Memory-V2V: Augmenting Video-to-Video Diffusion Models with Memory
Abstract: Recent foundational video-to-video diffusion models have achieved impressive results in editing user provided videos by modifying appearance, motion, or camera movement. However, real-world video editing is often an iterative process, where users refine results across multiple rounds of interaction. In this multi-turn setting, current video editors struggle to maintain cross-consistency across sequential edits. In this work, we tackle, for the first time, the problem of cross-consistency in multi-turn video editing and introduce Memory-V2V, a simple, yet effective framework that augments existing video-to-video models with explicit memory. Given an external cache of previously edited videos, Memory-V2V employs accurate retrieval and dynamic tokenization strategies to condition the current editing step on prior results. To further mitigate redundancy and computational overhead, we propose a learnable token compressor within the DiT backbone that compresses redundant conditioning tokens while preserving essential visual cues, achieving an overall speedup of 30%. We validate Memory-V2V on challenging tasks including video novel view synthesis and text-conditioned long video editing. Extensive experiments show that Memory-V2V produces videos that are significantly more cross-consistent with minimal computational overhead, while maintaining or even improving task-specific performance over state-of-the-art baselines. Project page: https://dohunlee1.github.io/MemoryV2V



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making video editing tools smarter and more reliable when you edit the same video many times in a row. The authors created a system called Memory‑V2V that helps video‑to‑video AI models remember what they changed before, so future edits stay consistent with past ones. This matters when you, for example, change the camera view of a scene multiple times or edit a long video in parts—without memory, the look of objects can drift or change unexpectedly from one edit to the next.
Key Questions
The paper asks three main questions in simple terms:
- How can we help video editing AIs remember what they did before, so later edits don’t contradict earlier ones?
- What’s the best way to store and reuse past edits without slowing everything down?
- Can this “memory” make multi‑step edits look better and stay consistent, especially for changing camera viewpoints and editing long videos with text instructions?
Methods and Ideas (Explained Simply)
To answer these questions, the researchers combined a few ideas. Think of Memory‑V2V like a smart scrapbook for videos:
- Memory cache: After each edit, the system saves a compact, “compressed” version of the edited video—like a zip file. In AI terms, this is a “latent” from a video VAE (a tool that compresses video into a smaller form that keeps important details).
- Smart retrieval: When you start a new edit, the system doesn’t load everything from the scrapbook. It first finds the most relevant past edits.
- For camera changes (novel view synthesis), it compares the directions the camera looked before and the new camera path. This is like checking which areas of the scene were already seen by the camera and how much they overlap.
- For text‑guided editing on long videos, it compares the current chunk of the source video to earlier chunks using visual features (DINOv2), then retrieves the matching edited chunks.
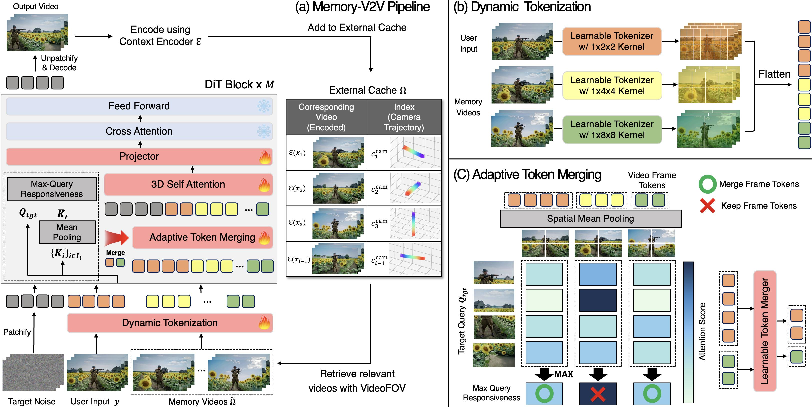
- Dynamic tokenization: Imagine breaking videos into “tokens,” like small puzzle pieces the AI uses to think. The system gives more, finer puzzle pieces to the most relevant past videos, and fewer, bigger pieces to less relevant ones. That balances detail and speed.
- Adaptive token merging: Inside the AI model, some frames matter more than others at each step. The model calculates which frames the AI is “paying attention” to. Frames that are less important get gently merged (compressed), not thrown away, so the AI stays fast without losing crucial information.
Technical terms simplified:
- Diffusion model: An AI that starts from noise and gradually “denoises” it into a realistic video. Each “edit” is an independent denoising process.
- VAE latent: A compressed version of a video that keeps the key visual content but uses fewer numbers.
- Tokens: Small chunks of data the AI processes. More tokens = more detail but slower.
- Attention responsiveness: A score that tells how much the AI is currently relying on a frame. High responsiveness = important; low = can be merged.
They also tested different ways to represent memory and found that using the same kind of compressed video representation the editor already understands (the video VAE latent) works best—better than special 3D reconstruction states or other encoders.
Main Findings
The authors tested Memory‑V2V on two challenging tasks:
- Video novel view synthesis: Re‑rendering a video from new camera paths in multiple rounds.
- Text‑guided long video editing: Editing long videos that are split into shorter segments, each edited separately.
What they found:
- Much better cross‑consistency: Edits stay visually and geometrically consistent across many rounds. For example, parts of the scene that appear only in new camera views look the same across iterations instead of changing.
- Stronger long‑video consistency: When editing long videos by segments, the model keeps objects and styles consistent across the whole video. For instance, if you add a “white door” to one segment, it stays the same “white door” in other segments, instead of turning into different versions.
- Efficiency gains: Thanks to adaptive merging, the method reduces computation and speed by about 30%, while keeping or improving quality.
- Competitive or better quality: The method either matches or improves the look and motion smoothness compared to state‑of‑the‑art baselines like ReCamMaster (for camera edits) and LucyEdit (for text edits).
Why This Matters
This research is important because real video editing is rarely a one‑and‑done task. People edit and refine videos through multiple steps. Without memory, each step can accidentally undo or alter what was done before, causing inconsistencies. Memory‑V2V:
- Makes iterative editing reliable: Edits build on each other instead of drifting or conflicting.
- Handles long videos gracefully: Even if the editor can only process short segments, the result looks cohesive from start to finish.
- Stays efficient: It adds memory without making the system painfully slow.
Overall, Memory‑V2V is a practical way to bring “long‑term visual memory” to video editing AIs, helping creators, filmmakers, and tool builders make consistent, high‑quality videos across many edits and long timelines.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains uncertain or unexplored in the paper, framed to be actionable for future research.
- Memory representation generality:
- The choice of video VAE latents as the memory representation is justified via a two-turn novel view synthesis experiment; it is unclear if this choice is optimal across other editing tasks, architectures, and datasets (e.g., non-DiT backbones, autoregressive models, or non-VAE latent spaces).
- The context encoder is frozen; joint learning of the memory representation with the editor could yield better alignment, but this is not explored.
- Retrieval design and robustness:
- VideoFOV retrieval is purely geometry-based and ignores scene content, occlusions, and motion; evaluating content-aware or learned retrieval (e.g., flow/depth-aware, semantics-driven, or metric learning approaches) is open.
- The DINO-based retrieval for text editing uses source segment similarity only; it may not align with the relevance of specific edits or prompt semantics. Multi-modal retrieval combining text, audio, spatial cues, and learned features remains unexplored.
- Sensitivity to retrieval hyperparameters (k, λ in the overlap/contain scores, number of sphere samples M) is not analyzed; adaptive or learned k and weighting strategies are missing.
- Retrieval cost and latency are not reported; scalable approximate retrieval (e.g., ANN, indexing) and its impact on quality are not studied.
- No strategy is provided for retrieval under noisy or unknown camera metadata; robustness to camera pose errors or estimates needs investigation.
- Tokenization and compression policy:
- Dynamic tokenization uses hand-picked compression factors and fixed allocation rules (e.g., top-3 videos get 1×4×4). A principled, learned token budget allocation under compute constraints or content-aware tokenization is missing.
- Adaptive token merging relies on attention-derived “responsiveness” using max over target queries; alternative importance measures (e.g., average attention, gradient-based saliency, entropy, temporal persistence) and their trade-offs are not studied.
- Block selection for token merging (Blocks 10 and 20 in a 30-block DiT) is derived from one architecture; generalization to different depths, attention configurations, or cross-attention designs is unknown.
- The exact mapping from number of memory videos to compression factor r is unspecified; how to tune r online or learn it end-to-end is open.
- Merging may still compress important information in edge cases; safeguards (e.g., uncertainty-aware compression, content-aware exceptions) are not discussed.
- Cross-iteration conflict handling and memory management:
- The system does not address conflicting edits across iterations (e.g., changing an object twice with incompatible prompts). A policy for precedence, selective forgetting, or edit-scoped memory is absent.
- Memory cache growth and management (eviction, decay, deduplication, filtering out low-quality past edits) are not considered; memory footprint and persistence policies (session-level vs project-level) are unreported.
- The risk of compounding artifacts from earlier generations is not analyzed; methods to detect and mitigate error accumulation across turns are missing.
- Task coverage and generalization:
- Evaluations focus on VNVS and text-guided long video editing; applicability to broader editing tasks (object insertion/removal, compositing, motion retiming, style transfer, color grading, camera/path re-timing) is untested.
- Generalization from synthetic multi-camera training data to real videos in diverse conditions (lighting, motion blur, occlusions, handheld capture) remains unclear.
- Dataset construction and evaluation protocol:
- Long video editing training uses target videos extended by an external model, potentially introducing artifacts or distribution shift; a dataset of genuinely long, human-authored edits is lacking.
- The VNVS training relies on synthetic 4D datasets; a real-world multi-view, dynamic-scene dataset for multi-turn VNVS evaluation is absent.
- Cross-iteration consistency metrics for editing (beyond MEt3R for VNVS and frame-wise DINO/CLIP similarities) are limited; developing task-specific, perceptual, and user-centric consistency metrics is needed.
- No user study evaluates the perceived consistency and edit faithfulness across turns; human-in-the-loop validation is missing.
- Temporal stitching and boundary handling:
- Long videos are edited segment-wise and stitched; methods for boundary-aware editing (overlaps, temporal blending, continuity constraints) and quantitative evaluation of boundary artifacts are not provided.
- The approach does not model global temporal structure or narrative coherence over very long sequences.
- Efficiency, scalability, and practicality:
- Reported latency (e.g., ~648 seconds in ablations) is far from interactive; profiling under different memory sizes, video lengths, and hardware (including consumer GPUs) and strategies for real-time or near-real-time performance are needed.
- FLOPs reductions are shown, but GPU memory footprint, cache storage costs, and throughput under heavy memory contexts are not quantified.
- Scaling behavior with many iterations (e.g., tens of turns) lacks quantitative analysis; degradation curves and upper bounds on performance vs memory size are open.
- Architectural scope:
- The method is demonstrated on ReCamMaster and LucyEdit; portability to other video editors (instruction-tuned, control-based, autoregressive) and to text-to-video or image-to-video generators needs validation.
- Interplay with explicit 3D proxies (point clouds, meshes) is not explored; investigating hybrid memory-geometry approaches to improve 3D consistency, especially in dynamic scenes, is an open avenue.
- Reliability and robustness:
- Robustness to fast motion, severe occlusions, large appearance changes, and scene cuts is not analyzed; stress-testing under challenging scenarios and reporting failure cases quantitatively is needed.
- The reliance on the model’s own VAE latents for memory may couple memory quality to generator biases; decoupled or cross-model memory representations could be explored.
- Control and user experience:
- There is no mechanism for user control over which past edits should persist or be ignored; designing UI-level memory controls (pin, prioritize, exclude, decay) is open.
- Trade-offs between strict consistency and flexibility for new edits are not formalized; adaptive weighting between memory, source video, and current instruction requires study.
- Privacy and ethics:
- External caches storing prior videos raise privacy concerns (e.g., leaking sensitive content across sessions or users); policies for encryption, access control, and ephemeral memory are not discussed.
- Biases introduced by retrieval (e.g., DINO feature biases) and their downstream effects on editing outcomes are not examined.
- Theoretical understanding:
- No theoretical analysis links attention responsiveness to optimal compression or to bounds on consistency; formalizing conditions under which memory improves consistency (and when it harms) is an open question.
- Understanding how memory conditioning interacts with rectified flow training dynamics and whether alternative training objectives could better support memory consistency is unexplored.
Glossary
- 4D datasets: Large multi-view spatiotemporal datasets representing dynamic scenes over time, often rendered from simulators. "large-scale synthetic 4D datasets rendered from simulation engines"
- Adaptive token merging: A method that compresses less-informative tokens based on attention responses to reduce computation while preserving essential context. "Adaptive token merging reduces latency and FLOPs by compressing less informative frames based on their attention-based responsiveness to the target query."
- Attention responsiveness score: A metric estimating how much a frame or token influences generation by measuring attention to it. "per-frame attention responsiveness score"
- Autoregressive generators: Models that generate sequences by conditioning each step on previously generated outputs. "reformulate full-sequence video diffusion models into auto-regressive generators"
- CLIP similarity: A feature-based similarity measure using CLIP embeddings to assess cross-frame or cross-video consistency. "cross-frame DINO/CLIP similarity metrics"
- CUT3R: A recurrent 3D reconstruction model that maintains a geometric state over time to infer scene structure from videos. "a recurrent 3D reconstructor model CUT3R"
- DiT (Diffusion Transformer): A transformer architecture used as the backbone for diffusion models, operating on tokenized latent representations. "a pretrained video DiT model"
- DINOv2 embeddings: Self-supervised visual features used for retrieval or similarity between video segments. "compute feature similarities using DINOv2 embeddings"
- Dynamic tokenization: Tokenization that adapts spatiotemporal compression per retrieved video based on relevance, allocating more tokens to important inputs. "learnable dynamic tokenizers"
- External cache: A storage of previously edited or generated videos (or their representations) used as memory for subsequent edits. "an external cache of previously edited videos"
- FIFO-Diffusion: A denoising schedule/process that follows a first-in-first-out diagonal pattern to simulate autoregressive generation. "FIFO-Diffusionâs diagonal denoising"
- Field-of-View (FOV): The set of rays or directions visible to a camera over a trajectory; used to measure overlap between views. "the field-of-view (FOV) of the target camera trajectory"
- FLOPs: Floating point operations; a measure of computational cost used to quantify efficiency improvements. "reduces FLOPs and latency by over 30%"
- Hidden states: Intermediate neural representations from prior generations used as conditioning memory for current generation. "or as hidden states"
- Latent video: A compact encoded representation of a video in the latent space (e.g., via a VAE) used for conditioning and retrieval. "we store the latent video"
- LVSM: A state-of-the-art novel view synthesis network that encodes images and ray embeddings for view rendering. "a state of the art novel view synthesis network LVSM"
- MEt3R: A metric evaluating multi-view 3D coherence/consistency across generated views. "we adopt MEt3R"
- Memory-V2V: The proposed memory-augmented framework that adds explicit visual memory to video-to-video diffusion models. "we introduce Memory-V2V"
- Novel view synthesis: Generating videos or images from unseen camera viewpoints while preserving scene geometry and dynamics. "video novel view synthesis aims to generate plausible videos captured from unseen camera trajectories"
- Plücker ray embeddings: A geometric representation of rays used to condition 3D-aware view synthesis models. "Plücker ray embeddings"
- Point-cloud renderings: Sparse geometric proxies rendered from point clouds to guide video synthesis with approximate spatial structure. "employs point-cloud renderings"
- Query–Key–Value (QKV): The triplet of matrices used in attention mechanisms to compute relevance-weighted aggregations. "Given query, key, and value matrices Q, K, V"
- ReCamMaster: A video-to-video diffusion model finetuned for multi-view novel view synthesis using large-scale synthetic data. "We consider ReCamMaster"
- Rectified flow matching: A training objective for flow-based generative modeling that learns a velocity field between noise and data. "with the rectified flow matching loss"
- RoPE (Rotary Positional Embedding): A positional encoding technique for transformers that encodes relative positions via rotations in feature space. "including RoPE design"
- Self-attention layers: Transformer layers that compute token-wise contextualization via attention across token sequences. "within the self-attention layers"
- Semantic video tokens: Compact token representations capturing high-level semantics of video content for long-context conditioning. "semantic video tokens"
- Token compressor: A learnable module that reduces the number of conditioning tokens by merging or compressing redundant information. "a learnable token compressor within the DiT backbone"
- Top-k retrieval: Selecting the k most relevant items (e.g., past videos) from a memory pool based on a relevance score. "only the top- most relevant videos are retrieved"
- TrajectoryCrafter: A method that uses camera trajectories and guidance for novel view video generation. "TrajectoryCrafter"
- VAE (video VAE): A variational autoencoder used to encode videos into latents that serve as effective conditioning for diffusion models. "the video VAE used by diffusion-based video generators"
- VBench: A benchmark suite of metrics assessing various aspects of video generation quality. "we report VBench metrics"
- VideoFOV retrieval: A retrieval algorithm ranking cached videos by geometric FOV overlap/containment with the target trajectory. "VideoFOV retrieval algorithm"
- Video-to-video diffusion models: Diffusion-based models that transform an input video into an edited/conditioned output video. "video-to-video diffusion models"
- VisionâLLM features: Cross-modal features from models trained jointly on vision and language, used as long-term context signals. "visionâLLM features"
Practical Applications
Overview
Memory-V2V augments existing video-to-video diffusion transformers with an explicit, efficient visual memory. It retrieves the most relevant prior edits (via camera Field-of-View overlap or content similarity), dynamically tokenizes them according to relevance, and compresses low-responsiveness tokens in selected transformer blocks. The result is multi-turn, cross-iteration consistency in video editing (e.g., long-form edits and novel-view synthesis) with minimal overhead and up to ~30% speedup.
Below are concrete applications and workflows that follow directly from the paper’s findings and methods. Each bullet notes sector(s), potential tools/products, and key assumptions or dependencies.
Immediate Applications
The following can be deployed now by integrating the paper’s methods into current video-to-video editing pipelines.
- [Media & Entertainment | Post-production] Consistent multi-pass video edits across shots and revisions
- What: Maintain subject appearance, props, and style across iterative edits (color changes, costume fixes, makeup continuity) over multiple rounds without drift.
- Tools/workflows: “Project Memory Vault” inside NLE/VFX tools; a Memory-V2V plug-in for Adobe Premiere/After Effects/Nuke that caches latent memories per sequence and enforces consistency across shot re-renders.
- Assumptions/dependencies: Access to a base V2V model (e.g., LucyEdit-like) and GPU inference; storage for per-project memory cache; predictable retrieval (DINOv2-based) across related shots.
- [Advertising | Brand/CGI] Brand-asset consistency over many deliverables
- What: Keep brand colors, logos, and product finishes identical across dozens of social cuts/versions created iteratively.
- Tools/products: “Brand Consistency Assistant” that seeds every render with a project memory cache; batch rendering with Retrieval + Dynamic Tokenization presets.
- Assumptions: Stable asset references in the memory cache; consistent prompts; QA with feature-similarity checks (CLIP/DINO).
- [E-commerce | Product video] Uniform appearance in 360° product spins and retakes
- What: Use novel view synthesis with memory to ensure textures/labels remain identical when generating new camera trajectories or re-shooting segments.
- Tools: VideoFOV-based retrieval for multi-view shots; “Multi-Turn NVS” mode in product-video pipelines.
- Assumptions: Camera intrinsics/poses (for VideoFOV); controlled studio conditions; base model like ReCamMaster.
- [Real Estate | Virtual tours] Consistent staging and materials across path variations
- What: Generate extra camera paths for the same property while keeping furniture/material edits identical.
- Tools: Tour generator with per-scene memory cache; FOV retrieval for path planning.
- Assumptions: Camera pose metadata or reliable SLAM for FOV estimation; sufficient compute for multi-path renders.
- [Social/Creator Tools] Long-form consistent edits across segmented videos
- What: Apply a filter/prop/transformation consistently to a vlog or tutorial split into multiple segments exceeding the base model’s window.
- Tools: Mobile/desktop editor with automatic segment stitching, DINO-based retrieval between segments, and adaptive token merging to keep latency low.
- Assumptions: On-device or cloud GPUs; consistent segmentation boundaries; adequate bandwidth for cloud workflows.
- [Education | Lecture capture] Stable whiteboard/object replacements over long recordings
- What: Replace boards/backgrounds or add AR annotations consistently across multi-hour lectures processed in segments.
- Tools: “Lecture Consistency Mode” that indexes prior segments by DINO similarity; responsiveness-driven compression to fit memory/compute budgets.
- Assumptions: Segment-level content similarity; privacy-safe storage of memory caches.
- [Sports & Live Events | Broadcast graphics] Iterative graphics edits without drift
- What: Maintain identical team overlays, sponsor graphics, and color grades across iterative tweaks to highlight reels.
- Tools: Broadcast editing extension with memory retrieval of previous versions; consistency QA panel (MEt3R-like score between versions).
- Assumptions: Stable branding guides; latency budgets compatible with adaptive token merging.
- [Software | Creative suites] API/SDK for memory-augmented V2V
- What: Provide an SDK exposing: memory cache I/O, VideoFOV/DINO retrieval, dynamic tokenization profiles, and block-wise token merging toggles.
- Tools: “Memory-V2V SDK” with presets: Quality, Balanced, Speed (tuning tokenizer compression and merge ratios).
- Assumptions: Developers have access to base DiT models and VAEs; licensing for embeddings (DINOv2).
- [Quality Assurance | Tooling] Automated consistency checks across iterations
- What: Integrate MEt3R/VBench-like metrics to flag cross-iteration inconsistencies before publishing.
- Tools: “Consistency Inspector” that compares novel regions or segment pairs and suggests additional retrieval candidates for re-renders.
- Assumptions: Compute for metric inference; per-project acceptance thresholds.
- [Operations | Cloud inference] Cost/latency reduction via adaptive token merging
- What: Reduce FLOPs and runtime for memory-conditioned edits at scale without quality loss.
- Tools: Inference scheduler that adjusts merge factors with the number of retrieved clips; mid/late-block merging policies as defaults.
- Assumptions: Profiling-based autotuning; reproducibility across GPU SKUs.
Long-Term Applications
These require further research, scaling, or new infrastructure (e.g., real-time constraints, broader datasets, or expanded base models).
- [AR/VR | Real-time effects] Live, consistent AR overlays across extended sessions
- What: Apply persistent AR stickers/wardrobe changes in live streams while users move between rooms or cameras.
- Tools: Low-latency retrieval (rolling memory), on-the-fly token merging on edge devices, and pose-free retrieval robust to motion blur.
- Dependencies: Further model optimization for real-time; memory write/read policies with strict latency; hardware acceleration.
- [Film/TV | Previsualization] Multi-turn pre-vis with identity/stylistic continuity across scenes
- What: Directors iterate on character looks and camera moves while the memory preserves continuity across sequences and reshoots.
- Tools: Studio-scale memory servers; collaborative memory vaults; shot-level VideoFOV augmented with scene graphs.
- Dependencies: Multi-user/versioned memory semantics; asset governance; large-scale retriever training.
- [Robotics & Simulation] Consistent synthetic multi-view videos for policy training
- What: Generate long-horizon, multi-camera scenes with consistent dynamics and identities for data augmentation.
- Tools: Simulation-to-video pipelines that use memory for camera sweeps; curriculum generation with retrieval of key states.
- Dependencies: Robustness to non-rigid motion; integration with 3D simulators; evaluation of policy transfer gains.
- [Autonomous Driving | ADAS] Cross-camera consistency in synthetic driving datasets
- What: Augment driving datasets with consistent new views/conditions across iterations for rare scenarios.
- Tools: Fleet-scale generator with VideoFOV over vehicle rigs; memory-based editing for weather/time-of-day changes.
- Dependencies: Accurate rig calibration (poses/FOVs); regulatory validation; provenance logging.
- [Telepresence | Virtual production] Persistent backgrounds/avatars across multi-session calls
- What: Maintain consistent digital humans or environments over weeks of calls, independent of session resets.
- Tools: Long-horizon memory indexed by identity embeddings; hierarchical retrieval (session → episode → project).
- Dependencies: Privacy-preserving memory storage; identity drift safeguards; efficient cold-start memory warming.
- [3D Content Creation | Digital twins] Memory-guided bridging from 2D video edits to 3D asset consistency
- What: Use consistent novel-view generations as constraints to stabilize 3D reconstructions or NeRF training for digital twins.
- Tools: “Memory-to-3D Bridge” that feeds multi-turn consistent views into 3D reconstruction; consistency-aware photometric losses.
- Dependencies: Tight coupling with 3D pipelines; handling dynamic/non-rigid scenes; cross-domain generalization.
- [Policy & Governance] Provenance and auditability of iterative edits
- What: Maintain an “edit memory ledger” that records which prior outputs influenced a final render, enabling audit trails and C2PA-style provenance.
- Tools: Signed memory-cache records; influence graphs; watermarking at memory-conditioned regions.
- Dependencies: Standardization across tools; user consent and data-retention policies; secure key management.
- [Foundational Research | Benchmarks & Methods] New benchmarks and memory architectures for multi-turn editing
- What: Public benchmarks for cross-iteration consistency; research into learned retrieval, memory compaction, and per-block responsiveness scheduling.
- Tools: Open datasets of multi-turn edit sequences; plug-and-play memory backends for DiTs; standardized metrics (MEt3R variants for editing).
- Dependencies: Community adoption; licensing for training data; reproducible evaluation.
- [Consumer Apps] On-device long-video editing with consistent effects
- What: Vloggers keep the same style/filters across an entire event recorded in clips, edited on phone.
- Tools: Compressed/mobile variants of Memory-V2V; hybrid on-device + cloud fallback; simplified “Consistency Lock” UI.
- Dependencies: Model distillation; energy/thermal constraints; intermittent connectivity handling.
Cross-cutting assumptions and risks
- Base models: Memory-V2V assumes access to capable video-to-video diffusion models (e.g., ReCamMaster for novel views; LucyEdit-class editors for text-guided edits) and a video VAE to store latents.
- Retrieval signals: VideoFOV requires camera poses/intrinsics; where unavailable, visual similarity (e.g., DINOv2) is used and may be imperfect on large domain shifts.
- Compute/storage: Project-level memory caches increase storage; responsiveness-based token merging mitigates but does not eliminate GPU demand for very long histories.
- Content safety & IP: Stronger consistency can aid deceptive edits. Integrations with provenance/watermarking and policy-compliant logging are important.
- Failure modes: Wrong retrieval or over-compression can cause subtle drift or artifacts; human-in-the-loop QA and metric-based gating (MEt3R/VBench/CLIP/DINO) are recommended.
Collections
Sign up for free to add this paper to one or more collections.