initializing or replacing unused entries in a vector-quantization codebook to maintain effective capacity. "as well as codebook reset for unused codes."
- Continuous latent actions: Real-valued action representations learned from data, typically regularized to control information capacity. "We find that continuous, but constrained, latent actions are able to capture the complexity of actions from in-the-wild videos"
- Controller: A learned module that maps known (embodied) actions and context to latent action codes to drive the world model. "we are able to train a controller that maps known actions to latent ones"
- Cosine annealing: A learning-rate schedule that decreases the rate following a cosine curve over training. "following a linear warmup over 10\% of the training followed by cosine annealing."
- Cross-attention: An attention mechanism that conditions one sequence on another, often used to fuse actions with visual context. "we use a cross-attention based adapter."
- Cross-Entropy Method (CEM): A stochastic optimization algorithm used for planning by iteratively sampling and refitting action distributions. "We plan at a horizon of steps using the Cross-Entropy Method (CEM)~\citep{rubinstein1997cem}"
- cycle-consistent: A property where applying inferred transformations to another sequence and re-inferencing recovers the original transformations. "To measure the transferability of latent actions, we measure if they inference is cycle-consistent."
- Diffusion based world models: World models that represent future uncertainty via diffusion processes. "This is reminiscent of diffusion based world models~\citep{alonso2024diffusion,bar2024navigation} for example."
- ego-/exo-centric actions: Actions defined relative to the camera wearer (ego) or external agents/objects in the scene (exo). "From then we can have a split between ego- and exo-centric actions, which separates actions of the camera wearer and other agents in the environment."
- Embodiment: The physical form or control interface of an agent, which defines its action space. "the lack of a common embodiment across videos."
- Embodiment token: A token indicating the agent type/body, enabling a shared action interface across different embodiments. "with an embodiment token~\citep{hansen2023td}"
- Exogenous noise: Variability in observations arising from external, uncontrollable factors rather than agent actions. "without capturing exogenous noise that may come from the environment."
- Forward model: A predictive model that estimates the next state from past states and (latent) actions. "a forward model which predicts the future using the past and obtained latent action."
- Future leakage: A failure mode where future information is inadvertently encoded in latent variables meant to represent actions. "Future leakage."
- In-the-wild videos: Uncurated, diverse real-world video data lacking action labels and consistent embodiments. "to demonstrate the viability of LAM on large scale in-the-wild natural videos"
- Inverse dynamics model (IDM): A model that infers latent actions from pairs of past and future observations. "an inverse dynamics model (IDM) that, given observations of the past and future, predicts a latent action that explains the difference between the two."
- Kullback–Leibler (KL) divergence: A measure of divergence between probability distributions, often used to regularize latent variables. ""
- Latent action model (LAM): A framework that learns an action space from unlabeled videos via inverse and forward dynamics. "This gap motivates the idea of learning a latent action model (LAM)~\citep{bruce2024genie,schmidt_actw-without-actions_2024,ye_lapa_2025,yang2025como,chen_igor_2024,cui_dynamo_2024}"
- Latent actions: Compact variables representing actions inferred from video pairs, used to condition predictions. "These latent actions are obtained thanks to an inverse dynamics model trained jointly with the world model."
- Linear warmup: A learning-rate schedule that increases the rate linearly at the start of training. "following a linear warmup over 10\% of the training"
- LPIPS: A learned perceptual metric evaluating image similarity that correlates with human judgment. "We report LPIPS values for ease of interpretation."
- Muon optimizer: An optimization algorithm used for training neural networks. "We use the Muon optimizer~\citep{jordan2024muon} with a learning rate of 0.02"
- Perceptual loss: A loss computed in a deep feature space (rather than pixels) to encourage perceptual fidelity. "trained with a combination of and perceptual loss~\citep{johnson2016perceptual,zhang2018unreasonable}."
- Positional embeddings: Encodings that inject position information into sequence models. "using RoPE~\citep{su2021rope,assran2025vjepa2} for positional embeddings."
- Quantized representations: Discrete representations obtained by mapping continuous vectors to codebook entries. "Another way to model uncertainty is to not consider directly, but instead output a distribution over possible futures , as is commonly done in text~\citep{radford2018gpt} or with quantized representations~\citep{hu2023gaia1,agarwal2025cosmos}."
- Relative Pose Error (RPE): A metric comparing relative motion between planned and ground-truth trajectories. "We rely on the Relative Pose Error (RPE)~\citep{sturm2012evaluating} between planned and groundtruth trajectories as our main metric."
- RoPE: Rotary Position Embeddings, a method for encoding positions in attention-based models. "using RoPE~\citep{su2021rope,assran2025vjepa2} for positional embeddings."
- Sparsity-based constraints: Regularization encouraging many components of latent vectors to be zero, controlling information content. "Sparsity. The first one, and perhaps most complex to implement, is sparsity based constraints~\citep{drozdov2024video}."
- Teacher forcing: A training technique where ground-truth previous outputs are fed to the model instead of its own predictions. "we train the model using teacher forcing~\citep{williams1989learning,vaswani2017attention}."
- Variance-Covariance-Mean (VCM) regularization: A constraint controlling variance, covariance, and mean of latents to prevent collapse and distribute information. "This Variance-Covariance-Mean (VCM) regularization, inspired by VICReg~\citep{bardes2021vicreg}, ensures an adequate spread of information and forces the sparsity constraints to be properly used by the model."
- Variational Autoencoder (VAE): A generative model framework with a probabilistic encoder/decoder, often used with KL regularization. "This can be implemented in a similar way as a VAE~\citep{kingma_auto-encoding_2014,gao2025adaworld}."
- Vector quantization: Mapping continuous vectors to discrete codebook entries during training/inference. "the most common approach is vector quantization~\citep{van2017vqvae} or a variant of it."
- VICReg: A self-supervised objective encouraging invariance while controlling variance and covariance to avoid collapse. "inspired by VICReg~\citep{bardes2021vicreg}"
- Vision Transformer (ViT): A transformer architecture applied to images/videos. "By default, is implemented as a ViT-L~\citep{dosovitskiy2021vit}"
- V-JEPA 2-L: A specific pretrained video encoder model used to produce frame representations. "A video of length is encoded through a frame causal encoder --V-JEPA 2-L~\citep{assran2025vjepa2} in our experiments--"
- Weight decay: L2-style regularization applied to weights to reduce overfitting. "We use 0.04 as weight decay."
- World model: A model that predicts future states of the world, often conditioned on actions. "A classical world model is endowed with actions represented as latent variables."
Practical Applications
Overview
The paper introduces a practical recipe for learning latent action world models (LAMs) directly from large-scale, in-the-wild video—without action labels—by jointly training an inverse dynamics model (IDM) and a forward world model over frozen visual representations. Key findings with immediate implications are: (1) continuous but constrained latent actions (via sparsity or noise) capture complex, real-world actions better than discrete/vector-quantized actions; (2) learned latent actions are spatially localized and camera-relative, enabling motion transfer across videos; and (3) a lightweight controller can map known action spaces to the learned latent actions, enabling planning in manipulation and navigation tasks at performance close to action-conditioned baselines. The authors also provide actionable evaluation protocols (scene-cut leakage and cycle-consistency) and scaling analyses.
Below are concrete applications organized by deployment horizon.
Immediate Applications
These are deployable with today’s tooling and the methods demonstrated in the paper.
- Bold-start Pretraining world models for robotics with unlabeled video
- Description: Use large amounts of public, unlabeled video to pretrain an action-aware world model, then train a small controller to map robot actions to the latent action space for planning (e.g., CEM-based goal-reaching).
- Sectors: Robotics (manipulation, mobile navigation), Industrial automation, R&D labs
- Tools/products/workflows:
- LAM pretrain → Controller adapter (MLP or cross-attention) → CEM planner with representation-space costs
- Reuse frozen encoders (e.g., V-JEPA 2) and adopt sparsity/noise-regularized continuous latents
- Minimal action-labeled data required only for controller training in the target embodiment
- Assumptions/dependencies:
- Access to large-scale in-the-wild video and compute (batch ≥ 1k, long training)
- Controller requires some action-labeled samples in the target domain
- Camera-relative latents necessitate using past representations as controller inputs
- Bold-start Bootstrapping navigation models from egocentric video
- Description: Train LAMs on egocentric data (e.g., RECON) and learn controllers to map navigation actions to latents; plan trajectories via CEM using representation-space goals.
- Sectors: Drones, AR/VR navigation aids, Mobile robotics
- Tools/products/workflows:
- Egocentric LAM pretraining → egocentric controller mapping (v, ω) → CEM over short horizons
- Relative Pose Error (RPE) for evaluation; rollouts to validate controller fidelity
- Assumptions/dependencies:
- Planning performance depends on latent capacity balance (not too constrained, not too free)
- Requires calibrated camera and consistent sensor stack between training and deployment
- Bold-start Action-aware video indexing and retrieval
- Description: Index videos using camera-relative, spatially localized latent actions (e.g., “entity enters frame,” “leftward motion”), not just appearance or text.
- Sectors: Media platforms, Enterprise video analytics, Sports tech
- Tools/products/workflows:
- Batch-infer latent action trajectories; build search keys over motion primitives and locality
- Use cycle-consistency to select latents that transfer reliably across contexts
- Assumptions/dependencies:
- Latent actions are not semantically labeled; may require weak supervision to attach ontology
- Quality depends on the encoder domain match to the video catalog
- Bold-start VFX prototyping: motion transfer between videos
- Description: Transfer motion from a source clip to a target clip using inferred latents; useful for concepting and previsualization.
- Sectors: Creative tools, Advertising, Post-production
- Tools/products/workflows:
- IDM inference on source → apply latents to target → visualize with a lightweight decoder
- Assumptions/dependencies:
- Visual fidelity of the provided decoder is for inspection; production requires a high-quality generator
- Best for coarse motion/layout changes, not fine appearance edits
- Bold-start Video QA and model selection using leakage and transfer diagnostics
- Description: Use the paper’s “scene-cut leakage” and “cycle-consistency” tests to pick regularization settings (sparse/noisy) that balance capacity and identifiability.
- Sectors: ML platform teams, Academia
- Tools/products/workflows:
- Integrate diagnostics in training pipelines to detect cheating (future leakage) and measure transferability
- Assumptions/dependencies:
- Requires stitched-video construction for leakage tests and consistent metrics (LPIPS or learned feature distances)
- Bold-start Data efficiency: augment domain-specific datasets with in-the-wild pretraining
- Description: Improve planning with minimal domain-labeled data by first pretraining LAMs on diverse videos, then training small embodiment-specific controllers.
- Sectors: Robotics, Autonomous systems, Edge AI
- Tools/products/workflows:
- Pretrain once; reuse across embodiments via new controllers; standardize controller training scripts
- Assumptions/dependencies:
- Domain gap exists; controller quality and representation alignment matter
- Planning performance is not perfectly correlated with rollout visual quality
- Bold-start Benchmarking and curricula for academic research
- Description: Adopt the paper’s evaluation suite (IDM unrolling, capacity vs. planning trade-offs, scaling curves) as open benchmarks to compare LAM variants.
- Sectors: Academia, Open-source ML
- Tools/products/workflows:
- Reproducible pipelines for: latent capacity sweeps, controller training, CEM planning, transfer tests
- Assumptions/dependencies:
- Access to standard datasets (Kinetics, RECON, DROID) and encoders (V-JEPA 2-L)
Long-Term Applications
These require further research, scaling, integration, or safety validation.
- Bold-start Universal action interface across embodiments
- Description: A shared latent action space that controls many agents (hands, mobile bases, drones, cameras) via thin controllers, enabling cross-domain transfer.
- Sectors: General-purpose robotics, Logistics, Consumer robotics
- Tools/products/workflows:
- Multi-embodiment controller library; auto-calibration of camera-relative → embodiment-relative mappings
- Assumptions/dependencies:
- Requires improved disentanglement of agent vs. environment actions and robust multi-embodiment training
- Bold-start Action-conditioned video generation without text supervision
- Description: Control high-fidelity video generators using latent actions learned from in-the-wild videos (reducing dependence on text-video pairs).
- Sectors: Media generation, Simulation
- Tools/products/workflows:
- LAM + diffusion/AR video generator; “action track” control timeline for editors
- Assumptions/dependencies:
- Needs strong generative decoders; evaluation standards for action faithfulness and safety
- Bold-start Learning by watching: robot skills from HowTo videos
- Description: Map latent actions inferred from instructional videos to robot controllers to acquire manipulation primitives (grasp, pour, fold).
- Sectors: Service robotics, Warehousing, Domestic assistance
- Tools/products/workflows:
- Video-to-latent alignment + teleoperation or kinesthetic demos to anchor the controller
- Assumptions/dependencies:
- Embodiment mismatch and camera-relative bias must be addressed; requires 3D geometry grounding and safety
- Bold-start Autonomous driving foresight from unlabeled dashcams
- Description: Pretrain world models on large dashcam corpora; learn controllers from limited action-logged data; plan with LAMs for closed-loop forecasting.
- Sectors: Automotive, ADAS
- Tools/products/workflows:
- LAM pretraining on diverse traffic; policy/controller finetuning; risk-aware planning
- Assumptions/dependencies:
- Safety-critical validation; multi-agent and map priors; regulatory approval
- Bold-start AR/VR predictive assistance and intent-aware interfaces
- Description: Predict near-future egocentric changes (e.g., object entry, user head motion) to stabilize views, prefetch content, or guide user tasks.
- Sectors: AR/VR, Wearables
- Tools/products/workflows:
- On-device LAM inference; latency-aware controllers; UI hooks for anticipatory guidance
- Assumptions/dependencies:
- Model compression; privacy-preserving on-device inference; robustness to rapid motion
- Bold-start Safety analytics and hazard anticipation in video streams
- Description: Detect actionful events (e.g., a person entering a restricted area) by modeling agent-induced changes distinct from background noise.
- Sectors: Occupational safety, Smart infrastructure
- Tools/products/workflows:
- Latent-change detectors; alerting with spatiotemporal localization; privacy-first deployment
- Assumptions/dependencies:
- Ethical use and compliance; domain adaptation; minimizing false alarms
- Bold-start Multi-agent simulation and planning from internet-scale priors
- Description: Use LAM world models to simulate plausible agent behaviors in complex environments without task-specific labels.
- Sectors: Urban planning, Gaming/AI agents, Defense training
- Tools/products/workflows:
- Scenario generation via latent sampling; planners operating in latent action space
- Assumptions/dependencies:
- Sampling/planning directly in latent space needs more research; controllability and calibration
- Bold-start Healthcare rehab coaching and skill assessment from video
- Description: Model motion patterns from rehab/exercise videos; provide patient guidance by transferring exemplar motions at a high level.
- Sectors: Digital health, Tele-rehab
- Tools/products/workflows:
- Patient video capture → latent action comparison → feedback loop; clinician dashboards
- Assumptions/dependencies:
- Clinical validation; personalization; privacy and regulatory compliance (HIPAA/GDPR)
- Bold-start Standards and policy for training on public in-the-wild video
- Description: Establish governance for dataset licensing, privacy, and safety validation of models trained on public video at scale.
- Sectors: Public policy, Legal/compliance
- Tools/products/workflows:
- Documentation standards (data sheets, model cards), opt-out mechanisms, evaluation protocols (leakage, transfer, robustness)
- Assumptions/dependencies:
- Cross-industry coordination; clear legal frameworks for web-scale video usage
- Bold-start Edge deployment and compression of LAM pipelines
- Description: Run LAM inference and controller planning on-device (robots, drones, AR glasses).
- Sectors: Edge AI, Consumer electronics
- Tools/products/workflows:
- Distillation/quantization of encoders and world models; streaming-friendly architectures
- Assumptions/dependencies:
- Performance/energy trade-offs; graceful degradation under bandwidth and compute limits
Cross-cutting assumptions and dependencies
- Continuous constrained latents (sparse/noisy) outperform discrete VQ for complex, in-the-wild actions; selecting the right capacity is task-dependent.
- Latent actions are camera-relative and spatially localized; controllers typically need past representations as input to disambiguate pose/context.
- Planning performance may not correlate monotonically with rollout visual quality; measure task metrics (e.g., RPE, goal distance).
- Legal/ethical constraints apply when training on public video (licensing, privacy, bias); safety-critical deployments require rigorous validation.
- Compute and data scale matter; longer training often helps more than merely scaling model width; availability of robust frozen encoders (e.g., V-JEPA 2) is assumed.
Collections
Sign up for free to add this paper to one or more collections.