- The paper introduces ThinkPRM, reducing the need for extensive step-level supervision by leveraging generative models to produce coherent reasoning chains.
- The methodology uses synthetic data to train verification chains, resulting in improved performance on benchmarks like ProcessBench and MATH-500.
- Implications include enhanced interpretability, data efficiency, and reliability for out-of-domain tasks in complex step-by-step processes.
Process Reward Models That Think
Introduction
This paper discusses the development and evaluation of "Process Reward Models That Think," a type of process reward model (PRM) designed to be data-efficient and capable of verifying step-by-step the process in solutions using a chain-of-thought (CoT) approach. This approach is in contrast to traditional discriminative PRMs, which require extensive step-level supervision to achieve high performance. The authors introduce ThinkPRM, which leverages generative models to construct long chains of reasoning using minimal data, demonstrating superior performance over conventional methods in various benchmarks and scenarios.
Methodology
The primary focus of ThinkPRM is to utilize fewer process labels while maintaining or enhancing performance in verification tasks. The key innovation lies in employing long CoTs, enabling PRMs to reason through problems effectively by generating comprehensive verification steps rather than merely classifying solution correctness at each step.
The paper presents a process for collecting synthetic data to train these models, showcasing a pipeline where reasoning models, specifically, QwQ-32B-Preview is used to critique solutions and generate verification CoTs. These synthetic chains are then filtered against known correct process labels to ensure high-quality data is used for finetuning.
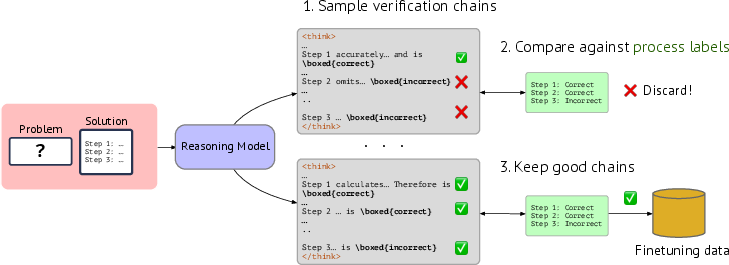
Figure 1: Collecting verification chains for finetuning, ensuring alignment with gold process labels.
Evaluation
ThinkPRM is evaluated against several challenging benchmarks, including ProcessBench, MATH-500, and out-of-domain tasks like GPQA-Diamond and LiveCodeBench. The model consistently outperforms both LLM-as-a-Judge and traditional discriminative verifiers by effectively utilizing generative modeling capabilities.
An analysis of CoT lengths indicates that standard LLM-as-a-Judge models often generate excessively long and repetitive chains, worsening performance due to issues like infinite loops and overthinking. ThinkPRM, however, significantly reduces these problems through training on synthetic data, resulting in more concise and accurate CoT outputs.
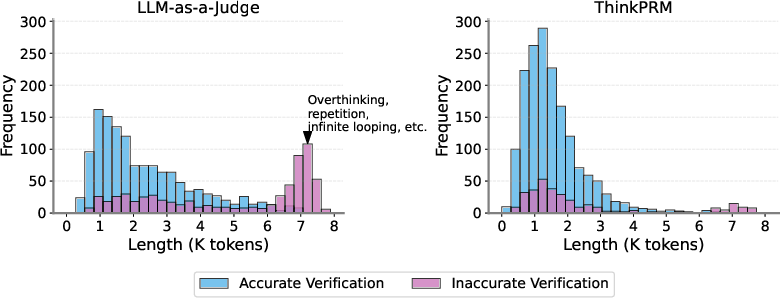
Figure 2: Verifier performance on ProcessBench with ThinkPRM effectively reducing issues of excessive CoT lengths and overthinking.
In best-of-N selection scenarios and verifier-guided search, ThinkPRM shows better performance than competing methods, including off-the-shelf PRMs trained on extensive step labels. This is particularly apparent in tasks requiring substantial reasoning, highlighting ThinkPRM's capacity for parallel and sequential scaling of verification compute.
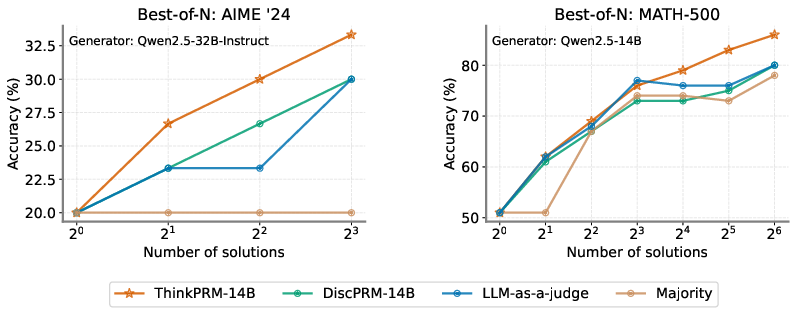
Figure 3: Best-of-N performance on AIME '24 and MATH-500, demonstrating the scaling efficiency of ThinkPRM compared to baselines.
Implications
The implications of this research are profound for the development of data-efficient and scalable PRMs. By reducing the reliance on large labeled datasets, ThinkPRM represents a step forward in making step-by-step verification more feasible and interpretable. The ability to generate coherent CoTs opens avenues for enhanced interpretability and dynamic scalability at test time.
Moreover, the findings indicate that generative PRMs can effectively generalize beyond the training domain, performing well in out-of-domain tasks due to their inherent reasoning capabilities. This adaptability is crucial for applications in varied problem domains.
Conclusion
ThinkPRM demonstrates that leveraging generative models for process verification offers notable advantages in terms of data efficiency, scalability, and performance. The use of synthetic data for training reveals a path forward for developing robust verification systems with minimal supervision. Moving forward, this approach could inform the design of PRMs for a broader range of applications, promoting more efficient and interpretable AI systems capable of complex reasoning tasks.