- The paper introduces PixCLIP, a novel approach that leverages pixel-level masks and LLM-powered text encoders to achieve any-granularity pixel-text alignment.
- It employs a multi-branch architecture, including mask-text contrastive learning and local-global enhancement, to deliver state-of-the-art region classification and retrieval performance.
- The study demonstrates significant improvements on benchmarks using the LongGRIT dataset and highlights the scalable integration of fine-grained visual and textual representations.
PixCLIP: Fine-Grained Visual-Language Understanding via Any-Granularity Pixel-Text Alignment
Introduction and Motivation
PixCLIP advances the state-of-the-art in multimodal foundation modeling by targeting two primary limitations of previous approaches: visual representation is typically restricted to either the entire image or coarse bounding boxes, and text encoding is often capped at short sequences due to architectural constraints—most notably, CLIP’s 77-token maximum. Existing models fail to robustly support arbitrary region-level inputs and long-form textual descriptions simultaneously, hindering high-fidelity alignment at fine-grained levels, particularly for tasks such as region-based semantic retrieval, referring expression comprehension, and mask/text matching.
PixCLIP is designed to overcome these bottlenecks by: (1) accepting pixel-level mask inputs that specify arbitrary regions of interest for visual embedding, and (2) leveraging LLM-powered text encoders to process long and semantically rich descriptions—thus achieving alignment across any granularity in vision-language tasks.
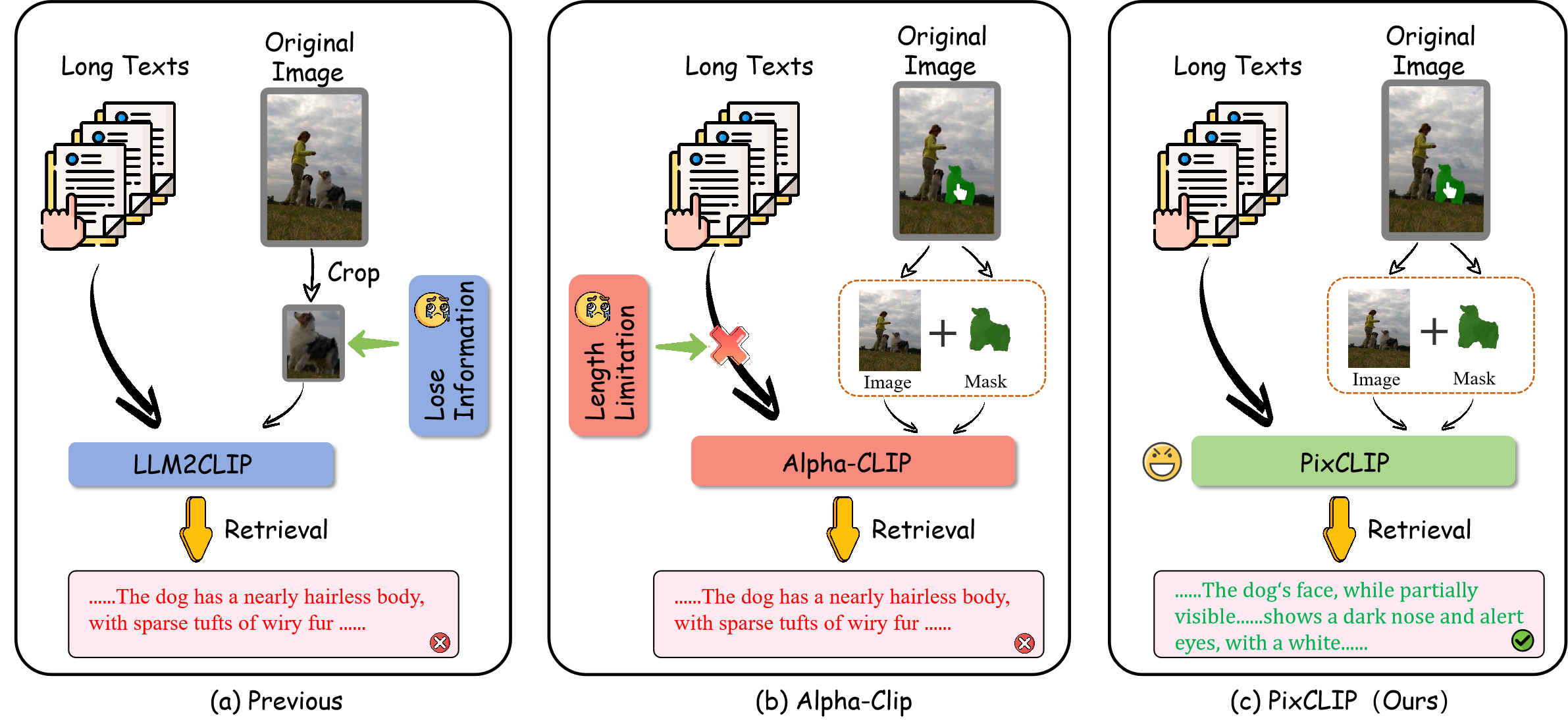
Figure 1: Comparison between prior methods, promptable models, and PixCLIP, highlighting PixCLIP’s capability to yield robust image/text embeddings regardless of input granularity.
Data Pipeline and LongGRIT Construction
A major contribution is the automated construction of the LongGRIT dataset—1.5M mask/text pairs with rich, precise descriptions and multi-level semantic coverage. The process is three-staged:
- Object-level: Masked object regions are described via InternVL2-76B, focusing on static attributes.
- Context-level: Griffon-G-26B generates relational captions by considering the bounding box within the image’s contextual environment.
- Fine-grained synthesis: DeepSeek-R1-70B merges these into hybrid captions with comprehensive detail.
Quality filtering is conducted with Qwen2-72B for semantic validity, resulting in region-caption pairs suitable for contrastive training, and benchmarking more robust mask/text retrieval than prior datasets restricted to short, global-level captions.
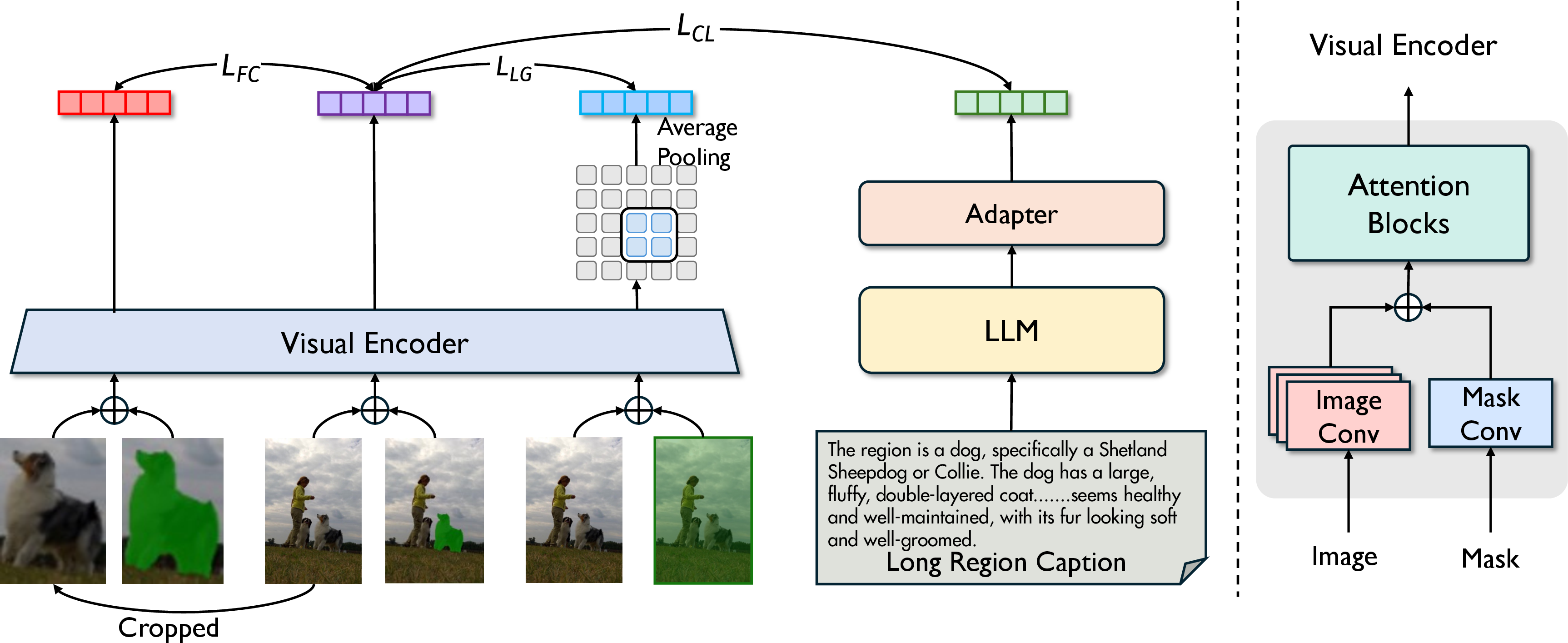
Figure 2: PixCLIP framework detailing inherited weights, parallel mask embedding, and multi-branch alignment modules for enhanced mask-based embedding.
Model Architecture and Training Methodology
The core changes to CLIP’s architecture are the addition of a mask patch embedding pathway, initialized at zero to preserve prior knowledge, and the replacement of the short-sequence Transformer text encoder with an LLM (e.g., LLAMA3-8B), which is first fine-tuned/self-supervised and then frozen to maximize training efficiency. This enables ingestion of both full-image and masked local inputs, paired with arbitrarily long textual descriptions.
Three branches orchestrate multi-granularity alignment:
- Mask-Text Contrastive Branch: Visual and text embeddings are aligned via contrastive loss, with mask inputs guiding the vision encoder focus and the LLM enabling long-form text features.
- Fine-Grained Cropping Alignment: Cropped masked regions are passed through the encoder; the resulting features are aligned with those from mask-based input, but only for positive samples to avoid excessive context loss.
- Local-Global Representation Enhancement: Embeddings from full-image (all-1 mask) inputs jointly optimize local detail and global context, using pooled features to reinforce complementary regional and holistic representation.
The overall loss integrates the three branches:
L=LCL+αLFC+βLLG
with α,β=0.25 suggested for ViT-B/16, batch size 1024, and convergence observed after 8 epochs on 8 H20 GPUs.
Experimental Analysis and Results
PixCLIP demonstrates SOTA results across a spectrum of fine-grained and classical benchmarks:
- Zero-shot Region Classification: On ImageNet-S (919 semantic segmentation classes), PixCLIP achieves 69.57% Top-1 accuracy and 91.17% Top-5 accuracy on ViT-B/16, outperforming MaskCLIP, Alpha-CLIP, and prompt engineering methods.
- Instance-COCO Region Classification: Achieves 76.68% Top-1 accuracy, notably higher than the previous SOTA for region-level recognition.
- Referring Expression Comprehension (REC): On RefCOCO/+/g, PixCLIP obtains 59.93/69.9/61.8% scores, surpassing Alpha-CLIP and traditional prompt-based and box-based methods.
- Pixel-Level Retrieval: On Ref-SAV, Recall@1 increases from 28.3% (Alpha-CLIP) to 47.3% (PixCLIP) for mask-to-text, and similar improvements for text-to-mask.
PixCLIP also matches or exceeds previous models such as LLM2CLIP and LongCLIP on both short-text and long-text cross-modal retrieval benchmarks (MSCOCO, Urban1K, DOCCI, ShareGPT4V), indicating that supporting any-granularity input does not sacrifice traditional CLIP capabilities.
Ablation Studies
Ablation experiments underscore the necessity of all three branches: direct mask-text alignment alone leads to catastrophic forgetting and degraded global performance, while the auxiliary cropping and local-global branches synergistically reinforce robust representation. Notably, mixing short and long texts during training counteracts distribution mismatches, maintaining high scores on both ImageNet and fine-grained retrieval.
Visualization and Interpretation
Attention map visualizations reveal targeted focus on user-indicated regions, with [CLS] token attention centered around masked areas. Full-image attention maps further demonstrate PixCLIP’s ability to enhance local features without diminishing global semantics when presented with composite and lengthy textual input.
Implementation Considerations
- Resource Requirements: Multi-branch training with large batch sizes and high-throughput GPUs (e.g., H20 100G) is necessary for convergence and real-world scalability.
- Data Generation: Automated, multi-MLLM data pipelines can be adapted to other domains; hard-negative mining and dataset scaling are promising avenues to enhance robustness.
- Inference: Only full-image and mask inputs are required at inference time, streamlining deployment relative to the training regime.
Limitations and Future Work
Current dataset size (1.5M) is suboptimal for further scaling, and the absence of aggressive hard-negative sampling may limit discriminative capacity. Future directions include integrating region-aware instruction-following in downstream MLLM tasks, generalized region-based adaptation, and open-set fine-grained benchmarking. Extending PixCLIP to novel modalities and enhancing transferability to video or 3D point clouds are areas ripe for exploration.
Conclusion
PixCLIP provides a scalable and unified solution for fine-grained pixel-text alignment, facilitating robust region-level modeling while retaining classical CLIP capabilities. The approach demonstrates that collaborative optimization of mask-guided and text-extended alignments is critical for building general multimodal systems with high granularity and interpretability. The release of the LongGRIT dataset and accompanying retrieval benchmarks contributes practical infrastructure for future research in the vision-language domain.

