- The paper introduces a training-free method that computes distribution discrepancy directly, eliminating iterative logits optimization and GT-dependent training.
- It details two computation modes—optimal path and maximum velocity—which yield competitive mIoU improvements against traditional segmentation methods.
- The analysis demonstrates that bypassing conventional training produces efficient, model-agnostic segmentation with robust performance across diverse benchmarks.
Direct Segmentation via Analytical Distribution Discrepancy for Training-Free Open-Vocabulary Semantic Segmentation
Open-vocabulary semantic segmentation (OVSS) requires pixel-level categorization using free-form textual prompts, placing demands on vision-language alignment. The conventional methodological core involves iteratively optimizing logits—the cosine similarity between visual and language representations—until their distribution matches the ground truth (GT) pixel annotations. This optimization is either dependent on labor-intensive human annotation and training or, in more recent unsupervised variants, model-dependent attention modulation strategies.
The paper "Direct Segmentation without Logits Optimization for Training-Free Open-Vocabulary Semantic Segmentation" (2604.07723) proposes a paradigm shift: eliminate the logits-optimization phase by directly formulating the segmentation task as an analytic solution based on distribution discrepancy. The key hypothesis posits that the distribution discrepancy, specifically its consistency within homogeneous regions and inconsistency between heterogeneous regions, encodes sufficient semantic information for segmentation. The optimization process is thus replaced with direct computation on the discrepancy between normalized logits and a degenerate surrogate distribution, circumventing the necessity for GT annotations, iterative training, and dependence on model-specific attention mechanisms.
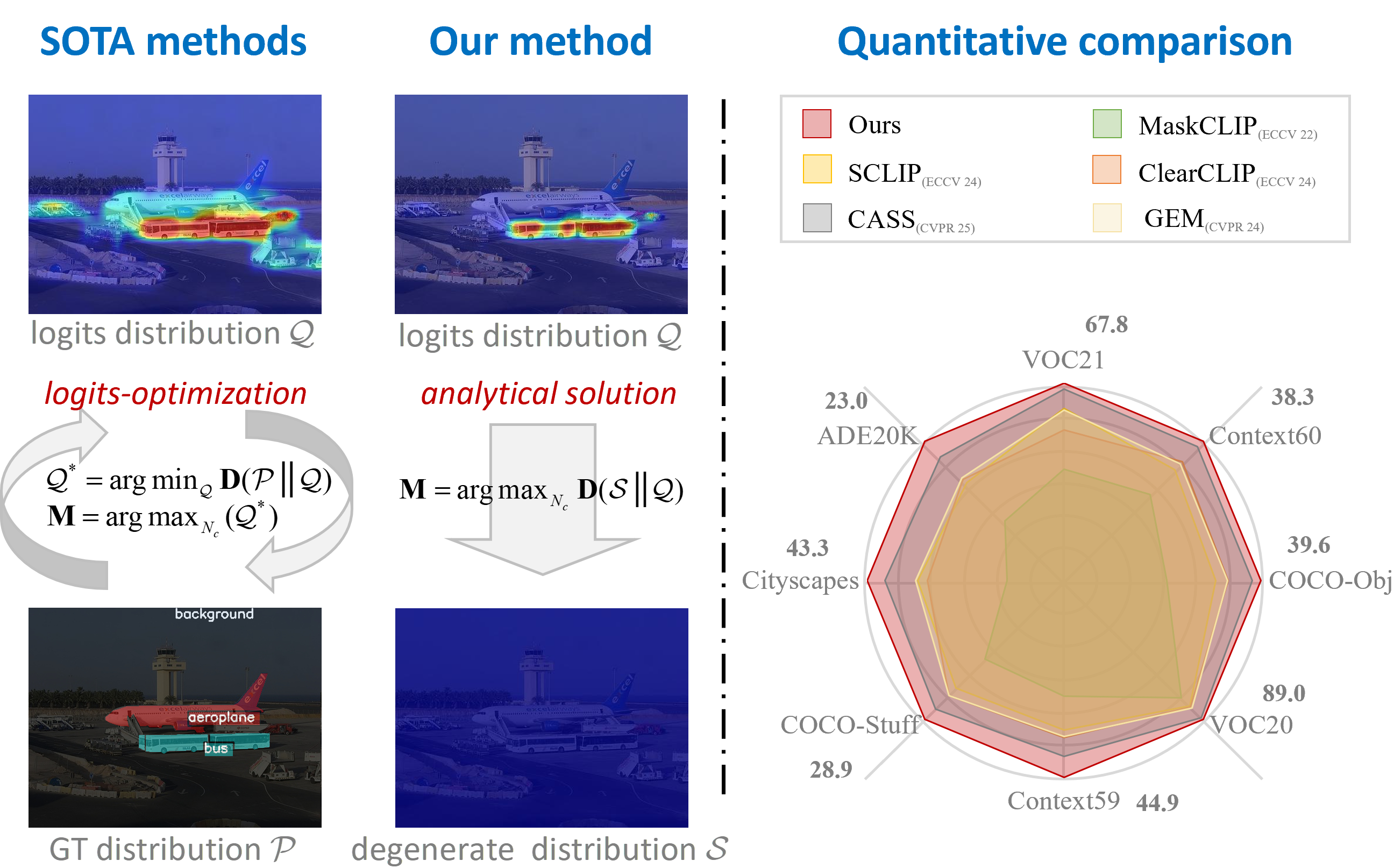
Figure 1: Reformulating logits-optimization into an analytical solution provides annotation independence, training elimination, and model-agnostic modulation.
Methodology
The proposed method follows a training-free pipeline: cosine similarity between image and prompt features is used to compute logits, followed by non-maximum suppression (NMS) and normalization. The core step is the analytical calculation of the distribution discrepancy between normalized logits and a degenerate reference distribution, which is upscaled via joint bilateral upsampling (JBU) to match the input resolution. The segmentation map is then generated through an argmax operation on this discrepancy map.

Figure 2: Pipeline overview — from logits generation to discrepancy computation, edge-preserving upsampling, and semantic map extraction.
The analytical reformulation is validated by examining equivalence between targeting degenerate surrogate and GT distributions, using KL divergence in three scenarios: logits-to-GT, logits-to-degenerate, and GT-to-degenerate. The equivalence is confirmed both quantitatively and qualitatively, supporting the substitution of GT with a degenerate distribution for inference-phase discrepancy computation.
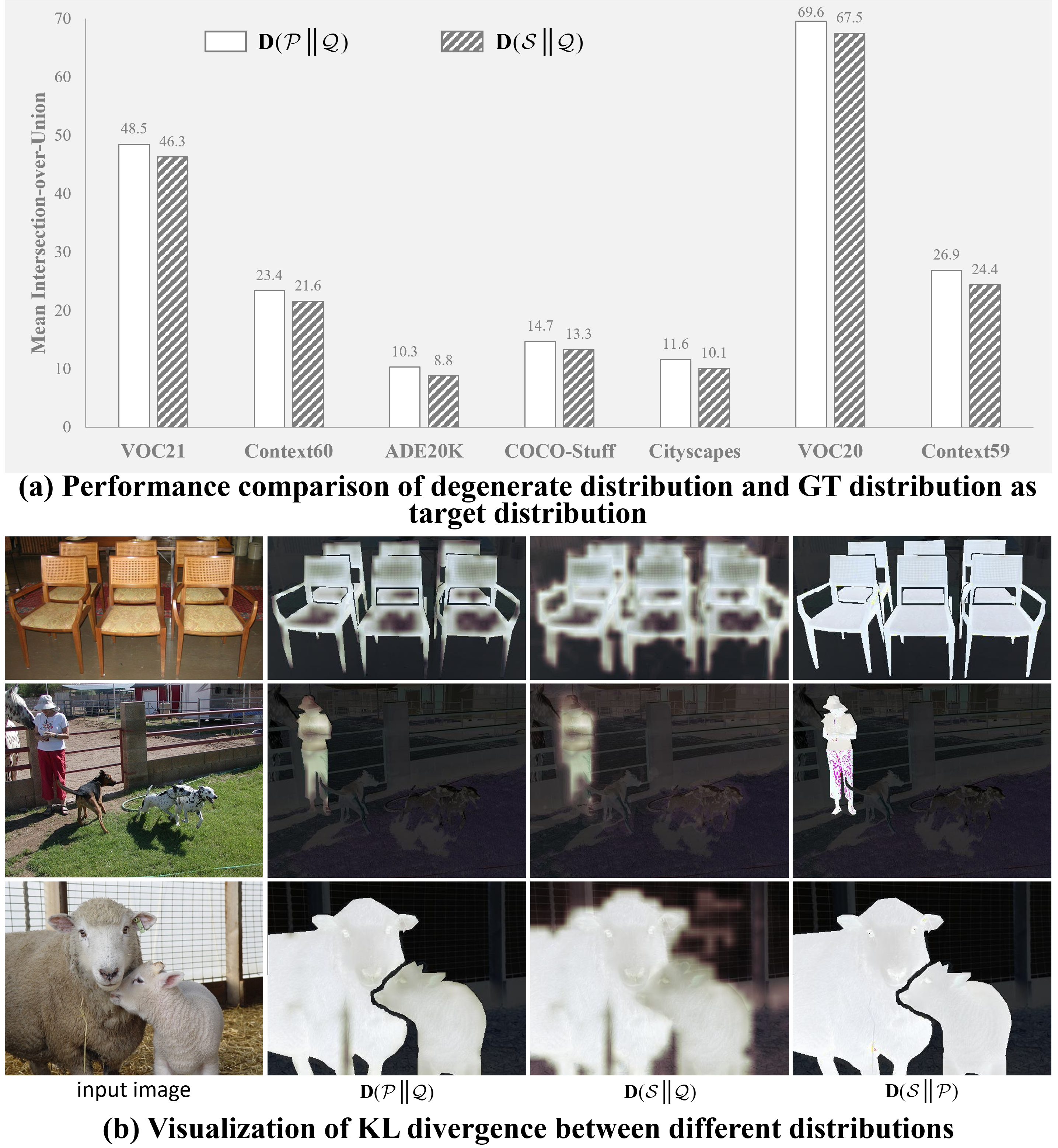
Figure 3: Quantitative performance and KL discrepancy visualizations demonstrate equivalence between degenerate and GT distributions for capturing semantic information.
Two modes for discrepancy computation are instantiated:
- Optimal Path Mode: Framed as an optimal transport problem, the method computes the path from each logits patch to the degenerate distribution using the Sinkhorn algorithm, leveraging layer-wise averaged self-attention tensors as the transport cost matrix. The optimal transport path encodes the semantic discrepancy map.
- Maximum Velocity Mode: The transition velocity in a Markov process from logits to the stationary (degenerate) distribution is calculated, with self-attention tensors forming the transition matrix. The maximum step velocity at which each patch converges to stationarity is used to quantify semantic discrepancy.

Figure 4: Stage-wise outputs and comparison between optimal path and maximum velocity segmentation maps—e.g., optimal path sensitivity for high-frequency details vs. maximum velocity for boundary delineation.
Experimental Results and Ablation Studies
System-level benchmarks cover VOC, Context, COCO-Stuff, Cityscapes, and ADE20K. The proposed method consistently achieves or approaches state-of-the-art performance, attaining improvements up to 2 mIoU points over existing attention-modulated and training-based OVSS methods. Both the optimal path and maximum velocity modes are competitive, with maximum velocity generally outperforming optimal path by a marginal amount.
Component-wise ablation confirms that direct use of distribution discrepancy (KL divergence) yields significant gains over raw logits, and that the analytical discrepancy maps (both path and velocity) further amplify performance (+22.2% and +23.0% mIoU on average relative to baseline).
Efficiency analysis indicates competitive computational complexity, with inference bottleneck primarily in self-attention map extraction (e.g., SD2 attention), but negligible overhead from discrepancy computation.
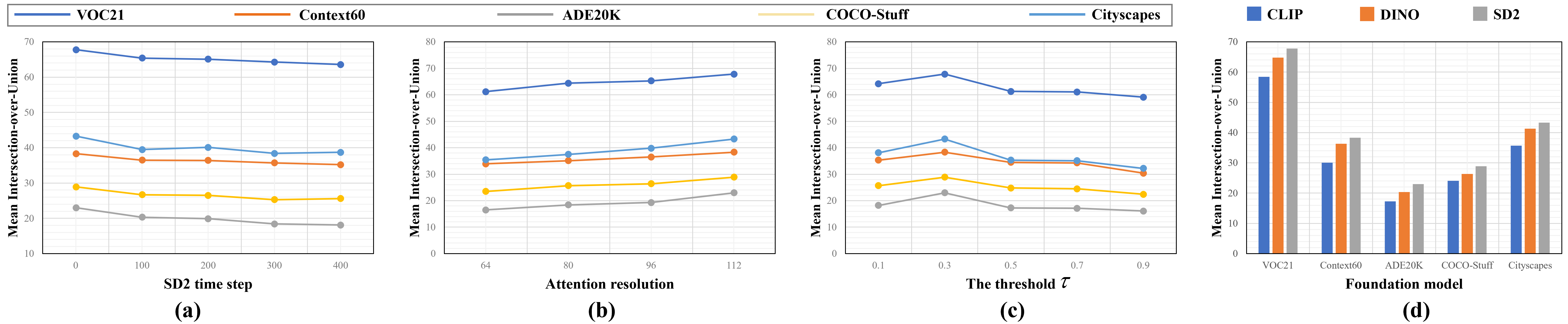
Figure 5: Quantitative effect of SD2 denoising step length, attention resolution, threshold, and foundation model on segmentation quality (maximum velocity mode).
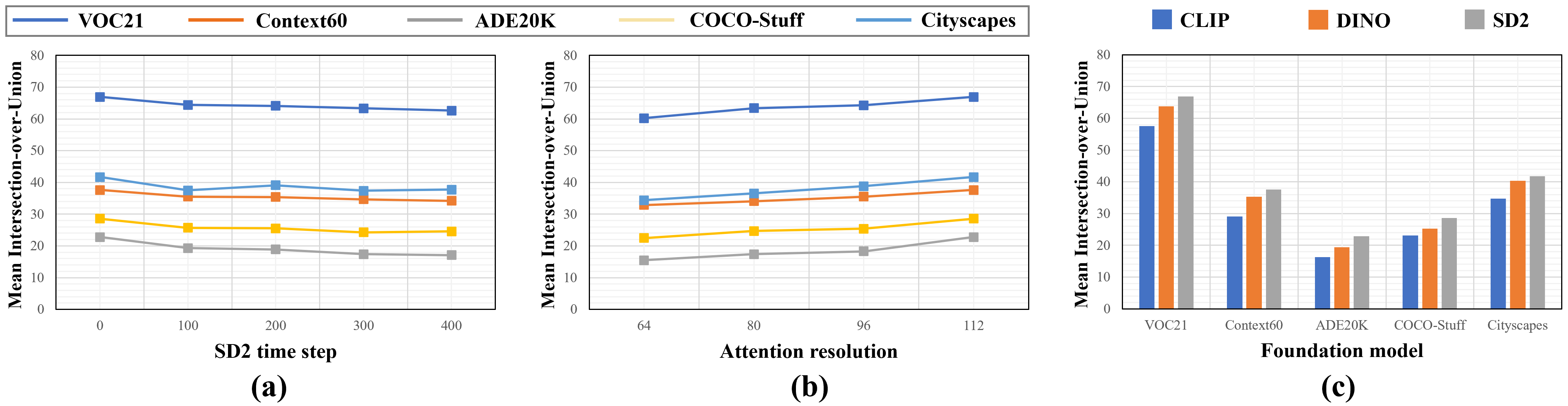
Figure 6: Quantitative effect of SD2 step length, resolution, and foundation model (optimal path mode).
Model versatility is demonstrated: the analytical discrepancy computation method, when integrated as a post-processing step, consistently boosts the performance of top SOTA models across all tested benchmarks.

Figure 7: Segmentation visualizations for COCO-Stuff, showing accurate category delineation.

Figure 8: Segmentation visualizations on Pascal VOC — precise separation of foreground and background regions.

Figure 9: ADE150k segmentation maps, revealing detailed semantic structures.

Figure 10: Pascal Context segmentations illustrating rich context differentiation.
Analysis and Implications
The elimination of the training/optimization phase has both practical and theoretical implications. Practically, it enables annotation-agnostic and model-independent segmentation with efficient inference. Theoretically, it demonstrates that semantically salient pixel categorization is achievable by quantifying the consistency and divergence of the distribution discrepancy between logits and a degenerate distribution, corroborated quantitatively and qualitatively.
Strong claims include the abandonment of GT-dependent iterative optimization in favor of analytic discrepancy solutions, validated across extensive datasets and competitive metric benchmarks.
The approach's agnosticism to model-specific attention modulation signals potential universality. In future AI segmentation systems, this paradigm could form the basis for plug-and-play post-processing modules, compatible with diverse vision-language architectures and foundational models. The insight that distribution discrepancy embodies sufficient semantic content may motivate further investigation into unsupervised, analytic, and post-hoc segmentation strategies, potentially generalizing across modalities and problem domains.

Figure 11: Visualization of maximum velocity maps under varying threshold.

Figure 12: Visualization of optimal path maps across iterative steps.
Conclusion
This work demonstrates that pixel-level semantic information can be reliably extracted in OVSS via direct analytic computation of the distribution discrepancy between vision-language logits and a degenerate surrogate distribution. The methodology eliminates the need for both GT annotations and iterative optimization, offering efficient, generalizable, and high-performance segmentation across benchmarks. The formal framework and empirical validation suggest broad applicability and further research potential on analytic, training-free methods for dense vision-language prediction.