cuRoboV2: Dynamics-Aware Motion Generation with Depth-Fused Distance Fields for High-DoF Robots
Abstract: Effective robot autonomy requires motion generation that is safe, feasible, and reactive. Current methods are fragmented: fast planners output physically unexecutable trajectories, reactive controllers struggle with high-fidelity perception, and existing solvers fail on high-DoF systems. We present cuRoboV2, a unified framework with three key innovations: (1) B-spline trajectory optimization that enforces smoothness and torque limits; (2) a GPU-native TSDF/ESDF perception pipeline that generates dense signed distance fields covering the full workspace, unlike existing methods that only provide distances within sparsely allocated blocks, up to 10x faster and in 8x less memory than the state-of-the-art at manipulation scale, with up to 99% collision recall; and (3) scalable GPU-native whole-body computation, namely topology-aware kinematics, differentiable inverse dynamics, and map-reduce self-collision, that achieves up to 61x speedup while also extending to high-DoF humanoids (where previous GPU implementations fail). On benchmarks, cuRoboV2 achieves 99.7% success under 3kg payload (where baselines achieve only 72--77%), 99.6% collision-free IK on a 48-DoF humanoid (where prior methods fail entirely), and 89.5% retargeting constraint satisfaction (vs. 61% for PyRoki); these collision-free motions yield locomotion policies with 21% lower tracking error than PyRoki and 12x lower cross-seed variance than mink. A ground-up codebase redesign for discoverability enabled LLM coding assistants to author up to 73% of new modules, including hand-optimized CUDA kernels, demonstrating that well-structured robotics code can unlock productive human--LLM collaboration. Together, these advances provide a unified, dynamics-aware motion generation stack that scales from single-arm manipulators to full humanoids.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces cuRoboV2, a new way to plan and control robot motion so that robots move smoothly, safely, and quickly—even when they have lots of joints like humanoid robots. The system combines smart motion planning, fast 3D perception from depth cameras, and physics-aware control, all running on a GPU (the same kind of chip used for gaming and AI). The goal is one unified toolbox that works for both slow, careful planning and fast reactions to changing scenes.
What questions does the paper ask?
To make robots truly useful in the real world, the authors focus on three kid-friendly questions:
- Can we plan paths that a real robot can actually follow without “breaking a sweat” (not exceeding its motor strength)?
- Can the robot “see” its surroundings in enough detail to avoid collisions, and update that view fast enough to react in real time?
- Can the same method still work when the robot has many moving parts (like arms, legs, and a torso) instead of just a single arm?
How does it work?
The system solves these problems with three main ideas. You can think of them like the robot’s “brain,” “eyes,” and “muscles,” all working together.
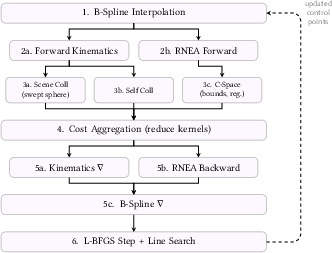
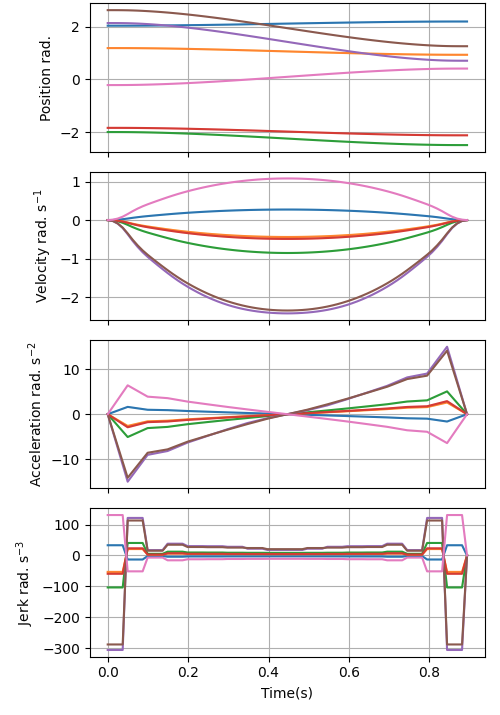
1) Smooth, safe motions using B‑splines (the robot’s “brain”)
- Idea in simple terms: Instead of plotting every tiny step of a motion separately, the system controls a smooth curve (called a B‑spline) using a small set of “control points.” Imagine hammering a few nails into a board and pulling a string around them—the string makes a smooth path. Move a nail a little, and only part of the string changes.
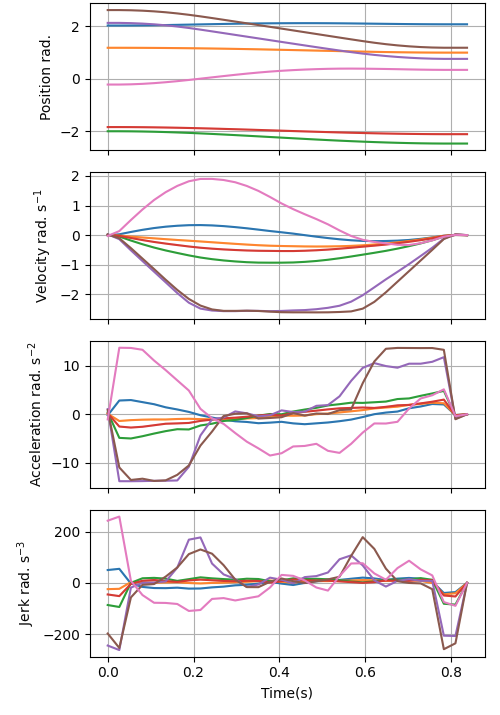
- Why this helps: Smooth curves naturally avoid jerky moves, which keeps motor effort (torque) within limits—like not asking a robot to lift too fast or too hard. This also makes it easier to optimize motions that stay safe (no collisions) and end where they should.
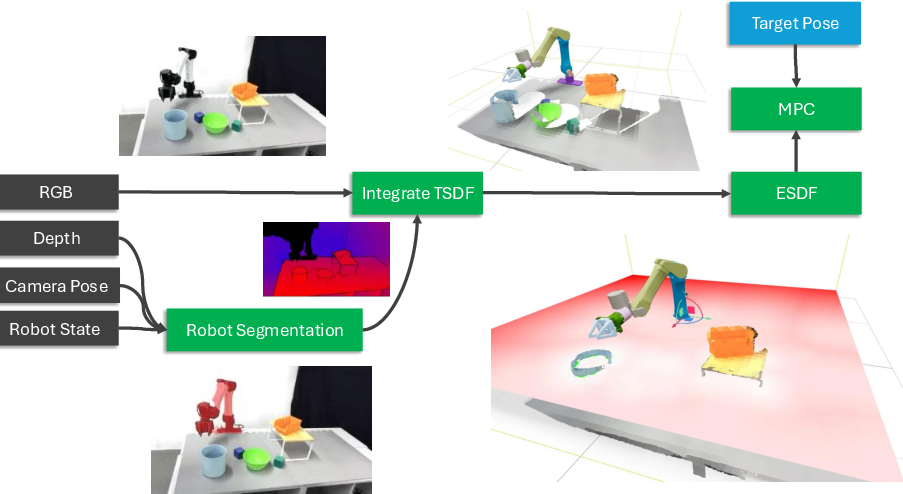
2) Fast 3D “distance-to-objects” maps from depth cameras (the robot’s “eyes”)
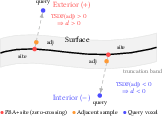
- What it builds: A 3D map that tells, at any point, “how far am I from the nearest object?” That’s called a signed distance field (SDF). Positive numbers mean you’re outside an object; negative means inside (which is bad for the robot!).
- How it’s made:
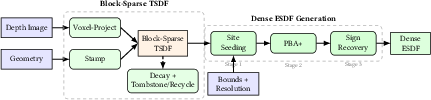
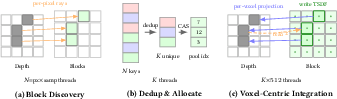
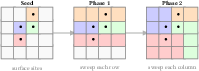
- The system fuses depth images and known shapes (like boxes or meshes) into a compact 3D grid (TSDF).
- When needed, it quickly builds a dense “everywhere” distance map (ESDF) so the robot can check collision distance at any point in constant time.
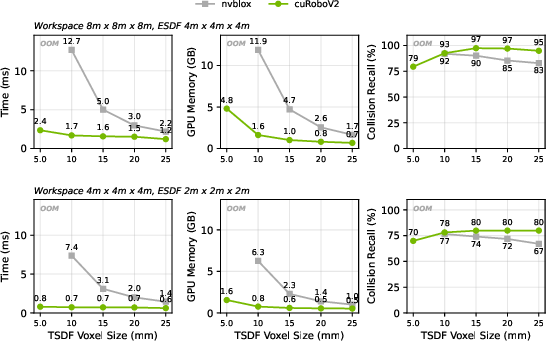
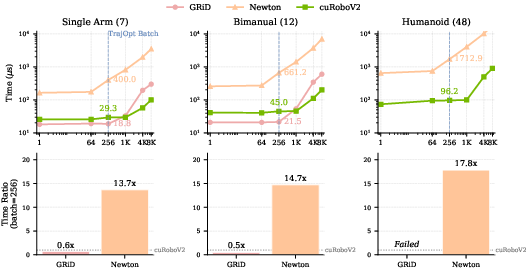
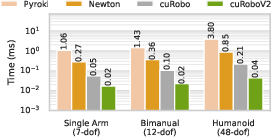
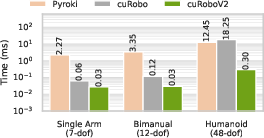
- Why it’s special: Many older methods only compute distances in small, scattered patches, leaving gaps elsewhere. cuRoboV2 can give distances across the whole workspace “on demand.” It does this up to 10× faster and using about 8× less memory (for typical manipulation scenes), with up to 99% collision recall (meaning it almost never misses obstacles).
3) Scales to complex, high‑DoF robots (the robot’s “muscles” and coordination)
- What “DoF” means: “Degrees of freedom” are the robot’s movable joints—more DoF means a more flexible, complicated robot.
- What’s new: The system includes GPU‑accelerated math for:
- Kinematics (where all the links/joints are in space),
- Dynamics (how much torque/motor effort is needed),
- Self‑collision (making sure the robot doesn’t bump into itself).
- Why GPUs help: A GPU can run thousands of tiny tasks at once—like having a huge team of helpers—so even complex robots can get quick answers. The paper reports up to 61× speedups for these whole‑body computations compared to earlier methods, letting the planner iterate quickly and find better solutions.
What did they find?
Here are some key results the authors report, and why they matter:
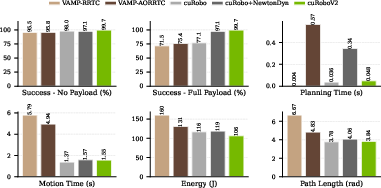
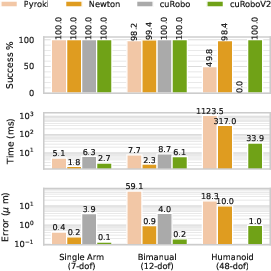
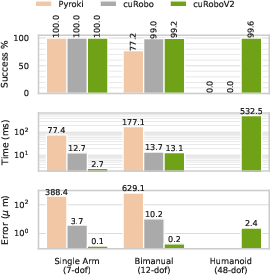
- Much higher success for heavy tasks: 99.7% success when moving with a 3 kg payload, while other methods got only 72–77%. This means plans are not just smooth—they’re actually doable by the robot’s motors.
- Safer, more complete perception: Up to 99% collision recall and up to 10× faster ESDF generation in 8× less memory than a popular library at manipulation scale. This means the robot can “see” its environment accurately and react quickly.
- Works for humanoids: 99.6% collision‑free inverse kinematics on a 48‑DoF humanoid, where earlier methods failed entirely. This is a big step for whole‑body robots.
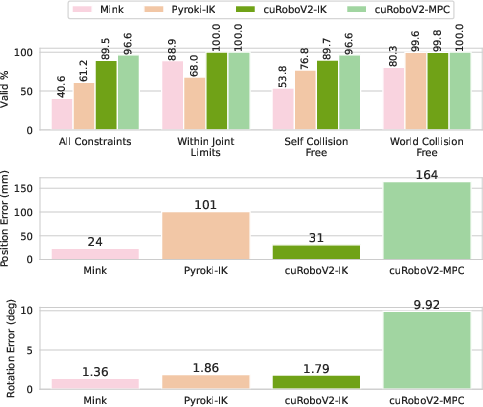
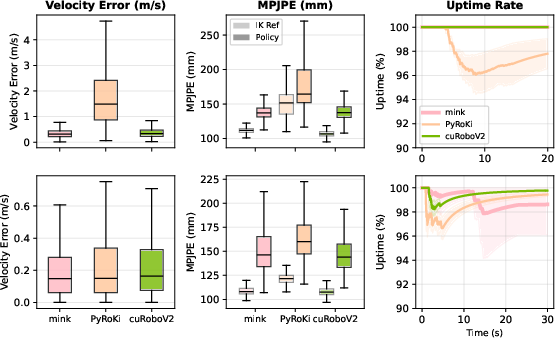
- Better motion retargeting (copying human motion to a robot): 89.5% of constraints satisfied (vs. 61% for a strong baseline, PyRoki), leading to locomotion policies with 21% lower tracking error and 12× lower run‑to‑run variability than another baseline (mink). That means more stable, reliable training for walking and movement.
- Big speedups: Up to 61× faster whole‑body computations, which helps the optimizer find solutions quickly.
- Faster development with AI help: Because the codebase is clean and well‑structured, LLM coding assistants wrote up to 73% of new modules, including GPU kernels. This hints that good software design speeds up robot research and engineering.
Why this matters
- Safer, smoother robot motion: Robots that move like this are less likely to collide, stall, or overstress their motors—important for factories, labs, and home assistants.
- Real‑time reactions: The robot can update its map of the world in milliseconds and adjust on the fly. That’s key for working near people or in changing environments.
- From simple arms to humanoids: The same framework scales from single‑arm manipulators to full‑body robots, which simplifies building complex systems.
- Better training for robot learning: Cleaner, collision‑free reference motions make it easier to train walking or manipulation policies that are stable and consistent.
- Faster progress through better tools: The code is designed so that both humans and AI assistants can extend it quickly, accelerating future robotics research and applications.
In short, cuRoboV2 pulls together smooth, physics‑aware planning, fast 3D perception, and scalable whole‑body computation into one system. It makes robots more capable and reliable, whether they’re lifting boxes, reacting to moving obstacles, or coordinating arms and legs like a humanoid.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes concrete gaps and unresolved questions that the paper leaves open, organized to guide follow-on research and engineering.
- Convergence and optimality guarantees:
- No formal analysis of convergence properties of the B-spline + L-BFGS formulation under nonconvex ESDF, self-collision, and torque-limit constraints; conditions for local/global convergence and failure modes are not characterized.
- Lack of ablation on sensitivity to initialization and seeding strategies in high-DoF, cluttered scenes (e.g., narrow passages for humanoids).
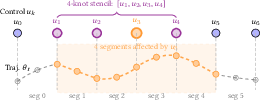
- Time parameterization and spline design:
- Fixed knot spacing and fixed segment time ; no procedure for optimizing timing (time-scaling) jointly with geometry to satisfy torque limits or improve feasibility.
- No strategy for adaptive knot placement or order selection to balance smoothness, conditioning, and responsiveness for fast-reactive tasks.
- Dynamics modeling and robustness:
- Inverse dynamics assumes accurate rigid-body parameters; robustness to model errors, unmodeled flexibilities, transmissions, or payload uncertainty (beyond the reported 3 kg) is not analyzed.
- No treatment of actuator thermal limits, velocity-dependent torque saturation, or motor current limits; only static torque bounds are enforced.
- Absence of stochastic/robust formulations (e.g., chance constraints) to handle parameter uncertainty and disturbances.
- Contacts and task-specific physics:
- Contact modeling (e.g., foot–ground contacts, sticking/slipping, friction cones, complementarity constraints) is not integrated; essential for locomotion, whole-body manipulation, and pushing tasks.
- Center-of-mass costs are supported, but zero-moment point (ZMP), centroidal dynamics constraints, or contact schedules are not addressed.
- Collision modeling fidelity:
- Robot geometry is approximated by spheres; there is no method to automatically guarantee clearance bounds or to adapt sphere coverage near sharp features (hands, feet, end-effectors).
- Continuous-time collision checking is approximated via CHOMP’s speed metric; there is no formal bound on missed collisions between discretization steps or on trilinear ESDF interpolation errors.
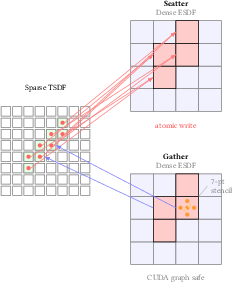
- ESDF site seeding coverage:
- The gather-based 7-point stencil may miss thin or highly oblique surfaces when ; coverage vs. resolution ratio is not quantified, nor are adaptive or anti-aliased sampling schemes evaluated.
- No mechanism to detect and mitigate seeding failures online (e.g., adaptive refinement where site density is low or gradients are inconsistent).
- ESDF sign recovery limitations:
- For depth-only surfaces, sign defaults to exterior outside the truncation band; interior/exterior classification for open surfaces (e.g., shelves, cavities) is undefined and may yield non-conservative behavior in tight spaces.
- The adjacent-sample sign recovery relies on watertight “geometry” channels; there is no approach to robustly infer sign for depth-fused geometry via multi-view closure, meshing, or occupancy-SDF hybrids.
- Real-time ESDF generation and scheduling:
- ESDF is generated “on demand” at a user-selected resolution, but policies for selecting workspace bounds, update frequency, and region-of-interest (ROI) sub-volumes to meet hard real-time budgets are not specified.
- Incremental ESDF updates (vs. full regeneration) and asynchronous pipelines for overlapping perception/optimization are not explored.
- Mapping dynamics and semantics:
- The frustum-aware time decay is heuristic; there is no dynamic object segmentation/tracking to avoid smearing moving obstacles into the map or to maintain consistent geometry under camera egomotion.
- Decay parameters (, ) lack tuning guidance and safety analysis for fast-moving obstacles.
- Multi-sensor fusion and calibration:
- Fusion of multiple depth cameras or LiDAR, handling extrinsic drift, and loop-closure for long-duration operations are not treated.
- Sensitivity to calibration errors and per-sensor noise models (e.g., missing/invalid pixels, specular surfaces) is not quantified.
- Numeric precision and discretization:
- TSDF uses float16 channels; the impact of quantization on clearance accuracy, especially for millimeter-level manipulation near tight tolerances, is unreported.
- There is no bound on ESDF interpolation error relative to collision sphere radii, nor guidelines for selecting and to meet a specified safety margin.
- GPU pipeline and real-time determinism:
- The voxel-centric integration requires a device-to-host synchronization to read (number of visible blocks); the effect on control loop jitter and deadlines is not measured, and fully device-side alternatives are not explored.
- Hash-table behavior under high load (collisions, fragmentation), worst-case allocation/deallocation latency, and memory compaction for long runs are not characterized.
- Scalability beyond manipulation scale:
- Claims of up to 10× speed and 8× less memory than nvblox are at “manipulation scale”; performance, memory, and latency at mobile or building scale (with sparse, large workspaces) are not presented.
- Strategies for multi-GPU tiling, out-of-core ESDF/TSDF, or streaming large environments are not discussed.
- Self-collision scaling:
- While a map-reduce approach is introduced, the growth of candidate pairs with the number of spheres remains a concern; broad-phase culling (e.g., BVHs, sweep-and-prune) and configuration-dependent pruning strategies are not detailed or benchmarked.
- Differentiability and gradient quality:
- The collision cost uses a min(depth, geometry) composition and ESDF zero-crossings; non-smoothness and subgradient selection are not analyzed, and smoothing strategies (e.g., soft-min, mollified SDF) are not evaluated for optimizer stability.
- Backprop through inverse dynamics is mentioned, but gradient correctness and numerical conditioning near joint singularities or mimic constraints are not validated.
- Closed-loop MPC behavior:
- There is no stability or recursive feasibility analysis for MPC-like receding-horizon use; behavior under solver timeouts, perception dropouts, or latency spikes is not covered, nor are safe fallback policies.
- Task generalization and benchmarking:
- Reported successes (e.g., 99.7% under 3 kg payload, humanoid IK/retargeting metrics) lack stress tests on adversarial geometries, very narrow passages, or highly dynamic scenes; standardized, publicly reproducible benchmarks are needed.
- Transfer to physical high-DoF humanoid hardware (with contacts, compliance, state estimation drift) is not demonstrated.
- Integration of learned priors:
- Although the framework emphasizes analytic pipelines, mechanisms to integrate learned warm starts or learned distance surrogates (with guarantees) are not explored for improving convergence in hard cases.
- Hyperparameter selection:
- No procedure for automatic or adaptive tuning of cost weights (), decay factors, or ESDF resolutions to meet specified safety/throughput targets.
- Constraint set completeness:
- Additional hardware constraints (joint velocity/acceleration bounds across the full trajectory, jerk limits for wear, backlash/clearance) and couplings (e.g., mechanically coupled joints beyond “mimic”) are only partially addressed.
- Safety margins and certification:
- There is no end-to-end analysis translating perception/ESDF errors, kinematic/dynamic modeling errors, and optimizer tolerances into guaranteed geometric and torque-limit safety margins suitable for certification.
- Extending beyond rigid scenes/robots:
- Handling deformable or articulated obstacles (e.g., humans, doors with compliant hinges) and robots with elastic elements is not considered; representations and constraints for such settings remain open.
These items suggest targeted experiments, ablations, algorithmic extensions, and systems engineering work that can turn the promising cuRoboV2 design into a rigorously validated, certifiable, and robustly deployable whole-body motion generation stack.
Practical Applications
Immediate Applications
The following applications can be deployed today by practitioners with access to depth sensors and GPU hardware. They leverage the paper’s B‑spline trajectory optimization with torque limits, the GPU TSDF/ESDF pipeline, and scalable whole‑body kinematics/dynamics/self‑collision modules.
- Dynamics‑aware motion planning for industrial manipulators under load
- Sectors: manufacturing, logistics, electronics assembly, warehousing
- Tools/products/workflows:
- Drop‑in planner for ROS2/MoveIt pipelines that replaces waypoint planners with torque‑limit‑aware B‑spline trajectories
- Payload‑aware task libraries (e.g., palletizing, bin‑picking) with reduced jerk and fewer torque-limit violations
- Shop‑floor deployment with single RTX/Jetson GPU for sub‑second plan generation
- Why now: Achieves 99.7% success under 3 kg payload (vs. 72–77% for baselines); smooth B‑splines satisfy hardware limits without expensive post‑processing
- Assumptions/dependencies: Accurate robot URDF/SRDF and torque limits; calibrated depth camera(s); GPU with adequate memory; conservative sphere approximation for collision models
- Reactive, collision‑aware MPC for collaborative robots (HRC)
- Sectors: human‑robot collaboration on assembly lines, quality inspection, service robotics in controlled environments
- Tools/products/workflows:
- Millisecond‑rate ESDF updates for safe reactive controllers (RMP/MPC) operating directly on fused depth and primitive geometry
- On‑device safety envelopes (O(1) distance queries) enabling speed‑and‑separation monitoring augmentation
- Why now: ESDF 10× faster and 8× lower memory than nvblox at manipulation scale; up to 99% collision recall
- Assumptions/dependencies: Stable depth sensing, correct extrinsic calibration, frustum‑aware decay tuned to scene dynamics, integration with robot safety PLCs per facility standards
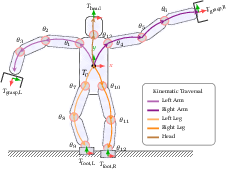
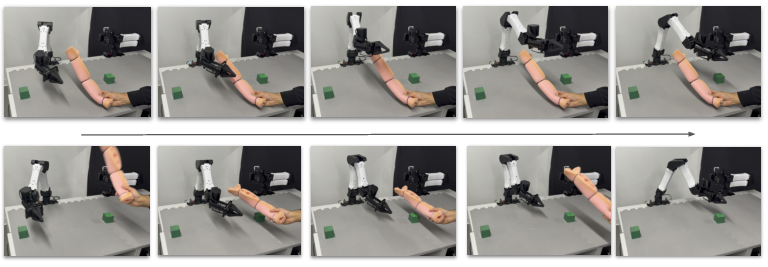
- Whole‑body, collision‑free inverse kinematics for high‑DoF robots
- Sectors: humanoid and bimanual research labs, entertainment/mocap, VR/AR telepresence
- Tools/products/workflows:
- IK solvers that respect joint/torque limits and self‑collision for 30–50+ DoF bodies
- Retargeting pipelines from human mocap to humanoids for data generation and teleoperation
- Why now: 99.6% collision‑free IK on 48‑DoF humanoid where prior methods fail; 89.5% constraint satisfaction for retargeting
- Assumptions/dependencies: High‑quality kinematic models (including mimic joints), tuned self‑collision pairs/spheres, synchronized motion capture streams
- Higher‑quality locomotion policy datasets via collision‑free retargeting
- Sectors: robotics ML/RL in academia and industry
- Tools/products/workflows:
- Data generation pipelines that eliminate self‑penetrations and joint‑limit violations before policy training
- Reduced training variance and improved tracking (reported 21% lower tracking error; 12× lower cross‑seed variance vs. mink)
- Assumptions/dependencies: Compatible RL stack (e.g., Isaac Gym/Sim, Mujoco); accurate contact modeling; consistent reference frame conventions
- GPU ESDF/TSDF as a standalone perception module for manipulation
- Sectors: robotics platforms (mobile manipulators, stationary cells), digital twins/simulation
- Tools/products/workflows:
- ROS2 node that fuses depth + known CAD into a dense ESDF covering the full workspace
- Task‑tuned ESDF generation (e.g., 5 mm for grasping; coarser for bases) to balance accuracy and memory
- Why now: Voxel‑project integration eliminates atomic contention; CUDA‑graph‑capturable ESDF pipeline with gather seeding and PBA+
- Assumptions/dependencies: Sufficient GPU memory for TSDF blocks and ESDF grid; watertightness of analytic geometry for sign recovery beyond truncation band
- Accelerated self‑collision and kinematics for complex robots
- Sectors: bimanual workcells, humanoid prototypes, exoskeleton R&D
- Tools/products/workflows:
- Whole‑body map‑reduce self‑collision and sparse Jacobians for branching trees and mimic joints
- Faster inner loops for optimization and control (reported up to 61× speedup in whole‑body compute)
- Assumptions/dependencies: Curated collision spheres/pairs; robust topology cache generation; real‑time GPU scheduling on robot controller
- LLM‑assisted robotics development workflows
- Sectors: software engineering for robotics, toolchain vendors
- Tools/products/workflows:
- Coding guidelines and repository structures that enable LLMs to author or refactor CUDA kernels and modules (up to 73% of new modules in the report)
- CI pipelines with auto‑generated tests/benchmarks for LLM‑proposed kernels
- Assumptions/dependencies: Strong codebase modularity; human‑in‑the‑loop review; reproducible perf tests; IP/compliance policies for LLM use
- Education and rapid prototyping
- Sectors: higher education, robotics bootcamps, startup prototyping
- Tools/products/workflows:
- Teaching labs demonstrating B‑spline vs. waypoint planners with torque constraints
- Course modules on GPU distance fields and parallel kinematics/dynamics
- Assumptions/dependencies: Access to commodity GPUs (e.g., RTX 3060+ or Jetson), depth sensors, and open URDFs
Long‑Term Applications
The following applications require additional research, scaling, validation, or standardization before broad deployment.
- Certified safety stacks for torque‑aware, vision‑in‑the‑loop motion generation
- Sectors: industrial safety, medical robotics, consumer cobots
- Tools/products/workflows:
- Safety‑certifiable ESDF‑based collision checking with worst‑case error bounds and formal verification of B‑spline controllers
- Redundant sensing and fail‑safe fallbacks coupled to torque‑limit enforcement
- Dependencies/assumptions: Certification evidence (e.g., ISO 10218/TS 15066), bounded perception latency and ESDF error, deterministic GPU scheduling, formal analyses of swept‑volume approximations
- General‑purpose household humanoids and mobile manipulation
- Sectors: consumer robotics, eldercare, hospitality
- Tools/products/workflows:
- Unified whole‑body planning and reactive control in unstructured, cluttered homes with continuous depth fusion
- Task libraries (tidying, fetching, assistive manipulation) with strong self‑collision and torque‑limit safety
- Dependencies/assumptions: Robust multi‑view perception and occlusion handling; affordable edge GPUs; long‑horizon failure recovery; reliable tactile/force sensing
- Plant‑scale ESDF mapping for fleets (shared collision maps)
- Sectors: logistics, warehousing, factories, construction sites
- Tools/products/workflows:
- Multi‑robot, cloud‑synchronized ESDFs supporting shared, O(1) distance queries across large workspaces
- Streaming updates with frustum/time decay tuned per zone; semantic layers (no‑go zones, human‑only aisles)
- Dependencies/assumptions: Network QoS, map consistency and versioning, privacy/security controls, scalable memory/computation at building scale
- Edge‑optimized deployment on embedded GPUs for mobile platforms
- Sectors: service robots, AGVs/AMRs, agriculture
- Tools/products/workflows:
- Memory‑aware ESDF/TSDF generators and kinematics tailored to Jetson‑class devices without sacrificing recall
- Power‑aware scheduling of perception/optimization kernels
- Dependencies/assumptions: Further kernel and memory layout optimization; thermal/power budgets; graceful degradation modes
- Semantic‑aware motion generation (geometry + semantics)
- Sectors: smart factories, healthcare facilities, retail
- Tools/products/workflows:
- ESDFs augmented with semantic cost layers (e.g., fragile areas, sterile zones) coupled to B‑spline optimizers
- Policy hooks to enforce facility rules or dynamic priorities
- Dependencies/assumptions: Reliable semantic perception; conflict resolution between geometric and semantic constraints; maintainable annotation pipelines
- Integrated learning‑planning pipelines with differentiable dynamics
- Sectors: autonomous systems R&D, animation and VFX, sports analytics
- Tools/products/workflows:
- Differentiable planners feeding RL/IL with high‑fidelity, constraint‑consistent trajectories
- End‑to‑end training that leverages GPU kinematics/dynamics for gradient flow through control objectives
- Dependencies/assumptions: Stable differentiable contact modeling; curriculum design to avoid local minima; sim‑to‑real transfer strategies
- Standardization of LLM‑in‑the‑loop robotics engineering
- Sectors: software tooling, enterprise robotics, governance
- Tools/products/workflows:
- Best‑practice guidelines (design patterns, test harnesses, perf baselines) for AI‑assisted kernel and systems development
- Audit trails and compliance frameworks for LLM contributions in safety‑relevant code
- Dependencies/assumptions: Organizational policies on AI code use; secure model hosting; tooling for provenance and regression detection
- Construction and field robotics with high‑DoF machinery
- Sectors: construction, mining, energy (maintenance)
- Tools/products/workflows:
- Whole‑body planning for articulated booms, excavators, and inspection manipulators in dynamic, partially known environments
- On‑the‑fly ESDF generation from lidar + depth, with torque‑limit‑aware actuation
- Dependencies/assumptions: Robust sensing in adverse conditions (dust, rain, sun); ruggedized compute; integration with heavy‑equipment safety systems
- AR/VR teleoperation with predictive, collision‑aware assistance
- Sectors: telepresence, surgical training simulators, remote inspection
- Tools/products/workflows:
- Predictive B‑spline assistance with ESDF‑based constraints to prevent collisions during human‑in‑the‑loop control
- Haptic feedback and visual cues derived from O(1) distance queries
- Dependencies/assumptions: Low‑latency comms; accurate environment reconstructions; human factors studies for acceptance/tuning
- Curricula and benchmarks for whole‑body motion generation
- Sectors: academia, standards bodies, open‑source communities
- Tools/products/workflows:
- Public suites comparing torque‑aware B‑splines vs. waypoint planners across high‑DoF tasks with standardized ESDF inputs
- Reference implementations fostering reproducibility and fair comparisons
- Dependencies/assumptions: Open datasets with depth, meshes, and ground‑truth; community adoption and maintenance
Cross‑cutting assumptions and dependencies to track
- Hardware: CUDA‑capable GPUs sized to task (memory headroom for TSDF blocks and ESDF grids); real‑time kernel scheduling constraints in embedded deployments.
- Perception: Calibrated, synchronized depth sensors; sign recovery relies on watertight CAD for reliable interior/exterior labeling beyond the truncation band.
- Modeling: Accurate URDFs (including mimic joints), torque limits, and collision geometry (sphere approximations and pairs).
- Safety: Facility‑specific safety controllers and standards compliance; formalization of worst‑case ESDF interpolation errors and swept‑volume approximations.
- Software: ROS2/MoveIt integration layers; CI/perf tests for LLM‑assisted code; reproducible benchmarks for optimization stability.
Glossary
- Atomic operations: Low-level synchronization primitives that ensure exclusive access when multiple threads write shared data; avoiding them can improve parallel performance. "no atomic operations are required."
- Axis-aligned bounding box: A bounding box whose faces are aligned with the coordinate axes, used for broad-phase collision and geometry stamping. "For each primitive, we compute its axis-aligned bounding box in voxel coordinates"
- B-spline: A piecewise polynomial basis for representing smooth curves with local control, used here to parameterize robot trajectories. "B-spline trajectory optimization"
- Block-sparse TSDF: A TSDF stored only in allocated voxel blocks near surfaces to save memory and compute. "a block-sparse TSDF that fuses depth and primitives into a persistent world model"
- CHOMP speed metric: A metric from the CHOMP planner that scales gradients by trajectory speed to improve collision recovery. "CHOMP speed metric"
- Coalesced memory writes: GPU memory access pattern where consecutive threads write to consecutive addresses, improving bandwidth utilization. "coalesced memory writes (adjacent threads write adjacent voxels)"
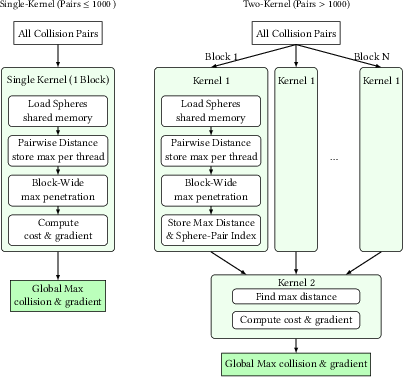
- Collision spheres: Spherical approximations of robot geometry used for fast collision queries. "the robot is approximated by collision spheres"
- Compare-And-Swap (CAS): An atomic instruction that updates memory only if it matches an expected value, used to safely insert into hash tables in parallel. "Compare-And-Swap (CAS) handling concurrent insertions."
- CUDA graph capture: A CUDA feature to record and replay a sequence of GPU operations with reduced launch overhead. "CUDA graph capture"
- CUDA streams: Independent command queues that allow concurrent kernel execution and data transfers on the GPU. "concurrently on separate CUDA streams"
- Device-to-host synchronization: A synchronization point that requires waiting for GPU work to finish so the CPU can read results. "requiring a device-to-host synchronization"
- Differentiable inverse dynamics: An inverse dynamics computation that supports gradient backpropagation, enabling torque-aware optimization. "differentiable inverse dynamics"
- ESDF (Euclidean Signed Distance Field): A grid storing the signed Euclidean distance to the nearest surface at each cell for fast collision queries. "a dense ESDF covering the full workspace"
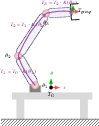
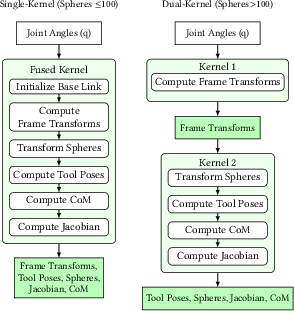
- Forward kinematics: Computing the positions and orientations of robot links from joint angles. "forward kinematics computes link poses and Jacobians"
- Frustum (camera frustum): The pyramidal volume defining what the camera can see, used here for visibility-aware updates/decay. "blocks within the current camera frustum"
- Hadamard product: Element-wise multiplication of vectors or matrices. "Notation: is the Hadamard product."
- Inverse dynamics: Computing joint torques required to achieve desired accelerations given robot dynamics. "computes the torques via inverse dynamics"
- Inverse kinematics (IK): Computing joint configurations that achieve a desired end-effector pose. "collision-free IK"
- Jacobian: The matrix of partial derivatives relating joint velocities to end-effector velocities; here computed sparsely for efficiency. "sparse Jacobian computation"
- Jump Flooding Algorithm (JFA): A parallel approximate method for distance transforms and Voronoi diagrams using multi-pass propagation. "approximate iterative methods such as JFA"
- L-BFGS: A limited-memory quasi-Newton optimization method suitable for large-scale smooth problems. "updates the B-spline control points via L-BFGS."
- Map-reduce (for self-collision): A parallel pattern that maps per-pair collision checks and reduces them to aggregate costs/gradients. "map-reduce self-collision"
- Maurer’s parabola intersection test: A linear-time method for exact 1D Euclidean distance transforms using parabola intersections. "Maurer's parabola intersection test"
- Model predictive control (MPC): A control strategy that repeatedly solves an optimization over a moving horizon and executes the first action. "model predictive control (MPC)"
- MPPI (Model Predictive Path Integral): A sampling-based MPC method that uses path integral control for trajectory optimization. "MPPI"
- nvblox: A GPU library for real-time volumetric mapping and ESDF computation. "nvblox"
- Parallel Banding Algorithm (PBA+): An exact, GPU-parallel algorithm for Euclidean distance transforms using separable sweeps. "Parallel Banding Algorithm (PBA+)"
- Probabilistically complete: A property of planning algorithms that guarantees finding a solution with probability approaching one as samples increase. "are probabilistically complete"
- Recursive Newton–Euler Algorithm (RNEA): A standard O(n) algorithm for computing inverse dynamics in articulated robots. "Recursive Newton-Euler Algorithm (RNEA)"
- Riemannian motion policies (RMPs): A framework for reactive motion generation that blends policies using Riemannian metrics for safety and stability. "Riemannian motion policies"
- Self-collision: Collisions between parts of the robot itself, which must be detected and avoided during motion. "self-collision"
- Signed distance field (SDF): A scalar field giving the signed distance to the closest surface at each point; negative inside, positive outside. "signed distance fields"
- Topology-aware kinematics: Kinematics computation that exploits the robot’s kinematic tree structure (e.g., ancestors/branches) for efficiency. "topology-aware kinematics"
- Torque limits: Actuator force/torque constraints that motions must respect to be physically feasible. "torque limits"
- Trilinear interpolation: Interpolation within a 3D grid cell using linear interpolation along three axes. "trilinear interpolation error"
- Truncation band: The region around observed surfaces within which TSDF values are updated; beyond it values are not integrated. "truncation band"
- TSDF (Truncated Signed Distance Field): A volumetric representation that stores truncated signed distances to surfaces for fusion of sensor data. "TSDF needs to represent millimeter-resolution geometry"
- Voxel-centric projection: A depth integration strategy where each voxel projects into the image to fetch its observation, eliminating write contention. "voxel-centric projection"
- Voronoi diagram: A partitioning of space into regions closest to each of a set of sites; used to derive exact distance fields. "the exact Voronoi diagram"
- Warp-level reduction: A GPU operation where threads within a warp cooperatively sum or reduce values efficiently. "warp-level reductions"
Collections
Sign up for free to add this paper to one or more collections.