- The paper introduces an innovative hybrid control architecture that combines GPU-accelerated kinodynamic MPC with a residual RL policy for torques.
- It employs GPU-parallelized MPC to solve thousands of concurrent kinodynamic optimizations, ensuring real-time feasibility on legged robots.
- Empirical evaluations show improved sample efficiency, broader command tracking, and robust sim-to-real performance over traditional methods.
Residual MPC: Integrating Reinforcement Learning with GPU-Parallelized Model Predictive Control
Introduction
This paper presents a unified control architecture that tightly integrates Model Predictive Control (MPC) and Reinforcement Learning (RL) for robust, adaptive locomotion in legged robots. The approach leverages a GPU-parallelized, kinodynamic whole-body MPC as a strong, interpretable control prior, while a residual policy—trained via RL—learns to make targeted corrections at the torque level. This architecture is designed to combine the interpretability, constraint handling, and physical grounding of MPC with the robustness and adaptability of RL, addressing the limitations of each paradigm in isolation.

Figure 1: Simulated locomotion for MPC (left, grey) and the residual policy (right, orange) at velocity commands of 2.25 m/s and -1.5 rad/s. The MPC controller fails due to self-collision, while the residual policy stabilizes the robot.
Residual Policy Architecture
The core of the proposed method is a parallel residual policy architecture, where the outputs of a fixed MPC controller and a learned policy are blended at the torque-control level. Both the MPC and the residual policy are evaluated at 100 Hz, and their outputs are combined downstream using a scaling factor λ on the policy output. The MPC solution is converted into desired torques, joint positions, and velocities via inverse dynamics, and the blending occurs before actuation.
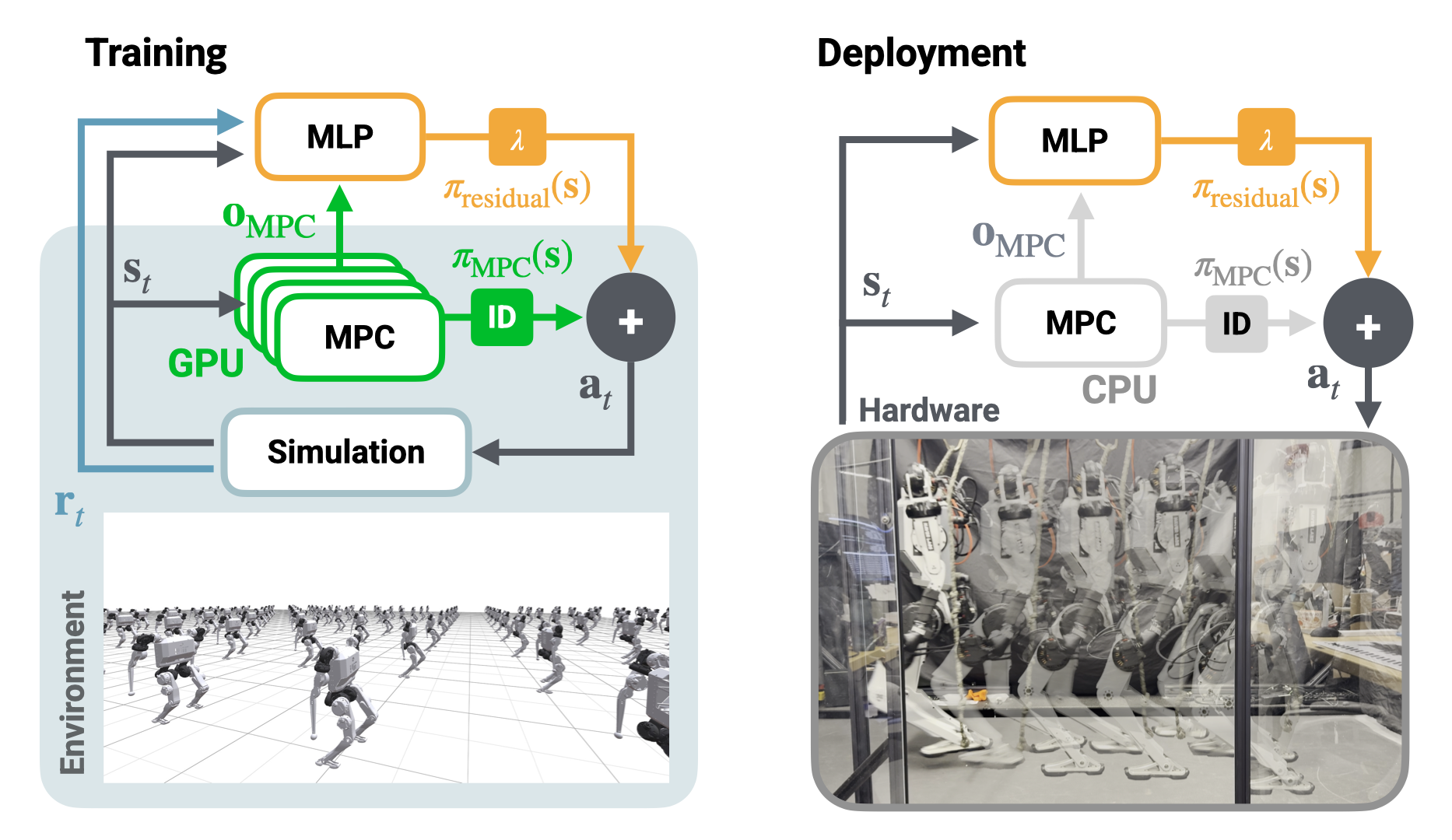
Figure 2: Diagram of the proposed residual policy architecture during training and deployment, showing concurrent evaluation and blending of MPC and residual policy outputs.
The residual policy is implemented as a three-layer MLP (256 ELU units per layer), observing the full robot state, contact phase, and a value from the MPC. The action space is restricted to leg torques, with blending strategies carefully designed to ensure stability at initialization and effective learning.
A key technical contribution is the development of a kinodynamic whole-body MPC formulation that is efficiently parallelized for GPU execution. The MPC optimizes over generalized coordinates, velocities, and ground reaction forces, subject to floating-base dynamics, contact constraints, swing trajectories (parametrized by Bezier curves), and joint limits. The optimization is solved using a real-time iteration scheme with a single SQP iteration per solve, reducing the problem to a QP addressed via OSQP's ADMM-based solver.

Figure 3: Visualized predictions for the MPC formulation, with swing foot trajectories parametrized by Bezier curves.
Parallelization is achieved using the CusADi code-generation framework and NVIDIA's cuDSS library for sparse LDL factorization and linear solves. This enables thousands of MPC instances to be solved concurrently on the GPU, making in-the-loop training with high-frequency MPC feasible.
Training and Blending Strategies
The RL component is trained using PPO with GAE, leveraging IsaacGym for fast simulation. The reward design is intentionally minimal, focusing on standard locomotion objectives and including sparse, non-differentiable penalties (e.g., self-collision, termination) that are difficult to encode in MPC. Three blending strategies are evaluated: joint action/joint blending, joint action/torque blending, and torque action/torque blending. Empirically, joint-space action representations yield superior learning dynamics compared to torque-space actions.
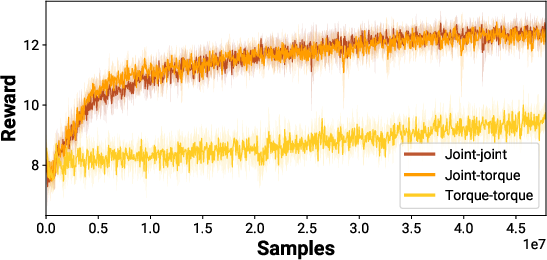
Figure 4: Reward comparison of three different blending strategies between MPC and the residual policy. Torque-space action representation performs significantly worse.
Sample Efficiency and Policy Behavior
The residual architecture demonstrates improved sample efficiency and higher asymptotic rewards compared to end-to-end RL, despite increased wall-clock training time due to the computational cost of parallelized MPC. The MPC prior biases exploration toward physically plausible behaviors, reducing the need for extensive reward engineering and mitigating the risk of the policy exploiting simulation artifacts.
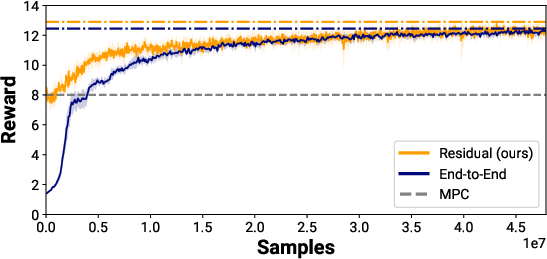
Figure 5: The reward incurred during training between the residual and end-to-end controllers. The residual architecture shows improved sample efficiency and asymptotic performance.
Qualitative analysis reveals that end-to-end RL policies often exploit simulation idiosyncrasies (e.g., "gliding" gaits), while the residual policy produces more realistic, hardware-viable locomotion. UMAP visualizations of the state distributions confirm that the residual policy remains close to the MPC-induced state manifold, while end-to-end RL diverges significantly.
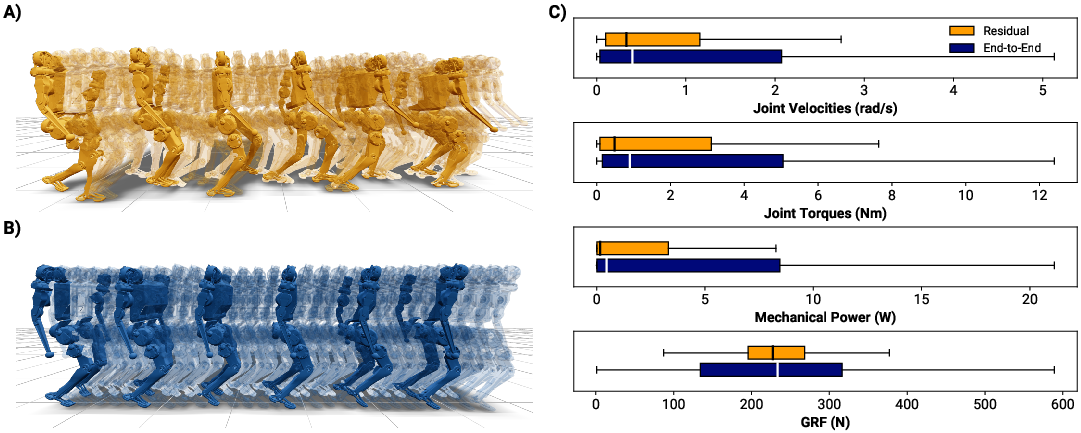
Figure 6: A) Snapshots of the residual policy in motion. B) End-to-end policy exhibits unrealistic "gliding". C) Residual policy shows lower medians and spreads in key metrics, indicating better sim-to-real transfer.
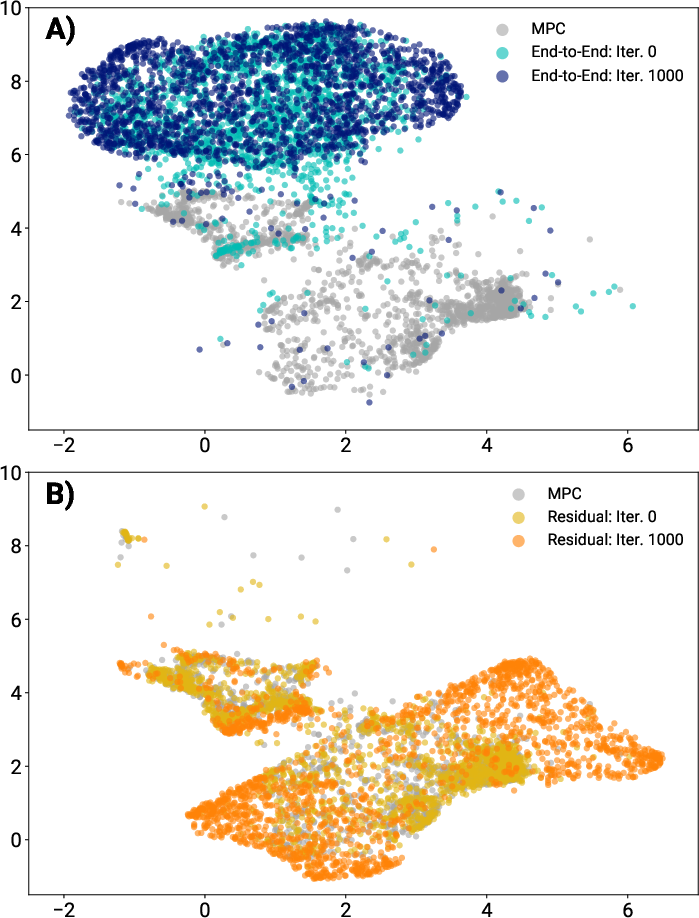
Figure 7: UMAP visualization of state distributions during training. The residual policy remains close to the MPC state manifold.
The residual policy substantially expands the range of trackable velocity commands compared to the MPC baseline (e.g., 78% improvement in vx), and matches or exceeds the performance of end-to-end RL in terms of command tracking. Notably, the residual policy enables zero-shot adaptation to out-of-distribution gaits (e.g., double stance, flight phases) and unseen terrain, despite being trained only on flat ground.
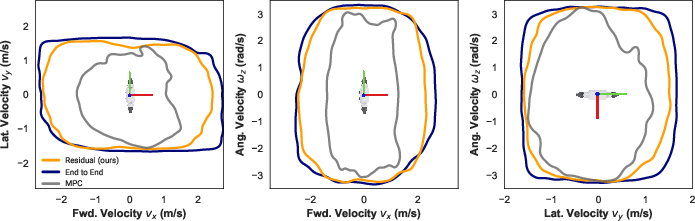
Figure 8: 95% kernel density estimate boundaries of trackable velocities. The residual policy network substantially improves the viable range of commands over the MPC baseline.

Figure 9: The residual policy adapts to novel gait parameters (double stance, flight phase) not seen during training.

Figure 10: The residual policy traverses unseen terrain, including uneven and sloped surfaces, without retraining.
Hardware validation confirms that the residual policy transfers to physical platforms, with successful demonstrations of forward, lateral, and turning locomotion.

Figure 11: Hardware validation of the residual policy architecture for forward, lateral, and turning locomotion.
Analysis of Residual-MPC Interaction
Detailed analysis of the residual and MPC torque outputs reveals that the residual policy is leveraged asymmetrically, with higher contribution for certain velocity commands (notably forward walking). The residual torques are often antagonistic to the MPC torques, especially near contact switches, suggesting that the learned corrections are critical for handling contact transitions and unmodeled dynamics.
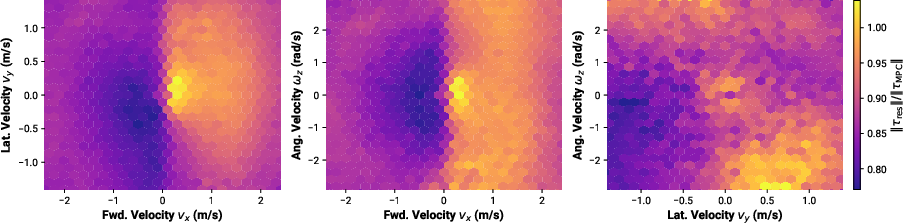
Figure 12: The ratio of residual to MPC torque magnitudes over commanded velocities, showing asymmetric leverage.
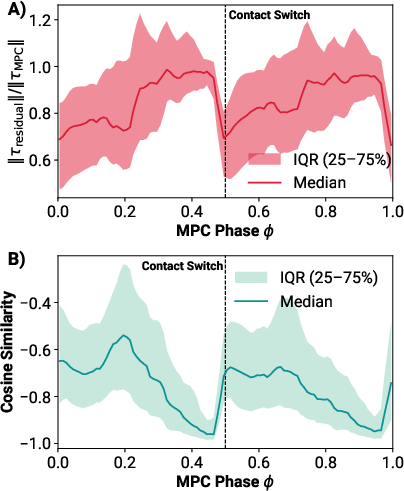
Figure 13: A) Percentage of torque from the residual as a function of phase. B) Cosine similarity between residual and MPC torques, indicating antagonism near contact switches.
On uneven terrain, the residual policy exhibits emergent behaviors such as toe-off and heel touchdown, adapting the contact strategy beyond what is encoded in the MPC.

Figure 14: Analysis of residual and MPC data over uneven terrain. The residual policy exhibits emergent toe-off and heel touchdown behavior.
Computational Considerations
While the GPU-parallelized MPC enables in-the-loop training, it incurs significant computational overhead. For 1,000 environments, a single simulation step takes approximately 0.5 seconds, making training 8x slower than end-to-end RL. However, the improved sample efficiency and policy quality justify the additional cost for applications where safety and sim-to-real transfer are critical.
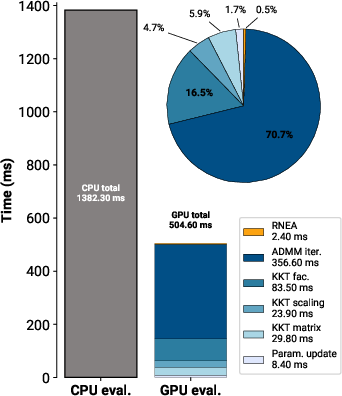
Figure 15: Computation time for evaluating the full MPC controller on CPU and GPU across 1,000 environments. GPU evaluation is ~2.5x faster than CPU.
Implications and Future Directions
This work demonstrates that embedding a high-frequency, GPU-parallelized MPC within an RL training loop is feasible and beneficial for legged locomotion. The residual architecture provides a principled mechanism for combining model-based and data-driven control, yielding policies that are robust, interpretable, and adaptable. The approach reduces reliance on reward engineering and manual curriculum design, and enables rapid adaptation to novel tasks and environments.
Theoretically, the results suggest that strong model-based priors can regularize RL training, biasing exploration toward desirable regions of the state space and mitigating the risk of converging to aphysical solutions. Practically, the architecture is validated both in simulation and on hardware, with evidence of improved sim-to-real transfer.
Future work includes extending the residual network to output MPC parameters (e.g., cost weights, contact schedules), leveraging the MPC value function for uncertainty estimation, and designing network architectures that mimic the structure of MPC solvers to further reduce computational cost.
Conclusion
The integration of GPU-parallelized MPC with RL via a residual policy architecture offers a compelling solution for robust, adaptive, and interpretable locomotion control. The approach achieves superior sample efficiency, broader command tracking, and enhanced generalization compared to standalone MPC or end-to-end RL. The findings underscore the value of combining model-based and learning-based methods, and open avenues for further research in scalable, hybrid control architectures for complex robotic systems.