LiTo: Surface Light Field Tokenization
Abstract: We propose a 3D latent representation that jointly models object geometry and view-dependent appearance. Most prior works focus on either reconstructing 3D geometry or predicting view-independent diffuse appearance, and thus struggle to capture realistic view-dependent effects. Our approach leverages that RGB-depth images provide samples of a surface light field. By encoding random subsamples of this surface light field into a compact set of latent vectors, our model learns to represent both geometry and appearance within a unified 3D latent space. This representation reproduces view-dependent effects such as specular highlights and Fresnel reflections under complex lighting. We further train a latent flow matching model on this representation to learn its distribution conditioned on a single input image, enabling the generation of 3D objects with appearances consistent with the lighting and materials in the input. Experiments show that our approach achieves higher visual quality and better input fidelity than existing methods.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
LiTo: Surface Light Field Tokenization — A Simple Explanation
1) What is this paper about?
This paper is about teaching computers to understand and recreate 3D objects that look realistic from every angle. The method, called LiTo, doesn’t just learn an object’s shape (like a statue’s outline); it also learns how the object’s appearance changes when you move the camera or the light—like shiny highlights on metal or the way edges look shinier when seen from the side. In other words, it learns both shape and “view-dependent” appearance.
2) What questions did the researchers ask?
- Can we build a compact “secret code” (a latent representation) that captures both the 3D shape of an object and how it looks from different angles and under different lighting?
- Can we use this code to:
- Reconstruct a 3D object with realistic reflections and highlights?
- Generate a 3D object from just a single photo that matches the photo’s look and lighting?
3) How did they do it? (Methods in simple terms)
Think of the method like compressing a huge, detailed 3D scene into a small set of smart “tokens” (short vectors of numbers) that store both shape and appearance. Here’s the idea, with everyday analogies:
- Surface light field (what’s being learned): Imagine every point on an object’s surface keeping track of how bright and what color it looks in every viewing direction. That full “catalog” is called a surface light field. It’s like a super-detailed scrapbook of “how this surface looks from any angle.”
- How they gather training data (RGB-D images):
- RGB (color) and
- D (depth, or how far away the surface is).
- From this, they get lots of samples: where a surface point is, which direction the camera looked, and what color it appeared.
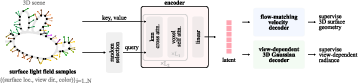
- Turning huge data into a small code (tokenization): The model reads about a million of these samples and compresses them into a small set of “tokens.” You can think of tokens like short notes that summarize large chunks of information. To make this faster, they group nearby surface points (like making “3D patches” using nearest neighbors) so the model doesn’t have to look at every point individually.
- Two decoders (two ways to use the code): 1) Geometry decoder (shape): This decoder learns to place points on the object’s surface. It uses a technique called “flow matching,” which you can picture as teaching random points how to “flow” from noise onto the exact surface. That builds an accurate 3D point cloud (and can be turned into a mesh if needed). 2) Appearance decoder (view-dependent look): This decoder turns the tokens into a “cloud of soft dots” called 3D Gaussians. Each dot can change color depending on viewing direction (using a math tool called spherical harmonics). That lets the model recreate shiny highlights, reflections, and edge shininess (Fresnel effects) from any camera angle.
- From a single image to 3D (generative model): They also train a generator that, given one input image, predicts the tokens for the full 3D object. It’s a diffusion-style transformer (a modern image generation approach) adapted for 3D. They align the world so the object’s orientation matches the input camera, which helps the output match the photo’s view exactly.
4) What did they find, and why is it important?
- Better appearance with realistic effects:
- Specular highlights (bright shiny spots that move as you move the camera)
- Fresnel reflections (edges look shinier when seen at glancing angles)
- Strong shape reconstruction: Even though it models appearance too, LiTo kept geometry (shape) quality high, reaching accuracy competitive with state-of-the-art methods focused mostly on shape.
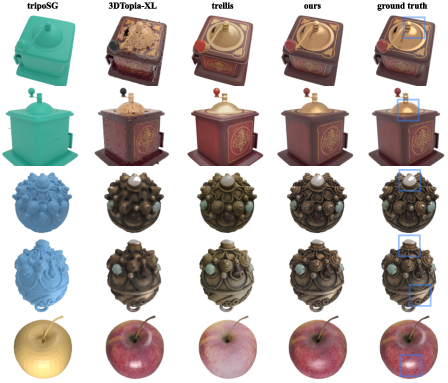
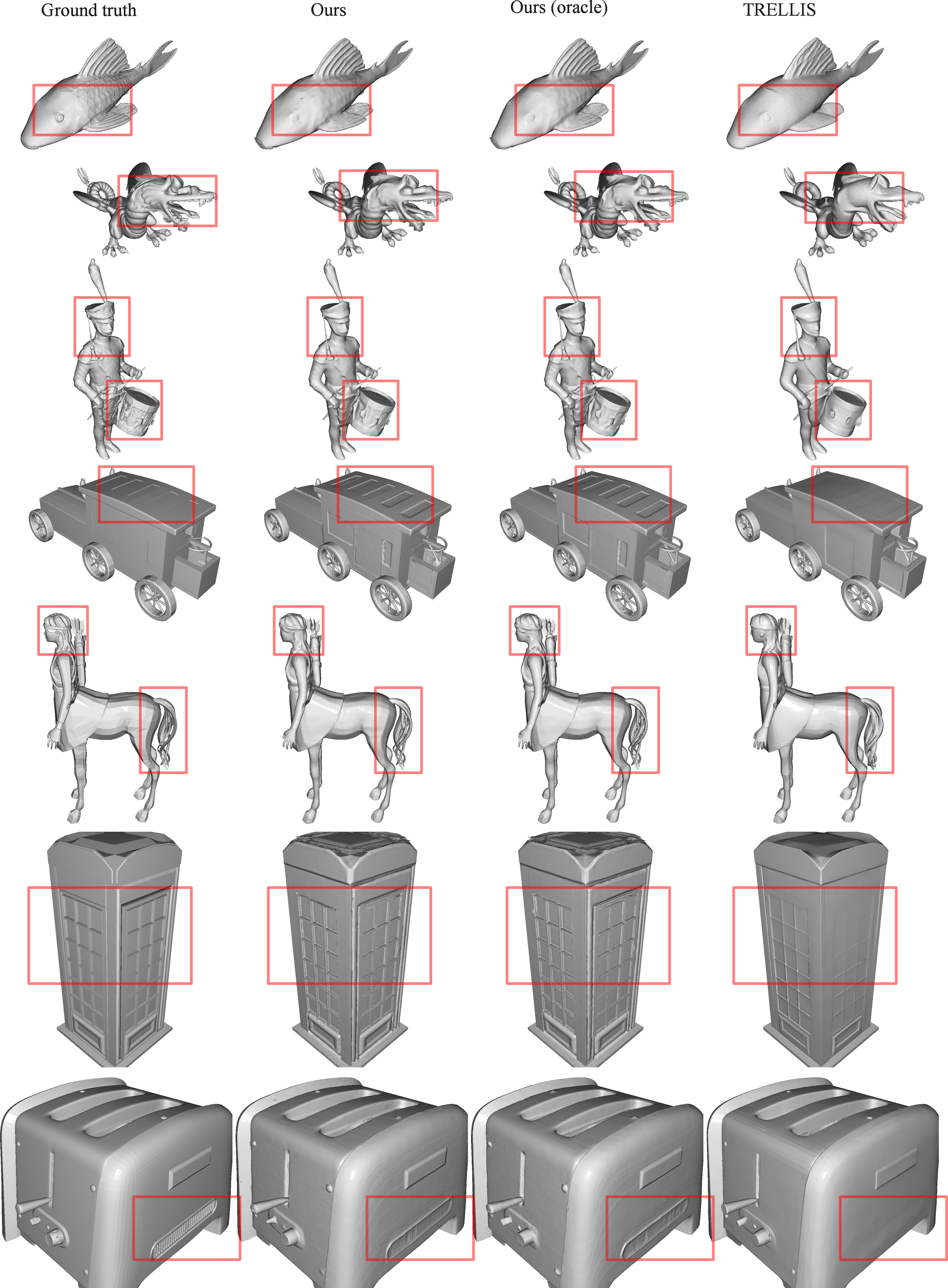
- Single-image-to-3D works well: Given one image, LiTo generated 3D objects that matched the input image’s look and orientation better than a leading baseline (TRELLIS). It achieved better scores on standard quality metrics (like FID/KID) and maintained good quality when viewed from new angles.
- Datasets and testing: They trained on a large, high-quality subset of Objaverse-XL and tested on multiple datasets (like Toys4k and GSO). Across different lights and zoom levels, LiTo consistently showed better or comparable performance.
Why it matters: Realistic view-dependent appearance is crucial for believable 3D assets in games, AR/VR, movies, and product visualization. LiTo brings these effects into a compact, learnable representation that can be generated from just one image.
5) What’s the bigger impact?
- More realistic 3D from less input: Artists, developers, and apps could turn a single image into a 3D object that not only looks right but also reacts to light and viewpoint like real materials do.
- A unified code for shape and appearance: Instead of handling geometry and materials separately (which can cause mismatches), LiTo stores both in one compact code. That simplifies pipelines and supports faster, more flexible 3D generation.
- Better foundations for future tools: The approach—compressing surface light fields into tokens, decoding with Gaussian splats for fast rendering, and guiding shape with flow matching—could inspire more efficient, realistic 3D tools and content creation systems.
In short: LiTo shows how to pack the “what it is” (shape) and “how it looks from any angle” (appearance) of objects into a small, powerful representation. This makes 3D reconstruction and generation more realistic, more consistent with input images, and more practical for real-world use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and limitations that remain unresolved in the paper, framed to guide future research.
- Data assumptions and practicality
- Reliance on dense, accurate multiview RGB‑D supervision: the method assumes per-pixel depth and clean object-centric renders (150 views at high resolution). It is unclear how performance degrades with noisy/sparse depth, imperfect calibration, or purely RGB inputs typical of real-world capture.
- Sensitivity to the number of views and input samples: no ablation on how reconstruction quality varies with fewer viewpoints, lower resolution, or reduced light-field samples (e.g., N=220 vs. fewer), which is critical for practical capture.
- Object-centric constraint: training/evaluation assumes isolated, centered objects with spherical camera distributions and box normalization. Generalization to cluttered backgrounds, partial views, or in-the-wild images is not assessed.
- Camera calibration at inference: the image-to-3D pipeline aligns the coordinate frame to the input view but does not clarify requirements for known intrinsics/extrinsics or robustness to unknown/incorrect camera parameters.
- Geometry and visibility coverage
- Unseen/occluded geometry: depth-derived surface samples may miss concavities or self-occluded regions even with spherical views; there is no analysis of coverage or strategies for hallucinating occluded geometry.
- Topology and manifoldness: while Chamfer distances are reported, there is no evaluation of watertightness, topology correctness, thin structures, or normal consistency.
- Representation and appearance modeling
- No material–lighting disentanglement: the approach encodes view-dependent radiance (baked appearance) rather than physically based material parameters and illumination. This limits relighting and PBR compatibility and conflates environment lighting with surface reflectance.
- Limited angular expressivity: the Gaussian decoder uses spherical harmonics up to degree 3, which may be insufficient for sharp specularities, glints, or anisotropic BRDFs; scalability to higher orders or alternative basis functions is unexplored.
- No translucency/subsurface/participating media: the method assumes depth at first surface intersection and does not model transmission, subsurface scattering, or volumetric effects.
- Runtime and memory footprint: the cost of decoding many Gaussians with SH coefficients (e.g., 64 per occupied voxel, degree-3 SH) and its impact on inference latency and memory is not quantified.
- Encoder design and scalability
- Approximate 3D “patchification”: using nearest-neighbor Euclidean assignment (rather than geodesic adjacency) can mix tokens across nearby but disjoint surfaces; the impact on thin/close surfaces and possible remedies (e.g., geodesic approximations or learned grouping) are not studied.
- Token budget and architecture sensitivity: there is no ablation on latent size (k=8192, d=32), the localized attention scheme, or the trade-off between efficiency and fidelity; guidance for minimal token counts is missing.
- Computational requirements: training requires large-scale compute (e.g., 64–128 GPUs for days). Strategies for distillation, pruning, or efficient training/inference regimes remain open.
- Decoding and occupancy dependencies
- Oracle occupancy during training: the Gaussian decoder is trained with ground-truth occupancy for query initialization; the performance gap when replacing this with predicted occupancy (from the flow-matched points or an occupancy decoder) is not quantified.
- Error propagation: the sensitivity of radiance reconstruction quality to errors in occupancy/geometry (and vice versa) is unreported.
- Generative modeling from a single image
- Camera conditioning and scale: the DiT uses DINOv2 features and avoids explicit ray/camera embeddings; how this affects scale ambiguity, shape fidelity, and generalization to varying FOVs is unclear (beyond a brief ablation note).
- Diversity vs. fidelity: the paper focuses on FID/KID and conditioning-view fidelity but does not analyze sample diversity, multi-modal reconstructions for ambiguous inputs, or controllability over geometry vs. appearance trade-offs.
- Multi-view conditioning: extension from single-image conditioning to multi-image inputs (with known or estimated cameras) is not explored, leaving open how to fuse sparse views effectively.
- Relighting and appearance control: although outputs “reflect the lighting” in the input image, there is no mechanism to edit lighting/materials post-generation or to condition on explicit environment maps or PBR material controls.
- Evaluation scope and fairness
- Real-image generalization: all supervision and most evaluation use rendered assets; performance on real photographs with sensor noise, background clutter, and imperfect segmentation remains unknown.
- Metrics beyond appearance/Chamfer: there is no evaluation of normal accuracy, reflectance fidelity, BRDF/BSDF plausibility, or relighting consistency—key for graphics/AR pipelines.
- Baseline coverage: comparisons to other recent radiance/GS-based large reconstruction models (e.g., GS-LRM), NeRF-latent variants, or material estimation methods are limited; cross-protocol comparisons (e.g., without occupancy or with different lighting) are sparse.
- Theoretical and methodological questions
- Sample complexity of surface light-field tokenization: there is no analysis of how many spatial/angular samples are required to reliably approximate the 5D surface light field for different material classes.
- Disentanglement claims: the paper asserts “better separation of geometry and appearance,” but offers no quantitative disentanglement metric or intervention study to validate that geometry is invariant to lighting and vice versa.
- Failure modes: the paper does not document typical failure cases (e.g., thin reflective objects, high-gloss anisotropy, semi-transparent materials) or propose diagnostics to detect them.
- Deliverables and interoperability
- Asset format limitations: decoding to 3D Gaussians with view-dependent color is not directly compatible with standard PBR pipelines; recovering meshes with physically based textures (albedo/roughness/metallic/normal) is not supported and remains an open conversion problem.
- Coordinate conventions: generation is aligned to the input view’s orientation; workflows that require canonical orientations or consistent category-level alignment are not addressed.
These gaps suggest concrete follow-ups: robustness to RGB-only and sparse inputs, geodesic-aware token grouping, higher-order/alternative angular bases, explicit material–light disentanglement with relighting, occupancy-free decoding, multi-view conditioning, real-image benchmarks, and efficiency improvements for broader adoption.
Practical Applications
Immediate Applications
Below are actionable use cases that could be deployed now, leveraging LiTo’s latent surface light field representation, its Gaussian-splat rendering with spherical harmonics (SH), and single-image-to-3D generation.
- Sector: Software/Graphics/Entertainment
- Use case: Rapid 3D asset creation from a single product or concept image for games, film, and marketing.
- Tools/products/workflows:
- “LiTo Asset Studio” plugin for Blender/Unreal/Unity to:
- Import a single image, run the LiTo-conditioned generator, and export a 3D Gaussian Splatting (3DGS) asset or baked mesh+textures.
- Preview view-dependent effects (specular/Fresnel) in-engine using SH degree-3 appearance.
- “LiTo Bake” utility to bake SH-coded view-dependent appearance to PBR textures under a target environment for DCC toolchains.
- Assumptions/dependencies:
- Best fidelity when the input photo is object-centric and well-segmented.
- 3DGS not universally supported; baking to meshes/PBR textures or NeRF-like assets may be needed for some engines.
- Generated appearance is faithful to observed lighting; true re-lighting is limited without additional inverse material estimation.
- Sector: E-commerce/Advertising
- Use case: Turn seller-uploaded product photos into realistic, rotatable 3D viewers with accurate reflections (e.g., jewelry, watches, electronics).
- Tools/products/workflows:
- Cloud API that ingests a single catalog image and returns a 3DGS asset and web-optimized viewer (WebGL/WebGPU).
- Automated background removal and pose normalization (the model already enforces input-view alignment).
- Assumptions/dependencies:
- IP/licensing clearance for products.
- For consistent brand lighting, consider “LiTo Bake” to unify look under a standardized environment map.
- Compute for occasional heavy inference (GPU/accelerator).
- Sector: AR/VR/Spatial Computing
- Use case: On-device or near-device capture of real objects with iPhone/iPad LiDAR (RGB-D multiview) for immediate AR preview with realistic reflectance.
- Tools/products/workflows:
- “LiTo Capture” iOS app: capture short RGB-D orbit, run tokenization and decoding to 3DGS, export to USDZ/RealityKit and glTF (after baking).
- Real-time preview via 3DGS; optional mesh conversion for AR platforms that lack 3DGS support.
- Assumptions/dependencies:
- Object-centric capture with limited background clutter.
- Depth quality impacts geometry; translucent objects partially supported (depth assumed at first surface).
- Battery/compute constraints may push encoding/decoding to edge/cloud.
- Sector: VFX/Virtual Production
- Use case: Fast, on-set scanning of hero props with accurate specular highlights for previs and look dev.
- Tools/products/workflows:
- Set-side LiTo capture rig (multiview RGB-D) to produce splat-based previews; later pipeline bakes to production meshes.
- Consistency to photographed lighting helps match plates quickly.
- Assumptions/dependencies:
- Controlled capture sphere preferred; auto-occupancy estimation or quick flow-matched geometry sampling available in tool.
- Baking step still required for renderer compatibility.
- Sector: Education/Training
- Use case: Interactive visualization of view-dependent optics and materials in classrooms.
- Tools/products/workflows:
- Lightweight browser-based viewer with SH degree sliders to demonstrate how harmonic orders correlate with appearance.
- Sample datasets and lesson plans showing specular/Fresnel effects under varying angles.
- Assumptions/dependencies:
- WebGPU/WebGL viewer needs 3DGS support or pre-baked assets.
- Sector: Robotics Simulation and Synthetic Data
- Use case: Populate simulators with photoreal assets that exhibit realistic specularities to improve sim-to-real transfer for vision.
- Tools/products/workflows:
- Batch convert product/household images to 3D assets for training detectors under glare and highlights.
- Domain randomization uses “LiTo Bake” to standardize environments across assets.
- Assumptions/dependencies:
- Assets are object-centric; scene-level global illumination not encoded.
- For physics tasks you will still need watertight meshes; use mesh decoder or retopology.
- Sector: Cultural Heritage/Museums
- Use case: Digitize shiny artifacts for web exhibitions with consistent view-dependent behavior from limited imagery.
- Tools/products/workflows:
- Curator workflow: capture limited multiview RGB-D or even a single hero photo for fast public previews.
- Later bake for archival PBR assets.
- Assumptions/dependencies:
- Preservation workflows require lossless archiving; keep latent tokens plus baked meshes as paired records.
- Legal permissions and handling policies.
- Sector: Manufacturing/Industrial Design
- Use case: Quick concept capture from reference photos to visualize reflective finishes and materials in early reviews.
- Tools/products/workflows:
- Internal viewer that allows stakeholders to rotate assets with realistic highlights.
- Mesh conversion for downstream CAD refinement.
- Assumptions/dependencies:
- Not a metrology tool; geometric tolerances are insufficient for engineering. Use only for concept visualization.
Long-Term Applications
The following applications are plausible but need further research, scaling, integrations, or new capabilities (e.g., re-lighting, scene-level modeling, material inference).
- Sector: General-Purpose Mobile 3D Scanning (Consumer Daily Life)
- Vision: Single-photo 3D scanning on smartphones with reliable geometry and view-dependent materials, running on-device.
- Tools/products/workflows:
- Native camera app mode: “Make 3D” from a snapshot; export to a standard format for AR sharing/messaging.
- Assumptions/dependencies:
- Further efficiency improvements; distillation to mobile NPUs/GPUs.
- Robustness to unconstrained backgrounds and lighting; better generalization to real photos vs. synthetic training.
- Sector: Re-lightable Asset Generation (Graphics/Commerce/Film)
- Vision: From a single image, infer physically-based BRDF/BSDF (roughness, metallic, normal maps) enabling accurate re-lighting in any environment.
- Tools/products/workflows:
- Hybrid LiTo+inverse rendering module that converts SH view-dependent codes into PBR parameters with uncertainty estimates.
- Assumptions/dependencies:
- Additional supervision/data for material disentanglement; physics-based priors.
- Domain shift handling from training lights to arbitrary HDRIs.
- Sector: Scene-Level Surface Light Field Tokenization (AR Cloud/Digital Twins)
- Vision: Extend LiTo from object-centric to room-/city-scale scenes capturing complex interreflections and occlusions.
- Tools/products/workflows:
- Multi-agent capture (phones/drones) to sample large-scale surface light fields; streaming tokens to a shared AR cloud.
- Assumptions/dependencies:
- Scalable encoders for millions to billions of tokens; memory/computation breakthroughs.
- Handling of indirect illumination and occlusions; new scene priors.
- Sector: Volumetric Telepresence and Holography
- Vision: Live capture and streaming of people/objects with accurate view-dependent appearance for XR conferencing.
- Tools/products/workflows:
- Real-time tokenization + 3DGS rendering over networks; predictive compression for low latency.
- Assumptions/dependencies:
- Real-time encoders and decoders; hardware acceleration.
- Robust tracking/segmentation and privacy-preserving pipelines.
- Sector: Robotics Perception Under Specularities
- Vision: Use LiTo-style tokens as features for perception/pose estimation of reflective objects in-the-wild.
- Tools/products/workflows:
- Train perception models that condition on light-field-aware latents to reduce failure modes on shiny objects.
- Assumptions/dependencies:
- New datasets with ground-truth poses and specular objects; real-time inference constraints on robots.
- Sector: 3D Search and Retrieval
- Vision: Search engines that return 3D assets from a single query photo, matching both shape and material appearance.
- Tools/products/workflows:
- Index latents; query-by-image to retrieve or generate assets; integration with marketplaces.
- Assumptions/dependencies:
- Standardization for latent exchange; copyright filters and provenance tracking.
- Sector: Policy/Standards
- Vision: Interchange standards for view-dependent appearance (e.g., 3DGS+SH or latent surface light field containers) and disclosure norms for generated 3D assets.
- Tools/products/workflows:
- Extension proposals to USD/glTF for SH-coded splats and provenance metadata.
- Guidelines for e-commerce labeling when 3D is generated from a single photo.
- Assumptions/dependencies:
- Consensus in industry standards bodies; compatibility with existing renderers.
- Sector: CAD/PLM and Additive Manufacturing
- Vision: Assistive conversion from photo-based LiTo assets to engineering-grade meshes and parametric surfaces for downstream manufacturing or printing.
- Tools/products/workflows:
- ML-assisted retopology, parametric fitting, and watertightness repair integrated into PLM.
- Assumptions/dependencies:
- Significant improvements in geometric accuracy and topology regularization.
- Sector: Research and Academia
- Vision: Foundational benchmarks and methods for learning and evaluating surface light fields, attention over 3D tokens, and latent flow matching in geometry+appearance.
- Tools/products/workflows:
- Open datasets with real captures (RGB-D multiview under varied lights), reproducible baselines, and metrics for view-dependent fidelity and re-lighting generalization.
- Assumptions/dependencies:
- Broader community adoption and shared capture protocols.
Notes on feasibility across applications:
- LiTo excels at reproducing view-dependent appearance tied to observed lighting; general re-lighting and full material disentanglement require additional modeling.
- Object-centric assumption simplifies capture and training; scene-level deployment demands new sampling, scaling, and occlusion handling.
- Immediate deployments often need conversions (3DGS→mesh/PBR) to fit existing pipelines; long-term value grows if engines adopt native splat rendering or standardize view-dependent formats.
- Compute and data are practical constraints today; efficiency, mobile inference, and real-world generalization are active areas for follow-up work.
Glossary
- 3D Gaussians: Parametric primitives used to represent and render 3D scenes by splatting anisotropic Gaussians. "we convert the latent into a set of 3D Gaussians,"
- area lighting: Illumination from extended light sources with area, producing soft shadows and smooth highlights. "1) fixed smooth area lighting (matching TRELLIS)"
- back-projecting: Recovering 3D points from image pixels and depths by inverting camera projection. "The surface location can be obtained by back-projecting the depth map,"
- box-normalize: Scaling and translating a scene so its bounding box fits a canonical range. "we box-normalize the scene to ,"
- canonical coordinate system: A fixed, dataset-specific orientation/pose frame used to standardize assets. "generates objects in a canonical coordinate system (i.e, their dataset orientation),"
- Chamfer distance: A set-to-set distance used to compare point clouds or surfaces by averaging nearest-neighbor distances. "We then compute Chamfer distance in #1{supp sec: recon metric} between these ground truth point clouds and reconstructed ones."
- classifier-free guidance (CFG) scale: A hyperparameter controlling the strength of guidance in conditional generative models. "CFG scale for both models are 3.0."
- cross attention: An attention mechanism where query tokens attend to a set of input tokens to aggregate information. "The encoder contains cross and self attention blocks,"
- DINOv2: A self-supervised vision model used to extract strong image embeddings/features. "The input image is encoded by DINOv2-large image embeddings"
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion/flow generative models. "We rely on a standard Diffusion Transformer (DiT) architecture"
- Dirac delta function: An idealized impulse distribution used to represent infinitely concentrated mass or density. "approximates a dirac delta function lying on 3D surfaces in the scene,"
- environment map: A panoramic image used to illuminate a scene with complex, omnidirectional lighting. "an all-white environment map,"
- FID: Fréchet Inception Distance; a metric comparing distributions of generated and real images. "our approach produces significantly improved FID~{Heusel2017GANsTB} and KID~{Binkowski2018DemystifyingMG} scores"
- field of view (FOV): The angular extent of the observable scene captured by a camera. "with $40$ degree field of view,"
- flow matching: A generative modeling approach that learns vector fields transporting noise to data. "The flow matching formulation also optionally allows us to sample "
- flow-matching time: The continuous time variable that indexes interpolation between noise and data in flow matching. "where is the flow-matching time,"
- flow-matching velocity decoder: A network that predicts the instantaneous velocity of points under the learned flow. "We utilize the same flow-matching velocity decoder used by \citet{chang20243d}."
- Fresnel reflections: Angle-dependent reflectance effects where surfaces reflect more light at grazing angles. "This representation reproduces view-dependent effects such as specular highlights and Fresnel reflections under complex lighting."
- Gaussian splats: Screen-space splatting of 3D Gaussians to render scenes, often with view-dependent color. "via a decoder that outputs Gaussian splats with higher-order spherical harmonics"
- geodesic distance: The shortest path distance along a surface manifold, as opposed to Euclidean distance. "we use distance of instead of geodesic distance."
- grazing angles: Viewing angles close to tangential incidence where reflection increases. "Fresnel reflections when viewed at grazing angles."
- KID: Kernel Inception Distance; an unbiased alternative to FID measuring distributional similarity. "KID is reported by ."
- latent flow matching model: A generative model that learns the distribution of latent codes using flow matching. "We further train a latent flow matching model"
- latent representation: A compact vectorized encoding of complex data (here, 3D geometry and appearance). "We propose a 3D latent representation"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual image similarity metric. "and measure PSNR, SSIM~{wang2004ssim}, and LPIPS~{Zhang2018TheUE}."
- mean-pooled: Aggregating features by averaging across a set, removing variation (e.g., across views). "multiview features are mean-pooled, discarding angular variation"
- multiview features: Visual features aggregated from multiple viewpoints to provide 3D-aware cues. "a sparse voxel grid fused with dense multiview visual features"
- object-centric scenes: Scenes centered around a single object, typically with cameras arranged around it. "Since we focus on object-centric scenes,"
- occupancy grid: A voxel grid indicating whether cells are occupied by the object’s geometry. "a low-resolution sparse occupancy grid"
- patchification: Grouping local inputs into coarse tokens (patches) for efficient transformer processing. "non-overlapping patchification in Vision Transformers"
- Perceiver IO: A general-purpose architecture using latent arrays with cross/self attention for arbitrary inputs/outputs. "We use Perceiver IO~{jaegle2021perceiver} as our encoder,"
- physically based rendering (PBR) materials: Material models with physically grounded parameters for realistic rendering. "we select a subset of 200 objects with PBR materials"
- pinhole camera model: A simple camera model mapping 3D points to the image plane through a single point. "view direction is derived from the pinhole camera model,"
- Plucker ray embeddings: Encodings of 3D rays using Plücker coordinates for geometry-aware conditioning. "e.g, Plucker ray embeddings,"
- PSNR: Peak Signal-to-Noise Ratio; a distortion metric measuring image reconstruction fidelity. "and measure PSNR, SSIM~{wang2004ssim}, and LPIPS~{Zhang2018TheUE}."
- radiance field: A function describing emitted light from every point and direction in space. "optimization-based radiance-field fitting"
- signed distance function (SDF): A scalar field giving the signed distance to the closest surface, negative inside. "signed distance functions (SDF)."
- spherical harmonics: A basis of functions on the sphere used to model angular variation in lighting/color. "spherical harmonics degree 3"
- sparse 3D convolution: Convolution operations defined only on non-empty voxels for efficiency. "windowed attention and sparse 3D convolution,"
- specular highlights: Bright reflections of light sources due to mirror-like reflection on glossy surfaces. "such as specular highlights and Fresnel reflections"
- SSIM: Structural Similarity Index; a perceptual metric assessing structural similarity between images. "and measure PSNR, SSIM~{wang2004ssim}, and LPIPS~{Zhang2018TheUE}."
- Structured LATent (SLAT) representation: A voxel-feature 3D latent used by TRELLIS, combining geometry and multiview cues. "Structured LATent (SLAT) representation: a sparse voxel grid fused with dense multiview visual features"
- view-dependent appearance: Appearance that changes with viewing direction due to material and lighting effects. "view-dependent appearance such as specular reflection."
- view-dependent radiance: Directional outgoing light from a surface point varying with view direction. "The supervision of the view-dependent radiance is through rendering multi-view images."
- view-independent diffuse color: Appearance component constant across viewing directions, lacking specular effects. "view-independent diffuse color."
- voxel grid: A 3D grid of volumetric cells used to discretize space for geometry/feature storage. "sparse voxel grid"
- watertight meshes: Meshes without holes so that inside/outside is well-defined for field-based methods. "Many methods require watertight meshes"
- windowed attention: Attention restricted to local windows to reduce computational cost in transformers. "employs transformers with windowed attention and sparse 3D convolution,"
- zero-shot: Performing a task without task-specific training data for that specific case. "and zero-shot estimate surface normals."
Collections
Sign up for free to add this paper to one or more collections.