Vulnerabilities in Partial TEE-Shielded LLM Inference with Precomputed Noise
Abstract: The deployment of LLMs on third-party devices requires new ways to protect model intellectual property. While Trusted Execution Environments (TEEs) offer a promising solution, their performance limits can lead to a critical compromise: using a precomputed, static secret basis to accelerate cryptographic operations. We demonstrate that this mainstream design pattern introduces a classic cryptographic flaw, the reuse of secret keying material, into the system's protocol. We prove its vulnerability with two distinct attacks: First, our attack on a model confidentiality system achieves a full confidentiality break by recovering its secret permutations and model weights. Second, our integrity attack completely bypasses the integrity checks of systems like Soter and TSQP. We demonstrate the practicality of our attacks against state-of-the-art LLMs, recovering a layer's secrets from a LLaMA-3 8B model in about 6 minutes and showing the attack scales to compromise 405B-parameter LLMs across a variety of configurations.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how to run big AI models (like chatbots) on someone else’s computer without letting them copy or mess with the model. Many systems try to do this by keeping the “secret parts” inside a secure chip area called a TEE (Trusted Execution Environment) and sending the heavy math to a fast graphics card (GPU). To save time, these systems reuse a small set of secret “noise” pieces to hide data. The paper shows that this performance shortcut is a serious security mistake: attackers can spot patterns in that reused noise, undo the protection, and either steal the model or bypass safety checks.
What questions did the researchers ask?
In simple terms, they asked:
- If a system uses a small, pre-made set of secret “noise” pieces to hide information, can an attacker figure out those patterns and break the system?
- Does this flaw let attackers:
- Steal the hidden parts of the model (so they can reconstruct it)?
- Trick the system’s built-in honesty checks (so it won’t notice when results are tampered with)?
How did they study it?
They examined a popular design pattern used to protect models called “Mask–Offload–Restore”:
- Mask: Inside the TEE (think of it as a locked room in the computer), the system hides the real data by adding secret “noise,” like putting on a disguise.
- Offload: It sends the disguised data to the GPU (fast but untrusted) to do the heavy calculations.
- Restore: The result goes back to the TEE, which removes the noise to get the correct answer or checks whether the GPU cheated.
Here’s the problem they found. To run fast, these systems don’t create totally fresh, random noise each time (that’s slow and uses lots of memory). Instead, they:
- Precompute a small set of K secret “basis” noise vectors at startup (think of mixing all sounds/noises from the same small set of 10 instruments).
- For each query, they just combine those K pieces in different amounts to make “new” noise.
That’s much faster—but it means every “random” noise actually lives inside the same small space (like every melody using the same 10 instruments). Over time, an attacker can learn that space and filter it out.
The researchers considered a strong attacker who:
- Controls everything outside the TEE (the operating system and GPU),
- Can see and alter messages going in and out of the TEE,
- Knows the system’s design,
- But cannot break into the TEE itself.
They analyzed two kinds of protections that use this precomputed noise:
- Model confidentiality (keeping the model’s “secret shuffle” of weights hidden),
- Computational integrity (hiding “test inputs” among real inputs to catch cheating).
They also explained why developers choose precomputation:
- On-the-fly true randomness is too slow and memory-heavy for big models (for some layers, it takes tens to hundreds of milliseconds per layer—far too slow).
- Precomputation is super fast (hundreds of times faster) but forces all noise into a tiny, predictable “noise space.”
What did they find?
Main results:
- The reuse of a small, static noise basis is a fundamental weakness. It’s like reusing parts of a secret key over and over.
- Attack 1 (stealing the model’s secrets): They showed how to recover the “secret shuffles” (permutations) used to lock the model’s weights. Once you know the shuffle, you can reorder things and reconstruct the original model. They did this on modern models (like LLaMA-3 8B) and could recover a layer’s secrets in about 6 minutes; the approach scales to extremely large models (405B parameters).
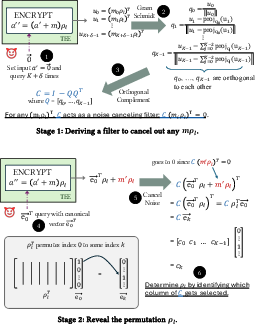
- How it works (simplified):
- Send special inputs to the system to collect only the noise output (e.g., sending zeros so the output is just noise).
- From many such outputs, learn the small noise space (like recognizing a band’s signature sound).
- Build a “filter” that removes this noise from future outputs.
- Then send simple “probe” inputs to see how positions are rearranged (like tracking where each card goes in a shuffled deck) and uncover the hidden shuffle.
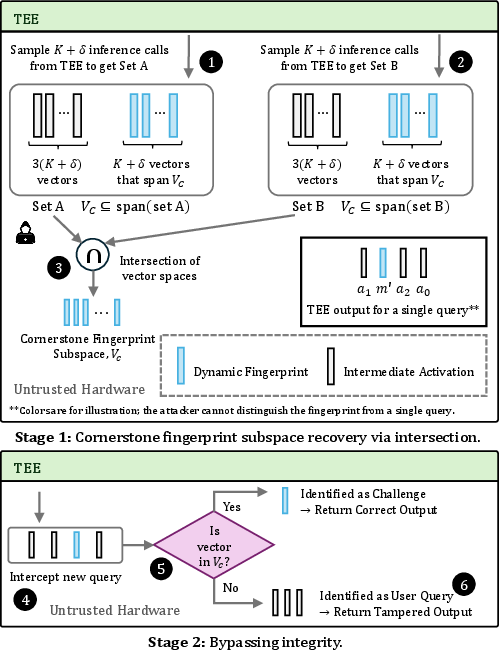
- Attack 2 (bypassing integrity checks): Systems like Soter and TSQP hide “known-answer tests” among real requests to catch cheating GPUs. But because those tests are generated from the same small noise basis, attackers can:
- Detect which inputs are hidden tests (they sit in the special noise space),
- Handle or forge the tests correctly,
- Tamper with the real work while staying undetected.
- These are not side-channel or hardware hacks. They are protocol-level weaknesses: the way the system is designed (reusing a small noise basis) is the root cause.
Why this is important:
- It shows that a widely used performance trick can break the very security it’s supposed to provide.
- It threatens both the confidentiality (protecting expensive, proprietary models) and integrity (ensuring honest computation) of large AI deployments.
Why does it matter?
- For AI companies: This means your models can be stolen or tampered with even if you use TEEs and standard protective tricks, if you rely on a small set of precomputed noise.
- For users and businesses: It questions the trustworthiness of local, “confidential” AI services that depend on these designs.
- For system designers: It’s a cautionary tale. Speed shortcuts that reuse secret material (like a small noise basis) can quietly introduce a “low-rank” signature that attackers can isolate and exploit.
Possible takeaways and directions:
- Avoid reusing a small noise basis across requests. True one-time randomness is safer—but today it’s too slow for huge models.
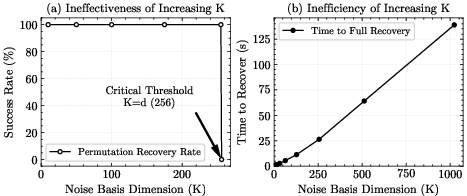
- If you must precompute, dramatically increasing K (the number of basis vectors) reduces predictability, but that quickly hits memory and speed limits.
- Invest in better hardware support (more capable TEEs or secure accelerators) or different protocols that don’t require removing noise effects inside the TEE.
- Re-examine integrity-check designs so hidden tests don’t live in a special, easily separable space.
In short: the paper shows a clear trade-off—speed vs. security—and warns that the current “fast path” many systems use can open the door to powerful, practical attacks on today’s largest LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future work could address to solidify, generalize, or bound the paper’s claims.
- Clarify and validate the attacker’s ability to issue chosen inputs at internal ENCRYPT call sites (e.g., sending zero vectors or canonical basis vectors to the FFN boundary). In realistic PTSE deployments, can the adversary programmatically invoke ENCRYPT with arbitrary activations, or are they restricted to activations produced by the forward pass?
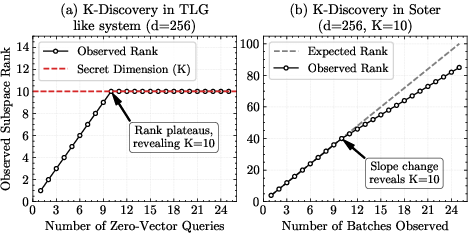
- Quantify the query complexity in full-model recovery. Stage 2 requires roughly d queries per layer (d ≈ 4k–16k), repeated across L layers (32–80+). How many end-to-end inference requests does this translate to, how long would a complete model recovery take in practice, and how detectable is this usage?
- Assess resilience against operational defenses such as rate limiting, session timeouts, quotas, anomaly detection (e.g., repeated near-zero or structured activations), and per-session auditing. How many queries can be realistically issued before triggering safeguards?
- Specify the scope and lifetime of the “static basis.” Is the basis fixed per process, per session, per user, per device, or per layer? Analyze how rekeying frequency (e.g., per batch or per token) affects attack feasibility and cost.
- Provide quantitative trade-offs between basis dimension K and attack success/cost. What K values (per layer) make subspace recovery impractical under realistic usage constraints, and how do memory/latency budgets translate into concrete risk windows?
- Evaluate the attack under alternative interface constraints (e.g., when the adversary cannot send zero vectors or canonical basis vectors). Can attackers induce required internal activations through adversarial prompts or linear combinations of plausible inputs?
- Reconcile the linear-algebraic attack procedures with finite field arithmetic. The paper invokes Gram–Schmidt and projection matrices (C = I − QQᵀ), but “orthonormality” and projections are ill-defined in the same way over finite fields. Provide a field-appropriate basis/annihilator construction (e.g., via nullspace computation) and analyze numerical/field-specific stability.
- Analyze the impact of quantization error, rounding, and potential modulo wrap-around on subspace identification and permutation recovery. What bounds on P and scaling are required to preserve linear structure across all layers without wrap-around, and how do real kernels’ rounding modes affect the attack?
- Examine nonlinearity and fused-kernel effects. While the attack targets linear sub-operations, do nonlinearity placements, fusion, or kernel reordering impede the ability to isolate and query the relevant linear blocks in practice?
- Provide complete end-to-end empirical timelines and costs for full-model recovery on representative LLMs (e.g., 8B, 70B, 405B): time per layer, number of queries, total wall clock time, and compute/logistics requirements across all layers.
- Investigate whether per-token, per-batch, or per-layer dynamic basis rotation (with secret PRF coefficients) materially increases attacker cost without reintroducing on-the-fly matrix multiplies. What rotation frequency is sufficient to block subspace learning under realistic load?
- Explore hybrid/structured restorations that avoid low-dimensional subspaces without incurring full on-the-fly cost (e.g., PRF-driven convolutional/Toeplitz masks with fast in-TEE transforms, FFT-friendly structures, or tile-wise streaming multiplies with partial precomputation).
- Reassess feasibility of on-the-fly approaches on modern server-class TEEs (Intel TDX, AMD SEV-SNP, Arm CCA) with large secure memory and higher in-enclave compute. Provide measurements (not just bounds) to determine if latency is acceptable with tiling, vectorization (AVX-512), or multi-core parallelism.
- Generalize beyond permutation-based locking. Do similar subspace attacks compromise other obfuscations (e.g., block-diagonal permutations, random orthogonal transforms, learned secret linear transforms, morphing schemes)? What transformations resist basis-reuse exploitation?
- Reevaluate the integrity attacks when defenders vary fingerprint generation (e.g., larger K, per-request dynamic basis, non-linear fingerprints, mixed-domain embeddings). How do these changes affect the subspace intersection attack’s success and stealth?
- Analyze detectability and service-impact trade-offs for integrity bypass. If an attacker tampers while avoiding detection on recovered fingerprint subspaces, what is the induced accuracy degradation, and how detectable is this via monitoring/telemetry?
- Consider deployments with confidential accelerators (e.g., NVIDIA Confidential Computing, future GPU TEEs). Can these eliminate or shift the need for precomputed noise effects, and thereby close the identified vulnerability? Provide a concrete security/performance assessment.
- Formalize security models and proofs. The paper argues a protocol-level “key reuse” flaw but does not provide a formal game/definition showing that precomputed basis reuse violates confidentiality/integrity under standard assumptions. A formal treatment would clarify the exact conditions under which the break holds.
- Specify how assumptions about obtaining π₁ from “permuted token embeddings” hold across tokenization schemes and embedding pipelines. What concrete observables are available to an attacker to recover π₁ in typical deployments?
- Provide robustness analyses for multi-tenant and distributed settings: concurrent sessions, batching across multiple users, noise from scheduling, and heterogeneity across GPUs/hosts. Do these factors help or hinder subspace isolation?
- Detail how the attack copes with defensive randomness outside the target subspace (e.g., extra random padding, randomized batch ordering, or shuffling of check placement). Can the attacker still isolate the low-rank component reliably?
- Offer and evaluate concrete mitigations with quantified overheads (e.g., frequent rekeying, larger K, hybrid on-the-fly tiling, randomized output blinding, authenticated computation proofs). Without measured defenses, it is unclear which mitigations are practical for LLM inference.
Glossary
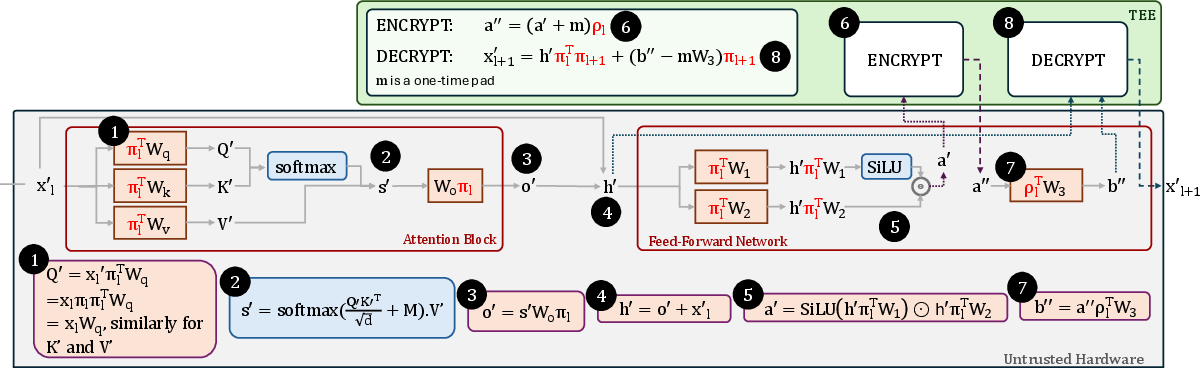
- Additive one-time pad: An encryption method that masks data by adding a random vector (over a finite field) to the input to hide plaintext values. "Additive one-time pad, , on the input feature map, : ."
- Blinding coin: A secret random scalar used to multiplicatively blind a linear operator so the computation reveals nothing about the true result without its reciprocal. "Parameter Morphing: Multiplies the linear operator with a secret scalar blinding coin, ."
- Canonical basis vector: A unit vector with a single 1 and the rest 0s, used to probe or reconstruct linear mappings coordinate-wise. "once for each canonical basis vector (e.g., )"
- Challenge Injection: An integrity technique that inserts hidden, known-answer inputs into a batch so the TEE can verify the correctness of offloaded computations. "Challenge Injection: Injects a fingerprint vector , a random linear combination of a static basis of cornerstone inputs, : ."
- Confidential computing architectures: Hardware platforms that provide isolated execution and memory protection for workloads, enabling secure processing on untrusted systems. "recent confidential computing architectures like Intel TDX, AMD SEV, Arm CCA, and NVIDIA's Confidential Computing"
- Computational integrity: The property that offloaded computations are performed correctly and have not been tampered with by untrusted hardware. "Model's computational integrity is sometimes protected using a technique called oblivious fingerprinting"
- Cornerstone inputs: A fixed set of preselected inputs whose outputs are precomputed so the TEE can verify linearity-based integrity checks efficiently. "a static basis of cornerstone inputs, "
- ENCRYPT-LINEAR-DECRYPT: A three-step protocol where the TEE masks data, the untrusted accelerator performs the linear computation, and the TEE then restores or verifies the result. "the system uses a three-step ENCRYPT-LINEAR-DECRYPT sequence"
- Finite field: A mathematical field with finitely many elements (often a prime field) that enables secure one-time pad masking without floating-point issues. "all computations are performed over a finite field."
- Fingerprint vector: A hidden probe input mixed with real activations to test and verify the correctness of offloaded computation. "Injects a fingerprint vector "
- Fixed-point quantization: Converting floating-point values to integer representations so arithmetic can be performed securely in a finite field. "all floating-point activations and weights are first quantized to fixed-point integers."
- Gram-Schmidt process: An algorithm that orthonormalizes a set of vectors to compute a basis for a subspace, useful for isolating reused noise subspaces. "applies the Gram-Schmidt process to compute an orthonormal basis"
- Homomorphic Encryption (HE): Cryptographic methods enabling computation on encrypted data without decrypting it. "One approach to securing inference relies on purely cryptographic methods like Homomorphic Encryption (HE), which allow computation on encrypted data."
- Key-reuse vulnerability: A cryptographic weakness where repeated use of the same secret material across queries enables algebraic or statistical attacks. "a new manifestation of key-reuse vulnerability in partial TEE-shielded executions."
- Lock-and-key principle: An obfuscation approach where a model is locked via a secret transformation and only usable with the corresponding secret key. "cryptographic obfuscation, which operates on a ``lock-and-key'' principle"
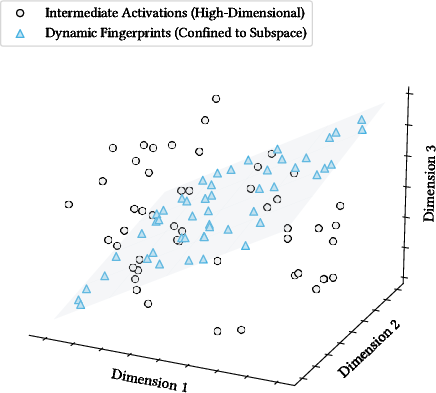
- Low-rank vulnerability: A weakness caused by randomness restricted to a low-dimensional subspace (due to a small basis), making it learnable across queries. "creates a low-rank vulnerability that our attacks exploit."
- Mask-Offload-Restore protocol: A pattern where inputs are masked in the TEE, heavy linear operations are offloaded, and outputs are restored or verified in the TEE. "a three-step Mask-Offload-Restore protocol"
- Model confidentiality: Protecting the intellectual property of model weights/parameters against disclosure on untrusted hardware. "Many TEE-based model confidentiality schemes operate on a lock-and-key authorization principle"
- Obfuscation: Transforming a model (e.g., via permutations) to conceal its parameters from unauthorized use, requiring a secret to recover functionality. "the model's weights are first ``locked'' offline through an obfuscation technique, such as permutation"
- Oblivious fingerprinting: Concealed integrity checks that are statistically indistinguishable from genuine inputs to detect tampering by untrusted accelerators. "Model's computational integrity is sometimes protected using a technique called oblivious fingerprinting"
- On-the-Fly operations: Per-query computation of fresh randomness and its effects during runtime, as opposed to using precomputed tables. "It would force the TEE to execute expensive On-the-Fly operations"
- Orthonormal basis: A set of mutually orthogonal unit vectors spanning a subspace, used for projection and noise cancellation. "compute an orthonormal basis"
- Parameter Morphing: A confidentiality technique that blinds linear operators by multiplying them with a secret scalar and later removing the effect. "Parameter Morphing: Multiplies the linear operator with a secret scalar blinding coin, ."
- Partial TEE-Shielded Execution (PTSE): An execution model where only security-critical parts run inside a TEE while heavy linear computations are offloaded to untrusted accelerators. "This has led to the mainstream paradigm of Partial TEE-Shielded Execution (PTSE)"
- Permutation-based locking: Securing a model by permuting weights so the model functions correctly only when paired with secret permutation keys. "A common approach to obfuscation in this domain is permutation-based locking, which secretly shuffles a model's weights"
- Permutation matrix: A binary matrix representing a permutation used to re-order activations or weights without changing values. "permutation matrices, and ."
- Precomputed static basis: A fixed set of secret noise vectors and their precomputed effects stored in the TEE for efficiency during inference. "a small, fixed set of secret noise vectors and their corresponding effects, which we call the precomputed static basis."
- Precomputation-based pattern: A design choice that precomputes mask vectors and their effects to avoid expensive on-the-fly multiplications. "a precomputation-based pattern."
- Projection matrix: A linear operator that projects vectors onto a subspace (or its complement), used here to cancel noise confined to a known subspace. "construct a projection matrix, ."
- Residual connection: A network mechanism that adds the input of a block to its output to preserve information and stabilize computation. "A residual connection is added"
- Static secret basis: Reused, fixed secret basis vectors within the TEE for generating masks or fingerprints, which can leak structure across queries. "the ``static secret basis'' pattern"
- Subspace (K-dimensional subspace): A linear subspace of dimension that constrains all generated noise or fingerprints when built from basis vectors. "low-dimensional (-dimensional) subspace"
- Trusted Execution Environments (TEEs): Hardware-protected enclaves that isolate code and data from a hostile host system. "hardware-based solutions using Trusted Execution Environments (TEEs) have emerged as a more practical alternative"
- Vector space intersection: A linear-algebraic technique for isolating or identifying a hidden subspace by intersecting spans of observed vectors. "through vector space intersection."
Practical Applications
Immediate Applications
The paper exposes a systemic vulnerability in Partial TEE-Shielded Execution (PTSE) for LLM inference—specifically, the reuse of a small, precomputed static noise/fingerprint basis (dimension K) in the mask–offload–restore pattern. Below are actionable applications that can be deployed now.
- Security audit and red-teaming of PTSE deployments (e.g., ShadowNet, SLIP, TLG, Soter, TSQP)
- What to do: Build/adopt test harnesses that (1) issue crafted queries (e.g., zero vectors and canonical basis vectors) to learn the low-dimensional subspace, (2) attempt algebraic recovery of layer-wise permutations and weight structure, and (3) try to bypass integrity checks by isolating the fingerprint subspace.
- Sectors: Software, cloud/edge AI providers, OEMs, managed security services (MSSPs), regulated industries deploying on-premise AI.
- Potential tools/workflows: Subspace extraction scripts (Gram–Schmidt/SVD), permutation-recovery utilities for transformer layers, integrity-bypass probes for Soter/TSQP-like systems.
- Assumptions/Dependencies: Ability to observe/manipulate TEE–GPU I/O; static basis reused across queries; small K; finite-field quantization paths; sufficient query volume to collect K+δ samples; weak rate limiting.
- Configuration hardening for current PTSE systems
- What to do: Increase K within memory/latency budget; rotate/rekey the basis per boot/session/token; use independent basis per layer; disallow zero-vector or obviously structured inputs; add query budgets and cooldowns; mix in unpredictability at the protocol level (e.g., randomize when fingerprints are injected).
- Sectors: AI platform vendors, enterprise IT, edge device vendors.
- Potential tools/workflows: “K sizing” calculators balancing memory/latency versus risk; basis-rotation schedulers; per-session rekey services.
- Assumptions/Dependencies: Performance headroom in the TEE; operational readiness to accept throughput/latency overhead; ability to modify TEE protocol logic; compatibility with application SLAs.
- Telemetry and anomaly detection for attack patterns
- What to do: Detect low-rank structure in masked activations/fingerprint streams; flag excessive zero or canonical-basis-like inputs; enforce per-tenant/batch rate limits; random spot-checks where TEE recomputes select linear operations on CPU to catch tampering.
- Sectors: Cloud AI gateways, appliance vendors, SOC teams.
- Potential tools/workflows: Rank/energy tests (e.g., PCA/SVD rank estimates) on observed masked vectors; Freivalds-style randomized verification; policy rules to block suspicious sequences.
- Assumptions/Dependencies: Access to sufficient statistics (without leaking secrets); negligible false-positive operational impact; modest CPU budget for randomized checks.
- Procurement and vendor due diligence
- What to do: Require disclosure of PTSE design details (use of precomputed static basis, values/ranges of K, rekey frequency, telemetry and rate-limiting policies, on-the-fly alternatives). Include security test results against subspace attacks as a purchasing condition.
- Sectors: Enterprise buyers (healthcare, finance, government), compliance/risk teams.
- Potential tools/workflows: Security questionnaires, contract clauses mandating periodic red-team assessments and incident reporting, SLAs with security KPIs.
- Assumptions/Dependencies: Vendor transparency; availability of third-party audit services.
- Deployment strategy shifts to stronger confidential hardware
- What to do: Prefer full-VM TEEs with large protected memory (Intel TDX, AMD SEV-SNP, Arm CCA) or GPU confidential computing (NVIDIA Confidential Computing) to reduce the need for static-basis precomputation and enable more on-the-fly computation inside trusted boundaries.
- Sectors: Cloud providers, OEMs, enterprise IT architects.
- Potential tools/workflows: Cost–performance–risk analyses comparing PTSE versus full-TEE/Confidential-GPU deployments; phased migrations for critical workloads.
- Assumptions/Dependencies: Hardware availability, cost constraints, attestation support, compatibility with accelerators and software stacks.
- Interim integrity protections not reliant on static bases
- What to do: Supplement or replace subspace-based fingerprints with randomized redundancy (e.g., duplicate a small fraction of linear ops on CPU), Freivalds’ algorithm variants for matrix checks, or diverse-path cross-checking.
- Sectors: Software, safety-critical systems (robotics, autonomous systems), finance.
- Potential tools/workflows: Integrity plug-ins for inference runtimes; policy-controlled sampling rates.
- Assumptions/Dependencies: Extra CPU budget and acceptable latency overhead; careful calibration to avoid attacker learning opportunities.
- IP protection and incident response readiness
- What to do: Embed robust weight/model watermarking; monitor for illicit model copies; prepare legal and technical playbooks for model exfiltration events.
- Sectors: Model providers, legal/compliance, marketplaces.
- Potential tools/workflows: Weight watermarking libraries; monitoring crawlers; takedown and legal escalation workflows.
- Assumptions/Dependencies: Watermark robustness; enforceability; monitoring coverage.
- Guidance for app developers and IT governance
- What to do: Avoid relying on “locked” proprietary models on untrusted devices via PTSE alone; prefer open models for on-device use or keep proprietary models in well-attested confidential hardware; document risk acceptance where PTSE is unavoidable.
- Sectors: Mobile/edge app developers, enterprise IT, education.
- Potential tools/workflows: Decision frameworks for deployment patterns (cloud vs. confidential hardware vs. PTSE); internal policy templates.
- Assumptions/Dependencies: Business tolerance for latency/cost; data residency/compliance requirements.
- Policy and compliance advisories
- What to do: Issue guidance that PTSE schemes using static precomputed bases constitute a known cryptographic-risk pattern (key reuse). Require disclosure and mitigation plans for deployments in regulated sectors.
- Sectors: Regulators, standards bodies, auditors.
- Potential tools/workflows: Best-practice notes; audit checklists; certification criteria draft text referencing subspace-risk assessments.
- Assumptions/Dependencies: Regulatory adoption timelines; cross-industry consensus.
Long-Term Applications
The paper motivates protocol, hardware, and standards evolution to eliminate low-rank subspace vulnerabilities while maintaining performance.
- Protocols that avoid static-basis reuse while keeping efficiency
- What to explore: Oblivious Linear Evaluation (OLE), function secret sharing (FSS), linearly homomorphic PRFs, or PRF-based “oblivious mW” computation to derive noise effects without constraining outputs to a fixed subspace; adaptive, per-query, cryptographically independent challenges for integrity.
- Sectors: Cryptography R&D, software platforms.
- Potential tools/workflows: Open libraries for OLE/FSS in ML inference; protocol proof frameworks; reference implementations for LLM layers.
- Assumptions/Dependencies: New constructions with acceptable latency; formal security proofs; integration with quantized fixed-field pipelines.
- Hardware–software co-design to compute noise effects inside trusted boundaries
- What to explore: In-enclave matvec/NPU blocks, AMX/VNNI-like accelerators enabled in TEEs; confidential GPUs with attested kernels; expanded TEE memory to permit on-the-fly randomness without precomputation.
- Sectors: Semiconductor, cloud hardware, mobile SoC vendors.
- Potential tools/workflows: ISA extensions for in-TEE linear algebra; enclave-friendly DMA and bandwidth improvements; trusted accelerator APIs.
- Assumptions/Dependencies: Silicon roadmaps; cost/power budgets; driver and attestation ecosystems.
- Stronger model obfuscation beyond simple permutations
- What to explore: Per-query ephemeral invertible transforms (dense random mixing) rather than fixed permutations; selective non-linear masking layers that remain invertible in-TEE but break linear subspace attacks.
- Sectors: ML systems research, platform vendors.
- Potential tools/workflows: Obfuscation compilers for LLM graphs; auto-tuning of transforms vs. latency.
- Assumptions/Dependencies: Mathematical soundness; avoiding new side channels; manageable overhead.
- Cryptographic integrity proofs for offloaded linear algebra
- What to explore: Interactive proofs/batching (e.g., optimized Freivalds variants), polynomial commitments, and zkML for critical subgraphs; amortized verification protocols for attention/FFN blocks.
- Sectors: Finance, healthcare, safety-critical robotics, cloud AI platforms.
- Potential tools/workflows: zk-friendly kernels; prover–verifier APIs embedded in inference servers; batching schedulers.
- Assumptions/Dependencies: Significant performance breakthroughs in provers; hardware acceleration for finite-field ops; developer tooling maturity.
- Secure metering and rekeying primitives in TEEs
- What to explore: Enclave-enforced rate limiting with monotonic counters; automatic basis expiration after limited exposures; cryptographically metered licensing for on-device models.
- Sectors: Platform vendors, licensing/ISV ecosystems.
- Potential tools/workflows: Attested usage meters; secure timers/counters; rekey orchestration services.
- Assumptions/Dependencies: TEE feature support; robust remote attestation; resilience against rollback attacks.
- Hybrid confidential ML stacks (TEE + crypto + secure accelerators)
- What to explore: Combine TEEs with lightweight homomorphic operations or MPC/OLE for specific linear steps (e.g., secure mW computation) while leveraging confidential GPUs for the rest.
- Sectors: Cloud providers, high-assurance AI services.
- Potential tools/workflows: Orchestrators that route graph segments to the optimal trust/compute domain; cost–risk optimizers.
- Assumptions/Dependencies: Interop across trust domains; acceptable end-to-end latency; cross-vendor attestation.
- Standardization and certification for confidential ML inference
- What to explore: Security profiles that explicitly forbid static-basis reuse without strong rotation; test suites that attempt subspace recovery; certification marks for cryptographically sound PTSE alternatives.
- Sectors: Standards bodies (e.g., NIST-like orgs), regulators, auditors.
- Potential tools/workflows: Conformance tests; public benchmarks for K–latency–risk trade-offs; red-team datasets and evaluation leaderboards.
- Assumptions/Dependencies: Broad industry engagement; reproducible test methodologies.
- Risk modeling and design-space optimization tools
- What to explore: Formal models connecting K, layer dimensions, TEE bandwidth/FLOPS, and attacker query budgets to breach probability/MTTD; automated advisors that recommend deployment choices (PTSE vs. full TEE vs. confidential GPU) given SLAs and threat models.
- Sectors: Platform engineering, SRE, enterprise architects.
- Potential tools/workflows: “ConfML Config Advisor” and “K Estimator” toolchains; what-if simulators for latency/cost/risk.
- Assumptions/Dependencies: Validated risk models; accurate hardware telemetry; evolving threat intelligence.
- OS and ecosystem support for trustworthy edge AI
- What to explore: Mobile/edge OS APIs that enforce use of confidential accelerators, unified attestation across CPU/GPU/NPUs, and policy controls over on-device proprietary model execution.
- Sectors: Mobile platforms, IoT, automotive.
- Potential tools/workflows: Attestation brokers; policy engines; hardware-backed key management for model artifacts.
- Assumptions/Dependencies: Vendor cooperation; secure boot and supply-chain assurances.
Notes on feasibility and assumptions across applications:
- The core vulnerability hinges on small-K, static precomputed bases constraining masks/fingerprints to low-dimensional subspaces; large, frequently rotated, or per-query-independent randomness materially raises attacker cost but impacts performance.
- The attacks assume visibility/interposition on TEE–GPU traffic and the ability to submit crafted inputs; strong rate limiting, anomaly detection, and session-level rekeying directly blunt data collection needed for subspace learning.
- Moving to larger TEEs or confidential GPUs can enable on-the-fly computation that eliminates the need for static bases but introduces cost/availability trade-offs.
Collections
Sign up for free to add this paper to one or more collections.

