Cross-Modal Redundancy and the Geometry of Vision-Language Embeddings
Abstract: Vision-LLMs (VLMs) align images and text with remarkable success, yet the geometry of their shared embedding space remains poorly understood. To probe this geometry, we begin from the Iso-Energy Assumption, which exploits cross-modal redundancy: a concept that is truly shared should exhibit the same average energy across modalities. We operationalize this assumption with an Aligned Sparse Autoencoder (SAE) that encourages energy consistency during training while preserving reconstruction. We find that this inductive bias changes the SAE solution without harming reconstruction, giving us a representation that serves as a tool for geometric analysis. Sanity checks on controlled data with known ground truth confirm that alignment improves when Iso-Energy holds and remains neutral when it does not. Applied to foundational VLMs, our framework reveals a clear structure with practical consequences: (i) sparse bimodal atoms carry the entire cross-modal alignment signal; (ii) unimodal atoms act as modality-specific biases and fully explain the modality gap; (iii) removing unimodal atoms collapses the gap without harming performance; (iv) restricting vector arithmetic to the bimodal subspace yields in-distribution edits and improved retrieval. These findings suggest that the right inductive bias can both preserve model fidelity and render the latent geometry interpretable and actionable.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks inside vision–LLMs (VLMs) like CLIP or SigLIP, which match images and text that talk about the same thing. The authors ask: what does the shared “space” where images and text meet actually look like, and how are the common ideas (like “dog,” “blue,” “running”) organized there? They introduce a simple rule, called the Iso‑Energy Assumption, to help reveal the hidden structure of these models and to make that structure useful.
What questions did the researchers ask?
They focused on a few big questions:
- How do VLMs organize concepts that are shared between pictures and words?
- Why do image and text representations often live in separate “clusters” (the “modality gap”) even though the model is trained to align them?
- Can we separate truly shared concepts from details that are specific to images or to text?
- If we can separate them, can we use that to improve editing and retrieval (finding the right image for a caption, and vice versa) without breaking the model?
How did they study it?
First, a quick translation of technical ideas into everyday language:
- A VLM turns an image or a caption into a list of numbers called an embedding. You can think of each embedding as a dot in a huge 3D-like space. Dots that mean similar things (e.g., a photo of a cat and the text “a cat”) should land close together.
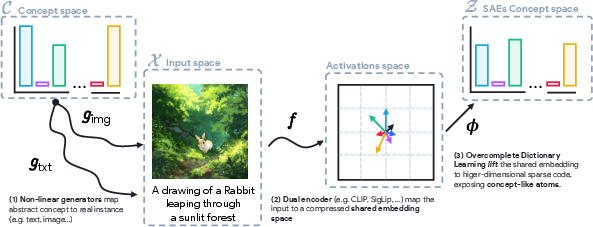
- A sparse autoencoder (SAE) tries to express each embedding as a mix of a few basic building blocks, called atoms or concepts (like “fur,” “round shape,” “blue color,” “word pattern”). “Sparse” means it uses only a small number of building blocks for each example, which helps make them interpretable.
- The authors noticed that standard SAEs often find atoms that fire for only one modality (only images or only text). This reflects the “modality gap,” where image and text dots sit in different regions of space.
Their main idea is the Iso‑Energy Assumption: if a concept is truly shared between images and text, it should show up with the same average strength in both. Think of “energy” like brightness on a dimmer switch. If “blue” is a real shared concept, its brightness should be similar whether it comes from a photo or a caption.
To use this idea, they train an Aligned SAE. It’s a normal SAE plus a tiny nudge in its training objective that encourages each shared atom to have similar average energy in images and in text. This nudge is small on purpose, so the model still reconstructs the original embeddings well. The point isn’t to force everything to be shared, but to gently favor atoms that behave like true cross‑modal concepts.
They test this in two stages:
- On toy (synthetic) data where they know the ground truth. If Iso‑Energy is true, the Aligned SAE recovers the shared concepts better than a standard SAE. If it’s not true, it doesn’t hallucinate shared concepts—it behaves about the same as a standard SAE.
- On real VLM embeddings (CLIP, OpenCLIP, SigLIP, etc.) at scale. They compare the standard SAE to the Aligned SAE using metrics that check reconstruction quality, cross‑modal alignment, and how useful the atoms are.
What did they find?
Here are the key takeaways:
- The Aligned SAE keeps the same reconstruction quality as a standard SAE but reveals a clearer structure.
- They find two kinds of atoms:
- Bimodal atoms: these fire for both images and text and carry the actual alignment signal (the meaningful shared ideas).
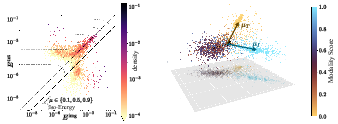
- Unimodal atoms: these fire for only images or only text and mainly act like modality‑specific biases (for example, image artifacts or text‑only patterns). A few of these have very high energy and explain most of the “modality gap.”
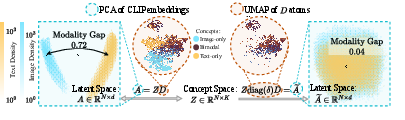
- If you remove the unimodal atoms, the modality gap largely disappears, yet the model still performs well on retrieval (finding matching images/text). This shows that the core cross‑modal understanding lives in the bimodal atoms.
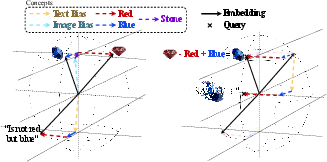
- If you do “semantic vector arithmetic” (like “make this stone blue instead of red”) using only the bimodal atoms, edits stay realistic and in‑distribution and retrieval improves. Using all atoms mixes in unimodal noise and can push the edit off the data manifold, making results worse.
Why this matters: it means we can separate what’s truly shared (semantics that connect images and text) from what is just modality‑specific noise, without harming the model’s abilities—and sometimes improving them.
Why is this important?
- It makes VLMs more understandable. We can point to the specific atoms that carry cross‑modal meaning and the ones that are just modality quirks.
- It provides practical tools. We can:
- Close the modality gap by filtering out unimodal atoms, while keeping performance.
- Do better “edits” and retrieval by operating only in the shared (bimodal) subspace.
- It shows that a simple, well‑chosen bias (Iso‑Energy) can keep models faithful to their original behavior while making their internal geometry clearer and more useful.
Implications and future directions
This work suggests a general recipe: add small, meaningful nudges to uncover the structure you care about and make it actionable. For VLMs, Iso‑Energy reveals a clean split between shared and modality‑specific concepts, enabling safer manipulation of embeddings.
The authors note some limits:
- The strength of the alignment nudge needs tuning—too small does little, too big can break the features.
- Their analysis uses the autoencoder’s reconstructions (a faithful copy, but still a copy) rather than the raw embeddings.
- They focused on dual‑encoder VLMs; it’s an open question whether the same approach works for models with different architectures (like ones with cross‑attention or generative training).
Overall, the paper shows that we can keep what works in VLMs, peel away what doesn’t help with cross‑modal understanding, and gain clearer, more controllable representations.
Knowledge Gaps
Below is a single, actionable list of the paper’s unresolved gaps, limitations, and open questions that future work could address.
- Formal identifiability: Provide theoretical conditions (and sample-complexity bounds) under which the Iso-Energy Assumption plus the Aligned SAE objective provably recovers the true bimodal dictionary, and characterize failure modes when the assumption is violated.
- Paired vs. unpaired training ambiguity: Clarify whether the alignment loss requires instance-level paired batches (the trace term implies paired rows). Develop and evaluate unpaired or weakly paired alternatives (e.g., moment matching, MMD, contrastive constraints) that avoid relying on aligned pairs.
- Sensitivity to the alignment weight β: Replace sweep-based selection with a principled scheme (e.g., bilevel optimization, Pareto frontiers of reconstruction vs. alignment, or stability-based criteria), and quantify the impact of β on degenerate/always-on features across datasets and models.
- Stability across random seeds: Quantitatively assess dictionary and atom stability under different initializations and data subsamples; report cross-seed matching scores and variability of uni-/bimodal partitions.
- Dependence on SAE architecture and hyperparameters: Test whether conclusions hold under different sparse coders (ReLU/JumpReLU/BatchTopK SAEs, k-SVD, Lasso) and across codebook sizes, target sparsity levels, and expansion ratios; map out robustness ranges.
- Sign/constraints of codes: The analysis treats concept cones (nonnegative combinations) but Matching Pursuit codes can be signed. Establish whether nonnegativity is enforced or required, and measure how sign patterns impact interpretability and the uni-/bimodal split.
- Higher-order moment invariance: Iso-Energy matches second moments; examine whether cross-modal shared concepts also exhibit invariance in higher-order moments (skew/kurtosis) or distributional shape, and whether such extensions improve concept recovery.
- Frequency and prevalence confounds: Equal energy across modalities can be confounded by uneven concept frequencies. Control for prevalence (e.g., by conditional resampling or reweighting) to verify that bimodality detection is not driven by occurrence imbalance.
- Modality-dependent SNR and scaling: Test robustness of Iso-Energy under asymmetric noise, augmentation, and encoder scaling across modalities; quantify misclassification rates of truly shared concepts when SNR differs.
- Domain and language coverage: Extend experiments beyond LAION-like English image–text pairs to multilingual, long-tail (e.g., medical), and specialized domains to assess generalization of the uni-/bimodal decomposition.
- Beyond dual encoders: Evaluate whether the geometric decomposition persists in cross-attention or generative VLMs (e.g., BLIP, PaLI, LMMs) and whether a comparable Iso-Energy bias can be defined and is effective in such architectures.
- Downstream task breadth: Measure the impact of removing unimodal atoms on tasks that rely on modality-specific details (e.g., pure image classification, image-only retrieval, text-only retrieval, OCR, layout, aesthetics), not just cross-modal retrieval.
- Necessity tests via ablation: Demonstrate causality by ablating bimodal atoms (not only unimodal) and quantifying the resulting drop in cross-modal performance; assess complementary/synergistic effects between atom groups.
- Metric dependence and statistical significance: Report full definitions, confidence intervals, and bootstrap tests for p_acc, ρ, FDA, and δ_r; show that findings are robust to metric variants and threshold choices.
- Modality-gap quantification: Validate the OOD-based gap measure against alternative metrics (mean-shift distance, density overlap, energy distance, classifier AUC) to ensure conclusions do not hinge on a single gap metric.
- Subspace orthogonality assumption: Proposition 1 relies on M ⊥ C. Empirically estimate subspace angles, study non-orthogonal regimes, and derive performance guarantees when M and C are partially overlapping.
- Vector arithmetic generality: Test bimodal-restricted edits on diverse editing tasks (attribute swaps, compositional and multi-step edits, style/content disentanglement) and multiple datasets beyond FashionIQ; quantify edit fidelity and OOD drift comprehensively.
- Cross-dataset/model consistency of “bias atoms”: Characterize whether high-energy unimodal “bias” features are stable across models and datasets, and whether a canonical set of bias directions can be learned and reused.
- Effect on fairness and leakage: Evaluate whether unimodal removal disproportionately affects sensitive attributes or language groups, and whether bimodal-only representations mitigate or exacerbate demographic or domain biases.
- Noise in paired data: Analyze robustness of Iso-Energy and SAE-A to noisy/mismatched image–text pairs (common in web-scale data); perform controlled noising studies to identify breakpoints and mitigation strategies.
- Bridging to encoder training: Explore integrating Iso-Energy constraints directly into VLM pretraining or fine-tuning (e.g., auxiliary losses on encoder features) to natively produce interpretable, bimodal-aligned subspaces.
- Computational cost and scalability: Report training/runtime costs of Matching Pursuit and alignment regularization at larger codebooks and datasets; propose approximations or incremental/online variants for production use.
- Interpretability validation: Go beyond activation galleries by collecting human annotations or automatic concept-labeling for atoms to quantify semantic coherence, monosemy, and cross-modal consistency.
- Edge cases and failure analyses: Identify classes of concepts inherently unimodal (e.g., cropping artifacts, tokenization quirks) versus genuinely cross-modal but energy-asymmetric; document failure cases where the method misclassifies or harms performance.
Glossary
- Aligned Sparse Autoencoder (SAE-A): A sparse autoencoder variant that adds an alignment penalty to encourage consistent activation energy across modalities while preserving reconstruction. "an alignment-penalized Matching Pursuit Sparse Autoencoder (Aligned SAE), which encourages energy consistency across modalities during training."
- Bimodal concept: A learned feature that activates for both image and text inputs, representing shared information across modalities. "bimodal concepts activate on both."
- Cone effect: A geometric phenomenon where embeddings for different modalities occupy distinct conical regions, underpinning separation in the shared space. "The cone effect naturally comes with a salient difference in modality wise means"
- Contrastive loss: A training objective that brings matched image–text pairs closer and pushes mismatched pairs apart in the shared embedding space. "training dynamics induced by the contrastive loss"
- Cross-modal alignment: The consistent mapping of semantically similar content from different modalities into a shared representation space. "genuinely support cross-modal alignment"
- Dictionary learning: Learning an overcomplete set of basis vectors (atoms) such that data can be represented as sparse combinations of these vectors. "Concept extraction is typically framed as a dictionary learning problem"
- Dual-encoder: An architecture with separate encoders (e.g., image and text) that project inputs into a common embedding space. "multimodal dual-encoders"
- Ellipsoid empty shells: The observation that embeddings concentrate near the surface of thin ellipsoidal shells rather than filling the space uniformly. "embeddings are contained near the surface of ellipsoid empty shells"
- Functional alignment (ρ): A metric assessing the extent to which cross-modal alignment is driven by bimodal rather than unimodal features. "ρ increases by more than an order of magnitude"
- Functional and Distributional Agreement (FDA): A population-level metric evaluating whether the functional roles of features match their distributional patterns across modalities. "Functional and Distributional Agreement (FDA)"
- Inductive bias: Prior structural assumptions built into learning algorithms that guide solution selection among many possibilities. "the right inductive bias can both preserve model fidelity"
- Iso-Energy Assumption: The principle that truly shared concepts should exhibit the same average squared activation (energy) across modalities. "we begin from the Iso-Energy Assumption"
- Johnson–Lindenstrauss embedding: A high-dimensional geometry result implying that random projections can approximately preserve distances, used to motivate sparse, near-orthogonal representations. "Johnson-Lindenstrauss-style embeddings"
- Linear Representation Hypothesis (LRH): The hypothesis that model activations can be expressed as sparse combinations of latent directions drawn from a high-dimensional concept basis. "Linear Representation Hypothesis (LRH)"
- Matching Pursuit (MP): A greedy algorithm for sparse approximation that iteratively selects dictionary atoms to best reduce residual error. "Matching Pursuit (MP) sparse autoencoder"
- Modality gap: The separation between image and text embedding distributions in the shared space, often forming distinct clusters or cones. "what is now commonly known as the modality-gap"
- Modality-specific information: Features or variations present only in one modality (e.g., image artifacts or text name patterns) that do not contribute to cross-modal semantics. "modality-specific information"
- Modality-wise means: The average embedding vectors for each modality whose difference often captures a large portion of the modality gap. "difference in modality wise means "
- Nonlinear ICA (Independent Component Analysis): Blind source separation under nonlinear mixing, which is generally unidentifiable without additional constraints. "nonlinear ICA is provably unidentifiable"
- Orthogonal complement: The subspace consisting of all vectors perpendicular to a given subspace, used to separate shared and modality-specific directions. "Γ would be the orthogonal complement."
- Out-of-distribution (OOD): Instances or queries that fall outside the distribution seen during training, often detected by distance-to-neighbor statistics. "out-of-distribution (OOD) literature"
- Overcomplete dictionary: A dictionary with more atoms than the dimensionality of the space, enabling sparse yet expressive representations. "an overcomplete set of basis vectors"
- Platonic representation hypothesis: The idea that different models converge toward shared, abstract features, providing a basis for cross-model or cross-modal alignment. "the platonic representation hypothesis"
- Probing accuracy (p_acc): A metric summarizing how well linear probes on atoms can predict modality membership, reflecting the dictionary’s modality structure. "Probing accuracy improves modestly"
- R-squared (R2): The proportion of variance explained by a model or reconstruction, used here to assess autoencoder fidelity. "R-squared value ()"
- Rosetta neurons: Neurons that appear to align across independently trained models or modalities, suggesting shared representational features. "the rosetta neurons"
- Sparse autoencoder (SAE): An autoencoder trained to produce sparse latent codes that can be interpreted as concept activations. "Sparse autoencoders (SAEs)"
- Sparse coding: Representing data as a linear combination of a small number of dictionary atoms, promoting interpretability and robustness. "via sparse coding"
- Vector arithmetic: Manipulating embeddings by adding or subtracting vectors to enact semantic edits or transformations. "restricting vector arithmetic to the \bimodal subspace"
- Wasserstein distance: A metric on probability distributions (Earth Mover’s Distance) used to compare learned atoms to ground truth. "using the Wasserstein distance"
Practical Applications
Below is a distilled set of practical applications drawn from the paper’s findings on Iso-Energy and Aligned Sparse Autoencoders (SAE) for vision–LLMs (VLMs). Items are grouped by deployability horizon and include sectors, potential tools/workflows, and feasibility notes.
Immediate Applications
The following applications can be implemented as post-hoc add-ons to existing dual-encoder VLMs (e.g., CLIP/SigLIP), using the paper’s Aligned SAE to separate bimodal vs. unimodal subspaces and to operate in the bimodal backbone.
- Cross‑modal retrieval improvements via bimodal filtering
- Sectors: software/search, e‑commerce, media/DAM, enterprise knowledge search
- Tools/Workflows: fit aligned SAE on existing embeddings; ablate unimodal atoms at query/index time; perform ranking using only the bimodal subspace; maintain unimodal components for unimodal tasks as needed
- Assumptions/Dependencies: access to embeddings; near-orthogonality between modality-specific and cross-modal subspaces (as in the paper’s proposition); minimal latency/compute overhead; SAE reconstruction quality maintained (R² ≈ baseline)
- Stable relative-caption retrieval and text-guided image search
- Sectors: e‑commerce (fashion/product search), creative tools, media libraries
- Tools/Workflows: restrict vector arithmetic (e.g., “add blue, remove red”) to the bimodal subspace to keep queries in-distribution; deploy for FashionIQ-like “relative caption” retrieval
- Assumptions/Dependencies: aligned SAE trained on domain-relevant embeddings; OOD checks integrated into evaluation; relying on dual-encoder architectures
- Modality‑gap reduction preprocessor for production embeddings
- Sectors: MLOps/infra, search platforms, recommendation systems
- Tools/Workflows: “GapCloser” transform that masks unimodal atoms to merge image/text distributions; monitor gap using OOD-style distance histograms as in the paper
- Assumptions/Dependencies: acceptance of a pre-processing step before indexing; monitoring to ensure unimodal capabilities aren’t required for target tasks
- Multimodal model auditing and interpretability dashboards
- Sectors: AI governance/compliance, ML platform teams, academia
- Tools/Workflows: “CrossModal Inspector” reporting modality score, probing accuracy, FDA, ρ; atom galleries distinguishing bimodal vs. unimodal features; seed stability checks
- Assumptions/Dependencies: availability of embeddings and compute to fit SAEs; stable thresholds/metrics; careful selection of β (alignment weight)
- Dataset and model bias detection via high‑energy unimodal atoms
- Sectors: data quality, dataset curation, risk and bias teams
- Tools/Workflows: “Unimodal Bias Scanner” to flag atoms tied to artifacts (e.g., cropping, name-patterns); guide dataset cleanup and augmentation
- Assumptions/Dependencies: human-in-the-loop review; domain expertise to interpret detected artifacts; risk of over-pruning if misapplied
- Query/prompt sanitization for cross‑modal pipelines
- Sectors: enterprise search, creative AI tooling, RAG systems involving images
- Tools/Workflows: filter text embeddings into bimodal subspace before combining with images; reduce spurious text-only directions that distort cross-modal edits
- Assumptions/Dependencies: balanced trade-off—some tasks may benefit from modality-specific nuances; validation on downstream KPIs
- More efficient indexing/storage for cross‑modal tasks
- Sectors: vector databases, search infra, edge/embedded systems
- Tools/Workflows: store bimodal projections for cross-modal retrieval; conditionally store unimodal components for modality-specific features; reduce memory/IO for cross-modal use cases
- Assumptions/Dependencies: space/latency benefits outweigh projection overhead; clear routing between cross-modal vs unimodal queries
- OOD monitoring and drift detection using modality‑gap measures
- Sectors: MLOps monitoring, production analytics
- Tools/Workflows: monitor separation between image and caption distance histograms (as in the paper); alert on gap widening; track FDA and ρ over time
- Assumptions/Dependencies: definition of acceptable ranges; stable sampling strategy; explainable alerts to operators
- Improved benchmarking of VLM alignment quality
- Sectors: academia, standards bodies, model evaluation teams
- Tools/Workflows: publish FDA, ρ, probing accuracy along with MSE/R²; include SAE-derived analyses in model cards; run sanity checks with synthetic controls
- Assumptions/Dependencies: community adoption; reproducible SAE training; availability of common evaluation datasets
- Enterprise media search and consumer photo search with better text alignment
- Sectors: consumer apps (photo galleries), enterprise DAM
- Tools/Workflows: apply bimodal-only retrieval for text-to-photo search; reduce mismatch due to modality-specific biases in captions or images
- Assumptions/Dependencies: access to gallery embeddings; on-device or server-side compute for the projection; testing on multilingual text if applicable
Long‑Term Applications
The following applications require integration into training, scaling to new architectures (e.g., cross‑attention/generative), or validation in specialized domains.
- Training‑time Iso‑Energy regularization for new VLMs
- Sectors: AI model development, foundation model labs
- Tools/Workflows: include energy-consistency penalty in contrastive objectives; induce a clean factorization into bimodal/unimodal subspaces by design; reduce reliance on post‑hoc SAEs
- Assumptions/Dependencies: careful β scheduling to avoid degenerate features; co-optimization with standard training losses; comprehensive evaluations across tasks
- Architecture designs with explicit subspace factorization
- Sectors: model architecture R&D
- Tools/Workflows: introduce heads/blocks that gate unimodal vs. bimodal channels; provide direct controls to route tasks; expose interpretability hooks natively
- Assumptions/Dependencies: compatibility with cross-attention/generative schemes; negligible performance trade-offs on unimodal tasks
- Robust multimodal grounding for robotics and embodied AI
- Sectors: robotics, AR/VR, autonomous systems
- Tools/Workflows: operate commands/percepts through the bimodal backbone for stable language grounding; reduce susceptibility to modality-specific noise/artifacts
- Assumptions/Dependencies: extension beyond dual encoders; real-time constraints; validation in physical environments and safety-critical scenarios
- Healthcare image–report alignment and retrieval with fewer artifacts
- Sectors: healthcare, medical imaging, bioinformatics
- Tools/Workflows: constrain cross-modal matching to bimodal subspace; reduce influence of scanner- or site-specific artifacts captured by unimodal biases; improve case retrieval and report linking
- Assumptions/Dependencies: stringent validation; domain-shift across sites; regulatory/compliance approvals; annotated corpora for sanity checks
- Safer and more controllable text‑driven visual editing
- Sectors: creative suites, media production, advertising
- Tools/Workflows: restrict edit vectors to bimodal atoms to avoid OOD drifts; integrate with diffusion/IMLE pipelines for semantic consistency
- Assumptions/Dependencies: bridging embedding‑space edits with pixel‑space generators; robust editing interfaces; user controls and guardrails
- Compliance and content moderation with reduced false matches
- Sectors: social platforms, finance (compliance review), legal tech
- Tools/Workflows: match image–text evidence via bimodal subspace to reduce spurious matches from modality-specific biases; explainability for auditor review
- Assumptions/Dependencies: domain-specific calibration; appeal workflows for flagged cases; logging and traceability requirements
- Privacy‑preserving or de‑biasing representations
- Sectors: privacy tech, regulated industries
- Tools/Workflows: ablate modality-specific signatures (e.g., device or pipeline artifacts) when they leak sensitive context unrelated to cross-modal semantics
- Assumptions/Dependencies: rigorous privacy evaluation to prevent utility loss; legal review; strong guarantees on what information is removed vs. retained
- Standards and policy for multimodal interpretability metrics
- Sectors: standards bodies, policy makers, procurement
- Tools/Workflows: define reporting guidelines for modality gap, FDA, ρ; certify models that demonstrate stable bimodal backbones and explainable decomposition
- Assumptions/Dependencies: consensus-building across industry/academia; alignment with existing AI transparency frameworks; cost of compliance
- Hardware and systems optimization for sparse concept pipelines
- Sectors: chip design, systems engineering, edge AI
- Tools/Workflows: accelerate Matching Pursuit/Top‑K sparse inference; on‑device bimodal projections; memory-efficient retrieval
- Assumptions/Dependencies: adoption of sparse kernels; predictable latency gains; co-design with vector databases
- Cross‑modal fairness auditing and mitigation
- Sectors: ethics/compliance, public sector
- Tools/Workflows: analyze whether alignment relies on biased unimodal atoms (e.g., name patterns); mitigate via data/process changes or by operating in the bimodal subspace
- Assumptions/Dependencies: careful fairness definitions; representative datasets; continuous monitoring to avoid regressions
Notes on feasibility across all applications:
- The Iso‑Energy principle assumes that genuinely shared concepts manifest with similar average energy across modalities; works best with dual-encoder VLMs (e.g., CLIP/SigLIP) and may require adaptation for cross-attention/generative models.
- Aligned SAE performance hinges on selection of β (alignment penalty weight) and maintaining high reconstruction fidelity; over-regularization risks degenerate features, under-regularization yields weak alignment benefits.
- The proposition ensuring ranking preservation after removing unimodal components relies on an approximate orthogonality between modality-specific and cross‑modal subspaces; empirical validation is advised per deployment context.
- Compute and data dependencies include access to embeddings, sufficient samples to fit SAEs (the paper used ~1M), and vector DB integration for production use.
Collections
Sign up for free to add this paper to one or more collections.