- The paper introduces a fast, tool-aware collision avoidance system that leverages learned perception and constrained RL integrated with classical IK to achieve real-time safety and precision.
- The paper demonstrates superior performance over traditional methods by reducing collision rates and computational load through holistic scene encoding.
- The modular design adapts to diverse tool geometries and interaction modes, making it ideal for dynamic, contact-rich human-robot collaboration.
Introduction
This paper presents a modular collision avoidance system for collaborative robots that adapts in real time to varying tool geometries and interaction modes. The system leverages a learned perception model to process raw point cloud data, enabling robust reasoning about occluded regions and dynamic obstacles. A constrained reinforcement learning (RL) policy, integrated with a classical inverse kinematics (IK) controller, ensures both high precision and rapid responsiveness. The approach is validated in both simulation and real-world experiments, demonstrating superior performance over traditional methods in dynamic, contact-rich environments.

Figure 1: The system manages robot-environment interactions by switching contact permissions based on the interaction mode input.
System Architecture
The proposed system consists of three main components: a 3D CNN-based encoder-decoder for scene representation, a safety critic for collision risk estimation, and a constrained RL policy for reactive control. The encoder processes workspace occupancy and proprioceptive inputs, filtering out robot and tool components from the point cloud. The safety critic outputs a scalar collision risk value, which determines whether the RL policy or the IK controller is used for motion generation.
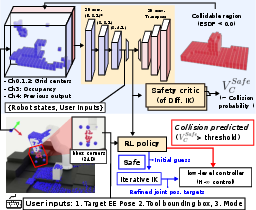
Figure 2: System overview showing the interplay between RL policy, IK solver, 3D CNN encoder, and safety critic.
The RL policy operates at 50 Hz, generating joint position residuals. When the safety critic value exceeds a threshold (0.8), the system switches to the RL policy for collision avoidance; otherwise, the IK controller refines the RL output for high-precision tracking.
The safety critic estimates the discounted probability of future constraint violations using a value iteration approach. For each constraint (body and tool collisions), the critic computes:
$V^{safe}_{C_i}(s_t) = c_i(s_t) + (1 - c_i(s_t)) \sum_{t'>t}^T \mathbb{E}\left[\gamma^{t'-t} c_i(s_{t'})\right}$
where ci is an indicator function for constraint violation. The overall risk is the maximum of the body and tool safety values.
The RL policy is trained using the Penalized Proximal Policy Optimization (P3O) algorithm within a Constrained Markov Decision Process (CMDP) framework. The action space consists of joint position residuals, and the observation space includes joint history, latent scene representation, and target end-effector pose. The reward function encourages pose tracking and smoothness, while cost functions penalize collisions, tool region violations, and speed limit breaches.
The system supports variable tool geometries by defining a bounding box attached to the end-effector, randomized during training. In Engage mode, the tool is permitted to contact the environment; in Protective mode, both robot and tool contacts are prohibited. The safety critic and policy adapt their behavior based on the current mode and tool configuration.

Figure 3: Experimental setup and tool-adaptive collision avoidance behaviors in Engage and Protective modes, with corresponding tool center trajectories and safety critic values.
Perception Model and Scene Representation
The encoder-decoder model reconstructs occupancy grids from raw point clouds, robustly filtering out robot and tool points. This approach eliminates the need for explicit filtering and hand-crafted occlusion heuristics, enabling reliable operation under partial observability.

Figure 4: Visualization of raw point cloud and estimated collidable regions at different trajectory points.
Comparative experiments show that end-to-end RL and pretrained autoencoders yield higher collision rates and lower success rates than the proposed method. Explicit mapping approaches suffer from perception uncertainties, especially near the robot and tool.
Experimental Evaluation
Real-World Setup
Experiments were conducted on an Indy7 collaborative arm with a two-finger gripper and a single Intel RealSense D435 depth camera. The system operates at 50 Hz, with an average action update time of 6 ms and model inference time of 1.3 ms. Point cloud processing is parallelized, averaging 7.9 ms per cycle.
Precision and Adaptivity
Task-space tracking errors were measured across different tool configurations. In open areas, errors remain at sub-millimeter levels; near obstacles, errors increase as collision avoidance is activated. Larger tool regions result in expanded high-error zones, demonstrating adaptive behavior.

Figure 5: Resource usage comparison showing the proposed system's lower computational and memory requirements relative to Curobo.
Baseline Comparisons
The system was compared against APF and MPPI controllers with various perception methods (convex hull, learned SDF). In dynamic obstacle scenarios, the proposed method achieves comparable or lower collision rates and higher success rates, especially under partial observability. APF suffers from local minima and oscillations, while MPPI struggles with responsiveness in dynamic settings. Convex hull approximations are vulnerable to occlusions, leading to underestimated obstacle sizes and increased collisions.
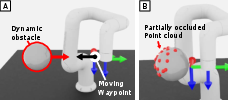
Figure 6: Dynamic obstacle avoidance experiment setup and point cloud visualization.
Scalability
Unlike traditional methods whose runtime scales with the number of obstacles, the proposed approach maintains constant per-cycle runtime due to holistic scene encoding. GPU memory usage is an order of magnitude lower than Curobo, and planning latency is reduced from hundreds of milliseconds to under 10 ms.
Implications and Future Directions
The integration of constrained RL with classical control enables a balance between responsiveness and precision, supporting real-time operation in dynamic, contact-rich environments. The tool-aware design allows seamless adaptation to diverse end-effector geometries and interaction modes, facilitating safe human-robot collaboration.
Theoretical implications include the demonstration of CMDP-based RL for high-dimensional, safety-critical manipulation tasks, and the efficacy of learned scene representations for robust perception under occlusion.
Future work may extend the system to mobile manipulators, multi-robot coordination, and integration with dexterous manipulation frameworks such as ALOHA. Further research into distributional critics and risk-aware RL could enhance safety in rare-event scenarios.
Conclusion
This paper introduces a fast, adaptive collision avoidance system for collaborative robots, combining learned perception, safety critics, and constrained RL with classical control. The approach achieves high precision, low latency, and robust performance in dynamic environments, outperforming traditional baselines in both collision rate and computational efficiency. The modular design and tool-aware capabilities position the system as a practical solution for safe, responsive robot operation in real-world settings.