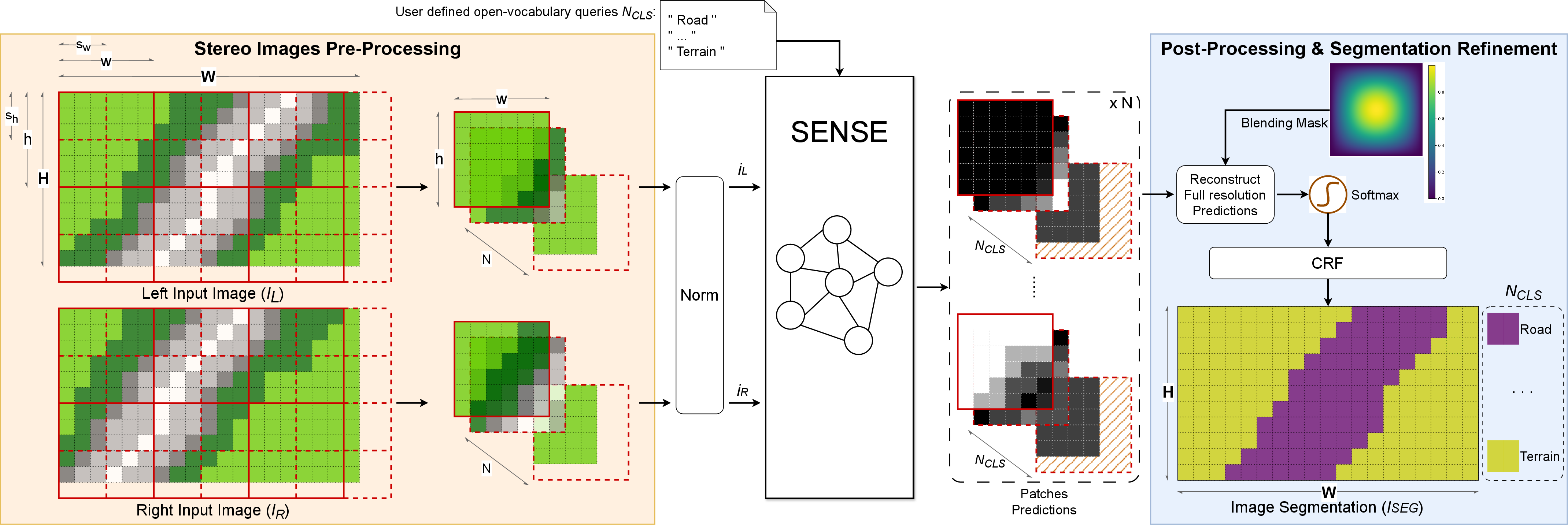
- The paper proposes SENSE, a novel stereo-guided framework that integrates geometric cues with CLIP semantics for zero-shot segmentation.
- It introduces SIEF and SDAF modules for adaptive feature fusion and disparity-aware attention, significantly sharpening mask boundaries and spatial consistency.
- Empirical results on Cityscapes, KITTI, and PhraseStereo demonstrate superior segmentation accuracy and real-time potential in challenging scenes.
SENSE: Stereo OpEN Vocabulary SEmantic Segmentation
Motivation and Context
Semantic segmentation is a pivotal task in autonomous navigation and scene understanding, where traditional approaches are limited by their dependence on closed-set class labels and monocular vision. Open-vocabulary segmentation, enabled by Vision-LLMs (VLMs), provides flexibility for segmenting arbitrary objects or regions based on free-form natural language queries. However, most current methods are constrained to single-view inputs and suffer from a lack of spatial precision, particularly in the presence of occlusions or at object boundaries.
SENSE introduces a paradigm shift by leveraging stereo vision and VLMs to address these limitations. By fusing geometric cues from stereo pairs with CLIP-based semantic representations, SENSE delivers improved spatial reasoning and segmentation accuracy in both zero-shot and referring expression tasks, aimed at robust deployment in Intelligent Transportation Systems (ITS) and autonomous robotics.

Figure 1: SENSE-512 produces zero-shot open-vocabulary semantic segmentation from stereo pairs, demonstrating improved spatial precision for arbitrary language prompts in Cityscapes.
Architectural Design
The SENSE architecture is built around the frozen CLIP ViT-B/16 vision and text encoders, processing left and right stereo images symmetrically. Intermediate activations are extracted from designated CLIP transformer blocks and fused adaptively through the Stereo Intermediate-level Embedding Fusion (SIEF) module. A transformer-based decoder, conditioned by textual queries via FiLM, further refines features using the Semantic Disparity Attention Fusion (SDAF) module, which incorporates disparity maps from an external stereo depth estimator such as Selective-IGEV.
The fusion strategy within SIEF learns spatially adaptive weights to combine left and right features, maintaining robustness to occlusions and ensuring geometric consistency. SDAF modulates semantic features with disparity-aware attention, producing spatially coherent segmentation, particularly near object boundaries and depth discontinuities.
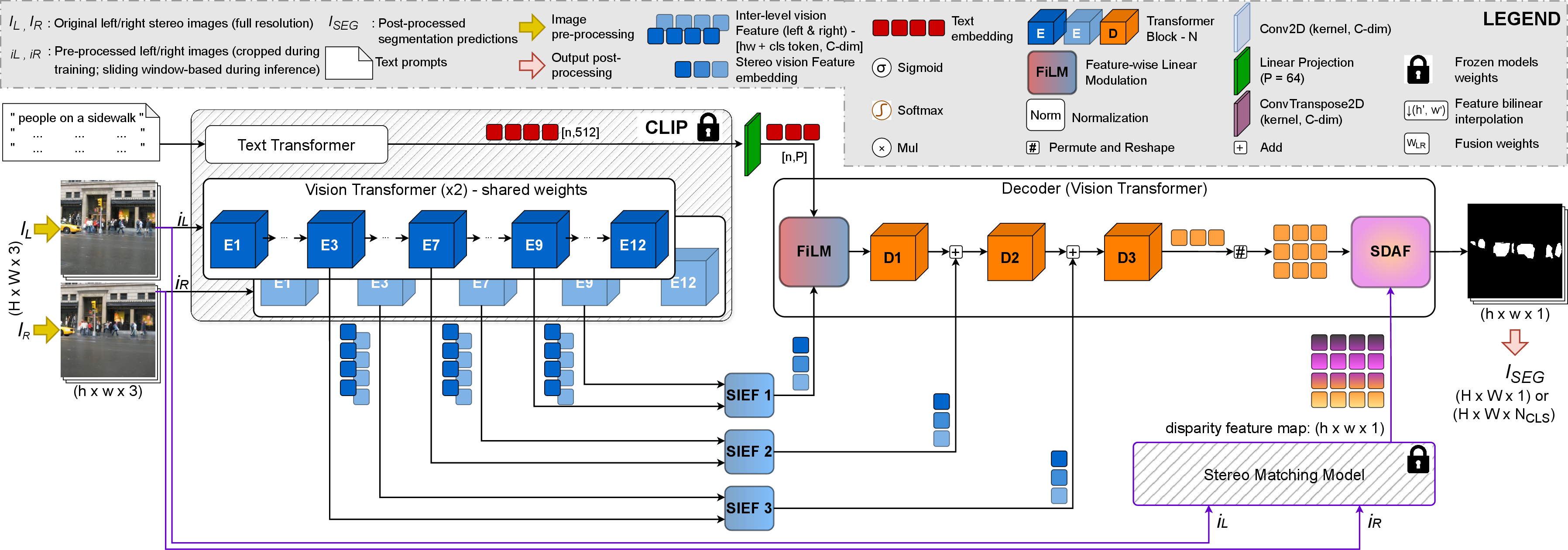
Figure 2: SENSE architecture leverages dual CLIP vision encoders, SIEF fusion, transformer decoding, and SDAF for disparity-aware mask refinement.
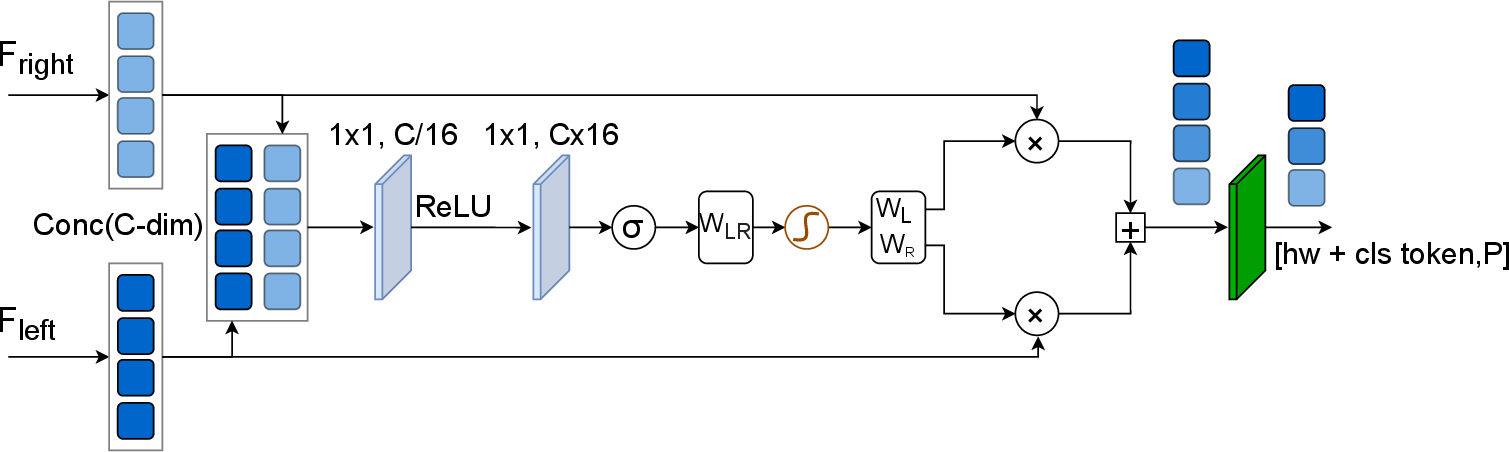
Figure 3: SIEF adaptively fuses features from both stereo views, projecting combined features to a compact embedding for decoder input.
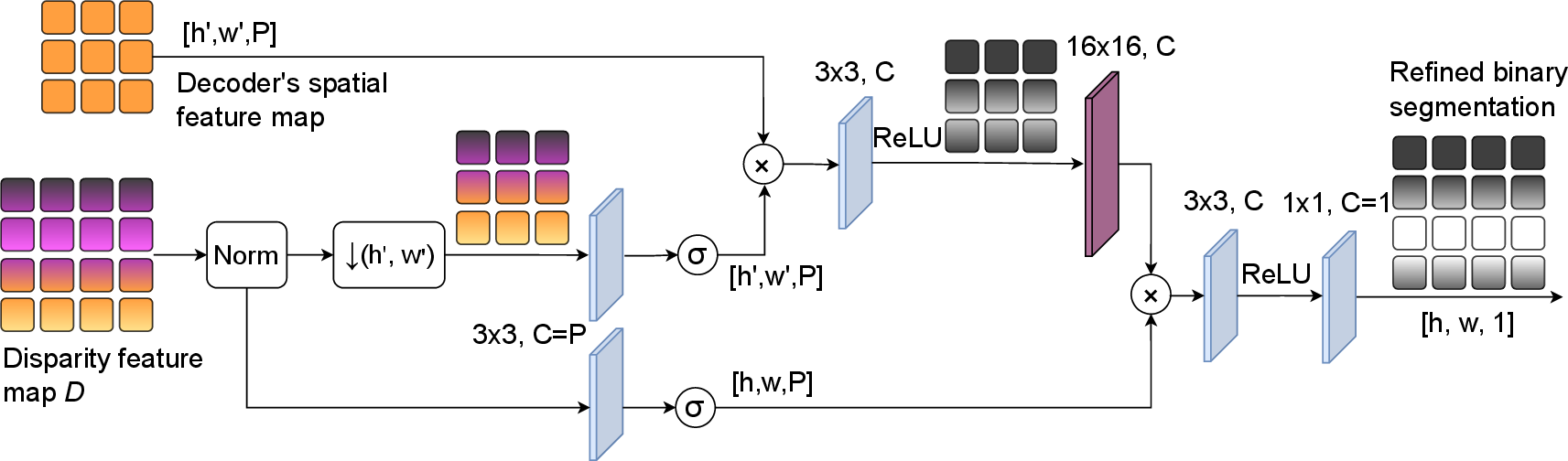
Figure 4: SDAF combines normalized disparity and semantic features for refined mask prediction, facilitating spatial coherence near boundaries.
Technical Contributions
Referring Expression Segmentation
On PhraseStereo, SENSE-352 achieves 47.2 mIoU, 57.0 IoUFG, and 78.8 AP, outperforming all CLIPSeg baselines and providing substantial gains in Average Precision (+2.9% over baselines, +0.76% over best prior) in phrase-grounded segmentation. Stereo fusion notably sharpens mask boundaries and enhances referent localization in challenging scenes.
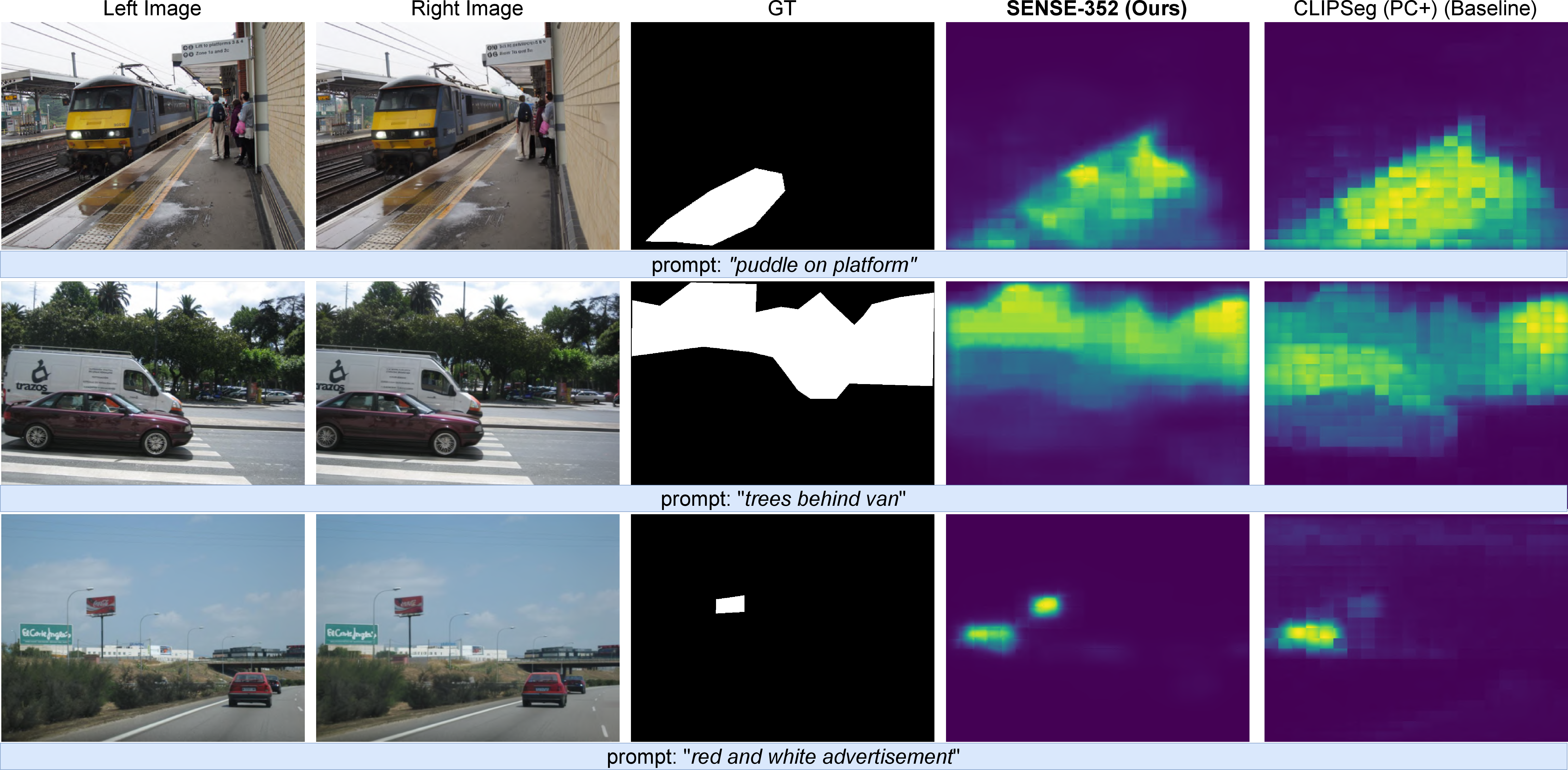
Figure 6: SENSE-352 delivers enhanced spatial precision for complex referring expressions, outperforming CLIPSeg in object-specific, relational, and attribute-based queries.
Zero-Shot Segmentation
On Cityscapes and KITTI, SENSE-512 and SENSE-352 attain 41.6% and 37.9% mIoU, respectively, representing a +3.5% improvement over CLIPSeg and up to +18% over weaker baselines. SENSE maintains competitive computational efficiency, with inference times of 194.74 ms (SENSE-352) and 284.54 ms (SENSE-512) with Selective-IGEV; substituting lighter stereo matchers yields real-time performance with negligible accuracy degradation.

Figure 7: SENSE variants attain superior mask sharpness and spatial consistency compared to OpenSeg and CLIPSeg baselines in zero-shot settings.
Computational and Practical Considerations
Disparity estimation represents the primary computational bottleneck; however, plug-in modules such as MobileStereoNet enable SENSE to run faster than monocular-only baselines while retaining segmentation accuracy. The architecture's modularity and plug-and-play disparity integration make it suitable for edge deployment and real-time applications.
Ablation and Robustness
Ablation studies confirm the necessity of both SIEF and SDAF modules, demonstrating that removal of stereo fusion or disparity attention substantially impairs spatial precision and foreground accuracy. The architecture is insensitive to backbone changes (ViT-B/16 vs. ResNet-50) and robust to prompt phrasing, although performance remains sensitive to prompt semantics due to CLIP's text encoding.
Qualitative Analysis and Limitations
SENSE consistently produces sharper, more coherent segmentation masks than monocular baselines, particularly in occluded or complex regions. Its flexibility is verified by substituting standard class names with detailed descriptions as prompts, achieving comparable segmentation performance. Remaining limitations include prompt dependence, sensitivity to negative phrasing, and the need for automated query generation in fully autonomous settings—future directions entail improved prompt robustness, scene-driven automatic querying, and further real-time speed optimizations.

Figure 8: SENSE-512 maintains segmentation accuracy when prompted with descriptive text, illustrating language-driven spatial generalization.
Theoretical and Practical Implications
Integrating stereo perception with open-vocabulary LLMs enables robust semantic segmentation adaptable to dynamic, safety-critical environments where novel categories and complex scene semantics are prevalent. SENSE's modular approach to geometric fusion and natural-language conditioning sets a precedent for future research in multimodal perception, bridging the gap between spatial reasoning and semantic understanding.
Conclusion
SENSE establishes a new benchmark for open-vocabulary semantic segmentation, leveraging stereo vision and vision-language fusion for enhanced mask precision and generalization. Its modularity, prompt-conditioned flexibility, and stereo-guided spatial accuracy position it as a foundational framework for robust scene understanding across autonomous navigation, ITS, and robotics. The integration of geometry and semantics beyond monocular, closed-set models signals substantial theoretical and practical advancements for multimodal AI systems (2604.15946).