Positional Encoding Field
Abstract: Diffusion Transformers (DiTs) have emerged as the dominant architecture for visual generation, powering state-of-the-art image and video models. By representing images as patch tokens with positional encodings (PEs), DiTs combine Transformer scalability with spatial and temporal inductive biases. In this work, we revisit how DiTs organize visual content and discover that patch tokens exhibit a surprising degree of independence: even when PEs are perturbed, DiTs still produce globally coherent outputs, indicating that spatial coherence is primarily governed by PEs. Motivated by this finding, we introduce the Positional Encoding Field (PE-Field), which extends positional encodings from the 2D plane to a structured 3D field. PE-Field incorporates depth-aware encodings for volumetric reasoning and hierarchical encodings for fine-grained sub-patch control, enabling DiTs to model geometry directly in 3D space. Our PE-Field-augmented DiT achieves state-of-the-art performance on single-image novel view synthesis and generalizes to controllable spatial image editing.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Positional Encoding Field — Explained Simply
Overview
This paper explores a new way for image-making AI models to understand where things are in a picture. The authors focus on a popular type of model called a Diffusion Transformer (DiT), and they show that how you tell the model the position of each piece of the image matters a lot. They propose a new system, called the Positional Encoding Field (PE-Field), that lets the model think in 3D (including depth), not just in 2D. This helps the model create images of the same scene from different viewpoints using just one input photo.
What questions does the paper ask?
The paper looks at a few simple but big questions:
- If you move around the “position labels” of image patches, will the model still make a sensible picture?
- Can we control how an image changes (like rotating the viewpoint) by adjusting those position labels instead of changing the image content itself?
- How can we add depth (how far things are from the camera) and more fine detail so the model handles 3D geometry better?
How does the method work?
Here are the key ideas, explained in everyday terms:
- Diffusion Transformers (DiTs): Think of an image as a grid of small tiles or “patches.” Each patch becomes a “token” (like a tiny data packet). The model learns to turn random noise into a detailed picture by looking at these tokens and their positions over many steps.
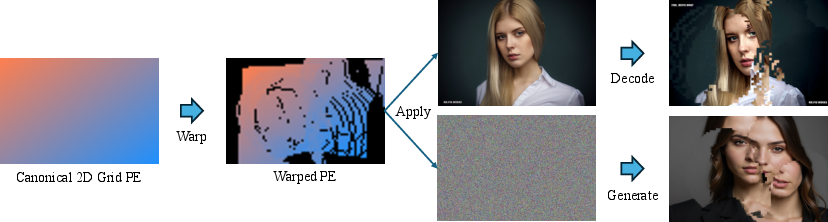
- Positional Encodings (PEs): Each token gets a position label, like an address on a map. The authors found something surprising: if you shuffle or change these position labels, the model still makes a coherent image—but it rearranges the content according to the new positions. That means the positions are what keep the picture organized.
- Positional Encoding Field (PE-Field): The authors extend position labels from a flat 2D map to a 3D field that also includes depth. That’s like upgrading from a street map to a city model with height. This 3D labeling helps the model understand which parts of the picture are closer or farther away.
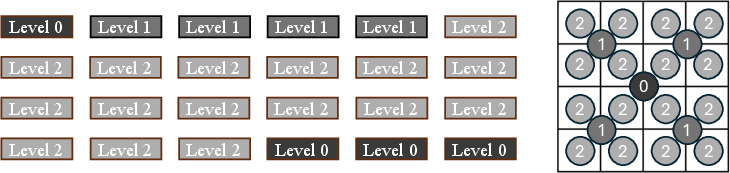
- Hierarchical (multi-level) encodings: Inside the Transformer, there are multiple “heads,” which you can think of as teams looking at the image in different ways. The authors assign some teams coarse position labels (whole patch level) and others fine labels (sub-patch level), like zooming in to smaller tiles inside each patch. This gives the model more precise control over details within each patch.
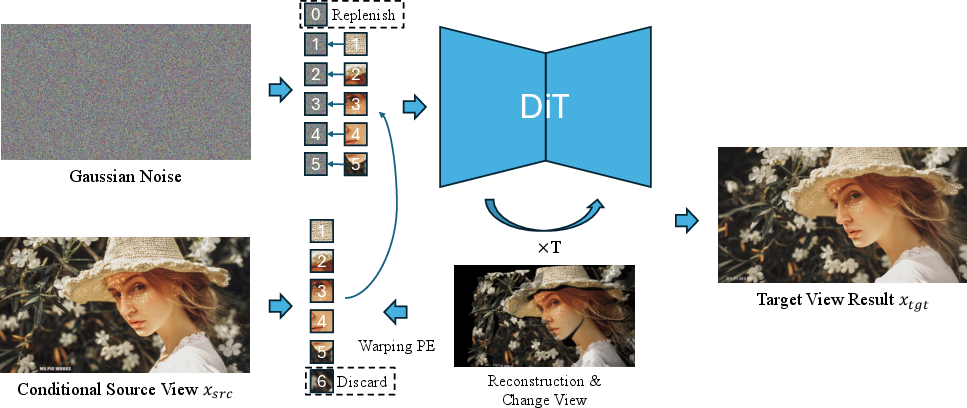
- Novel View Synthesis (NVS) from a single image: To create a new viewpoint, the model:
- Reconstructs an estimate of the scene’s 3D shape from the single input image (to get depth and camera pose).
- Projects the original image tokens to where they should be in the new camera view using the 3D positions.
- Fills any empty spots (areas the original image never showed) with noise tokens and lets the model “imagine” plausible content there.
- Because positions carry depth and fine detail, the model composes a consistent new-view image without clumsy 2D warping.
- Training: They use “rectified flow,” a training style that teaches the model to move from noise toward the correct target image more directly. They train on multi-view datasets where the same scene is captured from different angles, so the model learns consistent geometry.
What did they find, and why does it matter?
The authors report strong results:
- State-of-the-art performance: On standard benchmarks (Tanks-and-Temples, RE10K, DL3DV), their PE-Field–augmented DiT beat prior methods in image quality and geometric accuracy, measured by common metrics like PSNR, SSIM, and LPIPS.
- Precision and consistency: Their approach handles viewpoint changes accurately while keeping the look and identity of the original image stable, which is often hard for prompt-based editing tools.
- Speed advantage: Unlike video-based methods that generate many intermediate frames, their model goes straight to the target view, making it much faster for single-view synthesis.
- Ablation studies: Removing either the depth-aware part or the fine, multi-level encodings makes the results worse, proving both pieces are important.
- Extra applications: With the same 3D-aware thinking, the model can do spatial edits like rotating a single object, removing objects, or composing elements at new positions—all by tweaking position labels.
Why is this important?
This work shows that positional information—how you label where things are—is a powerful way to control image generation. By turning positions into a 3D, depth-aware, and detail-rich “field,” the model becomes better at geometry, making it useful for:
- Virtual cameras and AR/VR, where you want realistic new views from a single photo.
- Photo editing that respects 3D structure, like turning objects or adjusting scenes without breaking their shape.
- Future AI models that are more grounded in space and can be controlled simply by changing position labels rather than rewriting content.
In short, the paper suggests a new, simpler kind of control: change the positions, and the image follows—now with true 3D understanding.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains uncertain or unexplored in the paper and where future work could concretely intervene:
- Theoretical understanding of “patch token independence”
- No formal analysis explains why or when DiTs maintain global coherence primarily through PEs; derive conditions or toy models that predict when PE manipulations preserve semantics.
- Lacks cross-architecture validation (e.g., SD3, DiT-XL/2, hybrid UNet–Transformer) to establish whether the independence property generalizes beyond Flux.1 Kontext.
- Robustness to reconstruction errors
- The method depends on monocular depth and pose from VGGT; quantify sensitivity to systematic and random errors by injecting controlled perturbations in depth/intrinsics/extrinsics and measuring NVS degradation.
- No uncertainty-aware fusion; explore depth-confidence weighting, visibility masks, or learned uncertainty to mitigate erroneous 3D cues.
- Occlusion and visibility modeling
- 3D RoPE introduces a z channel but no explicit visibility handling; evaluate and add z-buffer–based attention masks, ray-consistency constraints, or layered tokens along a ray to disambiguate overlapping projections.
- Unclear how conflicts are resolved when multiple source tokens map to the same target cell; specify tie-breaking, blending, or multi-layer token strategies.
- Limits under large viewpoint changes
- Multi-step strategy is demonstrated qualitatively but not analyzed; provide quantitative studies on step count vs. fidelity/consistency, failure modes, and adaptive scheduling policies.
- Characterize the maximum reliable baseline/rotation where geometry remains consistent and when detail collapses.
- Sub-patch hierarchical PE design
- Head allocation rule (1:4:16… quotas, fixed level mapping) is heuristic; ablate the number of levels M, per-level head counts, and learnable vs. fixed allocations.
- Unclear dimension budget per axis (x/y/z) and per level; study trade-offs between capacity for content vs. positional subspaces and their impact on fidelity.
- Investigate training stability when reassigning many heads to fine levels and whether gradual unfreezing or curriculum improves performance.
- Depth-aware RoPE formulation
- The z-encoding is axis-factorized and camera-centric; test alternatives (e.g., spherical or ray-angle encodings, scene-centric coordinates) and camera model robustness (fisheye, rolling shutter).
- Examine whether coupling between axes (non-factorized 3D encodings) or learned 3D positional fields yields stronger volumetric reasoning.
- Dataset coverage and evaluation breadth
- Training uses DL3DV and MannequinChallenge; assess domain shift to in-the-wild scenes and categories underrepresented in these datasets.
- Evaluation focuses on PSNR/SSIM/LPIPS; add pose-accuracy metrics (e.g., reprojected keypoint errors), geometry metrics (depth/normal errors), and multi-view consistency measures across trajectories.
- Fairness of baselines: include recent single-image NVS models (e.g., LVSM) and strong geometry-aware diffusion models for a balanced comparison.
- Efficiency and scalability
- No reporting of compute/memory overhead from multi-level 3D RoPE at training and inference; profile throughput vs. baseline DiT and quantify speed advantage over video methods.
- Scaling to high resolutions (e.g., 1–4K) with fixed head counts is unclear; propose token pyramid strategies or sparse attention tailored to hierarchical PEs.
- Handling fine structures and texture ambiguities
- Sub-patch control is limited by tokenization granularity; study smaller patch sizes, adaptive tokenization, or token super-resolution to reduce aliasing in thin/reflective/textureless regions.
- Analyze failure cases on repeated textures and specular/transparent objects where monocular depth is unreliable.
- Integration with text and other conditions
- The model drops text conditioning; investigate joint text-and-PE-Field control, conflicts between prompt semantics and geometric constraints, and mechanisms to resolve them.
- Explore multi-image conditioning and how to fuse multiple source views’ tokens and PEs without ghosting.
- Attention mechanics under 3D PE-Field
- Assess whether 3D PEs bias attention toward geometrically plausible correspondences; visualize attention maps vs. ground-truth epipolar geometry and introduce losses to enforce epipolar consistency.
- Consider visibility-aware or depth-gated attention to suppress spurious long-range interactions across occlusion boundaries.
- Token placement and noise strategy
- Noise tokens default to depth=0; test alternative depth priors for unobserved regions (e.g., scene priors, learned depth proposals) and their effect on occlusion ordering and realism.
- Study strategies for handling tokens projected outside the grid (discarded) to avoid “holes,” such as border extrapolation or learned background priors.
- Generalization to videos and 4D
- Interplay between temporal PEs and the proposed 3D PE-Field is untested; extend and evaluate on video NVS with time-aware visibility and motion, including dynamic scenes and moving cameras.
- Examine temporal consistency and drift across long camera paths without generating intermediate frames.
- Safety and stability under PE manipulations
- Manipulating PEs yields powerful spatial control; characterize out-of-distribution PE transformations that trigger failure modes, and develop guardrails or regularizers for stable behavior.
- Reproducibility and training specifics
- Important training details are omitted (data scale, augmentations, schedules, regularization); release full configs and conduct sensitivity analyses to hyperparameters and initialization choices.
- Measure catastrophic forgetting of pretrained capabilities when reassigning head PEs, and test strategies (e.g., LoRA, adapters) to preserve general generative quality.
- Photometric realism and physical effects
- Changes in lighting, shadows, and interreflections across viewpoints are not modeled; evaluate and integrate relighting-aware components or physically informed constraints.
- The role of PEs vs. content features
- Disentangle how much geometry comes from PE-Field vs. content tokens; perform interventions (freeze content, vary PE granularity) and quantify contributions to accuracy and detail.
- Failure case taxonomy and benchmarks
- Provide a curated benchmark of challenging cases (extreme baselines, thin structures, reflective surfaces, cluttered occlusions) and a taxonomy of observed failures to standardize future comparisons.
Practical Applications
Immediate Applications
The following applications can be deployed with current PE-Field–augmented DiT capabilities and existing tooling (e.g., Flux.1 Kontext, VGGT for monocular depth/poses, standard VAEs), assuming access to GPU compute and integration into existing image-editing or content pipelines.
- Single-image novel view synthesis for product and property visualization
- SaaS/API that accepts an image plus a requested camera transform and returns the novel view
- Web dashboard with “Rotate 15°, 30°, 45°” presets and multi-step generation for large motions
- Assumptions/dependencies:
- Requires robust monocular depth and camera pose estimation (e.g., VGGT) for the input domain
- Performance drops with heavy occlusions, textureless regions, reflective surfaces; larger viewpoint changes benefit from multi-step generation
- Domain-specific fine-tuning may be needed (furniture vs. apparel vs. outdoor scenes)
- 3D-aware photo editing: viewpoint rotation, object removal, and recomposition
- Plugins for Photoshop, After Effects, DaVinci Resolve, or mobile photo apps
- “PE-Field camera” control in UI: rotate objects/background independently; slider for rotation angle; depth-aware masks
- Assumptions/dependencies:
- Accurate masks or object segmentation (e.g., SAM/GroundingDINO) to isolate target tokens/point clouds
- Depth estimation must be consistent with the scene; failure cases lead to misaligned fills or distortions
- Camera-aware compositing for design and CG pipelines
- Node in Nuke/Blender/Unreal that applies PE-Field transforms to reference plates and layers
- “Perspective match” operator powered by depth-aware RoPE
- Assumptions/dependencies:
- Reliant on depth maps or proxy geometry; scenes with complex occlusions may require manual cleanup
- Integration with existing pipelines and formats (EXR, USD) for token/latent interchange
- Data augmentation for vision models from single views
- Offline augmentation scripts that call NVS-DiT to produce extra views per image
- Benchmarks comparing geometric consistency (PSNR/SSIM/LPIPS) across augmented datasets
- Assumptions/dependencies:
- Synthetic views carry generative biases; must be flagged and separated from real data to avoid leakage in evaluation
- Augmentations should be domain-matched and validated for downstream task benefit
- Interactive educational content: explore perspectives from a single image
- Web widgets with PE-Field sliders for rotation/translation; guided tours of scenes
- Assumptions/dependencies:
- Works best on scenes with reliable depth cues; extreme rotations may require progressive multi-step synthesis
- Previsualization and shot planning from minimal assets
- “Previs from plate” utility using PE-Field transforms; angle presets and focal length emulation
- Assumptions/dependencies:
- Not a substitute for full multi-view capture; use for rough planning and look development
- Research probes and diagnostics for transformer positional encodings
- Open-source library to swap PE hierarchies per head and evaluate geometric consistency
- Visualization toolkit that overlays token grids and sub-patch PE levels
- Assumptions/dependencies:
- Requires access to large DiT backbones (Flux/SD3) and latent/VAE encoders; compute resources for experiments
- Policy-aligned provenance labeling for spatial edits
- Edit logs recording camera deltas and multi-step synthesis parameters; watermarking tied to PE transforms
- Assumptions/dependencies:
- Platform cooperation for metadata preservation; standards for describing geometry-aware generative edits
Long-Term Applications
These applications likely require further research, scaling, domain adaptation, or new hardware/software stacks to be practical and reliable.
- Real-time AR/VR camera repositioning from a single or sparse view
- On-device PE-Field acceleration (mobile NPUs/GPUs), streaming depth/pose estimation, temporal consistency modules
- Assumptions/dependencies:
- Low-latency monocular depth with minimal drift, robust occlusion handling, real-time denoising; safety constraints to avoid motion sickness artifacts
- 3D asset creation from sparse imagery with PE-Field–guided generative reconstruction
- Hybrid pipeline: PE-Field NVS → multi-view fusion → 3D optimization; asset export to standard formats (GLTF/USD)
- Assumptions/dependencies:
- Need reliable multi-view consistency across generated frames; failure modes in depth estimation/occlusion lead to geometry artifacts
- World-consistent video generation with precise camera control
- PE-Field camera controllers inside video diffusion models; trajectory editors and consistency validators
- Assumptions/dependencies:
- Temporal coherence modules, robust depth across time, scalable training on large multi-view/video datasets
- Robotics perception and simulation from limited observations
- PE-Field augmentation nodes in SLAM stacks; synthetic view generation for policy training; uncertainty-aware controllers
- Assumptions/dependencies:
- Safety-critical validation, uncertainty quantification, domain adaptation to robotic sensors (fisheye, event cameras)
- Remote inspection and infrastructure digital twins from sparse photos
- Inspection dashboards with PE-Field synthesis; integration with BIM/CAD; human-in-the-loop verification
- Assumptions/dependencies:
- Strict QA and disclaimers (synthetic views), calibration to specific asset types, conservative limits on viewpoint deltas
- Medical imaging view augmentation (research-only until validated)
- Research pipelines for PE-Field–like encodings adapted to medical modalities (e.g., depth proxies from learned priors)
- Assumptions/dependencies:
- Rigorous clinical validation, regulatory approvals, modality-specific physics constraints; potential risks of misleading artifacts
- Smartphone “post-capture perspective” feature
- On-device PE-Field models, lightweight monocular depth, UI sliders for subtle reframing; multi-step synthesis for larger changes
- Assumptions/dependencies:
- Efficient models for mobile NPUs, energy constraints, guardrails against extreme edits that degrade quality
- Forensic detection tools for synthetic viewpoint edits
- Classifiers trained on PE-Field edit logs; consistency checks across inferred geometry; provenance chains (C2PA)
- Assumptions/dependencies:
- Access to metadata and cooperation from platforms; robust detectors that generalize across models and edit strategies
- Standards and benchmarks for geometry-aware generative editing
- Metric suites (PSNR/SSIM/LPIPS + geometric alignment scores), public leaderboards, dataset curation guidelines
- Assumptions/dependencies:
- Multi-stakeholder consensus; stable reference datasets with ground-truth geometry
- Unified 2D–3D generative frameworks using PE-Field as a geometry prior
- Architectures combining depth-aware, hierarchical RoPE with multi-representation VAEs; cross-modal training pipelines
- Assumptions/dependencies:
- Large-scale multi-view/multimodal data, stable training methods, interpretability and safety evaluation
Cross-cutting assumptions and dependencies
- Monocular depth/pose estimation quality is a primary bottleneck; domain-specific fine-tuning and QA are often required.
- Hierarchical sub-patch PEs assume the pretrained DiT’s attention-head structure; porting to other backbones may need careful mapping and retraining.
- Large viewpoint changes benefit from progressive multi-step synthesis; single-step transforms can introduce artifacts.
- Compute requirements (GPU/TPU/NPU) and latency constraints determine real-time vs. offline feasibility.
- Ethical and policy considerations (disclosure, watermarking, provenance) are essential for deployments that manipulate viewpoint or remove objects.
Glossary
- Autoregressive: A modeling approach where outputs are generated sequentially, each step conditioned on previous outputs. "CausNVS~\cite{kong2025causnvs} also explores an autoregressive approach for novel view synthesis."
- Camera pose: The position and orientation of a camera in 3D space that determines the viewpoint of the scene. "However, directly encoding camera pose conditions as text embeddings makes it difficult to precisely control viewpoint changes."
- Depth-aware encodings: Positional encodings that incorporate depth information to represent 3D structure. "PE-Field incorporates depth-aware encodings for volumetric reasoning and hierarchical encodings for fine-grained sub-patch control."
- Denoising: The iterative process in diffusion models that removes noise to generate a clean output. "This independence also appears during denoising: as shown in Figure~\ref{fig:dit_analysis} (Bottom), perturbing PEs of noise tokens still yields globally coherent results..."
- Diffusion Transformers (DiTs): Transformer-based architectures used within diffusion models for image and video generation. "Diffusion Transformers (DiTs) have emerged as the dominant architecture for visual generation, powering state-of-the-art image and video models."
- Hierarchical encodings: Multi-level positional encodings that capture spatial information at varying granularities. "PE-Field incorporates depth-aware encodings for volumetric reasoning and hierarchical encodings for fine-grained sub-patch control."
- Inductive biases: Built-in assumptions in a model that guide learning toward certain structures or patterns. "DiTs leverage the scalability of Transformers while preserving the spatial inductive biases necessary for visual synthesis."
- Inpainting: Filling in missing or occluded regions of an image to produce a complete output. "warping into the target view is used which is then followed by inpainting to synthesize novel views."
- LPIPS: Learned Perceptual Image Patch Similarity; a metric quantifying perceptual differences between images. "We then calculated three metrics, PSNR, SSIM \cite{wang2004image}, and LPIPS \cite{zhang2018unreasonable}..."
- Monocular reconstruction: Estimating 3D structure from a single image using geometric or learned priors. "incorporate additional results from monocular reconstruction to provide an explicit geometric structure..."
- Multi-head self-attention (MHA): A Transformer mechanism that computes attention across multiple subspaces (heads) for richer relationships. "Within the transformer, multi-head self-attention (MHA) is applied by projecting into multiple subspaces (heads)..."
- NeRF: Neural Radiance Fields; a neural representation for 3D scenes enabling differentiable volumetric rendering. "PixelNeRF \cite{yu2021pixelnerf} employs NeRF \cite{mildenhall2020nerf} as the 3D representation..."
- Novel view synthesis (NVS): Generating images of a scene from new viewpoints given one or more input views. "Novel view synthesis (NVS) is a widely studied and discussed problem..."
- Optical axis: The line extending from the camera lens center along its viewing direction; used to define depth. "distance of each pixel’s corresponding 3D point from the camera along the optical axis (that is, its z coordinate in the camera coordinate system)."
- Patch tokens: Tokens representing image patches in Transformer-based generative models. "By representing images as patch tokens with positional encodings (PEs), DiTs combine Transformer scalability with spatial and temporal inductive biases."
- Patchifying: Converting an image into a sequence of fixed-size patches for tokenization. "DiT-based architectures model image generation by patchifying the input and representing each patch as a token with a 2D positional encoding (PE)."
- Positional Encoding Field (PE-Field): A 3D, depth-aware and hierarchical extension of positional encodings for geometry-aware generation. "we introduce the Positional Encoding Field (PE-Field), which extends positional encodings from the 2D plane to a structured 3D field."
- Positional encodings (PEs): Vector encodings that inject spatial information (e.g., position) into tokens for Transformers. "By encoding images into sequences of patch tokens and applying 2D positional encodings (PEs)~\cite{vaswani2017attention}..."
- PSNR: Peak Signal-to-Noise Ratio; a reconstruction quality metric measuring fidelity relative to ground truth. "We then calculated three metrics, PSNR, SSIM \cite{wang2004image}, and LPIPS..."
- Rectified flow: A training framework for generative models that learns direct flows from noise to data. "we leverage multi-view supervision under a rectified-flow \cite{liu2022flow} objective."
- RoPE: Rotary Position Embedding; a method to encode relative positions via rotations applied to queries and keys. "we extend standard 2D RoPE \cite{su2024roformer} to a 3D depth-aware encoding..."
- Reprojection errors: Discrepancies when projecting 3D points into 2D images due to geometry or pose inaccuracies. "However, reprojection errors in the warped image may disrupt the semantics of the source image and are difficult to correct during inpainting."
- SSIM: Structural Similarity Index Measure; a perceptual metric for image similarity focusing on structure. "We then calculated three metrics, PSNR, SSIM \cite{wang2004image}, and LPIPS..."
- Sub-patch granularity: Modeling and control at scales finer than a single patch to capture local detail. "allowing fine-grained spatial control at sub-patch granularity."
- Temporal PEs: Positional encodings that incorporate time indices to maintain coherence across video frames. "temporally coherent video synthesis (where additional temporal PEs are employed)."
- Tri-plane representations: A 3D representation using three orthogonal feature planes to model volumetric content. "LRM \cite{honglrm} uses tri-plane representations..."
- Variational Autoencoder (VAE): A generative model that encodes data into a latent distribution and decodes samples back to data. "obtained by the corresponding DiT's VAE encoder."
- View transformation: Mapping scene content from one camera viewpoint to another using 3D geometry. "since view transformation inherently occurs in 3D space..."
- Volumetric field: A 3D spatial field representation enabling reasoning across viewpoints and depths. "embedding tokens in a volumetric field that supports reasoning across viewpoints."
- Volumetric reasoning: Inferring and enforcing 3D relationships (including depth) to maintain geometric consistency. "PE-Field incorporates depth-aware encodings for volumetric reasoning..."
- Warping: Geometric transformation of image content to align with a target view or coordinate system. "warping into the target view is used which is then followed by inpainting to synthesize novel views."
Collections
Sign up for free to add this paper to one or more collections.