- The paper introduces a dual-distillation framework leveraging flow semantic distillation and reconstruction‐alignment to enable high-dimensional, semantically robust visual tokenization.
- It demonstrates state-of-the-art generation quality with improved gFID and inception scores while accelerating convergence compared to prior VFM-aligned methods.
- Empirical evaluations on ImageNet-1K validate that increasing latent dimensionality consistently enhances reconstruction, generation, and representation performance.
RecTok: Reconstruction Distillation along Rectified Flow
Motivation and Problem Statement
Continuous tokenization via autoencoders (VAE, VQ-VAE) is the workhorse for latent generative models, notably diffusion models. State-of-the-art image generation and editing models are increasingly bottlenecked by the latent space properties induced by their visual tokenizers. The empirical trade-off between latent dimensionality and generative performance remains unresolved: while high-dimensional latents preserve more content and permit discriminative representations, they have empirically led to optimization and generalization issues, causing the community to restrict production models to low-dimensional spaces. Prior attempts to distill semantics from vision foundation models (VFMs) into the tokenizers have not resolved this bottleneck; generation quality and convergence degrade as dimensionality increases beyond ∼32. The absence of a tokenizer that admits high-dimensional, semantically-rich, and generatively stable representations has hampered unified modeling of editing, generation, and understanding tasks.
Technical Contributions: Flow Semantic Distillation and Reconstruction-Alignment Distillation
RecTok introduces two novel mechanisms in visual tokenizer design, formalized within the rectified flow framework for image generation.
- Flow Semantic Distillation (FSD): Unlike prior approaches that align the VFM semantics only on the noiseless code x0, RecTok systematically supervises the forward flow {xt∣t∈[0,1]} between data and noise. This trajectory, governed by the rectified flow, is directly targeted by the diffusion models in downstream training. By distilling VFM features along this entire path (rather than solely x0), semantic structure is enforced on all intermediate latents, resulting in substantially more discriminative and robust representations for the diffusion transformer. This design choice is empirically validated via linear probing accuracy and t-SNE visualizations.
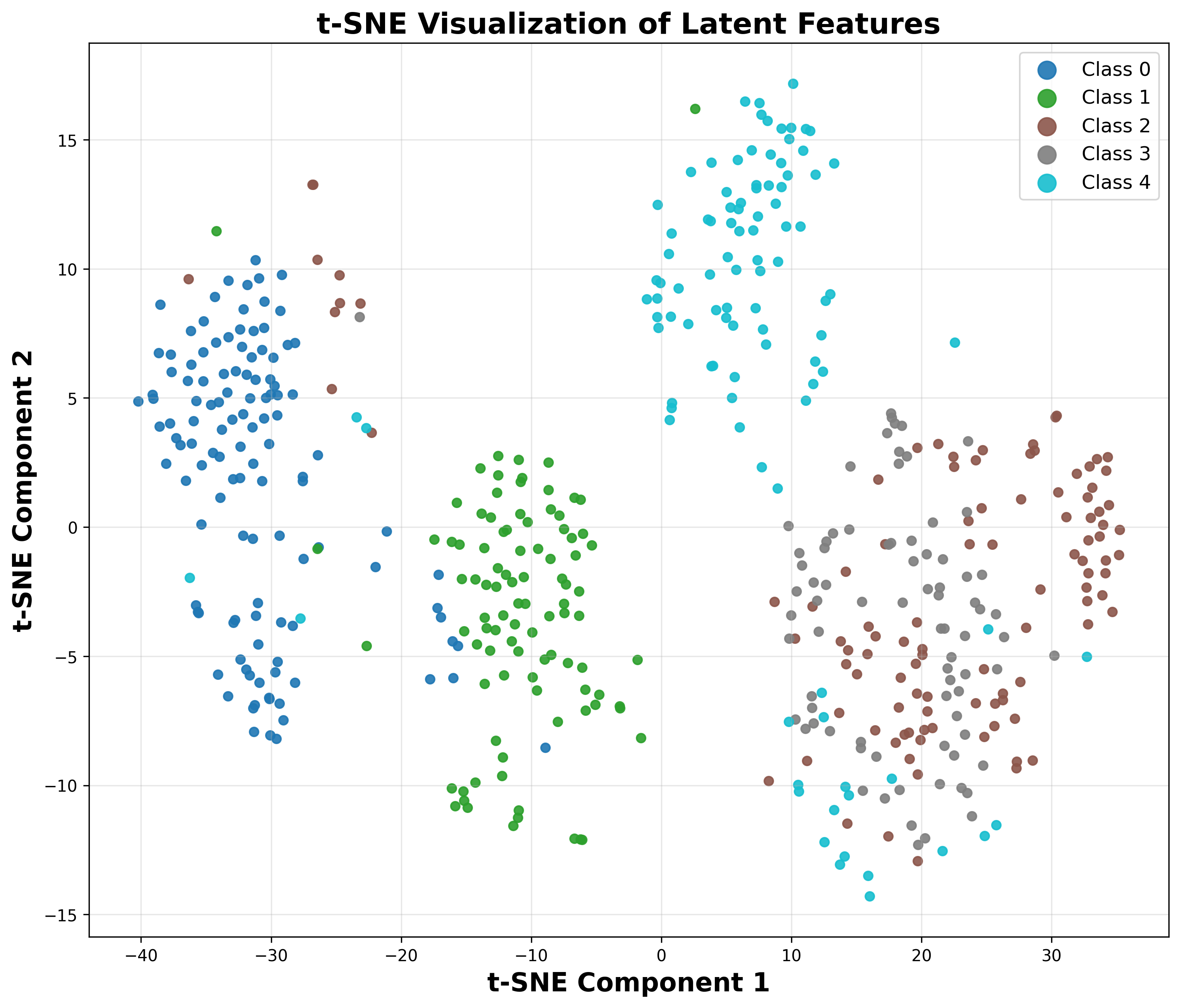
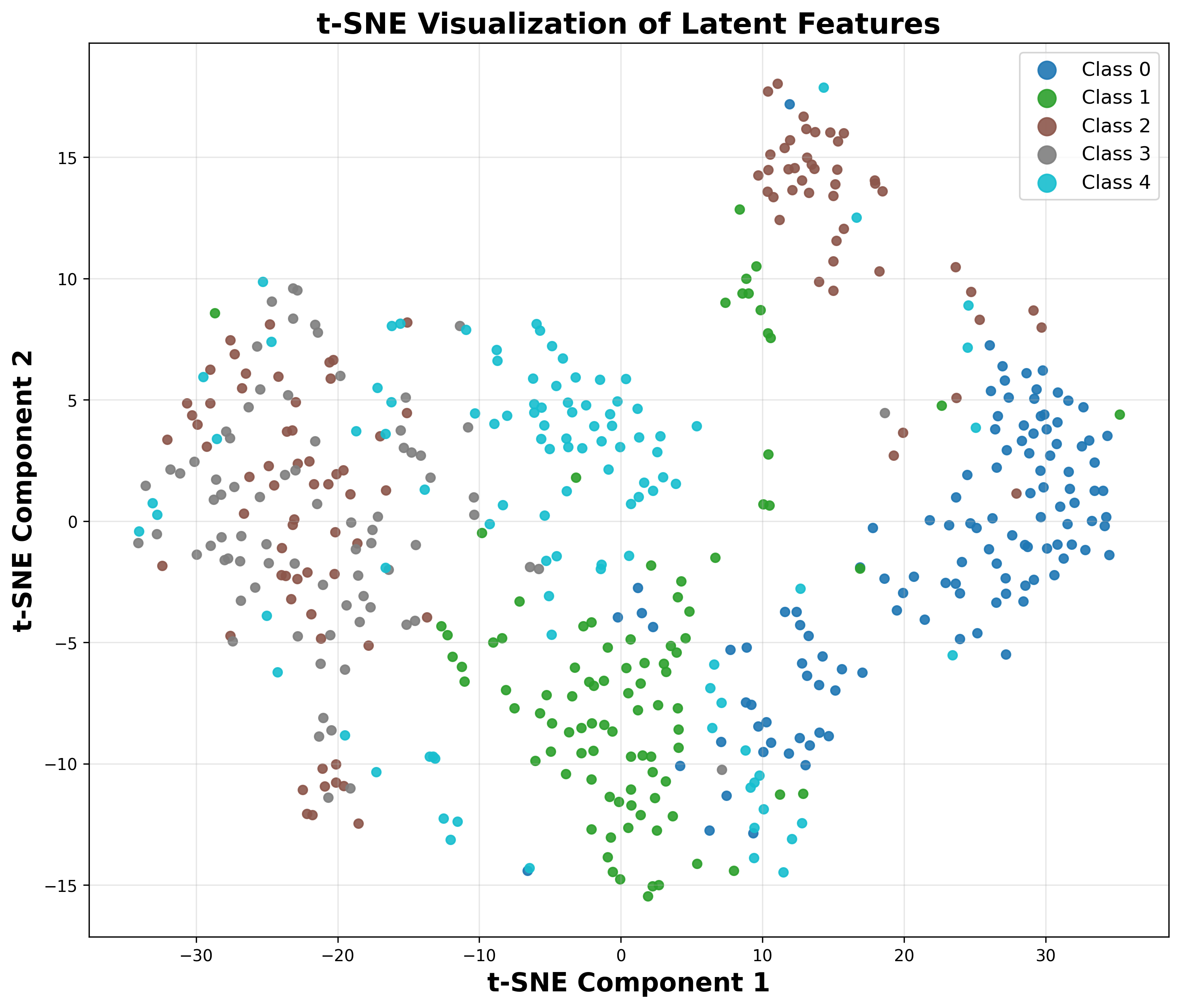
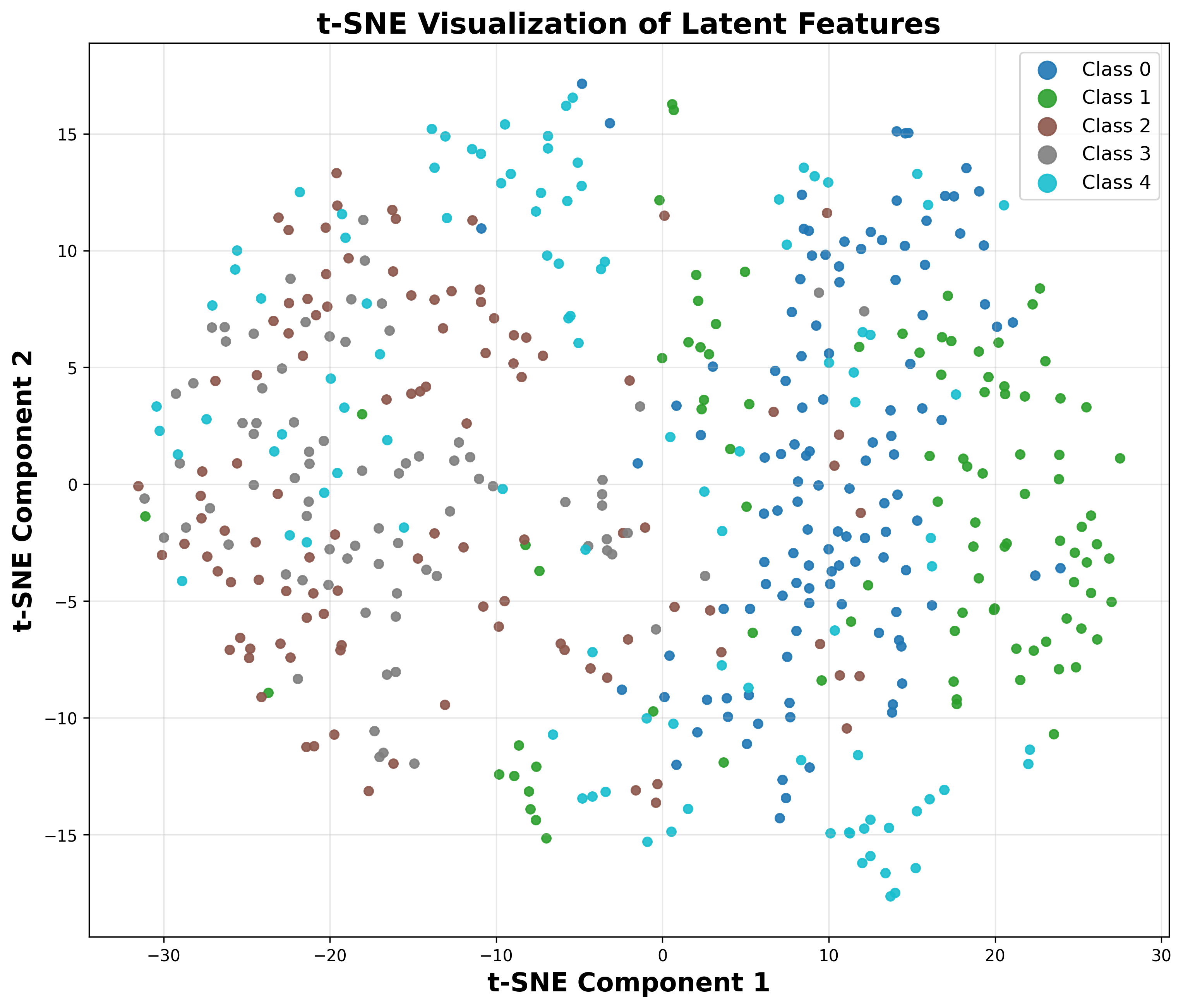
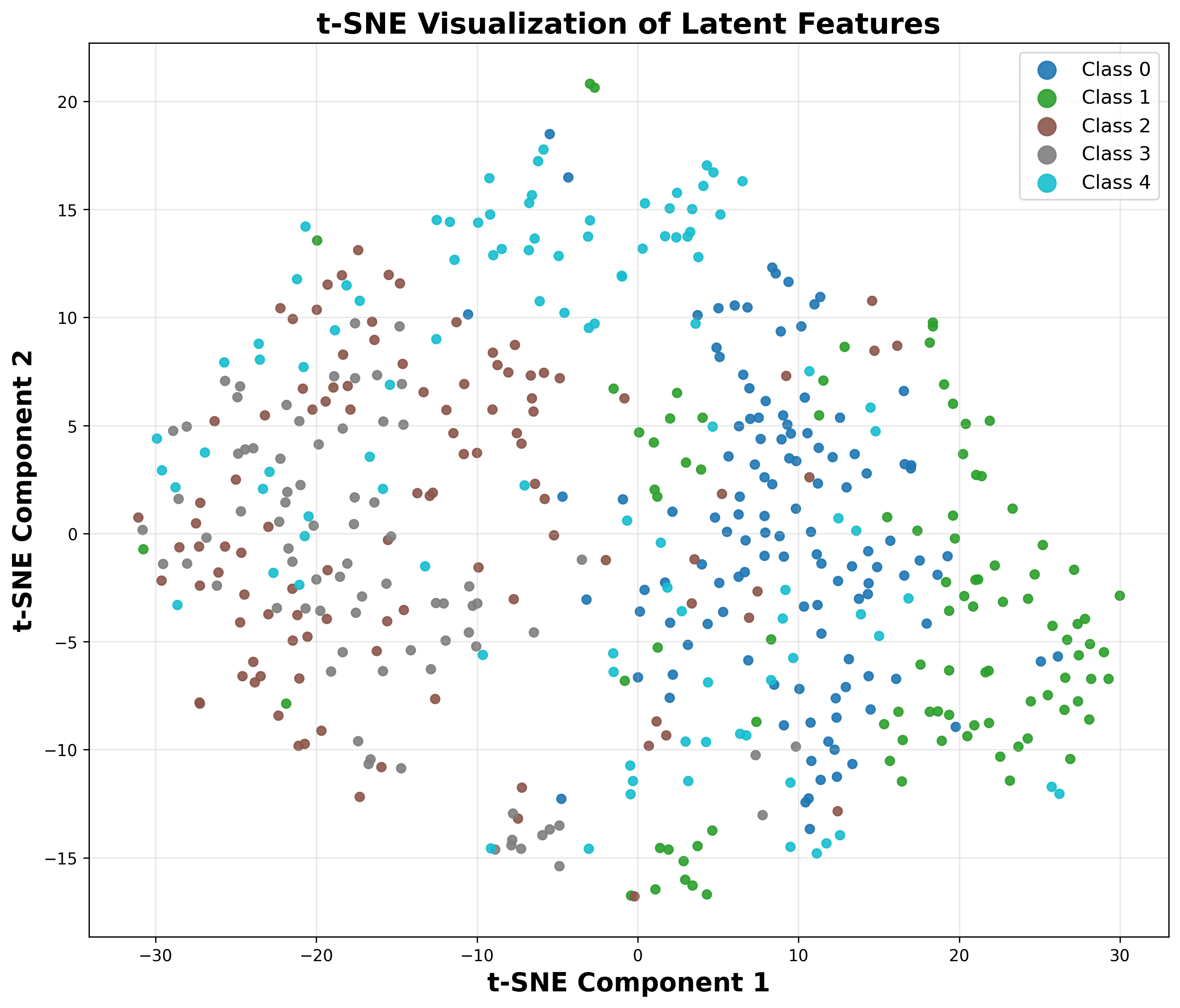
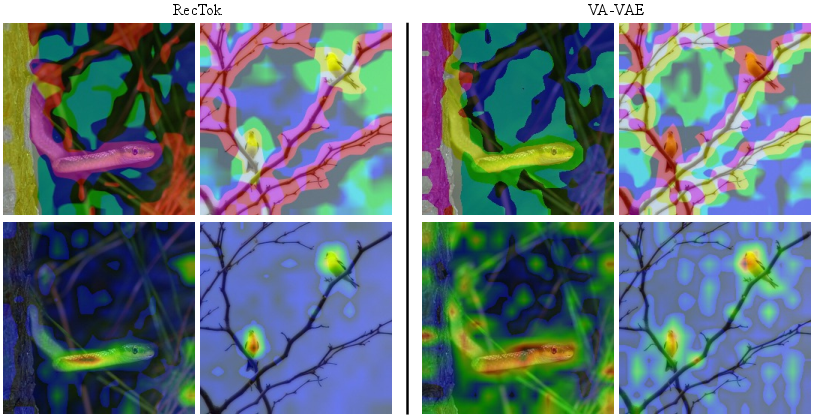
Figure 1: Linear probing accuracy and t-SNE organization show RecTok's superiority across the forward flow.
- Reconstruction-Alignment Distillation (RAD): Drawing inspiration from masked image modeling, random spatial masking is applied to the input. The goal is to reconstruct VFM features for both masked and unmasked regions by decoding noisy latent features from the forward flow. This dual-objective—pixel-space reconstruction and VFM feature alignment—further enforces semantic content and robustness, especially as latent dimensionality increases. Empirical ablations confirm that the joint optimization outperforms either objective in isolation.
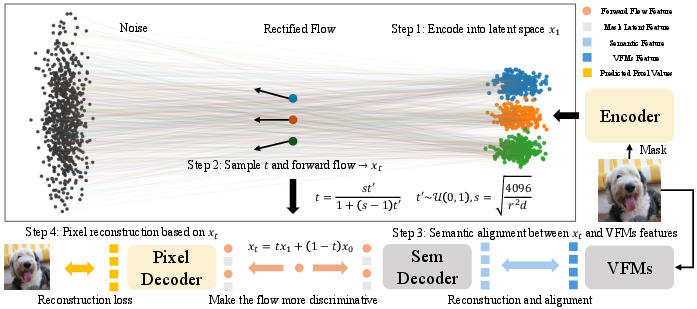
Figure 2: Overview of RecTok pipeline, illustrating random masking, forward flow, and dual decoders for training.
Empirical Validation and Ablations
RecTok is instantiated as a ViT-based autoencoder (ViT-B backbone with additional normalization and activation modules), evaluated primarily on ImageNet-1K at 256x256 resolution. The empirical results demonstrate:

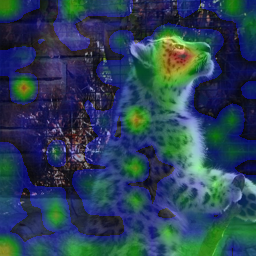
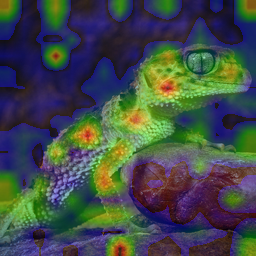


Figure 4: Foreground object structure is highly localized in RecTok features; VA-VAE lacks such explicit semantic grouping.
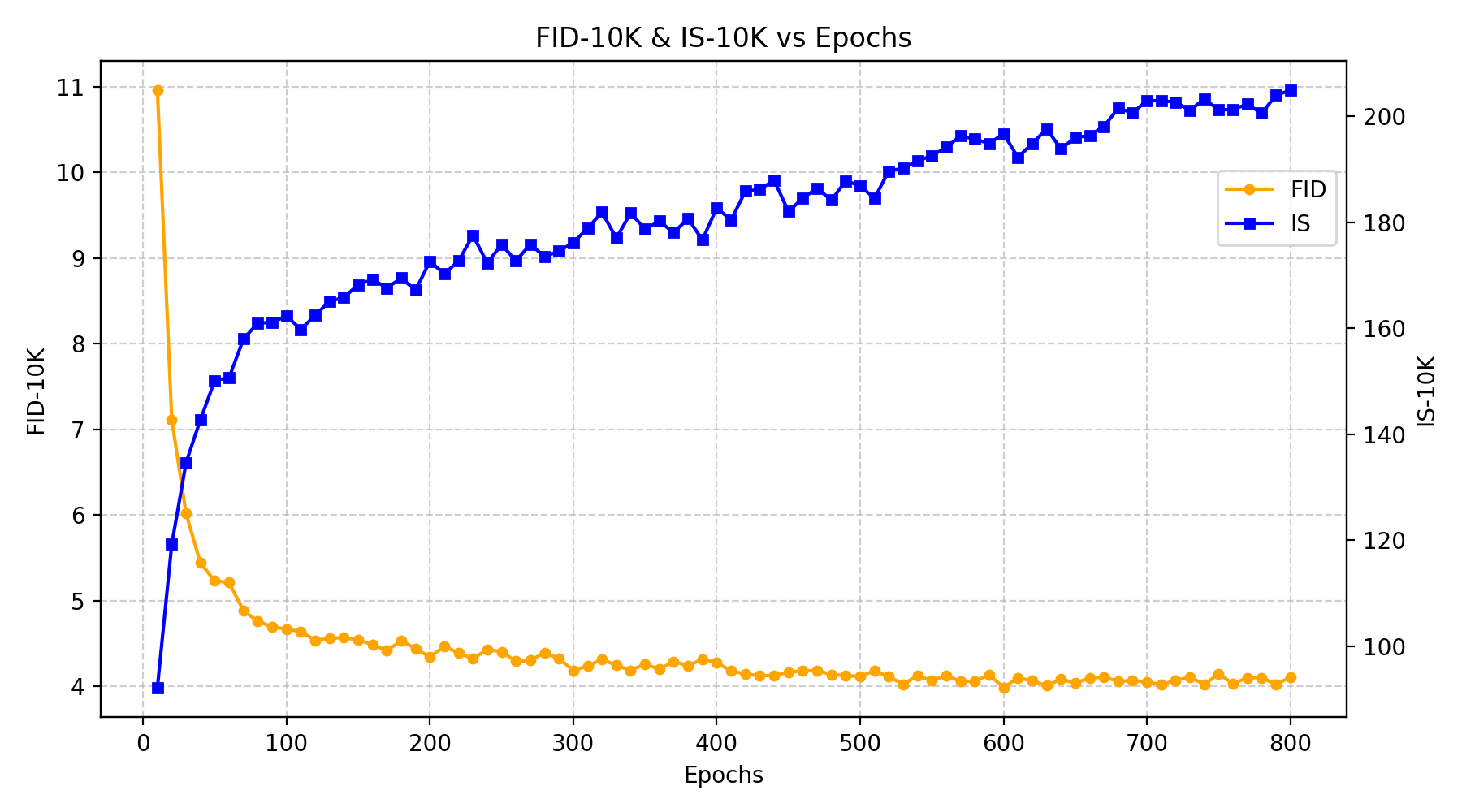
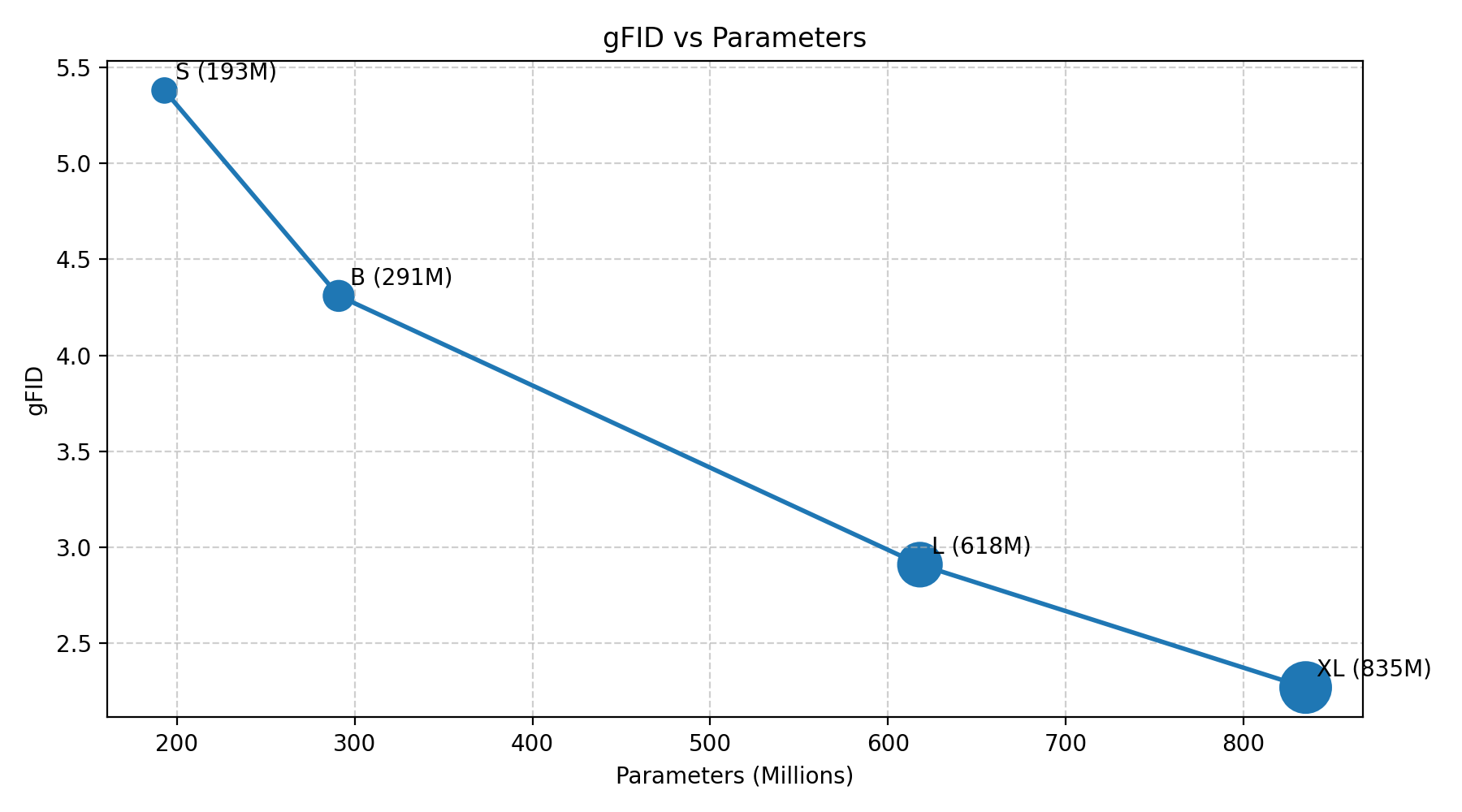
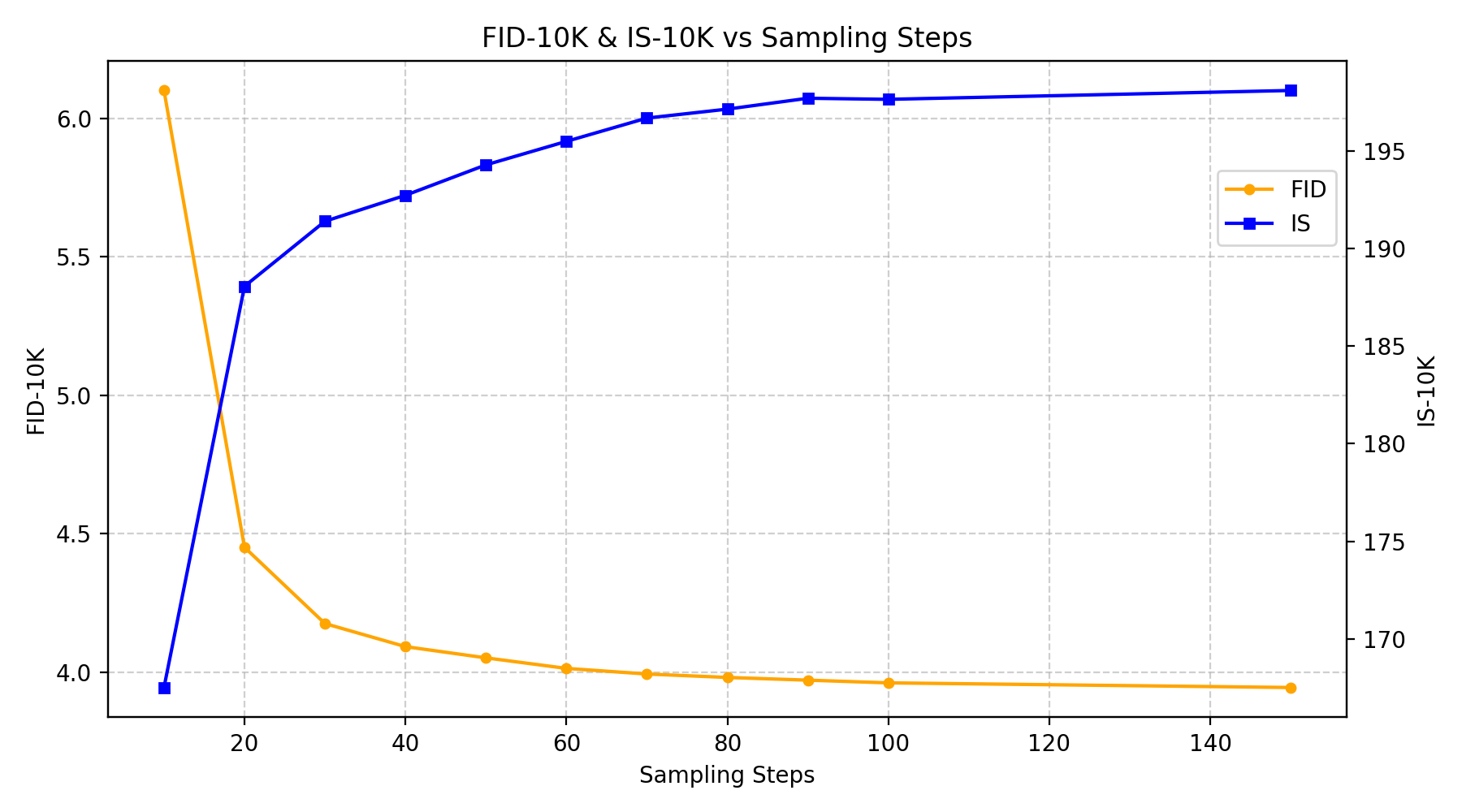
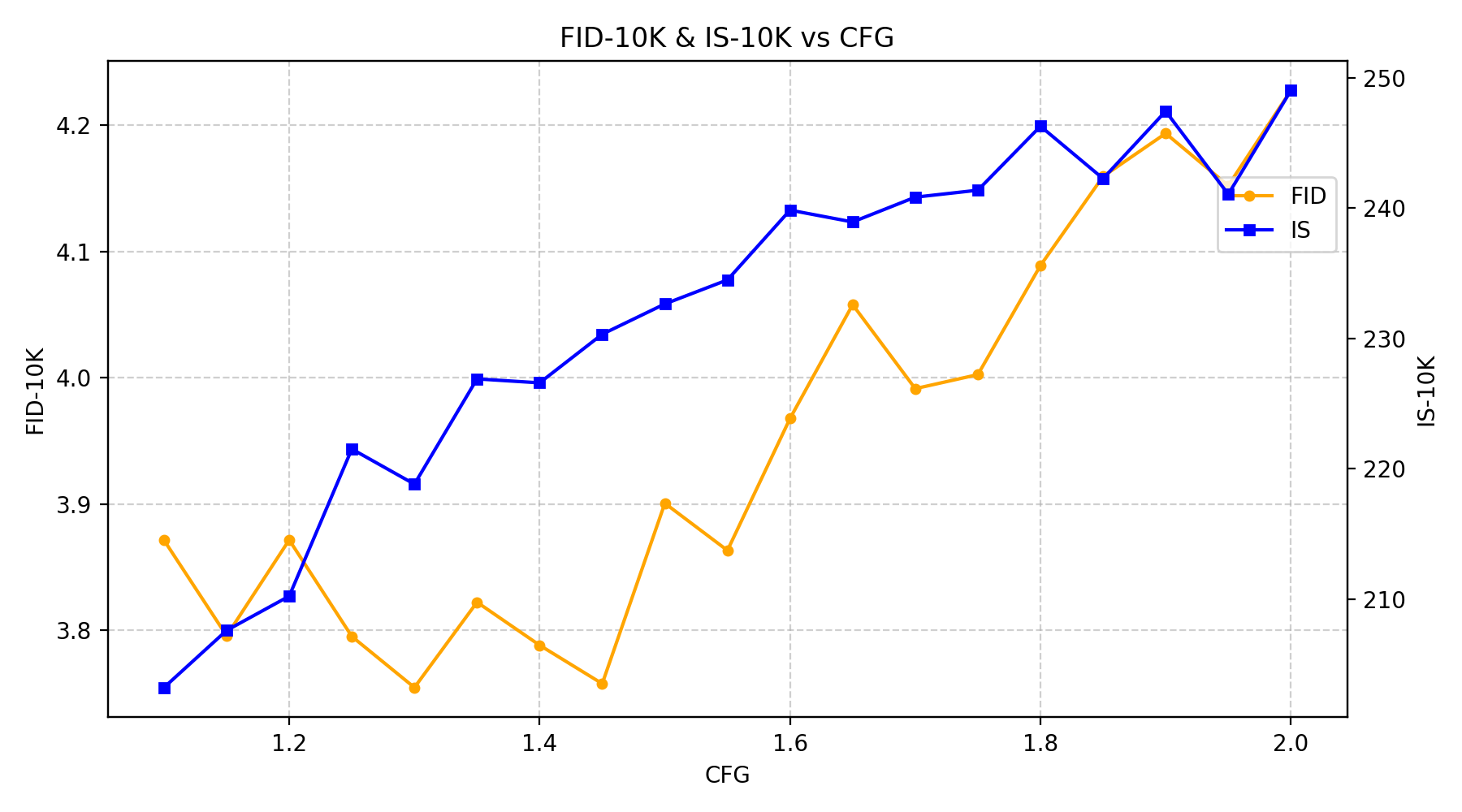
Figure 5: FID rapidly converges (left), scaling with parameter count and consistent improvements over epochs.
Qualitative Analysis
Class-conditional samples generated from RecTok-trained DiT models exhibit high-fidelity texture, color, and structure preservation, with the absence of typical artifacts prominent in high-compression or low-dimension regimes. Reconstructions faithfully capture fine object details, as illustrated by the inpainting and supplementary figures. RecTok’s outputs generalize across classes, indicating robust learned priors rather than mode collapse or overfitting.

Figure 6: High-quality ImageNet-1K generations, faithfully capturing class diversity and fine structure.


Figure 7: Input (left) and reconstructed (right) images demonstrate content fidelity and low distortion.
Theoretical and Practical Implications
The core insight is that semantic consistency across the full forward flow trajectory, rather than limited supervision at the origin of the flow, is essential for scalable tokenizers. This insight is formalized and validated by RecTok. The empirical claims—that increasing latent dimensionality no longer degrades generation or semantics—contradict the prevailing consensus in both the pixel-diffusion and latent-diffusion literature.
Practically, RecTok enables unified visual backbones for generation, editing, and understanding. The semantically consistent high-dimensional representation aligns the internal structure required for editing (where reconstruction fidelity is paramount) and class-conditional or open-ended generation (where expressiveness and diversity are necessary). This bridges the prior gap where low-dimensional latents were required for generation, but these same spaces were inadequate for representation-intensive tasks.
Theoretically, the study supports a deeper investigation into optimizing flow trajectories in generative models, particularly the induction of VFM-style semantics throughout the generative process. It also motivates further analysis of the interplay between KL regularization, reconstruction loss, and feature distillation at scale.
Future Directions
- Scaling latent dimensionality: With monotonic improvement observed up to 128 dimensions, it is plausible that even higher latent dimensionalities (subject to architecture and compute constraints) could enable direct application to high-resolution or video domains.
- Adaptive regularization: The results indicate that the balance between KL penalty and feature alignment is critical. Future work could explore adaptive or learned weighting for these signals, possibly leveraging task-driven or downstream feedback.
- Applications to unified multi-modal models: RecTok’s shared representation space is compatible with recent unified architectures (multimodal LLMs), enabling tokenization that equally supports synthesis and understanding.
- Further bridging with VFMs: Although RecTok narrows the gap, discriminative performance still lags behind frozen VFM backbones. Joint optimization, ensembling, or more sophisticated flow designs may close this gap.
Conclusion
RecTok establishes that high-dimensional, semantically-rich, and generatively robust visual tokenization is feasible and highly effective when semantic consistency is enforced along the rectified flow trajectory. This paradigm breaks the entrenched reconstruction-generation tradeoff, yielding state-of-the-art performance in both domains without sacrificing discriminative power. The methodology enables the practical unification of visual representation for editing, generation, and understanding in a single backbone and points toward further scaling and integration in future AI systems (2512.13421).