PEARL: Geometry Aligns Semantics for Training-Free Open-Vocabulary Semantic Segmentation
Abstract: Training-free open-vocabulary semantic segmentation (OVSS) promises rapid adaptation to new label sets without retraining. Yet, many methods rely on heavy post-processing or handle text and vision in isolation, leaving cross-modal geometry underutilized. Others introduce auxiliary vision backbones or multi-model pipelines, which increase complexity and latency while compromising design simplicity. We present PEARL, \textbf{\underline{P}}rocrust\textbf{\underline{e}}s \textbf{\underline{a}}lignment with text-awa\textbf{\underline{r}}e \textbf{\underline{L}}aplacian propagation, a compact two-step inference that follows an align-then-propagate principle. The Procrustes alignment step performs an orthogonal projection inside the last self-attention block, rotating keys toward the query subspace via a stable polar iteration. The text-aware Laplacian propagation then refines per-pixel logits on a small grid through a confidence-weighted, text-guided graph solve: text provides both a data-trust signal and neighbor gating, while image gradients preserve boundaries. In this work, our method is fully training-free, plug-and-play, and uses only fixed constants, adding minimal latency with a small per-head projection and a few conjugate-gradient steps. Our approach, PEARL, sets a new state-of-the-art in training-free OVSS without extra data or auxiliary backbones across standard benchmarks, achieving superior performance under both with-background and without-background protocols.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
PEARL: a simple explanation for teens
What is this paper about?
This paper is about teaching a computer to color every pixel in a picture with the right label (like “sky,” “road,” “cat,” or “backpack”) even when the list of labels is given at the last minute using plain words. This task is called open-vocabulary semantic segmentation. “Open-vocabulary” means you can name any categories you want using text. “Training-free” means the method works without teaching the model anything new—it uses an existing vision–LLM (like CLIP) as-is.
The paper introduces a method called PEARL that makes this work better and cleaner without extra training or extra helper models.
What questions does the paper try to answer?
In simple terms:
- How can we get sharper, more accurate pixel labels without retraining big models?
- Can we fix the way a model “looks” at image parts so it focuses less on background noise and more on actual objects?
- Can we use the meanings of words (like “car,” “truck,” “road”) to guide how labels spread across the image, so related classes help each other and edges are respected?
How does the method work?
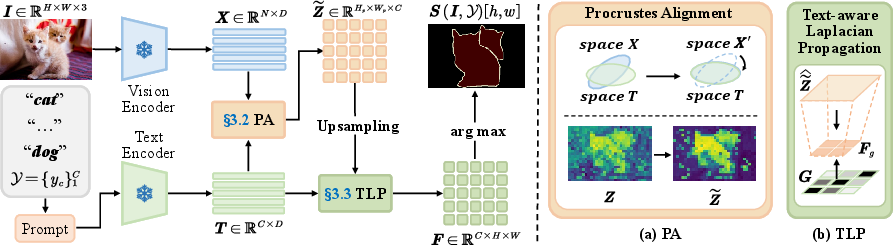
PEARL is a two-step, plug-and-play add-on that you run at test time. Think of it as “align, then smooth.”
- Align: Procrustes alignment in self-attention
- Analogy: Imagine comparing two maps that are slightly rotated relative to each other. If you rotate one to line up with the other, it’s easier to match places.
- Inside the model’s last attention layer, the method gently “rotates” one set of features (called “keys”) to better line up with another set (“queries”). This uses an orthogonal alignment (a fancy term for rotation without stretching).
- Why this helps: In CLIP-like models, the top layers are great at matching whole images to words, but not perfect at lining up tiny patches of the image. Background patterns can overwhelm object details. The rotation step fixes the geometry so patches compare to text more fairly and focus is less “blurry.”
- Smooth: Text-aware Laplacian propagation
- Analogy: After you color a map, you might smooth uneven areas, but you wouldn’t paint across borders like rivers or walls.
- The method refines per-pixel scores on a small grid. It spreads label confidence between neighboring pixels but:
- Respects image edges (so labels don’t leak across clear boundaries like object edges).
- Uses text relationships (so related labels, like “car” and “truck,” can support each other, while unrelated ones, like “car” and “sky,” don’t get mixed up).
- Trusts pixels with strong evidence more than uncertain ones.
- Technically, this is a simple, fast “graph solve”: think of it as gently averaging the labels where it makes sense, guided by both the image and the meanings of the words.
Both steps are training-free, add little extra time, and don’t require extra data or extra models.
What did they find, and why does it matter?
PEARL achieves state-of-the-art results among training-free methods that don’t use extra helper backbones. In practice, that means:
- Cleaner attention: the model looks at the right parts of objects, not the background.
- Better masks: fewer holes in objects, less “spilling” onto the background, and better preservation of thin structures (like poles or bicycle spokes).
- Strong numbers: across common benchmarks (like PASCAL VOC, Pascal Context, Cityscapes, COCO, and ADE20K), PEARL often scores the best or near the best among comparable training-free methods, all while staying simple and fast.
Why this is important:
- You can switch to new label sets on the fly (“open vocabulary”) without retraining.
- You get higher-quality pixel labeling with almost no extra cost.
- It keeps the system simple—no add-on models or extra training pipelines.
What’s the bigger impact?
PEARL shows you can improve pixel-level understanding just by:
- Fixing how the model compares parts of the image (alignment), and
- Using language meaning to guide how labels spread (text-aware smoothing).
This could help apps that need quick, flexible image understanding, like:
- Photo editing (“color all the roads darker”),
- Robot vision (“find all the tools on the table”),
- Medical or scientific imaging where labels change by task.
Limitations and future directions:
- Results depend on good label names and prompts.
- Very subtle boundaries are still tough.
- The method isn’t “instance-aware” (it doesn’t separate two overlapping objects of the same class yet).
- Future work could improve prompts, adapt the grid size automatically, or add ways to tell separate instances apart.
Overall, PEARL is a neat, practical upgrade: it makes existing vision–LLMs better at pixel-level tasks without any retraining, by first lining up their “view” and then spreading label information in a smart, text-aware way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- Layer placement and scope of alignment: Only the last self-attention block is modified. Does applying Procrustes alignment earlier, at multiple blocks, or selectively per layer/head yield better gains or unintended side effects?
- What to align: The method rotates keys only. Would aligning queries, values, or both (e.g., symmetric K–Q alignment, aligning V to preserve value geometry) improve stability without harming diversity?
- Centering strategy: Weighted centering uses πn ∝ ||qn|| and optionally drops CLS. How sensitive is performance to this choice? Are alternatives (robust centering, whitening/ZCA, per-head normalization, CLS reweighting) better across datasets?
- Head-wise diversity: Does Procrustes reduce inter-head diversity (and thus expressivity)? A quantitative analysis of attention diversity and head specialization under alignment is missing.
- Theoretical characterization: Formal conditions under which orthogonal Procrustes improves attention scores (e.g., bounds on softmax stability, relation to canonical correlation) are not provided.
- Numerical stability and implementation: The paper mentions SVD or polar iterations but does not analyze convergence/stability trade-offs, tolerance settings, or hardware variability for very large backbones.
- Per-window vs per-image alignment: Sliding-window inference is used, but it is unclear whether the orthogonal map R is computed per window or globally. Do per-window alignments introduce seam artifacts or inconsistent geometry across overlaps?
- Hyperparameter sensitivity in TLP: The effects of τs, λ, κ, ε, τ, grid size, and CG iteration count are not systematically analyzed. Automatic or data-driven parameter selection is not explored.
- Scaling to very large label sets: TLP builds a class graph G ∈ ℝC×C from text embeddings. How does memory/latency scale when C≫200 (e.g., LVIS or user-defined vocabularies)? Are sparse kNN graphs, low-rank approximations, or on-the-fly updates viable?
- Negative/repulsive relations: G is row-softmax of T T⊤ plus identity and edge gates are clipped to [0,1], disallowing repulsion. Can modeling mutual exclusion or negative edges prevent label bleeding between semantically close but visually distinct classes?
- Confidence weighting: ρi ∝ γi2(1+ui) may overweight popular or easy classes. Does this induce hubness or suppress rare categories? Alternative calibrations (e.g., temperature scaling, entropy-based weights) are untested.
- Boundary cues: TLP relies on grayscale gradients for edge weights, which struggles in low-contrast regions. Can self-supervised edges, learned boundary detectors, depth/normal cues, or multi-spectral signals improve boundary preservation?
- Grid design: A fixed, manually chosen grid size trades detail for cost. Adaptive grids (e.g., superpixels, quadtree/mesh refinement around edges or high-uncertainty areas) are not investigated.
- Prompt dependence and ambiguity: Results depend on single-template prompts. Effects of prompt ensembling, class-specific templates, prompt calibration, negative prompts, or multi-lingual prompts remain unexplored.
- Fine-grained and ambiguous taxonomies: ADE20K errors suggest confusion among related “stuff” categories. Strategies for disambiguation (contextual prompts, relations/attributes, hierarchical label constraints) are untested.
- Background modeling: No explicit background prototype or background-cleaning mechanism is used. Can lightweight background priors or adaptive background prototypes improve “things-only” settings (e.g., COCO-Object)?
- Instance awareness: The method is semantic (category-level) only. How to add instance cues (e.g., unsupervised grouping, depth/edge-aware seeds, motion in video) without training while preserving the plug-and-play nature?
- Temporal consistency: Extensions to video (spatiotemporal Laplacian, optical-flow-guided gates, temporal confidence) are not examined.
- Domain robustness: Generalization is evaluated on standard benchmarks only. Robustness under domain shift (night/rain, medical, satellite, artwork) and to common corruptions (noise, blur, compression) is unknown.
- Multi-scale and TTA: The pipeline uses single-scale inference. How do multi-scale/flip test-time augmentations interact with alignment and TLP (e.g., consistency across scales, latency trade-offs)?
- Backbone coverage: Experiments focus on CLIP ViT variants; other VLMs (OpenCLIP, SigLIP, EVA-CLIP), CNN-ViT hybrids, or larger ViT-H/G backbones are largely unexplored, especially regarding runtime of per-head SVD/polar steps.
- Vocabulary dynamics: Handling dynamic user-defined label sets at interactive speeds is not analyzed (e.g., incremental updates to G, amortized computation as classes are added/removed).
- Interoperability with other training-free modules: While TLP boosts SCLIP/NACLIP/SFP, interactions with other components (DenseCRF/PAMR, DINO/SAM objectness, head selection, entropy filtering) are only partially explored.
- Failure analysis: A detailed, per-class confusion analysis (e.g., where propagation helps/hurts, small-object IoU, thin-structure metrics) is missing, limiting targeted improvements.
- Fairness and bias: Text-space biases in CLIP propagate into G and neighbor gates, but bias amplification and mitigation strategies (e.g., debiasing prompts/graphs) are not discussed.
- Resource-constrained deployment: Memory/latency are reported for a single GPU and moderate resolutions. Performance on high-res inputs (4K), mobile/edge devices, and batch/streaming scenarios is not evaluated.
Practical Applications
Immediate Applications
These applications can be deployed now because PEARL is training-free, plug-and-play, and adds minimal latency when integrated into CLIP-style pipelines.
- Open-vocabulary segmentation API and SDKs (Software/AI products)
- Use case: Build a “Prompt-to-Mask” service that segments any user-specified category (e.g., “asphalt”, “power lines”, “backpack”) without retraining.
- Tools/workflows: Wrap Procrustes alignment + text-aware Laplacian propagation (TLP) as an inference module for CLIP ViT-B/16; expose REST/ONNX runtimes for server and edge.
- Assumptions/dependencies: Requires a CLIP-like VLM encoder; prompt quality affects accuracy; not instance-aware (semantic masks only).
- Rapid dataset bootstrapping and weak supervision (Academia/ML Ops)
- Use case: Auto-generate semantic masks for new taxonomies to pre-label datasets; reduce manual segmentation and accelerate closed-set training.
- Tools/workflows: Batch inference over unlabelled corpora; human-in-the-loop correction; prompt banks for consistent label phrasing; per-project prompt calibration.
- Assumptions/dependencies: Quality varies by domain shift and prompt wording; thin structures improve but low-contrast edges remain hard.
- Content-aware editing and rotoscoping by text prompts (Media/design/advertising)
- Use case: “Remove background sky”, “isolate hair”, “highlight signage” for image and frame-wise video editing.
- Tools/workflows: Photoshop/After Effects plug-ins; timeline-aware processing via frame-by-frame masks; compositor pipelines use PEARL masks as mattes.
- Assumptions/dependencies: Frame consistency not guaranteed (no temporal modeling); may require light smoothing or tracking for video.
- Privacy redaction and compliance (Policy/compliance, Security)
- Use case: Mask “faces”, “license plates”, “badges”, or “weapons” on the fly in user-generated content or bodycam footage.
- Tools/workflows: On-device redaction using CLIP + PEARL; rule-based prompt sets; audit logs for masked regions.
- Assumptions/dependencies: False positives/negatives must be monitored; no instance differentiation; high-stakes contexts require human review.
- Visual search and catalog curation (E-commerce/retail)
- Use case: Automatically segment “handbags”, “sneakers”, “sleeves” for background removal, product cut-outs, and AR try-on previews.
- Tools/workflows: Batch pipeline for catalog photos; interactive UI with text prompts; rapid adaptation to new product taxonomies.
- Assumptions/dependencies: Works best on natural images; domain-specific styling may reduce accuracy without careful prompting.
- Map labeling and scene parsing for operations planning (Smart cities/Autonomy; offline use)
- Use case: Offline processing of street scenes to segment “road”, “sidewalk”, “barricade”, “construction cone” when taxonomies change.
- Tools/workflows: Batch inference over dashcam datasets; dynamic category sets per project; export masks for GIS or HD map tools.
- Assumptions/dependencies: Not validated for safety-critical real-time; background-cleaning heuristics not included; open-vocab ambiguity persists.
- Teleoperation and human-in-the-loop robotics overlays (Robotics)
- Use case: Operator UI that highlights arbitrary objects (“wrench”, “valve”, “spill”) on request to assist remote manipulation or inspection.
- Tools/workflows: Lightweight inference on an edge GPU; clickable prompt presets; overlay masks on video feeds.
- Assumptions/dependencies: Domain shift (industrial scenes) may degrade CLIP features; not suitable for autonomous, safety-critical decisions.
- Accessible scene descriptions and educational tools (Accessibility/Education)
- Use case: Region-wise descriptions guided by text masks (e.g., “highlight traffic signs and describe them”); classroom demos of open-vocab vision.
- Tools/workflows: Combine masks with captioning to generate structured alt text; interactive notebooks for teaching segmentation.
- Assumptions/dependencies: Relies on captioner quality; semantics can be ambiguous without prompt engineering.
- Quality improvement for existing training-free methods (Research/Engineering)
- Use case: Drop-in TLP module to lift mask coherence for current CLIP-based systems (e.g., SCLIP, NACLIP, SFP).
- Tools/workflows: Insert TLP after logit computation; reuse existing prompts and encoders; small number of conjugate-gradient iterations.
- Assumptions/dependencies: Gains depend on baseline quality; grid size must be tuned to content scale (trade-off accuracy vs. cost).
Long-Term Applications
These applications require further research, domain-specific models, scaling, or additional modules (e.g., instance or temporal reasoning) before robust deployment.
- Instance-aware and panoptic open-vocabulary segmentation (Software/Autonomy/Robotics)
- Future product: Open-vocab panoptic pipelines that combine PEARL’s semantics with instance grouping and tracking.
- Needed advances: Instance grouping and count-aware mechanisms; integration with detectors/trackers; evaluation on open-set benchmarks.
- Assumptions/dependencies: Reliable instance cues and temporal consistency beyond current semantic-only PEARL.
- Real-time video segmentation with temporal propagation (AR/VR, Broadcasting, Autonomy)
- Future product: Live “prompt-to-mask” video filters and HUDs operating at 30–60 fps with temporal stability.
- Needed advances: Spatio-temporal Laplacian propagation, fast polar iterations, model quantization, and caching across frames.
- Assumptions/dependencies: Hardware acceleration on mobile/AR devices; robust handling of motion blur and occlusions.
- Domain-specific open-vocab perception (Healthcare, Manufacturing, Remote sensing)
- Future product: Training-free segmentation for specialized domains (e.g., “tumor core”, “defect crack”, “flooded field”) using domain VLMs.
- Needed advances: CLIP-like encoders pre-trained on domain corpora (MedCLIP, industrial CLIPs, satellite VLMs); prompt ontologies; validation.
- Assumptions/dependencies: Current CLIP (natural images) is insufficient for medical/industrial modalities; regulatory approval for clinical use.
- Autonomous driving production deployment (Automotive)
- Future product: Flexible taxonomy updates in perception stacks (e.g., new road furniture classes) without retraining.
- Needed advances: Extensive safety validation, background filtering, instance-level tracking, sensor fusion (LiDAR/radar), and fail-safe logic.
- Assumptions/dependencies: Must satisfy real-time constraints and safety standards; PEARL currently optimized for offline/analysis.
- Large-scale data governance and content moderation (Policy/Compliance)
- Future product: Enterprise pipelines that auto-mask sensitive categories with auditable, explainable decisions and taxonomy updates on the fly.
- Needed advances: Prompt governance frameworks, human-in-the-loop review, bias auditing, and provenance tracking for redactions.
- Assumptions/dependencies: Policy alignment and risk controls; handling of adversarial or ambiguous content.
- Human-robot collaboration with language-guided tasking (Robotics/Industry 4.0)
- Future product: Workers specify objects and workspace regions in natural language for on-the-fly segmentation that informs grasping and safety zones.
- Needed advances: Coupling to grasp planners and safety monitors; open-vocab affordance understanding; domain-tuned VLMs.
- Assumptions/dependencies: Real-time guarantees and robust open-set recognition under variable lighting and clutter.
- Multimodal AR assistants and scene understanding (AR/VR, Consumer tech)
- Future product: Wearable assistants that “highlight exits”, “find recycling bins”, or “mask reflective surfaces” via open-vocab segmentation.
- Needed advances: On-device acceleration, low-power inference, temporal consistency, and personalization of prompts and semantics.
- Assumptions/dependencies: Robustness to egocentric motion and diverse environments; user privacy safeguards.
- Research tools for prompt engineering and taxonomy design (Academia/Standards)
- Future product: Prompt calibration suites, text-graph editors, and evaluation dashboards for open-vocabulary segmentation systems.
- Needed advances: Methods to reduce prompt sensitivity (e.g., ensembles, retrieval-augmented prompts) and to exploit class-relationship graphs more effectively.
- Assumptions/dependencies: Community datasets with standardized open-vocab protocols; interpretability research.
- Energy-efficient and edge-native implementations (Energy/Embedded systems)
- Future product: FPGA/ASIC implementations of Procrustes alignment (polar iteration) and TLP (sparse CG solver) for drones/IoT cameras.
- Needed advances: Hardware-friendly approximations, mixed-precision arithmetic, and memory-efficient token handling.
- Assumptions/dependencies: Co-design with encoder backbones; careful accuracy–efficiency trade-offs.
- Assisted scientific imaging and environmental monitoring (Science/Climate)
- Future product: Rapid, label-flexible segmentation for field expeditions (e.g., “algal bloom”, “erosion scar”, “coral bleaching”).
- Needed advances: Domain-adapted VLMs for aerial/satellite/underwater imagery; robust prompts and uncertainty estimates.
- Assumptions/dependencies: Address domain shift and low-contrast structures; integrate geo-referencing and temporal change detection.
Cross-cutting assumptions and dependencies
- Requires a CLIP-like vision–language backbone with access to the last self-attention block for Procrustes alignment; TLP needs only logits and image gradients.
- Performance depends on prompt wording and class names; prompt calibration or ensembles may be necessary for reliability.
- Not instance-aware and not temporally consistent out of the box; safety-critical use demands further modules and validation.
- Low-contrast boundaries and heavy domain shifts can degrade quality; grid size for TLP trades detail for compute and must be tuned per use case.
Glossary
- 4-connected graph: A grid graph where each node connects to its immediate up, down, left, and right neighbors; used to define neighborhood structure for propagation. "On each grid node i of a 4-connected graph G=(V,E)"
- Adaptive pooling: Downsampling that aggregates values to a fixed-size grid regardless of input dimensions. "They are averaged on a small grid of size H_g×W_g (adaptive pooling)"
- Attention head: One of multiple parallel subspaces in multi-head attention that computes its own attention patterns. "select informative attention heads"
- Attention map: A visualization or matrix showing how attention weights distribute across tokens for a given query. "we compare the attention maps produced by CLIP, NACLIP, and our PEARL."
- Bilinear upsampling: Resizing method that interpolates pixel values linearly in both dimensions. "Z is bilinearly upsampled to image resolution"
- CLS token: A special classification token in Transformers used to aggregate global information. "including the CLS token"
- Conjugate-gradient: An iterative algorithm for solving large symmetric positive definite linear systems. "a few conjugate-gradient steps."
- Contrastive pretraining: Training paradigm where models learn by pulling matched pairs together and pushing mismatched pairs apart in embedding space. "Contrastive pretraining emphasizes global image-text agreement rather than dense prediction."
- Cosine similarity: A normalized dot product measuring angle-based similarity between vectors. "computes cosine similarity between dense CLIP features and text prompts."
- Cross-covariance: A matrix capturing the covariance between two sets of variables; used here to compute the Procrustes rotation. "The optimizer is the orthogonal factor of the cross-covariance."
- Cross-modal geometry: The geometric relationship between representations from different modalities (e.g., text and vision). "leaving cross-modal geometry underutilized."
- DenseCRF: A dense Conditional Random Field used as a post-processing step to refine segmentation boundaries. "no DenseCRF or PAMR refinement is used"
- Graph Laplacian: Matrix encoding a graph’s structure that penalizes differences across edges; central to diffusion/propagation. "Let L be the weighted graph Laplacian of G"
- Logits: Raw, unnormalized scores output by a model before applying a normalization like softmax. "The text-aware Laplacian propagation then refines per-pixel logits"
- Mean Intersection-over-Union (mIoU): A standard segmentation metric averaging IoU over classes. "All metrics are mIoU (%)"
- Newton–Schulz iterations: An iterative method to compute matrix inverses or matrix factors like the polar factor. "a few Newton-Schulz iterations on the polar factor for an SVD-free implementation."
- Normal equations: Linear system derived from minimizing a quadratic objective in least-squares problems. "The resulting normal equations are:"
- Open-vocabulary semantic segmentation (OVSS): Assigning pixel-level labels from arbitrary, at-inference-time categories using text prompts. "Training-free open-vocabulary semantic segmentation (OVSS) promises rapid adaptation to new label sets without retraining."
- Orthogonal map: A linear transformation that preserves lengths and angles (a rotation/reflection). "a single orthogonal map computed per head and per input"
- Orthogonal projection: Projection onto a subspace using an orthogonal operator, preserving angles in the target subspace. "performs an orthogonal projection inside the last self-attention block"
- Orthogonal Procrustes problem: Finding the closest orthogonal matrix that aligns one set of vectors to another. "An orthogonal Procrustes problem aligns keys to queries:"
- Patch tokens: Token embeddings corresponding to image patches in a Vision Transformer. "a frozen ViT vision encoder yields patch tokens."
- Pixel accuracy (pAcc): The percentage of correctly classified pixels. "using average pixel accuracy (pAcc, %)"
- Polar factor: The orthogonal component in the polar decomposition of a matrix. "on the polar factor"
- Polar iteration: Iterative procedure to compute the polar decomposition (orthogonal factor). "via a stable polar iteration."
- Procrustes alignment: Aligning one set of vectors to another via an optimal orthogonal transform to correct geometric mismatch. "We present PEARL, Procrustes alignment with text-aware Laplacian propagation"
- Query–Key–Value (Q, K, V): The three vector sets used in attention: queries attend to keys to combine values. "linear projections produce Q, K, V"
- Row-softmax: Applying softmax independently to each row of a matrix. "row-softmax applies a softmax independently to each row"
- Self-attention: Mechanism where tokens attend to each other to aggregate context within a sequence. "applies multi-head self-attention."
- Sliding-window inference: Processing large images by tiling them into overlapping crops and fusing the results. "We adopt sliding-window inference with a 224×224 crop and stride 112"
- Spectral cues: Signals derived from spectral (eigen) analysis of features/graphs that capture global structure. "through spectral cues or multi-model assemblies"
- Symmetric positive definite: Property of a matrix indicating all eigenvalues are positive and the matrix is symmetric, ensuring unique solutions and CG applicability. "which are symmetric positive definite when at least one ρ_i>0."
- Temperature (softmax temperature): A scaling factor controlling the sharpness of softmax distributions. "τ_s>0 is a temperature"
- Text-aware Laplacian propagation: Refinement that spreads label evidence across an image guided by both text-derived class relations and image edges. "The text-aware Laplacian propagation then refines per-pixel logits"
- Text-consistency gate: A weighting factor modulating propagation between neighbors based on semantic agreement in text space. "receive an image edge strength and a text-consistency gate"
- Text prototypes: Embedding vectors representing class names/prompts used for matching with visual features. "text prototypes provide the semantic anchor"
- Unit-norm: Vectors normalized to have length one, often used to stabilize cosine-based comparisons. "to unit-norm prototypes"
- Vision-language backbone: The core pretrained network jointly embedding images and text used without fine-tuning. "a frozen vision-language backbone"
- Vision-LLM (VLM): A model jointly trained on image–text pairs to align their embeddings. "contrastive vision-LLMs (VLMs) such as CLIP and ALIGN"
- Vision Transformer (ViT): A Transformer architecture applied to image patches for vision tasks. "using the CLIP ViT-B/16 vision encoder."
- Zero-shot: Making predictions for classes unseen during training by leveraging auxiliary information like text. "built on zero-shot scene parsing"
Collections
Sign up for free to add this paper to one or more collections.