Looking Beyond the Window: Global-Local Aligned CLIP for Training-free Open-Vocabulary Semantic Segmentation
Abstract: A sliding-window inference strategy is commonly adopted in recent training-free open-vocabulary semantic segmentation methods to overcome limitation of the CLIP in processing high-resolution images. However, this approach introduces a new challenge: each window is processed independently, leading to semantic discrepancy across windows. To address this issue, we propose Global-Local Aligned CLIP~(GLA-CLIP), a framework that facilitates comprehensive information exchange across windows. Rather than limiting attention to tokens within individual windows, GLA-CLIP extends key-value tokens to incorporate contextual cues from all windows. Nevertheless, we observe a window bias: outer-window tokens are less likely to be attended, since query features are produced through interactions within the inner window patches, thereby lacking semantic grounding beyond their local context. To mitigate this, we introduce a proxy anchor, constructed by aggregating tokens highly similar to the given query from all windows, which provides a unified semantic reference for measuring similarity across both inner- and outer-window patches. Furthermore, we propose a dynamic normalization scheme that adjusts attention strength according to object scale by dynamically scaling and thresholding the attention map to cope with small-object scenarios. Moreover, GLA-CLIP can be equipped on existing methods and broad their receptive field. Extensive experiments validate the effectiveness of GLA-CLIP in enhancing training-free open-vocabulary semantic segmentation performance. Code is available at https://github.com/2btlFe/GLA-CLIP.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper is about teaching computers to “color in” every pixel of an image with the right label (like road, sky, dog) without doing any extra training. It builds on a famous model called CLIP, which already knows a lot about images and words from the internet. The paper focuses on making this work well on big, high‑resolution pictures and on categories that may not have been part of a fixed training list (this is called “open‑vocabulary” semantic segmentation).
The main questions the paper asks
- How can we use CLIP, without retraining it, to label every pixel in large images, even for categories the model wasn’t specifically trained to segment?
- Why do “sliding‑window” methods (cutting a big image into tiles) sometimes create visible grid-like mistakes, and how can we fix that?
- Can we make this approach both accurate and efficient on memory and speed?
- Will it still work well when the images come from very different sources (like satellites) instead of typical web photos?
How the method works (with simple analogies)
Big images are larger than CLIP’s usual input size (224×224). So many methods use “sliding windows”: they crop the big image into smaller squares, label each one, and then stitch the results back together. But this can cause mismatches where the tiles meet (like a quilt with misaligned patterns). The paper identifies this as a “window inconsistency” problem.
Their idea is called Global‑Local Alignment (GLA). Think of it like this:
- Local view: looking through a small magnifying glass (each window).
- Global view: stepping back and seeing the entire picture at once.
They align what the model sees up close with what it knows about the whole scene, so the pieces fit together smoothly.
To make this work, they add three helpful pieces:
- Key‑Value Extension (KVE): Like letting each small window “borrow notes” from the whole image, so it doesn’t miss the big context.
- Proxy Anchor: Like a guidepost or a coach that summarizes each category’s look and gently pulls local decisions toward more consistent choices.
- Dynamic Normalization: Like an automatic volume knob. Instead of using one fixed confidence setting everywhere, it adjusts based on how confident the model is for each part of the image. This helps with objects of different sizes and avoids over‑ or under‑labeling.
How they measure success:
- mIoU (mean Intersection over Union): A common accuracy score for segmentation. Higher is better.
- BER (Boundary Error related to grid artifacts): A score that checks for “checkerboard” or grid-like mistakes caused by sliding windows. Lower is better, and it captures visual smoothness that mIoU can miss.
They also test “domain shift,” which means trying the method on images very different from normal web photos (like aerial or satellite images). This checks how robust the method is.
Finally, they compare speed and memory: how many windows are needed, how long it takes, and how much GPU memory it uses.
What they found and why it matters
- Better accuracy without retraining: Their method consistently improves over recent training‑free baselines (like ProxyCLIP), raising mIoU while keeping CLIP’s zero‑shot (open‑vocabulary) strengths.
- Fewer grid artifacts: The masks look smoother and more natural across window boundaries. BER confirms this visual improvement, showing the method doesn’t just score better—it looks better too.
- Dynamic Normalization is crucial: When they turn it off, performance drops the most. It especially helps when combined with KVE and the Proxy Anchor.
- Works well across settings: Even when they change how they crop or stride windows, their method stays better than the baseline, showing it’s not fragile to setup changes.
- Robust to domain shift: On remote sensing datasets (like satellite views), their training‑free method beats a training‑based competitor (CLIP‑DINOiser), suggesting it handles new image types better without needing fine‑tuning.
- Efficient in practice: It supports batching multiple windows at once, so even with more windows, memory stays reasonable and speed is competitive. It’s more memory‑friendly than some alternatives (like CASS) while keeping good accuracy.
- Scales to big images: They define high‑resolution as anything larger than CLIP’s 224×224 input—exactly where sliding windows are needed—and they directly address the problems that show up there.
- Plays well with big foundation models: The approach can be adapted to work with models like SAM, showing it’s compatible with modern vision tools.
Why this is important
Open‑vocabulary, training‑free segmentation means you can label new kinds of objects without collecting data and retraining a model, saving lots of time and compute. Fixing the “sliding‑window” problem makes results look cleaner and more trustworthy on large images, which are common in real life (maps, street scenes, medical scans, and more). The method’s robustness to new domains suggests it could work well in places like remote sensing, where images look very different from everyday photos.
Final takeaway
This paper shows a practical way to use CLIP for pixel‑level labeling on big images, without retraining, by smartly combining global and local views. The result is more accurate, smoother segmentations that hold up across different datasets and remain efficient. While the approach is currently tied to a specific backbone (like a particular CLIP variant), within that setup it generalizes well—and it can plug into larger vision systems. This makes training‑free open‑vocabulary segmentation more useful and ready for real‑world applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- Statistical significance of the reported (modest) mIoU gains: no confidence intervals or across-run variability are reported; evaluate significance across multiple seeds, datasets, and label sets.
- Reliance on sliding-window inference for “high-resolution” inputs (>224×224): compare against non-sliding strategies (e.g., pyramid pooling, sparse/long-range attention, patch merging, memory-efficient full-resolution inference) to test if window inconsistency can be reduced without tiling.
- Global-Local Alignment (GLA) fusion details: formalize and ablate the exact merging strategy across overlapping windows (how features/masks are reconciled, weighting schemes), and quantify its impact on boundaries and class consistency.
- Dynamic normalization (Norm) mechanism: provide a theoretical justification, sensitivity analysis, and automatic per-image tuning (for parameters like u, w); assess robustness across datasets and backbones.
- Component interactions (KVE, Proxy Anchor, Dynamic Norm): move beyond isolated ablations to mechanistic analysis of why combinations help, and derive principled guidelines for when each component should be active.
- Proxy Anchor design: specify how proxies are selected/constructed, how many per class, and whether they can be adapted per image or per dataset; investigate automated proxy generation that scales with vocabulary size.
- BER metric validation: quantify correlation with human perceptual judgments and boundary quality metrics (e.g., boundary F-score), test its stability across datasets and resolutions, and examine cases where mIoU and BER disagree.
- Metric suite expansion: evaluate additional metrics (e.g., panoptic quality, calibration metrics such as pixel-wise ECE/Brier score) to understand trade-offs between accuracy, boundary quality, and confidence calibration.
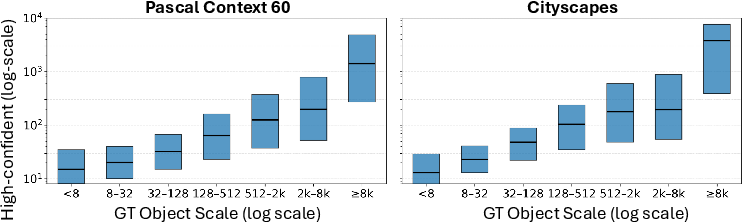
- High-confident token heuristic: characterize failure modes (texture-rich backgrounds, cluttered scenes, long-tailed classes), and compare against alternative object-scale proxies (multi-scale attention maps, saliency, uncertainty estimates).
- Adaptive stride and window sizing: develop algorithms to select stride/crop size per image/content to minimize BER under memory constraints; analyze performance on tiny/thin structures and large uniform regions.
- Backbone specificity: the approach is acknowledged to be backbone-specific; test and adapt across diverse CLIP variants (ViT-B/16, L/14, H/14, RN50/101), OpenCLIP, DINOv2, and other vision backbones to achieve backbone-agnostic behavior.
- Foundation model compatibility: quantify and standardize integration with SAM (versions, prompts, post-processing), and extend benchmarking to other large-scale models (e.g., DINOv2, OWL-ViT, EVA-CLIP).
- Domain shift robustness beyond remote sensing: broaden evaluation to medical, nighttime/adverse weather, cross-cultural scenes, and synthetic-to-real domains; include more training-based baselines and few-shot/hybrid strategies.
- Compute benchmarking scope: provide comprehensive scaling curves over image resolution, class vocabulary size, window count, and hardware (GPU/CPU, memory tiers); include worst-case analyses and out-of-core inference strategies for gigapixel imagery.
- Batch processing across windows: detail how global context is shared across windows in batch mode, and analyze latency–memory trade-offs as window count grows; explore distributed/streaming inference.
- Background threshold selection: replace fixed thresholds with calibrated or uncertainty-aware methods; study sensitivity and provide per-image adaptive calibration procedures.
- Prompt engineering effects: systematically evaluate label synonyms, multi-word phrases, negative prompts, and cross-lingual prompts; provide strategies for disambiguation in polysemous or fine-grained label sets.
- Vocabulary size scaling: analyze how performance and compute scale with larger open vocabularies (hundreds–thousands of classes), including conflict resolution when multiple labels fire for the same pixel.
- Small and rare object performance: conduct targeted evaluation on datasets emphasizing tiny/thin structures and rare classes; study recall vs. precision trade-offs with varying stride/window sizes.
- Failure modes beyond grid artifacts: quantify errors due to occlusions, overlapping instances, complex boundaries, motion blur, compression/noise; relate these to component choices (KVE, Proxy, Norm).
- Training-free vs training-based trade-offs: delineate regimes where light fine-tuning or few-shot adaptation improves robustness without undermining zero-shot generality; explore hybrid training-free + prompt-tuning approaches.
- Confidence calibration: assess whether dynamic norm improves calibration; report pixel-wise calibration metrics and investigate techniques (temperature scaling, Dirichlet calibration) tailored to open-vocabulary settings.
- Class name mapping and renaming: analyze how dataset-specific renaming (“Rename O→X”) affects semantic alignment and performance; propose automated label-space alignment methods.
- Reproducibility and auto-tuning: provide principled default settings and automatic hyperparameter selection strategies for new datasets, including window stride, crop size, normalization parameters, and background thresholds.
- Ethical and bias assessment: evaluate how CLIP’s known biases propagate to segmentation outputs; measure fairness across demographics and geographies, and propose mitigation strategies for open-vocabulary label sets.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented with the paper’s training-free, open-vocabulary semantic segmentation (OVSS) method that improves sliding-window consistency via global–local alignment (GLA), dynamic normalization, and proxy anchors, and that preserves CLIP’s zero-shot capability.
- High‑resolution, text‑prompted object selection in creative and GIS software
- Sector: software/media, GIS
- What: A plug‑in/SDK for Photoshop/GIMP and QGIS/ArcGIS that performs open‑vocabulary segmentation on high‑res images without retraining (e.g., “select all ‘road signs’,” “segment ‘water bodies’”).
- Why this paper: GLA reduces visible grid artifacts from sliding‑window inference on large images; works training‑free and supports batch window processing for efficiency.
- Tools/products/workflows: Desktop plug‑ins, a web API for text-to-mask, batch processing scripts for photo/GIS archives.
- Assumptions/dependencies: CLIP backbone available; GPU/VRAM budget scales with number of windows; careful prompt wording; performance best on domains covered by CLIP’s pretraining.
- Rapid, zero‑shot land‑cover and damage mapping from aerial/satellite imagery
- Sector: remote sensing, public sector, insurance
- What: Post‑disaster flood/burn scar/building footprint segmentation or general land‑cover mapping via prompts without labeled data or fine‑tuning.
- Why this paper: Demonstrated robustness under domain shift, particularly on multiple remote sensing datasets; fewer window‑grid artifacts and stable mIoU.
- Tools/products/workflows: Emergency mapping pipelines; insurer risk assessment; municipal planning dashboards.
- Assumptions/dependencies: Access to high‑res imagery; prompt taxonomies aligned to target classes; human-in-the-loop validation for critical decisions.
- Data mining and labeling acceleration for autonomy datasets
- Sector: automotive, robotics, ML Ops
- What: Zero‑shot segmentation to discover/flag rare categories (e.g., “construction cones,” “fallen tree”) and to pre‑label frames for human review.
- Why this paper: Training‑free deployment across diverse scenes; better consistency across tiles reduces QA burden; BER metric can flag stitching artifacts.
- Tools/products/workflows: Labeling queues pre‑seeded with masks; automatic mining of frames containing target categories; BER integrated into QC.
- Assumptions/dependencies: Primarily offline pipelines (not hard real‑time); CLIP bias toward web imagery; prompts curated for operational categories.
- Warehouse/indoor robotics: prompt‑based segmentation for manipulation
- Sector: robotics, logistics
- What: On‑the‑fly segmentation of novel items (“blue box,” “shipping label”) to support grasp planning without collecting labels.
- Why this paper: Compatible with foundation models like SAM—CLIP provides category semantics, SAM refines boundaries; GLA reduces window seams on high‑res frames.
- Tools/products/workflows: ROS node for text‑to‑mask; task graphs that bind prompts to downstream manipulation.
- Assumptions/dependencies: Lighting/backgrounds similar to web imagery improve results; prompts may require site‑specific tuning.
- Retail analytics and security video queries without retraining
- Sector: retail, security
- What: Batch analysis to segment newly defined classes (“shopping carts,” “safety vests”) across archived footage.
- Why this paper: Training‑free, scalable, fewer tiling artifacts; robust across settings and strides per ablations.
- Tools/products/workflows: Periodic audits; compliance checks; heatmaps of segmented objects.
- Assumptions/dependencies: Ethical and privacy compliance; typically offline or near‑real‑time workloads.
- Environmental monitoring and utilities inspection
- Sector: energy, environment, infrastructure
- What: Segment features like “solar panels,” “oil spills,” “corrosion,” “vegetation encroachment” in drone imagery with text prompts.
- Why this paper: Domain‑shift resilience shown on aerial data; window alignment reduces false seam boundaries on large frames.
- Tools/products/workflows: Drone ops post‑processing; maintenance ticket triggers; change detection workflows.
- Assumptions/dependencies: Domain coverage of CLIP varies—human verification recommended; prompt engineering for material/texture cues.
- Open‑vocabulary segmentation as a drop‑in improvement for existing windowed CLIP pipelines
- Sector: CV platforms, enterprise AI
- What: Replace or augment sliding‑window inference with GLA to lift mIoU and reduce artifacts without retraining models.
- Why this paper: Consistent gains over recent training‑free baselines; supports batched multi‑window inference with modest memory/latency.
- Tools/products/workflows: Library upgrade in internal CV services; configuration templates for stride/crop settings.
- Assumptions/dependencies: Same backbone family; memory increases with more windows but remains manageable.
- Better QA metrics for high‑res segmentation via BER
- Sector: research, ML Ops
- What: Adopt BER alongside mIoU to detect grid artifacts from window stitching during model validation and CI/CD gates.
- Why this paper: BER captures visual seam artifacts overlooked by mIoU; aligns with perceptual quality.
- Tools/products/workflows: Evaluation scripts; model release checklists; automated artifact alerts.
- Assumptions/dependencies: Implementation of BER; threshold calibration to operational needs.
- Teaching and demos of zero‑shot segmentation
- Sector: education, outreach
- What: Classroom/lab exercises demonstrating open‑vocabulary segmentation on high‑res images.
- Why this paper: Clear, modular ablations (KVE, proxy anchors, dynamic norm) enable instructive exploration.
- Tools/products/workflows: Notebooks and interactive apps.
- Assumptions/dependencies: GPU access for classes; curated prompt sets.
Long‑Term Applications
These opportunities are plausible but need additional research, integration, scaling, or domain adaptation before widespread deployment.
- Real‑time, on‑device open‑vocabulary segmentation
- Sector: automotive, AR/VR, mobile
- What: Streamed segmentation at video rates on edge hardware for HUD overlays or driver assistance.
- Path from paper: Optimize CLIP backbones, distill to lighter models, fuse GLA with efficient global context, and co‑design with accelerators.
- Assumptions/dependencies: Significant model compression; sustained latency targets; robustness in motion blur/low light.
- Clinical and scientific imaging zero‑shot segmentation
- Sector: healthcare, life sciences
- What: Prompted segmentation in radiology or microscopy (“necrotic tissue,” “tumor margin”) without labeled data.
- Path from paper: Swap in medically pretrained vision–LLMs (e.g., MedCLIP variants), validate rigorously, and adapt GLA to modality specifics.
- Assumptions/dependencies: Regulatory approval, domain shift is large; stringent QA and bias auditing required.
- 3D/Multimodal open‑vocabulary segmentation (RGB‑LiDAR, point clouds, volumetric)
- Sector: robotics, mapping, geospatial
- What: Global–local alignment across spatial blocks for 3D scenes with text prompts.
- Path from paper: Generalize window alignment and dynamic normalization to 3D neighborhoods; cross‑modal CLIP‑like embeddings.
- Assumptions/dependencies: Large‑scale 3D pretraining; memory‑efficient block processing.
- Text‑to‑instance segmentation by orchestrating SAM and OVSS at scale
- Sector: software, content creation, autonomy
- What: Productized service that turns prompts into per‑instance masks with clean boundaries across high‑res assets.
- Path from paper: Tight coupling of CLIP semantics (class scoring) with SAM proposals and GLA for tile coherence; cue fusion and de‑duplication.
- Assumptions/dependencies: Instance association across windows; efficient NMS/grouping; API and UX design.
- Nationwide disaster mapping and policy pipelines
- Sector: public sector, NGOs
- What: Standardized, prompt‑driven segmentation workflows for floods, wildfire, and infrastructure status at national scale.
- Path from paper: Proven domain‑shift handling; need enterprise orchestration, auditing, versioning, and human oversight.
- Assumptions/dependencies: Procurement, compliance, reproducibility, and workforce training.
- Massive‑scale auto‑labeling for dataset creation
- Sector: ML Ops, autonomy, vision platforms
- What: Pre‑segment millions of images/videos using evolving prompt catalogs; humans verify/correct.
- Path from paper: Use BER to auto‑tune stride/crop; dynamic norms as heuristics for object scale; active learning to prioritize uncertain samples.
- Assumptions/dependencies: Compute cost, storage pipelines, UI for efficient correction, bias management.
- Adaptive windowing controllers guided by BER and uncertainty
- Sector: systems, embedded AI
- What: Controllers that allocate stride/window density and batch size per frame to meet latency/quality targets.
- Path from paper: BER as a signal for artifact‑aware scheduling; dynamic normalization to adapt to object scale.
- Assumptions/dependencies: Real‑time resource monitors; multi‑objective optimization.
- Bias/fairness and safety auditing via open‑vocabulary probes
- Sector: governance, compliance
- What: Use prompts to probe segmentation behavior across demographics/contexts and detect failure modes.
- Path from paper: Training‑free probing lowers barrier to targeted evaluations; BER+mIoU capture visual and accuracy facets.
- Assumptions/dependencies: Curated, representative prompt sets; annotation and expert review.
- Cross‑lingual and domain‑aware prompting
- Sector: global software, localization
- What: Use multilingual prompts and synonyms for inclusive deployments.
- Path from paper: Extend CLIP/text encoder to multilingual variants; evaluate GLA stability across languages.
- Assumptions/dependencies: Availability of multilingual vision–language backbones; prompt standardization.
- Privacy‑preserving and offline deployments
- Sector: defense, healthcare, finance
- What: On‑premise OVSS stacks with no internet or cloud dependency.
- Path from paper: Model quantization, local GPU support, efficient batch windowing, policy‑compliant logging.
- Assumptions/dependencies: Hardware availability; reproducible builds; compliance audits.
Notes on global feasibility and dependencies across applications:
- Backbone specificity: The method currently assumes a fixed CLIP‑family backbone; porting to other encoders may require engineering.
- Prompt quality matters: Clear, domain‑appropriate prompts improve performance; controlled vocabularies help.
- Compute and memory: More windows increase memory; batching mitigates latency, but edge constraints may bind.
- Domain shift: Stronger in web‑adjacent and aerial domains; specialized domains (e.g., medical) require adapted backbones.
- Metrics: Pair mIoU with BER to monitor both accuracy and artifact‑free visual quality.
- Ethics and policy: For surveillance, healthcare, and public sector uses, ensure privacy, consent, and bias assessments.
Glossary
- Ablation study: A controlled analysis to assess the contribution of components or settings by systematically removing or varying them. "CASS + GLA Ablation Study."
- Attention pattern: The configuration of attention connections or receptive fields in an attention-based model. "single attn-pattern extension."
- Backbone: The core feature-extractor network that other components build upon. "backbone-specificity"
- Batch inference: Executing predictions on multiple inputs (e.g., windows) simultaneously for efficiency. "without batch inference"
- BER: A segmentation quality metric that captures boundary or grid-like artifacts not reflected by mIoU. "BER (\textcolor{blue}{Supp. Sec.~7}) captures sliding-window grid artifacts overlooked by mIoU."
- CASS: A prior method/baseline for training-free open-vocabulary segmentation used for comparison and combination with GLA. "CASS processes windows sequentially without batch inference"
- CLIP: A large vision-LLM (Contrastive Language–Image Pretraining) used for zero-shot recognition and as a backbone for OVSS. "CLIPâs resolution (224Ã224)"
- CLIP-DINOiser: A training-based method combining CLIP with DINO-like features for segmentation, used as a comparative baseline. "CLIP-DINOiser (Training-based)"
- CLIP-DIY: A prior method in the comparison set that, unlike most others, does not rely on sliding-window inference. "except CLIP-DIY"
- Domain shift: A change in data distribution between training and testing that can degrade model performance. "domain shift"
- Dynamic Norm: A dynamic normalization strategy that adapts normalization based on token confidence or context. "Fixed vs. Dynamic Norm ablation"
- Foundation model: A large, general-purpose pretrained model adaptable to many tasks, often via prompts or light tuning. "foundation model (SAM)"
- GLA (Global-Local Alignment): A mechanism aligning global and local evidence to mitigate inconsistencies from windowed inference. "addressed via global-local alignment."
- Grid artifacts: Unnatural, grid-like seams or patterns that arise from tiling images during sliding-window inference. "grid artifacts"
- Ground truth (GT): The human-annotated reference labels used for evaluation. "GT object size"
- High-confident tokens: Token-level features with high predicted confidence used as a heuristic for object presence or scale. "High-confident token count"
- High-resolution images: Inputs larger than the model’s native resolution that require tiling for inference. "We define high-resolution images as inputs exceeding CLIPâs resolution (224Ã224)"
- Key-Value Extension (KVE): An attention mechanism modification that extends key/value features to incorporate broader context. "KVE: Key-Value Extension"
- Latency: The time delay for processing, typically measured per image or per batch. "latency, and memory usage"
- mIoU: Mean Intersection over Union, the primary metric for segmentation accuracy averaged across classes. "mIoU gains"
- Normalization (Norm): Scaling or standardizing scores/activations (e.g., fixed vs dynamic) to stabilize predictions. "Norm: Normalization (Fixed, Dynamic)."
- Open-Vocabulary Semantic Segmentation (OVSS): Segmenting images into categories from an open set specified by text prompts, without closed-set training. "training-free OVSS"
- Proxy Anchor: Learnable proxy vectors serving as anchors to stabilize similarity-based classification or metric learning. "Proxy: Proxy Anchor"
- ProxyCLIP: A baseline method that augments CLIP with proxy anchors for segmentation. "ProxyCLIP (Baseline)"
- SAM: Segment Anything Model, a foundation model for segmentation used to test compatibility. "SAM"
- SCLIP: A specific CLIP-based setting/protocol referenced for fair measurement of latency and memory. "SCLIP setting"
- Sliding-window inference: Processing large images by tiling them into overlapping windows and merging predictions. "sliding-window inference"
- Stride: The step size between adjacent sliding windows, affecting overlap, accuracy, and cost. "sliding-window stride"
- Window inconsistency: Prediction discrepancies across neighboring tiles that cause visual seams or label mismatches. "window inconsistency"
- Zero-shot capability: The ability to perform a task without task-specific training by leveraging pretrained knowledge. "zero-shot capability"
Collections
Sign up for free to add this paper to one or more collections.