Modeling Distinct Human Interaction in Web Agents
Abstract: Despite rapid progress in autonomous web agents, human involvement remains essential for shaping preferences and correcting agent behavior as tasks unfold. However, current agentic systems lack a principled understanding of when and why humans intervene, often proceeding autonomously past critical decision points or requesting unnecessary confirmation. In this work, we introduce the task of modeling human intervention to support collaborative web task execution. We collect CowCorpus, a dataset of 400 real-user web navigation trajectories containing over 4,200 interleaved human and agent actions. We identify four distinct patterns of user interaction with agents -- hands-off supervision, hands-on oversight, collaborative task-solving, and full user takeover. Leveraging these insights, we train LMs to anticipate when users are likely to intervene based on their interaction styles, yielding a 61.4-63.4% improvement in intervention prediction accuracy over base LMs. Finally, we deploy these intervention-aware models in live web navigation agents and evaluate them in a user study, finding a 26.5% increase in user-rated agent usefulness. Together, our results show structured modeling of human intervention leads to more adaptive, collaborative agents.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies how people and AI “web agents” can work together better while doing tasks online, like shopping, searching for information, or filling out forms. The main idea is that even when AI is good at browsing and clicking, humans still need to step in sometimes—either to fix mistakes, add preferences, or prevent problems. The authors show how to model and predict those moments when a human is likely to intervene, so the AI can ask for help at the right time and avoid bothering the user when it’s not needed.
What questions did the researchers ask?
They focused on a few simple questions:
- When do people step in while an AI agent is doing a web task?
- Why do they step in?
- Can an AI learn to predict these human interventions?
- If the AI could anticipate human help, would it make the agent more useful and less annoying?
How did they study it?
Building a dataset (CowCorpus)
The team created a dataset called “CowCorpus,” made up of 400 real human–AI web sessions. In total, it includes over 4,200 actions taken by both the AI and humans during tasks across many websites. They included:
- 10 “standard” tasks from a known benchmark (Mind2Web), like finding a flight or comparing car listings.
- 10 “free-form” tasks chosen by users themselves, like searching for the latest model of a car or drafting a social media post.
For each session, they recorded what happened step-by-step: who clicked or typed, what the webpage looked like, and whether the human took control.
Understanding user styles
From these sessions, they discovered four common styles of how people interact with AI agents:
- Hands-off: The user mostly lets the agent do the task with very few interruptions.
- Hands-on: The user frequently steps in, often switching control back and forth with the agent.
- Collaborative: The user helps in short bursts and quickly gives control back, like a helpful co-pilot.
- Takeover: The user rarely intervenes, but when they do, they keep control and finish the task themselves.
Teaching models to predict interventions
They trained LLMs that look at:
- What’s happened so far in the session (the history),
- What the webpage currently shows (a screenshot and the page’s structure),
- What the agent is about to do next, and then decide whether a human is likely to intervene at that step.
They built two types of models:
- A general model that tries to predict intervention for everyone.
- Style-specific models that adapt to each user’s interaction style (like Hands-on or Collaborative).
Measuring timing with a simple idea
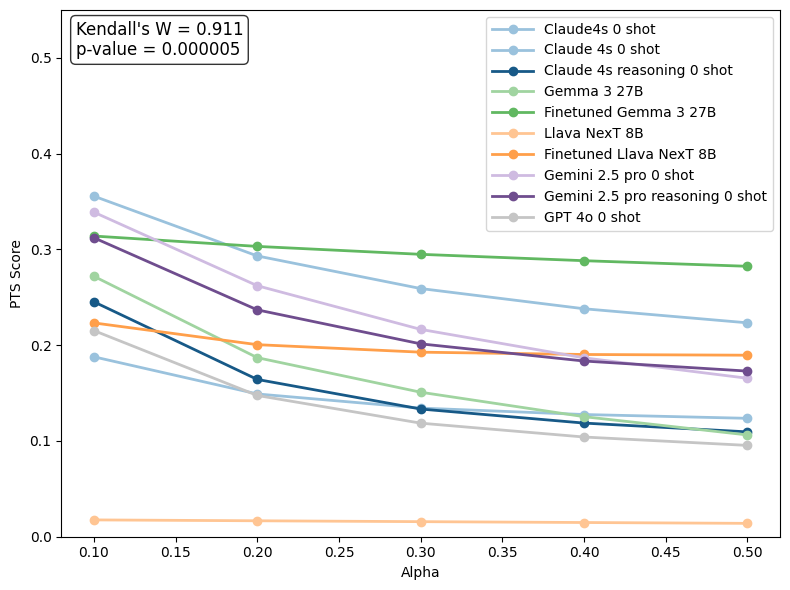
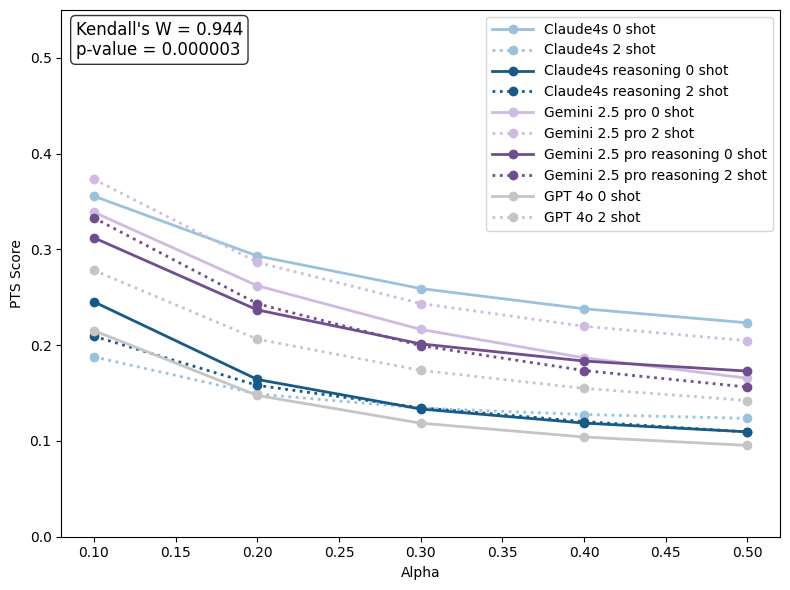
It’s not enough to know that a human will intervene—it’s important to predict the right moment. The researchers used a measure called Perfect Timing Score (PTS), which rewards models for flagging intervention at the exact step it happens and penalizes “false alarms” made too early or too late.
Think of it like raising your hand in class: You get the best score if you raise your hand exactly when the teacher calls on you, not before or after. If you raise your hand at the wrong time, your score drops the further off you are.
What did they find?
Here are the main results in plain language:
- Clear patterns: People intervene for three main reasons:
- Error correction: The agent clicks the wrong thing or gets stuck.
- Preference alignment: The agent misses specific user requirements (like price limits or location).
- Assistive takeover: The website is complex (dropdowns, captchas, dynamic pages), so the human steps in to avoid trouble.
- Predicting human help works: Models trained on these patterns got much better at predicting intervention—improving accuracy by about 61–63% compared to untrained “base” models.
- Smaller, specialized beats bigger, general: Fine-tuned, smaller open-source models trained on the CowCorpus did better at timing predictions than larger, general-purpose models that weren’t specialized.
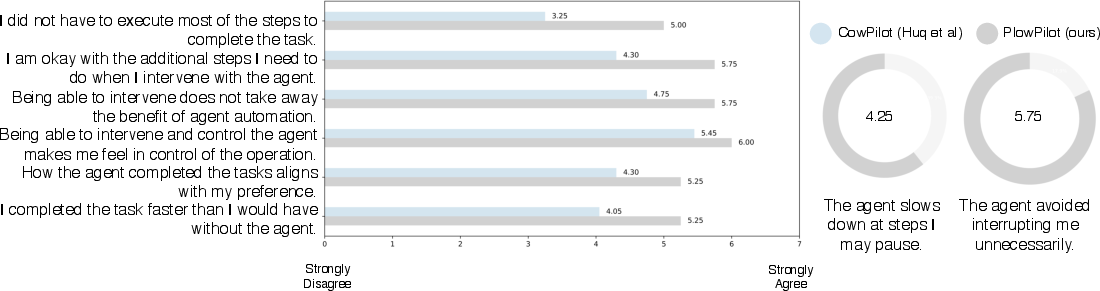
- Real-world impact: When these prediction models were added to a live web agent (so it only asked for help when intervention was likely), users rated the agent as 26.5% more useful on average. Importantly, the browsing agent itself didn’t change—only the timing of when it asked for human input improved.
Why does this matter?
This work shows a shift from “make the AI do everything by itself” to “make the AI a good teammate.” By learning when humans are likely to help and how different people prefer to interact, AI agents can:
- Avoid unnecessary interruptions,
- Ask for help at the right time,
- Reduce the mental load on users,
- And ultimately make web tasks faster, easier, and more trustworthy.
In short, modeling human intervention makes web agents more adaptable and more pleasant to use—like working with a smart assistant that knows when to take the lead and when to let you steer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research.
- Dataset scale and diversity: CowCorpus includes only 20 users and 400 trajectories; it is unclear how findings generalize across demographics, expertise levels, cultures, accessibility needs, task types (e.g., transactional vs. informational), and websites beyond those sampled.
- Agent-specific bias: All data were collected with a single framework (CowPilot), potentially entangling user intervention patterns with that agent’s idiosyncratic failure modes; replicability across different web agents and execution stacks is not evaluated.
- Website/domain shift: Generalization to unseen websites, rapidly changing DOMs, and UI patterns is not tested; robustness to live web variability (A/B tests, paywalls, dynamic content) remains unknown.
- Limited deployment evaluation: The second user study involves only 4 returning participants; statistical significance, confidence intervals, and effect sizes for the reported 26.5% improvement are not provided.
- Lack of objective task outcomes post-deployment: No measurements of task success rate, completion time, error rates, number of unnecessary prompts, or intervention frequency are reported in the live agent study.
- Class imbalance handling: Training data has ~1:7 intervention to non-intervention steps; the paper does not specify loss weighting, sampling strategies, or calibration methods to mitigate skew and improve recall on intervention steps.
- Exclusion of “Hands-off” cluster: Hands-off users are omitted from modeling because they rarely intervene; real-world systems still need to detect rare, critical interventions from predominantly hands-off users and transitions from hands-off to intervention mid-task.
- Static user-style assignment: Style-conditioned models are trained per cluster and assigned based on prior sessions; no method is provided for inferring a new user’s style online, handling cold-start, or adapting to style shifts within or across tasks.
- Limited personalization signals: Models condition only on interaction logs and web context; user-specific preferences, profiles, history, or explicit control settings (e.g., desired autonomy level) are not modeled or retained across sessions.
- Intervention granularity and intent: Interventions are modeled as a binary decision (<ask_user> vs. <agent_continue>); the system does not classify the reason/type (error correction vs. preference refinement vs. assistive takeover) or recommend tailored follow-up actions (e.g., clarify constraint, retry action, change plan).
- Multi-intervention trajectories: The Perfect Timing Score (PTS) appears designed around a single “ground-truth intervention step”; handling multiple intervention events per trajectory, overlapping or closely spaced events, and penalties for false negatives or late predictions is not clearly defined.
- PTS validity and transparency: The PTS formula has mismatched parentheses and ambiguous terms; it penalizes false positives before intervention but lacks explicit treatment for after-intervention false positives/negatives, making its sensitivity and interpretability uncertain.
- Thresholding and cost-sensitive decision-making: The paper does not detail how “high likelihood” thresholds are chosen in deployment, nor how costs of incorrect prompts (interruptions) vs. missed interventions (errors) are balanced or optimized per user/task.
- Calibration and reliability: No assessment of probability calibration, decision confidence, or abstention strategies is provided; reliability under uncertain contexts (e.g., sparse history, ambiguous UI) is unstudied.
- Temporal adaptation: While intervention timing is modeled, there is no mechanism to update the model’s behavior mid-session based on user feedback, observed errors, or evolving task state (e.g., meta-control or online learning).
- Policy-level integration: The POMDP framing is not operationalized beyond a binary classifier; there is no joint policy that optimizes when to request input, how to alter proposed actions, or how to plan contingencies if intervention is predicted.
- Effect of agent proposed action quality: The model conditions on a textual description of the agent’s proposed action, but the fidelity and format of that description (e.g., level of detail, rationale included) are not analyzed for their impact on prediction accuracy.
- Intervention efficacy: The paper does not measure whether interventions improve task outcomes (e.g., error reduction, faster completion) vs. merely changing control; the causal effect of interventions on performance is unquantified.
- Safety and high-stakes actions: There is no evaluation of risk-aware intervention (e.g., for purchases, data entry, irreversible steps); safeguards against proceeding autonomously on sensitive actions or misclicks are not studied.
- Heuristic baselines: Non-learning baselines (Always Interv, Always No Interv) are simplistic; stronger baselines (e.g., risk-based heuristics, action-type rules, uncertainty thresholds) are missing, limiting context for reported gains.
- Cross-task and cross-website generalization: The train/test split is per trajectory, but standardized tasks repeat across users; potential memorization or leakage of task patterns is not ruled out, and out-of-distribution generalization is not tested.
- Annotation reliability: Step-level intervention labels (pause, resume, override) lack details on annotation protocol, inter-rater agreement, or error analysis; noise and bias in labeling are not quantified.
- Data ethics and privacy: Free-form tasks (e.g., emails, accounts) raise privacy/security concerns; consent procedures, data redaction, and risk mitigation strategies are not described in detail.
- Accessibility and UI complexity: Agents struggle with complex UI (captchas, dynamic layouts); systematic evaluation of intervention modeling across accessibility scenarios (screen readers, keyboard-only navigation, ARIA roles) is not conducted.
- Preference modeling: Users frequently intervene due to preference misalignment; there is no mechanism to learn, store, and reuse preferences across sessions or to prompt for missing constraints early to reduce mid-task corrections.
- Mixed-mode collaboration: The four clusters reduce interaction styles to discrete categories; modeling hybrid styles, transitions over time, and context-conditional styles (e.g., hands-off for browsing, hands-on for transactions) remains unexplored.
- Scaling fine-tuning: Fine-tuning LLaVA-8B and Gemma-27B on a small dataset risks overfitting; cross-validation, learning curves, and data augmentation strategies are not presented.
- Ablations and component analysis: The paper lacks ablations on input modalities (screenshot vs. accessibility tree vs. action text), history length, or prompt serialization choices to isolate which components drive performance.
- Robustness to latency and system constraints: Real-time inference overhead, its impact on user experience, and trade-offs between responsiveness and accuracy are not measured, despite latency concerns noted in prior work.
- Cross-agent coordination: Some free-form tasks mention multi-agent collaboration; the proposed system does not address predicting intervention in multi-agent settings or coordinating control among agents and humans.
- Public benchmarking: Intervention prediction is not benchmarked on external datasets or standardized tasks designed for collaborative agents, limiting comparability and reproducibility across research groups.
- Generalization beyond web: Applicability to other UI domains (mobile apps, desktop software, IDEs) remains untested; portability of intervention modeling across interaction paradigms is an open question.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that leverage the paper’s dataset (CowCorpus), modeling approach (step-wise human intervention prediction with multimodal inputs), user-style clustering (Hands-off, Hands-on, Collaborative, Takeover), and evaluation metric (Perfect Timing Score, PTS). Each item includes sector links, potential tools/products/workflows, and key assumptions/dependencies.
- Intervention-aware shopping and travel assistants (e-commerce, travel)
- Use case: Browser-based agents that proactively ask for confirmation only when intervention likelihood is high (e.g., preference mismatches on price, brand, destination dates), reducing unnecessary interrupts while preventing costly mistakes.
- Tools/products: Chrome/Edge extensions akin to PlowPilot; intervention-aware web agent SDKs that expose an ask_user gate; plug-ins for WebArena/BrowserGym.
- Dependencies: Access to screenshots/DOM trees; latency small enough for in-the-loop decisions; privacy safeguards for browsing data; generalization across dynamic UIs and websites.
- Human-in-the-loop RPA triggers in procurement/HR/IT (enterprise software)
- Use case: Enterprise web bots escalate to employees only when predicted (e.g., unusual vendor terms or payroll edge cases), lowering oversight load without sacrificing control.
- Tools/products: “Intervention Gateway” microservice for RPA orchestrators (UiPath, Automation Anywhere); dashboards to tune autonomy thresholds using PTS.
- Dependencies: Integration with existing RPA logs; domain adaptation of the model to enterprise portals; audit requirements.
- Accessibility co-pilots that minimize oversight burden (accessibility, public sector)
- Use case: Agents assisting blind/low-vision users anticipate when the user will step in (e.g., captchas, complex dropdowns) and only prompt when needed, reducing cognitive load.
- Tools/products: Screen-reader-integrated assistants; WCAG-aware heuristics combined with intervention models.
- Dependencies: Robust multimodal parsing of accessibility trees; compliance with accessibility and privacy regulations.
- Adaptive customer support co-browsing (customer service, SaaS)
- Use case: Self-serve web agent escalates to human support at predicted struggle points (loops, repeated invalid actions), improving resolution and CSAT.
- Tools/products: Contact-center integrations (Zendesk, Salesforce) with intervention likelihood signals and PTS-based QA.
- Dependencies: Data-sharing agreements; careful logging and privacy opt-ins; latency budgets for real-time escalation.
- Personalized collaboration style onboarding (cross-sector)
- Use case: Quick profiling of users into Hands-on/Collaborative/Takeover styles from early interactions to personalize when the agent seeks confirmation and when it proceeds autonomously.
- Tools/products: Lightweight “style classifier” module; per-user autonomy “dial” in agent settings.
- Dependencies: Short warm-up interactions sufficient for reliable clustering; graceful handling of Hands-off users.
- Safer automation for critical web forms (healthcare portals, gov services, finance)
- Use case: Agents fill forms but trigger confirmation at predicted high-impact fields (e.g., consent, personal data, payment).
- Tools/products: “Critical Field Guardrail” integrated into form-filling agents.
- Dependencies: Accurate critical-field detection; compliance with HIPAA/GDPR/PCI; provenance tracking of actions.
- PTS-based evaluation and A/B testing for agent teams (software/ML ops)
- Use case: Product teams quantify timing quality of user prompts to reduce notification fatigue and measure gains in usefulness.
- Tools/products: PTS calculators; experiment harnesses; benchmarking suites using CowCorpus-like logs.
- Dependencies: Sufficient logged trajectories; calibration across task distributions; handling class imbalance.
- Fintech onboarding with targeted human review (finance)
- Use case: KYC/KYB and loan application bots trigger analyst review only when intervention probability spikes (ambiguities, anomalous docs).
- Tools/products: Review routers informed by intervention probabilities; analyst workload dashboards.
- Dependencies: Secure document handling; model alignment to institution-specific policies and risk criteria.
- Training open-weight LMs for intervention awareness (academia, open-source)
- Use case: Fine-tune smaller models (e.g., Gemma-27B, LLaVA-8B) with CowCorpus-like data to outperform generalist models on intervention timing, lowering cost.
- Tools/products: Reproducible SFT scripts; public benchmarks; community baselines.
- Dependencies: Dataset representativeness; licensing constraints; compute availability.
- Workflow analytics to locate friction (product ops, UX research)
- Use case: Analyze logs for where users frequently take over, then remediate UI or agent strategies on those steps.
- Tools/products: “Intervention Heatmap” analytics; cohort analysis by collaboration style.
- Dependencies: Clean action logs with actor labels; consented telemetry collection.
Long-Term Applications
These applications extend the paper’s methods to new domains or require scaling, standardization, or further research before broad deployment.
- Cross-domain handover modeling for GUI automation and robotics (software, robotics)
- Vision: Generalize step-wise intervention prediction to OS-level “computer use” and physical robots for smooth human-robot handovers.
- Tools/products: OS-automation “Intervention API”; robot control stacks that modulate autonomy by predicted user intent.
- Dependencies: Rich multimodal sensing; real-time constraints; safety validation; domain-specific datasets.
- Regulatory standards for appropriate oversight (policy, compliance)
- Vision: Use timing metrics like PTS to operationalize “human-in-the-loop” requirements (e.g., EU AI Act), reducing alert fatigue while preserving control.
- Tools/products: Audit reports with PTS; compliance checklists for intervention-aware agents.
- Dependencies: Regulator buy-in; sector-specific risk thresholds; standardized logging formats.
- Lifelong, style-adaptive agents (personalization across sectors)
- Vision: Continuously update a per-user “style embedding” from interaction traces to tailor autonomy and prompting as preferences evolve.
- Tools/products: On-device or server-side personalization pipelines; privacy-preserving learning.
- Dependencies: Drift detection; consent and data minimization; robust cold-start strategies.
- Proactive preference elicitation policies (e-commerce, education, productivity)
- Vision: Agents ask clarifying questions only when misalignment risk is high, combining intervention prediction with uncertainty estimation.
- Tools/products: Clarification policy engines; sequential decision policies gated by p(y_t=1).
- Dependencies: Calibrated uncertainty; high-quality preference taxonomies; cost-benefit tuning of prompts.
- Multi-agent orchestration with human escalation (SaaS, enterprise IT)
- Vision: Coordinators route tasks among specialized agents and humans based on predicted intervention moments and styles.
- Tools/products: Orchestrators with intervention-aware routing; SLAs tied to escalation timing.
- Dependencies: Interoperable APIs; resource scheduling; robust failure handling.
- Clinical and safety-critical decision support (healthcare, aviation, energy)
- Vision: Predict when clinician/operator intervention is needed to reduce alert fatigue and ensure control at critical junctures.
- Tools/products: Alert systems driven by timing-aware models; human factors testing with PTS-like metrics.
- Dependencies: High-stakes validation; domain-specific datasets; liability frameworks.
- Risk controls in trading and payments (finance)
- Vision: Trigger trader approval for orders/payments when model predicts elevated intervention need (e.g., anomalous size, venue).
- Tools/products: Trading OMS hooks; payment approval gates with intervention probabilities.
- Dependencies: Latency constraints; adversarial robustness; regulatory audits.
- Adaptive tutoring and study aids (education)
- Vision: Tutors that decide when to intervene or let learners proceed, minimizing over-prompting and improving flow.
- Tools/products: LMS plug-ins with intervention timing; learner-style profiling.
- Dependencies: Pedagogical validation; data privacy in schools; integration with existing LMS.
- Cross-platform “Intervention API” standard (agent ecosystem)
- Vision: A vendor-neutral API to publish/consume p(y_t=1), log interventions, and benchmark PTS across agent platforms.
- Tools/products: Open standards group; SDKs for browsers, RPA, mobile, and robots.
- Dependencies: Community adoption; schema and privacy standards; backward compatibility.
- Large-scale, domain-specific corpora (research, industry)
- Vision: Expand CowCorpus-like datasets across sectors (healthcare, finance, government portals) to improve generalization.
- Tools/products: Federated/crowdsourced data pipelines; synthetic-augmented logs with privacy guarantees.
- Dependencies: Ethical data collection; de-identification; coverage of rare but critical events.
- Trust and safety gates for high-risk actions (cross-sector)
- Vision: Combine intervention prediction with risk detectors (e.g., ToolEmu, TrustAgent) to gate dangerous actions at the right time.
- Tools/products: “Risk × Timing” policy layers; explainability modules for why/when a handover is requested.
- Dependencies: Risk taxonomy; red-teaming; human factors evaluation.
- Cost-efficient deployment with specialized small models (software infra)
- Vision: Replace reliance on large proprietary models with fine-tuned smaller LMs that match or exceed timing performance.
- Tools/products: Distilled, edge-deployable models; batching/streaming inference pipelines.
- Dependencies: Hardware constraints; continual learning; MLOps for small LMs.
Assumptions and dependencies common across applications:
- Data and generalization: CowCorpus is relatively small (20 users, 400 trajectories), and the user study follow-up had 4 participants; broader deployment needs larger, more diverse data and validation.
- Context requirements: Models depend on accurate, timely screenshots/DOM/accessibility trees and stable tool APIs; dynamic and protected content (CAPTCHAs, paywalls) remain challenging.
- Personalization: Reliable identification and updating of user collaboration styles is required; cold-start strategies are necessary.
- Latency and UX: Prediction must be fast enough to not disrupt task flow; mis-timed prompts can harm usability.
- Privacy and compliance: Logging and personalization require strong privacy protections, user consent, and domain-specific regulatory compliance.
Glossary
- Accessibility tree: A structured representation of a webpage’s UI elements used for accessibility and programmatic interaction. "consisting of the current screenshot and the webpage accessibility tree ."
- Actor policy: The decision function that maps observations to actions for an actor (agent or human). "This observation is passed into the actor policy to generate the next action ."
- Agentic systems: AI systems designed to operate autonomously as agents in an environment. "current agentic systems lack a principled understanding of when and why humans intervene"
- Always Interv: A baseline policy that requests user intervention at every step. "Always Interv, a fully confirmation-dependent policy that requests intervention at every step."
- Always No Interv: A baseline policy that never requests user intervention. "Always No Interv, a fully autonomous policy that never requests user intervention"
- Assistive takeover: A user’s proactive control shift to compensate for agent limitations in complex environments. "human involvement is driven by three recurring needs: error correction, preference refinement, and assistive takeover."
- Class imbalance: A distribution where one class (e.g., non-intervention) significantly outnumbers another, affecting evaluation. "We report F1 scores separately for intervention and non-intervention steps to account for class imbalance."
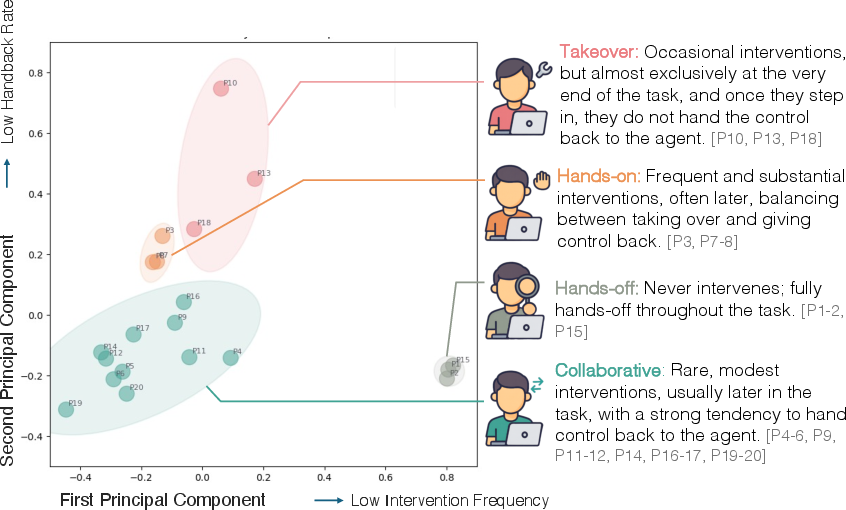
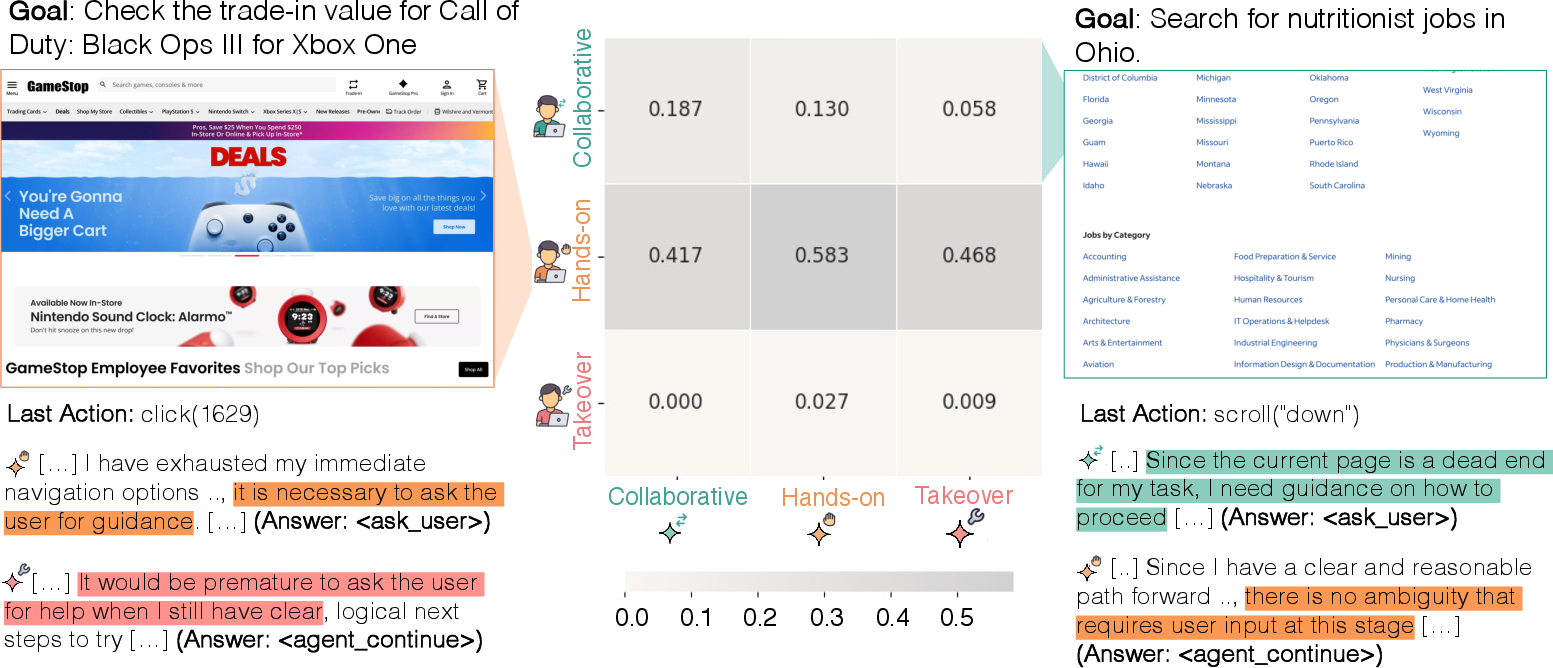
- Collaborative (interaction style): A pattern where users intervene selectively and return control to the agent to support ongoing collaboration. "We identify four distinct patterns of user interaction with agents -- \textcolor{group1}{hands-off} supervision, \textcolor{group2}{hands-on} oversight, \textcolor{group0}{collaborative} task-solving, and full user \textcolor{group3}{takeover}."
- Computer Use capabilities: Model abilities that enable direct interaction with graphical user interfaces. "The emergence of recent Computer Use capabilities from models like Claude \citep{anthropic_2024} and Operator have further closed the gap between human browsing and machine execution"
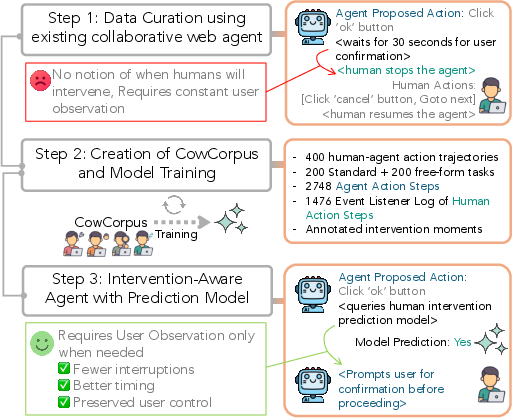
- CowCorpus: A dataset of real-user human–agent web navigation trajectories for modeling intervention. "we introduce CowCorpus, a dataset of 400 real-user web navigation trajectories containing over 4{,}200 interleaved human and agent actions."
- CowPilot: An open-source framework used to facilitate human–agent collaboration in web tasks. "specifically, the open-source framework CowPilot \citep{cowpilot}."
- Data leakage: Unintended information overlap between training and test sets that can inflate performance. "We split CowCorpus data into train and test sets at the trajectory level to avoid leakage."
- Document Object Model (DOM): The tree-structured representation of a webpage’s content and elements. "Agents struggled with dropdowns, captchas, dynamic layouts, or complex DOM elements in certain websites."
- Handback rate: The proportion of intervention events after which control returns to the agent. "Handback Rate. We measure whether control returns to the agent after a human intervention."
- Hands-off (supervision): A pattern where users rarely intervene and largely allow autonomous agent execution. "We identify four distinct patterns of user interaction with agents -- \textcolor{group1}{hands-off} supervision, \textcolor{group2}{hands-on} oversight, \textcolor{group0}{collaborative} task-solving, and full user \textcolor{group3}{takeover}."
- Hands-on (oversight): A pattern where users intervene frequently and alternate control with the agent. "We identify four distinct patterns of user interaction with agents -- \textcolor{group1}{hands-off} supervision, \textcolor{group2}{hands-on} oversight, \textcolor{group0}{collaborative} task-solving, and full user \textcolor{group3}{takeover}."
- Human intervention modeling: The task of predicting whether and when a user will intervene during agent execution. "We define this human intervention modeling task to be a step-wise binary classification"
- Intervention intensity: The ratio of total human steps to total agent steps within trajectories. "Intervention Intensity measures the ratio of total human steps to total agent steps:"
- Intervention-aware model: A model trained to anticipate and adapt to likely points of user intervention. "a general intervention-aware model that moves beyond purely autonomous execution"
- Intervention frequency: How often a user intervenes relative to the total number of actions. "Intervention Frequency measures how often a user intervenes over the total number of actions:"
- K-means clustering: An unsupervised method for partitioning users into k groups based on interaction features. "we cluster users by interaction behavior with -means ()."
- LLMs: High-capacity neural models trained on large text corpora used for reasoning and generation. "Recent advances in LLMs have enabled AI agents to perform increasingly complex tasks in web navigation"
- Large multimodal model (LMM): A model that processes multiple modalities (e.g., text and images) to make predictions or generate actions. "We approach this using a large multimodal model (LMM) optimized via supervised fine-tuning (SFT)."
- Multimodal observation: The combined input (e.g., screenshot and accessibility tree) representing the current state. "we construct a multimodal observation of the current state"
- Open-weight models: Models whose parameters are publicly available for fine-tuning and deployment. "In contrast, fine-tuning open-weight models on CowCorpus yields the most significant performance gains"
- Partially Observable Markov Decision Process (POMDP): A framework for decision-making when the full state is not directly observable. "We formulate the human-agent collaboration as a Partially Observable Markov Decision Process (POMDP)."
- Perfect Timing Score (PTS): A metric that measures both correctness and timing accuracy of intervention predictions. "Perfect Timing Score (PTS): evaluates how accurately a model predicts the timing of human intervention."
- Policy (π): The function that determines the next action based on observations and history in a decision process. "following policies and "
- Principal Component Analysis (PCA): A dimensionality reduction technique used to visualize and analyze user interaction features. "We then project these features into two dimensions using PCA for visualization"
- Serialized prompt: A structured input string that encodes history, current observation, and proposed action for the model. "The model takes a serialized prompt containing (1) the history trajectory , (2) the current observation , and (3) a description of the agent-proposed action ."
- Stepwise sequence prediction: Predicting outcomes at each step of an evolving sequence given context and history. "We cast this problem as a stepwise sequence prediction task: at each agent action, the model estimates the likelihood of user intervention"
- Supervised Fine-Tuning (SFT): Adapting a pretrained model using labeled examples to optimize for a specific task. "We approach this using a large multimodal model (LMM) optimized via supervised fine-tuning (SFT)."
- Takeover: A pattern where users intervene late and retain control rather than returning it to the agent. "We identify four distinct patterns of user interaction with agents -- \textcolor{group1}{hands-off} supervision, \textcolor{group2}{hands-on} oversight, \textcolor{group0}{collaborative} task-solving, and full user \textcolor{group3}{takeover}."
- Two-shot prompting: Providing two illustrative examples in a prompt to guide a model’s behavior. "Additional results with two-shot prompting and with reasoning are reported in \textsection\ref{sec:4.5:benchmark-table}."
- Zero-shot: Using a model to perform a task without providing task-specific examples in the prompt. "We evaluate three families of closed-source LMs ... using zero-shot without reasoning."
Collections
Sign up for free to add this paper to one or more collections.