SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations
Abstract: Mixture of Experts (MoE) models have emerged as the de facto architecture for scaling up LLMs without significantly increasing the computational cost. Recent MoE models demonstrate a clear trend towards high expert granularity (smaller expert intermediate dimension) and higher sparsity (constant number of activated experts with higher number of total experts), which improve model quality per FLOP. However, fine-grained MoEs suffer from increased activation memory footprint and reduced hardware efficiency due to higher IO costs, while sparser MoEs suffer from wasted computations due to padding in Grouped GEMM kernels. In response, we propose a memory-efficient algorithm to compute the forward and backward passes of MoEs with minimal activation caching for the backward pass. We also design GPU kernels that overlap memory IO with computation benefiting all MoE architectures. Finally, we propose a novel "token rounding" method that minimizes the wasted compute due to padding in Grouped GEMM kernels. As a result, our method SonicMoE reduces activation memory by 45% and achieves a 1.86x compute throughput improvement on Hopper GPUs compared to ScatterMoE's BF16 MoE kernel for a fine-grained 7B MoE. Concretely, SonicMoE on 64 H100s achieves a training throughput of 213 billion tokens per day comparable to ScatterMoE's 225 billion tokens per day on 96 H100s for a 7B MoE model training with FSDP-2 using the lm-engine codebase. Under high MoE sparsity settings, our tile-aware token rounding algorithm yields an additional 1.16x speedup on kernel execution time compared to vanilla top-$K$ routing while maintaining similar downstream performance. We open-source all our kernels to enable faster MoE model training.



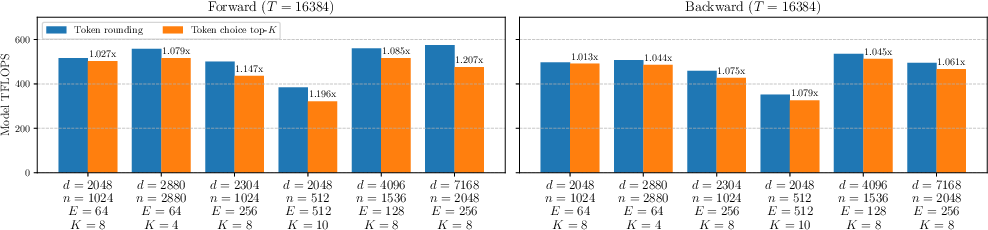

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SonicMoE: A simple explanation for young readers
1) What is this paper about?
This paper is about making a special kind of AI model, called a Mixture of Experts (MoE), run much faster and use less memory on modern GPUs. MoE models are powerful because they don’t use every “expert” (small sub-network) for every word or token—they only use a few, which saves compute. But as people build MoEs with more experts (and make each expert smaller), training them gets slower and more memory‑hungry because of data shuffling and other low-level costs. The authors introduce SonicMoE, a set of clever software and GPU tricks that make MoEs faster and more memory‑efficient, without hurting their accuracy.
2) What questions were the researchers trying to answer?
In everyday terms, they asked:
- How can we train MoE models that have many small experts (fine-grained) and only activate a few experts per token (sparse) without wasting time and memory?
- Can we reduce the extra “data moving” (called IO) that slows things down on GPUs?
- Can we avoid doing useless work caused by how GPUs prefer to compute in fixed blocks (tiles)?
- Can these improvements work on today’s top GPUs (like NVIDIA H100 and Blackwell) and keep the same quality?
3) How did they do it? (Methods explained with analogies)
Think of an MoE model like a hospital:
- Tokens (words) are patients.
- Experts are specialists (like cardiology, neurology, etc.).
- A router is the front desk that decides which specialists each patient should see.
- Training forward/backward passes are like doing a checkup and then reviewing what to improve.
SonicMoE speeds things up with three main ideas:
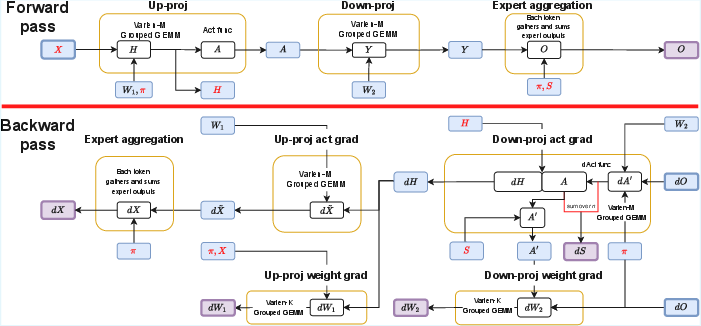
- Memory‑smart training (less “souvenir keeping”)
- Usual training keeps a lot of “snapshots” (activations) to reuse later during learning. SonicMoE carefully rearranges the math so it can throw away many of those snapshots and still compute all the needed gradients correctly.
- In practice, they avoid storing the biggest temporary data and only keep what’s absolutely necessary (like keeping just a patient’s essential records instead of the whole file), which shrinks memory use—especially when there are many experts.
- Overlapping data movement with computation (like multitasking)
- GPUs are fast at math but slow at moving data around. SonicMoE designs custom GPU kernels so that while some parts of the chip are moving data, other parts are already computing—like a kitchen where one cook preps ingredients while another cook is already cooking.
- They also “fuse” steps that usually happen separately (e.g., gathering tokens and multiplying matrices, or applying activations right after computing) to cut down on back‑and‑forth trips to memory.
- Tile‑aware token rounding (matching the GPU’s favorite block size)
- GPUs like to work in fixed block sizes called tiles (for example, groups of 128). If a group of tokens for an expert isn’t a neat multiple of the tile size, the GPU does extra “padding” work that doesn’t help the model.
- SonicMoE introduces “token rounding,” which slightly adjusts how many tokens each expert processes so it fits those tiles better—without changing token assignments much. Each expert’s token count changes by at most one tile, so it stays faithful to the original routing and preserves accuracy while saving wasted compute.
Along the way, they also:
- Combine gathering tokens with loading them to fast on‑chip memory (so there’s no separate slow “gather” step).
- Compute certain gradients in a smarter place (the “epilogue,” right after a matrix multiply), which reduces extra reads and writes.
- Target their design to modern GPUs (Hopper/H100 and Blackwell) to use their newest features.
4) What did they find, and why does it matter?
Here are the main results, in plain terms:
- Much less memory during training:
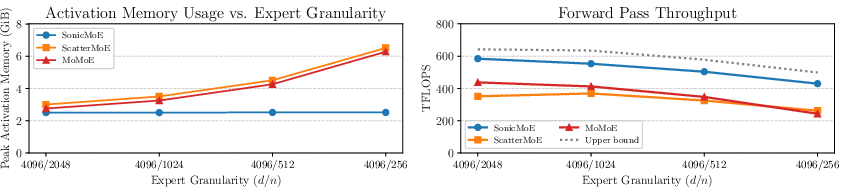
- SonicMoE reduces activation memory by up to 45% per layer for a fine‑grained 7B MoE. This is important because memory limits often cap how big and fast you can train.
- Much faster training throughput:
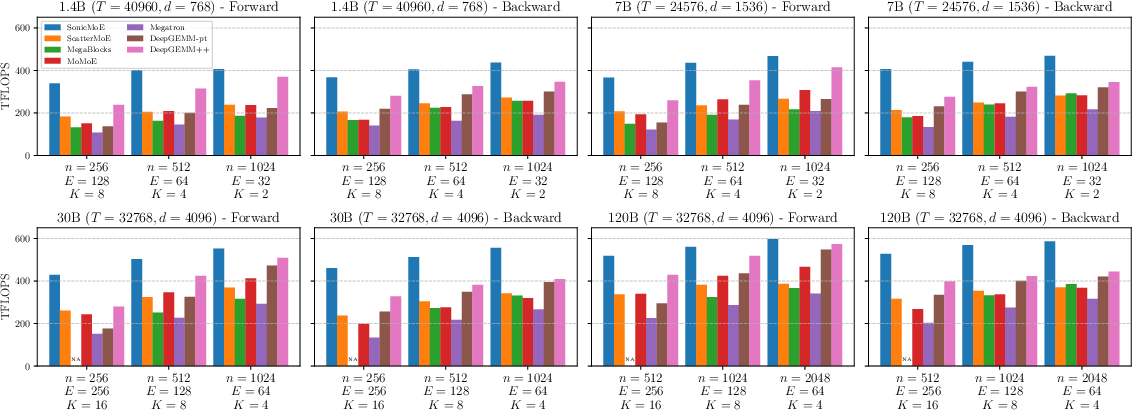
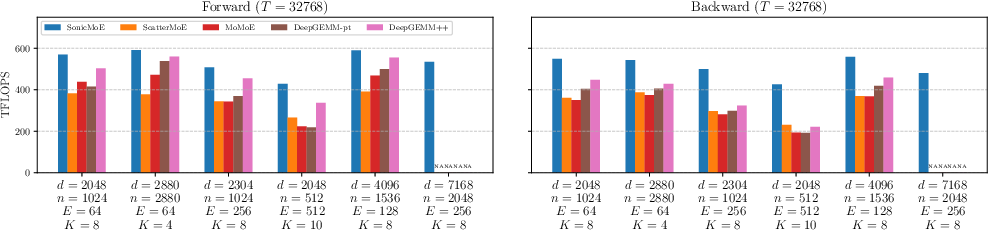
- On H100 GPUs, their kernels are up to 1.86× faster than a strong baseline (ScatterMoE) for the fine‑grained 7B model.
- In a real training setup, SonicMoE on 64 H100s reached about 213 billion tokens/day, close to a baseline that needed 96 H100s (225 billion tokens/day). In other words, same ballpark performance with fewer GPUs.
- Near the hardware’s speed limit in forward pass:
- Their forward computation reaches about 86–91% of an “upper bound” speed (a very optimistic reference using cuBLAS).
- Extra gains from tile‑aware token rounding:
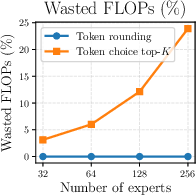
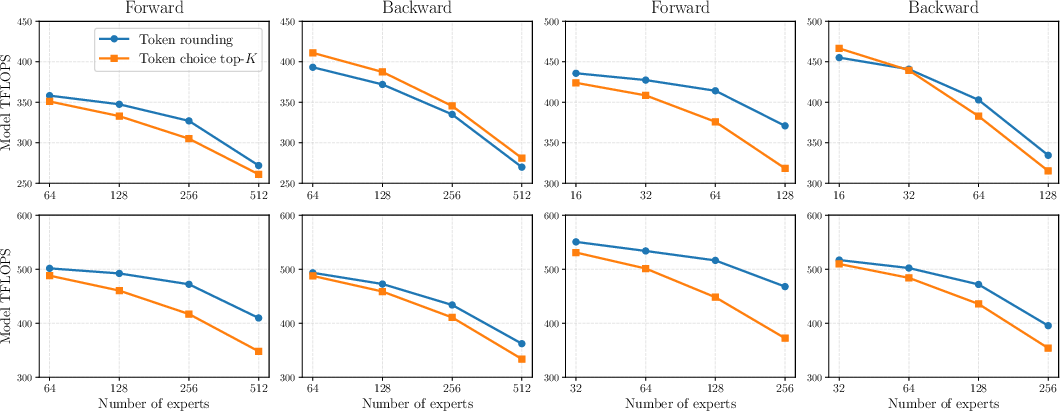
- When MoEs get very sparse (lots of experts, but only a few active per token), token rounding gives an additional speedup—up to about 16% more TFLOPS in highly sparse regimes and about 1.16× faster kernel time vs. standard top‑K routing—while keeping downstream performance similar.
Why this matters:
- Faster training means lower costs and quicker experimentation.
- Lower memory use allows bigger or more efficient models on the same hardware.
- These gains specifically target the direction MoEs are heading (more experts, fewer active), so they help future models too.
5) What’s the impact?
SonicMoE shows that smarter engineering—reducing saved activations, overlapping data movement with computation, and matching GPU tile sizes—can make modern MoE models train faster and cheaper without losing quality. This helps researchers and companies:
- Train larger, more efficient MoE models using the same or fewer GPUs.
- Keep pushing toward “fine‑grained” and “sparse” MoEs that give better quality per unit of compute.
- Use open‑source kernels (the authors released their code) to speed up community progress.
In short, SonicMoE helps turn the promise of MoE—doing more with less—into practical, real‑world speedups on today’s GPUs.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a focused list of concrete gaps the paper leaves open that future work can address:
- Blackwell evaluation: Provide end-to-end benchmarks, kernel-level breakdowns, and scaling studies on Blackwell GPUs (2-CTA clusters, relay-warp scheme) across tile sizes, cluster configurations, and precision modes.
- Precision coverage beyond BF16: Quantify performance and numerical stability for FP8/INT8 (including per-channel scaling, dequant in epilogue), and assess how gather fusion and epilogue fusion interact with low-precision formats.
- Token rounding at scale: Validate token rounding on larger models (e.g., 7B/30B/120B+), diverse datasets (multilingual, code, long-context), and training to convergence, including full downstream benchmarks.
- Load balance and EP interplay under token rounding: Measure how tile-aligned rounding affects expert load skew, all-to-all traffic, capacity factors, token dropping/rerouting, and auxiliary load-balancing losses in expert-parallel multi-node training.
- Behavior when per-expert token counts are below a tile: Design and evaluate policies for very sparse experts (e.g., stochastic rounding, microbatch accumulation, adaptive tile sizes) to avoid large assignment deviations when counts < tile size.
- Determinism and numeric robustness: Develop deterministic, high-accuracy alternatives (e.g., higher-precision accumulators, reproducible reductions) to enable atomic-free aggregation and removal of Y materialization without sacrificing determinism or accuracy.
- Router generality: Verify correctness/performance of the dS formulation and activation-caching strategy for routers beyond top-K token choice (e.g., top-P, null experts/skip experts, soft gating, EC with agreement losses), and for alternative expert types/activations.
- Routing metadata clarity and memory cost: Precisely specify what routing data is stored (indices only vs. full S vs. top-K gates), its memory footprint at large E (e.g., 256–512), compression/quantization schemes, and the bandwidth implications in backward.
- Distributed communication overlap: Evaluate compute–communication overlap for all-to-all/all-gather in expert parallelism, including sensitivity to routing skew and interconnect (NVLink vs. InfiniBand/Ethernet) and cross-node scaling efficiency.
- Inference performance: Report latency/throughput for prompt processing and autoregressive decoding at small batch sizes; assess whether gather fusion, eight-kernel structure, and token rounding help or hurt inference efficiency and quality.
- Auto-tuning and robustness: Provide autotuners for tile sizes, pipeline depth, warp scheduling (e.g., ping-pong warpgroups), and MMA shapes; quantify sensitivity across shapes, batch sizes, and model configs.
- Portability: Assess performance and support on A100/Ampere and non-NVIDIA backends (e.g., AMD ROCm); identify required adaptations when cp.async/TMA/WGMMA features differ.
- Router cost scaling: Quantify router (top-K/sort) runtime as E and K scale (e.g., E≥512), and assess approximate/top-k alternatives or fused router–dispatch designs to keep router overhead sublinear.
- Worst-case routing skew: Stress-test kernels under highly imbalanced routing and bursty token distributions; provide safeguards (e.g., adaptive capacity, smoothing) and measure degradation.
- Upper-bound realism: Replace the “cuBLAS upper bound” with a roofline that includes router, gather/aggregation IO, and epilogue fusion overheads to better contextualize 88–91% utilization claims.
- Interaction with memory-saving techniques: Study combined effects with activation checkpointing, ZeRO/offloading, tensor parallelism, and memory fragmentation; quantify real-world peak/fragmentation under large-scale training.
- Training convergence over long horizons: Report full training curves (loss, perplexity), final accuracy, and robustness across granularity/sparsity settings with token rounding, not just short-run or small-model snapshots.
- Workspace and allocator overhead: Detail and quantify costs for temporary buffers (Y, A′), index structures, and dynamic packing; propose allocators to reduce fragmentation and synchronization overhead.
- cp.async vs. TMA on Blackwell: Provide a principled comparison (throughput, latency, overhead of relay warp and cluster barriers), and switching heuristics between cp.async and TMA for gathered loads.
- Aggregation without Y materialization: Explore segmented reductions, warp-aggregated atomics, or on-chip accumulation strategies compatible with expert parallel all-to-all; characterize determinism/accuracy trade-offs.
- Heterogeneous experts: Extend grouped GEMM and tile-aware rounding to mixed-size or adaptive-width experts; analyze scheduling, padding, and accuracy/computation trade-offs.
- Small-batch and serving regimes: Characterize kernel launch overheads and occupancy at low T (e.g., interactive serving), and consider further fusions to reduce per-layer kernel count in latency-sensitive settings.
Practical Applications
Immediate Applications
Below are concrete, deployable uses derived from SonicMoE’s methods (activation-memory–minimal training, IO/computation overlap, and tile-aware token rounding). Each item notes sectors, potential tools/products/workflows, and key assumptions/dependencies.
- Cheaper, faster MoE training on Hopper-class GPUs
- Sectors: AI infrastructure, cloud, software
- What: Swap in SonicMoE kernels to accelerate training throughput (up to 1.86x vs. ScatterMoE kernels on H100) and reduce activation memory (~45%), enabling fewer GPUs per job or higher tokens/day (e.g., 213B tokens/day on 64×H100).
- Tools/workflows: Integrate SonicMoE (CuTe-DSL, PyTorch interface) with existing stacks (FSDP-2, lm-engine, Megatron-like pipelines); container images/AMIs for “SonicMoE-optimized” training.
- Assumptions/dependencies: Hopper GPUs (H100), CUDA toolchain, BF16/FP8 support as configured, top-K MoE with Grouped GEMM; largest benefits in fine-grained, high-sparsity regimes.
- Fit larger models, longer contexts, and/or larger batches on the same GPU budget
- Sectors: Enterprise R&D, startups, academia
- What: Use SonicMoE’s reduced activation footprint to increase per-GPU effective model size, sequence length, or batch size while keeping FLOPs fixed.
- Tools/workflows: Tuning FSDP configurations; memory-aware training recipes; static memory budgets per layer.
- Assumptions/dependencies: Routing metadata footprint stays negligible; training remains stable under new batch/sequence settings.
- Fine-grained and highly sparse MoE design exploration without throughput collapse
- Sectors: Model research, foundation model labs
- What: Explore higher expert granularity and larger E with constant K using SonicMoE’s IO-aware kernels and token rounding to mitigate tile padding waste.
- Tools/workflows: Parameter sweeps over (K/E/G) with hardware-aware routing; ablation dashboards for FLOPs/IO and routed-token distributions.
- Assumptions/dependencies: Token rounding preserves quality (validated at 1.4B; likely but not yet proven at larger scales); routing skew manageable.
- Cloud cost and capacity optimization for MoE workloads
- Sectors: Cloud providers, MLOps platforms
- What: Offer SonicMoE-optimized training SKUs; scheduling policies that use fewer H100s per job for the same tokens/day; improved cluster throughput per rack.
- Tools/workflows: Prebuilt Docker images; autoscaling templates; job admission rules using arithmetic-intensity/IO models.
- Assumptions/dependencies: Production validation on representative customer models; consistent driver/CUDA versions.
- MLOps observability for padding waste and IO bottlenecks
- Sectors: MLOps/software tooling
- What: Add telemetry for tile-alignment waste, arithmetic intensity, gather bandwidth, and epilogue fusion effectiveness; recommend token rounding or tile-size adjustments.
- Tools/workflows: Profiler plugins; CI checks for regression in tile utilization; automatic knobs for tile size and K/E.
- Assumptions/dependencies: Access to kernel-level counters or derived metrics; stable profiling interfaces.
- Faster domain-specific MoE finetuning with limited compute
- Sectors: Healthcare, finance, legal, manufacturing
- What: Train or finetune private MoEs on fewer GPUs without sacrificing wall-clock; accelerate iteration cycles for vertical models.
- Tools/workflows: Private-cloud or on-prem stacks using SonicMoE kernels; standard finetuning recipes (LoRA + MoE).
- Assumptions/dependencies: Data governance/privacy constraints; domain performance validated post-routing modifications.
- Energy and carbon savings per training run
- Sectors: Sustainability/ESG reporting, data centers
- What: Reduce total energy per token via less IO and fewer wasted FLOPs/padding; report energy-per-token gains for ESG disclosures.
- Tools/workflows: Energy metering dashboards; tokens/kWh KPI; procurement justifications for efficiency-focused kernels.
- Assumptions/dependencies: Accurate power telemetry; comparable model quality at new settings.
- Higher-throughput batched MoE inference on Hopper
- Sectors: Model serving platforms, SaaS
- What: Reuse SonicMoE’s forward expert aggregation and varlen-M Grouped GEMM to boost throughput for batched requests (especially in multi-turn assistants or batch scoring).
- Tools/workflows: Integration with high-throughput servers (e.g., vLLM-like); batching strategies that promote tile alignment.
- Assumptions/dependencies: Sufficient batch sizes to exploit tile utilization; limited gains for tiny batches or extreme decoding skew.
- Academic and educational adoption
- Sectors: Academia, education
- What: Use open-source SonicMoE kernels as a strong baseline for MoE systems research and teaching (co-design of kernels and architecture).
- Tools/workflows: Reproducible labs comparing ScatterMoE/MoMoE/MegaBlocks vs. SonicMoE; curriculum modules on IO-compute overlap.
- Assumptions/dependencies: Access to Hopper GPUs in academic clusters; consistent software environments.
- Hardware-vendor and library feedback loop
- Sectors: Semiconductors, compiler/runtime teams
- What: Use SonicMoE as a reference to refine CUTLASS/CuTe-DSL epilogues, WGMMA scheduling, gather pipelines, and cluster sync patterns.
- Tools/workflows: Microbench harnesses; issue trackers/PRs to vendor libraries.
- Assumptions/dependencies: Vendor engagement; forward-compatibility with Blackwell features.
Long-Term Applications
These uses require further research, integration, or hardware availability but are enabled by SonicMoE’s methods and results.
- Upstreaming into major frameworks and default MoE ops
- Sectors: AI software/frameworks
- What: Make SonicMoE-like kernels the default in PyTorch extensions, Megatron/DeepSpeed, and cloud training stacks.
- Dependencies: API stabilization, upstream reviews, wide hardware coverage (Hopper/Blackwell), CI across diverse models.
- Hardware-aware, learning-based routing beyond simple rounding
- Sectors: ML research, systems
- What: Train routers that explicitly optimize tile utilization, cluster bandwidth, and memory traffic under accuracy constraints (differentiable or RL-based).
- Dependencies: Robust accuracy guarantees at scale; convergence/regularization to avoid quality regressions.
- Generalization to other sparse architectures (PEER, Memory Layers, Ultra-Mem)
- Sectors: ML research, libraries
- What: Port IO/computation overlap and epilogue-fusion patterns to non-MoE sparse blocks with similar gather/aggregation idioms.
- Dependencies: Kernel refactors, mathematical equivalences for backprop, task-level validation.
- Deterministic, EP-friendly elimination of temporary intermediates
- Sectors: Systems research, hardware co-design
- What: Remove transient materializations (e.g., Y) with numerically safe atomics or new GPU primitives to keep determinism/precision and support expert-parallel communication overlaps.
- Dependencies: Hardware features (deterministic BF16 atomics), kernel design, EP all-to-all overlap.
- Multi-tenant MoE serving scheduler using tile alignment to reduce tail latency
- Sectors: Cloud serving, platform ops
- What: Admission control/batching that aligns token-to-expert counts to tile sizes across tenants to cut padding waste and p95/p99 latency.
- Dependencies: Integration with serving frameworks (e.g., vLLM), QoS policies, traffic-shaping.
- Blackwell-optimized production training at scale
- Sectors: AI infrastructure
- What: Mature the 2-CTA cluster gather pipeline and relay warp strategy; ship production-grade B100/B200 kernels once hardware is widely deployed.
- Dependencies: Broad Blackwell availability, CUDA/compiler maturity, ops hardening.
- Auto-tuners for K/E/G under cost/latency/energy constraints
- Sectors: MLOps, research tooling
- What: Use arithmetic-intensity and IO-cost models to pick expert granularity/sparsity, tile sizes, and routing hyperparameters for a given SLA and budget.
- Dependencies: Reliable cost models; automated search tied to real-time telemetry; model-quality tradeoff curves.
- Edge/on-device training and finetuning of small MoEs
- Sectors: Edge/embedded, robotics
- What: Leverage activation memory efficiency to bring modest MoE finetuning to edge accelerators or Grace-Hopper-class nodes near data sources.
- Dependencies: Smaller MoE designs; kernel ports to edge GPUs/NPUs; power/thermal constraints.
- Policy and standards for energy-efficient AI training
- Sectors: Policy, standards bodies
- What: Encourage reporting tokens/day per kWh; promote hardware-aware routing and IO-efficient kernels as best practices in grants/procurement.
- Dependencies: Community consensus on metrics; collaboration with data-center operators and research agencies.
- Vertical toolkits that bake in efficiency and compliance
- Sectors: Healthcare, finance, government
- What: Build turnkey MoE training/finetuning stacks integrating SonicMoE with domain data pipelines, governance, and audit trails to meet regulatory timelines at lower cost.
- Dependencies: Industry partnerships; validation on domain tasks; certification/compliance workflows.
Cross-cutting Assumptions and Dependencies
- Hardware availability and features: Most gains rely on Hopper/Blackwell capabilities (cp.async, WGMMA, cluster sync). Benefits on older GPUs may be smaller.
- Model/routing regimes: Largest acceleration appears in fine-grained, high-sparsity MoEs using Grouped GEMM. Gains diminish for coarse-grained MoEs or dense MLPs.
- Accuracy considerations: Token rounding preserves performance in 1.4B-scale experiments; large-scale validation (taller models, diverse tasks) is recommended before defaulting in mission-critical settings.
- Software stack stability: CUDA/CUTLASS/CuTe-DSL versions, PyTorch bindings, and EP communication libraries must align; CI is needed to keep kernels performant/deterministic.
- Serving vs. training: The paper targets training; inference gains are strongest in batched regimes and may be limited for small, highly skewed batches.
Glossary
- Activation memory footprint: The amount of GPU memory consumed by intermediate activations that must be stored for backward computation. "fine-grained MoEs suffer from increased activation memory footprint and reduced hardware efficiency due to higher IO costs"
- all-gather: A collective communication primitive that gathers data from all processes and makes it available to all. "incompatibility with expert parallelism all2all or all-gather communication"
- all2all: A collective communication operation where each process sends data to and receives data from every other process. "incompatibility with expert parallelism all2all or all-gather communication"
- Arithmetic intensity: The ratio of floating-point operations to memory traffic; indicates whether a kernel is compute-bound or memory-bound. "Arithmetic intensity, defined as the ratio of FLOPs over the number of transferred bytes (IO), is a metric to quantify whether a kernel is memory-bound (kernel runtime dominated by memory IO cost) or compute-bound (kernel runtime dominated by compute throughput)."
- Autoregressive decoding: Inference where each token is generated conditioned on all previously generated tokens; certain training-time routing methods are incompatible with it. "it is incompatible with autoregressive decoding"
- Auxiliary loss: An additional training objective used to encourage desired behavior, such as alignment between routing strategies. "introduce an auxiliary loss to promote the agreement between TC and EC routing results"
- BF16 (bfloat16): A 16-bit floating-point format with 8-bit exponent, commonly used to accelerate training while maintaining numerical range. "ScatterMoE's BF16 MoE kernel"
- Blackwell GPUs: NVIDIA’s GPU architecture succeeding Hopper, offering new features for memory and compute overlap. "a GPU kernel tailored to NVIDIA Blackwell and Hopper generation GPUs"
- BMM (batched matrix multiply): A library- or hardware-level operation performing many matrix multiplies in a batch. "cuBLAS BMM + activation + cuBLAS BMM + aggregation on H100"
- cp.async: An asynchronous copy instruction in NVIDIA GPUs used to move data from global to shared memory. "via Blackwell and Hopper's instruction"
- CTA (Cooperative Thread Array): A CUDA thread-block; building block of GPU kernel execution that can be organized into clusters. "2-CTA clusters"
- cuBLAS: NVIDIA’s high-performance CUDA library for dense linear algebra operations. "cuBLAS BMM + activation + cuBLAS BMM + aggregation on H100"
- CUTLASS: A CUDA C++ template library for GEMM and related operations optimized for NVIDIA GPUs. "This notation is adopted by CUTLASS~{nvidia_cutlass} which implements efficient GEMM on CUDA."
- CuTe-DSL: A domain-specific language for expressing high-performance CUDA kernels used in SonicMoE’s implementation. "mainly written in CuTe-DSL~{cutedsl} with a PyTorch interface"
- dSwiGLU: The backward (gradient) computation of the SwiGLU activation function. "that computes dSwiGLU and together."
- Epilogue: The final stage of a GEMM kernel where post-processing and writes to memory occur. "After the mainloop, we enter the epilogue stage where the consumer warpgroups apply post-processing (activation function and write results back to HBM) on the final MMA results."
- Expert activation ratio (K/E): The fraction of experts activated per token, defined as K (activated) out of E (total) experts. "Expert activation ratio ()"
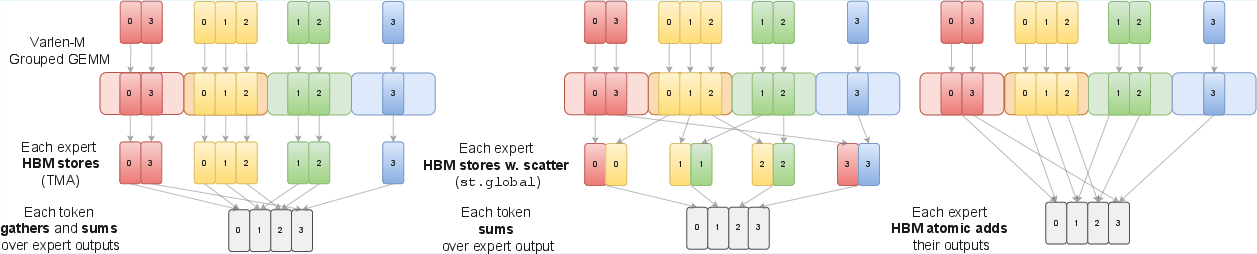
- Expert aggregation: The process of combining each token’s outputs from its selected experts back into the original token order. "Expert aggregation Kernel"
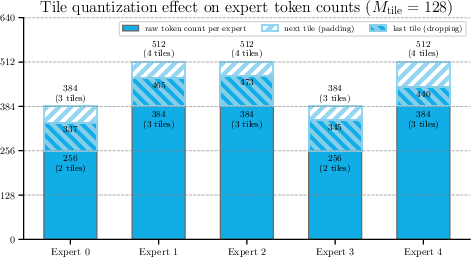
- Expert frequency: The number of tokens routed to a given expert in a batch. "rounds the number of received tokens per expert (``expert frequency'')"
- Expert granularity: The ratio between the model embedding dimension and each expert’s intermediate size; higher granularity means smaller experts relative to the embedding. "high expert granularity (smaller expert intermediate dimension)"
- Expert parallelism: A parallel training strategy that distributes experts across devices for efficiency and scale. "incompatibility with expert parallelism all2all or all-gather communication"
- FSDP-2: A variant of Fully Sharded Data Parallelism for memory-efficient distributed training. "training with FSDP-2 using the lm-engine codebase"
- GEMM (general matrix multiply): A core linear algebra operation computing C = A×B, central to neural network layers. "A GEMM (general matrix multiply)~{Blas} kernel often has 3 stages: prologue (start input loading), mainloop (keep loading inputs and compute GEMM) and epilogue"
- GMEM (global memory): The off-chip device memory (often HBM) addressable by all threads on the GPU. "from High Bandwidth Memory (HBM), or global memory (GMEM) logically, to shared memory (SMEM)"
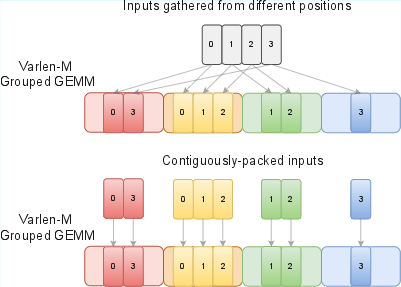
- Grouped GEMM: A batched set of matrix multiplies over multiple experts, potentially with varying dimensions. "MoE computation often requires a Grouped GEMM."
- HBM (High Bandwidth Memory): High-throughput on-package memory used by modern GPUs. "High Bandwidth Memory (HBM)"
- Hopper GPUs: NVIDIA’s GPU architecture preceding Blackwell, introducing WGMMA and advanced asynchronous pipelines. "On NVIDIA Hopper GPUs, GEMM is performed asynchronously with a producer-consumer paradigm"
- IO (Input/Output): Data movement to and from memory; often the bottleneck in fine-grained/sparse MoE kernels. "increased IO cost"
- Mainloop: The central iteration of a GEMM kernel where tiles are repeatedly loaded and multiplied. "mainloop (keep loading inputs and compute GEMM)"
- mbarrier: A GPU synchronization primitive (memory barrier) with cluster scope used for coordinating CTAs. "e.g., mbarrier with cluster scope"
- MMA (matrix multiply-accumulate): The fused operation performed by Tensor Cores that computes and accumulates partial matrix products. "Hopper GPUs provide a high-throughput WGMMA instruction for MMA"
- MoE (Mixture of Experts): An architecture that activates a small subset of specialized sub-networks (“experts”) per token for efficiency. "Mixture of Experts (MoE) models have emerged as the de facto architecture for scaling up LLMs without significantly increasing the computational cost."
- Null experts: Special routing targets that effectively skip expert computation to adjust compute dynamically. "use ``null experts'' to dynamically adjust the number of activated experts."
- Prologue: The initial stage of a GEMM kernel where inputs are prepared and loaded. "prologue (start input loading)"
- Producer-consumer paradigm: An execution model where dedicated producer warps load data while consumer warps perform compute, enabling overlap. "GEMM is performed asynchronously with a producer-consumer paradigm"
- SMEM (shared memory): On-chip memory shared within a thread block, used as a fast staging area for GEMM tiles. "to shared memory (SMEM)"
- SwiGLU: A gated activation function variant used in transformer MLPs; SonicMoE fuses its forward/backward with epilogues. "We fuse the SwiGLU and backward of SwiGLU with the epilogue of forward up-proj and backward down-proj activation gradient kernel respectively"
- Tensor Cores: Specialized GPU units providing high-throughput matrix multiply-accumulate operations. "Modern GPUs support Tensor Cores; specialized hardware units with high matrix multiplication throughput"
- Tile quantization effects: Inefficiencies due to padding inputs to align with fixed GEMM tile sizes, causing wasted FLOPs. "wasted computations due to tile quantization effects of grouped GEMM"
- Tile size: The hardware-aligned dimensions of submatrices used in tiled GEMM; aligning token counts to these reduces padding waste. "rounds the per-expert token counts to multiples of the tile size (e.g., 128) used by grouped GEMM"
- TMA (Tensor Memory Accelerator): A hardware-assisted mechanism on newer NVIDIA GPUs for efficient memory transfers to shared memory. "The gather on dim would require 1D TMA load"
- Token choice (TC) routing: A routing strategy where each token independently selects its top-scoring experts. "Token choice (TC) routing where each token independently selects the activated expert"
- Token rounding: A tile-aware routing method that rounds per-expert token counts to reduce padding waste in Grouped GEMM. "we propose a novel ``token rounding'' method that minimizes the wasted compute due to padding in Grouped GEMM kernels"
- Top-K routing: Selecting the K highest-scoring experts per token during routing. "vanilla top- routing"
- varlen-K Grouped GEMM: A Grouped GEMM where the reduction (token) dimension varies across experts during weight-gradient computation. "which we refer to as ``varlen- Grouped GEMM''."
- varlen-M Grouped GEMM: A Grouped GEMM where the token (row) dimension varies across experts during forward/activation-gradient computation. "We refer to this Grouped GEMM as ``varlen- Grouped GEMM''."
- Warp: The basic scheduling unit on NVIDIA GPUs, comprising 32 threads executed in lockstep. "A warp is the basic execution unit on an NVIDIA GPU."
- Warpgroup: A set of four contiguous warps (128 threads) that collectively issue WGMMA operations on Hopper. "A warpgroup in Hopper GEMM consists of 4 contiguous warps (128 threads)."
- WGMMA: A warpgroup-level matrix multiply-accumulate instruction introduced on NVIDIA Hopper for high-throughput GEMM. "Hopper GPUs provide a high-throughput WGMMA instruction for MMA"
Collections
Sign up for free to add this paper to one or more collections.

