Mitigating Objectness Bias and Region-to-Text Misalignment for Open-Vocabulary Panoptic Segmentation
Abstract: Open-vocabulary panoptic segmentation remains hindered by two coupled issues: (i) mask selection bias, where objectness heads trained on closed vocabularies suppress masks of categories not observed in training, and (ii) limited regional understanding in vision-LLMs such as CLIP, which were optimized for global image classification rather than localized segmentation. We introduce OVRCOAT, a simple, modular framework that tackles both. First, a CLIP-conditioned objectness adjustment (COAT) updates background/foreground probabilities, preserving high-quality masks for out-of-vocabulary objects. Second, an open-vocabulary mask-to-text refinement (OVR) strengthens CLIP's region-level alignment to improve classification of both seen and unseen classes with markedly lower memory cost than prior fine-tuning schemes. The two components combine to jointly improve objectness estimation and mask recognition, yielding consistent panoptic gains. Despite its simplicity, OVRCOAT sets a new state of the art on ADE20K (+5.5% PQ) and delivers clear gains on Mapillary Vistas and Cityscapes (+7.1% and +3% PQ, respectively). The code is available at: https://github.com/nickormushev/OVRCOAT

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers to understand everything in a picture at once, even objects they’ve never been trained to recognize. The task is called panoptic segmentation: the computer has to label every pixel in an image and also separate individual objects (like each person, each car) from background stuff (like road, sky).
The twist: real life has far more object types than any training set. So the authors build a method, called OVRCOAT, that helps models find and name objects that weren’t in their training list, while still doing well on known objects.
What problem are they trying to solve?
Here are the main questions the paper tackles:
- How do we stop models from ignoring “unknown” objects? Many systems learn a sense of “objectness” only from a fixed set of categories. At test time, they often throw away good masks (object outlines) for new categories and call them “background.”
- How can we make vision–LLMs like CLIP (which are great at matching whole images to words) better at understanding smaller regions or parts of images? CLIP wasn’t originally trained to label precise object regions, so it can mislabel parts.
How does their method work?
Think of the system as a two-step helper for an existing segmentation model:
- The base model proposes object “masks,” which are like cookie cutters showing where each object might be.
- OVRCOAT adds two simple modules to make better decisions about which masks to keep and what to call them.
To make this more intuitive, here are the two modules with everyday analogies:
- COAT: Fixing the “objectness” gate
- Problem: There’s a “bouncer at the door” (the objectness gate) deciding which masks are real objects. Because it was trained only on a limited guest list (known categories), it often turns away new but valid guests (unknown categories).
- Idea: Ask CLIP for a second opinion. CLIP is like a well-traveled friend who’s seen lots of images and words. If CLIP thinks a mask likely matches any name in the test vocabulary, COAT raises the chance that the mask is a real object.
- Effect: Fewer good masks get incorrectly rejected as background, especially for objects the model has never seen during training.
- OVR: Teaching CLIP to look closely at regions, not just whole images
- Problem: CLIP is great at matching an entire picture to a label, but not as good at matching small regions (like just the painting on a wall).
- Idea: Fine-tune CLIP gently so its features line up better with mask regions and text labels. This is done in two stages:
- Stage 1: Keep CLIP mostly frozen and train the mask-making part so it proposes good regions.
- Stage 2: Unfreeze most of CLIP (but keep a few layers frozen) and train it together with the mask-maker so region features match class names better.
- Effect: CLIP becomes better at naming both known and unknown objects when looking at the masked region, not just the whole image.
In short: COAT helps decide which masks are real objects; OVR helps name them more accurately.
What did they find?
The authors tested on tough, real-world datasets where many categories aren’t in the training set:
- ADE20K: +5.5% improvement in the main score (Panoptic Quality, or PQ) compared to the previous best method.
- Mapillary Vistas: +7.1% PQ.
- Cityscapes: +3% PQ.
Why this matters:
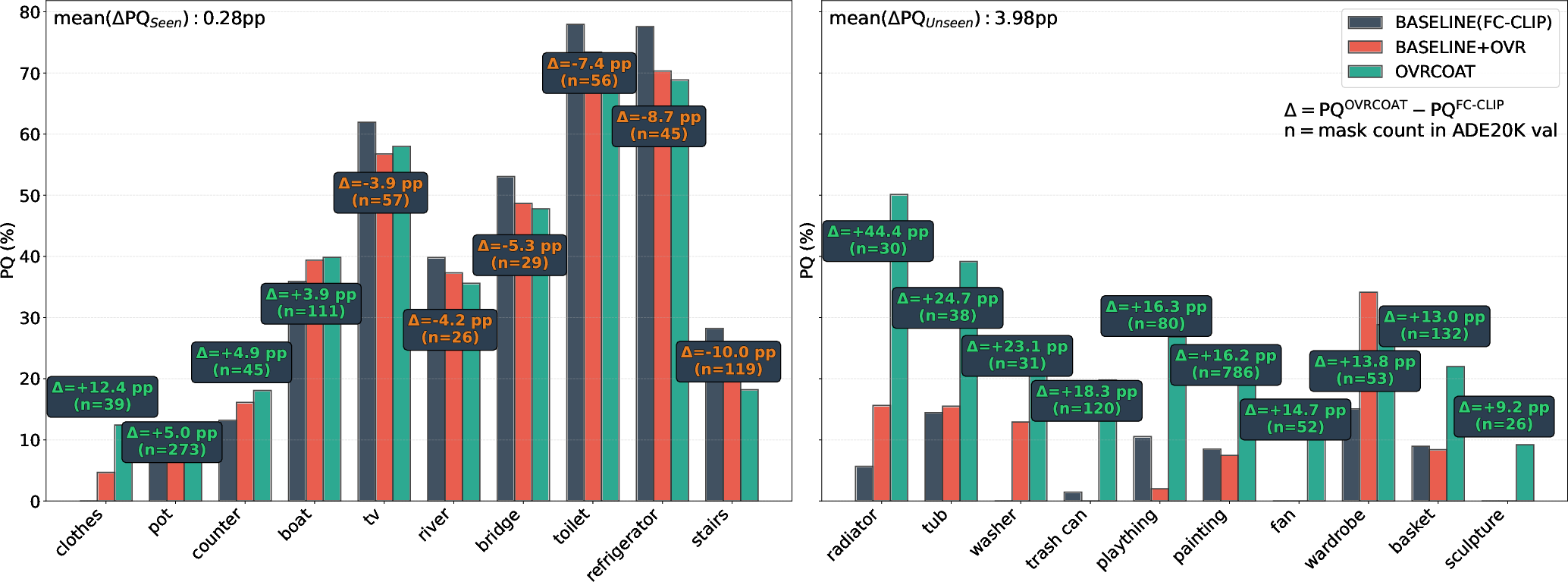
- Better at unseen objects: The method stops throwing away valid masks for new categories (for example, recognizing “paintings” even if “painting” wasn’t in training).
- Stronger region understanding: The refined CLIP is better at labeling the exact object area, not just the whole scene.
- Memory friendly: Their approach uses much less GPU memory than a popular prior method (roughly 56% less per image in their setup), making it easier and cheaper to train.
There is a small trade-off: on the training dataset (COCO), performance is about the same or just slightly lower in some cases, which is expected because they adjust the objectness decisions to generalize better beyond that training set.
Why is this important?
- Real-world readiness: In the real world, you constantly see objects that weren’t in a fixed training list. Systems need to handle that gracefully. OVRCOAT moves us closer to models that understand new objects without retraining from scratch.
- Practical and modular: It plugs into common segmentation systems (like Mask2Former) without complicated changes and saves memory. That makes it easier for others to use and build upon.
- A better balance: By both rescuing good masks (COAT) and improving regional naming (OVR), the method raises overall quality across different datasets and scenes.
Takeaway
OVRCOAT is a simple, smart upgrade for open-vocabulary panoptic segmentation. It:
- Keeps good object masks that older systems would wrongly discard.
- Teaches a vision–LLM (CLIP) to pay attention to smaller regions, not just whole images.
- Achieves new state-of-the-art results on challenging benchmarks while using less memory.
This brings computer vision a step closer to “open-world” understanding—recognizing and labeling whatever appears, not just a fixed list of categories.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes concrete gaps, uncertainties, and unexplored aspects that remain after this work, to guide future research:
- COAT’s certainty proxy uses the max softmax over CLIP class scores, which is known to be miscalibrated; how to replace or calibrate this proxy (e.g., temperature scaling, margin/energy scores, Dirichlet priors, ensembles) to make objectness adjustment more reliable?
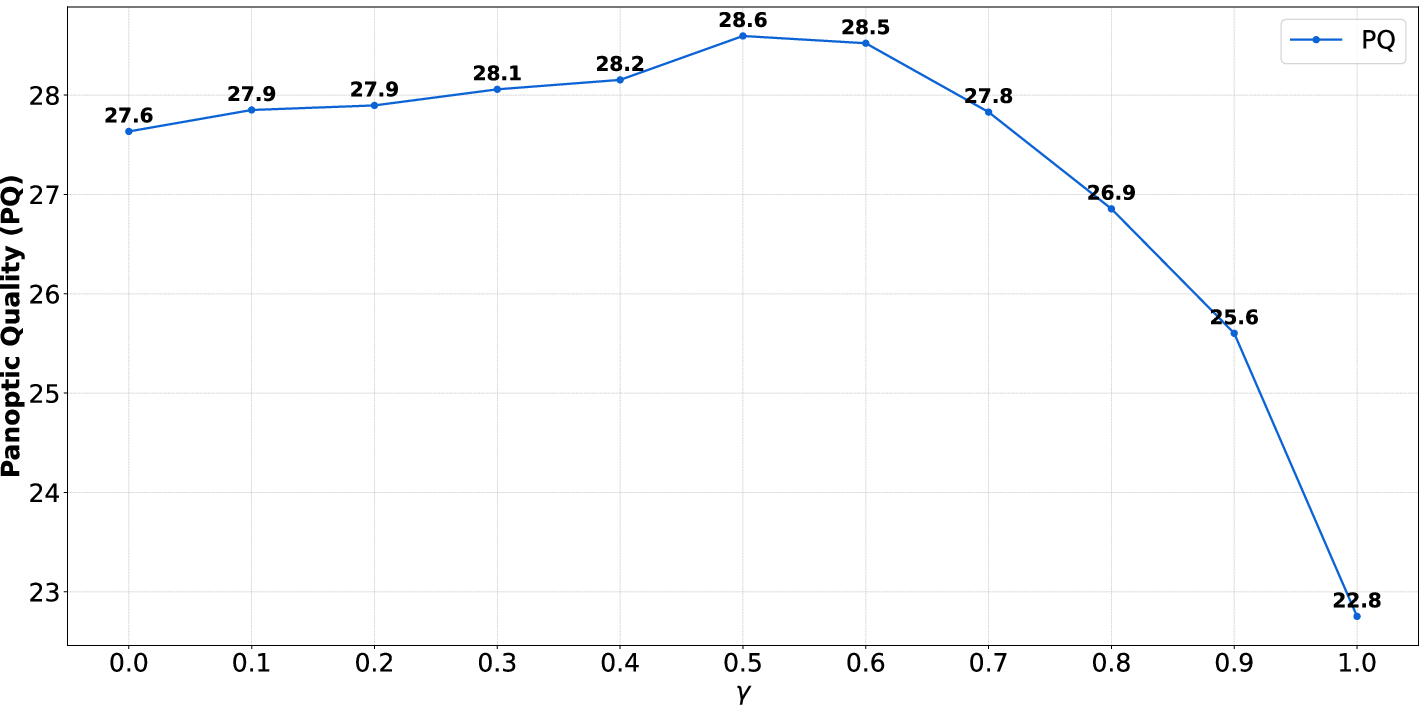
- The CLIP trust factor γ is fixed and tuned only on ADE20K; can γ be adaptively estimated per-dataset, per-image, or per-mask (e.g., via calibration metrics or uncertainty cues) without supervision, and does this improve cross-domain robustness?
- COAT introduces a performance trade-off on seen classes (e.g., COCO); can a learned fusion or gating policy selectively apply COAT based on mask-level confidence to avoid hurting closed-set performance?
- COAT relies on CLIP’s region features despite known locality weaknesses; can region features be improved via attention-based mask pooling, boundary-aware pooling, per-mask patch cropping, or learned per-mask adapters to reduce noise in objectness correction?
- OVR uses a simple cross-entropy for mask-to-text alignment; how do contrastive, metric-learning (triplet, InfoNCE), or mutual-information objectives on region-to-text pairs affect regional alignment and generalization?
- Text encoder is frozen; what is the impact of fine-tuning CLIP’s text encoder (lightweight adapters, LoRA) and using richer prompt templates, synonyms, or hierarchical taxonomies on classification of unseen classes?
- Prompt design is underspecified (templates, context phrases, multi-lingual prompts); how sensitive are results to prompt choices, and can automatic prompt optimization improve unseen-category recall?
- Training uses only COCO panoptic labels; does multi-source training (e.g., ADE, LVIS, Mapillary, BDD) or incorporating captioned/unlabeled data improve open-vocabulary panoptic generalization without hurting closed-set accuracy?
- Handling unlabeled novel objects in training images is not addressed; can semi-/weakly-supervised strategies (pseudo-labeling of novel masks, open-set regularizers) reduce void-token bias learned from incomplete annotations?
- The objectness “void” token remains a single prototype; would multiple background prototypes or a learned mixture model reduce over-suppression of diverse unseen objects?
- COAT is vocabulary-conditioned and cannot recognize truly unknown classes (not in the test-time label list); how to integrate unknown/none-of-the-above detection and evaluate novelty detection in open-vocabulary panoptic segmentation?
- No learned fusion between CLIP and mask-transformer classifiers is explored; can a lightweight meta-classifier or calibration/fusion layer learn optimal combination rules across domains and categories?
- Runtime and scalability are not reported; what are the per-image inference costs (latency, FLOPs) and how do they scale with the number of mask proposals on high-resolution datasets like Mapillary Vistas?
- Inference-time memory is not evaluated; what is the footprint under realistic batch sizes, and can memory-aware techniques (activation checkpointing, mask pruning) retain gains while reducing deployment cost?
- The semantic segmentation setting shows COAT degrading mIoU; can objectness adjustment be reformulated for per-pixel aggregation (e.g., pixelwise confidence calibration) to help semantic segmentation instead of injecting noise?
- Failure mode analysis is limited; what are the systematic errors by size (small vs large), occlusion/crowding, “stuff” vs “things”, and rare/long-tailed classes, and which component (COAT vs OVR) dominates each failure?
- The effect of taxonomy mismatches across datasets (label granularity, synonyms) is not studied; how do label mappings and hierarchical evaluation protocols impact open-vocabulary comparisons and training?
- The number of queries/masks and mask-transformer design are fixed; do decoder architectural choices (queries, multi-scale features, denoising, proposal refinement) interact with OVRCOAT’s gains?
- Hyperparameter sensitivity beyond γ and α is not explored; do learning rates, stage durations, loss weights, and freezing policies yield more stable or better generalization, and can automated tuning be applied?
- Only ConvNeXt-L OpenCLIP is tested; how does OVRCOAT transfer to different VLMs/backbones (ViT-L/ViT-H, SigLIP, EVA-CLIP) and to smaller/mobile models for resource-constrained deployments?
- Oracle-mask experiments show classification gains, but the interplay with mask-generator errors remains open; can teacher–student training or joint optimization reduce compounding errors in challenging scenes?
- Duplicate/overlapping mask handling in panoptic inference is not discussed; does COAT increase false positives or mask conflicts, and can better mask selection/suppression policies mitigate this?
- No evaluation on additional open-world benchmarks (e.g., LVIS panoptic, BDD, OpenPanoptic); do OVRCOAT’s gains hold across broader domains and taxonomies?
- Domain fairness and bias are not assessed; does COAT/OVR amplify or mitigate biases (e.g., geographic, demographic), and how can fairness-aware objectives be integrated?
- The approach is static; extending to video panoptic segmentation requires temporal consistency and cross-frame objectness alignment—what adaptations are needed (temporal CLIP features, mask tracking, flow-guided pooling)?
- Validation of CLIP trust calibration is supervised (with PQ on validation); can self-supervised or unsupervised calibration methods be used to avoid overfitting while maintaining cross-domain performance?
- Open-source reproducibility lacks details such as seeds, query counts, prompt templates, and exact taxonomic mappings; establishing standardized protocols would improve comparability and reliability of future work.
Practical Applications
Immediate Applications
Below are actionable uses that can be piloted or deployed now, leveraging the paper’s two modular contributions: CLIP-conditioned objectness adjustment (COAT) and open-vocabulary mask-to-text refinement (OVR). Each item lists sector(s), potential tools/workflows, and key assumptions/dependencies.
- Bold sector(s): ADAS/Autonomous Vehicles, Mapping
- What: Improve detection of unusual or previously unseen road objects (e.g., fallen cargo, new construction equipment, temporary barriers) in street scenes.
- How: Integrate OVRCOAT as a panoptic head in perception stacks; use COAT to recover masks that would be suppressed as background and OVR to better classify novel segments; tune CLIP trust factor γ for recall/precision balance.
- Tools/Workflows: Drop-in module for Mask2Former-based pipelines; batch inference over dashcam streams for hazard mining; MLOps monitoring of seen vs. unseen RQ/PQ.
- Assumptions/Dependencies: Availability of CLIP and Mask2Former features; domain shift manageable (OVRCOAT shows gains on Cityscapes and Mapillary Vistas); GPU budget compatible with ConvNeXt-L; safety validation needed before fleet-wide rollouts.
- Bold sector(s): Retail Analytics, Supply Chain
- What: Shelf analytics and planogram compliance with open-vocabulary instance segmentation of novel SKUs, packaging changes, or promotional displays.
- How: Use COAT to avoid suppressing new or rare products; OVR to improve classification with text prompts describing categories and attributes.
- Tools/Workflows: Store-camera ingestion → OVRCOAT panoptic parsing → SKU/attribute prompts → out-of-planogram alerting; integration with existing retail AI dashboards.
- Assumptions/Dependencies: Lighting and viewpoint variation may require light fine-tuning; CLIP’s text prompts must reflect current product taxonomies; privacy compliance.
- Bold sector(s): Security/Video Analytics
- What: Open-vocabulary detection/segmentation of unusual or prohibited items (e.g., “ladder,” “drone,” “knife”) in facilities.
- How: Deploy OVRCOAT as a segmentation step; COAT raises objectness of rare targets; apply prompt lists and thresholding; optionally fuse with a tracker for temporal stability.
- Tools/Workflows: Video pipeline with per-frame OVRCOAT → temporal smoothing → alert triage UI; configurable prompt packs per venue.
- Assumptions/Dependencies: CLIP’s global-training bias may cause miscalibration; strong access control and audit logs; local inference to minimize latency/privacy risk.
- Bold sector(s): Data Annotation/ML Ops
- What: Human-in-the-loop labeling acceleration and dataset auditing for missed labels.
- How: Use COAT to surface “formerly-background” masks as candidates; OVR to produce initial labels with text prompts; reviewers accept/merge/fix proposals.
- Tools/Workflows: Plugins for CVAT/Label Studio; “unknown” mask queue; per-class PQ seen/unseen dashboards; automated reports on dataset bias (e.g., frequent missed categories like “paintings”).
- Assumptions/Dependencies: Annotators remain in the loop; per-project tuning of γ to control false positives; clear taxonomy update process.
- Bold sector(s): AR/VR, Creative Tools, Mobile Imaging
- What: Instance-level background removal, selective edits, and object-aware effects for arbitrary categories (even if unseen during training).
- How: Use OVRCOAT for open-vocabulary instance segmentation in photo/video editors; user prompt like “segment all bottles and glasses.”
- Tools/Workflows: Plugin/SDK for compositing apps; on-device or near-device inference; batch “smart cutout” for content studios.
- Assumptions/Dependencies: Real-time constraints may require lighter backbones or quantization; careful UX for category phrasing.
- Bold sector(s): Robotics (Home, Logistics)
- What: Robust segmentation of novel household items or packages for navigation and grasp planning.
- How: Use COAT to avoid discarding unfamiliar objects; OVR for better region-level classification; couple with depth and grasp planners.
- Tools/Workflows: Perception node in ROS integrating OVRCOAT; prompt lists for affordance proxies (e.g., “handle,” “box,” “spillage”).
- Assumptions/Dependencies: Latency/compute constraints on embedded GPUs; integration with pose/SLAM and manipulation stack; environment-specific prompts.
- Bold sector(s): Academic/Research and Teaching
- What: Baseline and teaching resource for open-world panoptic segmentation, debiasing objectness, and region-level VLM alignment.
- How: Use the released code and minimal training complexity to reproduce SOTA PQ on ADE20K; run ablations on γ, OVR freezing, and loss designs.
- Tools/Workflows: Course labs; reproducible benchmarks; comparisons against MAFT+ with lower memory requirements.
- Assumptions/Dependencies: Access to A100-class or smaller GPUs (memory-friendly design improves accessibility).
- Bold sector(s): Software Platforms/Frameworks
- What: Productize COAT as a drop-in “objectness debiaser” for Mask2Former-based open-vocab systems, and OVR as a lightweight finetuning recipe.
- How: Offer pip-installable module with a simple API to adjust p_obj given CLIP logits; configuration file for γ and vocabulary prompts; training script for OVR.
- Tools/Workflows: CI tests on ADE20K/Cityscapes/Mapillary; model cards with seen/unseen PQ, SQ, RQ; guardrails for prompt management.
- Assumptions/Dependencies: Compatible feature shapes from the backbone/decoder; legal use of OpenCLIP/LAION weights.
- Bold sector(s): Manufacturing QA (Pilot)
- What: Open-vocab segmentation of emergent defects or new parts without exhaustive retraining.
- How: Use COAT to preserve anomalous regions; OVR with prompts like “scratch,” “dent,” “contamination.”
- Tools/Workflows: Visual inspection line → OVRCOAT segmentation → anomaly triage; feedback loop to refine prompts.
- Assumptions/Dependencies: Domain shift vs. natural-image CLIP can be significant; expect pilot-stage tuning and possible domain-adapted VLM later.
Long-Term Applications
These applications are promising but require further research, domain adaptation, scaling, or productization beyond current results.
- Bold sector(s): Safety-Critical AV Certification
- What: Open-world panoptic perception with calibrated uncertainty, temporal consistency, and fail-safe behavior.
- How: Extend OVRCOAT to video panoptics with temporal smoothing/tracking; rigorous calibration of COAT’s CLIP-conditioned objectness; safety cases and standards alignment.
- Dependencies: Real-time guarantees; uncertainty estimation and OOD detection; regulatory evaluation; large-scale closed-loop sim and on-road validation.
- Bold sector(s): Healthcare/Medical Imaging
- What: Open-vocabulary panoptic segmentation of anatomical structures and pathology variants.
- How: Replace CLIP with domain-pretrained VLMs; rework prompts to clinical ontologies; train OVR with medically curated datasets.
- Dependencies: Domain shift from natural to medical images; strict validation, explainability, and regulatory compliance.
- Bold sector(s): Aerial/Satellite Geospatial
- What: Open-vocab segmentation of rare or emergent features (e.g., flood debris, new infrastructure).
- How: Adapt OVRCOAT with remote-sensing VLMs (e.g., SatCLIP-like variants); incorporate multi-spectral inputs; large-scale tile processing.
- Dependencies: High-resolution data pipelines; domain-specific pretraining; geospatial labeling taxonomies.
- Bold sector(s): Continual/Active Learning Pipelines
- What: Automatic discovery and curation of new classes, with human-in-the-loop acceptance and taxonomy growth.
- How: Use COAT to propose “unknown” segments; OVR for provisional names via prompts; active-learning loops for confident additions.
- Dependencies: Robust class-merging policies; dataset/version governance; drift monitoring.
- Bold sector(s): Edge/Mobile Real-Time XR
- What: Real-time open-vocab panoptic segmentation on mobile SoCs for AR navigation and assistive overlays.
- How: Model compression, distillation, and quantization of OVRCOAT; prompt caching; efficient mask decoding.
- Dependencies: Tight latency and power budgets; on-device privacy constraints; hardware-specific optimizations.
- Bold sector(s): Environmental Monitoring/Wildlife
- What: Open-vocab detection and segmentation of rare species or invasive objects in camera traps or drones.
- How: Domain-adapted VLMs; prompt sets curated by ecologists; seasonal drift handling.
- Dependencies: Sparse labels; strong domain adaptation; evaluation with expert-verified datasets.
- Bold sector(s): Disaster Response/Insurance
- What: Segmentation of novel damage types and debris categories after rare events.
- How: Rapid-adaptation OVR finetunes on small event-specific samples; open-vocab prompts for emergent categories.
- Dependencies: Robustness to extreme conditions; human-in-the-loop validation; integration with claims workflows.
- Bold sector(s): Policy, Standards, and Benchmarking
- What: Guidelines and metrics for open-vocabulary panoptic systems in public procurement and safety compliance.
- How: Establish seen/unseen PQ/SQ/RQ reporting; standardized prompt sets; evaluation of objectness debiasing and calibration.
- Dependencies: Multi-stakeholder consensus; reference datasets with controlled OOD scenarios; auditing of text-prompt governance.
- Bold sector(s): Foundation Model Upgrades and Multimodality
- What: Swap-in stronger VLMs (e.g., SigLIP-like, multilingual) or multimodal context (audio, text, 3D) for richer open-world perception.
- How: Leverage OVRCOAT’s modularity to upgrade encoders and expand prompt capabilities; integrate depth/LiDAR for 3D panoptics.
- Dependencies: Training stability with larger backbones; cross-modal synchronization; compute and data scaling.
Cross-Cutting Assumptions and Dependencies
- CLIP availability and licensing: Many applications rely on OpenCLIP or compatible VLMs trained on large web corpora; ensure compliance with data and model licenses.
- Prompt engineering: Performance depends on well-crafted, domain-relevant text prompts; consider multilingual needs and taxonomy governance.
- Calibration and thresholds: COAT’s trust factor γ impacts recall/precision; miscalibration risk in safety-critical contexts; per-domain tuning required.
- Domain shift: CLIP pretraining on natural images can underperform in specialized domains (medical/industrial/remote sensing); expect domain-adapted VLMs or additional finetuning.
- Compute/latency: Although more memory-efficient than prior art, real-time or edge deployments may require model compression, distillation, or lighter backbones.
- Human oversight: For high-stakes or novel categories, human-in-the-loop review remains critical to manage false positives/negatives and taxonomy updates.
Glossary
- ADE20K: A large-scale scene parsing dataset widely used to evaluate segmentation methods. "OVRCOAT sets a new state of the art on ADE20K (+5.5\% PQ)"
- AdamW: An optimizer that decouples weight decay from the gradient update to improve training stability. "We train OVRCOAT using the AdamW optimiser"
- ALIGN: A vision–LLM trained with contrastive learning on image–text pairs. "Seminal works such as CLIP~\cite{radford2021learning} and ALIGN~\cite{jia2021scaling} adopt a contrastive objective"
- Cityscapes: A benchmark dataset for urban scene understanding used for segmentation evaluation. "Cityscapes~\cite{cordts2016cityscapes}"
- CLIP: A contrastively trained vision–LLM that aligns images and text in a shared embedding space and enables zero-shot transfer. "CLIP~\cite{radford2021learning}"
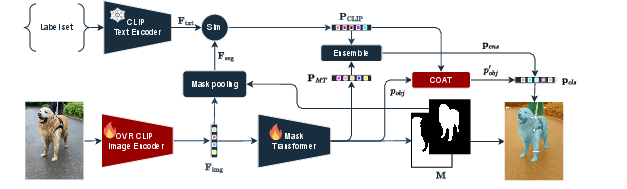
- CLIP-conditioned objectness adjustment (COAT): A module that adjusts mask objectness using CLIP’s class confidence to reduce bias against unseen categories. "A CLIP-conditioned objectness adjustment (COAT) leverages CLIP~\cite{radford2021learning} to refine mask selection"
- contrastive objective: A learning objective that brings matched image–text pairs closer while pushing mismatched pairs apart in embedding space. "adopt a contrastive objective that jointly optimizes image and text encoders"
- ConvNeXt-Large: A high-capacity convolutional backbone architecture used as the CLIP image encoder. "ConvNeXt-Large~\cite{radford2021learning, liu2022convnet, yu2023convolutions}"
- cross-entropy loss: A standard classification loss measuring the discrepancy between predicted class probabilities and ground-truth labels. "Classification is supervised by a cross-entropy loss"
- dense prediction: Tasks requiring per-pixel outputs (e.g., segmentation) rather than image-level labels. "which are crucial for dense prediction~\cite{rao2022denseclip}"
- ensembled per-vocabulary-class probability density: A combined class probability computed from multiple sources (e.g., mask transformer and CLIP). "ensembled per-vocabulary-class probability density~\cite{yu2023convolutions}"
- FC-CLIP: A method that uses a frozen convolutional CLIP backbone for open-vocabulary segmentation. "FC-CLIP~\cite{yu2023convolutions}"
- global mask pooling: Aggregating features within a mask by averaging over its spatial extent to obtain a single region descriptor. "by a global mask pooling"
- Gram Matrix consistency loss: A constraint enforcing consistency of feature correlations (Gram matrices) during fine-tuning. "adds a Gram Matrix consistency loss inspired by DINOv3~\cite{simeoni2025dinov3}"
- Hungarian matching: An algorithm for optimal assignment used to match predicted masks to ground truth during training. "Hungarian matching~\cite{kuhn1955hungarian}"
- LAION-2B: A massive image–text dataset used to pretrain OpenCLIP. "LAION-2B~\cite{schuhmann2022laion}"
- Mapillary Vistas: A large-scale street-scene dataset for evaluating segmentation models across diverse conditions. "Mapillary Vistas~\cite{neuhold2017mapillary}"
- Mask2Former: A mask-transformer architecture for universal image segmentation tasks. "Mask2Former~\cite{cheng2022masked}"
- mask proposals: Candidate segmentation masks generated by the model before classification and filtering. "generating individual mask proposals"
- mask selection bias: Systematic suppression of valid masks for unseen classes due to training on a closed vocabulary. "this introduces a mask selection bias"
- mask transformer: A transformer-based decoder that predicts a set of masks and associated scores for segmentation. "mask transformer"
- objectness score: A probability estimating whether a predicted region corresponds to a foreground object rather than background. "removing those with low objectness score"
- open-vocabulary mask-to-text refinement (OVR): A training protocol that improves CLIP’s regional alignment for mask classification across seen and unseen classes. "open-vocabulary mask-to-text refinement (OVR) strengthens CLIPâs region-level alignment"
- open-vocabulary panoptic segmentation: Panoptic segmentation setting where categories are not limited to those seen during training. "Open-vocabulary panoptic segmentation remains hindered by two coupled issues"
- OpenCLIP: An open-source implementation and set of checkpoints for CLIP trained on large web-scale datasets. "OpenCLIP~\cite{ilharco2021openclip}"
- out-of-vocabulary (OOV): Classes or datasets containing categories not present in the training label set. "out-of-vocabulary (OOV) datasets"
- Panoptic Quality (PQ): A metric combining segmentation and recognition quality to evaluate panoptic segmentation. "Panoptic Quality (PQ), Segmentation Quality (SQ) and Recognition Quality (RQ)"
- panoptic segmentation: Jointly performing semantic segmentation and instance segmentation by labeling every pixel and distinguishing object instances. "Panoptic segmentation provides a semantic visual scene decomposition"
- Recognition Quality (RQ): The detection component of PQ measuring how well instances are correctly recognized. "Panoptic Quality (PQ), Segmentation Quality (SQ) and Recognition Quality (RQ)"
- representation consistency (RC) loss: An auxiliary loss that aims to preserve CLIP’s embedding alignment during fine-tuning. "representation consistency (RC) loss"
- segmentation oracle: An evaluation setup using perfect ground-truth masks to isolate classification performance. "a segmentation oracle"
- Segmentation Quality (SQ): The mask overlap component of PQ assessing the quality of predicted mask shapes. "Panoptic Quality (PQ), Segmentation Quality (SQ) and Recognition Quality (RQ)"
- softmax: A normalization function converting logits into a probability distribution over classes. "computed by softmax over dot-products"
- stuff: Amorphous background categories (e.g., sky, road) contrasted with countable object instances. "background regions (stuff)"
- things: Countable object instances (e.g., car, person) distinguished from background regions. "object instances (things)"
- trust factor: A scalar weight controlling how strongly CLIP’s confidence influences the adjusted objectness. "the CLIP trust factor"
- vision-LLMs (VLMs): Models that jointly learn from images and text to align multimodal representations. "Vision-LLMs (VLMs) learn mappings of images and text into a shared embedding space"
- void token: A special token representing background/unknown class used by the mask transformer for objectness gating. "the mask transformer as a (normalized) similarity of the mask-wide feature with a pre-trained void token"
- zero-shot performance: The ability to recognize classes without task-specific fine-tuning by leveraging aligned text embeddings. "These models demonstrate strong zero-shot performance"
Collections
Sign up for free to add this paper to one or more collections.