UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
Abstract: While specialized AI models excel at isolated video tasks like generation or understanding, real-world applications demand complex, iterative workflows that combine these capabilities. To bridge this gap, we introduce UniVA, an open-source, omni-capable multi-agent framework for next-generation video generalists that unifies video understanding, segmentation, editing, and generation into cohesive workflows. UniVA employs a Plan-and-Act dual-agent architecture that drives a highly automated and proactive workflow: a planner agent interprets user intentions and decomposes them into structured video-processing steps, while executor agents execute these through modular, MCP-based tool servers (for analysis, generation, editing, tracking, etc.). Through a hierarchical multi-level memory (global knowledge, task context, and user-specific preferences), UniVA sustains long-horizon reasoning, contextual continuity, and inter-agent communication, enabling interactive and self-reflective video creation with full traceability. This design enables iterative and any-conditioned video workflows (e.g., text/image/video-conditioned generation $\rightarrow$ multi-round editing $\rightarrow$ object segmentation $\rightarrow$ compositional synthesis) that were previously cumbersome to achieve with single-purpose models or monolithic video-LLMs. We also introduce UniVA-Bench, a benchmark suite of multi-step video tasks spanning understanding, editing, segmentation, and generation, to rigorously evaluate such agentic video systems. Both UniVA and UniVA-Bench are fully open-sourced, aiming to catalyze research on interactive, agentic, and general-purpose video intelligence for the next generation of multimodal AI systems. (https://univa.online/)













Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (overview)
This paper introduces UniVA, a smart, open‑source “video assistant” that can do many video tasks together—like understanding a video, cutting and editing it, separating objects, and even creating new videos from text or images. Instead of using lots of separate tools that don’t talk to each other, UniVA plans and runs the whole process like a movie director working with a crew.
It also comes with UniVA‑Bench, a new test set to fairly measure how well such an assistant plans, remembers, and completes multi‑step video projects.
What the researchers wanted to achieve (objectives)
Put simply, they asked:
- Can we build one system that understands, edits, and generates videos in a single, smooth workflow?
- Can the system plan multi‑step jobs (like “make a cartoon of my dog, change the background, add music”) without a human stitching tools together?
- Can it remember important details across long tasks (like a character’s look or a user’s favorite style)?
- How do we measure not just the final video quality, but also the agent’s planning, tool use, and memory?
How UniVA works (methods, in everyday language)
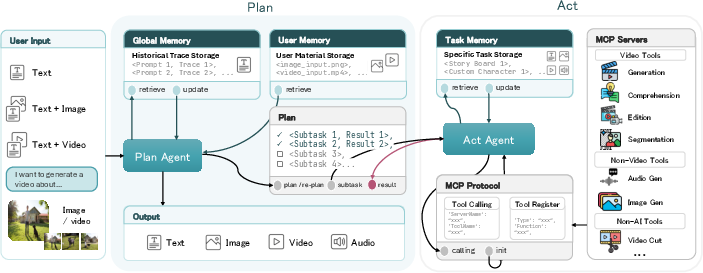
Think of UniVA like a two‑person team with a shared notebook and a huge toolbox:
- The Planner (the “director”) reads your request, breaks it into steps, and decides the order: for example, “find the dog → make it cartoon‑style → change the background → add music.”
- The Actor (the “crew”) carries out each step by picking the right tool and feeding it the right inputs.
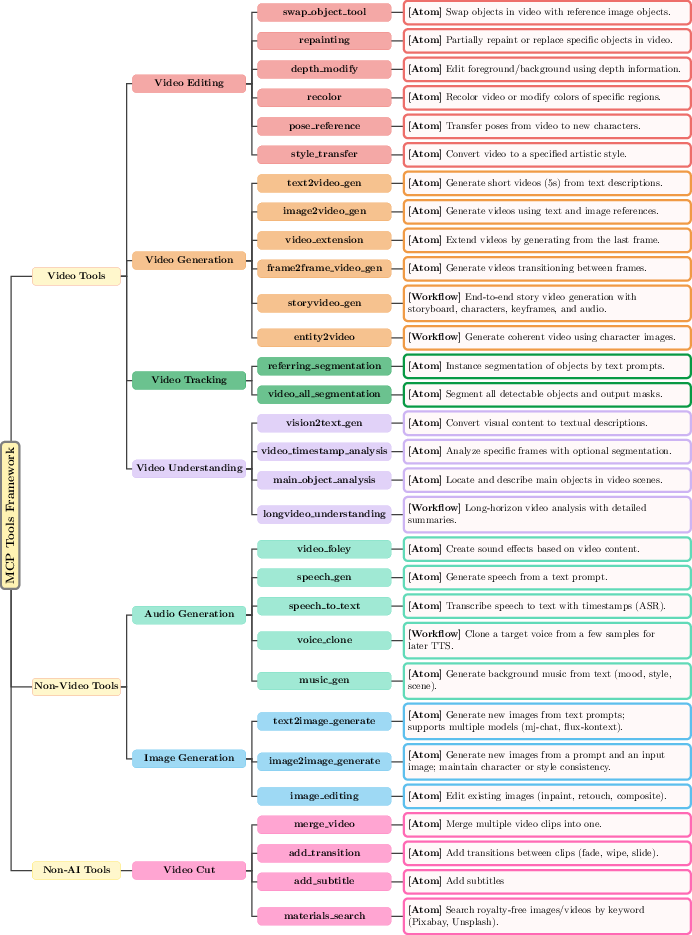
They connect to many specialized tools through something called MCP (Model Context Protocol). You can think of MCP like a universal plug that lets UniVA easily add or swap tools—video generators, editors, segmenters, audio tools, and more—without rebuilding the whole system.
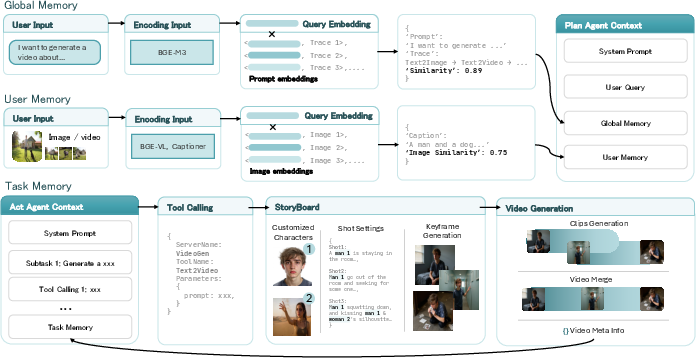
To handle long, complex tasks, UniVA uses three kinds of memory. These are like notes it keeps so it doesn’t forget what it’s doing:
- Global memory: general knowledge and past good examples the system can learn from.
- Task memory: everything about the current job—intermediate results, masks, storyboards, tool outputs—so later steps can reuse earlier work.
- User memory: your preferences (like favorite styles or resolutions) and references (like photos of your dog), so it stays consistent over time.
Under the hood, UniVA treats video creation like following a to‑do list with checkpoints. It decides a sequence of actions, runs them, checks the results, and updates its plan if needed. The team also built a web app so users can chat with UniVA while seeing changes on a timeline, just like a real editor.
What they found (main results and why they matter)
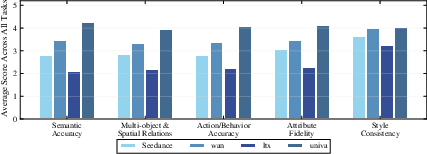
UniVA shows clear advantages over single‑purpose models and “one big model” approaches, especially on multi‑step, long projects.
Highlights:
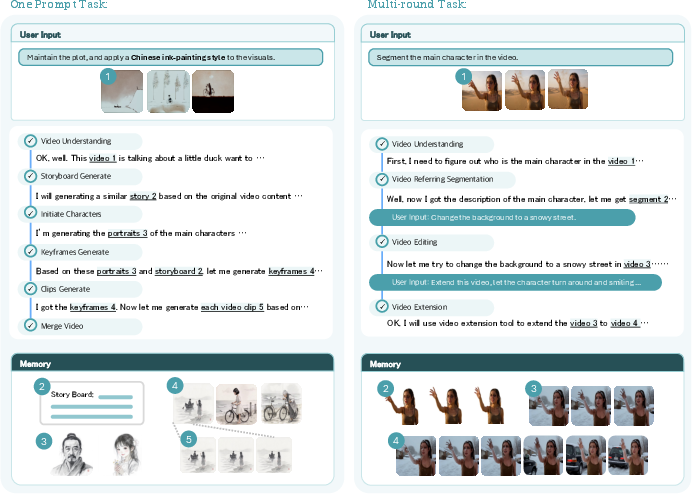
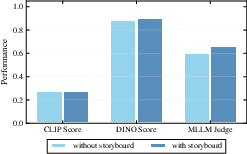
- Better planning for long prompts: When given long or messy instructions, UniVA first makes a storyboard/plan, which helps it follow instructions more faithfully and produce more coherent videos.
- Strong identity and story consistency: It keeps characters consistent across scenes and edits, and can rewrite or extend stories while keeping the original style.
- Long‑video understanding: UniVA answers questions about long videos more accurately than several popular multimodal models, because it can break complex questions into sub‑tasks and use memory.
- Editing and segmentation over long videos: It performs multi‑step edits (like style changes across multiple shots) and segments objects over time better than baselines, thanks to its planning and the way it reuses intermediate results (like masks) and context.
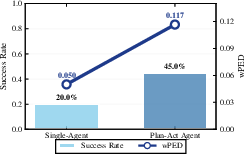
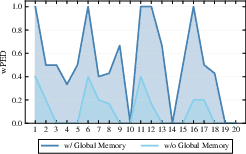
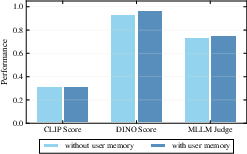
- Planning and memory really help: Tests show the Plan‑and‑Act design makes plans that are both more valid and higher quality, and the memory modules reduce failures and improve consistency.
- People prefer its results: In human evaluations, viewers often favored UniVA’s videos for following instructions and telling coherent stories.
In short, UniVA isn’t just a collection of tools—it’s the coordination, memory, and planning that make the whole greater than the sum of its parts.
Why this matters (implications and impact)
- For creators: UniVA can turn a single request into a complete, editable video workflow, saving time and making complex video tasks more accessible.
- For reliability: Built‑in planning and memory make it better at long, multi‑step jobs where most systems forget details or break down.
- For research: UniVA‑Bench gives the community a way to test not just video quality, but also agent skills like planning, tool‑choosing, and remembering.
- For the future of AI: UniVA shows how “agentic” AI—systems that plan, act, and remember—can unify many skills (understanding, editing, generation) into one interactive assistant. Because it’s open‑source and tool‑friendly (via MCP), it can keep growing as new video tools come out.
Bottom line: UniVA points toward a next‑generation “universal video assistant” that can understand your intent, plan the steps, use the right tools, and keep everything consistent—turning complex video creation into a smoother, more collaborative process.
Knowledge Gaps
Unresolved limitations, knowledge gaps, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
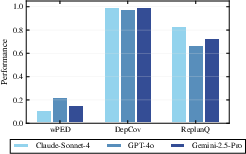
- Planner learning vs. prompting: The Planner is selected (Claude Sonnet 4) rather than trained; no exploration of learning a policy π via supervised imitation, RL, or hybrid self-improvement on planning traces to improve wPED/DepCov/ReplanQ.
- Cost- and latency-aware planning: Plans do not optimize for multi-objective trade-offs (quality, compute time, API cost, CO2). No scheduling or budgeting strategies, cost-aware tool routing, or latency benchmarking across end-to-end workflows.
- Robustness to real tool faults: While “injected failures” are mentioned, there is no systematic evaluation under realistic tool errors (rate-limits, API version drift, degraded quality, partial outputs, non-determinism) or formal fallback/escalation strategies.
- Tool selection under uncertainty: No methods for online tool quality estimation, capability discovery, or confidence-aware tool routing when multiple tools can fulfill a subtask with different strengths/costs.
- Parallelization and caching: The framework does not quantify or exploit opportunities for parallel tool calls, memoization, result caching, or speculative execution to reduce end-to-end latency.
- Memory governance and privacy: The hierarchical memory stores user data and traces, but retention policies, PII handling, consent, GDPR/CCPA compliance, data minimization, and secure deletion are not addressed.
- Memory corruption and drift: No mechanisms to detect, prevent, or recover from stale, contradictory, or adversarial entries in global/user/task memory (e.g., memory hygiene, verification, rollbacks, or provenance auditing).
- Traceability depth: Although “full traceability” is claimed, the paper does not specify the granularity, schema, and verifiability of execution traces (e.g., reproducible EDLs, tool parameters, seeds, model versions, hashes).
- Safety and misuse mitigation: There is no safety layer for deepfakes, identity manipulation, or harmful content (e.g., face swaps, protected persons, copyrighted characters), nor watermark detection/insertion or policy enforcement across tools.
- Benchmark representativeness: UniVA-Bench scale, domain diversity (cultures, languages, camera styles), content licenses, and distribution splits are under-specified; potential dataset bias and generalization outside the benchmark remain unknown.
- Metric validity and coverage: Heavy reliance on CLIP/DINO and an MLLM-as-a-Judge lacks robust temporal metrics (e.g., FVD, tOF/FID-V, temporal LPIPS, identity/motion drift measures), and no evaluation of audio quality or sync.
- MLLM-as-a-Judge reliability: The paper does not report judge model identity, inter-rater agreement with humans, test-retest stability, or bias analyses; the scale and protocol of the human study are not detailed (annotator count, IAA, instructions).
- Apples-to-apples segmentation fairness: The agent’s segmentation leverages language/contextual queries; comparisons to purely pixel-level baselines may be unfair. A fair setting would compare against segmentation systems augmented with text/video context.
- Identity preservation limits: UniVA underperforms on DINO in some identity-centric settings; no targeted modules (e.g., identity embeddings, face/body re-id constraints, subject tokens, diffusion guidance) or ablations are provided to close this gap.
- Long-horizon consistency measurement: Claims of narrative/coherence are not backed with dedicated metrics (e.g., story beat alignment, character continuity scores, storyboard-to-video adherence) or rigorous user studies on story comprehension.
- Generalization to non-English and code-switched prompts: Multilingual instruction-following, OCR-heavy or ASR-conditioned workflows, and cultural content handling are not evaluated.
- Audio pipeline under-evaluated: Although audio tools are supported, there is no quantitative or perceptual evaluation of audio generation/editing, lip sync, music continuity, or multimodal alignment.
- Planner transparency and explainability: No assessment of plan readability/editability for human operators (e.g., editor acceptance rate, time-to-correct, usability studies of plan traces in professional NLE workflows).
- Security of MCP ecosystem: No discussion of supply-chain risks from third-party MCP servers, sandboxing, permissioning, secrets management, or integrity checks for tool outputs.
- Reproducibility with proprietary components: The Planner and several tools appear to be proprietary APIs; reproducing results without paid services or closed models is unclear. Open-source fallbacks and parity assessments are missing.
- Tool schema and contracts: The MCP function registry is described, but there is no formal schema for tool capabilities, input/output typing, versioning, and error contracts, nor conformance tests to ensure reliability across tool updates.
- Storyboard generation quality: Storyboards are claimed to help, but the quality of generated storyboards, their faithfulness to prompts, and how storyboard granularity affects downstream video outcomes are not systematically studied.
- Data leakage and contamination: No analysis of potential content memorization by LLMs/video models on benchmark items, or safeguards to prevent memory modules from leaking ground truth into evaluations.
- Scaling limits: Maximum video length, resolution, and number of entities the system can handle with acceptable latency/quality are not characterized; memory and compute scaling curves are absent.
- Human productivity impact: There is no controlled user study measuring editing throughput, error rate, or satisfaction versus traditional pipelines or single-model baselines in realistic production settings.
- Failure mode taxonomy: A principled catalog of common failure modes (tool hallucination, mask leakage, identity drift, timing misalignment, plan loops) and targeted mitigations is not provided.
- Continual tool learning: The system does not adapt its planner/actor to new tools over time via meta-learning or auto-discovery; how to update π and memory to leverage newly added capabilities remains open.
- Objective Q in Eq. (1): The quality function Q is not operationalized beyond proxy metrics; multi-objective or user-specific Q definitions and optimization strategies (e.g., preference learning) are missing.
- Cross-agent designs: Only Plan–Act is explored; open questions remain on whether multi-specialist agents (e.g., planner, verifier, safety, reviewer) with communication protocols would improve robustness and quality.
- Statistical rigor: Many comparisons lack confidence intervals, significance tests, and sample size disclosures; the robustness of reported improvements is unclear.
- Industry interoperability: Export/import to standard EDLs, AAF/AAF-like formats, and round-tripping with professional NLEs (Premiere/Resolve) are not evaluated, limiting deployment clarity.
Practical Applications
Immediate Applications
Below is a focused list of practical use cases that can be deployed now, based on UniVA’s agentic Plan–Act architecture, MCP-based tool integration, and hierarchical memory.
- Automated ad and social content production — sectors: media, marketing, e-commerce
- What: Turn text/image/video briefs into short-form ads with identity-preserving product shots, style transfer, background replacement, and multi-round edits.
- Workflow/tools: Planner decomposes brief → storyboard in Task Memory → generation (text/image/video-conditioned) → segmentation (object/person) → edit/inpaint/compose → audio addition; MCP servers orchestrate models like SAM2-style segmentation, Runway/Seedance/Wan for generation, NLE operations.
- Assumptions/dependencies: Access to high-quality video generation APIs; brand assets; GPU/compute; licensing for third-party tools; quality control via human review for legal compliance.
- Industrial rotoscoping and VFX pre-vis — sectors: film/TV post-production
- What: Automate mask creation, long-video identity tracking, and style-coherent edits across shots; accelerate pre-visualization with agentic planning.
- Workflow/tools: Segmentation on long clips → track masks via Task Memory → targeted inpaint/compose → style transfer; traceability via execution logs for reproducibility.
- Assumptions/dependencies: Reliable long-video segmentation; temporal consistency; integration with NLEs via MCP; human-in-the-loop approvals.
- Lecture and MOOC content refinement — sectors: education
- What: Summarize long lectures, auto-generate highlight reels, insert diagrams, and redact student identities for privacy.
- Workflow/tools: Understanding module for long-video Q&A/highlights → segmentation for face/person blurring → editing pipeline; User Memory for instructor preferences (branding, caption style).
- Assumptions/dependencies: ASR/captioning tools integrated via MCP; institutional privacy policies; consistent camera framing.
- Sports highlight assembly and tactical analysis — sectors: sports analytics, media
- What: Extract key plays, track players/ball, generate explainers and highlight packages from full-match footage.
- Workflow/tools: Q&A-style understanding for event detection → segmentation/tracking → compositional overlays → narrated summaries via generation.
- Assumptions/dependencies: Domain-tuned detection heuristics; robust tracking in occlusions; access to broadcast footage rights.
- Compliance redaction for public release videos — sectors: policy, law enforcement, government, healthcare
- What: De-identify faces, license plates, or protected health information in bodycam/surveillance/surgical videos with audited traces.
- Workflow/tools: Segmentation and grounding → automated mask application → redact/blur; Plan–Act agents maintain trace memory for auditability; export EDLs.
- Assumptions/dependencies: Agency-approved redaction standards; accurate detection of sensitive entities; storage/retention policies for User/Task Memory.
- Personal creator assistant — sectors: daily life, creator economy
- What: Create and iterate family montages, travel vlogs, and stylized posts using conversational co-creation and persistent preferences.
- Workflow/tools: Multi-round dialogue → Planner decomposes intents → generation/editing; User Memory enforces preferred resolution, LUTs, fonts.
- Assumptions/dependencies: Consumer-accessible UI (e.g., OpenCut-based frontend); safe handling of personal media; cloud costs.
- Newsroom explainer and package assembly — sectors: news/media
- What: Quickly produce visual explainers from raw footage, insert context, and maintain cross-shot narrative coherence.
- Workflow/tools: Long-video understanding for story extraction → storyboard generation → compositional edits and subtitling via MCP tools.
- Assumptions/dependencies: Editorial oversight; misinformation safeguards; licensing for archive footage.
- Academic benchmarking and reproducible agent research — sectors: academia, software
- What: Use UniVA-Bench to evaluate planning, memory use, and tool orchestration; develop new MCP servers and agent strategies.
- Workflow/tools: Agentic metrics (wPED, DepCov, ReplanQ) + task metrics; standardized traces and goal cards; plug-in tool servers.
- Assumptions/dependencies: Community adoption of MCP; availability of open models/APIs; reproducible environments and seeds.
- E-commerce product video pipelines — sectors: retail/e-commerce
- What: Generate consistent catalog videos (colorways, backgrounds, 360 spins), adapt to regions/languages, and A/B test variants.
- Workflow/tools: Entities2Video for identity-preserving generation → background replacement → caption/voiceover; Planner tracks variants in Task Memory.
- Assumptions/dependencies: Product image references; brand guidelines; localization tools; storefront integrations.
- Customer support and training video refinement — sectors: software, enterprise training
- What: Edit long tutorial recordings into modular clips, add callouts, and maintain consistency across updates.
- Workflow/tools: Understanding for topic segmentation → compositional editing and overlays → multimodal outputs (video + annotated steps).
- Assumptions/dependencies: Integration with LMS/knowledge bases; versioning of assets; stable UI screen capture quality.
Long-Term Applications
These applications require further research, integration, scaling, or policy development before broad deployment.
- Live multi-camera directing with agentic switching — sectors: broadcast, events
- What: Real-time planning across camera feeds (staging, cues), automatic shot selection, and style-consistent overlays.
- Workflow/tools: Plan–Act with low-latency video understanding; Task Memory for live story state; MCP orchestration of vision + switching hardware.
- Assumptions/dependencies: Real-time inference at broadcast framerates; robust failure recovery; hardware I/O integration; operator oversight.
- End-to-end cinematic production co-director — sectors: film/TV
- What: Persistent “agentic co-director” that carries narrative intent from pre-vis to post, enforcing continuity of character, wardrobe, props, and style.
- Workflow/tools: Global/User/Task Memory across months-long projects; asset registries; plan re-evaluation via ReplanQ; compositional synthesis.
- Assumptions/dependencies: Scalable memory, rights management for assets, union and IP compliance, human creative control frameworks.
- Synthetic video dataset factory — sectors: robotics, AV/ADAS, healthcare AI, education
- What: Generate diverse, long-form, context-rich videos for training perception and reasoning systems with controllable labels.
- Workflow/tools: Planner builds parametric storyboards → generation with domain constraints → segmentation/annotations retained in Task Memory.
- Assumptions/dependencies: Domain fidelity; label accuracy; standardization for dataset metadata; compute budgets.
- Smart surveillance and incident reconstruction — sectors: public safety, transportation
- What: Multi-camera, long-horizon reasoning to reconstruct timelines, track entities across occlusions, and auto-generate incident summaries.
- Workflow/tools: Long-video QA + segmentation + cross-feed grounding; hierarchical memory; audited trace outputs.
- Assumptions/dependencies: Privacy and civil liberties safeguards; cross-camera calibration; regulatory approval; robust disambiguation in crowded scenes.
- Accessibility-first video pipelines — sectors: policy, public communications, education
- What: Agents that proactively enforce accessibility (accurate captions, sign-language overlays, audio descriptions) across large content repositories.
- Workflow/tools: Planner routes ASR/TTS/gesture models; Task Memory maintains accessibility artifacts; QC via agentic metrics.
- Assumptions/dependencies: High-quality ASR/SL translation; standardized accessibility guidelines; multilingual support.
- Brand digital twin for content governance — sectors: marketing, enterprise
- What: Persistent memory of brand identity, visual grammar, and compliance rules that guides all generated/edited assets.
- Workflow/tools: User Memory as brand registry; policy-aware planning; automated QC; compositional edits guarded by constraints.
- Assumptions/dependencies: Formalized brand ontologies; governance policies; audit trails; integration with DAM/CMS.
- Agentic NLE plugins at scale — sectors: software/media tooling
- What: Native UniVA-MCP plugins for Premiere/Resolve/Avid enabling plan-aware timelines, auto-suggested tool chains, and traceable edits.
- Workflow/tools: MCP client inside NLE; Planner surfaces plan steps to timeline; Task Memory maps to EDLs and versions.
- Assumptions/dependencies: Vendor APIs; UX design for agent-in-the-loop; reliability guarantees; enterprise IT acceptance.
- Regulatory auditing of generative content — sectors: policy, finance, advertising standards
- What: Use trace memory and agentic metrics to certify that generated videos follow declared inputs, constraints, and disclosure rules.
- Workflow/tools: Exportable plan graphs, tool-call logs, dependency checks (DepCov), re-planning records (ReplanQ).
- Assumptions/dependencies: Agreed standards for audit artifacts; third-party verification; legal frameworks for disclosure.
- Personalized long-form education and therapy media — sectors: healthcare, education
- What: Agents co-create tailored lesson or therapy videos, adapt pacing and visuals over sessions using User Memory.
- Workflow/tools: Planner uses historical performance/preferences; compositional generation/editing; secure memory storage.
- Assumptions/dependencies: Clinical/educational validation; privacy-preserving memory; ethical oversight; content safety.
- On-device privacy-preserving video agents — sectors: mobile, consumer, enterprise
- What: Run UniVA locally for sensitive media, with federated/global memory distilled to devices.
- Workflow/tools: Lightweight Planner/Actor; model compression; local MCP servers for segmentation/editing; optional edge GPU.
- Assumptions/dependencies: Efficient models; battery/compute constraints; secure storage; limited third-party dependencies.
- Real-time creative assistance on set — sectors: film/commercial production
- What: Instant continuity checks, style previews, and edit impact forecasts during shoots.
- Workflow/tools: Fast understanding; incremental storyboards in Task Memory; “what-if” plan branches (ReplanQ).
- Assumptions/dependencies: Low-latency inference; robust camera ingest; professional acceptance; safety nets for false positives.
- Cross-modal policy analytics for public archives — sectors: government, NGOs, journalism
- What: Large-scale processing of public video archives to surface trends, ensure privacy redactions, and generate accessible summaries.
- Workflow/tools: Batch Plan–Act orchestration; memory-driven consistency across collections; agentic QC pipelines.
- Assumptions/dependencies: Data access rights; scalable infrastructure; governance for memory retention; auditing protocols.
Common Assumptions and Dependencies Across Applications
- Model quality and availability: Performance depends on access to strong generation, segmentation, and understanding models integrated via MCP (some may be proprietary or API-bound).
- Compute and latency: Long-form, multi-step workflows require substantial GPU/TPU resources and may face latency challenges, especially for live or near-real-time use.
- Memory management and privacy: Hierarchical memory must be stored and governed securely; user consent and retention policies are essential.
- Tool orchestration reliability: Robust MCP servers, validated tool routing, and clear failure recovery (ReplanQ) are needed for production-grade reliability.
- Legal and ethical compliance: Rights management for source assets, disclosures for generated media, accessibility standards, and domain-specific regulations (e.g., healthcare, law enforcement) must be observed.
- Human-in-the-loop: For high-stakes contexts (broadcast, policy, medical), expert review and override mechanisms remain necessary.
Glossary
- Actor: The execution agent in a Plan–Act system that invokes tools to carry out planned steps. "The Actor receives each sub-goal from the Planner, selects the appropriate tool through the MCP interface"
- Agentic: Refers to systems or workflows that plan, decide, and act autonomously with tools. "agentic video systems"
- autoregressive models: Generative models that produce sequences one step at a time conditioned on previous outputs. "video generation has progressed from autoregressive models, such as VideoGPT"
- CLIP Score: A metric measuring text–video alignment via CLIP embeddings. "using established metrics like CLIP Score for command following"
- compositional synthesis: Combining segmented objects/elements into new scenes or videos. "object segmentation compositional synthesis"
- compositionality: The ability to solve tasks by composing multiple operations or tools. "designed to test compositionality, tool swaps, and long-form reasoning"
- controllable synthesis: Video generation guided by external conditions or controls. "controllable synthesis via conditional inputs"
- cross-modal editing: Editing that transfers or aligns information across different modalities (e.g., text to video). "cross-modal editing"
- cross-shot consistency: Maintaining consistent identities/styles across multiple shots in long videos. "Editing (long video edits with cross-shot consistency)"
- DepCov: Dependency Coverage; a plan-level metric assessing whether task dependencies are satisfied. "assessed using our novel, specialized metrics (wPED, DepCov, and ReplanQ)"
- diffusion-based methods: Generative models that iteratively denoise to synthesize videos. "diffusion-based methods, including Imagen Video"
- DINO Score: A metric for subject/identity consistency using self-supervised visual features. "CLIP Score for command following and DINO Score for subject consistency"
- Edit Decision List (EDL): A structured list specifying edits (cuts, transitions) in post-production. "gold artifacts (e.g., evidence spans, masks, EDLs)"
- Entities2Video: A task setting where reference images/entities condition video generation. "Generation (LongText2Video, Image/Entities2Video, Video2Video)"
- Global Memory: Long-term store of reusable knowledge and statistics for planning. "Global Memory. Stores persistent knowledge and reusable resources"
- hierarchical multi-level memory: Layered memory design spanning global, task, and user contexts. "Through a hierarchical multi-level memory (global knowledge, task context, and user-specific preferences)"
- identity preservation: Ensuring the same character/object remains visually consistent across scenes. "using 1--3 reference images to enforce identity preservation and cross-scene coherence"
- LongText2Video: Generating videos from long or noisy textual prompts. "LongText2Video, handling long or noisy prompts that necessitate storyboard-first planning"
- MLLM-as-a-Judge: Using a multimodal LLM to provide preference judgments. "preference ratings from an MLLM-as-a-Judge"
- Model Context Protocol (MCP): A protocol to connect agents with external tools through standardized interfaces. "We achieve unified management of the action space through MCP protocol."
- Plan–Act dual-agent architecture: Separation of planning (strategy) and acting (tool execution) into two agents. "The core of UniVA is a Plan--Act dual-agent architecture."
- referential stability: Maintaining stable references to the same entities across generated frames. "ensuring referential stability for persons and objects."
- ReplanQ: Replanning Quality; a metric evaluating robustness and quality when plans must be revised. "assessed using our novel, specialized metrics (wPED, DepCov, and ReplanQ)"
- retrieval-augmented generation (RAG): Enhancing generation by retrieving relevant user assets or knowledge. "via a RAG mechanism"
- storyboard: An intermediate structured plan of shots/scenes guiding video generation. "storyboard-first planning"
- Task Memory: Per-task store of intermediate artifacts and execution traces. "Task Memory. Maintains intermediate artifacts, tool outputs, and execution traces for the current workflow."
- temporal coherence: Smooth, consistent appearance and motion over time in generated videos. "achieved improved fidelity and temporal coherence"
- tool orchestration: Coordinating multiple tools in sequence to accomplish complex tasks. "the need for explicit planning, memory, and tool orchestration."
- tool-routing efficiency: How effectively an agent selects and sequences tools to achieve goals. "tool-routing efficiency"
- traceability: The ability to inspect and reproduce each step of the agent’s workflow. "enabling interactive and self-reflective video creation with full traceability."
- User Memory: Records user preferences and history to personalize future actions. "User Memory. Tracks user-specific preferences and historical interactions"
- Video2Video: Conditioning generation on an input video to produce a transformed output. "Video2Video"
- video-language foundation models: Large models jointly trained to understand/generate video conditioned on language. "video-language foundation models like VILA-U"
- Video-LLMs: LLMs extended to process video inputs and outputs. "Extensions of Video-LLMs integrate segmentation modules"
- wPED: Weighted Plan Edit Distance; a metric measuring plan quality against expert references. "assessed using our novel, specialized metrics (wPED, DepCov, and ReplanQ)"
Collections
Sign up for free to add this paper to one or more collections.