Secure Linear Alignment of Large Language Models
Abstract: LLMs increasingly appear to learn similar representations, despite differences in training objectives, architectures, and data modalities. This emerging compatibility between independently trained models introduces new opportunities for cross-model alignment to downstream objectives. Moreover, it unlocks new potential application domains, such as settings where security, privacy, or competitive constraints prohibit direct data or model sharing. In this work, we propose a privacy-preserving framework that exploits representational convergence to enable cross-silo inference between independent LLMs. The framework learns an affine transformation over a shared public dataset and applies homomorphic encryption to protect client queries during inference. By encrypting only the linear alignment and classification operations, the method achieves sub-second inference latency while maintaining strong security guarantees. We support this framework with an empirical investigation into representational convergence, in which we learn linear transformations between the final hidden states of independent models. We evaluate these cross-model mappings on embedding classification and out-of-distribution detection, observing minimal performance degradation across model pairs. Additionally, we show for the first time that linear alignment sometimes enables text generation across independently trained models.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
The paper explores a simple but powerful idea: many different LLMs seem to “think” in similar ways on the inside. Because of that, you can often translate the internal features from one model into the “language” of another model using a very simple rule. The authors show how to use this translation to:
- combine parts of different models,
- do tasks like classification and even some text generation across models, and
- keep users’ data private and secure while doing it, using fast encryption.
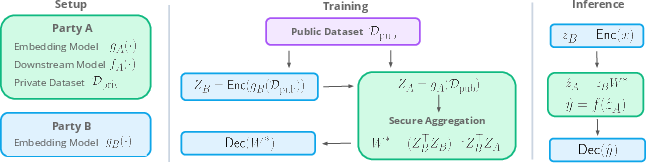
They call their approach a secure alignment method that performs only simple, linear math on encrypted data, so it stays fast (sub‑second per input) and private.
What questions the researchers asked
The paper focuses on three easy-to-understand questions:
- Do different LLMs learn similar “internal representations” (their hidden features) even if they were trained separately?
- If yes, can a simple “translator” (a linear/affine map—think of it like a straightforward conversion formula) move features from one model into another model’s space so a shared tool (like a classifier or a text decoder) still works well?
- Can we do this translation and prediction privately—so the service never sees the user’s input—without slowing things down too much?
How they approached it (methods in everyday terms)
- Internal features as “embeddings”: When a model reads text, it turns it into a big list of numbers that summarize meaning—this is called an embedding. Think of it like a fingerprint of the sentence.
- A simple translator: The authors learn a simple formula that takes embeddings from Model B and converts them into the form that Model A expects. This formula is linear (like “multiply by this matrix and add this bias”), which is fast and easy to compute.
- Learned on public data: They learn this translator using a shared, non-sensitive public dataset (like Wikipedia or IMDB), so no private data needs to be exchanged.
- Private prediction with “locked” data: They use a technique called homomorphic encryption (HE). Imagine locking your numbers in a box that still lets someone do math on them without opening it. The server runs the final, simple math (the linear classifier) on your locked (encrypted) features and sends back a locked answer. Only you can unlock it. Because the math is linear, this stays fast.
- What they tested:
- Representational similarity: They measured how similar different models’ internal features are using a metric called CKA. You can think of CKA as a “how similarly do they see the world?” score.
- Downstream tasks: They tried text classification and finding out-of-distribution (OOD) inputs (detecting when something looks unfamiliar) after translating embeddings between models.
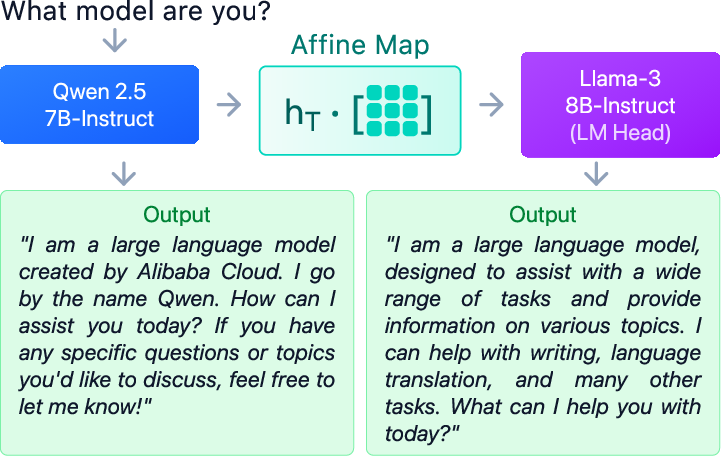
- Text generation: They tried a tougher test—using one model’s internal features but another model’s output head to generate text. This is like plugging one brain into another model’s mouth and asking it to speak.
- Extra tech terms in simple words:
- Linear/affine map: A straightforward “conversion recipe” for numbers: multiply by a matrix, add a vector.
- Tokenizer: How a model chops text into small pieces (like splitting a sentence into word-parts). If two models chop text very differently, it’s harder to plug them together for generation.
What they found and why it matters
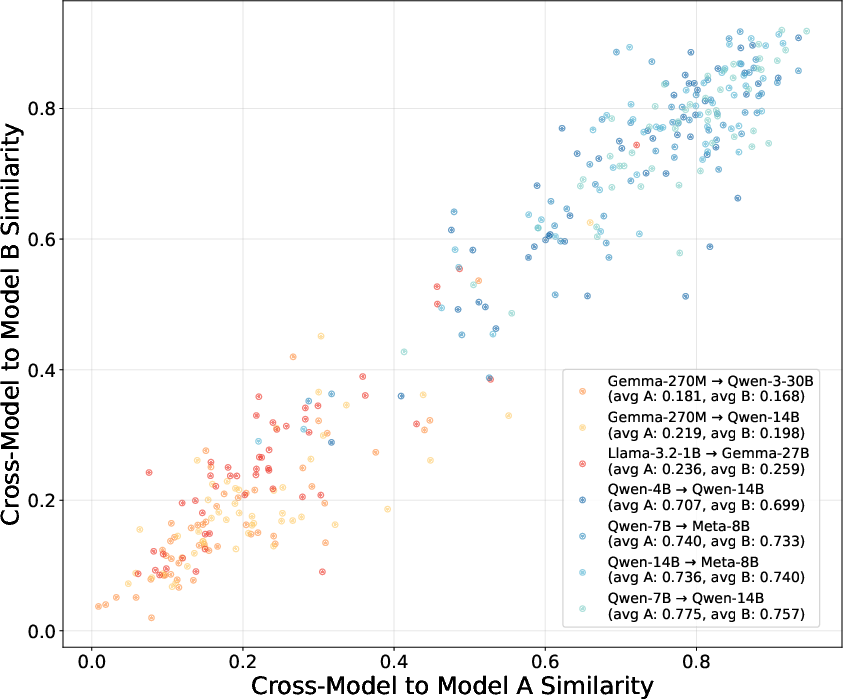
- Different models are more similar than you might think:
- Their similarity scores (CKA) were high across many pairs of models from different companies, meaning the models’ internal representations share a lot of structure.
- Classification still works after translation:
- They trained a classifier on Model A’s features and then fed it translated features from Model B. Accuracy stayed close to the original model’s performance on tasks like TREC, AG News, MNLI, and DBpedia.
- Even for OOD detection (spotting unfamiliar inputs based on confidence), the translated features often matched or even improved the baseline confidence behavior.
- Text generation sometimes works—under the right conditions:
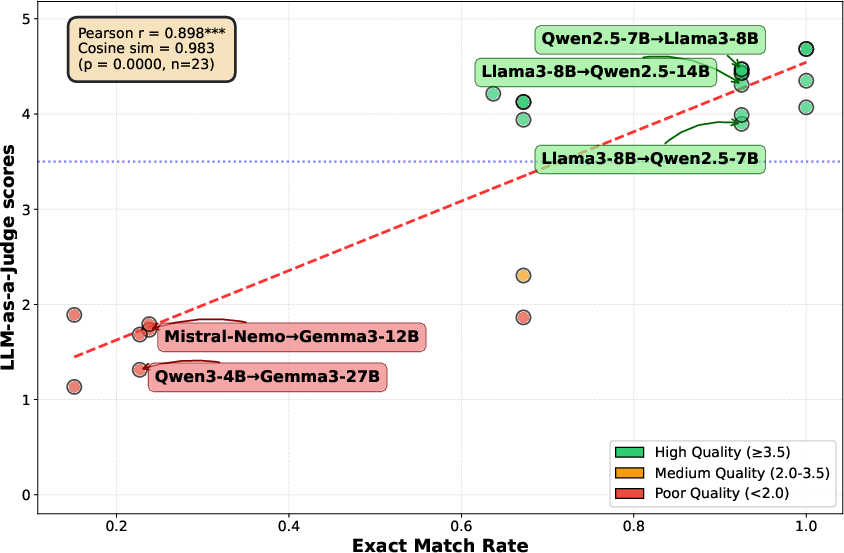
- When they mapped Model B’s hidden features into Model A’s feature space and used Model A’s output head, some model pairs produced coherent text.
- Two big factors predicted success:
- Tokenizer compatibility: If the two models split text similarly, generation quality was much higher. This was strongly correlated with better outputs.
- Model size: Smaller models (below ~4B parameters) struggled to generate good text when stitched to larger models. Stronger source models mapped into weaker targets worked better than the reverse.
- Fast and private:
- Because they encrypt only the simple linear parts (translation and classification), prediction runs in under a second per example with strong security (128‑bit).
- The server never sees the user’s raw text or embeddings; it only sees encrypted vectors. The model owner also doesn’t have to share their model.
- Practical trade-offs:
- Learning the translator only on public data already works well. Adding a tiny number of in‑distribution examples (like 64–128 samples) can boost performance more, but that involves sharing a small amount of task data, which some settings may not allow.
What this could mean going forward (implications)
- Privacy-friendly collaboration: Companies or organizations can combine strengths—one uses their own embedding model locally, another provides a powerful classifier—without sharing private data or proprietary models.
- Modular AI systems: If different models naturally “think” similarly, future systems can be built like Lego blocks: swap in an encoder from one place and a classifier or decoder from another, connected by a simple translator.
- Faster secure AI: Encrypting only the simple, linear parts keeps private inference practical and fast, making it more feasible to deploy privacy-preserving AI in real apps (e.g., healthcare, finance, education).
- Research insight: The results support the idea that big models converge on similar internal representations. This encourages more research into cross-model compatibility—and how to design tokenizers and architectures to make stitching even easier.
- Limitations to keep in mind: The approach relies on a linear translator and a shared public dataset, works best for classification, and only sometimes for generation. It assumes both sides behave honestly (semi-honest security model) and doesn’t encrypt the entire transformer, just the final linear parts.
In one sentence
The paper shows that different LLMs often “think” alike enough that a simple, secure translator can connect them—letting people use one model’s features with another model’s tools, privately and quickly, with strong results on classification and, in some cases, even text generation.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future work.
- Theoretical guarantees for cross-model linear alignment: No formal bounds are provided on when an affine map preserves task performance across models with differing architectures, objectives, tokenizers, and data. Develop conditions and error bounds (e.g., excess risk under linear mapping, stability under distribution shift) and sample complexity for learning .
- Sensitivity to public–private distribution shift: Alignment is fit on public data (optionally with 64–128 in-distribution samples), but the impact of domain mismatch on downstream accuracy and OOD reliability is not quantified. Characterize performance as a function of distribution divergence, and estimate how many public samples are needed to achieve given accuracy targets.
- Choice of alignment objective: Only ridge regression (normal equations) is used. Compare alternatives (orthogonal Procrustes, CCA/SVCCA, partial least squares, constrained/orthogonal mappings, per-layer or token-wise maps) and assess trade-offs for classification and generation.
- Layer selection and multi-layer alignment: Alignment is performed on the final/penultimate hidden state. Evaluate whether aligning earlier or multiple layers (or layer-wise ensembles) improves transfer, especially for generation and OOD detection.
- Nonlinear adapters under HE constraints: The framework limits secure computation to linear heads. Investigate low-degree polynomial or piecewise-linear adapters compatible with CKKS to recover nonlinearity benefits while maintaining feasible latency.
- Robustness and stability of : Numerical stability of under collinearity and high dimensionality is not analyzed. Study conditioning, regularization selection, and pre-/post-normalization (centering, whitening) impacts on performance and privacy.
- Tokenization mismatch remediation: Success in generation correlates with tokenizer compatibility but no remedy is proposed. Explore learned token translation layers, byte/character-level bridging, shared vocabulary induction, or alignment in a tokenizer-agnostic space.
- Causal factors in generation success: Correlations with tokenizer match rate and model size are reported, but causal mechanisms are untested. Perform ablations (same architecture/different tokenizers, same tokenizer/different architectures) and controlled token-mapping interventions to isolate causes.
- Generality of generation results: Generation is evaluated on short prompts with greedy decoding and up to 128 tokens. Assess longer contexts, diverse decoding strategies (beam, nucleus), safety/toxicity, factuality, and robustness across broader tasks and domains.
- Asymmetric transfer in generation: Strong→weak mappings work better than weak→strong. Clarify whether this is due to head capacity, representation quality, or tokenization. Test with controlled capacity-matched heads and calibrated normalization.
- Multilingual and cross-modal applicability: All experiments appear English-centric and text-only. Evaluate alignment and secure inference in multilingual settings (different scripts and tokenizers) and across modalities (e.g., speech/text, text/vision embeddings).
- OOD detection calibration under mapping: Energy-based OOD relies on calibrated logits; how mapping affects logit scale and calibration is unclear. Study temperature scaling, score calibration, and alternative OOD scores after alignment.
- Security model limitations (semi-honest only): The protocol assumes honest-but-curious parties. Extend to malicious adversaries with verifiable computation (e.g., ZK proofs of correct encryption/computation), and analyze resilience to poisoning or adaptive attacks by a malicious client/provider.
- Leakage from returning logits: The framework returns full logits to the client by default; this may enable model extraction or membership inference against the provider. Quantify leakage and benchmark encrypted argmax/top-k, noisy logits, or DP mechanisms to mitigate it.
- Privacy of the alignment map : Although initial membership inference analysis is referenced, may leak sensitive structural properties (e.g., subspace directions) of the provider’s representation. Provide formal leakage bounds (e.g., DP on ), test property inference attacks, and evaluate defense efficacy.
- Training-time leakage and attack surface: The secure training protocol exposes encrypted and plaintext to the provider and returns to the client. Analyze whether repeated protocol runs, chosen-public sets, or collusion can amplify leakage, and evaluate protections (noise addition, auditing, rate-limiting).
- End-to-end scalability of secure training: No measurements are given for time/compute to homomorphically compute at realistic scales (large N, high ). Benchmark training runtime, memory, and communication with streaming and batching, and assess GPU/ASIC acceleration for HE.
- Inference throughput and batching: Latency is reported as sub-second per sample, but throughput under batching, multi-query pipelines, and varying , , and number of classes K is not characterized. Provide throughput/latency curves and communication-volume measurements over realistic networks.
- CKKS precision effects: The impact of CKKS quantization/noise on logit accuracy, calibration, and OOD detection is not separated from the plaintext baseline. Quantify accuracy degradation from HE alone and tune scale/modulus to trade precision vs. latency.
- Applicability to nonlinear or multi-head classifiers: Many real systems use multilayer or attention-based heads. Explore structured linear heads (low-rank, block-diagonal) or HE-friendly approximations to better match practical classifiers.
- Robustness to adversarial queries: The susceptibility of aligned, encrypted inference to adversarial example transfer or gradient-free extraction is unexplored. Evaluate adversarial robustness and design defenses (randomized smoothing, dropout at representation level, certified bounds).
- Dynamic drift and model versioning: Vendor embeddings and tokenizers evolve. Devise mechanisms to detect drift, update with minimal public data, and ensure backward compatibility without exposing private information.
- Multi-tenant and many-to-one deployments: How to manage and isolate many client-specific maps to a single provider head (scalability, storage, and interference)? Analyze cross-client leakage and collusion risks.
- Key management and side channels: Practical deployment issues (key rotation, compromised keys, timing/traffic analysis, ciphertext size side channels) are not addressed. Propose mitigations and evaluate overhead.
- Fairness and bias transfer: Whether alignment preserves, amplifies, or mitigates biases from either model is unexamined. Audit subgroup performance, measure bias transfer, and test fairness-aware alignment objectives.
- Reproducibility with proprietary APIs: Reliance on vendor embeddings limits reproducibility and longitudinal stability. Provide open-source replications and document variability due to API updates or rate limiting.
- Communication-cost quantification: Communication overhead is asserted (<1 MB per sample) but not empirically measured across dimensions, batch sizes, and packing schemes. Report end-to-end bytes transferred and sensitivity to HE parameters.
- Integration with DP for formal client/provider guarantees: No differential privacy is applied. Explore DP-noised sufficient statistics for training and DP on logits at inference to provide formal privacy budgets for both parties.
- Extending secure generation: The secure framework only covers linear heads; text generation experiments are plaintext. Investigate whether any part of cross-model generation can be secured efficiently (e.g., securing only token selection or partial linear projections) without prohibitive latency.
Practical Applications
Immediate Applications
The following applications can be deployed today using the paper’s method (secure linear alignment with homomorphic encryption over linear operations), empirical results (classification, OOD detection, sub-second latency), and observed constraints (public-data alignment, semi-honest threat model, tokenizer effects).
- Bold: Bring-your-own-encoder (BYOE) privacy-preserving classification APIs
- Sectors: healthcare, finance, legal, government, enterprise IT, customer support
- What: Clients compute embeddings locally with their own model, linearly align them to the provider’s feature space, encrypt the aligned vector, and get predictions from the provider’s encrypted linear head (sub-second latency).
- Tools/products/workflows:
- “Secure Feature Alignment SDK” (client-side): compute W*, apply alignment, CKKS encrypt, call provider’s API
- “Encrypted Linear Head Service” (provider-side): CKKS-enabled microservice that performs homomorphic logits computation (e.g., TenSEAL-based)
- MLOps integration: a minimal HE gateway that sits in front of existing linear heads (logistic regression, linear SVM, linear layer)
- Dependencies/assumptions: semi-honest threat model; linear head on provider side; availability of a shared public dataset to fit W*; client can compute embeddings locally; leakage via W* is bounded as analyzed; optional encrypted argmax for stronger provider IP protection
- Bold: Privacy-preserving ticket routing, triage, and tagging
- Sectors: customer support, IT service management, HR, legal ops
- What: Classify tickets/emails/documents (e.g., urgency, team routing, topic) using private client data and public alignment into a provider’s task head without sharing raw text.
- Tools/products/workflows: “Encrypted Triage Router” plugin for helpdesk software (e.g., ServiceNow, Zendesk); linear heads trained per client vertical; on-device or VPC embedding generation
- Dependencies/assumptions: linear classification head; public data alignment; low-latency internet link; semi-honest model
- Bold: Protected content moderation and safety classification
- Sectors: social platforms, gaming, enterprise collaboration
- What: On-device embeddings for user content; encrypted classification for toxicity, self-harm risk, policy violations using provider’s specialized head trained on sensitive data.
- Tools/products/workflows: “Privacy-Preserving Moderation API”; mobile SDK for on-device embedding and CKKS client; server-side HE inference shard
- Dependencies/assumptions: linear head; public alignment set; content not exfiltrated; semi-honest threat model
- Bold: Secure OOD detection and drift monitoring as a service
- Sectors: regulated AI deployments across all industries
- What: Use energy-based OOD detection on encrypted aligned embeddings to monitor distribution shift or data quality issues without exposing inputs.
- Tools/products/workflows: “Encrypted Drift Monitor” that ingests encrypted aligned vectors and returns confidence/OOD flags; dashboards for risk teams
- Dependencies/assumptions: frozen linear head with accessible logits; public alignment set; semi-honest model; suitable thresholds per deployment
- Bold: Cross-vendor embedding interoperability for MLOps
- Sectors: software/ML platforms, SaaS
- What: Align embeddings from Vendor B to Vendor A’s feature space to reuse trained linear heads, reduce relabeling, and ease migration/A/B tests.
- Tools/products/workflows: “Embedding Bridge” adapter between vectorization backends; batch re-scoring pipelines that map stored embeddings to new heads
- Dependencies/assumptions: representational convergence holds between chosen models; linear head; availability of public dataset similar enough to the task domain for W*
- Bold: Private legal and compliance classification
- Sectors: legal, compliance, procurement
- What: Classify contracts, policies, or disclosures (e.g., clause type, risk flags, regulatory categories) with encrypted aligned embeddings; provider keeps specialized head proprietary.
- Tools/products/workflows: “Encrypted Clause Classifier” microservice; client-side alignment step integrated into DMS/CLM systems
- Dependencies/assumptions: linear head; semi-honest model; public alignment data; data residency/privacy approvals are simplified since only encrypted aligned vectors leave the client
- Bold: Enterprise email/spam/phishing filtering with user privacy
- Sectors: enterprise security, productivity
- What: On-device or gateway embeddings; encrypted classification for spam/phishing categories using provider’s head trained on threat intel datasets.
- Tools/products/workflows: “HE Mail Filter” gateway; client-side alignment agent on mail server; provider head updated without client data sharing
- Dependencies/assumptions: linear head; timely inference (sub-second is sufficient for server processing); public alignment data
- Bold: Research tooling for representational analysis and model stitching
- Sectors: academia, applied research labs
- What: Use linear CKA, linear alignment, and cross-model performance transfer to study representational convergence, reproducibility, and interpretability under privacy constraints.
- Tools/products/workflows: Open-source “Model Stitching Lab” package (affine map fitting, CKA/SVCCA, encrypted covariance exchange); shared benchmarks for classification and OOD
- Dependencies/assumptions: access to public corpora for alignment; standardized embedding extraction pipelines
- Bold: Privacy-preserving benchmarking marketplaces for domain heads
- Sectors: AI marketplaces, specialized model providers
- What: Providers offer encrypted linear heads trained on proprietary data (e.g., medical triage, financial risk), and clients evaluate performance privately using BYOE embeddings plus alignment.
- Tools/products/workflows: “Encrypted Head Catalog” with trial keys, usage metering, rate limiting, and optional encrypted argmax to reduce extraction risk
- Dependencies/assumptions: linear head; public alignment data; licensing/commercial terms for head usage; semi-honest model
- Bold: Edge-cloud split for regulated deployments
- Sectors: healthcare, finance, government, telecom
- What: Edge devices (or on-prem) compute embeddings; cloud performs encrypted classification with tight latency budgets for interactive workflows (e.g., clinician support).
- Tools/products/workflows: “Edge Embedding + Cloud HE Head” architecture; containerized CKKS microservices with autoscaling; audit logs showing encrypted-only data movement
- Dependencies/assumptions: reliable edge embedding throughput; linear head; tight networking SLAs; semi-honest assumptions
Long-Term Applications
The following applications require further research, scaling, or ecosystem development (e.g., stronger security models, tokenizer/architecture standards, or broader protocol support).
- Bold: Hybrid LLMs via cross-model linear alignment for generation
- Sectors: software, creative tools, education, conversational AI
- What: Compose a source model’s transformer blocks with a target model’s LM head to generate text across independently trained models; exploit tokenizer compatibility and sufficient model scale.
- Tools/products/workflows: “Hybrid Decoder” runtime that learns affine maps, performs token-level alignment, and orchestrates cross-model decoding
- Dependencies/assumptions: strong tokenizer compatibility (e.g., exact token match rate ≥ ~0.67) and sufficiently large source model (≥ ~4B parameters) as indicated by the paper; robust token alignment; quality/consistency validation; not yet production-grade across arbitrary pairs
- Bold: Cross-vendor RAG interoperability and secure retrieval
- Sectors: enterprise search, knowledge management
- What: Map client embeddings to the server’s VDB space to enable retrieval with mismatched encoders; optionally encrypt query vectors for privacy-preserving search.
- Tools/products/workflows: “Alignment Adapter” for vector databases (Pinecone/Weaviate) that accepts aligned queries; optional HE/MPC for private similarity search
- Dependencies/assumptions: alignment trained on public data that matches the domain; potential accuracy loss if representational convergence is weak; secure search beyond linear ops requires additional crypto systems
- Bold: Federated transfer learning via alignment statistics
- Sectors: healthcare networks, consortia in finance/government
- What: Institutions exchange only encrypted sufficient statistics (cross-covariances) to compute W* and reuse heads across silos without sharing raw data, embeddings, or full models.
- Tools/products/workflows: “HE Federated Alignment” protocol and scheduler; secure aggregation for cross-covariances; governance templates for cross-institution usage
- Dependencies/assumptions: semi-honest model; alignment quality depends on public/pooled data; coordination overhead; compliance reviews
- Bold: Stronger adversarial security (malicious settings) and provider IP protection
- Sectors: all regulated/competitive domains
- What: Extend to malicious adversary models (e.g., HE+MPC, ZK proofs of correct evaluation, encrypted argmax-only responses) to reduce extraction risks and tighten leakage bounds.
- Tools/products/workflows: “Hardened HELD” combining CKKS with MPC/NIZK; rate-limiting and watermarking; secure audit trails
- Dependencies/assumptions: higher latency/compute; protocol complexity; formal security proofs and red-team validation
- Bold: Standardized interoperability layer for LLM feature spaces
- Sectors: AI infrastructure, standards bodies
- What: Define specs for feature-space dimensions, token alignment metadata, and linear adapter formats so model providers can advertise compatibility and clients can switch providers with minimal friction.
- Tools/products/workflows: “Feature Alignment Manifest” published with models; conformance tests (CKA thresholds, stitching performance)
- Dependencies/assumptions: multi-vendor collaboration; benchmarking and certification processes
- Bold: Hardware-accelerated HE for real-time encrypted inference
- Sectors: cloud providers, chip vendors, telecom
- What: Accelerate CKKS (and related schemes) on GPUs/ASICs to support large batch encrypted linear algebra and lower end-to-end inference latency well below 100 ms for interactive use.
- Tools/products/workflows: HE kernels integrated into BLAS/cuBLAS equivalents; HE-aware autoscaling; cost-aware schedulers
- Dependencies/assumptions: hardware availability; optimized packing/rotation strategies; engineering investment
- Bold: Multi-head encrypted inference marketplaces
- Sectors: AI marketplaces, vertical model providers
- What: Compose multiple encrypted linear heads (toxicity, sentiment, policy, risk) over the same aligned embedding stream to deliver a “privacy-preserving analytics bundle.”
- Tools/products/workflows: “Encrypted Head Graph” runtime; unified billing/SLAs; client-side alignment once, many encrypted heads downstream
- Dependencies/assumptions: composability of linear heads; governance for downstream usage; pricing models
- Bold: Cross-domain and multimodal extensions
- Sectors: robotics, autonomous systems, vision/speech analytics
- What: Investigate whether representational convergence and linear alignment extend across modalities (e.g., map audio/vision encoders to shared heads), enabling privacy-preserving classification from sensors.
- Tools/products/workflows: “Multimodal Alignment Lab” to estimate W* across modalities, evaluate OOD and safety classifications
- Dependencies/assumptions: empirical validation of convergence across modalities; domain-appropriate public datasets; potentially different tokenization/alignment challenges
- Bold: Policy and compliance frameworks recognizing feature-level encrypted inference
- Sectors: regulators, standards bodies, compliance teams
- What: Establish guidelines that treat encrypted aligned features and HE-only inference as compliant cross-border processing for PII/PHI, reducing barriers to secure AI adoption.
- Tools/products/workflows: Model risk management templates; DPIAs tailored to HE alignment; procurement clauses specifying semi-honest guarantees and leakage analyses
- Dependencies/assumptions: regulator engagement; formal privacy analyses; sector-specific requirements (e.g., HIPAA, GDPR)
- Bold: Automated alignment selection and quality prediction
- Sectors: MLOps, platform engineering
- What: Choose model pairs automatically based on tokenizer compatibility (exact match/Jaccard), CKA metrics, and pilot stitching scores to predict success before deployment.
- Tools/products/workflows: “Alignment Recommender” service; CI/CD checks that fail unsafe/low-compatibility pairings; monitoring for drift in alignment quality
- Dependencies/assumptions: access to compatibility signals; periodic revalidation as models/versions change
Notes on Core Assumptions and Dependencies
- Representational convergence: The approach relies on empirical linear compatibility between independently trained models; quality varies by pair.
- Public dataset for alignment: W* is estimated from shared public data; utility improves with closer domain match or limited in-distribution augmentation (privacy–utility trade-off).
- Linear heads: Strongest results and sub-second latency assume a linear classifier (or final linear token head).
- Threat model: Semi-honest adversaries; malicious security requires additional protocols (at increased cost/latency).
- Tokenizer compatibility and model scale: For generation, success depends on tokenizer overlap and sufficient source model size (≥ ~4B parameters) per the paper’s findings.
- Performance/latency: CKKS over linear ops achieves sub-second inference; network conditions and batch size affect real-world latency.
- Leakage: Alignment map W* reveals structural info (e.g., dimensions) but not training labels or head parameters; measured membership inference advantage is negligible under stated configurations.
Glossary
- affine transformation: A linear mapping combined with a bias shift that preserves points, straight lines, and planes. Example: "The framework learns an affine transformation over a shared public dataset"
- AUROC: Area Under the Receiver Operating Characteristic curve; a scalar measuring how well a score separates two classes. Example: "We report AUROC by thresholding to distinguish in- vs.\ out-of-distribution samples."
- autoregressive architectures: Models that generate or predict the next element in a sequence based on previous elements. Example: "encoder-style and autoregressive architectures achieving strong generalization across diverse tasks"
- bootstrapping: In HE, a costly operation that refreshes ciphertext noise to allow deeper computations. Example: "requiring no bootstrapping or modulus switching beyond standard rescaling."
- Centered Kernel Alignment (CKA): A similarity metric for comparing representations across neural networks. Example: "Linear CKA similarity across embedding APIs."
- CKKS: A homomorphic encryption scheme supporting approximate arithmetic on real-valued vectors. Example: "We implement \gls{held} using TenSEAL CKKS with poly_modulus_degree=8192"
- cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. Example: "We compare Cross-Model text generation to the text produced by each base model using cosine similarity (using OpenAI's embedding-001)."
- cross-covariance: A matrix capturing pairwise covariances between two sets of variables or representations. Example: "computes the encrypted cross-covariance "
- cross-silo inference: Performing inference across different organizations or systems that cannot share data/models directly. Example: "enable cross-silo inference between independent LLMs."
- Energy score: An OOD detection metric computed from logits by log-summing exponentials; higher values suggest OOD. Example: "We use the Energy score"
- Homomorphic Encryption: Cryptography that enables computation on encrypted data without decrypting it. Example: "applies homomorphic encryption to protect client queries during inference."
- Homomorphic Encryption Security Standard: A community standard specifying security levels and parameter choices for HE. Example: "according to the Homomorphic Encryption Security Standard"
- honest-but-curious (semi-honest) threat model: Assumes parties follow the protocol but try to learn additional information from messages. Example: "We adopt a semi-honest (honest-but-curious) threat model"
- Jaccard index: A set-similarity measure defined as intersection over union; here used for vocabulary overlap. Example: "Jaccard index (r = 0.822) correlating with text generation quality."
- linear identifiability: The property that learned representations can be related by an invertible linear transform under certain conditions. Example: "Linear Identifiability."
- logits: Pre-softmax scores output by a classifier that indicate relative confidence for each class. Example: "OOD detection evaluates whether a model can separate in-distribution inputs from unseen data by probing its logits confidence."
- LLM-as-a-Judge: An evaluation approach where a LLM scores or compares outputs for quality. Example: "We assess quality through LLM-as-a-Judge evaluation"
- membership inference attacks: Attacks aiming to determine whether a specific sample was in a model’s training data. Example: "defend against model extraction and membership inference attacks"
- model extraction: Attempts to recover a model or its parameters by querying it and analyzing outputs. Example: "defend against model extraction and membership inference attacks"
- model stitching: Connecting parts of different models via adapters to test interchangeability of representations. Example: "prior work on model stitching shows that independently trained models can be aligned"
- multiplicative depth: The number of sequential multiplications in a circuit; a key complexity/feasibility metric in HE. Example: "minimal multiplicative depth (depth-1: one ciphertext-plaintext multiplication)"
- ordinary least squares: A regression method minimizing squared errors between predictions and targets. Example: "ordinary least squares with ridge regularization ()"
- out-of-distribution (OOD) detection: Identifying inputs that do not come from the training distribution. Example: "OOD detection evaluates whether a model can separate in-distribution inputs from unseen data"
- perplexity: A measure of uncertainty in language modeling; lower values indicate better predictive performance. Example: "show lower perplexity degradation"
- Platonic Representation Hypothesis: The idea that large models converge to similar latent structures capturing real-world statistics. Example: "the Platonic Representation Hypothesis"
- ridge regularization: L2 penalty added to regression to improve conditioning and prevent overfitting. Example: "ridge regularization ()"
- scaling laws: Empirical relationships linking model/data/compute scale to performance and capabilities. Example: "driven by scaling laws that link model size, compute, and data volume to emergent capabilities"
- secure aggregation: A protocol that aggregates client data in encrypted form so the server learns only the aggregate. Example: "via secure aggregation."
- secure multi-party computation (MPC): Cryptographic methods that allow parties to jointly compute a function without revealing inputs. Example: "combines \gls{he} with \gls{mpc} to accelerate end-to-end interactive private inference."
- semantic security: A strong guarantee that ciphertexts leak no information about plaintexts beyond what is inferable from outputs. Example: "semantic security implies these ciphertexts reveal no information"
- SIMD packing: Packing multiple values into a single ciphertext to enable parallel encrypted operations. Example: "since CKKS uses SIMD packing to encrypt multiple values into a single ciphertext."
- tokenizer compatibility: Degree to which two tokenizers produce matching token sequences/vocabularies; affects cross-model transfer. Example: "tokenizer compatibility strongly predicts success"
Collections
Sign up for free to add this paper to one or more collections.