Canonicalizing Multimodal Contrastive Representation Learning
Abstract: As models and data scale, independently trained networks often induce analogous notions of similarity. But, matching similarities is weaker than establishing an explicit correspondence between the representation spaces, especially for multimodal models, where consistency must hold not only within each modality, but also for the learned image-text coupling. We therefore ask: given two independently trained multimodal contrastive models (with encoders $(f, g)$ and $(\widetilde{f},\widetilde{g})$) -- trained on different distributions and with different architectures -- does a systematic geometric relationship exist between their embedding spaces? If so, what form does it take, and does it hold uniformly across modalities? In this work, we show that across model families such as CLIP, SigLIP, and FLAVA, this geometric relationship is well approximated by an orthogonal map (up to a global mean shift), i.e., there exists an orthogonal map $Q$ where $Q\top Q = I$ such that $\widetilde{f}(x)\approx Q f(x)$ for paired images $x$. Strikingly, the same $Q$ simultaneously aligns the text encoders i.e., $\widetilde{g}(y)\approx Q g(y)$ for texts $y$. Theoretically, we prove that if the multimodal kernel agrees across models on a small anchor set i.e. $\langle f(x), g(y)\rangle \approx \langle \widetilde{f}(x), \widetilde{g}(y)\rangle$, then the two models must be related by a single orthogonal map $Q$ and the same $Q$ maps images and text across models. More broadly, this finding enables backward-compatible model upgrades, avoiding costly re-embedding, and has implications for the privacy of learned representations. Our project page: https://canonical-multimodal.github.io/


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper looks at big AI models that connect pictures and words (like CLIP, SigLIP, and FLAVA). These models turn images and text into numbers called embeddings so they can compare how well a caption matches a picture. The authors ask a simple question: if two of these models are trained separately (on different data and with different designs), do they end up “thinking” in the same way? Their surprising answer: yes, and even better—you can line up their internal “maps” with a single rotation-like transformation. Even more surprising, the same transformation works for both images and text at once.
What questions were the researchers trying to answer?
They focused on three related questions:
- Do two independently trained image–text models end up with embedding spaces that are related in a simple, predictable way?
- If so, what kind of transformation connects them—do you need something complicated, or is a clean rotation/reflection enough?
- Does the same transformation work for both images and text, or do you need separate fixes for each?
How did they study it?
First, a quick analogy: imagine each model builds its own globe of knowledge. Every image and caption gets a location (a point) on that globe. Two models might both organize the world sensibly but spin their globes differently. The researchers ask: can we rotate one globe to match the other?
Here’s what they did, in plain terms:
- Contrastive learning basics:
- These models learn by pulling matching image–text pairs closer together and pushing mismatched pairs apart.
- Each image and text is mapped to a unit-length vector (a point on a high‑dimensional sphere). The dot product (cosine similarity) measures how well they match.
- The “modality gap”:
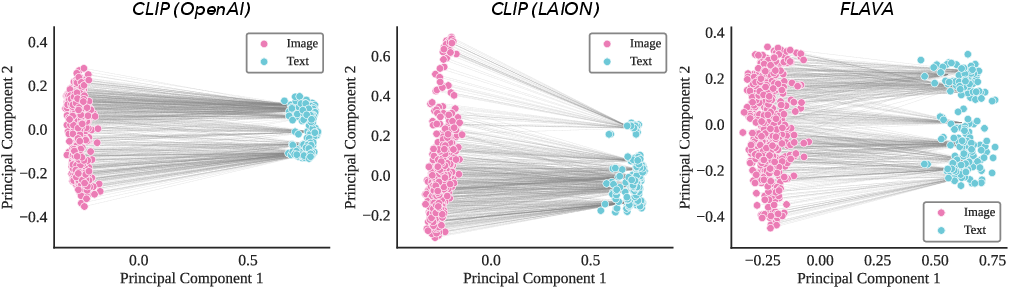
- In practice, image embeddings and text embeddings don’t sit on top of each other. They form two separate “clouds” on the sphere. This makes it non‑obvious that a single transformation learned from images would also work for texts.
- Theoretical analysis (explained simply):
- The score these models try to learn is basically “how much do this picture and this caption belong together?” In statistics terms, that relates to pointwise mutual information (PMI), but you can think of it as a measure of “fit.”
- If two models agree on that “fit” (even approximately) when you check a small set of reference pairs (anchors), then there must be a simple linear transformation that aligns one model’s space to the other.
- Because all embeddings live on a unit sphere, that linear transformation must act like a rotation/reflection (an orthogonal map). In other words, it preserves lengths and angles—so it won’t warp the geometry.
- Even if alignment isn’t perfect point by point, as long as the “signal” that separates classes is bigger than the “noise,” the model will still pick the correct class after alignment.
- Practical method:
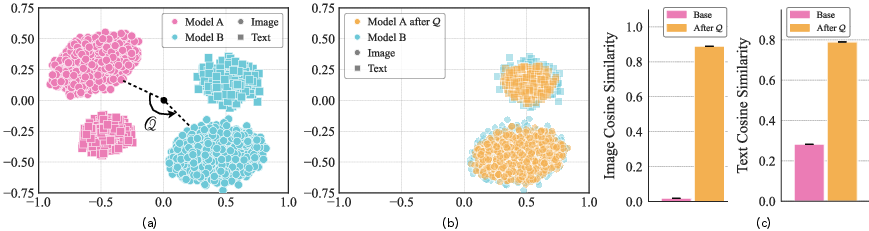
- They estimate the best rotation using the Orthogonal Procrustes algorithm. Think of it as: given matching points from Model A and Model B (e.g., embeddings of the same images), find the rotation that best overlays A onto B. This can be computed very efficiently using SVD (a standard math tool).
- Importantly, they learn this rotation only using images, and then test whether it also aligns the text spaces.
- Experiments:
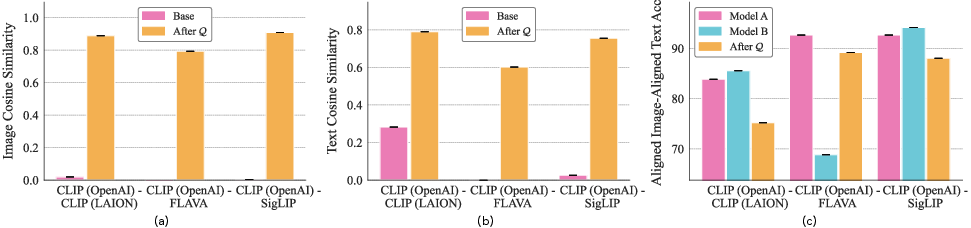
- They tested pairs like CLIP (OpenAI) vs CLIP (LAION), CLIP vs SigLIP, and CLIP vs FLAVA on datasets such as Oxford-IIIT Pets, CIFAR-100, Caltech-101, STL10, and DTD.
- They measured: paired cosine similarity (how close the same item is across models), retrieval accuracy (does an aligned embedding retrieve the right class?), and whether alignment trained on one dataset transfers to another.
What did they find, and why does it matter?
Here are the main takeaways:
- A single rotation-like map aligns models:
- Two independently trained models’ image embeddings can be lined up extremely well by a single orthogonal transformation (a rotation/reflection), often boosting cross-model similarity from near zero to very high.
- The same transformation, learned only from images, also aligns the text embeddings—without ever seeing text during training. That’s a big deal: it means the relationship is shared across modalities.
- The relative geometry is stable:
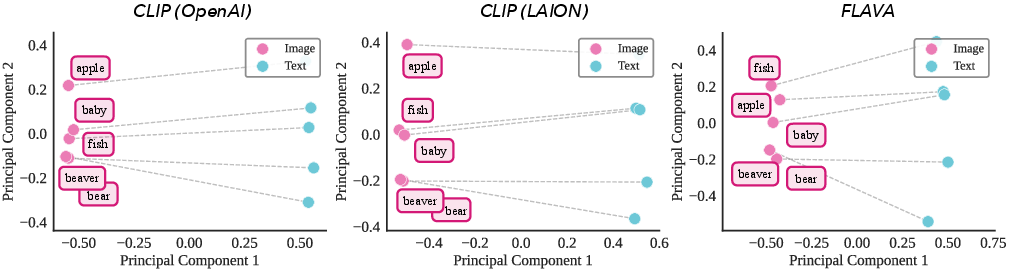
- Even though images and text live in separate “clouds” (the modality gap), the angles between images and texts—the “who matches who” structure—stay consistent across models. This stability makes shared alignment possible.
- It’s data-efficient:
- You need only a small “anchor set” (for example, image embeddings from a handful of classes) to learn the rotation. Performance levels off after surprisingly few classes.
- It generalizes:
- A map learned on one dataset (like Oxford Pets) still works well on another (like Caltech-101). You don’t need to refit for every new domain.
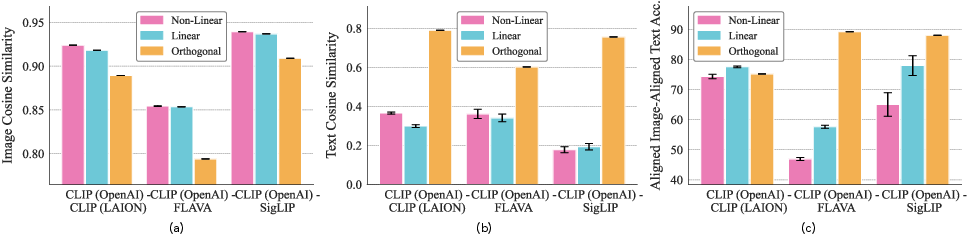
- Simple beats complex:
- More flexible mappings (like general linear maps or neural networks) can make some numbers look better on the training set, but they often hurt the important geometry and don’t transfer well to text. The rigid, angle-preserving rotation works best across tasks and modalities.
- It preserves decisions:
- After alignment, nearest-neighbor retrieval and zero‑shot classification remain strong—often matching the target model’s performance.
- It “commutes” with retrieval:
- Whether you go directly from image to image across models, or go image → text → image, you end up in very similar neighborhoods. That’s a sign the alignment respects the shared image–text structure.
What’s the impact of this research?
- Backward-compatible upgrades:
- In real systems, switching to a new embedding model usually means re-encoding billions of items—expensive and time-consuming. This work suggests you can instead learn one rotation to map old embeddings into the new model’s space, saving massive compute and time while preserving comparisons.
- Mix-and-match components:
- If one model has a stronger image encoder and another has a better text encoder, this alignment lets you combine their strengths while keeping their shared geometry intact.
- Robust comparisons across models:
- Teams using different models can meaningfully compare or merge embeddings after learning a small alignment map, enabling collaboration and evaluation across systems.
- Privacy considerations:
- If alignment is this easy, it may be possible to relate embeddings from different models more than people expect. That could have implications for how embeddings are shared or protected.
In short, the paper shows that “independent” vision–LLMs aren’t as different as they look. Under the hood, they build very similar worlds—and with a single, clean rotation you can bring those worlds into the same coordinates, for both images and text. This makes upgrading, comparing, and combining models far simpler and more reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper, aiming to guide concrete future research:
- Generality beyond the tested models: Alignment was evaluated primarily on CLIP (OpenAI, LAION), SigLIP, and FLAVA. It is unclear whether the single orthogonal map holds for larger or newer architectures (e.g., ViT-H/G, EVA-CLIP, OpenCLIP variants), multimodal transformers with cross-attention fusion, or non-contrastive/generative VLMs.
- Modalities beyond image–text: The approach was not tested on audio–text, video–text, or multi-sensor setups. Do analogous orthogonal relationships exist across independently trained multimodal models in these domains?
- Cross-lingual and multilingual towers: The paper does not assess whether a single Q aligns models with different language coverage (e.g., multilingual vs. English-only text towers) or across language pairs. How does cross-lingual variability affect kernel agreement and the shared isometry?
- Robustness under strong distribution shift: Experiments focus on small to medium-scale vision datasets (Pets, CIFAR-100, Caltech-101, STL10, DTD). It is unknown if Q generalizes under large domain shifts (medical, satellite, scientific imagery) or highly heterogeneous text distributions.
- Sensitivity to dataset curation assumptions: The PMI invariance result hinges on modality-specific curation functions acting independently (no cross-modal bias). Real-world pipelines often filter based on joint image–text consistency. How sensitive is the theory and empirical alignment to violations of this assumption?
- Failure modes and boundaries: The paper does not report cases where orthogonal alignment fails or significantly degrades. Identifying regimes (e.g., low-data training, heavy label noise, radically different corpora) where kernel agreement breaks would clarify applicability limits.
- Sample complexity and anchor set size: While empirical data efficiency is shown, there is no theoretical bound on the number of anchors needed (as a function of embedding dimension d, noise, or distribution mismatch) to reliably estimate Q with high probability.
- Anchor selection strategies: The work uses simple anchor selection (random classes/images). What selection procedures (e.g., ensuring Sym(d)-spanning, diversity/covering, active selection) minimize the number of anchors while maximizing transfer quality?
- Dimensionality mismatch treatment: For d < 𝑑̃, alignment projects text onto Im(Q), leaving unaligned residual components. The paper does not quantify how much downstream performance depends on residuals or propose methods to align or model them.
- Uniqueness and identifiability of Q: In the approximate regime, multiple near-optimal orthogonal maps may exist. Conditions ensuring uniqueness (or methods to select among equivalent Q’s) are not discussed.
- Stability under noise and outliers: The sensitivity of Procrustes estimation to mislabeled pairs, outliers, or adversarial anchors is not analyzed. Robust estimators or diagnostics for anchor quality remain to be developed.
- Dynamics and model drift: Q is estimated once; the impact of target/source model fine-tuning, continual training, or test-time adaptation on the stability of Q—and whether incremental or adaptive re-calibration is needed—remains unexplored.
- Practical deployment at billion-scale: While the approach aims to avoid re-embedding, the paper does not address integration with large-scale ANN indices (e.g., HNSW, IVF-PQ), quantization effects when applying Q post hoc, and operational costs of transforming stored embeddings at scale.
- Quantitative commutativity: The commuting diagram evidence is qualitative (nearest-neighbor examples). A quantitative measure of commutativity (e.g., agreement rates between alignment paths at scale, bounds on discrepancy) would strengthen the claim.
- Fairness and subgroup robustness: Closing the modality gap via translation harms fairness, but the fairness impact of orthogonal alignment is not evaluated. How do subgroup-wise metrics (e.g., demographic slices, attribute biases) change after alignment?
- Task breadth: Evaluation focuses on cosine similarity and class-level retrieval. Effects on richer downstream tasks (captioning, VQA, zero-shot detection/segmentation, retrieval at million-scale) remain untested.
- Theoretical tightness and approximation bounds: Approximate kernel matching guarantees are deferred to the appendix; their tightness, dependence on ε, and implications for retrieval accuracy are not characterized in the main text.
- Mean-centering and global shifts: Mean-centering improves pointwise cosine but is claimed to be negligible for decision geometry. A systematic analysis of when mean shifts arise, how to estimate them, and their impact across datasets and tasks is missing.
- Beyond orthogonal maps: Linear and MLP aligners improve image cosine but degrade cross-modal transfer; the paper does not provide a formal explanation or negative result characterizing why non-orthogonal maps distort geometry (e.g., overfitting to the image manifold).
- Compositionality and cycles at scale: While compositionality is mentioned, rigorous tests across many models (multi-hop chains, larger families) and formal guarantees for cycle consistency are not provided.
- Privacy implications: The paper notes privacy concerns but does not quantify risks (e.g., aligning proprietary embeddings with public ones using small anchor sets, potential for model inversion or membership inference). A formal threat model and mitigations are needed.
- Detection/verification of alignment validity: No procedure is proposed to certify that a learned Q preserves semantic neighborhoods beyond small tests; criteria or statistical tests for acceptance/rejection of Q would aid safe deployment.
- Handling low-rank or degenerate anchors: The theoretical results assume invertible anchor matrices and Sym(d)-spanning subsets. Practical guidance or algorithms for rank-deficient cases (e.g., low-variance datasets, repeated prompts) are absent.
- Extending beyond dual-encoders: The approach is tailored to dual-encoder contrastive objectives. Whether and how to canonicalize models with joint encoders (cross-attention) or unified representations is an open question.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that follow directly from the paper’s findings that independently trained multimodal contrastive models (e.g., CLIP, SigLIP, FLAVA) can be aligned with a single orthogonal map, learned from a small anchor set, and shared across image and text modalities.
- Backward-compatible embedding model upgrades (vector search and RAG)
- Sectors: software, search, e-commerce, media, enterprise AI, developer tools
- Tools/workflows:
- Fit Q via orthogonal Procrustes on a small, unlabeled anchor set (e.g., a few classes or ~1–2k items from your corpus)
- Preserve existing document embeddings and ANN indices; map new-model query embeddings into the old space with Qᵀ (or map old embeddings into the new space with Q) at query time
- Integrate a “Q calibrator” module into FAISS/ScaNN/Milvus pipelines; apply mean-centering as recommended
- Assumptions/dependencies:
- Access to encode the anchor set with both models (or their embeddings)
- Models are contrastive with unit-normalized embeddings; moderate domain compatibility so the multimodal kernel is approximately preserved
- For compressed indexes (e.g., product quantization), prefer query-side transforms to avoid index rebuilds; orthogonal transforms preserve cosine similarity but may interact with codebooks
- Cross-vendor interoperability of multimodal embeddings
- Sectors: platforms, SaaS AI providers, ad-tech, DAM (digital asset management), media libraries
- Tools/workflows:
- “Embedding bridge” microservice that transforms between vendor/model spaces using precomputed Q matrices and modality means
- Unified analytics/retrieval across teams using different CLIP-like backbones
- Assumptions/dependencies:
- Small shared anchor set or public benchmark anchor set to learn Q
- Vendor/API terms permit encoding shared anchors
- Mixed-model rollouts and A/B tests without re-indexing
- Sectors: product engineering, MLOps
- Tools/workflows:
- Route a portion of traffic to a new model while mapping its embeddings into the legacy space with Qᵀ; compare metrics apples-to-apples
- Gradually phase in the new model without re-embedding the entire corpus
- Assumptions/dependencies:
- Anchor set collected from production traffic or a held-out sample
- Monitoring of retrieval parity and fairness metrics across the transform
- Tower swapping to combine strengths (e.g., multilingual text with stronger vision)
- Sectors: multilingual search, media platforms, enterprise knowledge management
- Tools/workflows:
- Use Q to align the image tower of model A with the text tower of model B, preserving zero-shot decision geometry
- Compose “hybrid” systems without joint retraining
- Assumptions/dependencies:
- Dimensionality mismatches are handled with rectangular Q; classification boundaries preserved in the shared subspace
- Adequate anchor diversity for stable alignment
- Federated and cross-organization analytics with heterogeneous models
- Sectors: cross-company partnerships, media consortia, research collaborations
- Tools/workflows:
- Each party shares small anchor embeddings and derives a shared Q to a “canonical” space
- Perform joint retrieval and analysis without exchanging raw data
- Assumptions/dependencies:
- Legal permission to share anchors or their embeddings
- Sufficient anchor diversity and comparable domains
- Content moderation and policy threshold portability
- Sectors: trust & safety, platform integrity
- Tools/workflows:
- Transfer cosine-based thresholds (e.g., similarity to known-abuse prompts) across model upgrades by mapping with Q
- Validate thresholds on a small labeled anchor set to confirm invariance
- Assumptions/dependencies:
- Orthogonal maps preserve angles; monitor for drift under domain shift
- Ensure anchors represent policy-relevant edge cases
- Privacy and leakage auditing for embedding sharing
- Sectors: policy, compliance, legal, security
- Tools/workflows:
- Compute Q between two embedding sets to assess how well one model’s space aligns to another (e.g., high aligned cosine indicates potential linkage risk)
- Incorporate alignment-based risk scoring into data-sharing assessments
- Assumptions/dependencies:
- Availability of anchors or surrogate anchors (e.g., public images/prompts)
- Recognition that alignment can reveal semantic correspondence across systems
- Cross-institution retrieval in healthcare and scientific imaging
- Sectors: healthcare, medical imaging, life sciences
- Tools/workflows:
- Align radiology image–report retrieval systems across hospitals using a small, de-identified anchor set
- Enable cross-site zero-shot search without re-embedding entire archives
- Assumptions/dependencies:
- Strict privacy/compliance review; use synthetic or IRB-approved anchors
- Comparable modality pairing semantics across institutions
- Fleet-level perception alignment in robotics
- Sectors: robotics, manufacturing, logistics
- Tools/workflows:
- Align perceptual embeddings across robots with different on-device models; share policies and retrieval-based modules in a canonical space
- Assumptions/dependencies:
- Anchors representative of operational environments
- Model towers are contrastive and roughly kernel-compatible
- Personal knowledge base and app migration
- Sectors: consumer productivity, note-taking, photo management
- Tools/workflows:
- Export/import embeddings between AI apps by mapping with a learned Q
- Preserve search and organization semantics across app upgrades
- Assumptions/dependencies:
- Apps expose embeddings or allow anchor encoding
- Small calibration set from the user’s own corpus
Long-Term Applications
These applications require some combination of further validation, engineering scale-up, standardization, or policy work.
- Canonical embedding standards and registries
- Sectors: standards bodies, AI infrastructure, cloud platforms
- Tools/products:
- A public “canonical” space (e.g., anchored to a community model) with published Q matrices and means for popular models
- Standardized anchor sets (e.g., ImageNet-Lite, curated multimodal anchors) for reproducible calibration
- Assumptions/dependencies:
- Vendor adoption and licensing accommodations
- Governance over updates as models evolve
- Plug-and-play embedding ensembles and mixture-of-experts at the representation layer
- Sectors: search, recommendation, multimodal assistants
- Tools/products:
- Align multiple model spaces into a canonical basis; combine embeddings (e.g., weighted sums) to improve recall/robustness
- On-the-fly selection of the “best” tower by task/domain
- Assumptions/dependencies:
- Reliable cross-model Qs and monitoring for stability under domain shifts
- Efficient runtime transforms for latency-sensitive applications
- Training-time backward-compatibility regularization
- Sectors: foundation model providers, MLOps
- Tools/products:
- Add an “orthogonality-to-previous” constraint or Procrustes loss during fine-tunes to maintain compatibility with prior versions
- Versioned Qs that bound drift across releases
- Assumptions/dependencies:
- Access to prior model or its embeddings during training
- Careful balancing with performance gains on new data
- Edge–cloud alignment for split computing
- Sectors: mobile, IoT, AR/VR
- Tools/products:
- Deploy a lightweight on-device model; map its embeddings to a cloud canonical space with a precomputed Q for unified retrieval
- Assumptions/dependencies:
- Stable alignment across device domains and camera characteristics
- Efficient on-device matrix multiply and mean-centering
- Secure embedding sharing with keyed orthogonal transforms
- Sectors: security, privacy-preserving ML
- Tools/products:
- Apply secret orthogonal keys (and mean shifts) before sharing/storing embeddings; authorized parties apply inverse keys
- Assumptions/dependencies:
- Key management and rotation protocols
- Trade-off between interoperability and privacy protection
- Cross-institution canonicalization frameworks (e.g., healthcare, finance)
- Sectors: healthcare, finance, legal discovery
- Tools/products:
- Federated pipelines that establish a shared canonical space using approved anchors, enabling secure multi-site retrieval and analytics
- Assumptions/dependencies:
- Regulatory clearance and standardized consent/data-use agreements
- Robust auditing and alignment drift detection
- IP leakage detection and model attribution for embeddings
- Sectors: legal, compliance, model governance
- Tools/products:
- Use alignment strength and Q composition tests to infer whether proprietary embeddings are derived from (or very close to) a known model family
- Assumptions/dependencies:
- Availability of reference models/spaces and robust statistical tests
- False-positive/negative characterization under convergent training
- Interoperability in embedding marketplaces and data exchanges
- Sectors: data marketplaces, third-party content providers
- Tools/products:
- Standard exchange formats that include Qs to/from canonical spaces; buyers integrate embeddings regardless of provider model
- Assumptions/dependencies:
- Broad standard adoption and versioning discipline
- Quality controls on anchor selection and reporting
- Dynamic, alignment-aware retrieval systems
- Sectors: enterprise search, customer support, copilots
- Tools/products:
- Systems that pick model–space pairings at query time and apply the appropriate Q for optimal performance per domain/user
- Assumptions/dependencies:
- Low-latency transforms; robust routing policies
- Monitoring for degradation when domains drift
- Regulatory guidance treating embeddings as potentially identifying data
- Sectors: policy, compliance
- Tools/products:
- Guidelines recognizing that cross-model alignment can re-link embeddings to semantics; recommended controls (e.g., DP, encryption, restricted sharing of anchors)
- Assumptions/dependencies:
- Consensus among regulators and standards bodies
- Clear risk taxonomies grounded in alignment tests
Notes on Feasibility and Dependencies (common across many items)
- Anchor sufficiency and diversity: The orthogonal map is identifiable with a modest, diverse anchor set (often 10–15 classes or ~30% of a small dataset); anchors should span the representation’s symmetric subspace to avoid degenerate fits.
- Modality means and centering: Mean-centering by modality improves pointwise cosine agreement; the orthogonal map preserves class-level retrieval with or without centering.
- Dimensionality mismatch: Rectangular Q (semi-orthogonal with QᵀQ = I) works when dimensions differ; text alignments project onto the image-aligned subspace.
- Domain shift: Q learned on one dataset often transfers, but extreme shifts reduce reliability; monitor and refresh Q as needed.
- Compute/latency: Applying Q is a single matrix multiply per embedding (plus mean adjustments), typically negligible at inference time.
- Legal and policy: Encoding anchors with different vendors/models must respect terms of service and privacy; alignment increases the importance of treating embeddings as sensitive.
Glossary
- Anchor set: A small curated subset of paired examples used to constrain or estimate alignment between models. "if the multimodal kernel agrees across models on a small anchor set i.e. "
- Bayes-optimal score: The score function that minimizes expected loss under the true data distribution. "if and are Bayes-optimal scores for the contrastive models trained on two distinct distributions defined in~\Cref{eq:curation-main}, then there exists a constant such that"
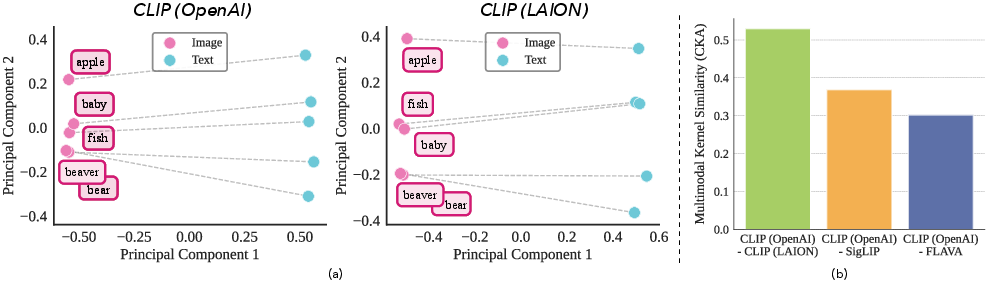
- CKA: Centered Kernel Alignment; a measure of representation similarity across models. "CKA compares induced similarity structure rather than the precise geometric correspondence between them"
- CLIP: Contrastive Language–Image Pretraining; a family of vision-language contrastive models. "Concretely, across model families such as CLIP~\citep{radford2021clip}, SigLIP~\citep{zhai2023siglip}, and FLAVA~\citep{singh2022flava},"
- Commuting correspondence: A property where mapping and comparison operations commute across modalities and models. "This induces a commuting correspondence between encoders; once is learned, any embedding produced by one model---image or text---can be mapped into the other modelâs coordinate system and back and compared meaningfully with any embedding there."
- Contrastive objective: A learning objective that increases similarity for matched pairs and decreases it for mismatched pairs. "the contrastive objective depends only on within-model dot products "
- Contrastive critic: The scoring function used by a contrastive learner to evaluate pairs. "we derive the optimal multimodal contrastive critic and show that, on a fixed target domain, agreement of cross-modal similarity kernel i.e on a small set of anchor pairs, forces a shared orthogonal map across modalities"
- Curation (dataset curation): A modality-specific selection process that reweights the underlying data distribution. "We model each training corpus as a curation of i.e. for dataset , there exist measurable weights and such that"
- Dual-encoder: An architecture with separate encoders for each modality that map to a shared embedding space. "We consider the standard dual-encoder framework where data consists of co-occurring pairs (e.g., images and text)."
- InfoNCE: A contrastive loss that estimates mutual information via noise contrastive estimation. "This alignment is achieved by optimizing the symmetric InfoNCE objective~\citep{oord2018cpc}."
- Isometry: A distance- and angle-preserving map (e.g., an orthogonal transformation) between embedding spaces. "we therefore study a strictly stronger question---whether the joint image-text geometry of two multimodal models is identifiable up to a single, rigid isometry shared across modalities"
- k-NN retrieval: Nearest-neighbor search that returns the top-k most similar items. "Qualitative k-NN retrieval under two alignment paths for Oxford Pets."
- Mean-centering: Subtracting the mean of embeddings prior to alignment to isolate rotational structure. "Even without the mean-centering, this alignment holds up to semantic boundaries i.e. class-level retrieval and decision geometry; the mean shift primarily improves pointwise cosine agreement."
- Modality gap: The separation between image and text embedding regions in contrastive models. "contrastive models exhibit a pronounced modality gap where image and text embeddings occupy largely disjoint regions of the sphere~\citep{liang2022modalitygap,shi2023towards,udandarao2022understanding}."
- Multimodal kernel: The cross-modal similarity function defined by dot products of image and text embeddings. "the multimodal kernel (relative angles between image and text embeddings) is strongly preserved (dashed lines), unlike the unimodal kernel "
- Orthogonal identifiability: The condition that forces the alignment map to be orthogonal under sufficient diversity. "(Orthogonal Identifiability, proof in~\Cref{sec:rotation_alignment).}"
- Orthogonal map: A transformation with that preserves norms and angles. "there exists an orthogonal map where such that for paired images ."
- Orthogonal Procrustes Problem: An optimization to find the best orthogonal alignment between two sets of vectors. "This is the classic Orthogonal Procrustes Problem, which has a closed-form solution via the Singular Value Decomposition (SVD) of the cross-covariance matrix ."
- Platonic distribution: The underlying “reality” distribution from which curated datasets are derived. "Platonic distribution and Dataset Curation."
- Platonic Representation Hypothesis: The hypothesis that large models converge to a shared representation reflecting world structure. "This idea is central to the Platonic Representation Hypothesis (PRH), which posits that, at a sufficiently large scale, learned embeddings converge towards a shared representation that reflects the underlying structure of the world"
- PMI (Pointwise Mutual Information): The log density ratio indicating the association strength between paired variables. "let denote the pointwise density ratio, and be the Pointwise Mutual Information (PMI)."
- Representational similarity analyses: Methods that compare learned representations via similarity structures. "this convergence is commonly studied through representational similarity analyses such as SVCCA and CKA"
- Semi-orthogonal: A rectangular matrix with orthonormal columns, satisfying . "where becomes a semi-orthogonal i.e. ."
- Singular Value Decomposition (SVD): A matrix factorization used to solve alignment problems. "via the Singular Value Decomposition (SVD) of the cross-covariance matrix ."
- Stability bounds: Theoretical guarantees quantifying robustness of alignment under approximate kernel matching. "We further move beyond the exact regime, proving stability bounds that quantify how approximate cross-modal kernel alignment translates into reliable alignment."
- SVCCA: Singular Vector Canonical Correlation Analysis; a technique for comparing neural representations. "representational similarity analyses such as SVCCA and CKA"
- Sym(d)-spanning: A diversity condition where the set spans the space of symmetric matrices. "(Sym(d)-spanning) A set of vectors is -spanning if the rank-one matrices span the space of symmetric matrices ."
- Temperature parameter: A scaling factor in the score function that controls the sharpness of similarity. "where is a temperature parameter and is a scalar bias."
- Unit hypersphere: The set of unit-norm vectors in to which embeddings are normalized. "which map inputs to the unit hypersphere in ."
- Zero-shot classification: Classification using text prompts without task-specific training or finetuning. "Zero-shot classification for (3) aligned images against target text (aligned imageâtext), (4) target images against aligned text (imageâaligned text), and (5) both images and text aligned (aligned imageâaligned text)."
Collections
Sign up for free to add this paper to one or more collections.

