TimeSearch-R: Adaptive Temporal Search for Long-Form Video Understanding via Self-Verification Reinforcement Learning
Abstract: Temporal search aims to identify a minimal set of relevant frames from tens of thousands based on a given query, serving as a foundation for accurate long-form video understanding. Existing works attempt to progressively narrow the search space. However, these approaches typically rely on a hand-crafted search process, lacking end-to-end optimization for learning optimal search strategies. In this paper, we propose TimeSearch-R, which reformulates temporal search as interleaved text-video thinking, seamlessly integrating searching video clips into the reasoning process through reinforcement learning (RL). However, applying RL training methods, such as Group Relative Policy Optimization (GRPO), to video reasoning can result in unsupervised intermediate search decisions. This leads to insufficient exploration of the video content and inconsistent logical reasoning. To address these issues, we introduce GRPO with Completeness Self-Verification (GRPO-CSV), which gathers searched video frames from the interleaved reasoning process and utilizes the same policy model to verify the adequacy of searched frames, thereby improving the completeness of video reasoning. Additionally, we construct datasets specifically designed for the SFT cold-start and RL training of GRPO-CSV, filtering out samples with weak temporal dependencies to enhance task difficulty and improve temporal search capabilities. Extensive experiments demonstrate that TimeSearch-R achieves significant improvements on temporal search benchmarks such as Haystack-LVBench and Haystack-Ego4D, as well as long-form video understanding benchmarks like VideoMME and MLVU. Notably, TimeSearch-R establishes a new state-of-the-art on LongVideoBench with 4.1% improvement over the base model Qwen2.5-VL and 2.0% over the advanced video reasoning model Video-R1. Our code is available at https://github.com/Time-Search/TimeSearch-R.

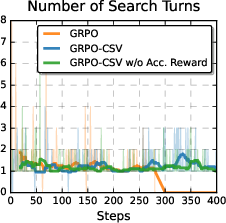

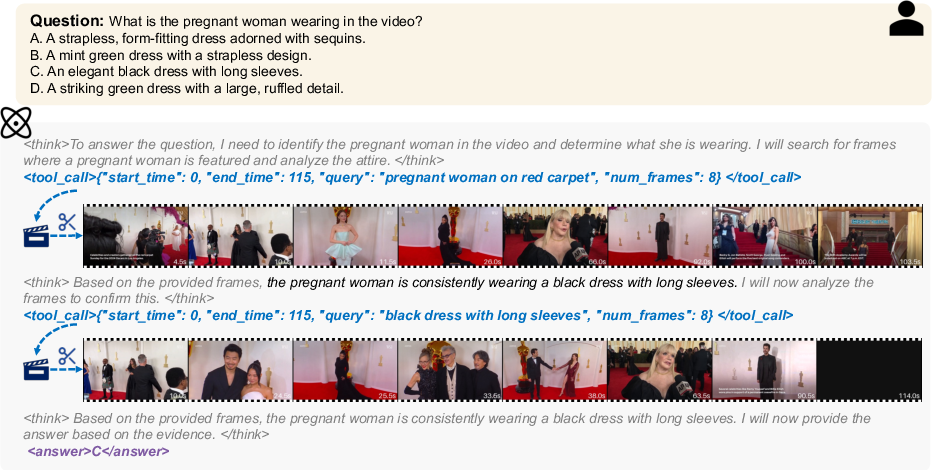

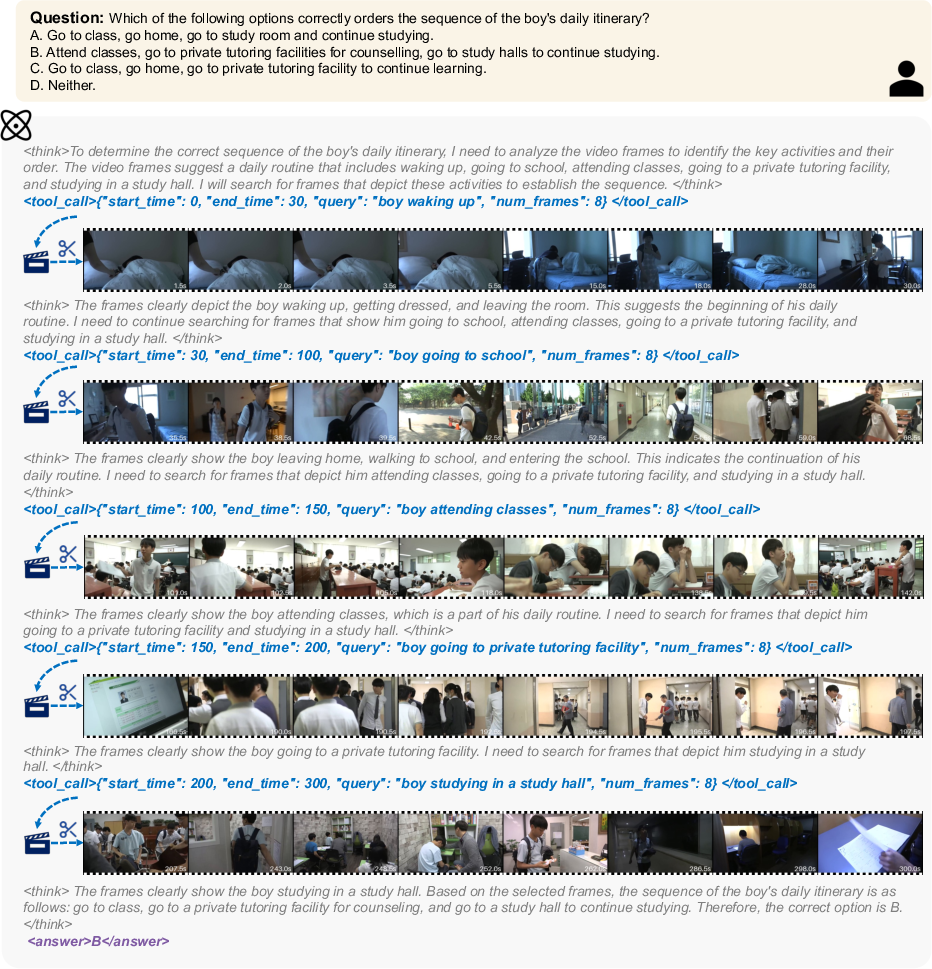
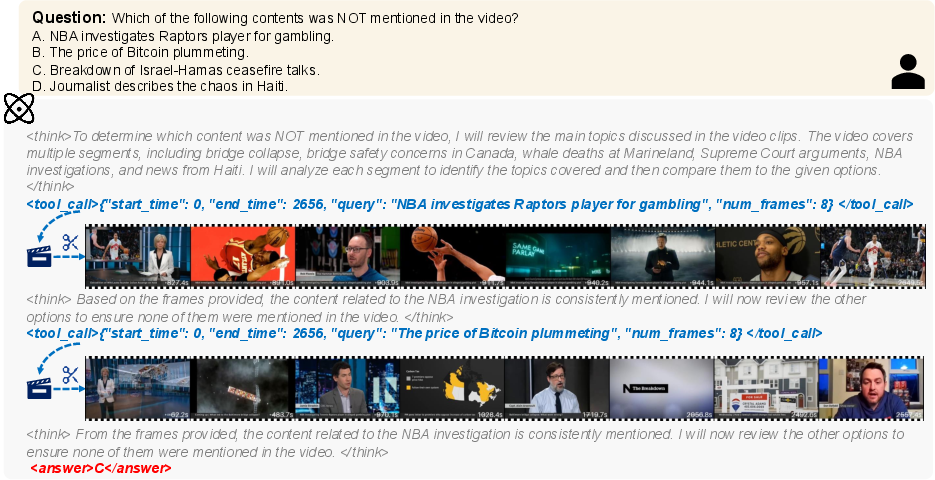
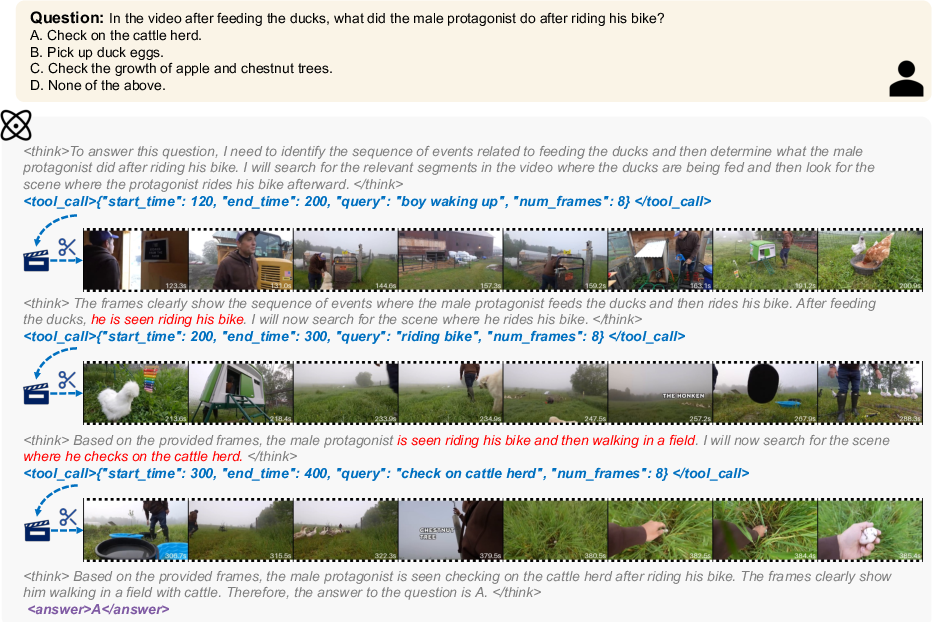
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about teaching AI systems to watch very long videos (think TV episodes, sports matches, or vlogs) and find the exact moments that matter for answering a question. The authors create a new method, called TimeSearch-R, that lets an AI “think” while it watches and actively search for the right frames at the right time, instead of looking at a fixed set of frames picked in advance.
The main questions the paper tries to answer
- How can an AI smartly search through tens of thousands of video frames to find just the few that are most useful?
- Can we train the AI to mix “text thinking” (like reasoning in words) with “video searching” so it gets better over time?
- How do we stop the AI from guessing answers without truly looking, or from thinking in a way that doesn’t match its final answer?
- Does this approach actually beat the best existing methods on real tests?
How the method works (in simple terms)
1) Interleaved “think and search”
Imagine you’re trying to answer a question about a movie scene. You might:
- First, skim some parts of the movie.
- Think about what you learned.
- Decide to jump to another part to look for a clue.
- Repeat until you’re confident about the answer.
TimeSearch-R trains an AI to do this. It:
- Starts with a small preview of the video.
- Writes down its thoughts step-by-step (like a study notebook).
- When needed, it issues a “search instruction” that says: “From time X to time Y, look for frames related to this idea.”
- It then adds the new frames it found into its ongoing reasoning and continues.
This way, the AI’s reasoning and video searching happen together, and the set of frames it uses grows dynamically based on what it’s thinking.
2) Picking useful and diverse frames
When the AI searches a time window, a helper tool scores frames by how relevant they are to the AI’s current query (using a smaller vision-LLM). It then picks a handful of frames that are both:
- informative (likely to help answer the question), and
- diverse (not all similar, so they cover different visual moments).
Think of it like collecting notes from different angles rather than copying the same sentence over and over.
3) Training with reinforcement learning (RL)
Reinforcement learning is like practice with feedback: the AI tries things, gets rewards for good outcomes, and learns to repeat better strategies.
The paper uses an RL method (GRPO) but finds two common problems if you only reward the final answer:
- Insufficient exploration: the AI might guess correctly without really looking at the right frames.
- Inconsistent thinking: the AI’s written “thinking” doesn’t match the final answer (like a messy math solution that accidentally ends with the right number).
To fix this, they add Completeness Self-Verification (CSV):
- After the AI finishes its “think and search” and produces an answer, the system extracts the frames it found.
- Then the AI must re-answer the question using only those frames, with no further searching allowed.
- If both the original answer and the re-answer are correct, it gets a “completeness” reward. This checks whether the AI actually gathered enough visual evidence.
- They also give rewards for proper format (following the think/search/answer structure) and for answer accuracy.
In short: the AI gets rewarded not just for being right, but for being right for the right reasons.
4) Good training data matters
To make RL effective, the authors carefully filter training examples:
- Remove “too easy” questions that can be answered by language patterns alone (so the AI can’t just guess without looking).
- Remove “impossible” or noisy cases that don’t help the model learn. This makes the AI truly practice useful video searching.
5) Two-stage training
- First, supervised fine-tuning (SFT) teaches the AI the right way to write its thoughts and issue search commands (a “cold start”).
- Then, RL with CSV improves the AI’s searching strategy and its overall reasoning quality.
What did they find?
Here are the key results, explained simply:
- On tests designed for “find the needle in a haystack” in long videos, TimeSearch-R found the right moments more often than previous methods. Its temporal search score jumped far above older agents that relied on hand-crafted rules.
- On general long-video understanding benchmarks (like VideoMME, MLVU, and LongVideoBench), it beat strong models, including large commercial systems and recent reasoning-focused models. For example, on LongVideoBench, it improved by about 4.1% over its base model (Qwen2.5-VL) and 2.0% over Video-R1.
- The CSV add-on made training more stable and led to better alignment between the AI’s step-by-step thinking and its final answers.
- Simply adding “search prompts” to a normal model without this RL training actually hurt performance, showing that learning the search strategy end-to-end is essential.
Why this matters:
- It shows that letting an AI actively search video in the middle of its reasoning is more powerful than pre-selecting frames in advance.
- It proves that rewarding the AI for both correctness and completeness (using its own found frames) leads to more reliable understanding.
Why this is important and what it could impact
- Smarter video assistants: Better at answering questions about long videos, like summarizing a lecture, reviewing a sports game, or checking a security recording.
- More trustworthy reasoning: The AI’s answers are backed by the frames it actually found, making it less likely to bluff or rely on shortcuts.
- Efficiency: Instead of scanning every frame, the AI learns when and where to look, saving time and computation.
- General idea: The approach (think-then-search, verify completeness) could be useful beyond videos—for any task that needs gathering the right evidence before deciding, like searching documents, browsing the web, or analyzing long medical records.
In short, TimeSearch-R teaches AI to watch long videos more like a careful human: think, search, check, and answer—leading to more accurate and reliable results.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Confirmation bias in self-verification: CSV uses the same policy model to generate answers and to verify completeness, potentially reinforcing its own mistakes. Would an external verifier (e.g., a separate model, cross-model voting, or human-in-the-loop checks) reduce bias and improve evidence sufficiency assessment?
- Conditional CSV reward gating: Completeness reward is only applied when the original answer is correct, providing no learning signal for wrong-but-productive searches. Can alternative reward designs (e.g., dense evidence rewards, partial credit for improved evidence quality, or contrastive rewards) encourage exploration even when the initial answer is incorrect?
- Faithfulness of “sufficiency” metric: CSV assumes that “re-answering with searched frames” validates sufficiency, but it doesn’t guarantee that the frames truly contain the needed evidence. How can we incorporate frame-level human annotations, adversarial counterfactuals, or automated grounding diagnostics to verify that evidence is genuinely present and used?
- LLM-as-a-judge accuracy bias: Open-ended evaluation uses an LLM judge, which may be biased or inconsistent. What is the impact of different judges, calibration, or human evaluations on measured gains, and can robust automatic metrics (e.g., entailment or reference-based scoring) replace or complement the judge?
- Frozen, non-learned retrieval tool: The search function relies on a fixed SigLIP similarity plus DPP selection outside the policy’s learning loop. Can we jointly learn the retriever (e.g., through differentiable retrieval, RL-tuned scorers, or policy gradients) to achieve end-to-end optimization of search quality?
- Limited action space: The policy only specifies temporal windows and a text query; it cannot perform spatio-temporal actions (crop, track objects, zoom, stabilize, or adjust stride). What gains would a richer action space bring, and how should such actions be parameterized and rewarded?
- Loss of motion cues: The system selects keyframes rather than modeling temporal dynamics within clips. Would clip-level encoders, motion features (e.g., optical flow), or short video tokens improve temporal reasoning and reduce missed motion-dependent evidence?
- No audio/subtitle integration: Audio and ASR/subtitles are ignored, despite their importance in many long-form tasks. How much does adding audio-aware or text-audio-video co-search improve completeness and QA, and what is the best way to fuse modalities during search?
- Fixed search budget and stop rule: The agent is capped at 8 steps and 8 frames per step, with a pre-defined budget rather than a learned stopping criterion. How does performance scale with search budget, and can we learn to stop early with confidence (and quantify compute-accuracy trade-offs and latency)?
- Compute and latency not measured: The method adds multiple search calls and uses an auxiliary VLM, yet efficiency, wall-clock latency, and throughput are not reported. What is the real-time viability and energy footprint, and how do we optimize cost-performance under deployment constraints?
- Baseline fairness and frame budgets: Some comparisons use different numbers of frames (e.g., 768 vs 32), making it hard to isolate algorithmic gains from input budget. Can controlled experiments with matched frame budgets and identical tool stacks clarify true improvements?
- Low absolute temporal F1: Despite relative gains, the temporal F1 (8.1) remains low in absolute terms. What are the main bottlenecks (e.g., initial preview coverage, retrieval noise, action granularity), and which changes most effectively lift absolute temporal localization quality?
- Sensitivity to initial preview sampling: The method relies on a uniformly sampled preview. How sensitive is performance to preview length and sampling strategy, and can adaptive initial glimpses or curriculum previews reduce early-stage misses?
- Data filtering introduces curation bias: Filtering removes “trivial” and “unsolvable” samples using model-dependent heuristics, which may tailor the dataset to the method and reduce robustness to real-world difficulty. Can we quantify and mitigate curation bias, and evaluate on raw, unfiltered distributions?
- Generalization across domains and languages: Experiments cover a limited set of long-video benchmarks in English. How well does the learned policy transfer to new domains (sports, tutorials, surveillance), non-English queries/subtitles, or culturally different content?
- Robustness to adversarial and bias-exploiting prompts: Although the training data is filtered to reduce linguistic shortcuts, there is no dedicated robustness evaluation. How susceptible is the system to adversarial questions or spurious correlations at test time?
- Failure mode taxonomy post-RL: Beyond two reported failure modes (insufficient exploration, inconsistent reasoning), a systematic error taxonomy is missing. What are the dominant failure patterns after GRPO-CSV (e.g., off-by-few-seconds localization, object confusion, long-horizon dependencies), and which interventions fix each?
- Reward shaping ablations: The contributions of reward components and hyperparameters (weights, KL penalty, CSV threshold) are not deeply explored. What combinations optimize stability and sample efficiency, and how do they interact with rollout count and group size?
- Alternative RL algorithms and credit assignment: The work focuses on GRPO. Would other on-/off-policy methods (e.g., PPO variants, AWR, Q-learning, tree-search RL) or temporal credit assignment mechanisms improve learning with delayed rewards and long-horizon searches?
- External verification and multi-agent setups: CSV uses a single model for both reasoning and verification. Do multi-agent verification, debate, or cross-checking with specialized verifiers (e.g., object/ASR detectors, OCR, audio event models) increase faithfulness and reduce hallucinations?
- Learned retrieval vs. tool orchestration: The retrieval tool is rule-based (SigLIP+DPP). Can the policy learn to orchestrate multiple specialized tools (captioners, detectors, ASR, OCR) and learn when to call which tool to maximize evidence yield per unit cost?
- Learning to ground answers: The method evaluates consistency via re-answering, but not explicit grounding (e.g., pointing to the exact frames/regions supporting each reasoning step). Can we add grounding rewards or alignment losses to improve faithfulness and explainability?
- Scaling and model size: Results are based on a 7B base. Do CSV gains persist or amplify with larger backbones (13B, 72B), or shrink due to stronger base reasoning? What are the scaling laws for search quality vs. model size and compute?
- Corpus-level retrieval and multi-video tasks: The method searches within a single video. How can it extend to corpus-level temporal search (e.g., across episodes, multi-camera feeds, or knowledge-video retrieval) with hierarchical planning?
- Long-horizon memory and planning: Handling hours-long content may require hierarchical memory and multi-stage plans. Can we integrate hierarchical policies, episodic memory, or retrieval-augmented memory to manage extremely long contexts?
- Stopping and confidence calibration: The agent lacks explicit confidence estimates for when it has gathered “enough” evidence. Can we calibrate uncertainty and incorporate risk-sensitive stopping rules to balance accuracy, compute, and user latency?
- Tool-call parsing robustness: The format reward enforces schema adherence, but real-world parsing errors and noisy outputs are not analyzed. How robust is the system to malformed tool calls, and can structured action APIs reduce brittleness?
- Ablations on DPP and similarity scoring: The choice of SigLIP similarity and DPP sampling is not ablated. Would alternative diversity/coverage objectives, learned scorers, or temporal-aware sampling improve search quality?
- Human evaluation of CoT faithfulness: Case studies are illustrative but not systematically validated. Can human raters assess whether reasoning steps are supported by the retrieved frames and whether the chain-of-thought avoids post-hoc rationalization?
Practical Applications
Immediate Applications
The following use cases can be deployed with today’s capabilities, using the paper’s interleaved text-video thinking, adaptive temporal search, and GRPO-CSV training pipeline to improve accuracy, efficiency, and interpretability in long-form video analysis.
- Industry — Security and Compliance Monitoring
- Use case: Post-hoc incident search and triage in hours of CCTV/bodycam footage; fast retrieval of key moments (e.g., falls, near misses, trespassing) with interpretable evidence trails.
- Sector: Security, public safety, retail operations, insurance.
- Tools/Workflows: “Think–Search–Verify” pipeline integrated into a Video Management System (VMS); dynamic frame retrieval with SigLIP+DPP; CSV-based verification to ensure the retrieved frames suffice to support claims.
- Assumptions/Dependencies: Access to stored video archives; integration with VMS time indexing; domain adaptation to camera viewpoints and lighting; privacy/compliance constraints.
- Industry — Manufacturing Process Verification
- Use case: Verify that multi-step procedures (e.g., PPE compliance, lockout–tagout, assembly sequences) occurred in the correct order; flag missing or out-of-order steps.
- Sector: Manufacturing, energy, logistics.
- Tools/Workflows: Temporal policy that issues targeted tool_calls (time windows + queries) to fetch minimal evidence; CSV re-answering to validate sufficiency of evidence before alerting.
- Assumptions/Dependencies: Sufficient camera coverage; procedure templates; acceptable false positive/negative rates for QA; change management with operators.
- Media and Entertainment — Highlighting and Editing Assist
- Use case: Automatic highlight extraction and scene-based indexing for sports broadcasts, livestreams, and long-form content; “find all scenes where Player X celebrates” with grounded clips.
- Sector: Sports analytics, broadcast, post-production.
- Tools/Workflows: Interleaved reasoning to hypothesize events, search supporting frames, and assemble a highlight reel; plug-in for NLEs to produce time-stamped shot-lists.
- Assumptions/Dependencies: Production metadata (teams/players) boosts precision; consistent camera angles and predictable event semantics improve reliability.
- Enterprise Knowledge — Meeting and Training Video QA
- Use case: Ask questions of multi-hour meeting recordings or training sessions; retrieve minimal set of frames supporting the answer; verify consistency with CSV.
- Sector: Software, consulting, enterprise enablement.
- Tools/Workflows: “Ask-your-video” assistant embedded in meeting platforms; hybrid use of transcripts + temporal visual search to disambiguate references (e.g., diagrams, whiteboards).
- Assumptions/Dependencies: Accurate time-aligned transcripts improve coverage; data governance and access control.
- Healthcare (retrospective) — Surgical Video Review and Training
- Use case: Retrospective QA of surgical procedures to locate key events (incision, instrument exchanges, critical steps) with evidence-backed reasoning chains for training/peer review.
- Sector: Healthcare, medical education.
- Tools/Workflows: Offline batch processing of OR recordings; CSV ensures searched frames alone justify the assessment; timeline summaries of step adherence.
- Assumptions/Dependencies: Institutional approvals; domain-specific fine-tuning; stringent privacy/PHI safeguards; no claims of diagnostic use.
- Academia and R&D — Reusable Training and Evaluation Pipelines
- Use case: Adopt GRPO-CSV to stabilize RL for multimodal reasoning; reuse the paper’s two-stage data filtering pipeline to remove trivial/unsolvable samples in new domains.
- Sector: ML research, CV/NLP labs.
- Tools/Workflows: Open-source TimeSearch-R codebase; pluggable CSV reward; determinantal point processes (DPP) for informative frame sampling; group-based RL (GRPO).
- Assumptions/Dependencies: GPU resources for RL; reliable LLM-as-a-Judge for open-ended accuracy scoring or domain-appropriate graders; curated datasets.
- Ecology and Scientific Video — Rapid Triage of Long Recordings
- Use case: Camera-trap and lab observation triage (e.g., “find all predator–prey interactions,” “locate grooming behavior episodes”) with minimal frames.
- Sector: Ecology, animal behavior, neuroscience.
- Tools/Workflows: Hypothesis-driven search; CSV to confirm completeness before committing annotations; human-in-the-loop QA.
- Assumptions/Dependencies: Species/action ontologies; varied lighting and weather; potential domain-specific pretraining.
- Content Safety and Moderation — Policy Violation Localization
- Use case: Triage long videos to locate potential policy violations (e.g., weapons, self-harm cues) and surface the supporting frames for reviewer escalation.
- Sector: Trust and Safety, social media platforms.
- Tools/Workflows: Tiered moderation where TimeSearch-R preselects time windows and frames; reviewer sees the interleaved chain-of-thought and evidence to accelerate decisions.
- Assumptions/Dependencies: Clear policy taxonomies; calibration to minimize harm from false positives; periodic audits for bias.
- Legal and Insurance — Evidence Discovery in Video
- Use case: E-discovery and claims validation from bodycams, dashcams, and store cameras; retrieve key frames and verify sufficiency via CSV before legal review.
- Sector: Legal tech, insurance claims.
- Tools/Workflows: Time-indexed retrieval portal with exportable evidence packets; audit trails of the model’s search decisions.
- Assumptions/Dependencies: Chain-of-custody requirements; explainability and reproducibility; jurisdictional privacy laws.
- Developer Tools — Edge Prefiltering and Cost Control
- Use case: Reduce bandwidth and compute by running the paper’s small-VLM similarity + DPP frame selection on edge devices, forwarding only informative frames.
- Sector: IoT, embedded systems.
- Tools/Workflows: Lightweight frame-scorer daemon; configurable time-window queries generated by a central LVLM.
- Assumptions/Dependencies: Edge compute budget; memory constraints; secure model updates.
Long-Term Applications
These opportunities likely require further research, scaling, integration, or regulation before deployment.
- Real-time, On-device Temporal Search for Autonomy
- Use case: Robots, drones, and autonomous vehicles performing hypothesis-driven temporal search on streaming video to guide actions and recall recent context.
- Sector: Robotics, automotive, defense, disaster response.
- Tools/Workflows: Closed-loop “Think–Search–Act–Verify” with hard real-time constraints; streaming GRPO-CSV variants.
- Assumptions/Dependencies: Low-latency inference; power-efficient LVLMs; safety certification; robust handling of distribution shift and occlusions.
- Healthcare (prospective) — In-Procedure Alerts and Guidance
- Use case: Live monitoring of OR feeds to alert about missing critical steps or instrument misplacement, with verifiable supporting frames.
- Sector: Healthcare.
- Tools/Workflows: Real-time temporal search and CSV gating of alerts to control false positives; integration with surgical platforms.
- Assumptions/Dependencies: Regulatory approval (e.g., FDA/CE); clinical validation; explainability and medico-legal frameworks.
- City-scale, Multicam Spatiotemporal Search
- Use case: Cross-camera, cross-duration reasoning (e.g., “track object/person across cameras and hours” with grounded evidence).
- Sector: Smart cities, transportation, public safety.
- Tools/Workflows: Distributed temporal-search orchestrators; identity/track linking; CSV to ensure evidence sufficiency before escalation.
- Assumptions/Dependencies: Re-identification robustness; governance and privacy-by-design; scalable storage and indexing.
- Privacy-preserving and Federated Video Reasoning
- Use case: Temporal search and self-verification performed locally, sharing only minimal, obfuscated evidence summaries for central analytics.
- Sector: Healthcare, finance, consumer devices.
- Tools/Workflows: Federated GRPO-CSV; encrypted evidence capsules; consent-aware policy enforcement.
- Assumptions/Dependencies: Federated optimization for RL; secure enclaves; standardized consent and audit tools.
- Multimodal Interleaved Reasoning Beyond Video
- Use case: Extend the “interleaved thinking + search + CSV” paradigm to audio streams, sensor logs, EHR time series, and code execution traces.
- Sector: DevOps, cybersecurity, industrial IoT, clinical informatics.
- Tools/Workflows: Generalized tool_call schema for time-indexed modalities; CSV-style re-answering with searched segments only.
- Assumptions/Dependencies: Modality-specific retrieval functions; ground-truth or surrogate judges; domain risk controls.
- Education — Skill Assessment from Student Lab and Shop Videos
- Use case: Automated assessment of procedural correctness in lab classes or skilled trades, with time-stamped evidence and feedback.
- Sector: Education, workforce training.
- Tools/Workflows: Curriculum-aligned temporal templates; CSV-backed feedback explaining missing steps.
- Assumptions/Dependencies: Fairness and accessibility safeguards; institutional policies; parent/guardian consent for minors.
- Broadcast and AR — Live Assistants with Temporal Memory
- Use case: Real-time sports commentary assistants and AR overlays that recall earlier plays/scenes, verify with CSV, and surface concise visual evidence.
- Sector: Media, consumer AR.
- Tools/Workflows: Low-latency interleaved search; overlay APIs; confidence-calibrated suggestions.
- Assumptions/Dependencies: Latency budgets; hardware acceleration; UX to avoid distraction.
- Scientific Discovery — High-throughput Behavioral Analytics
- Use case: Automated discovery of rare or sequential behaviors in ultra-long lab recordings (e.g., sleep studies, animal colonies), with auditable evidence.
- Sector: Life sciences, neuroscience.
- Tools/Workflows: Domain-specific ontologies; batched GRPO-CSV runs over petabytes; human-in-the-loop validation.
- Assumptions/Dependencies: Storage/compute scaling; ethical use of animal/human data; reproducibility standards.
- Policy and Governance — Auditable AI Video Review Pipelines
- Use case: Standards and regulatory frameworks for AI-assisted public records review (e.g., FOIA), mandating verifiable evidence trails and sufficiency checks like CSV.
- Sector: Government, legal policy.
- Tools/Workflows: Certification for “self-verified” evidence localization; audit logs of tool_calls and retrieved frames.
- Assumptions/Dependencies: Legislative adoption; transparency tooling; clear accountability lines.
Notes on Feasibility and Dependencies
- Model and compute: RL post-training with GRPO-CSV requires substantial GPU resources; production deployments benefit from model distillation and edge prefiltering.
- Integration: The temporal search relies on a retrieval function (e.g., SigLIP similarity + DPP sampling) and a tool_call schema; host platforms must support time-indexed retrieval.
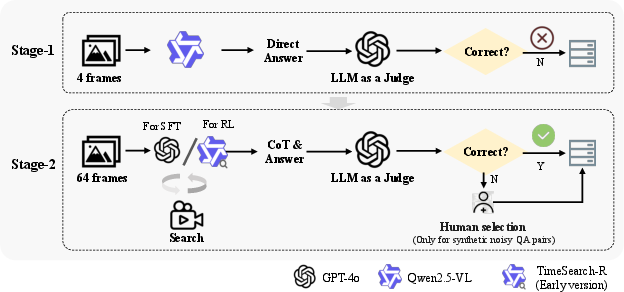
- Data quality: The two-stage filtering pipeline reduces trivial or unsolvable samples; similar curation is needed when porting to new domains to avoid RL collapse.
- Evaluation: For open-ended answers, LLM-as-a-Judge scoring is a dependency; domain-specific graders may be needed to reduce grading bias.
- Reliability and safety: Calibration, bias audits, and human-in-the-loop checkpoints are necessary, especially in policy, healthcare, and public safety.
- Privacy and compliance: Access controls, consent, encryption, and audit trails are prerequisites for regulated sectors; on-device/federated variants may be required.
- Generalization: Domain adaptation is needed for unusual viewpoints, low light, and occlusions; additional supervision (weak labels, ontologies) can accelerate transfer.
Glossary
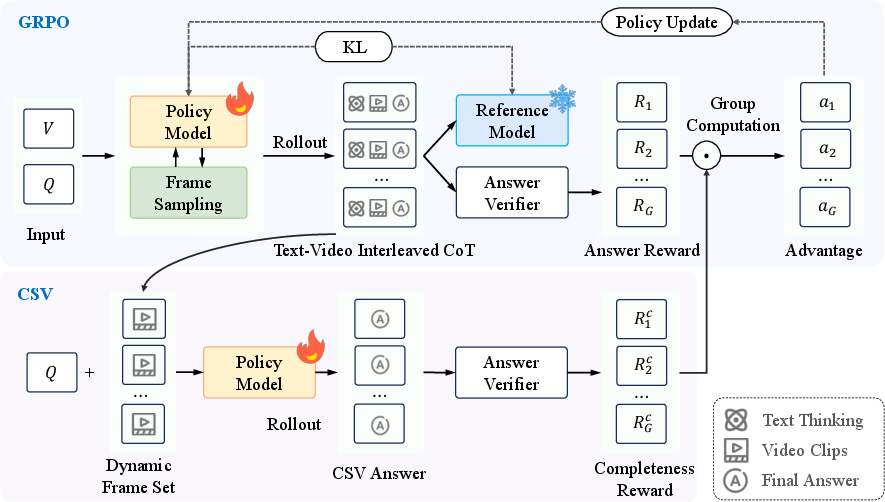
- AdamW: An optimizer that decouples weight decay from gradient updates to improve generalization. "In the RL training, we use the AdamW~\citep{loshchilov2017adamw} optimizer with a learning rate of 1e-6, a KL penalty coefficient = 0.005, and a batch size of 4 with 8 rollouts per prompt."
- Chain-of-Thought (CoT): A step-by-step reasoning trace the model generates to break down complex problems. "retrieving a clip that is appended to the ongoing chain of thought (CoT) as input for later steps."
- Completeness Self-Verification (CSV): A mechanism that re-answers using only the searched frames to verify sufficiency and consistency of evidence during RL. "we introduce GRPO with Completeness Self-Verification (GRPO-CSV), which gathers searched video frames from the interleaved reasoning process and utilizes the same policy model to verify the adequacy of searched frames"
- Determinantal Point Process (DPP): A probabilistic model that favors diverse subsets; used here to sample informative, non-redundant frames. "The most informative frames are then sampled using determinantal point process (DPP)"
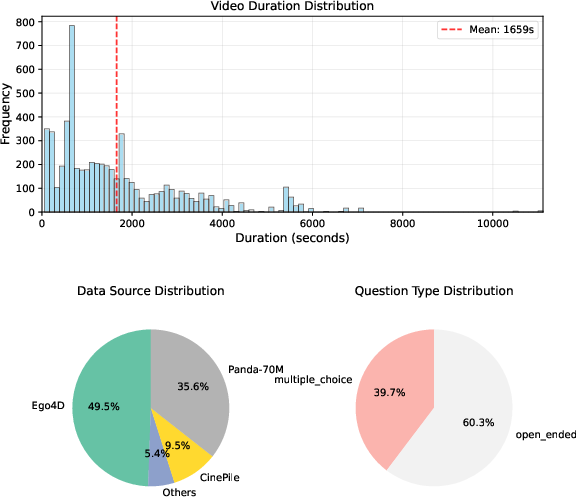
- Egocentric data: Video data captured from a first-person viewpoint. "After applying data filtering, the model trained solely on egocentric data recovers baseline performance, but the lack of diversity weakens the benefits of RL."
- End-to-end optimization: Training a system holistically so all components are learned jointly for the task. "lacking end-to-end optimization for learning optimal search strategies."
- Exocentric data: Video data captured from a third-person viewpoint. "By incorporating exocentric data to enhance domain diversity, the model achieves its best general QA accuracy of 66.6\%."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that uses group-relative outcome signals to optimize policies. "applying RL training methods, such as Group Relative Policy Optimization (GRPO), to video reasoning can result in unsupervised intermediate search decisions."
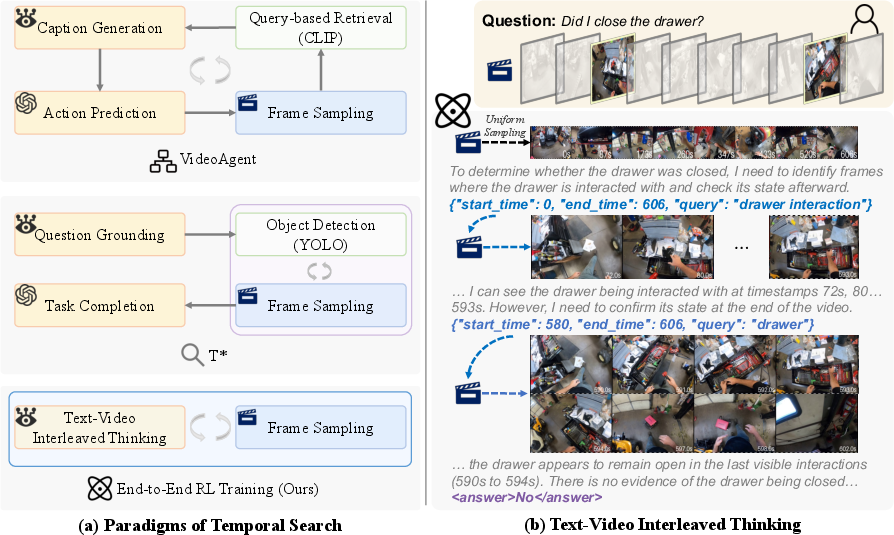
- Interleaved text-video thinking: A reasoning paradigm that alternates textual reasoning with temporal video search within a single process. "we reformulate the temporal search task as an interleaved text-video thinking process"
- KL penalty coefficient: The strength of the Kullback–Leibler regularization term that constrains policy updates during RL. "a KL penalty coefficient = 0.005"
- Large Video-LLMs (LVLMs): Foundation models that jointly process video and language inputs. "current large video-LLMs (LVLMs) primarily rely on hand-crafted search strategies with static frame sampling"
- LLM-as-a-Judge: Using a LLM to evaluate the semantic correctness of open-ended answers. "we adopt an LLM-as-a-Judge approach~\citep{ZhengC00WZL0LXZ23LLM-as-a-Judge} to assess the semantic agreement between the modelâs final answer and the reference answer."
- Needle-in-a-haystack: A challenging evaluation setup requiring locating small, relevant snippets within very long videos. "the task is modeled as long video needle-in-a-haystack, measuring temporal and visual similarity as well as QA accuracy."
- Outcome reward: A reward signal based solely on the correctness of the final output, without supervising intermediate steps. "We introduce CSV as a complement to GRPO with only outcome rewards."
- Policy model: The parameterized decision-maker that outputs reasoning steps and search actions in RL. "the policy model generates a textual reasoning ."
- Reinforcement learning (RL): A learning paradigm where an agent optimizes behavior via rewards obtained from interactions. "seamlessly integrating searching video clips into the reasoning process through reinforcement learning (RL)."
- Rollout phase: The stage in RL where trajectories are sampled from the current policy for computing rewards and updates. "During the GRPO rollout phase, the policy model generates a text-video interleaved CoT and a final answer ."
- Self-verification: A model-internal check to ensure sufficient evidence has been gathered for a reliable answer. "GRPO-CSV tackles insufficient temporal exploration by ensuring the model to acquire sufficient visual evidence through self-verification"
- SigLIP: A vision-language embedding model used to compute frame–text similarity for retrieval. "employing a small VLM (e.g., SigLIP~\citep{zhai2023siglip}) to calculate the similarity among frames within the specified temporal clip"
- Supervised Fine-Tuning (SFT): Training on labeled examples to adapt a pre-trained model to desired formats and behaviors. "In the first stage, supervised fine-tuning (SFT) serves as a cold start, guiding the model to follow the correct reasoning format"
- Temporal search: Selecting a minimal, relevant subset of frames from long videos to support reasoning. "Temporal search aims to identify a minimal set of relevant frames from tens of thousands based on a given query"
- Tree-structured search: A hierarchical exploration strategy that expands candidate regions in a tree to improve search efficiency. "strategies that introduce tree-structured search to improve efficiency have also been explored"
- Visual grounding: Ensuring answers are supported by specific visual evidence rather than language priors. "LVLMs may arrive at correct answers through partial evidence or language bias without proper visual grounding"
- Vision-LLM (VLM): A model that jointly understands visual inputs and text for multimodal tasks. "iteratively calls tools like vision-LLMs (VLMs) and CLIP"
Collections
Sign up for free to add this paper to one or more collections.

