- The paper presents a framework using hierarchical token deduplication and expert swap that reduces AlltoAll communication by up to 3.32× and end-to-end training time by up to 1.27×.
- It leverages multi-level GPU interconnect topology to deduplicate redundant tokens and minimize transfers across low-bandwidth links.
- Empirical evaluations on 32-GPU clusters demonstrate stable iteration times and broad applicability for scaling large language models.
HierMoE: Accelerating Mixture-of-Experts Training via Hierarchical Token Deduplication and Expert Swap
Introduction and Motivation
Mixture-of-Experts (MoE) architectures have become a standard approach for scaling LLMs due to their sparse activation and sub-linear computational scaling with parameter count. In MoE, each layer consists of multiple feed-forward networks (experts), and a gating function dynamically routes tokens to a subset of these experts. Expert parallelism (EP) is required to distribute experts across multiple GPUs, but this introduces substantial communication overhead, primarily due to the AlltoAll collective required for token dispatch and result aggregation. Communication costs can account for 30–60% of total training time in large clusters, severely limiting scalability.
Existing optimizations, such as hierarchical AlltoAll algorithms (e.g., Tutel-2DH) and expert placement strategies (e.g., SmartMoE), do not fully exploit the hierarchical structure of GPU interconnects and often neglect the impact of token duplication and workload imbalance. HierMoE addresses these limitations by introducing topology-aware token deduplication and expert swap strategies, underpinned by theoretical performance models that generalize across hardware and model configurations.
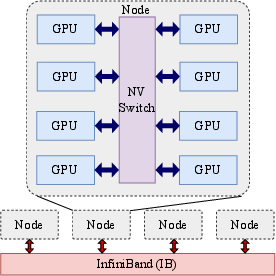
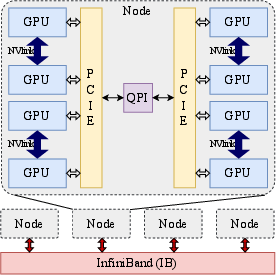
Figure 1: Two-level hierarchy of GPU interconnects, illustrating the hierarchical communication topology leveraged by HierMoE.
Hierarchical Token Deduplication
HierMoE introduces a multi-dimensional hierarchical AlltoAll algorithm with token deduplication (HierD-AlltoAll). The key insight is that when multiple experts reside on the same GPU, tokens routed to more than one local expert are redundantly transmitted, inflating communication volume. By deduplicating tokens at each hierarchical level (node, QPI, NVLink, PCIe), HierMoE minimizes redundant transfers, especially across low-bandwidth links.

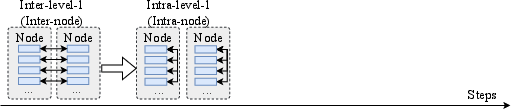
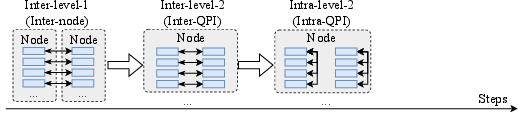
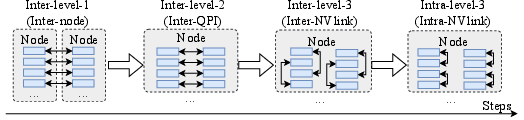
Figure 2: One-dimensional AlltoAll communication, representing the baseline case without topology awareness.
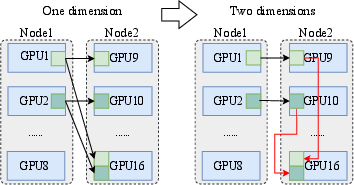
Figure 3: Illustration of token deduplication in hierarchical AlltoAll with 2 nodes and 16 GPUs, showing reduced inter-node communication.
The deduplication strategy is parameterized by the number of hierarchical dimensions D, the number of experts per group R, and the top-K selection per token. Empirical analysis demonstrates that higher K and lower R exacerbate duplication rates, making deduplication increasingly beneficial in modern MoE models.
HierMoE formulates a performance model for each hierarchical dimension, capturing startup and per-byte transmission costs (α, β) for each link type. The optimal dimension d∗ is selected by minimizing the total communication time, which is computed using the deduplicated token assignment for each expert group.
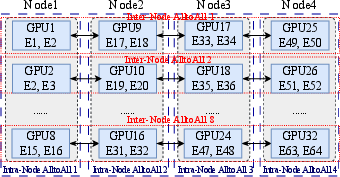
Figure 4: Experts and GPU indices for Inter-Node/Intra-Node AlltoAll, clarifying the mapping for deduplication.
Hierarchical Expert Swap
While deduplication reduces communication volume, workload imbalance across GPUs persists due to the stochastic nature of token routing. HierMoE introduces a hierarchical expert swap (HierD-ES) mechanism, which iteratively swaps expert placements to minimize communication overhead, considering both deduplication and hierarchical bandwidth constraints.
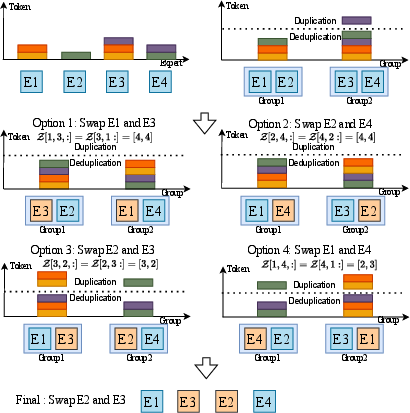
Figure 5: Strategy for expert swap, selecting the expert pair that minimizes communication overhead after deduplication.
The swap optimization is formalized as a search over all expert pairs, evaluating the estimated communication time post-swap using the deduplicated token assignment. To reduce computational complexity, HierMoE employs a case-based update strategy for token counts, leveraging the structure of token-expert assignments. A smooth-max function is used to stabilize the optimization landscape.
HierMoE is implemented atop Megatron-LM and evaluated on a 32-GPU cluster with DeepSeek-V3 and Qwen3-30B-A3B models. The system benchmarks include end-to-end training time and AlltoAll communication time, compared against Megatron-LM, Tutel-2DH, and SmartMoE.
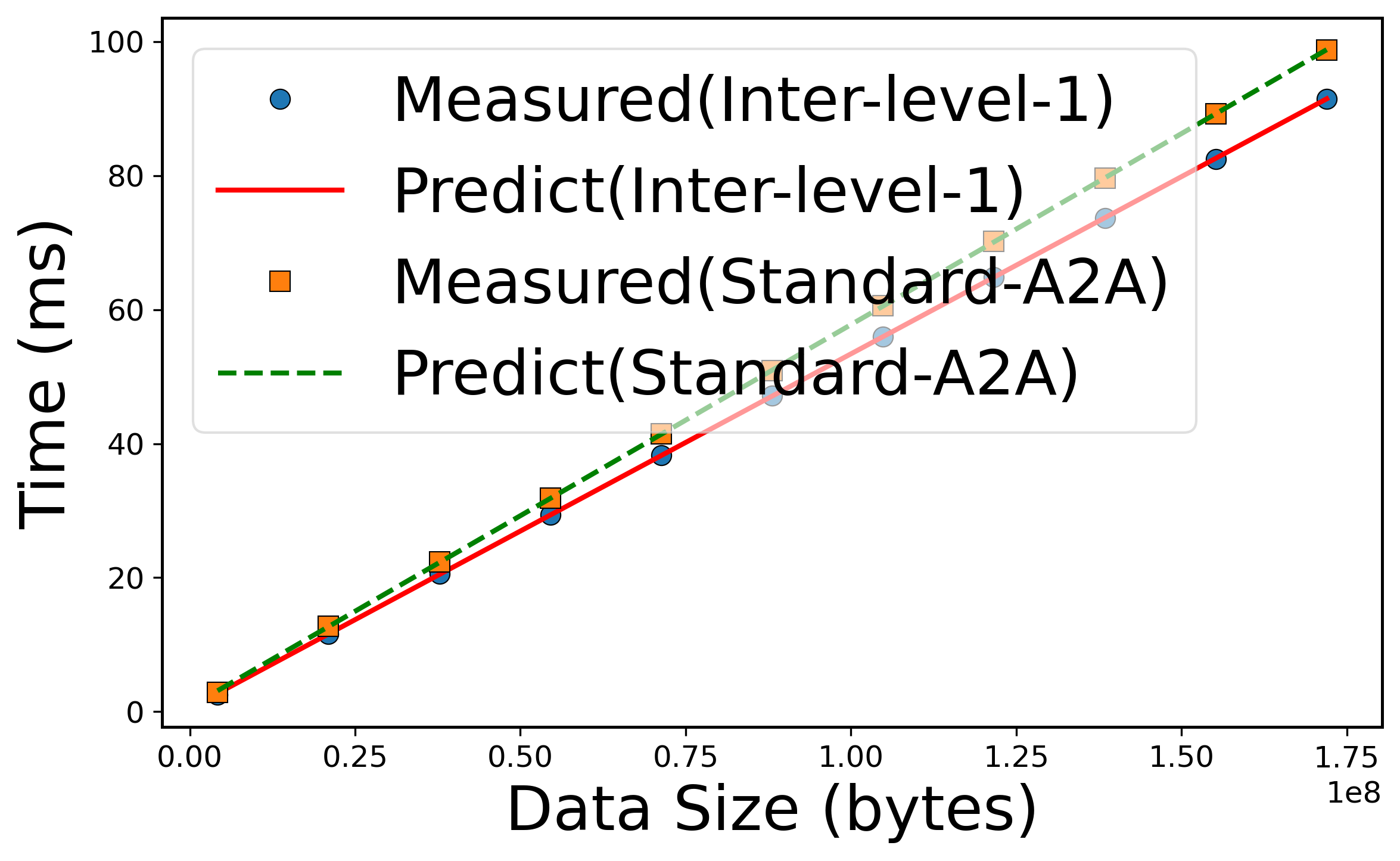
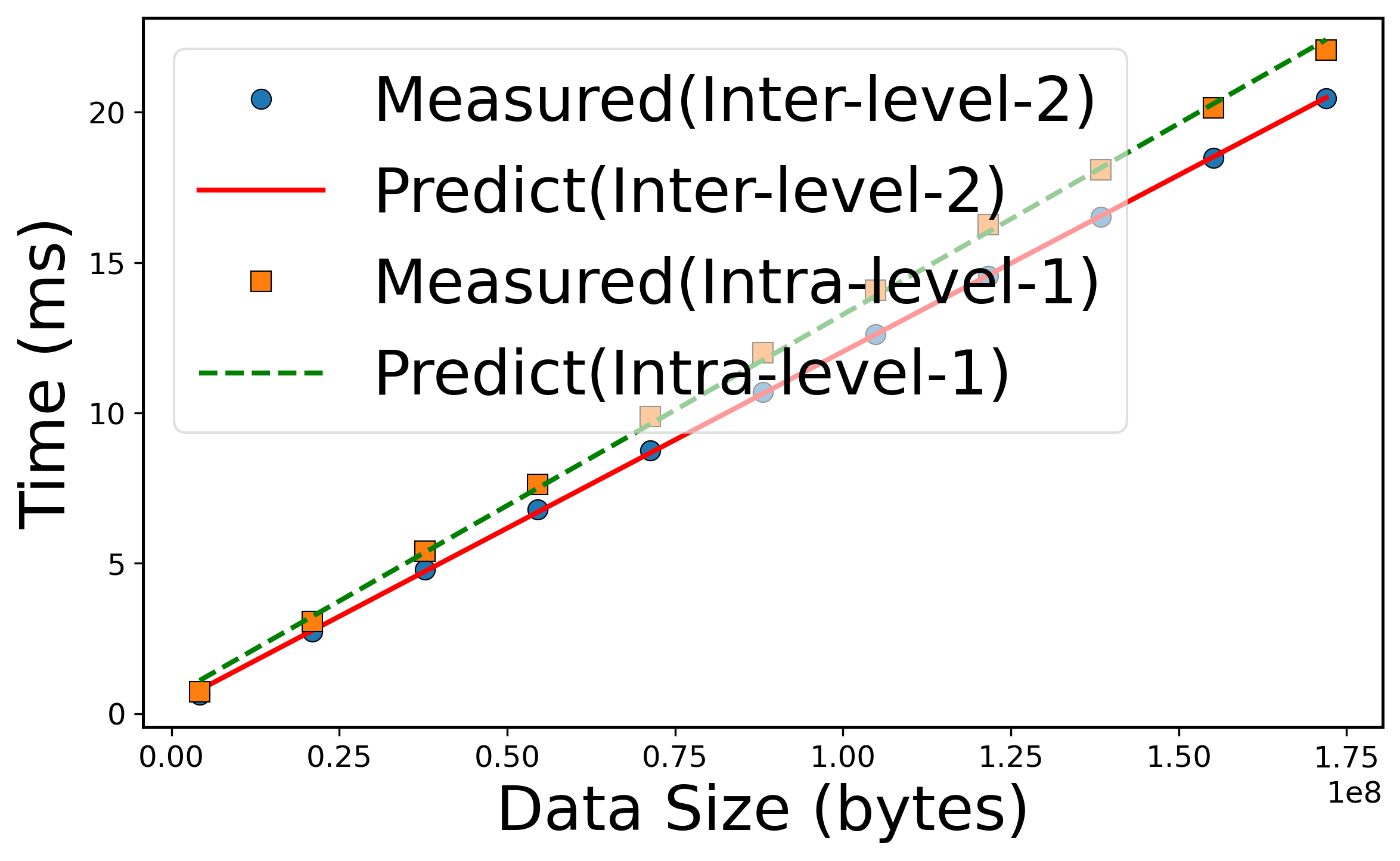
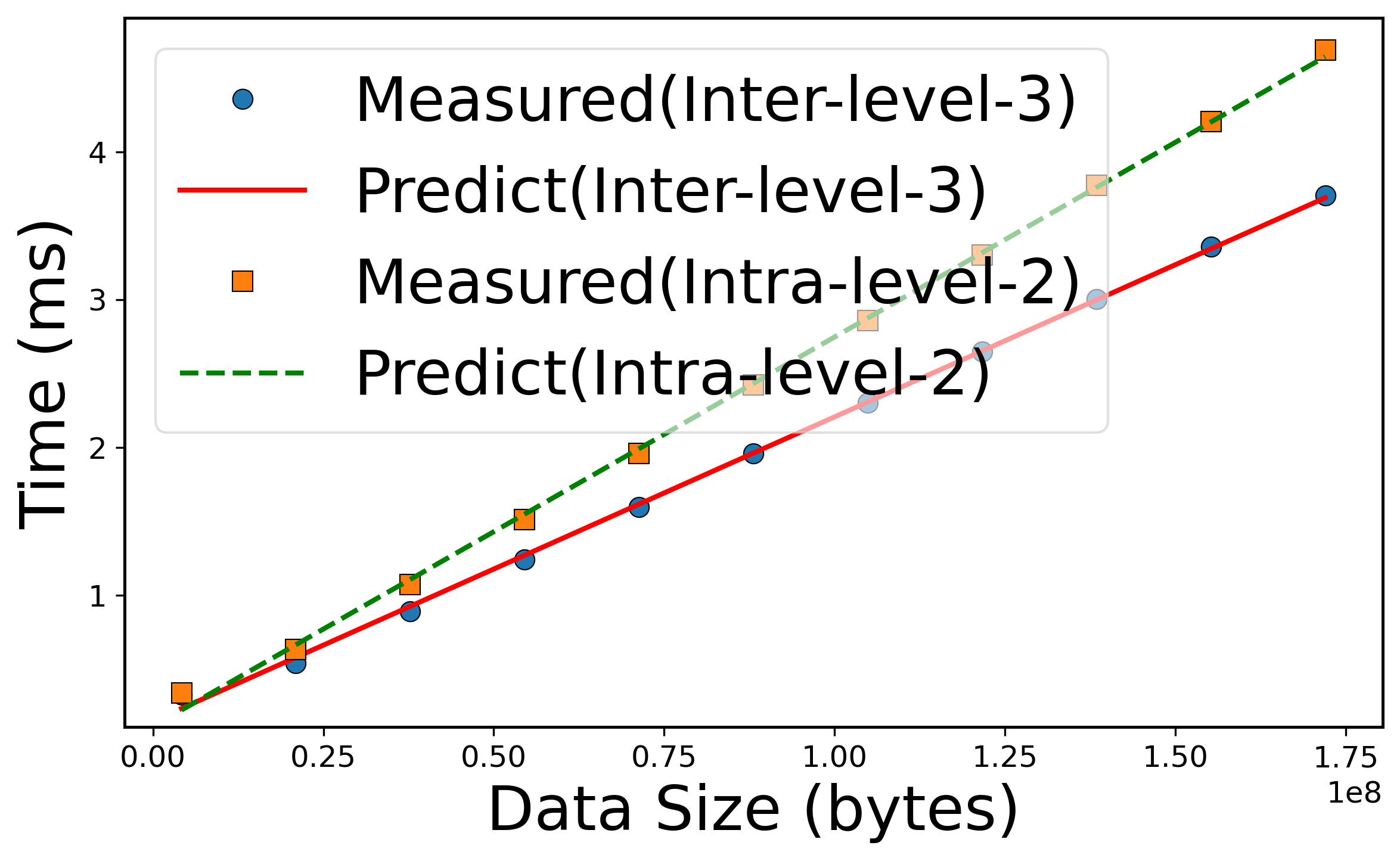
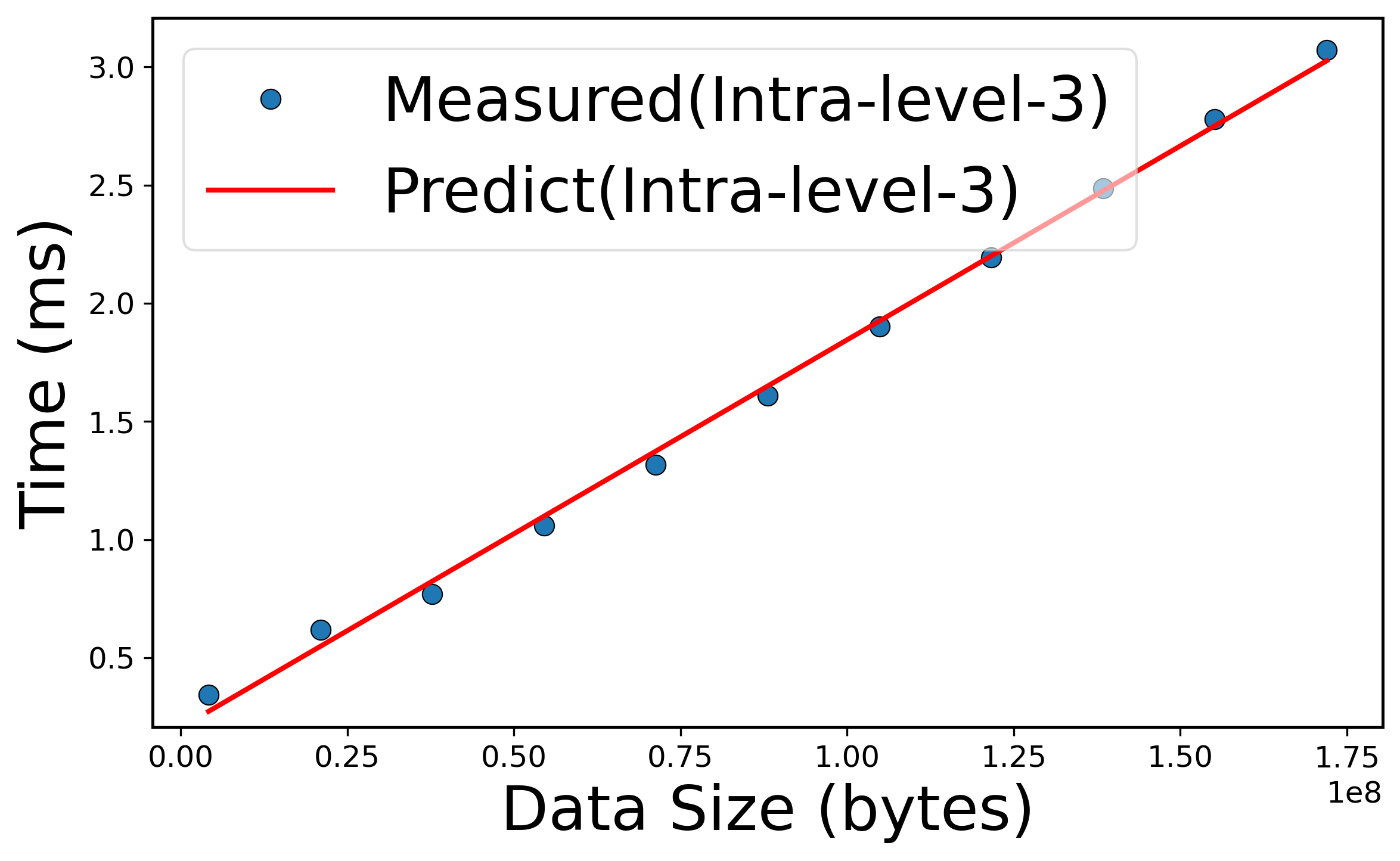
Figure 6: Performance models for AlltoAll communication, showing close fit between measured and predicted values for various hierarchical levels.
HierMoE achieves 1.55× to 3.32× faster AlltoAll communication and 1.18× to 1.27× faster end-to-end training compared to state-of-the-art baselines. Notably, Tutel-2DH underperforms relative to Megatron-LM in some configurations, while HierMoE consistently outperforms all baselines. Ablation studies confirm that deduplication and expert swap are both necessary for optimal performance; naive expert swap (HD2-MoE-Smart) can degrade performance due to increased duplication.
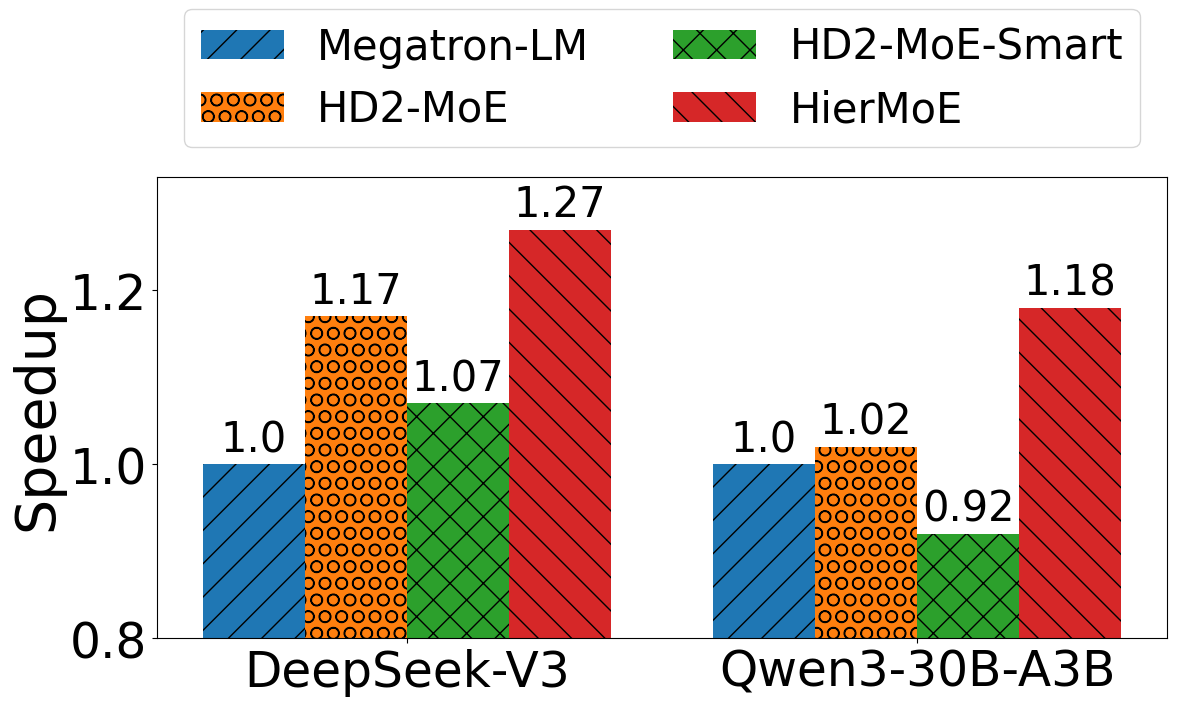
Figure 7: End-to-end speedup of HierMoE, HD2-MoE, and HD2-MoE-Smart over Megatron-LM on DeepSeek-V3 and Qwen3-30B-A3B.
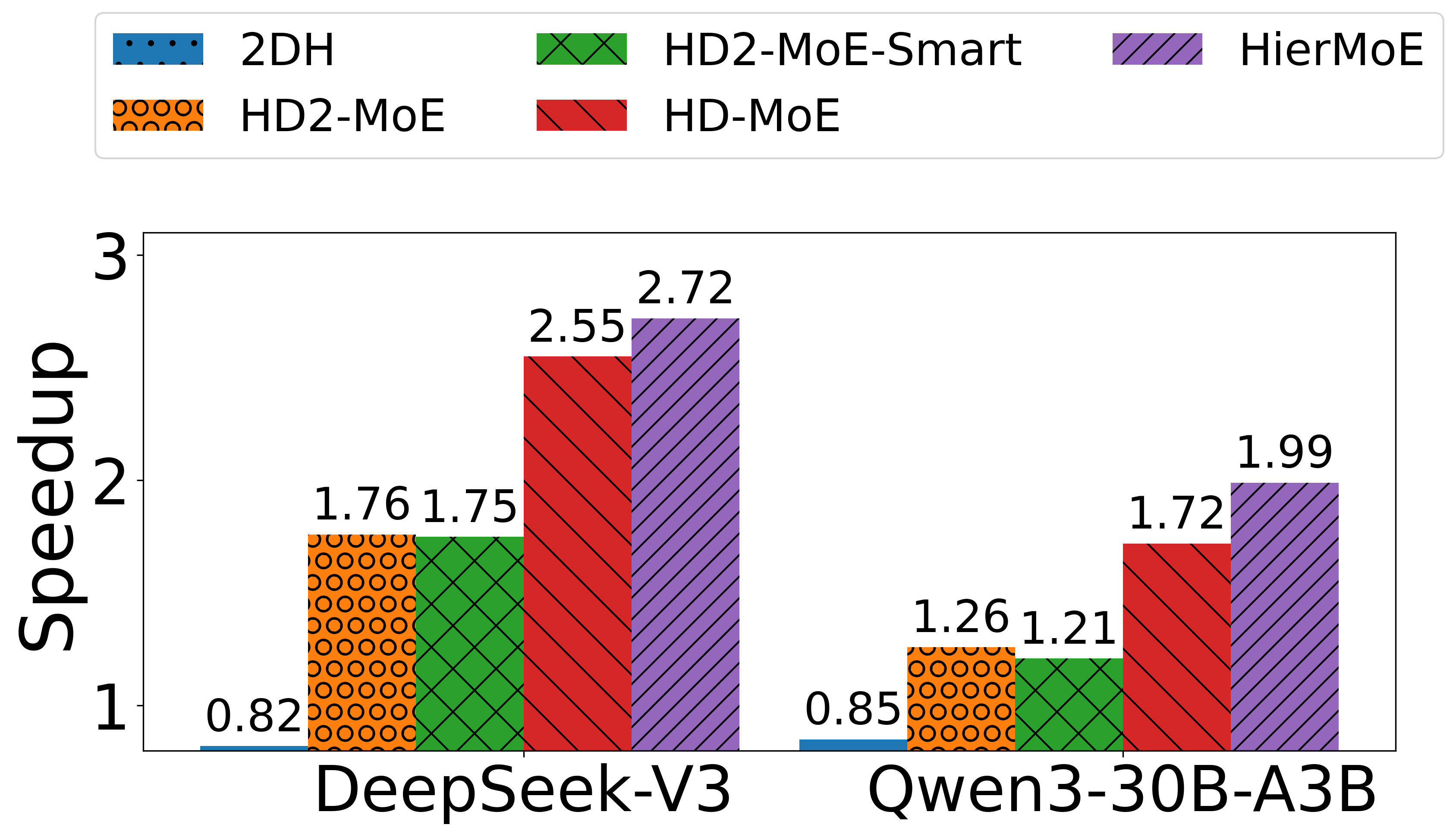
Figure 8: AlltoAll communication speedup of HierMoE and baselines over Megatron-LM.
HierMoE demonstrates stable iteration times and low sensitivity to the smooth-max parameter γ. The expert swap update frequency has a minor impact on overall performance, with higher frequencies yielding marginally better results.
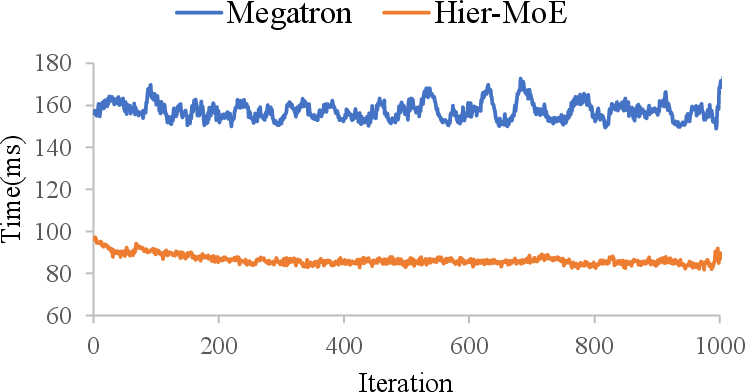
Figure 9: Smoothness of AlltoAll time curves for HierMoE and Megatron-LM across training iterations.
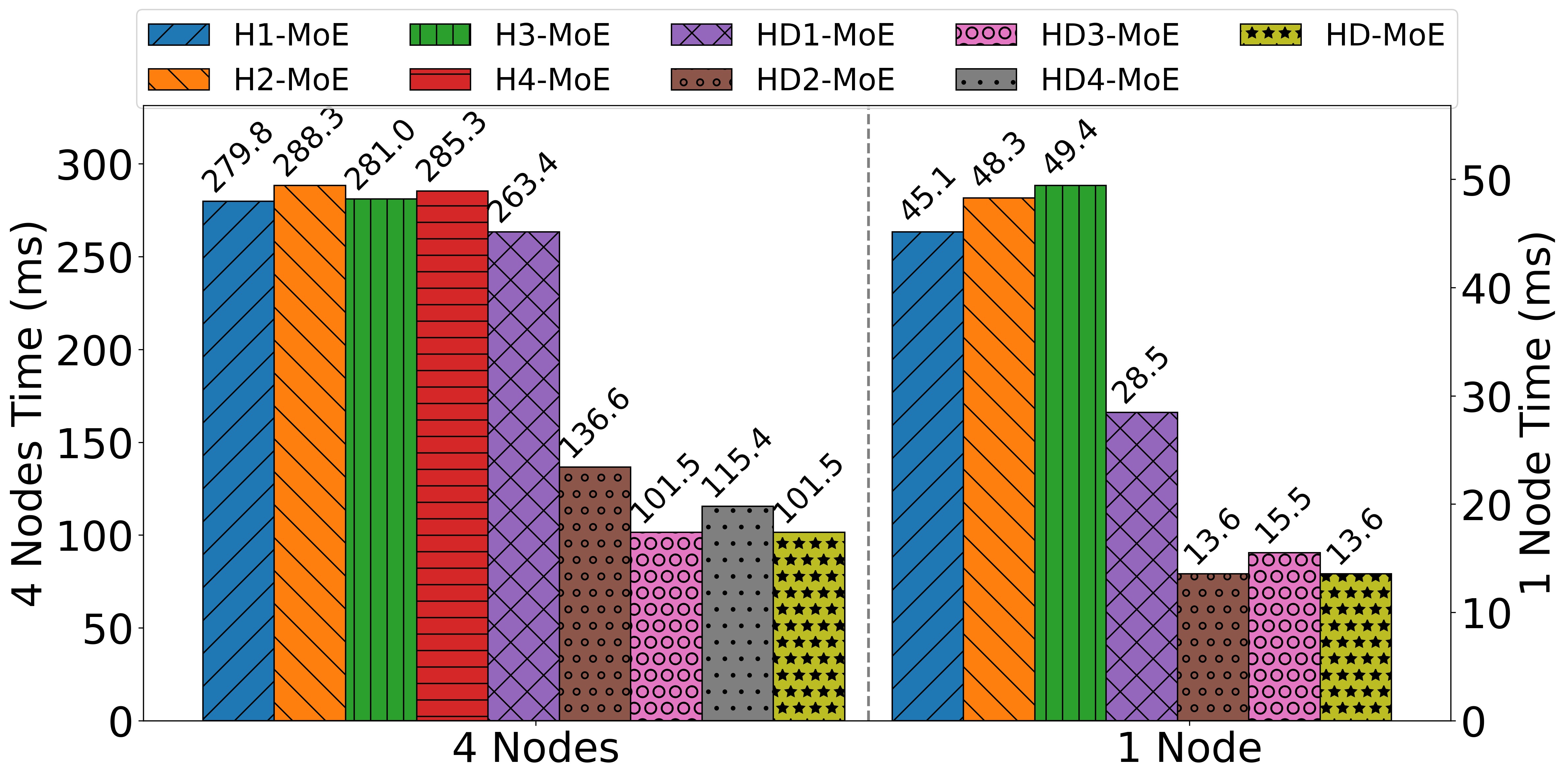
Figure 10: AlltoAll time cost for different hierarchical configurations on 4 nodes and 1 node, highlighting the impact of deduplication and optimal dimension selection.
Practical and Theoretical Implications
HierMoE provides a generalizable framework for optimizing MoE training in distributed environments with complex hierarchical interconnects. The theoretical models enable automatic adaptation to arbitrary hardware topologies and model configurations, facilitating deployment in heterogeneous clusters. The deduplication and expert swap strategies are compatible with existing MoE systems and can be integrated with further communication-computation overlap techniques.
The strong numerical results—up to 3.32× communication speedup and 1.27× end-to-end training speedup—demonstrate that communication bottlenecks in MoE training can be substantially mitigated without compromising model accuracy. This has direct implications for scaling LLMs to trillions of parameters and for efficient utilization of large GPU clusters.
Future Directions
Potential future work includes extending HierMoE to support dynamic topology changes, integrating with advanced scheduling and pipelining frameworks, and exploring its applicability to other sparse model architectures beyond MoE. Further research may investigate joint optimization of communication, computation, and memory placement, as well as hardware-aware expert routing functions.
Conclusion
HierMoE introduces hierarchical token deduplication and expert swap strategies, underpinned by rigorous performance modeling, to accelerate MoE training in distributed GPU clusters. The approach achieves significant reductions in communication overhead and overall training time, outperforming existing state-of-the-art systems. HierMoE's generality and strong empirical results position it as a robust solution for scalable sparse model training, with broad applicability to future large-scale AI systems.

