- The paper introduces SeeCo, a training-free module that recalibrates open-vocabulary segmentation by enforcing geometric and semantic consensus.
- It employs geometric consensus learning by simulating multi-view, rotated inputs to generate robust, rotation-invariant pseudo-labels.
- Semantic consensus learning enriches class descriptions via LLMs, yielding significant mIoU improvements across diverse remote sensing benchmarks.
Geometric-Semantic Consensus Recalibration for Open-Vocabulary Remote Sensing Semantic Segmentation
Introduction and Motivation
Remote sensing semantic segmentation (RSSS) plays a crucial role in earth observation applications such as land cover mapping, precision agriculture, and urban development. The recent surge of vision-LLMs (VLMs) such as CLIP has catalyzed rapid progress in open-vocabulary semantic segmentation (OVSS), allowing models to segment arbitrary land cover categories specified by textual queries. However, remote sensing images (RSIs) introduce two major challenges to current OVSS paradigms: arbitrary target orientations resulting from bird’s-eye observation and substantial intra-class heterogeneity across varied environments. Existing training-free OVSS methods inherit a static inference paradigm, which fails to dynamically adapt both vision and text representations to the unique geometric and semantic statistics of each test scene. This results in semantic ambiguity and under-activation of target regions.
To address these limitations, the paper proposes SeeCo (Seeking Consensus), a plug-and-play, training-free framework for inference-time adaptation of any OVSS model in remote sensing. SeeCo enforces both geometric and semantic consensus via a geometric consensus learning (GCL) module leveraging multi-view observations, and a semantic consensus learning (SCL) module that adaptively expands category descriptions using LLMs and visual priors. A lightweight online consensus injector (OCI) fuses these adaptations into vision and text branches, enabling on-the-fly recalibration without retraining.
Methodology
Geometric Consensus Learning
RSIs often contain rotated or non-canonical orientation targets, making rotation-equivariant representation essential. The GCL module simulates K diverse observation views of an input image by applying rotation operators. The segmentation model generates prediction maps on each rotated view, which are then inversely transformed and averaged to produce a robust, rotation-invariant geometric consensus target.
This target serves as self-supervised pseudo-labels for online adaptation at test time, regularizing the classifier to activate all spatial locations corresponding to the object across various geometric contexts. Compared to conventional masked image modeling and pseudo-labeling strategies, enforcing explicit multi-view consistency proves more effective in suppressing false positives and completing under-activated regions.
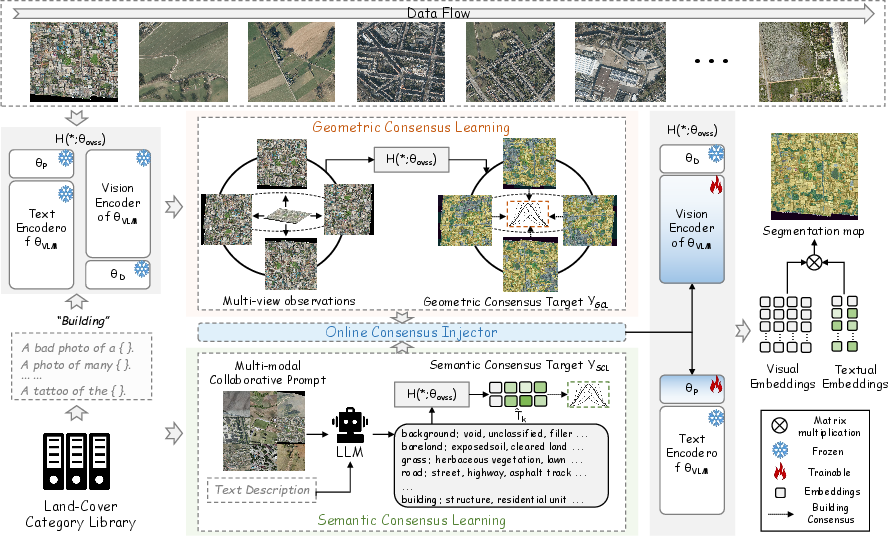
Figure 1: SeeCo framework overview—GCL simulates multi-view segmentation, SCL leverages LLMs and visual priors for textual enrichment, and OCI injects consensus for on-the-fly recalibration.
Semantic Consensus Learning
Fine-grained land cover categories in RSIs exhibit significant intra-class diversity, undermining cross-modal matching when fixed, static category names are used. SCL overcomes this by constructing multi-modal collaborative prompts for LLMs. Specifically, for each class, diverse synonyms and contextually relevant phrases are mined by providing textual instructions and visual priors from scene images to the LLM. The resulting enriched description library is encoded by the frozen VLM text encoder.
A learnable, scene-adaptive fusion mechanism aggregates the embeddings of these enriched descriptions into a semantic consensus target, which is then used to supervise online adaptation. This yields improved coverage of class semantics, enhances foreground activation, and mitigates the performance drop imposed by natural-image-pretrained text encoders facing remote sensing distribution shifts.
Figure 2: Multi-modal collaborative prompting synthesizes category synonyms and visually informed descriptions for robust text embedding enrichment.
Online Consensus Injector
The OCI module fuses geometric and semantic consensus into base OVSS models:
- Text branch: OCI implements adaptive context recalibration by injecting trainable context vectors into the text encoder.
- Vision branch: A low-rank adaptation (LoRA) head is appended to the last few transformer blocks, facilitating lightweight vision-side updates.
Combined, these parameter-efficient adapters can be optimized online for each image, using self-supervised and consensus-driven losses, without modifying the frozen VLM parameters.
Experimental Analysis
SeeCo was evaluated on eight diverse remote sensing benchmarks, including OpenEarthMap, LoveDA, iSAID, Potsdam, Vaihingen, UAVid, UDD5, and VDD, in both satellite and UAV imagery contexts. The system was integrated as a plug-in module into several methods: ClearCLIP, ProxyCLIP, and SegEarth-OV.
Results: Significant and consistent improvements were observed across all backbones and benchmarks. For instance, adding SeeCo to ProxyCLIP achieved a mean IoU (mIoU) improvement of 4.3% averaged across datasets, with absolute gains up to 11.9% on Vaihingen, a domain with pronounced distribution gap from natural images. Even when starting from a specialized remote sensing model like SegEarth-OV, SeeCo delivered a 3.3% mIoU boost.
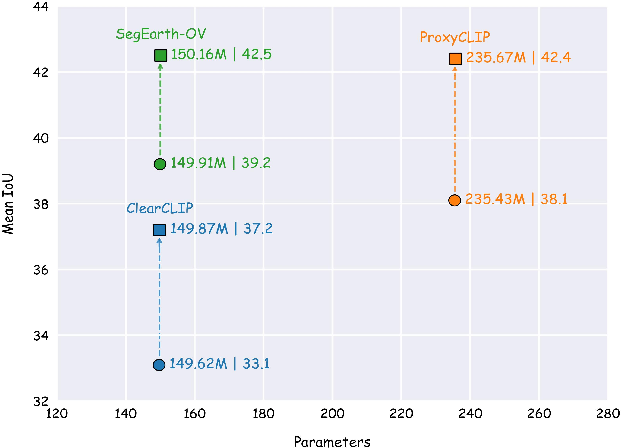
Figure 3: Performance gains and parameter increase from inserting SeeCo into SOTA OVSS methods on eight benchmarks.
SeeCo imposes negligible computational and memory overhead relative to the base models, with almost identical parameter counts and marginal test-time latency increases.
Qualitative analysis, including segmentation visualizations and t-SNE embeddings, demonstrates SeeCo’s superior ability to fully segment foreground regions, eliminate class confusion, and restore object boundaries that are missed in static paradigms.
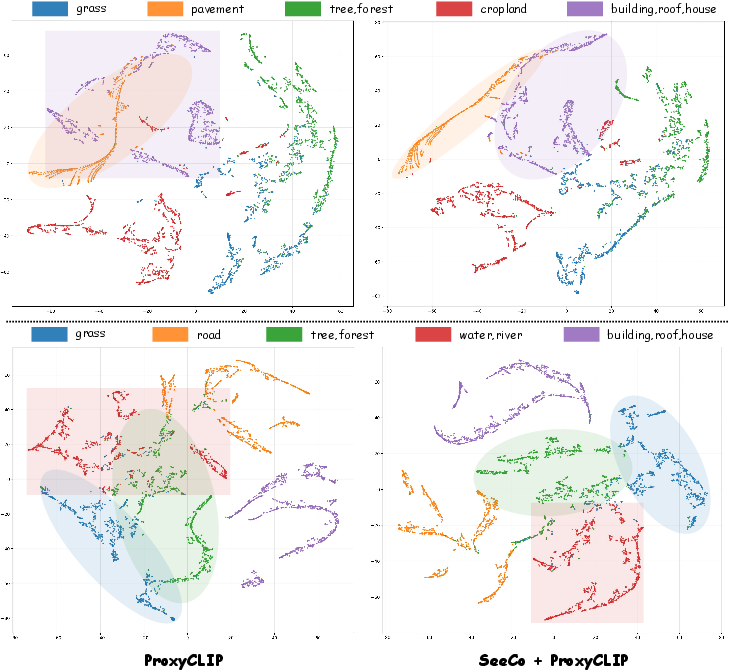
Figure 4: t-SNE feature distributions on OpenEarthMap show SeeCo’s improved inter-class separation over baselines.

Figure 5: Qualitative segmentation results on UDD5 and VDD highlight improved completeness and accuracy of land cover predictions under SeeCo.
Ablation and Component Analysis
Component-level ablation studies validate the necessity and complementarity of GCL and SCL. Geometric consensus provides average gains of 1–1.5% mIoU, and semantic consensus 1.5–2.6%; their combination realizes full benefits.
Comparisons against alternative self-supervised learning strategies (e.g., MIM, pseudo-labeling) confirm the advantage of explicit multi-view aggregation for geometric adaptation. Analogously, the synergy of text and visual prompts for SCL produces superior performance over purely textual enrichment.
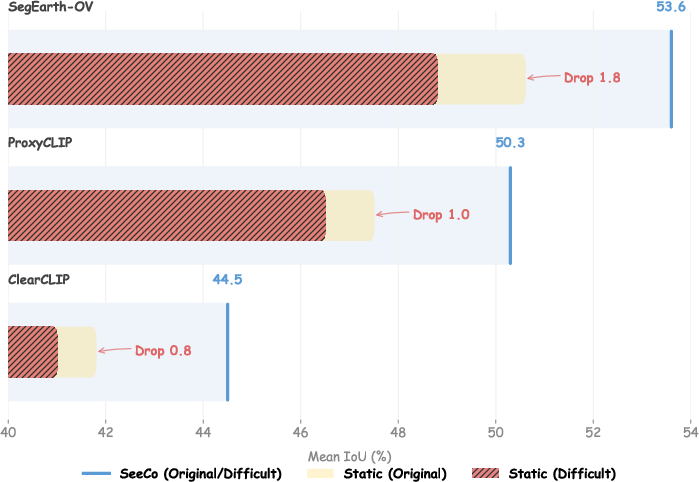
Figure 6: Multi-view observation robustness—SeeCo reduces accuracy degradation under drastic target orientation changes compared to baselines.
Hyperparameter sweeps show that performance is robust to the number of multi-view observations and the depth of injected blocks. Optimal gains are reached with four views and adaptation in the top two transformer layers.
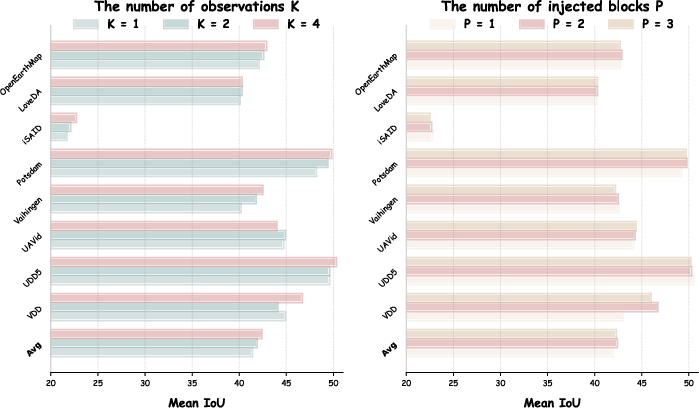
Figure 7: Effect of number of views K and number of adapted blocks P; SeeCo maintains robustness across a range of settings.
Theoretical and Practical Implications
SeeCo demonstrates that explicit geometric and semantic adaptation at inference time—without retraining or labeled data—can markedly improve VLM-based segmentation in domains with strong distribution shifts and non-canonical object arrangements. The plug-and-play design means SeeCo can serve as a universal enhancement module, extending to other dense prediction tasks or domains where semantic and geometric variation is prevalent.
The approach also validates the utility of LLM-assisted prompt engineering in low-supervision regimes, even with frozen encoders, pointing towards broader applications of on-the-fly context enrichment for cross-modal tasks.
Conclusion
SeeCo introduces a framework for inference-only, per-scene recalibration of OVSS models in remote sensing, synthesizing geometric consensus from multi-view analysis and semantic consensus from LLM-powered textual enrichment. This dual-adaptation significantly reduces under-activation and semantic ambiguity, as evidenced by comprehensive empirical results, and offers a general recipe for robust open-vocabulary perception in distribution-shifted or weakly supervised settings. Future research may extend SeeCo to general visual domains, scale the adaptive modules, and investigate joint optimization of multi-modal consensus signals.