AToken: A Unified Tokenizer for Vision
Abstract: We present AToken, the first unified visual tokenizer that achieves both high-fidelity reconstruction and semantic understanding across images, videos, and 3D assets. Unlike existing tokenizers that specialize in either reconstruction or understanding for single modalities, AToken encodes these diverse visual inputs into a shared 4D latent space, unifying both tasks and modalities in a single framework. Specifically, we introduce a pure transformer architecture with 4D rotary position embeddings to process visual inputs of arbitrary resolutions and temporal durations. To ensure stable training, we introduce an adversarial-free training objective that combines perceptual and Gram matrix losses, achieving state-of-the-art reconstruction quality. By employing a progressive training curriculum, AToken gradually expands from single images, videos, and 3D, and supports both continuous and discrete latent tokens. AToken achieves 0.21 rFID with 82.2% ImageNet accuracy for images, 3.01 rFVD with 40.2% MSRVTT retrieval for videos, and 28.28 PSNR with 90.9% classification accuracy for 3D.. In downstream applications, AToken enables both visual generation tasks (e.g., image generation with continuous and discrete tokens, text-to-video generation, image-to-3D synthesis) and understanding tasks (e.g., multimodal LLMs), achieving competitive performance across all benchmarks. These results shed light on the next-generation multimodal AI systems built upon unified visual tokenization.
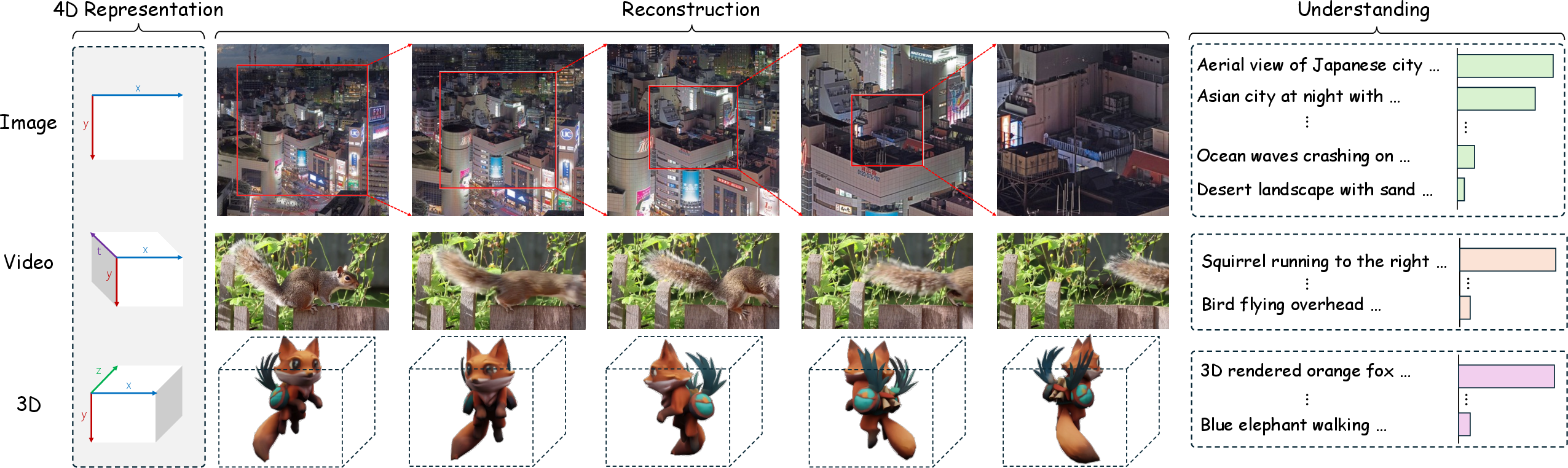







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces AToken, a new way for computers to “read” visual stuff (like photos, videos, and 3D objects) using the same kind of simple building blocks called tokens. AToken can both:
- rebuild the original visual content with high quality (reconstruction), and
- understand what’s in it (semantics), like recognizing objects or matching images to text.
It brings images, videos, and 3D into one shared system, kind of like how LLMs turn all kinds of text into tokens they can work with.
What questions did the researchers ask?
- Can we make one visual “tokenizer” that works for images, videos, and 3D models instead of having separate tools for each?
- Can that one tokenizer both rebuild visuals with lots of detail and understand their meaning?
- Can we do this without using unstable training tricks (like GANs) and still get top-quality results?
How did they do it?
One shared “alphabet” for pictures, videos, and 3D
Think of tokens as an alphabet the computer understands. The team designed a shared 4D space for all visual types:
- Images are like flat slices (x, y),
- Videos add time (t),
- 3D objects add depth (z).
They place everything into the same 4D coordinate system [t, x, y, z], but only use the parts they need (for example, images don’t use time or depth). This makes one universal representation for all visuals.
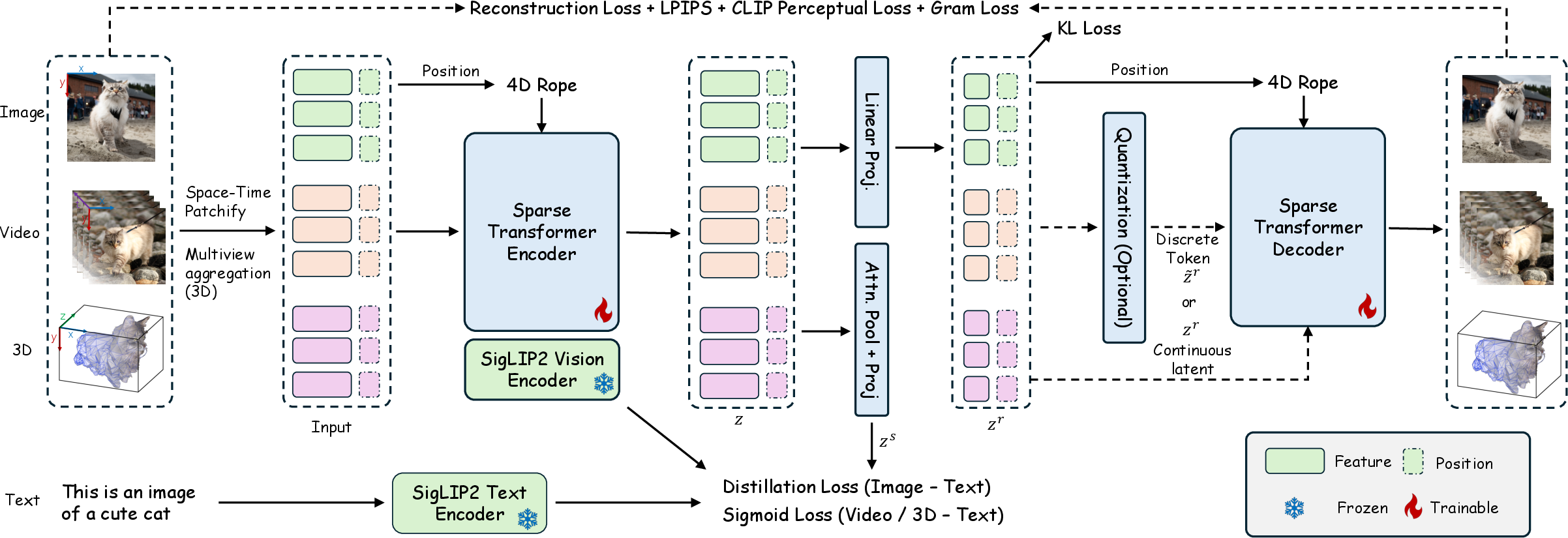
The model: a transformer with 4D positions
They use a transformer (a powerful pattern-finding model also used in chatbots) and give each visual patch a 4D “address,” so the model knows where and when it came from. This 4D positional info is like a GPS for each piece of the picture/video/3D shape.
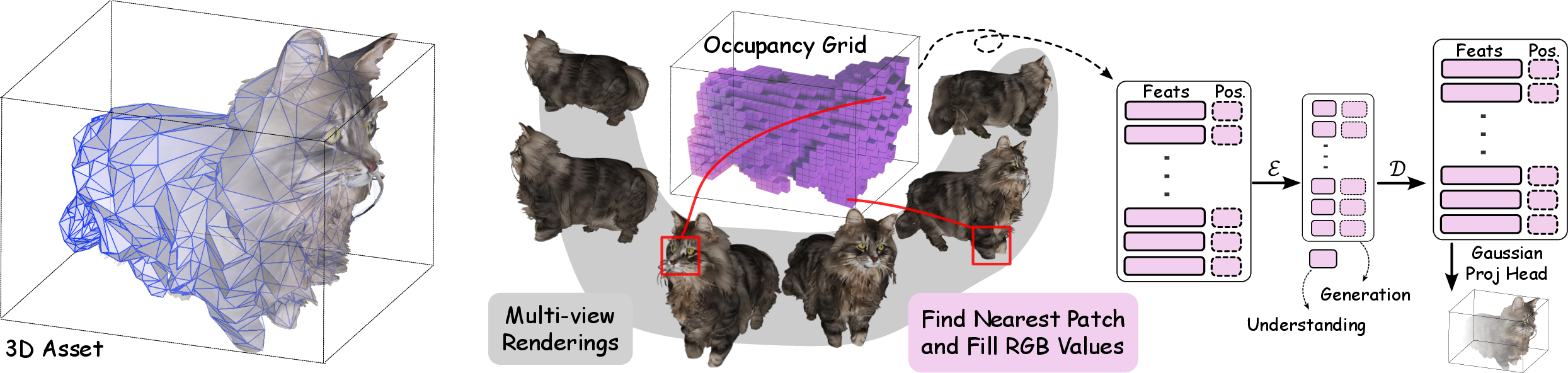
- For 3D, they render the object from many camera views, gather features into a 3D grid (voxels), and later decode it using “Gaussian splats” (think of painting the object with many tiny soft blobs) to make it viewable.
- The same encoder handles all modalities. That means no separate networks for images, videos, or 3D—just one.
Training without “adversaries”
Many image/video tools use GANs (an “artist” network vs. a “critic” network) to get sharp results, but GANs can be unstable. Instead, AToken uses:
- Perceptual loss: encourages outputs to look right to a human-like feature detector.
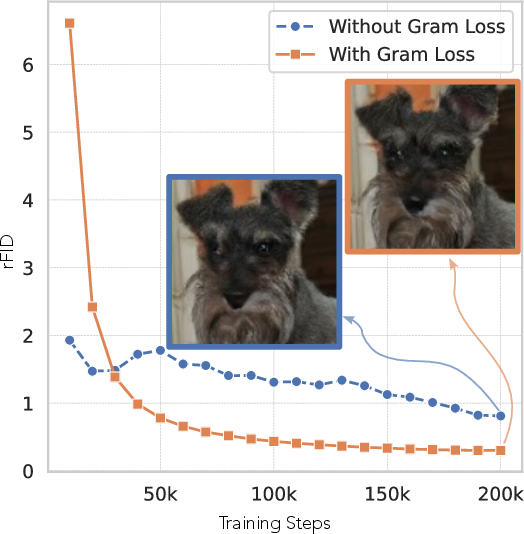
- Gram matrix loss: matches textures and styles by aligning how features co-vary, like making sure the “fabric weave” of an image looks right.
- A tiny regularization (KL) to keep the compressed codes neat and compact.
- Semantic alignment: aligns visual features with text features (so it understands content), using a strong text-image teacher model.
This avoids GANs while still producing very realistic reconstructions.
Step-by-step learning (a curriculum)
They teach the model in stages, growing its skills:
- Learn image understanding and image reconstruction.
- Add videos and learn motion.
- Add 3D geometry and learn shape.
- Optionally, convert smooth codes (continuous tokens) into fixed levels (discrete tokens), which some generators prefer.
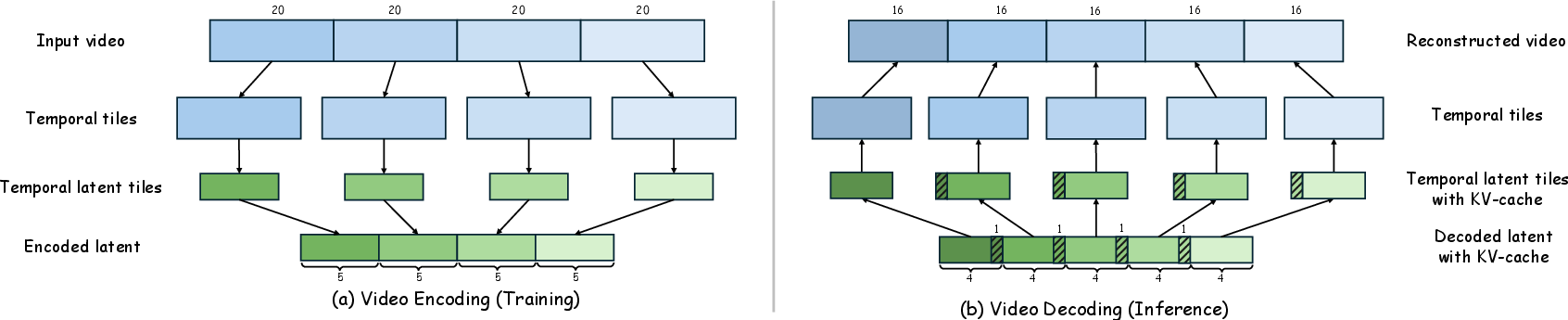
They also use smart memory for videos (KV-caching) so the model doesn’t re-do the same work for overlapping frames.
What did they find?
AToken achieved strong results across all three areas (numbers below are standard vision scores; “lower is better” for rFID/rFVD/LPIPS, “higher is better” for PSNR/accuracy):
- Images: rFID 0.21 with 82.2% zero-shot ImageNet accuracy. This means it rebuilds images with high realism and also understands them well.
- Videos: rFVD 3.01 and good text-to-video retrieval. It handles motion and content meaningfully.
- 3D: PSNR about 28.2 and 90.9% classification accuracy. It reconstructs 3D shapes clearly and recognizes them.
Two more key findings:
- One model can truly cover images, videos, and 3D for both reconstruction and understanding—something past methods didn’t do all at once.
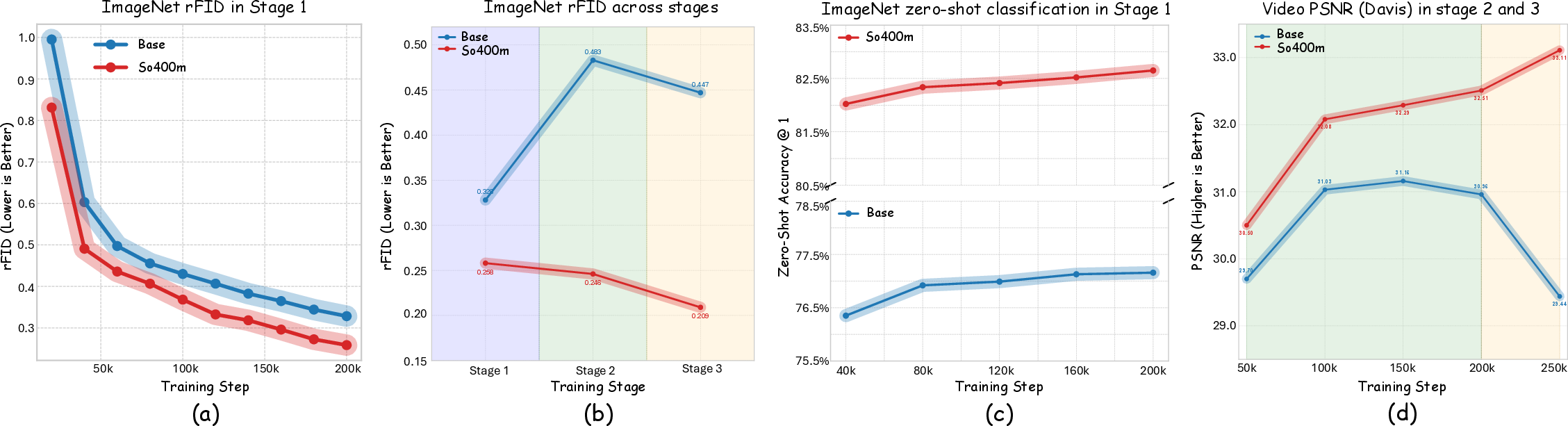
- Multimodal training (adding video and 3D) actually improved image quality instead of hurting it.
Why does this matter?
- A single, unified visual tokenizer is like giving AI one shared “visual language.” That makes it easier to build powerful systems that can both understand and create visuals.
- It could power next-gen multimodal AI: think assistants that can describe, edit, animate, or 3D-print from the same shared representation.
- By avoiding unstable training (no GANs) and supporting both continuous and discrete tokens, AToken is easier to scale and plug into different generators, including those used with LLMs.
In short, AToken moves vision closer to where LLMs already are: one simple token space for many tasks and formats, enabling smarter, more flexible AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored, organized by theme to help guide follow-up research.
Architecture and representation
- Lack of ablations disentangling the contributions of 4D RoPE, sparse 4D patchification, and SigLIP2 initialization to both reconstruction and understanding; unclear which component drives most gains.
- No analysis of how mixing “metric” 3D coordinates (occupancy) with 2D/temporal grid indices affects attention patterns; unclear whether 4D RoPE fully bridges these semantics or introduces modality-specific biases.
- Unspecified attention sparsity patterns or locality constraints for the sparse transformer; complexity scaling and attention layouts (global vs local/windowed vs block-sparse) are not detailed or compared.
- Missing study of extrapolation behavior for 4D RoPE to very long temporal sequences, very high spatial resolutions, or larger voxel grids (e.g., beyond 643); absence of positional scaling/interpolation strategies for extreme settings.
- The 3D pipeline aggregates multi-view 2D features into a 643 voxel space but does not examine fidelity vs. voxel resolution trade-offs, thin structures, or geometric ambiguities due to limited viewpoints.
Training objectives and curriculum
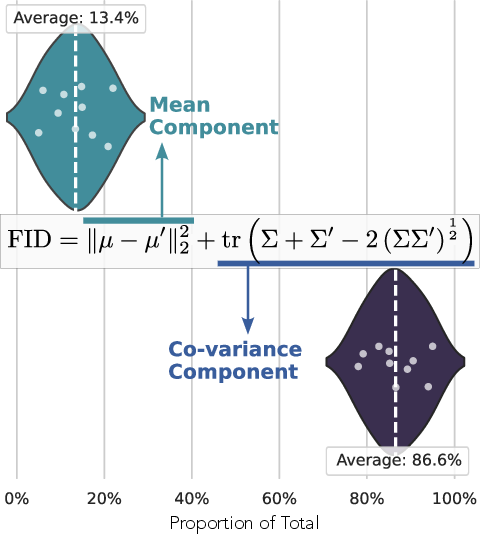
- Gram matrix loss is motivated by an rFID covariance decomposition, but there is no formal justification or generalization analysis across diverse datasets/modalities; sensitivity to feature extractors (choice of Φ and layers) remains unexplored.
- For video and 3D, only L1 reconstruction is used (perceptual and Gram losses omitted for efficiency). It is unclear how much performance is left on the table and whether lightweight perceptual losses or distillation could recover texture/temporal details.
- No systematic exploration of the multi-objective trade-off (λrec, λsem, λKL). How do different weightings impact the generation–understanding Pareto frontier?
- The progressive curriculum improves image rFID, but there is no comparison to single-stage joint training or alternative curricula; mechanism behind cross-modal gains (e.g., how video/3D bolster image quality) is not analyzed.
Quantization and discrete tokens
- FSQ configuration (8 groups × 6 dims × 4 levels) is fixed; no exploration of groupings, level counts, or modality-specific quantizers vs a shared quantizer.
- Absent token statistics (e.g., perplexity, utilization, dead code rates) and rate–distortion curves; no entropy model or bitrate estimates for practical compression.
- Limited evidence on the downstream utility of discrete tokens with LLMs (sequence length, compatibility, training stability, and generation quality across tasks).
Modality coverage and generality
- 3D handling is restricted to static assets decoded as Gaussian splats; dynamic 3D (4D scenes), meshes, NeRFs, point clouds, or implicit fields are not evaluated or integrated.
- Video is evaluated on short sequences and tiles; robustness to long-form, streaming, or real-time scenarios with KV caching remains unquantified.
- The unified 4D latent is demonstrated for images, videos, and 3D, but extension to other visual signals (e.g., depth maps, optical flow, multi-spectral, panoramic, or event cameras) is not explored.
Evaluation scope and metrics
- Understanding performance on video trails specialized encoders (e.g., VideoPrism); no analysis of failure cases, domain shift, or what semantics are missing.
- 3D evaluation is limited (e.g., Toys4k); lacks diverse benchmarks, novel-view generalization, and viewpoint-robust metrics beyond PSNR/LPIPS and simple classification.
- Video evaluation uses rFVD and PSNR; no human studies, temporal consistency metrics, or motion-specific measures (e.g., optical-flow–based consistency).
- Image evaluation emphasizes rFID/PSNR, but not human preference, texture realism, or rare object fidelity; semantic reconstruction fidelity (object/attribute consistency) is not assessed.
Efficiency, scaling, and deployment
- Inference throughput, latency, memory footprint, and energy usage under different resolutions/sequence lengths are not reported; KV caching speedups are mentioned but not quantified.
- No scaling laws with model size, depth, width, or dataset scale; unclear whether performance scales smoothly and which bottlenecks dominate.
- The 3D pipeline’s compute/memory costs (multi-view rendering, voxel aggregation, Gaussian decoding/rendering) are not benchmarked end-to-end.
Semantic alignment and text supervision
- Image semantics rely on SigLIP2 distillation; 3D/video use SigLIP’s sigmoid loss, but the text encoder remains frozen and likely monolingual; multilingual alignment and cross-lingual transfer are not examined.
- No studies of bias propagation from the SigLIP2 teacher (e.g., demographic, geographic, or object-frequency biases) or remedies via debiasing objectives.
- Cross-modal semantic coherence in the shared latent (e.g., whether similar latent tokens convey aligned semantics across image/video/3D) is not quantified or visualized.
Robustness and safety
- Robustness to occlusions, motion blur, lighting changes, adversarial perturbations, or OOD content is not evaluated.
- No discussion of safety, watermarking/traceability of generated content, or mitigation against misuse (e.g., deepfakes, 3D asset cloning).
Reproducibility and data transparency
- Training uses internal datasets alongside public ones; data composition, licensing, and potential benchmark contamination are not detailed.
- Code, pretrained checkpoints, and training scripts are not stated as available; exact data preprocessing and sampling policies may hinder full reproducibility.
Downstream applications
- Claims of enabling multimodal LLMs, text-to-video, and image-to-3D are not paired with comprehensive, standardized benchmarks and head-to-head comparisons with specialized SOTA systems.
- Limited analysis of how token choices (continuous vs discrete) affect downstream generative modeling paradigms (diffusion, AR, masked modeling) in terms of sample quality, diversity, and controllability.
Glossary
- 4D Rotary Position Embeddings (RoPE): Incorporates relative position encoding within a 4D space to enhance the transformer model's spatial-temporal understanding. Used in "We introduce a pure transformer architecture with 4D rotary position embeddings to process visual inputs of arbitrary resolutions and temporal durations."
- Adversarial-Free Training: A training approach that achieves high-quality results without using adversarial networks, relying on alternative loss functions like perceptual and Gram matrix losses. From the abstract: "To ensure stable training, we introduce an adversarial-free training objective that combines perceptual and Gram matrix losses."
- rFID (Reconstruction Fréchet Inception Distance): Metric to evaluate the quality of reconstructed images compared to original ones, similar to FID but specifically for reconstructions. Seen as "achieves 0.21 rFID with 82.2\% ImageNet accuracy for images."
- Semantic Embeddings: Representations that capture high-level conceptual meanings of visual inputs for better understanding and alignment with textual data. Used in "semantic embeddings for understanding" as part of the unified representation strategy.
- KV-Caching: A mechanism that caches key-value pairs in transformers to increase inference efficiency, particularly for temporal sequences. Mentioned in context with video processing in "The model natively processes arbitrary resolutions and time duration, and accelerates inference through KV-caching mechanisms."
- Gram Matrix Loss: A loss function targeting the style or texture in image reconstructions, emphasizing second-order statistics. Discussed under "reconstruction loss optimizing feature covariance without adversarial training."
- Sparse Representation: A way to represent data or features that only includes non-zero values, enhancing efficiency and scalability. Referred to in "We implement this through a pure transformer architecture with space-time patch embeddings and 4D Rotary Position Embeddings (RoPE), enabling efficient scaling..."
- 3D Gaussian Splatting: Technique to render 3D objects using surface voxels parameterized by Gaussian functions. Seen in the usage "an additional layer to generate Gaussian splatting parameters for efficient rendering."
- Quantization (FSQ - Finite Scalar Quantization): A compression method that discretizes continuous values to reduce model complexity and facilitate understanding or generation. Discussed in discrete tokenization: "we add FSQ quantization for discrete generation tasks."
- Zero-shot Text Retrieval: The ability of a model to retrieve relevant text information from visual inputs without requiring task-specific fine-tuning. Evaluated as "zero-shot retrieval for videos."
- Semantic Alignment: The strategy of aligning visual and textual modalities in a shared representational space for improved multimodal tasks. Seen in the context of "semantic loss" aiming for alignment.
- Progressive Curriculum: A staged learning strategy to gradually introduce complexities and modalities to stabilize training, described in the stages: "Stage 1: Image Foundation" to "Stage 4: Discrete Tokenization."
- SigLIP2 Vision Encoder: A specific encoder architecture mentioned as a foundation in "starting from the pretrained SigLIP2 encoder."
- Attention Pooling: A method that aggregates feature vectors using attention mechanisms to form a unified representation, aiding in understanding tasks. Used in context "we aggregate latents via attention pooling."
- Perceptual Loss (LPIPS - Learned Perceptual Image Patch Similarity): A loss function that measures the perceptual difference between images, maintaining visual authenticity over pixel-wise accuracy. Discussed under loss functions: "combining four complementary loss components including perceptual."
- Text-to-Video Generation: Generative task involving creating video content from textual descriptions, one of the applications enabled by the tokenizer. Example usage: "...enables both visual generation tasks (e.g., image generation with continuous and discrete tokens, text-to-video generation...)."
- Voxel Representation: A grid-based 3D representation capturing spatial occupancy, used in conjunction with 3D Gaussian splatting. Mentioned in relation to 3D assets: "...and 3D assets as surface voxels extracted from multi-view renderings..."
Collections
Sign up for free to add this paper to one or more collections.

