Reasoning over mathematical objects: on-policy reward modeling and test time aggregation
Abstract: The ability to precisely derive mathematical objects is a core requirement for downstream STEM applications, including mathematics, physics, and chemistry, where reasoning must culminate in formally structured expressions. Yet, current LM evaluations of mathematical and scientific reasoning rely heavily on simplified answer formats such as numerical values or multiple choice options due to the convenience of automated assessment. In this paper we provide three contributions for improving reasoning over mathematical objects: (i) we build and release training data and benchmarks for deriving mathematical objects, the Principia suite; (ii) we provide training recipes with strong LLM-judges and verifiers, where we show that on-policy judge training boosts performance; (iii) we show how on-policy training can also be used to scale test-time compute via aggregation. We find that strong LMs such as Qwen3-235B and o3 struggle on Principia, while our training recipes can bring significant improvements over different LLM backbones, while simultaneously improving results on existing numerical and MCQA tasks, demonstrating cross-format generalization of reasoning abilities.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Reasoning over mathematical objects: a simple explanation
What this paper is about
This paper is about teaching AI models to do “real” math reasoning, not just picking answers from a list or giving a single number. In many science and engineering problems, the correct answer is a full mathematical object—like an equation, an inequality, an interval, a set, a matrix, or a piecewise function. The authors build new tests and training methods to help AI write these kinds of answers accurately.
What the researchers wanted to find out
The team set out to do three things:
- Create better tests and training data that force AI to produce complete math objects, not just multiple-choice picks or short numbers.
- Develop a new way to train AI using a strong “AI judge” that reads the full reasoning and decides which answers are better, trained in a way that matches how the AI will actually be used (“on-policy”).
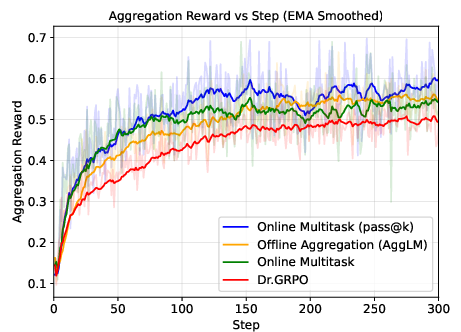
- Improve how AIs use extra thinking time at test time by having them generate several solutions in parallel and then combine them smartly, again trained in a way that matches real use.
How they did it (explained with simple ideas)
The work has three main parts. Below, whenever a technical term appears, it’s explained in everyday language.
1) The Principia suite: new data for “math object” answers
- PrincipiaBench: This is a test set with 2,558 problems where the answer has to be a full math object (like a matrix or a piecewise function). The authors removed multiple-choice options so models can’t “guess by elimination.” This makes the test closer to how people solve real math and science problems.
- Principia Collection: This is a training set with 248,000 synthetic (computer-generated) problems, built using official topic lists for math and physics (MSC 2020 and PhySH). Every problem requires one of six answer types: equations, inequalities, intervals, sets, matrices, or piecewise functions. The problems are designed to be at graduate (advanced) level, so they’re detailed and realistic.
How did they make sure answers were correct if the same math can be written in many ways? They used a “verifier,” which is like a grader that checks if two answers mean the same thing even if they look different.
- Rule-based verifiers (like symbolic math programs) struggled with different formats (for example, “-u/2” vs “(-1/2)u”).
- Model-based verifiers (a strong LLM acting as a judge) did much better at recognizing when two expressions are equivalent.
To prove which verifier is more reliable, they built Principia VerifyBench, where humans labeled tricky cases. The model-based judge agreed with humans about 94% of the time in disagreements, better than the rule-based checker.
Key idea: Verifiers are “judges” for answers. Model-based judges are better at understanding that different-looking math can still mean the same thing.
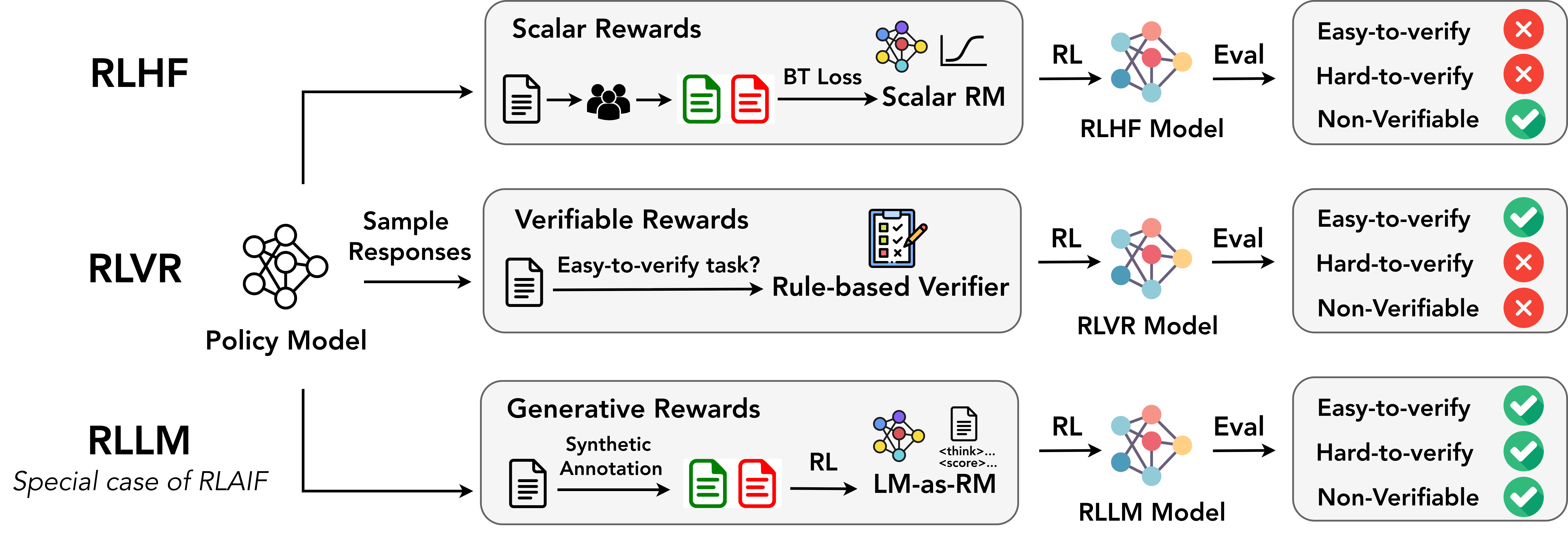
2) RLLM: training with an “AI judge” that thinks
The authors introduce RLLM (Reinforcement Learning with a LLM as the Reward Model). Think of this as training a student (the AI) using a teacher (another AI) that reads the work and gives feedback.
- Reinforcement learning (RL): A training method where the AI tries answers, gets feedback (a “reward”), and learns to do better next time—similar to practicing a sport with coaching.
- Reward model (RM): The “teacher” that scores the answers.
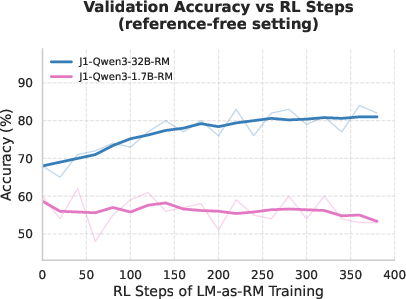
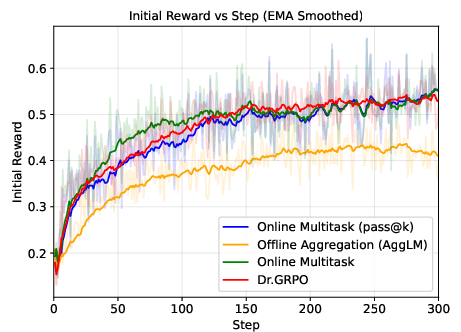
- On-policy: Train the “teacher” on the same kind of answers the “student” is currently producing. It’s like training a referee on the exact style of play in a game, so their feedback matches the game well.
Why this helps: Traditional reward models often just score a final answer, not the chain of thought, which can lead to “reward hacking” (the AI learns shortcuts that look good but aren’t real reasoning). Rule-based checking only works when there’s a simple way to verify correctness (like a numeric answer). RLLM instead uses a thinking AI judge that can compare multiple candidate answers and choose the best one, even for hard-to-verify tasks.
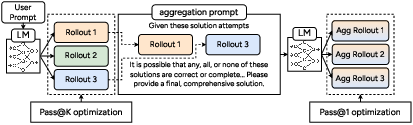
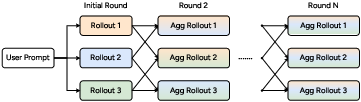
3) ParaGator: smarter parallel thinking at test time
“Parallel thinking” means the AI tries several different solution paths at once and then picks or combines the best parts. The authors found two problems in existing methods:
- The generator (the part that produces candidate solutions) doesn’t know its outputs will be combined later, so the solutions can be redundant.
- Training often uses “off-policy” data (solutions not produced the same way the model will produce them during real use), causing a mismatch.
ParaGator fixes this by training both the generator and the aggregator together, online, and on-policy:
- pass@k optimization for generation: encourage producing k diverse attempts so that at least one is good.
- pass@1 optimization for aggregation: train the combiner to pick or synthesize one best final answer.
Simple analogy: It’s like training a team where each member knows their ideas will be blended, so they try to cover different angles, and the captain learns to select the best final plan.
What they found and why it matters
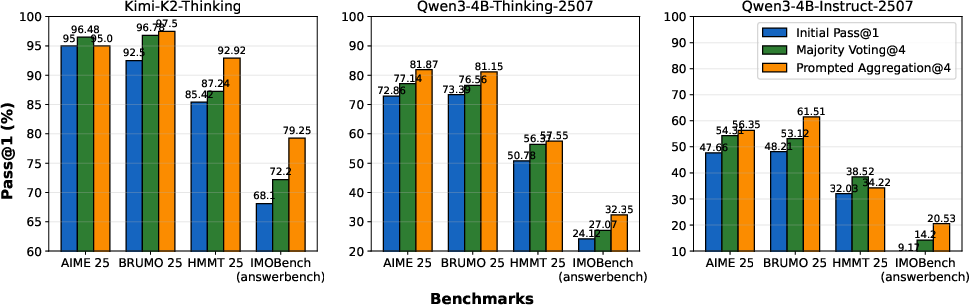
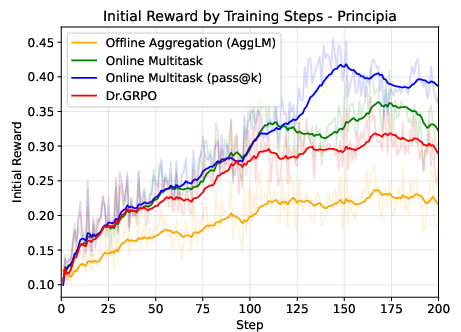
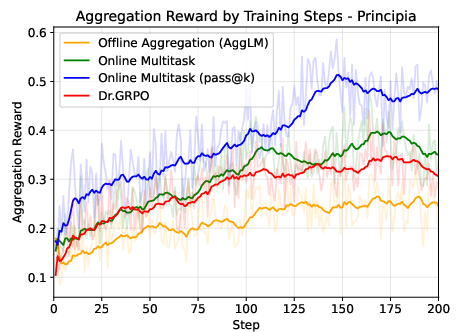
- Big models struggled on PrincipiaBench: Strong LLMs that do very well on standard tests (like AIME or multiple-choice science quizzes) drop a lot on PrincipiaBench when asked to produce full math objects. Removing multiple-choice options caused a 10–20% drop even for top models. This shows that picking from options is much easier than deriving the exact math.
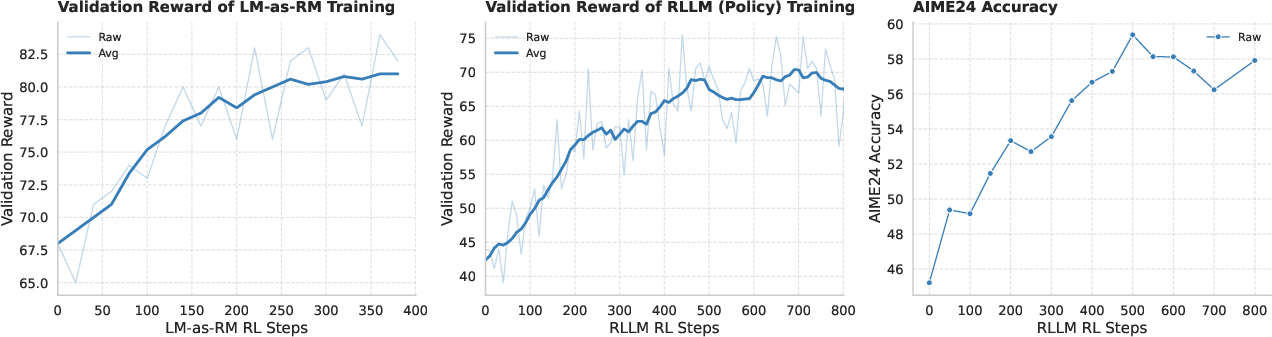
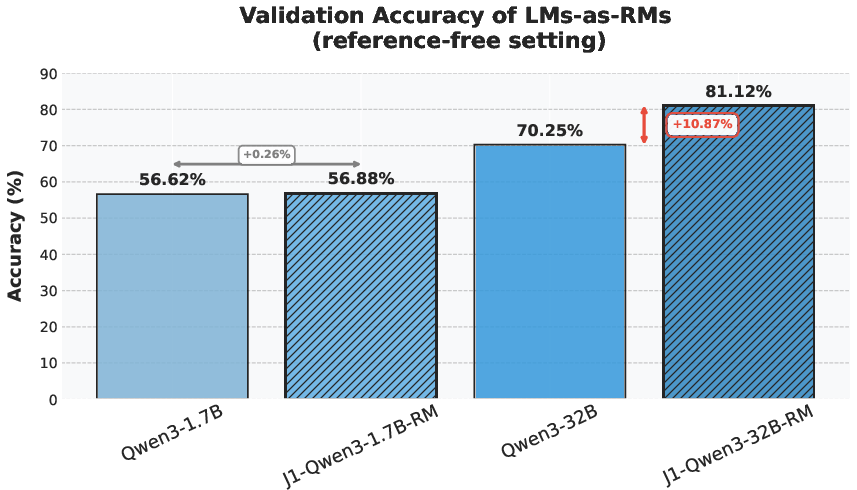
- Training on Principia Collection helps a lot: When they trained several base models on the Principia Collection using RL, scores on PrincipiaBench went up by about 7% to 18%, depending on the model. Surprisingly, this training also improved performance on regular number-answer and multiple-choice tests (like AIME 2024 and GPQA-Diamond), showing that better reasoning transfers across formats.
- Model-based judges are more reliable: In cases where rule-based tools and the AI judge disagreed, human labels showed the AI judge was correct about 94% of the time. This means AI judges can be dependable graders for complex math objects.
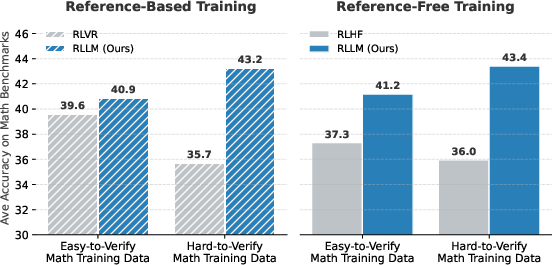
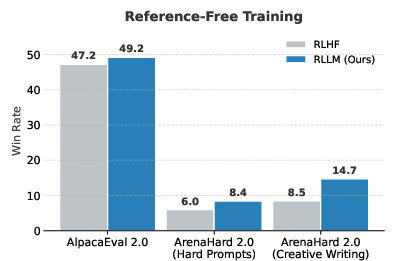
- RLLM beats older methods: Training with an on-policy AI judge outperformed both RL with human-style scalar scores (RLHF) and RL with simple rule-based checking (RLVR), on both easy-to-verify and hard-to-verify problems, and even on tasks without clear “right or wrong” answers (instruction following).
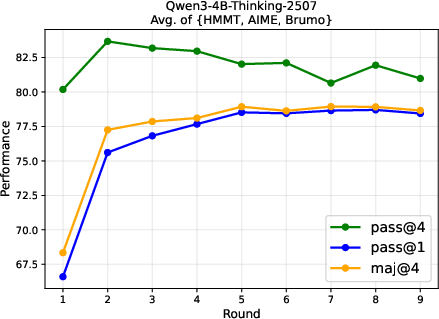
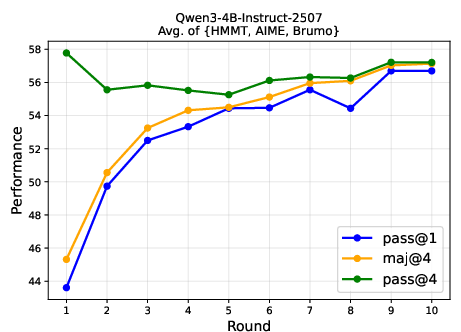
- ParaGator improves reasoning at test time: Training the parallel generator and aggregator together led to better results than previous parallel thinking methods on math and science benchmarks, including PrincipiaBench.
Why this matters: Many real STEM tasks need precise formulas and structures, not just single numbers or picks. These results show how to train AIs to produce those complex answers more reliably.
What this could mean for the future
- Better science helpers: AIs that can write correct, complete math expressions can be much more useful in physics, engineering, and advanced math—where the “shape” of the answer matters.
- Fairer and harder tests: PrincipiaBench reveals hidden weaknesses that multiple-choice tests miss. This will help researchers build genuinely smarter models.
- Smarter training recipes: Using strong AI judges and on-policy training reduces shortcuts and teaches models to reason more like students who show their work.
- Stronger use of extra compute: ParaGator shows how to make the most of trying many solutions by planning for aggregation from the start.
In short, this paper builds the tools (datasets, judges, and methods) to push AI beyond guessing and into producing exact mathematical objects—an important step toward trustworthy AI in real scientific problem solving.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, organized to guide concrete follow‑up work.
Data and Benchmark Design
- Coverage limitations of answer formats: the Principia Collection constrains outputs to six types (equations, inequalities, intervals, sets, matrices, piecewise functions), omitting other common STEM objects (e.g., polynomials as objects, tensors, vector fields/operators, graphs, distributions/measures, algorithms, symbolic derivatives/integrals as standalone objects). Assess whether expanding object types alters training/evaluation dynamics.
- Domain scope gaps: construction centers on mathematics and physics (MSC/PhySH); chemistry, biology, economics, control systems, and other STEM areas with rich mathematical objects are not represented. Measure generalization and extend the taxonomy to those domains.
- Synthetic-data artifacts: all training problems are model‑generated (GPT‑OSS‑120B). There is no human audit of problem well‑posedness, originality, or subtle leakage of answers into statements. Quantify artifact rates and ill‑posedness via human review and introduce human-in-the-loop refinement.
- Ground-truth uniqueness: removing options from MCQA sources may yield problems with multiple valid object answers. The paper filters for “clarity,” but does not verify answer uniqueness. Add a uniqueness check (e.g., via formal solvers or multi‑judge consensus) and report remaining ambiguity rates.
- Dataset contamination: PrincipiaBench draws from public benchmarks likely present in base-model pretraining. Conduct contamination audits (document-level and paraphrase-level) and re‑report results on decontaminated subsets.
- Scale and representativeness: PrincipiaBench (2,158 items) is relatively small; it is unclear if it covers the long tail of object types and topic combinations. Provide stratified coverage statistics, difficulty calibration, and learning curves to justify statistical power.
- Length–difficulty confounding: token lengths are longer in Principia, but no controlled study isolates whether gains come from object-structure learning vs. handling longer outputs. Perform ablations controlling for answer length while holding object type constant.
Verification and Evaluation
- Reliance on model-based judges: evaluation depends on an LLM judge (o3) with a binary Equivalent/Not-Equivalent decision. There is no analysis of judge calibration, variance under re‑prompts, or sensitivity to formatting perturbations. Report judge stability, confidence, and robustness to paraphrase/format changes.
- Small, biased verifier benchmark: Principia VerifyBench has only 168 disagreement cases and is constructed from model–verifier conflicts, not a random sample. Expand the benchmark, report inter‑annotator agreement (κ), and include randomly sampled and adversarial cases.
- Circularity and generalization of judging: the same family of LMs (GPT‑OSS‑120B, o3) is used for problem generation, majority‑vote equivalence, and evaluation. Test cross‑judge validity with independent models, ensemble judges, and symbolic/proof‑assistant baselines; quantify cross‑judge disagreement.
- Equivalence canonicalization: the paper uses heuristic pairwise equivalence with a transitivity threshold and union–find for clustering. There is no formal canonicalization pipeline for objects (e.g., interval normal forms, set normalization, matrix canonical forms). Develop and evaluate canonicalizers to reduce judge dependency.
- Partial credit and structured error analysis: binary equivalence provides no insight into near‑misses (e.g., wrong interval boundary, sign error). Introduce structured, object‑aware grading for partial credit and error typology to guide model improvements.
- Robustness to adversarial formatting: known failures of SymPy and LMs stem from LaTeX/tokenization quirks. Stress‑test judges with adversarial but equivalent forms (variable renaming, reordered factors, different notations) and quantify false‑negative rates.
Training Methods (RLLM)
- Reward model (RM)–policy collusion and overfitting: on-policy LM‑as‑RM may favor stylistic artifacts or specific reasoning templates, risking reward hacking. Evaluate on adversarial prompts and unseen styles; add RM–policy disentanglement (e.g., freeze RM, data‑splits by domain) and report robustness.
- RM training data diversity: the RM is trained on verifiable math/physics; its transfer to non‑verifiable instruction tasks is claimed but not substantiated in the provided text. Quantify cross‑domain generalization and failure cases when rubrics are underspecified.
- Stability and hyperparameters: RL stability, reward scaling, k‑wise comparison details, and sensitivity analyses are missing. Provide training curves, hyperparameter sweeps, and failure mode reports (mode collapse, oscillations).
- Human alignment vs. LM judgments: no comparison to human preference RMs on these object tasks. Collect small high‑quality human preference datasets for object‑correctness and compare RLLM gains to RLHF baselines.
- Safety and bias of LM‑as‑RM: without human oversight, RMs may encode biases or hallucinate rubrics. Audit RM decisions for consistency, bias across object types, and susceptibility to prompt injection or adversarial reasoning chains.
Test-time Aggregation (ParaGator)
- Cost–performance scaling: pass@k optimization and aggregation increase compute, but accuracy vs. cost curves, diminishing returns beyond k, and latency budgets are not reported. Provide detailed Pareto fronts and guidance for deployment.
- Diversity vs. quality trade‑offs: ParaGator encourages complementary solutions, yet there is no quantitative measure of diversity or its causal impact on final accuracy. Add diversity metrics (e.g., solution clustering, derivation edit distances) and ablate their contributions.
- Aggregator failure modes: when synthesis is allowed, aggregators may hallucinate “Frankenstein” objects inconsistent with any candidate. Quantify the rate of inconsistent or ill‑formed final objects and add well‑formedness checks.
- Sensitivity to k and generator–aggregator architecture: the optimal k, temperature, and division of labor between generator and aggregator are not characterized. Provide ablations over k, temperatures, and aggregation strategies (selection‑only vs. synthesis).
- Robustness to correlated errors: parallel candidates often share mistakes due to shared prompt/model biases. Evaluate ParaGator on settings with intentionally correlated errors and explore decorrelation methods (prompt diversity, sampling controls, mixture-of-experts).
Experimental Analysis and Reporting
- Object‑type‑wise performance: results are averaged; there is no breakdown by object type (equation vs. set vs. matrix), topic, length, or difficulty. Add stratified analyses to identify where methods help and where they fail.
- Error typology: no systematic categorization of model errors (e.g., algebraic slip, boundary condition error, wrong branch, ill‑posed output). Build an error taxonomy and annotate a subset to guide targeted improvements.
- Transfer mechanisms: improvements on AIME and GPQA are reported, but what skills transfer is unclear. Analyze cross‑format transfer by mapping object‑type training to specific numerical/MCQA gains (e.g., inequality reasoning → numeric bound questions).
- Ablations on training data: figure hints that excluding MCQA in training helps, but comprehensive ablations (by topic, object type, CoT usage in generation, problem length) are not shown. Provide controlled ablations to isolate drivers of gains.
Reproducibility and Accessibility
- Judge prompts and seeds: exact equivalence prompts, temperature settings, and retry strategies for judges/verifiers are not fully specified. Release prompts, seeds, and multiple‑run variance to ensure reproducibility.
- Compute budget transparency: RL and on‑policy training with large judges can be expensive. Report FLOPs, wall‑clock, and energy, and offer guidance for smaller‑compute settings.
- Open-source verifiers: o3 is proprietary; evaluation reproducibility is limited. Provide open-source judge alternatives or ensembles, and report gaps relative to o3.
Broader Scope and Future Extensions
- Formal verification integration: explore hybrid pipelines that combine LLM judging with CAS/SMT/proof assistants for higher‑confidence equivalence (e.g., canonical forms + solver‑backed checks).
- Multilingual and notation variance: the benchmark targets English/LaTeX‑like notation. Assess performance across languages and discipline‑specific notations (e.g., physics vs. pure‑math conventions).
- Downstream utility: no end‑to‑end evaluation on real research or coursework tasks where object derivations feed into subsequent steps (simulation, theorem application). Build multi‑stage tasks to test usefulness beyond single‑shot answers.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s models and infrastructure, building directly on the Principia suite (PrincipiaBench, Principia Collection, Principia VerifyBench), RLLM (on‑policy LM‑as‑Reward‑Model training), and ParaGator (on‑policy parallel generation and aggregation).
- Evaluation and model selection for math-heavy use cases
- What: Use PrincipiaBench to assess LMs’ ability to produce equations, inequalities, intervals, sets, matrices, and piecewise functions; use Principia VerifyBench to validate/verdict the reliability of verifiers.
- Sectors: AI model development, education tech, enterprise analytics, scientific software.
- Tools/workflows:
- “PrincipiaBench-as-a-Service” leaderboard for procurement and internal model gating.
- “Math-Object Judge API” that performs reference-based equivalence checks using a strong LM judge.
- Assumptions/dependencies: Access to a strong model-based judge (e.g., o3/GPT-OSS-120B-class); evaluation costs; licensing constraints of closed or commercial LMs.
- Training pipelines to improve small/medium models’ reasoning over structured math outputs
- What: Fine-tune base LMs (e.g., Qwen2.5/3, OctoThinker) on the Principia Collection using a model-based verifier for reward; expect cross-format gains (open-ended math → improved MCQA/numeric performance).
- Sectors: AI vendors, startups building domain copilots in engineering/finance/physics.
- Tools/workflows:
- “RLLM Trainer” that learns a thinking reward model on-policy, then RL-trains task policies using k-wise comparative judgments.
- Reference-free post-training where verifiable tasks seed a reward model used for harder-to-verify tasks.
- Assumptions/dependencies: RL compute budget; stable access to capable verifier LMs; careful prompt/rubric design to avoid reward hacking; synthetic data quality/coverage.
- Test-time accuracy boosts for math outputs via parallel generation and aggregation
- What: Apply ParaGator to existing LMs to generate diverse solution candidates (pass@k optimization) and aggregate them into a final answer (pass@1 optimization), improving reliability of equation/inequality/matrix outputs.
- Sectors: Scientific assistants, code/maths copilots, enterprise analytics tools.
- Tools/workflows:
- “ParaGator Inference Engine” wrapper that orchestrates parallel thinking with online-tuned aggregation.
- Assumptions/dependencies: More inference compute per query; latency/throughput trade-offs; aggregation quality depends on on-policy training of the generator and aggregator.
- Autograding and feedback for math-object answers in education
- What: Grade homework/exams requiring equations, intervals, sets, matrices, and piecewise functions; accept equivalent forms; provide formative feedback.
- Sectors: Education (universities, MOOCs, LMS providers).
- Tools/workflows:
- “Equation-Aware Autograder” combining LLM-based equivalence judgments with optional symbolic checks.
- Rubric-guided LLM judges for partial credit and error localization.
- Assumptions/dependencies: Human-in-the-loop for high-stakes grading; alignment with course rubrics; privacy and academic integrity policies.
- Scientific authoring and review assistance
- What: Draft, refactor, and validate equations and piecewise definitions in papers, lab reports, and documentation; check equivalence between alternative formulations.
- Sectors: Academia, R&D labs, scientific publishing.
- Tools/workflows:
- “Equation Refactor & Validator” plugin for Overleaf/Jupyter/VScode.
- Reviewer aids that flag suspect steps and verify object equivalence against references.
- Assumptions/dependencies: LLM judge reliability on domain-specific notation; integration with CAS (e.g., SymPy) for cross-checking.
- Enterprise analytics and BI with canonical formula enforcement
- What: Ensure KPIs, pricing formulas, and policy constraints are expressed in canonical or equivalent forms; detect mismatches or inconsistent definitions across teams.
- Sectors: Finance, operations, supply chain, SaaS.
- Tools/workflows:
- “Formula Linter” in analytics pipelines and metric registries.
- Schema enforcement where metrics are stored as mathematical objects with equivalence checks on updates.
- Assumptions/dependencies: Clear canonical definitions; domain ontology for symbols/units; governance and version control.
- Engineering and robotics control synthesis checks
- What: Validate that controller designs (gain matrices, piecewise controllers, constraints) match specifications; surface equivalence or deviation.
- Sectors: Robotics, automotive, aerospace, industrial automation.
- Tools/workflows:
- “Control-Object Verifier” integrated into model-based design (e.g., MATLAB/Simulink or Modelica toolchains).
- Assumptions/dependencies: Domain-specific symbol/units handling and coordinate conventions; human oversight for safety-critical deployments.
- Content generation for curricula and assessments
- What: Generate graduate-level problem statements that require structured mathematical answers, with verified reference solutions.
- Sectors: Education publishing, test prep, MOOCs.
- Tools/workflows:
- “Principia-based Item Generator” with self-consistent majority voting and LLM-judge curation.
- Assumptions/dependencies: Quality control to avoid artifacts; diversity and fairness in topics; periodic human review.
- Conversion of MCQA materials into open-ended formats
- What: Remove options to create more rigorous assessments; re-evaluate difficulty and content validity.
- Sectors: Testing services, corporate training.
- Tools/workflows:
- MCQA-to-open-ended transformer with automatic recalibration using PrincipiaBench-style evaluation.
- Assumptions/dependencies: Stakeholder acceptance of re-benchmarked scores; transition plans for auto-scoring.
Long-Term Applications
These opportunities are plausible but require further research, scaling, or ecosystem development (e.g., more robust verifiers, formal integrations, or cost-effective compute).
- End-to-end AI assistants for scientific discovery that produce validated mathematical artifacts
- What: Agents that derive, check, and iterate on models (PDEs/ODEs, stochastic models, matrix factorizations) across physics, chemistry, and engineering workflows.
- Sectors: Materials discovery, climate modeling, pharmacometrics, semiconductor design.
- Tools/products:
- “Scientific Copilot” that integrates ParaGator, RLLM, and CAS/proof systems; supports experiment–theory loops.
- Dependencies: Stronger equivalence/judging across notations; hybrid neuro-symbolic verification; dataset coverage of niche subfields.
- Formal integration with proof assistants and CAS for machine-checked math-object equivalence
- What: Bridge LLM judgments with formal proof systems (Lean/Coq/Isabelle) and CAS to provide provable equivalence of derived objects.
- Sectors: Formal methods, safety-critical engineering, mathematical publishing.
- Tools/products:
- “Equivalence-Prover Bridge” translating LLM reasoning into checkable derivations.
- Dependencies: Reliable translation of natural-language math to formal syntax; scalable proof search.
- Regulatory and compliance automation for formula-based policies
- What: Encode regulations (e.g., risk limits, energy dispatch constraints) as mathematical objects; verify proposed policies/models for compliance and equivalence.
- Sectors: Finance (risk), energy (grid constraints), healthcare (dose calculation protocols), telecom (spectrum rules).
- Tools/products:
- “Policy-as-Equations” compliance engine with versioned canonical rules and equivalence audits.
- Dependencies: Formalization of regulatory text; standard ontologies; strong audit trails and legal acceptance.
- Continual on-policy reward-model training for alignment in non-verifiable domains
- What: Extend RLLM beyond math/physics to creative or open-ended tasks where gold answers are scarce, using LM-judges trained on-policy to reduce reward hacking.
- Sectors: General-purpose assistants, enterprise copilots, creative tools.
- Tools/products:
- “Self-Improving Reward Model” pipelines that bootstrap from verifiable seeds and expand into harder domains.
- Dependencies: Robustness of LM-judge preferences; safeguards against mode collapse and bias; cost-efficient online training.
- Dynamic compute allocation at inference via parallel aggregation
- What: Systems that adaptively choose the number of parallel solution paths per query based on uncertainty, SLAs, and cost.
- Sectors: Cloud AI platforms, edge AI, real-time decisioning.
- Tools/products:
- “Adaptive ParaGator Scheduler” that tunes pass@k per task/user profile and provides fallback to single-pass.
- Dependencies: Reliable uncertainty signals; latency budgets; hardware/software support for parallel decoding.
- Domain-specific copilots that output, verify, and maintain mathematical specifications
- What: Assistants for controls, signal processing, quantitative finance, and econometrics that co-edit equations/matrices and maintain consistency across documents/code.
- Sectors: Engineering, finance, econometrics, operations research.
- Tools/products:
- “Spec Guardian” that syncs code, docs, and models through math-object links and equivalence checks.
- Dependencies: Deep domain adaptation; symbol/unit standardization; integration with CI/CD and documentation pipelines.
- Standardized credentialing and assessment for advanced STEM reasoning
- What: Exams and micro-credentials emphasizing open-ended derivations over MCQA, auto-scored with validated judges.
- Sectors: Higher education, professional certification, workforce skilling.
- Tools/products:
- “Open-Ended STEM Assessment Suite” with psychometric calibration and secure proctoring.
- Dependencies: Broad acceptance of LM-augmented scoring; stronger detectors for academic integrity; fairness audits.
- Improved symbolic equivalence ecosystems
- What: Next-generation hybrid verifiers that robustly parse LaTeX/MathML, handle variable renamings and structural transformations, and combine symbolic and LLM reasoning.
- Sectors: CAS vendors, educational platforms, scientific tooling.
- Tools/products:
- “Hybrid Symbolic–LLM Verifier” SDK for third-party integration.
- Dependencies: Benchmarks beyond Principia VerifyBench; open standards for math-object interchange formats.
Notes on feasibility across applications
- Reliability: While model-based verifiers outperform rule-based ones in many cases, they can still misjudge edge cases; high-stakes settings require human oversight and/or formal verification.
- Cost and licensing: RLLM and ParaGator increase training/inference costs; access to high-capability LMs (often closed/source-restricted) may limit adoption.
- Generalization: The Principia Collection is synthetic and may embed LLM biases; domain adaptation and human curation remain crucial.
- Governance: For education and regulation, alignment with institutional rubrics, legal frameworks, and auditability is essential.
Glossary
- answer equivalence: A criterion for whether two differently formatted outputs represent the same mathematical object. "answer equivalenceâwhether a modelâs output represents the same mathematical object as the ground truth despite differences in expression."
- backward chaining: A reasoning strategy that starts from possible answers and works backward to see which conditions they satisfy. "engages in backward chaining"
- canonical ensemble: A statistical mechanics model of a system at fixed particle number, volume, and temperature. "Consider a classical canonical ensemble"
- chain-of-thought: Step-by-step reasoning traces used by models to explain or structure their solutions. "Scalar reward models do not generate chain-of-thought reasoning"
- equivalence checking: The process of determining if two expressions denote the same mathematical object. "making equivalence checking challenging."
- equivalence matrix: A matrix indicating pairwise equivalence relationships among multiple candidate answers. "producing an equivalence matrix"
- GibbsâBogoliubov inequality: A variational bound relating free energies of systems via trial Hamiltonians. "Add a quantitative upper bound using convexity of (GibbsâBogoliubov inequality)."
- Hamiltonian: The total energy function of a system in physics, defining its dynamics. "The Hamiltonian of the system is"
- Helmholtz free energy: A thermodynamic potential defined as F = U − TS, often expressed via the partition function. "the Helmholtz free energies be"
- interpolating Hamiltonian: A Hamiltonian that smoothly connects two systems via a parameter to analyze changes in free energy. "Introduce the interpolating Hamiltonian"
- k-wise comparative judgments: Evaluations where a judge compares k candidate solutions to provide relative preferences. "LM-as-RM's k-wise comparative judgments as rewards."
- LM-as-RM: Using a LLM itself as a Reward Model to provide judgments for training another model. "LM-as-RM's k-wise comparative judgments as rewards."
- math-verify: A rule-based tool (built on Sympy) used to check mathematical equivalence between expressions. "math-verify judges as ``Equivalent''"
- model-based verifier: A general-purpose LLM prompted to judge whether two answers are equivalent. "a model-based verifier"
- multiple-choice question answering (MCQA): A setting where the model selects an answer from given options. "multiple-choice question answering (MCQA) settings"
- MSC 2020: The Mathematics Subject Classification 2020, a taxonomy for organizing mathematical topics. "Mathematics Subject Classification (MSC 2020)"
- off-policy: Using data or generations from a different policy than the one currently being trained or evaluated. "aggregating off-policy generations"
- on-policy: Training or judging using data generated by the current policy/model. "on-policy judge training"
- open-ended generation: Producing unconstrained free-form answers rather than selecting from options. "open-ended generation is information-theoretically harder"
- pair-correlation functions: Functions describing how particle density varies as a function of distance from a reference particle. "pair-correlation functions"
- pair potential: A function giving the interaction energy between a pair of particles as a function of their separation. "the pair potential is replaced"
- Parallel Thinking: A prompting scaffold where multiple solution paths are generated in parallel before aggregation. "Parallel Thinkingâa scaffold"
- pass@1: The probability that at least one correct solution is found within a single generated attempt. "pass@1 optimization"
- pass@k: The probability that at least one correct solution is found among k generated attempts. "pass@k optimization"
- partition functions: Summations over states that normalize probabilities and connect to free energies in statistical mechanics. "canonical partition functions"
- PhySH: Physics Subject Headings, a taxonomy for organizing physics topics. "Physics Subject Headings (PhySH)"
- plane generic immersion: A smooth map of a graph or manifold into the plane with only generic (simple) self-intersections. "be a plane generic immersion."
- radial distribution function: The pair-correlation function for a homogeneous fluid, giving relative particle density versus radius. "radial distribution function "
- reference-based evaluation: Judging a model’s answer by comparing it to a provided reference solution. "reference-based evaluation"
- reference-free: Evaluations or tasks that do not rely on a ground-truth reference answer. "reference-free vs. reference-based tasks"
- Reward Model (RM): A model that assigns scalar or comparative rewards to outputs to guide reinforcement learning. "Reward Model (RM)"
- reward hacking: Exploiting flaws in a reward function to achieve high reward without truly solving the intended task. "reward hacking"
- RLHF: Reinforcement Learning from Human Feedback, using human preference data to train a policy via a reward model. "Reinforcement Learning from Human Feedback (RLHF)"
- RLVR: Reinforcement Learning with Verifiable Rewards, using rule-based or programmatic checks as reward signals. "Reinforcement Learning with Verifiable Rewards (RLVR)"
- rubric-based evaluation: Assessments guided by structured criteria or rubrics to judge quality. "rubric-based evaluation methods"
- scalar reward models: Reward models that output a single scalar score rather than structured feedback or comparisons. "Scalar reward models"
- self-consistency: Aggregating multiple independent generations to pick the most consistent or majority answer. "apply self-consistency"
- Sympy: A Python library for symbolic mathematics used for checking equivalences and manipulating expressions. "Python Sympy library"
- test time scaling: Increasing compute or using strategies at inference time (e.g., multiple samples) to improve performance. "test time scaling recipe"
- test-time compute: The computational budget spent during inference, often scaled via multiple generations or reranking. "test-time compute"
- two-particle density: A function describing joint density of finding two particles at given positions in a system. "two-particle density"
- union–find algorithm: A data structure/algorithm for maintaining disjoint sets with efficient union and find operations. "unionâfind algorithm"
- verifiable rewards: Rewards derived from verifiable checks (e.g., rule-based or programmatic validators). "with verifiable rewards"
Collections
Sign up for free to add this paper to one or more collections.