Learning Next Action Predictors from Human-Computer Interaction
Abstract: Truly proactive AI systems must anticipate what we will do next. This foresight demands far richer information than the sparse signals we type into our prompts -- it demands reasoning over the entire context of what we see and do. We formalize this as next action prediction (NAP): given a sequence of a user's multimodal interactions with a computer (screenshots, clicks, sensor data), predict that user's next action. Progress on this task requires both new data and modeling approaches. To scale data, we annotate longitudinal, naturalistic computer use with vision-LLMs. We release an open-source pipeline for performing this labeling on private infrastructure, and label over 360K actions across one month of continuous phone usage from 20 users, amounting to 1,800 hours of screen time. We then introduce LongNAP, a user model that combines parametric and in-context learning to reason over long interaction histories. LongNAP is trained via policy gradient methods to generate user-specific reasoning traces given some context; retrieve relevant traces from a library of past traces; and then apply retrieved traces in-context to predict future actions. Using an LLM-as-judge evaluation metric (0-1 similarity to ground truth), LongNAP significantly outperforms supervised finetuning and prompted baselines on held-out data (by 79% and 39% respectively). Additionally, LongNAP generalizes to held out users when trained across individuals. The space of next actions a user might take at any moment is unbounded, spanning thousands of possible outcomes. Despite this, 17.1% of LongNAP's predicted trajectories are well-aligned with what a user does next (LLM-judge score $\geq$ 0.5). This rises to 26% when we filter to highly confident predictions. In sum, we argue that learning from the full context of user behavior to anticipate user needs is now a viable task with substantial opportunity.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper is about teaching computers to be proactive helpers. Instead of waiting for you to type a prompt, the system tries to guess what you’ll do next on your phone or computer—like a smart friend who watches what’s on your screen and predicts your next step. The authors call this task Next Action Prediction (NAP).
To make this work, they:
- Collected natural “screen life” data (screenshots and taps/clicks) from real people over a month.
- Built a tool to label what people were doing in those screenshots.
- Designed a new AI model, called LongNAP, that learns from your long-term habits to predict your next actions.
What are the key questions?
The paper focuses on two big questions:
- How can we collect and label enough real-life device use data to train a system that predicts what people will do next?
- How can we build a model that uses everything it knows—what’s on the screen now and what’s happened in the past—to make better predictions?
How did they do it?
Collecting and labeling real-life data (NAPsack)
The team built an open-source pipeline called NAPsack that runs on private, secure computers. Think of NAPsack like a diary-keeper for your device use:
- It takes screenshots when you interact (like tapping, clicking, scrolling) so it only saves important moments, not every second. This cuts storage by about 75%.
- It groups nearby actions together and feeds short chunks of screenshots (and, when available, input events like key presses) to a vision-LLM—an AI that can “read” images and write captions. The AI turns raw screenshots into simple action descriptions like “Opened Gmail and clicked on a new message.”
They tested different ways to label the data and found:
- Breaking long sessions into short chunks strongly improved label quality.
- Saving only frames where the user interacted kept quality while saving lots of space.
- Adding input events (like key presses) made labels much more accurate.
Using NAPsack, they annotated a large, real-world dataset:
- 20 users
- 28 days
- About 1.9 million screenshots
- Around 1,800 hours of screen-on time
- About 360,000 action labels
The prediction model (LongNAP)
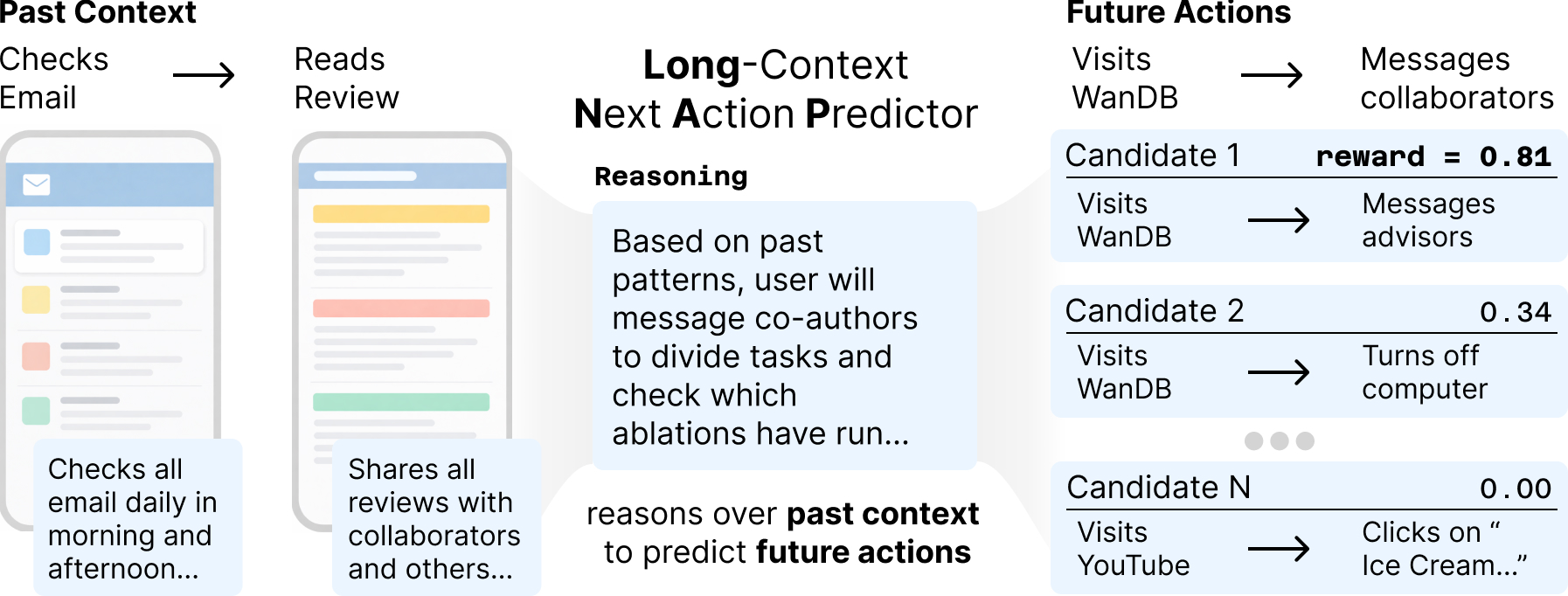
LongNAP is the model that makes the predictions. It uses a two-step “think like a person” process:
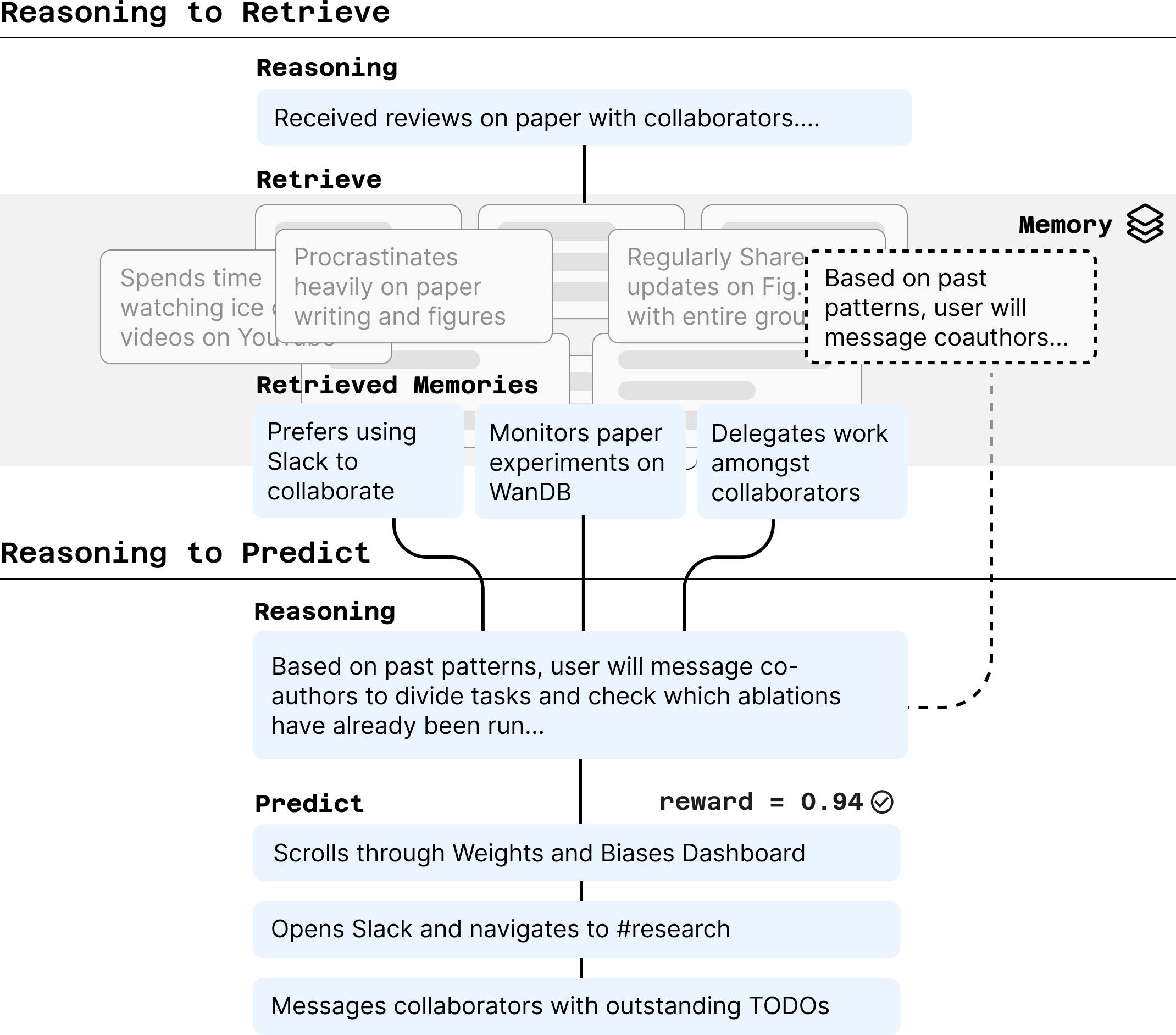
- Reason to Retrieve:
- The model looks at what you’ve just been doing and writes a short “note to self” about what might be happening and what could come next.
- It uses that note to search a memory bank of past situations and past “notes to self.”
- Example: If you just opened an email with tough feedback on a paper, the model might retrieve a past note that says “This user often messages co-authors on Slack to split up tasks.”
- Reason to Predict:
- The model combines the current context and the retrieved notes to write a refined “note to self,” then predicts the next actions (like “Open Slack → Go to #research → Message teammates about revisions”).
- The best reasoning notes get saved back into memory to help with future predictions.
You can think of this like a student who:
- Writes a quick plan,
- Looks through old class notes for similar problems,
- Updates the plan, and
- Solves the problem better with the help of past examples.
How they graded the predictions
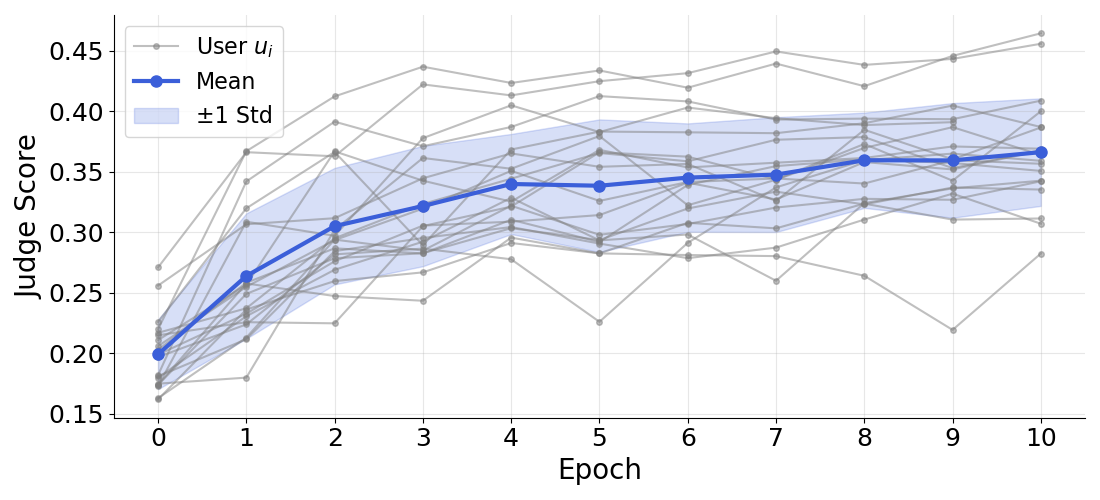
Because they collected real, time-ordered data, the team could simply wait and see what the user actually did next. Then they used another AI (an “LLM judge”) to score how similar the model’s predicted actions were to the real actions. The score goes from 0 (not similar at all) to 1 (very similar). This automatic scoring let them train the model with trial-and-error: good predictions get higher “rewards,” and the model learns from that.
What did they find?
- The LongNAP model beat several strong alternatives:
- Compared to a model fine-tuned the usual way, LongNAP did 79% better.
- Compared to prompt-based methods (like zero-shot or few-shot prompting), LongNAP did 39% better on average.
- It worked best when trained for a specific person, but it also showed promising results when trained on many people and tested on new users (about 13% better than the strongest prompted baseline in that setting).
- Predicting people’s next actions is hard because there are many possible next steps. Even so:
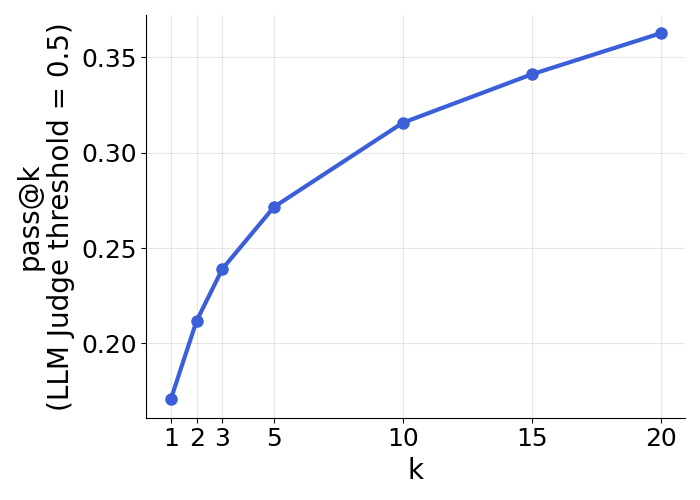
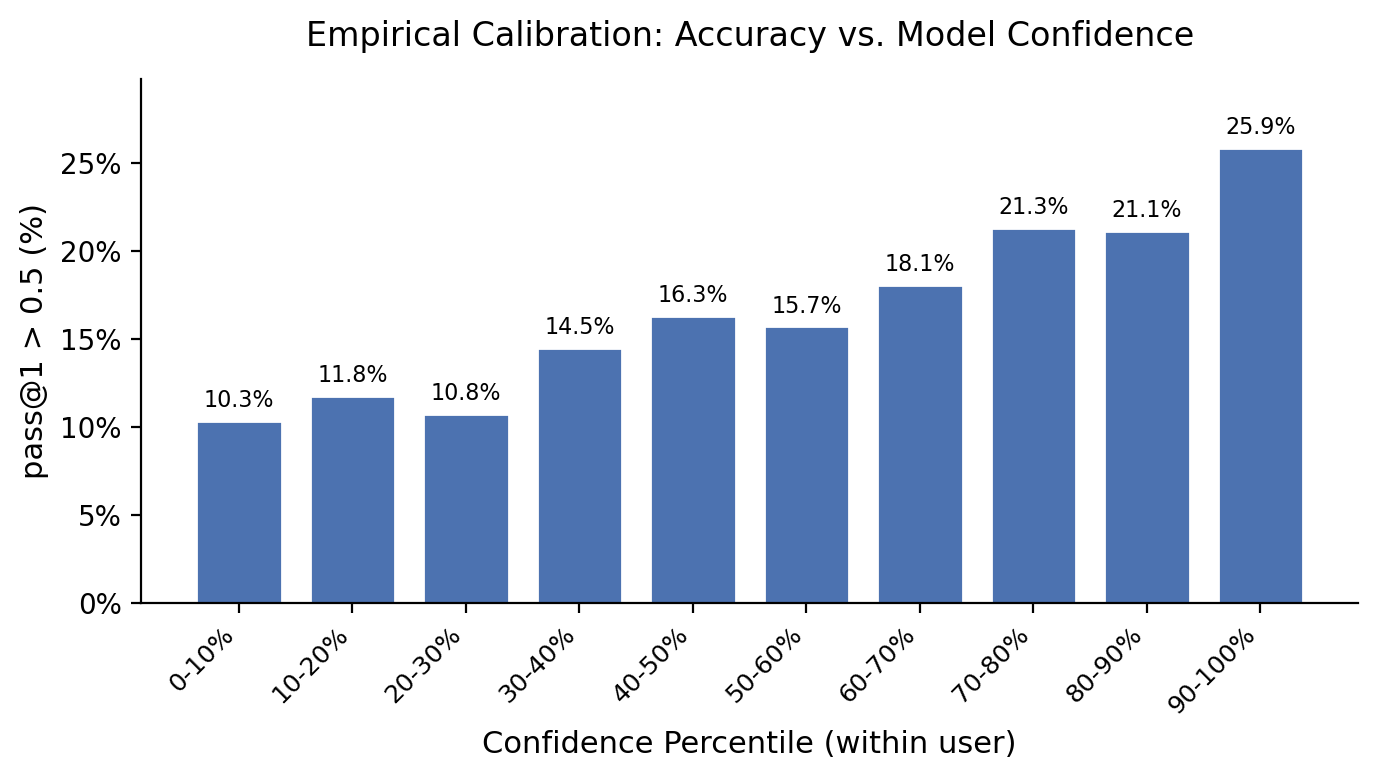
- About 17% of the time, LongNAP’s first guess was well-aligned with what the user actually did next (judge score ≥ 0.5).
- When the model was “most confident” (its multiple guesses agreed with each other), accuracy rose to about 26%.
- If you let the model make multiple guesses, the chance that at least one is a good match goes up (for example, about 36% at 20 guesses).
Why does this matter?
If computers can understand what you’re doing and what you’ll probably do next, they can help proactively, not just reactively. That could mean:
- Surfacing the right files or apps at the right moment,
- Suggesting the next step in a task,
- Preparing information before you ask,
- Or coordinating with your tools (email, chat, dashboards) to save you time.
The paper also shows that it’s possible to build and train such systems while keeping data private by running the collection and labeling pipeline on secure, user-controlled systems.
Final takeaways and impact
- Main idea: Predicting the next thing you’ll do on your device is now practical by learning from your full context—what’s on the screen and what you did before—not just from typed prompts.
- Key tools:
- NAPsack: a way to collect and label natural device use efficiently and privately.
- LongNAP: a model that thinks in two steps—retrieve helpful memories, then make a refined prediction.
- Why it’s important: This is a step toward proactive, personalized AI assistants that feel helpful without you having to spell out every request.
- What to watch next:
- Handling privacy carefully (the data is sensitive).
- Reducing label noise further.
- Scaling to more users and devices.
- Making predictions even more accurate and useful in real time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
Data and labeling
- Limited population and representativeness: only 20 users, one month, mobile screenshots from 2021; unclear generalizability across demographics, cultures, languages, device types (iOS vs Android), desktop OSes, and app ecosystems that change over time.
- Label noise from VLM-generated captions: no large-scale, blinded human audit of Screenomics-derived labels; no per-domain error analysis (e.g., small-font OCR failures, UI ambiguity, dark mode, non-English content).
- Input modality mismatch: NAPsack evaluation uses PC sessions with I/O, while the main dataset lacks I/O; the impact of missing keystrokes/clicks/scrolls on label quality and prediction accuracy is not quantified.
- Lack of public benchmark: privacy prevents dataset release; there is no synthetic or de-identified benchmark that preserves task difficulty to enable reproducible comparisons.
- Compression choices untested at scale: no analysis of hash-based compression vs event-driven approaches on recall/precision of meaningful frames in long, noisy mobile traces.
- Sparse/absent modalities: no use of accessible structured OS logs, notification text, calendar metadata, or sensor streams (e.g., time-of-day, location) that could disambiguate intent.
- Action granularity control: no systematic study of how action abstraction levels (low-level UI steps vs task-level intents) affect label quality, model training, and downstream predictability.
Modeling and methodology
- Retrieval design under-explored: BM25 lexical retrieval over model-generated text ignores visual content and semantics; no comparison to dense retrievers (multimodal embeddings, cross-encoders), hybrid retrieval, or learned retrievers trained end-to-end.
- Memory scaling and hygiene: unbounded memory growth, error accumulation from storing model-generated reasoning, and lack of deduplication/summarization/aging policies are not studied; no safeguards against self-reinforcing hallucinations.
- Fixed horizons and context: no exploration of different (context length), (prediction horizon), variable-length prediction, or hierarchical temporal modeling (short/medium/long-term forecasting).
- Stage and component ablations missing: no quantification of contributions from reasoning-to-retrieve vs plain retrieval, memory vs no memory, CoT vs no-CoT, RL vs SFT, retriever dropout, or masking strategies.
- Model capacity limits: primary results use a 7B VLM; no tests with stronger open or closed models (e.g., InternVL, Qwen2-VL-72B, GPT-4o/Claude) to establish a performance ceiling or isolate benefits attributable to architecture vs capacity.
- Credit assignment in RL: unclear how rewards propagate across retrieval and prediction phases; no analysis of variance, instability, or sensitivity to GRPO group size, temperature, or LoRA settings.
- Continual learning and drift: no protocols for online adaptation to behavioral change, catastrophic forgetting tests, or evaluation under non-stationarity across months/years.
- Confidence and abstention: confidence is proxied by embedding variance but not calibrated; no selective prediction/abstention strategies, risk-aware objectives, or thresholds optimized for different costs of false positives/negatives.
- Out-of-domain behavior: no detection or handling of rare/novel activities, app updates, or unseen UI layouts; robustness to OOD events is untested.
Evaluation and metrics
- LLM-as-judge dependence: reward/evaluation relies on a single judge (Gemini 3.0 Flash); no sensitivity analysis to judge choice/prompting, calibration curves, inter-judge agreement, or failure modes (reward hacking, style over substance).
- Limited human validation: small-scale, author-annotated preference tests; no large, blinded, third-party human study with inter-rater reliability or task-specific criteria (e.g., exact app, page, and ordering correctness).
- Coarse outcome measure: similarity scores lack decomposed sub-metrics (exact action match, ordering, intent match, UI target match); no per-category breakdown (communication, shopping, banking) to identify where models succeed/fail.
- pass@k interpretability: no analysis of how temperature, sampling strategy, or k affects accuracy vs latency; no AUC/ROC or calibration for the 0.5 similarity threshold.
- Baseline coverage: no comparisons to simple but strong sequence models (Markov models, HMMs, Hawkes processes, n-gram click models), classical personalization (RNNs/LSTMs/Transformers without CoT), or modern agentic baselines with memory/RAG.
- Causality and ground truth: ground truth actions are VLM-labeled screenshots, not verified low-level UI events; no alignment between predicted natural-language actions and actual clicks/keystrokes/app transitions.
- Generalization scaling laws: cross-user generalization gains are modest; no scaling experiments vs number/diversity of users, or analyses of user-level predictability factors (routine strength, app entropy).
Privacy, safety, and ethics
- Privacy-preserving learning: no experiments with on-device inference, federated learning, secure aggregation, or differential privacy; memory encryption, access control, and right-to-be-forgotten procedures are unspecified.
- Third-party exposure: screenshots can capture bystanders’ data (messages, emails, bank info); no redaction pipeline evaluation or PII leakage audits for both training and memory retrieval.
- Misuse risks: no red-teaming or policy guidance to prevent surveillance/monitoring use cases (employers, stalkers), or to mitigate sensitive attribute inference.
- Transparency and control: users’ ability to inspect, edit, or delete memory traces and explanations is not evaluated; no study on acceptability, consent UX, or trust calibration.
Deployment and systems
- On-device feasibility: compute, memory, battery, and latency for continual capture, retrieval, and VLM inference are not measured; no edge-accelerated or streaming designs for real-time prediction.
- Memory/retrieval costs: indexing, storage footprint, and lookup latency at month/year scale are unreported; no benchmarks for different memory management policies under resource constraints.
- Integration with assistants/agents: no experiments with proactive interventions, user-in-the-loop correction, or effect on task success and satisfaction; triggers for when to act vs remain silent are undefined.
Reproducibility and openness
- Limited reproducibility: core dataset is private; training code/configs, seeds, and compute budget are not fully detailed for independent replication; training variance across multiple runs is not reported.
- Benchmark standardization: no released proxy tasks, simulators, or de-identified logs to allow apples-to-apples evaluation of NAP methods and LLM-judge setups.
Task design and analysis
- Action taxonomy: no standardized schema linking natural-language actions to UI primitives; mapping ambiguity hampers metric precision and agent execution.
- Error analysis: lacks qualitative/quantitative breakdowns of common failure modes (e.g., misreading small UI elements, confusing similar apps, misordering steps) to guide targeted improvements.
- Domain adaptation: no exploration of app-specific adapters, UI parsers, or OCR fine-tuning to improve performance on high-value domains (e.g., productivity, finance, health).
Practical Applications
Immediate Applications
Below are practical use cases that can be prototyped or deployed now using the paper’s methods (NAPsack for passive labeling; LongNAP-style retrieval-and-reasoning; LLM-as-judge rewards) with available models and hardware.
- Proactive command palettes and next-step recommendations in productivity apps — Software/Productivity
- Description: Surface “likely next actions” (e.g., open doc, switch tab, paste from clipboard, message team) based on a user’s recent screenshots and actions.
- Tools/workflows: In-app side panel in IDEs, browsers, office suites; a predictive command palette that ranks shortcuts/macros; cross-app launcher suggestions.
- Assumptions/dependencies: On-device VLM inference or secure backend; screenshot and input-event permissions; per-user adaptation requires recent history; UI affordances for suggestions (not auto-execution) for safety.
- Intelligent RPA macro discovery and suggestion — Enterprise IT, RPA/Automation, Customer Support
- Description: Mine repeated action sequences from natural work and suggest one-click macros or automations (e.g., “after ticket triage, open CRM, prefill fields”).
- Tools/workflows: NAPsack for passive labeling of employee desktops; LongNAP/RAG for predicting repeated flows; macro recorder seeded by predicted next steps.
- Assumptions/dependencies: Strong privacy/consent; sand-boxed logs; heterogeneity of apps across roles; model confidence gating to avoid erroneous automations.
- Context-aware notification triage and batching — Mobile/OS, Productivity, Daily Life
- Description: Predict whether a user is about to attend to email, chat, calendar, etc., and prioritize or defer notifications accordingly.
- Tools/workflows: OS-level notification scheduler using recent event window; “focus mode” trigger based on predicted trajectory; user-facing controls.
- Assumptions/dependencies: OS APIs for notification control; user consent for passive capture; light-weight on-device inference for latency.
- Adaptive accessibility shortcuts — Accessibility/Assistive Tech
- Description: For users with motor or cognitive impairments, suggest or pre-stage the next interface element/action (e.g., keyboard shortcut, zoom target).
- Tools/workflows: Screen reader integration that announces “next likely action”; overlay buttons for predicted targets; reduced-click macro suggestions.
- Assumptions/dependencies: Accessibility APIs; high-precision UI element detection (VLM quality on screenshots); strong opt-in and on-device processing.
- Prefetching and resource warming — Web/Cloud, Software
- Description: Prefetch the next likely webpage, dashboard, or dataset to reduce perceived latency (e.g., preloading dashboards after email review).
- Tools/workflows: Browser extensions/Service Workers that fetch likely next URLs; caching dashboards or model artifacts in ML ops UIs.
- Assumptions/dependencies: Network/bandwidth constraints; mispredictions cost; careful privacy (don’t prefetch sensitive endpoints inadvertently).
- Customer support agent copilot — Enterprise/Contact Centers
- Description: On agent desktops, predict the next tool or knowledge article based on the current CRM view and chat context; prepare forms or snippets.
- Tools/workflows: Desktop overlay with predicted actions; one-click navigation and form prefill; knowledge-base retrieval seeded by predicted trajectory.
- Assumptions/dependencies: Screen access within VDI environments; integration with CRM/KB; compliance and auditing requirements.
- Semantic evaluation for UI agents and workflow models — Academia, AI/ML, Software
- Description: Use the LLM-as-judge similarity metric to train/evaluate computer-use agents with rewards that reflect trajectory-level intent alignment.
- Tools/workflows: Replace brittle lexical metrics with LLM-judged pass@k; apply to RL fine-tuning for UI agents; benchmark longitudinal predictions.
- Assumptions/dependencies: Cost and stability of LLM judges; prompt calibration and bias checks; periodic human audits.
- Privacy-preserving behavior analytics for UX research — Industry UX, Academia (HCI)
- Description: Generate action-level labels from naturalistic usage to analyze funnels, friction points, and emergent behaviors without manual annotation.
- Tools/workflows: NAPsack on secure, private infrastructure; anonymized aggregation; dashboards of predicted task sequences and drop-offs.
- Assumptions/dependencies: IRB/ethics or internal review; de-identification; robust secure storage; mitigations for labeling noise.
- Personal knowledge/activities timeline with predictive journaling — Daily Life, PKM
- Description: Build a private activity timeline that groups actions into tasks and suggests likely next todos (e.g., “follow up with X on Slack”).
- Tools/workflows: Local app that indexes screenshots and actions; predicted next-step suggestions; optional integration with notes and task managers.
- Assumptions/dependencies: Local storage and encryption; efficient on-device VLM; clear deletion/export controls.
- Security anomaly flagging (behavioral deviation alerts) — Cybersecurity/IT
- Description: Flag sessions where actual actions diverge materially from predicted patterns (possible account takeover or policy violation).
- Tools/workflows: Compare predicted vs. actual trajectories; alert thresholds for high-severity deviations; SOC dashboard integration.
- Assumptions/dependencies: Careful thresholding to reduce false positives; privacy-preserving deployment; role-based baselines to avoid bias.
Long-Term Applications
These use cases require further research, scaling, and/or ecosystem changes (e.g., OS APIs, regulation, robust on-device VLMs) to reach reliable deployment.
- Truly proactive, cross-app personal agents — Software/OS, Consumer Productivity
- Description: Agents that prepare workspaces, draft messages, or execute multi-step tasks unprompted when confidence is high and policies allow.
- Tools/products: OS-level “Personal LongNAP” with memory of reasoning traces; policy engine for auto-execution vs. suggestion; explainable trace viewer.
- Dependencies: High-precision predictions with calibrated uncertainty; robust safety, undo, and consent flows; standardized cross-app automation APIs.
- Clinician workstation copilots that preload orders and docs — Healthcare IT
- Description: Anticipate next steps in EHR workflows (e.g., open relevant labs, preload order sets) based on patient context and clinician patterns.
- Tools/products: EHR-integrated predictive panels; pre-drafted notes/orders; proactive alerts for missing steps in care pathways.
- Dependencies: Integration with EHR vendors; clinical validation and safety; HIPAA-compliant on-prem inference; bias and fairness evaluation.
- Adaptive learning environments that anticipate study actions — EdTech
- Description: Predict a learner’s next study step and dynamically structure content and tools (e.g., suggest switching to practice, open references).
- Tools/products: LMS plugins with predictive sequencing; context-aware hinting and resource prefetching; student model memory for learned patterns.
- Dependencies: Privacy-safe telemetry; per-student adaptation with consent; pedagogical efficacy trials; guardrails against over-reliance.
- Trading/ops dashboards with proactive setup and guardrails — Finance/Operations
- Description: Pre-stage analytical views, prefill tickets, and predict routine follow-on actions in trading, risk, or IT ops consoles; detect deviation.
- Tools/products: Predictive command trays in Bloomberg-like terminals; automated runbook step suggestions; variance-based anomaly triggers.
- Dependencies: Strict compliance and audit; low-latency, on-prem inference; robust backtesting and human-in-the-loop supervision.
- Team-level “workflow digital twins” — Enterprise Analytics, Process Engineering
- Description: Aggregate (opt-in) predictions across roles to model end-to-end processes, identify bottlenecks, and auto-suggest process improvements.
- Tools/products: Process mining augmented with NAP-based action semantics; simulation sandboxes; automation opportunity discovery.
- Dependencies: Strong anonymization; labor/union considerations; governance for fair use; variance across roles and teams.
- Context-aware browsers and OS UIs that reconfigure proactively — Platforms/OS
- Description: Dynamic UI rearrangement (tabs, panels, toolbars) based on predicted next steps; “focus spaces” that load before the user asks.
- Tools/products: Predictive workspace templates; dynamic command bars; cross-device continuity preloading.
- Dependencies: Platform-level extensibility; latency and compute budgets; user control over adaptivity and explainability.
- Safety and well-being interventions timed by predicted trajectories — Public Health, Digital Wellbeing
- Description: Predict when a user is likely to doomscroll or procrastinate and offer timed nudges or lockouts; or suggest breaks before long sessions.
- Tools/products: Wellbeing modules integrated into OS or apps; adaptive schedules for breaks; personalizable interventions.
- Dependencies: Ethical guidelines; opt-in consent; avoidance of paternalism; efficacy studies across demographics.
- Privacy-by-design personal AI platforms and standards — Policy/Regulation, Industry Consortia
- Description: Standards for on-device personal models that learn from full-context interactions; APIs for data minimization, consent, and portability.
- Tools/products: Edge inference SDKs; standardized logging/retention policies; model-card requirements for personal AI.
- Dependencies: Regulatory clarity (e.g., data protection laws); certification and auditing frameworks; interoperable OS APIs.
- Training computer-use agents from passive, human-in-the-loop rewards — AI/ML Research, Agents
- Description: Use temporal LLM-judge rewards and LongNAP’s memory mechanism to train generalist UI agents that learn from everyday interaction traces.
- Tools/products: RL pipelines with trajectory-level rewards; memory-augmented policies; open benchmarks built from passive, consented logs.
- Dependencies: Scalable, unbiased judges; cost-effective evaluation; richer multimodal signals (IO, eye-tracking optional).
- Trust, audit, and explainability layers for predictive UIs — Cross-sector
- Description: User-facing “why this suggestion?” with retrieved reasoning traces and past exemplars; auditors can review memory entries and rewards.
- Tools/products: Trace viewers; differential privacy for memory; red-teaming dashboards for misprediction and bias.
- Dependencies: UX patterns for explanations; privacy-safe logging; governance for memory retention and deletion.
Cross-cutting assumptions and dependencies
- Privacy, consent, and governance: Continuous screenshots and IO logging are highly sensitive. Strong opt-in, on-device processing, encryption, and deletion/export controls are prerequisites. IRB/ethics for studies.
- Platform/API access: Viability depends on OS/browser permissions for screenshots and events (mobile OS restrictions vary).
- Compute and latency: On-device VLMs or efficient edge/cloud hybrids are needed for real-time suggestions; retrieval memory must be fast and bounded.
- Data quality and noise: NAPsack’s VLM-generated labels are imperfect; quality improves with IO signals and chunking; downstream models must be robust to noise.
- Generalization and personalization: Best performance occurs with per-user adaptation and memory. Cross-user generalization is moderate; cold-start strategies and few-shot adaptation are needed.
- Evaluation reliability: LLM-as-judge provides semantic signals but can be biased; human validation, calibration, and periodic re-benchmarking are needed.
- Safety and UX: Predictions should default to suggestion, not automation, with clear controls, undo, and explanations; high-confidence gating for auto-actions.
Glossary
- BM25: A classic term-weighting ranking function used in information retrieval to score lexical matches between a query and documents. "we instantiate a lexical retriever , using BM25~\citep{robertson1995okapi}."
- Chain-of-thought: An explicit, step-by-step natural-language reasoning trace generated by a model to make its intermediate inferences transparent. "a chain-of-thought, , generated by the model during a previous prediction"
- Context window: The finite span of recent inputs/events provided to a model for conditioning its predictions. "Given a query time and a context window containing recent events , the goal is to predict future events"
- Dropout (for retrieval): Randomly removing, reordering, or omitting retrieved items during training to stabilize learning and prevent over-reliance on memory. "we apply a form of ``dropout'' to our retriever."
- GRPO: Group Relative Policy Optimization, a policy-gradient reinforcement learning method that uses grouped rollouts for variance reduction. "using GRPO~\citep{shao2024deepseekmath, liu2025understanding} for variance reduction with a group size of 4."
- In-context learning: A model’s ability to adapt to new tasks or patterns based solely on examples in its input, without changing parameters. "LongNAP, a user model that combines parametric and in-context learning to reason over long interaction histories."
- Latent learning: Acquiring knowledge that isn’t immediately needed but can be recalled and applied later to new tasks. "parametric models struggle with latent learning: the ability to acquire and retain information that has no immediate relevance to the current task, but that can be retrieved and applied when it becomes useful for future tasks"
- Lexical retriever: A retrieval component that searches memory based on word-level matches rather than learned dense embeddings. "we instantiate a lexical retriever "
- LLM-as-a-judge: Using a LLM to evaluate and score the similarity or quality of generated outputs relative to references. "we use an LLM-as-a-judge to measure semantic similarity between predicted and actual future actions."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique that injects low-rank matrices into pretrained weights. "We use LoRA~\citep{hu2022lora} due to memory constraints, where RL results generally match full finetuning"
- LongNAP: The proposed Long-context Next Action Predictor that retrieves and reasons over long interaction histories to predict user actions. "we introduce LongNAP, a user model that combines parametric and in-context learning to reason over long interaction histories."
- NAPsack: A passive data collection and labeling pipeline for human-computer interaction traces used to train next action predictors. "we introduce NAPsack: a passive tool for labeling interaction data from a user at scale."
- Next action prediction (NAP): The task of forecasting a user’s next computer action from a sequence of multimodal interactions. "We formalize this task as next action prediction (NAP): given a sequence of a user's multimodal interactions with a computer (screenshots, clicks, sensor data), predict that user's next action."
- Parametric models: Models whose learned knowledge is stored in their parameters/weights and accessed through forward computation. "However, parametric models struggle with latent learning"
- Pass@k: A metric reporting whether any of k sampled outputs meet a correctness threshold; estimates upper-bound success via multiple attempts. "We also report pass@k performance."
- Passive supervision: Learning from naturally occurring, unlabeled or automatically labeled behavior without actively instructing users or collecting explicit annotations. "We address this through passive supervision: rather than instructing users to complete specific tasks, we simply observe what they naturally do on their devices"
- Policy gradient methods: Reinforcement learning techniques that optimize a parameterized policy by ascending the gradient of expected reward. "LongNAP is trained via policy gradient methods"
- Reasoning to Predict: A LongNAP phase where the model integrates retrieved traces to refine its reasoning and output future actions. "Phase 2: Reasoning to Predict."
- Reasoning to Retrieve: A LongNAP phase where the model generates a reasoning trace and uses it as a semantic query to fetch relevant past context from memory. "Phase 1: Reasoning to Retrieve."
- Retrieval-augmented generation (RAG): Generation that conditions on retrieved context relevant to the query to improve accuracy and specificity. "we additionally implement a basic few-shot RAG baseline"
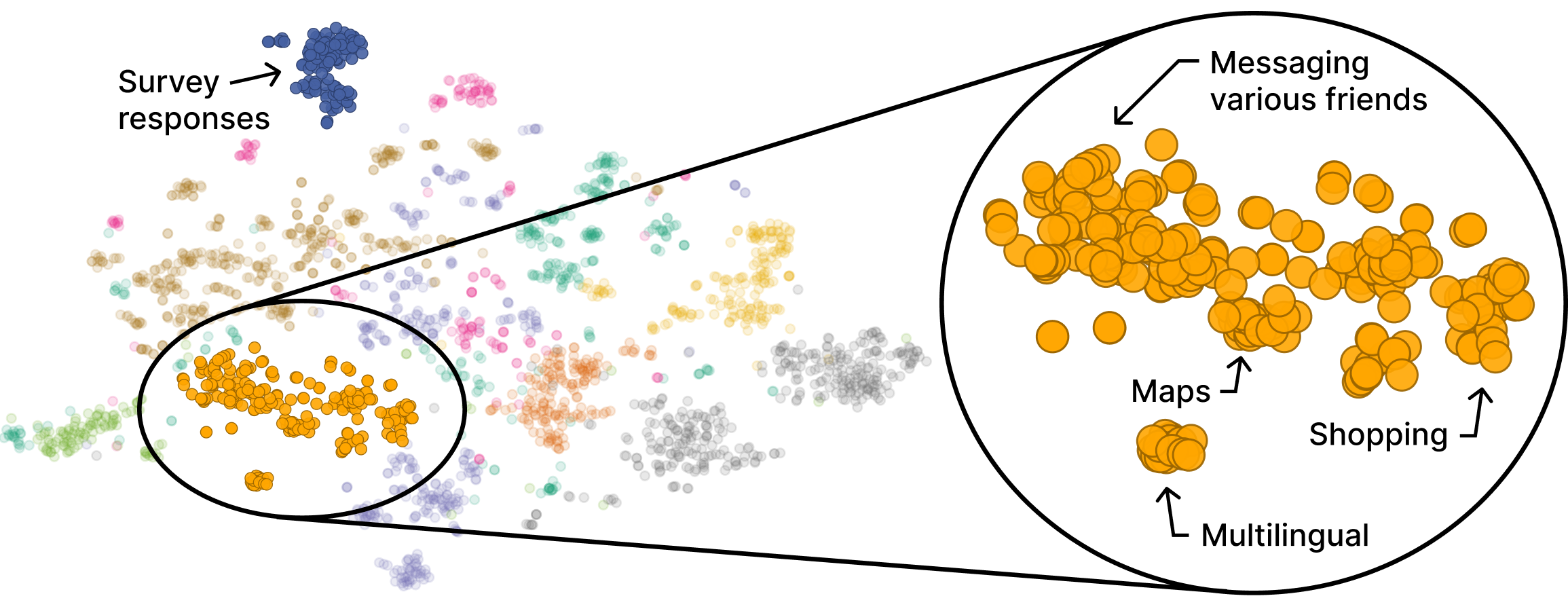
- Screenomics: A large-scale repository of continuous mobile screenshots capturing naturalistic device use for research. "we draw on Screenomics~\citep{reeves2021screenomics}"
- Sentence transformer: A neural encoder architecture (e.g., based on transformer models) that produces fixed-size sentence embeddings for similarity/clustering. "we embed each sample using a sentence transformer (using the all-MiniLM-L6-v2 model; \citet{wang2020minilm,reimers2019sentence})."
- Supervised finetuning (SFT): Adapting a pretrained model to a specific task by training on labeled examples with supervised objectives. "LongNAP significantly outperforms supervised finetuning and prompted baselines"
- Temporal reward: A reward signal derived from future observed outcomes over time—here, comparing predicted actions with what actually happened later. "we introduce a temporal reward"
- Vision-LLM (VLM): A model that jointly processes images and text to perform multimodal understanding or generation. "We can model this process using a vision-LLM (VLM) policy "
Collections
Sign up for free to add this paper to one or more collections.

