- The paper introduces a sample-based probabilistic framework on SE(3) to estimate full 6D pose posteriors, addressing ambiguity from occlusion and symmetry.
- It integrates RGB-D inputs using transformers with mask-guided attention and fused visual-geometric features for efficient, robust pose estimation.
- Experimental results show improved grasp success rates from 75% to 95% and real-time performance in challenging, uncertain environments.
SE(3)-PoseFlow: Uncertainty-Aware 6D Pose Estimation for Robust Robotic Manipulation
Introduction and Motivation
6D object pose estimation under partial observability, occlusion, and symmetry remains a core problem for perceptual robotics. Deterministic deep networks achieve strong accuracy in controlled settings but are inherently overconfident in ambiguous views, outputting a single "best guess" even in the presence of geometric symmetries or heavy occlusion. This overconfidence leads to unreliable planning, unsafe grasping, and brittle closed-loop control. SE(3)-PoseFlow tackles pose ambiguity by introducing a probabilistic, sample-based framework leveraging flow matching on the SE(3) manifold to estimate the full posterior over object pose given RGB-D input, rather than a single hypothesis. The method tightly integrates geometric and visual signals and enables robotic agents to reason about uncertainty to actively resolve ambiguity or synthesize robust grasps.

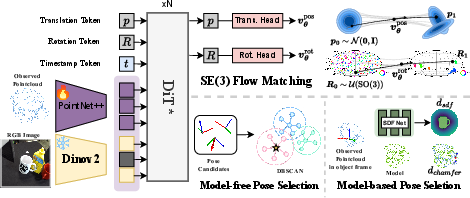
Figure 1: Uncertainty-aware 6D object pose estimation via SE(3) flow matching, visualizing pose ambiguity on real examples and enabling robust downstream robotic decisions in unconstrained scenes.
Pipeline Architecture and Implementation
At its core, SE(3)-PoseFlow implements a generative flow-matching model on the SE(3) group, conditioned on dense point cloud and image features. The practical pipeline integrates both frozen, high-capacity visual encoders and learned geometric representations with a transformer-style fusion backbone and a SE(3) flow head. The core components are as follows:
Implementation Details
- Training occurs on key category- and instance-level datasets (Real275, YCB-V, LM-O) with synchronized point cloud and image inputs.
- The PointNet++ encoder is trained from scratch, while DINOv2 is frozen—critical to ensure transfer and robust high-level semantics.
- Masked attention is implemented to ensure background clutter does not corrupt pose token attention.
- Flow matching loss is optimized over uniform random pose pairs; velocity losses are weighted (λ=10) to calibrate translation/rotation scales.
- Inference involves running K rollouts per detection (typically K=50) with fast ODE-based integration for each sample.
Flow Matching on SE(3): Mathematical and Practical Properties
SE(3)-PoseFlow leverages manifold-aware flow matching. Rather than score-based diffusion (which suffers on non-Euclidean SO(3)/SE(3) due to intractable normalization constants and inefficiency in multi-modality), flow matching provides efficient, simulation-free, closed-form ODE integration:
pt=(1−t)p0+tp1,Rt=R0exp(t⋅log(R0⊤R1))
The network learns conditional velocities matching the true flow from t to $1$ given the current pose and observation. Supervision is on vector fields in SE(3), overcoming the need for expensive mixture models or Bingham/vMF parameterizations. Training is parallelizable, and inference can exploit fast ODE integration (few steps suffice). The resulting model:
- Efficiently handles complex, multi-modal pose distributions, as required for symmetries/occlusion.
- Avoids likelihood normalization headaches (unlike SO(3) mixture Bingham/vMF).
- Supports natural sample-based downstream uncertainty quantification.
Pose Selection and Downstream Decision-Making
SE(3)-PoseFlow supports modular pose selection by:
- Model-Free Clustering: DBSCAN in SE(3) using a hybrid geodesic distance. The Karcher mean extracts consensus without model dependencies, enabling symmetry-aware multi-modality.
- Model-Based Scoring: For applications with 3D geometry, hypothesized poses are ranked by Chamfer or SDF losses, further filtering out outlier modes and refining alignment to the observed point cloud. When dense SDF supervision is available, this scoring produces both higher precision for tight-threshold accuracy and better transfer to robotic execution.
The sample-based pose posterior is not just an intermediate: it can be directly leveraged for active perception, planning, and grasp synthesis.

Figure 3: Qualitative comparison of pose estimation results across benchmarks using SE(3)-PoseFlow, showing enhanced performance on ambiguous and real-world cases.
Exploiting Pose Distributions in Robotic Tasks
Active Perception
The covariance structure of sample-based pose hypotheses quantifies rotational and translational uncertainty in R3 and the tangent space of SO(3). Robots can actively select next-best views by minimizing expected pose covariance, adaptively placing the camera for maximal disambiguation. This allows closed-loop exploration under an information-theoretic objective, directly integrating probabilistic pose structure into viewpoint planning.
Uncertainty-Aware Grasp Synthesis
Robust grasp planning under pose uncertainty is made possible by marginalizing over the pose distribution at the function level---specifically, by averaging the velocity fields for grasp flow synthesis. Concretely, grasps are synthesized by EquiGraspFlow, marginalizing over pose samples rather than a single deterministic estimate. This produces high-probability grasps concentrated in pose-robust regions—favoring, for example, top-down grasps over ambiguous azimuths in occluded mugs, but restoring side grasps when ambiguity vanishes.
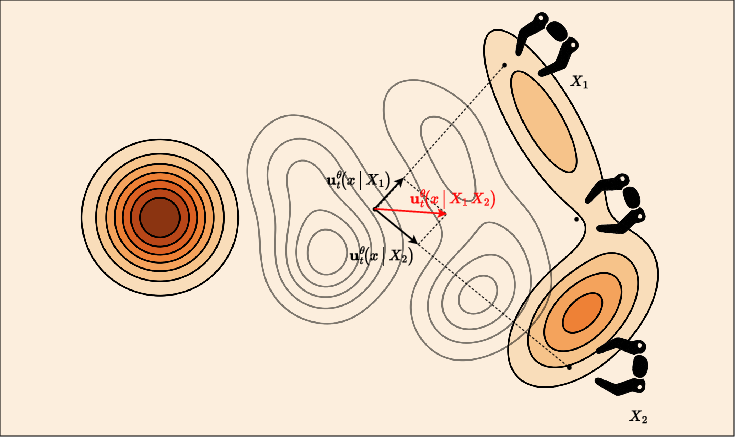
Figure 4: Averaging EquiGraspFlow velocities across pose hypotheses to yield robust mean grasp field, supressing unreliable modes tied to ambiguous geometry.

Figure 5: Uncertainty-aware mug grasping: Marginalized grasps remain robust in occluded, multi-modal pose settings but automatically specialize to target handle when unimodality is achieved.
Experimental Evaluation and Ablation
SE(3)-PoseFlow establishes state-of-the-art or strong competitive results on Real275, YCB-V, and LM-O across strict and relaxed 6D pose thresholds:
- Probabilistic methods (GenPose, SE(3)-PoseFlow) outperform deterministic baselines (e.g., NOCS) by a substantial margin, especially on 5°5cm, 10°5cm thresholds.
- Direct SE(3) hypothesis sampling produces more reliable multi-modal estimates than approaches requiring intermediate representations (NOCS maps).
- Ablation: Fusing RGB and point cloud, plus mask-based attention, outperforms unimodal and unmasked variants—critical for textured and cluttered scenes (YCB-V).
- Pose selection: Model-based (notably SDF) scoring elevates precision on high-fidelity datasets with mesh supervision; clustering provides robustness when geometry is unavailable.
- Inference efficiency: Fast ODE-based integration converges in few steps, enabling both pose estimation and tracking at real-time rates.
- Downstream grasping: Marginalizing grasp generation over the pose posterior increases physical grasp success from 75% (single mode) to 95% (multi-modal), eliminating failure in ambiguous configurations.
Trade-Offs, Resource Requirements, and Deployment
- Resource Constraints: The principal computational load lies in the transformer blocks and repeated ODE integration for multiple samples, but in practice, batch processing and efficient GPU ODE solvers yield near real-time performance.
- Distribution Modeling: Unlike generative diffusion methods, flow matching’s deterministic generative procedure is computationally lighter and more amenable to deployment on resource-limited robots.
- Limitations: Sample-based uncertainty is not a guarantee of calibrated Bayesian uncertainty; further work is required for online particle filtering and full Bayesian integration.
- Multi-Object Extension: The framework is currently single-object; joint pose distributions over multiple interacting objects pose scalability and sample complexity challenges.
- Modality Gap: The representation of images and point clouds remains disjoint; future work may benefit from unified point-based vision encoders.
Practical and Theoretical Implications
- Safe Manipulation: End-to-end propagation of pose ambiguity into grasp planning allows for integrated planning under uncertainty, reducing collision and failure risk without brittle hand-designed uncertainty propagation.
- Scalable Probabilistic Perception: Flow matching on SE(3) enables high-dimensional, sample-efficient posterior estimation on non-Euclidean manifolds—a foundation for future composable, scalable probabilistic scene representations in robotics and computer vision.
- Information-Theoretic Planning: Direct access to pose entropy allows for closed-loop, information-maximizing robot policies in active perception and manipulation.
- Generality: The approach supports both category- and instance-level pose estimation, and adapts to settings with or without mesh supervision, enabling broad applicability.
Future Directions
Key future advances include:
- Bayesian inference over pose distribution samples (e.g., SMC/particle filtering for tracking in continuous video).
- Multi-object scene models that scale flow-matching generative modeling to the combinatorial hypothesis space of real environments.
- Unified point-based (modality-agnostic) encoders to overcome vision–geometry fusion bottlenecks.
- Application of manifold flow matching to downstream control (e.g., end-to-end policy learning on SE(3) task spaces).
- Principled calibration of uncertainty estimates to facilitate verification and runtime safety guarantees.
Conclusion
SE(3)-PoseFlow provides a practical probabilistic 6D object pose estimation framework, efficiently sampling multi-modal pose hypotheses via flow matching on the SE(3) manifold. This enables practical, real-time reasoning about pose ambiguity in the face of symmetry and occlusion, supporting robust downstream manipulation planning and active perception. The method bridges recent geometric probability advances with scalable vision–geometry fusion, and demonstrates clear empirical gains and practical safety enhancements in real-world robotic systems.