- The paper introduces a unified RL framework that integrates teleoperation, mocap, and video data to teach mobile bimanual robots versatile manipulation skills.
- It employs a hybrid sim2real control strategy with closed-loop PnP localization, achieving a mean success rate of 67.8% and a +54% improvement over baselines.
- Key insights include high sample efficiency, effective DAgger-based vision policy distillation, and robust generalization to varied object geometries and environments.
HERMES: Human-to-Robot Embodied Learning from Multi-Source Motion Data for Mobile Dexterous Manipulation
Introduction and Motivation
HERMES presents a unified framework for mobile bimanual dexterous manipulation, leveraging heterogeneous human motion data sources—teleoperation, mocap, and raw video—to impart versatile manipulation skills to robots equipped with multi-fingered hands. The system addresses the embodiment gap and sim2real transfer challenges by integrating reinforcement learning (RL), vision-based policy distillation, and a closed-loop navigation-localization pipeline. The framework is designed to generalize across diverse, unstructured environments and complex manipulation tasks, with a focus on high sample efficiency and robust real-world deployment.

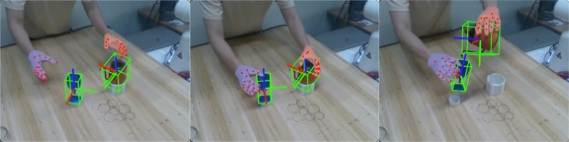
Figure 1: HERMES demonstrates a broad spectrum of mobile bimanual dexterous manipulation skills in real-world scenarios, learned from one-shot human motion.
System Architecture
HERMES comprises a mobile base, dual 6-DoF arms, and two 6-DoF dexterous hands, with high-fidelity simulation models constructed in MuJoCo and MJX. The simulation accurately models passive joints and collision dynamics using equality constraints and primitive shape approximations, facilitating stable and realistic training. The hardware setup includes RGBD and fisheye cameras for manipulation and navigation, respectively, and is controlled via ROS on an RTX 4090-equipped laptop.

Figure 2: Unified mobile bimanual robot setup in simulation and real world, enabling sim2real transfer for complex tasks.
Learning from Multi-Source Human Motion
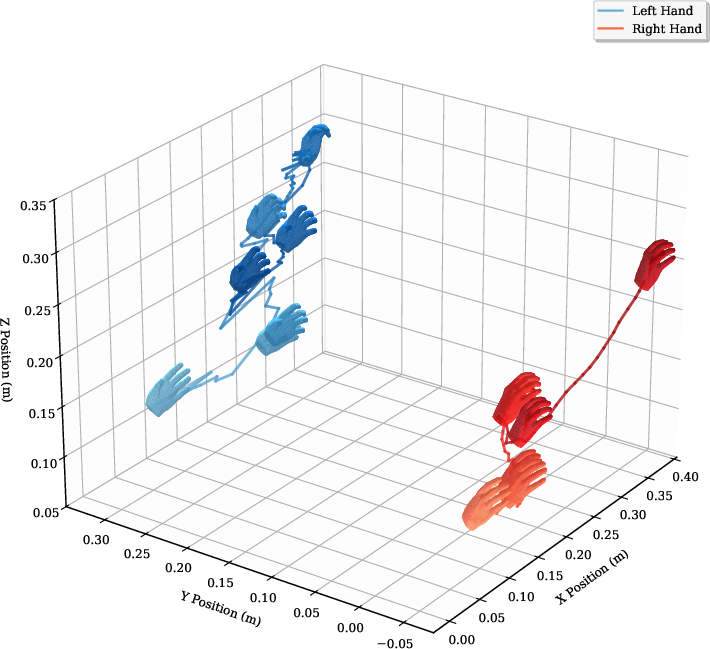
HERMES supports three modalities for human motion acquisition:
Trajectory augmentation is performed by randomizing object positions/orientations, enabling spatial generalization from a single demonstration. DexPilot is used for initial retargeting, followed by RL refinement.
Reinforcement Learning and Reward Design
Tasks are formulated as goal-conditioned MDPs, with state s including proprioception and goal state from the reference trajectory. The reward function is unified across tasks, comprising:
Residual action learning is employed: arm actions are decomposed into coarse (from human trajectory) and fine (network-predicted) components, while hand actions are fully network-driven. Early termination and collision disabling are used to improve exploration efficiency.
DrM (off-policy, dormant ratio) and PPO (on MJX for parallel training) are implemented, with high sample efficiency and cross-algorithm generality.
Vision-Based Sim2Real Transfer
State-based RL policies are distilled into vision-based policies via DAgger, using depth images as input. Depth augmentation includes clipping, Gaussian noise/blur, and mixup with NYU Depth Dataset, achieving semantic and distributional alignment between simulation and real-world depth maps.

Figure 6: Depth image comparison shows strong semantic correspondence between simulated and real-world representations after preprocessing.
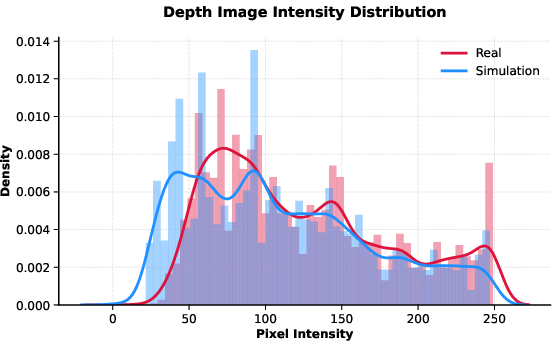
Figure 7: Depth intensity distributions from simulation and real-world images are closely aligned.
DAgger distillation uses stacked depth frames and a ResNet-18 encoder (with GroupNorm), with a rollout scheduler annealing expert/student policy usage. L1/L2 action losses and proprioception noise injection further improve generalization.
Hybrid Sim2Real Control
A hybrid control strategy is adopted: real-world observations infer actions, which are executed in simulation to compute joint values, then mapped to the real robot. This maintains dynamic consistency and mitigates sim2real discrepancies.
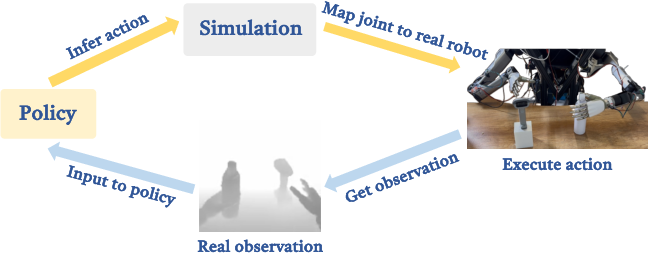
Figure 8: Hybrid sim2real control leverages real-world observations for action inference and simulation for joint computation.
Navigation and Localization
ViNT is used for image-goal navigation, supporting long-horizon, zero-shot generalization. However, ViNT alone does not guarantee precise pose alignment. HERMES introduces a closed-loop PnP localization step:
Experimental Results
Sample Efficiency and Generalization
HERMES demonstrates high sample efficiency across seven tasks, outperforming ObjDex in both single-object and multi-object scenarios. RL-based policies significantly outperform kinematic retargeting and direct replay, especially under randomized object poses.
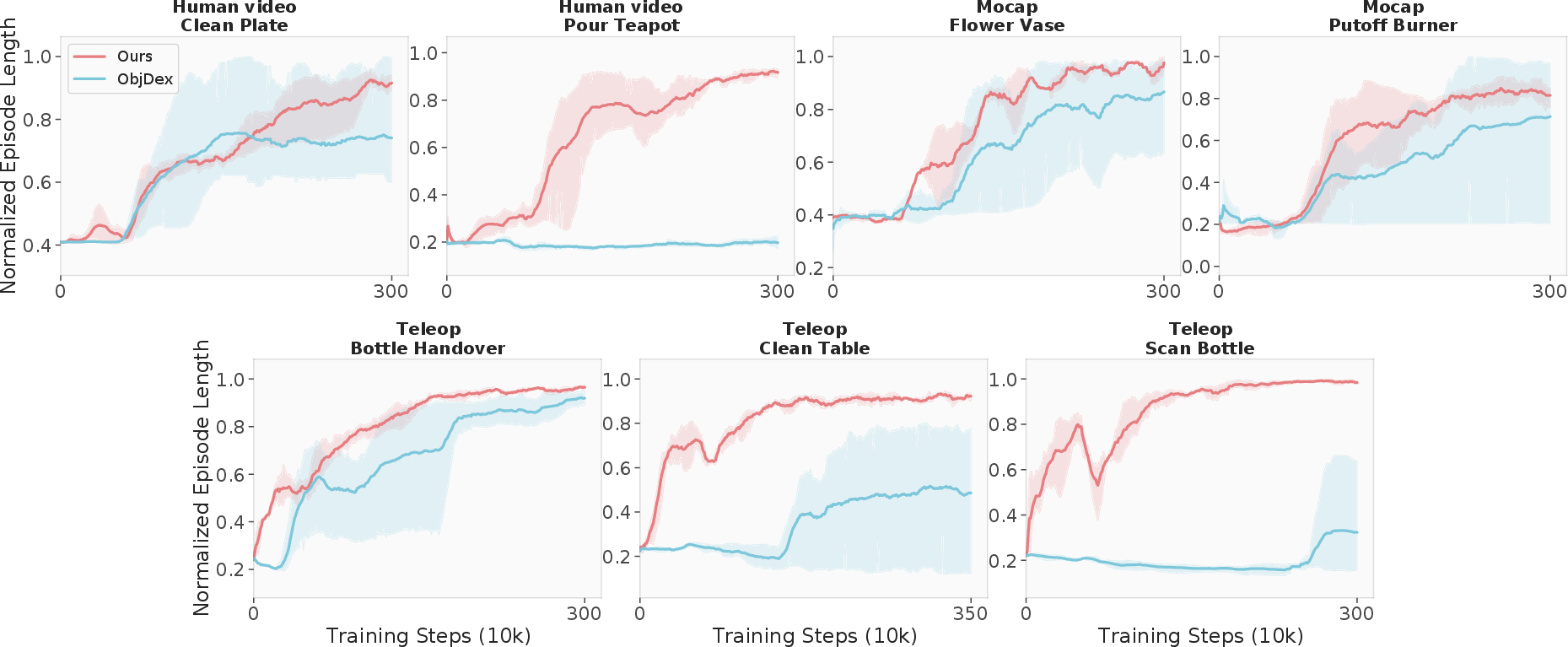
Figure 10: Training curves show HERMES achieves superior sample efficiency and task completion across diverse human motion sources.
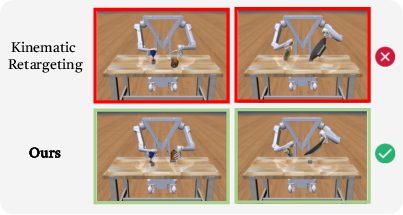
Figure 11: HERMES learns nuanced object interactions beyond kinematic retargeting.
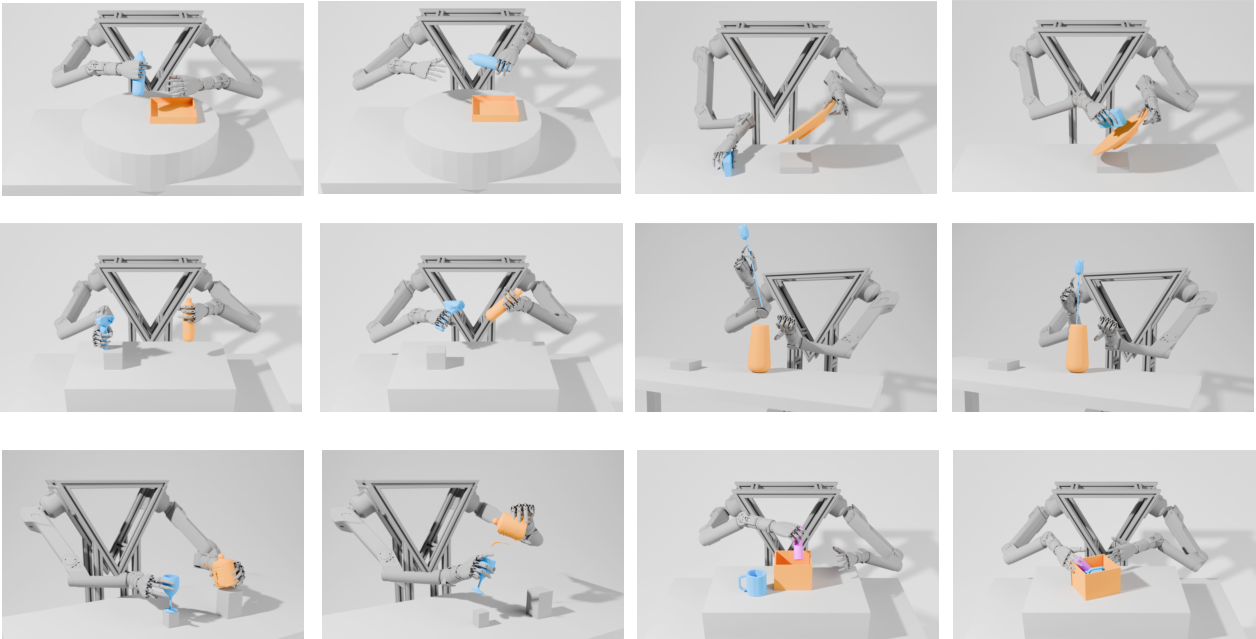
Figure 12: Simulation visualizations of diverse training tasks from single reference trajectories.
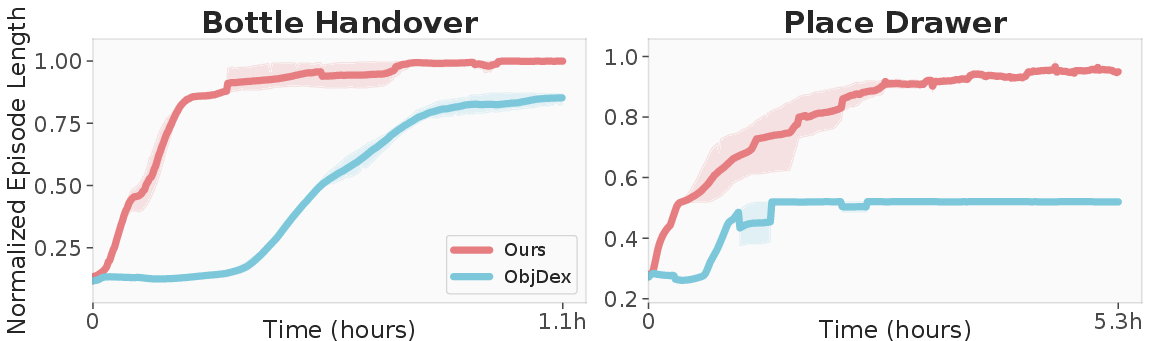
Figure 13: Parallel training in MJX yields high wall-time efficiency and strong asymptotic performance.
Real-World Manipulation and Sim2Real Transfer
Zero-shot transfer of DAgger-trained policies achieves a mean success rate of 67.8% across six real-world bimanual tasks, outperforming raw depth baselines by +54.5%. Fine-tuning is only required for tasks with high visual noise or transparent objects.
Navigation and Localization Accuracy
Closed-loop PnP reduces localization errors to 1.3–3.2 cm (translation) and 0.57–2.06° (orientation), outperforming ViNT and RGBD-SLAM (RTAB-MAP) especially in textureless scenarios.

Figure 14: HERMES achieves close alignment of terminal and target point clouds, outperforming ViNT in localization accuracy.

Figure 15: HERMES maintains precise localization in environments with sparse visual features.
Mobile Manipulation
End-to-end evaluation shows HERMES achieves a +54% improvement in manipulation success rate over ViNT-only localization, demonstrating the necessity of closed-loop PnP for bridging navigation and manipulation.
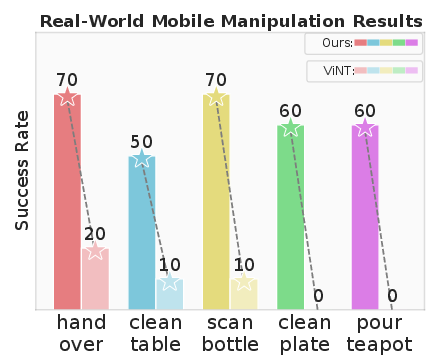
Figure 16: HERMES outperforms ViNT-only baseline in real-world mobile bimanual manipulation tasks.
Instance Generalization
Object geometry randomization during training enables zero-shot generalization to novel object shapes.

Figure 17: Policy adapts to randomized object geometries for robust manipulation.
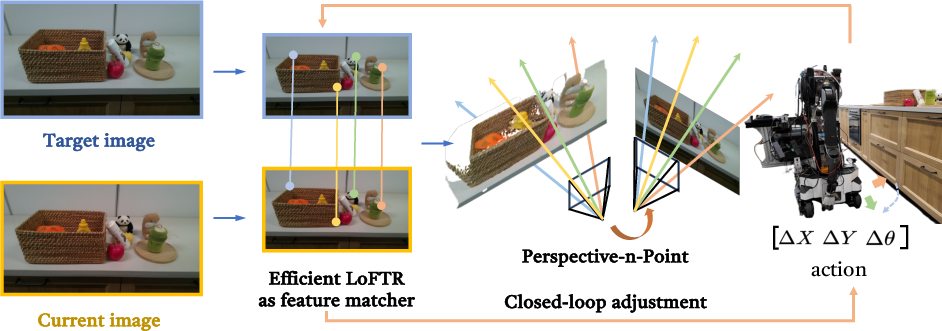
Closed-Loop PnP and Feature Matching
Iterative closed-loop PnP achieves high-precision pose alignment across scenarios.

Figure 18: Closed-loop PnP visualization shows iterative refinement of robot pose.
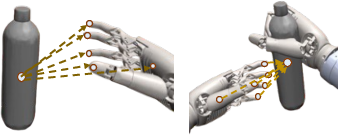
Efficient LoFTR provides dense, high-frequency feature correspondences for robust PnP estimation.

Figure 19: Efficient LoFTR establishes dense correspondences for PnP pose estimation.
DAgger Training Efficiency
HERMES attains high sample efficiency and asymptotic performance across task types, outperforming pure imitation and student training.
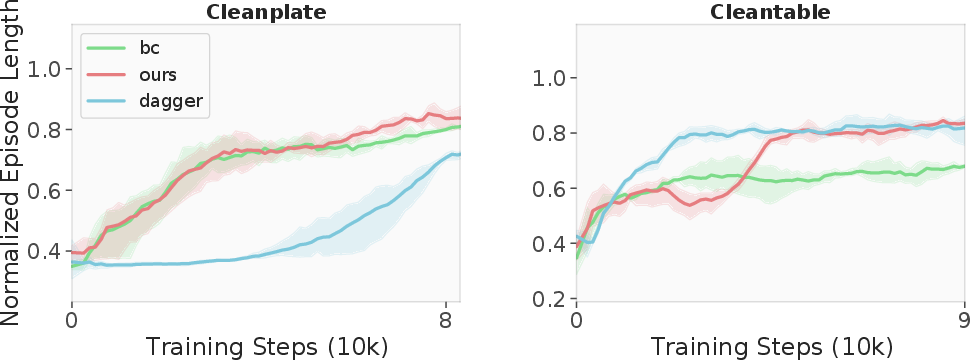
Figure 20: DAgger training curves demonstrate sample efficiency and robust performance.
Hybrid Control Consistency
Hybrid control maintains consistent joint dynamics between simulation and real robot, reducing sim2real gaps.
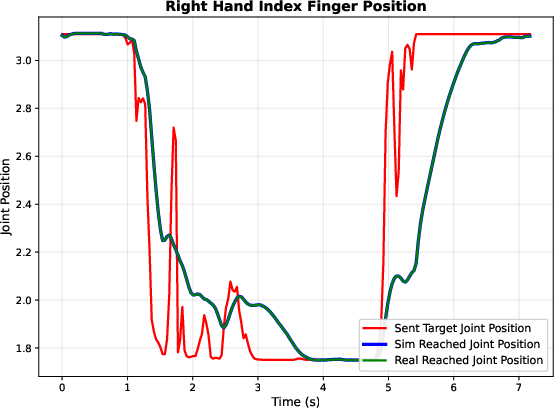
Figure 21: Hybrid control aligns simulated and real joint trajectories, minimizing dynamic discrepancies.
Depth-Anything Comparison
Depth-Anything achieves semantic alignment but exhibits quantitative distributional gaps, resulting in lower success rates compared to HERMES’s direct depth augmentation.

Figure 22: Depth-Anything generates semantically aligned depth images between simulation and real world.
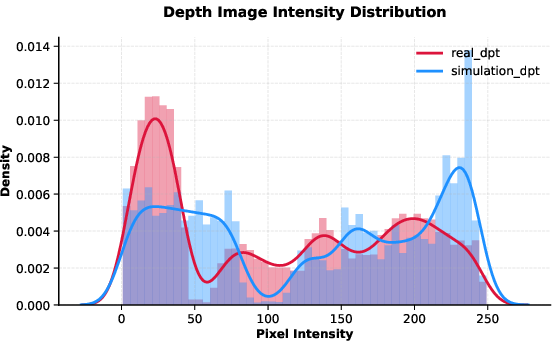
Figure 23: Depth-Anything depth maps reveal pronounced quantitative gaps between domains.
Implications and Future Directions
HERMES demonstrates that unified RL-based frameworks, leveraging diverse human motion sources and robust sim2real transfer, can endow mobile bimanual robots with generalizable dexterous manipulation skills. The closed-loop PnP localization is critical for bridging navigation and manipulation, especially in unstructured and textureless environments. The hybrid control strategy and depth-based vision pipeline are effective for mitigating sim2real gaps.
Limitations include reliance on quasi-static tasks, manual tuning of collision parameters, and hardware-simulation calibration mismatches. Future work should address dynamic tasks, automate simulation setup, and improve hardware robustness.
Conclusion
HERMES establishes a comprehensive pipeline for mobile bimanual dexterous manipulation, integrating multi-source human motion learning, RL-based policy refinement, vision-based sim2real transfer, and closed-loop navigation-localization. The framework achieves high sample efficiency, robust sim2real transfer, and strong generalization in real-world scenarios, providing a solid foundation for future research in embodied robot learning and mobile manipulation.