EgoEdit: Dataset, Real-Time Streaming Model, and Benchmark for Egocentric Video Editing
Abstract: We study instruction-guided editing of egocentric videos for interactive AR applications. While recent AI video editors perform well on third-person footage, egocentric views present unique challenges - including rapid egomotion and frequent hand-object interactions - that create a significant domain gap. Moreover, existing offline editing pipelines suffer from high latency, limiting real-time interaction. To address these issues, we present a complete ecosystem for egocentric video editing. First, we construct EgoEditData, a carefully designed and manually curated dataset specifically designed for egocentric editing scenarios, featuring rich hand-object interactions, while explicitly preserving hands. Second, we develop EgoEdit, an instruction-following egocentric video editor that supports real-time streaming inference on a single GPU. Finally, we introduce EgoEditBench, an evaluation suite targeting instruction faithfulness, hand and interaction preservation, and temporal stability under egomotion. Across both egocentric and general editing tasks, EgoEdit produces temporally stable, instruction-faithful results with interactive latency. It achieves clear gains on egocentric editing benchmarks-where existing methods struggle-while maintaining performance comparable to the strongest baselines on general editing tasks. EgoEditData and EgoEditBench will be made public for the research community. See our website at https://snap-research.github.io/EgoEdit




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making it easy to edit first-person videos in real time using plain language instructions. Think of wearing a camera (like a GoPro) and saying, “Replace the apple I’m holding with a glowing crystal,” and the video changes while you move, without messing up your hands or the scene around you. The authors build three things to make this happen:
- a high-quality dataset of first-person (egocentric) video edits,
- a fast, real-time editing model,
- and a fair benchmark to measure how well different methods work.
Key Questions
The paper tries to answer simple, practical questions:
- Can we edit first-person videos live, using text instructions, while the camera moves a lot?
- Can we keep hands and objects looking correct during edits, even when they touch, overlap, or move quickly?
- Can we do all this with low latency (very short delay), so it feels interactive for augmented reality (AR)?
How They Did It
To tackle the problem, the authors created an end-to-end setup focused on three parts.
1) EgoEditData (the dataset)
They built a carefully curated dataset of “before and after” video pairs and clear edit instructions, all from a first-person view. It focuses on realistic hand–object interactions, like:
- removing an object someone’s holding,
- replacing it with another object (ordinary or imaginary),
- and making sure the hands look natural and are preserved in the final edit.
How they made it:
- They started with real first-person videos.
- They used AI tools to detect hands and find the exact object being manipulated.
- They generated edited versions where the object is changed or removed.
- They had humans review the results and keep only the high-quality edits.
- They wrote precise, descriptive instructions for each pair.
Result: 49.7k videos and 99.7k instruction–edit pairs, all focused on egocentric scenarios.
2) EgoEdit (the real-time model)
They trained a video editor that follows text instructions and can run fast enough to be used live.
Key ideas explained in everyday terms:
- Start with a strong video generator (a model that can make videos from text).
- Teach it to edit instead of creating from scratch by feeding it:
- the original video,
- the desired instruction,
- and training it on lots of “before/after” examples so it learns how to change only what’s needed.
- Make it fast through “distillation,” which is like compressing a slow but smart model into a quicker version. They use two steps:
- DMD: reduces the number of generation steps so it runs faster.
- Self-Forcing: the model practices on its own outputs and learns to correct its mistakes over time, which helps it keep videos consistent as they stream.
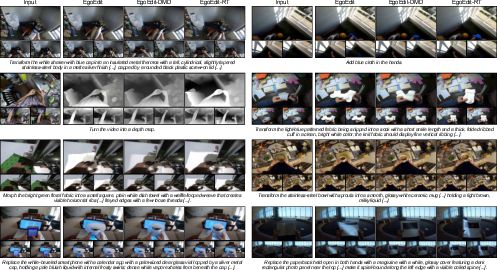
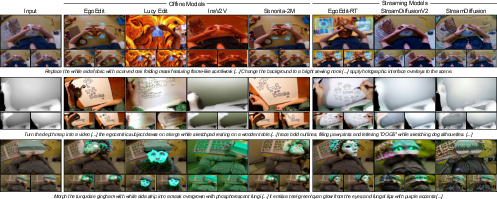
Streaming means the model edits chunk by chunk while the video is recorded, so you see the first edited frame quickly. Their fast version, called EgoEdit-RT, reaches about 38.1 frames per second, with the first edited frame showing in roughly 0.855 seconds on a single GPU.
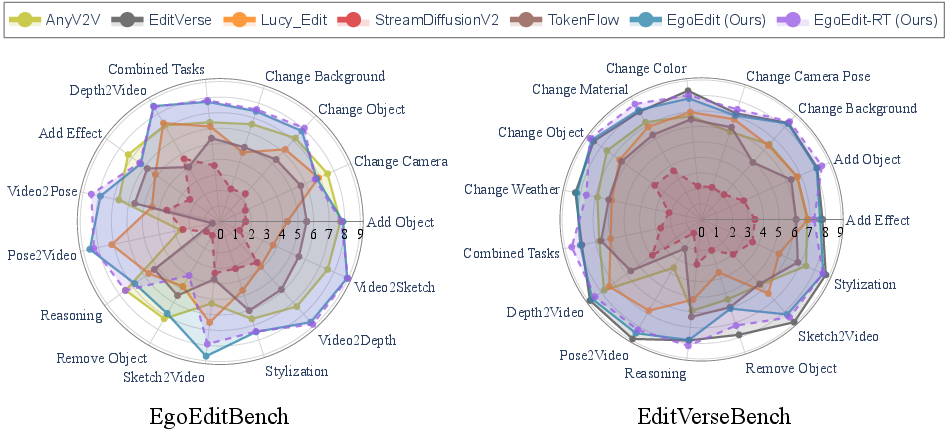
3) EgoEditBench (the benchmark)
They built a fair test suite for first-person video editing that checks:
- instruction faithfulness (does the edit match what you asked?),
- hand and interaction preservation (are hands and touched objects kept intact?),
- temporal stability (does the edit stay consistent across frames while the camera and hands move?).
It covers 15 typical AR-style tasks, like adding/removing objects, changing styles or backgrounds, and using guides like sketches, poses, or depth maps. It uses automated scoring to compare different methods in a consistent way.
Main Findings
Here are the key results that the authors highlight:
- EgoEdit (the base model) and EgoEdit-RT (the fast streaming version) produce edits that follow instructions well, stay stable over time, and keep hands and interacting objects looking correct.
- On egocentric tasks (first-person videos), EgoEdit beats other methods that struggle with rapid camera motion and hand–object overlaps.
- On general editing tasks (third-person videos), EgoEdit stays competitive with top methods.
- EgoEdit-RT, the real-time version, is almost as good as the full model but runs fast enough for interactive use.
- The curated dataset, EgoEditData, significantly boosts performance: more egocentric examples lead to better editing in first-person scenarios.
Why This Matters
This work moves us closer to live, language-driven AR experiences. Imagine apps where you can:
- restyle your surroundings on the fly,
- swap out objects you’re holding with fun or useful items,
- add effects or characters that react to your movements,
- all while keeping your hands and the scene realistic.
Beyond cool demos, the dataset and benchmark give researchers a common foundation to build and compare new methods. The model’s real-time speed means it can be used in interactive settings, like AR glasses or mobile devices in the future.
A simple note on limitations
While strong, the model isn’t perfect:
- Very tricky or unusual edits can still fail.
- If an object disappears behind something and reappears, consistency can drop.
- It runs at a modest resolution and frame rate, and the first-frame delay, while under a second, could be even lower.
Even with these limits, the paper offers a complete ecosystem—data, model, and benchmark—that makes real-time, instruction-guided editing of first-person videos practical and measurable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, written to be directly actionable for future research.
- Real-world human evaluation for AR: No user studies quantify perceived edit fidelity, comfort, latency tolerance, or interaction quality in head-mounted AR settings; design controlled studies comparing EgoEdit/EgoEdit-RT vs baselines on task success and UX.
- Metric validity in egocentric settings: Heavy reliance on VLM-based scoring, Pick Score, and automated Text Alignment may not capture hand geometry preservation, occlusion handling, or interaction plausibility; develop human-validated and task-specific metrics (e.g., hand mesh consistency, contact plausibility, edit locality).
- Long-horizon stability and drift: Streaming generation is evaluated on short clips and small chunks (first chunk 9 RGB frames, next chunks 12 frames); measure identity drift, hand-object alignment, and exposure bias over multi-minute egocentric streams and propose training/metrics to address it.
- Occlusion robustness: Authors note weaker performance when edited objects are temporarily occluded; create benchmarks and training augmentations for extreme occlusions and reappearance, and measure frame-reacquisition stability.
- Physics and causal interaction limits: Inserted objects do not induce consequential environmental changes (e.g., swords do not cut, objects do not move real items); investigate lightweight physics priors, contact-aware generative constraints, or hybrid perception–simulation to improve causal realism.
- Latency optimization trade-offs: First-frame latency (855 ms) is dominated by chunk recording (3 latent ≈ 9 RGB frames); study effects of smaller chunk sizes on temporal consistency, guidance, and exposure bias, and explore predictive pre-roll or partial-frame streaming.
- Resolution and frame rate constraints: Model runs at 512×384px and 16 fps, below typical AR (≥720p, ≥30–60 fps); identify bottlenecks (autoencoder, transformer, KV cache) and develop scalable architectures, distillation, or quantization to achieve 720p/1080p at interactive frame rates.
- Mobile and edge deployment: Results are reported on a single H100 GPU; quantify performance, power, and thermal behavior on mobile SoCs/AR headsets, explore on-device acceleration, 8-bit/4-bit quantization, and memory–latency trade-offs.
- Benchmark completeness and reproducibility: EgoEditBench uses GPT-generated instructions and automated signals; provide fixed seeds, human-curated prompts, and ground-truth targets to reduce LLM-induced variability and allow rigorous, reproducible comparisons.
- Coverage of reference/mask-based interactive editing: The model does not support reference image conditioning or edit-with-mask tasks (excluded from EditVerseBench evaluation); extend conditioning modalities (masks, sketches, reference frames) and test interactive local edits guided by gestures/voice.
- Dataset domain bias: EgoEditData derives from Ego4D/EgoExo4D and filters out jitter/blur; measure generalization to low-light, motion-blur, extreme egomotion, outdoor/industrial scenes, varied FOVs (e.g., fisheye), and consumer AR devices.
- Mask quality and ground truth: Hand/object masks rely on SAM 2 prompted by detectors; quantify failure rates, provide human-annotated masks for a subset, and study how mask errors propagate to editing quality.
- Instruction generation and bias: Edit instructions are LLM-generated (GPT-5 Mini) and may encode style/bias; audit instruction diversity, ambiguity, and cultural bias, and release a human-curated subset to disentangle instruction quality from model performance.
- Reliance on closed or proprietary components: Data synthesis (Wan 2.1 VACE 14B), LLMs (GPT-5 Mini), and teacher models may be unavailable to many labs; evaluate alternative open-source pipelines, report sensitivity to different teachers/autoencoders, and document compute requirements for reproducibility.
- Ablation scope and scaling laws: Distillation ablations focus on DMD + Self-Forcing; systematically compare APT2 (1-NFE), different chunk sizes, guidance schedules, KV caching strategies, and sequence lengths to establish scaling laws for egocentric streaming editing.
- Multi-object and compositional edits: Dataset emphasizes single manipulated object edits; benchmark and train for multi-object, multi-step, and compositional edits (e.g., “replace mug, restyle table, add lighting” in one pass), with measures of instruction coverage and interference.
- Robust instruction following under OOD language: Authors note weaker proficiency on out-of-distribution instructions; build robustness via paraphrase augmentation, multilingual prompts, disfluencies, multi-turn refinement, and explicit error detection/recovery in streaming loops.
- Hand preservation fairness: Hands are central but fairness across skin tones, accessories (rings, watches), gloves, and prosthetics is unreported; audit and mitigate demographic/appearance biases in hand preservation and interaction fidelity.
- Safety, privacy, and ethical considerations: Egocentric streams may include bystanders and sensitive environments; study on-device processing, privacy-preserving training, red-teaming for harmful edits, and AR-specific safety guidelines (e.g., not inserting objects that occlude hazards).
- Ground-truth alignment of synthetic targets: Edited “after” videos are generated by another model and filtered; quantify mismatch between intended instructions and synthetic outcomes, and establish human-verified targets to calibrate instruction faithfulness.
- Generalization to varied hardware and camera pipelines: Performance across different sensors, rolling-shutter artifacts, stabilization methods, and compression settings is unexplored; build cross-device benchmarks and characterize robustness.
- Error accumulation and recovery in streaming: Develop mechanisms to detect accumulated artifacts (e.g., jitter, texture drift) and recover gracefully mid-stream (re-anchoring to the source), with measurable recovery metrics and user-controllable resets.
- Integration with AR interaction primitives: Explore real-time edit control via gaze, hand gestures, spatial anchors, and scene graphs; measure responsiveness, accuracy, and conflicts between edits and tracked anchors in interactive AR applications.
Practical Applications
Practical Applications of EgoEdit, EgoEditData, and EgoEditBench
Below are concrete, real-world applications derived from the paper’s dataset (EgoEditData), model (EgoEdit and EgoEdit-RT), and benchmark (EgoEditBench). Items are grouped by deployment horizon and include linked sectors, potential tools/workflows, and key dependencies that affect feasibility.
Immediate Applications
- Live, hand-aware AR effects for creators and ads (Media & Entertainment, Social, Advertising, E-commerce)
- What: Real-time insertion/removal/restyling of objects in first-person videos, with reliable hand preservation and temporal stability for moving cameras.
- Tools/workflows: Cloud-based “Egocentric Video Editing Service” powered by EgoEdit-RT; effect marketplace where creators author language-driven effects; integration into live streaming apps.
- Dependencies/assumptions: GPU servers (e.g., H100) for 512×384 @ ~16 fps; stable uplink for streaming; content safety and disclosure policies; quality degrades under heavy occlusions or OOD prompts.
- Video conferencing and live collaboration enhancements (Software, Communications)
- What: Instruction-guided background restyling, object removal (e.g., whiteboard cleanup), and hand-aware effects during calls.
- Tools/workflows: WebRTC plug-in with server-side EgoEdit-RT; presets controlled by chat commands.
- Dependencies/assumptions: Cloud offload; bandwidth/latency budgets; privacy controls; current resolution/FPS limits.
- Body-worn camera privacy filters (Public Safety, Compliance, Enterprise)
- What: Near-real-time removal of sensitive objects/logos or restyling of bystanders in first-person footage while preserving the wearer’s hands and core interactions.
- Tools/workflows: “Privacy-Edit” pipeline that applies object removal/substitution instructions and logs changes for audit.
- Dependencies/assumptions: High reliability demands; auditability; strict policies on edited evidence; cloud/GPU availability; model limitations on occlusion cases.
- Retail live demos and product placement (E-commerce, Marketing)
- What: Virtual try-before-you-buy for handheld products in creator streams; object substitution anchored to the user’s hands.
- Tools/workflows: Product insertion microservice; SKU-to-instruction templates; CMS linking product assets to prompts.
- Dependencies/assumptions: Access to product images/3D proxies; legal disclosure of virtual placements; hand/object segmentation quality affects realism.
- Sports/skill coaching from headcams (Sports, Education)
- What: Overlay cues, replace/augment tools (e.g., different club/racket), add effects showing technique or target zones in first-person view.
- Tools/workflows: Coaching app with preset instruction templates; post-session batch edits using the non-RT EgoEdit for higher quality.
- Dependencies/assumptions: Temporal stability under fast motion; safety disclaimers; lower resolution may limit fine-grained analysis.
- Field service/maintenance guidance (Industrial, Utilities, Energy)
- What: Live substitution/annotation of parts in egocentric video to preview variants, identify targets, or highlight steps.
- Tools/workflows: Remote-assist dashboards; instruction libraries per task; recordings processed with EgoEdit offline for training documentation.
- Dependencies/assumptions: Integration with existing AR headsets; safety-critical workflows demand human-in-the-loop validation; resolution/FPS constraints.
- Egocentric editing dataset and benchmark adoption (Academia, Industry R&D)
- What: Use EgoEditData to train/editors for hand-object interactions; use EgoEditBench as a standardized CI gate for egocentric editing quality and temporal stability.
- Tools/workflows: Public dataset for model fine-tuning; leaderboard/CI tied to EgoEditBench metrics; ablation platforms.
- Dependencies/assumptions: Dataset licensing and usage compliance (derivatives of Ego4D/EgoExo4D); compute resources; reproducibility guidelines.
- Synthetic data generation for hand–object interactions (Robotics, Computer Vision, ML)
- What: Generate diverse “before/after” egocentric sequences by replacing/removing objects while preserving hands, to augment training for detection, segmentation, manipulation planning, and VLMs.
- Tools/workflows: Data augmentation service driven by instruction templates; curated subsets for imitation learning.
- Dependencies/assumptions: Distribution shift to real robot sensors; curated taxonomy of objects; rights to distribute derivatives.
- Post-production editing of first-person content (Media & Entertainment, Education)
- What: Offline instruction-guided edits (higher NFE/base EgoEdit) for higher fidelity on vlogs, training videos, or tutorials.
- Tools/workflows: NLE plug-ins; batch render farms using EgoEdit; prompt libraries for common edits.
- Dependencies/assumptions: Compute cost; editorial oversight; consistent hand preservation under heavy occlusions is still a challenge.
- Accessibility and focus aids (Assistive Tech, Education)
- What: Remove visual clutter, highlight task-relevant objects, and simplify scenes for cognitive accessibility in first-person recordings.
- Tools/workflows: Preset instructions tailored to attention support; on-demand edits for instructional materials.
- Dependencies/assumptions: Ethical deployment; user consent; cloud vs on-device constraints.
Long-Term Applications
- On-device, glasses-grade egocentric editing (Hardware, Mobile, AR Platforms)
- What: Running real-time editing locally on AR glasses or phones without cloud reliance.
- Tools/workflows: Further distillation/quantization, hardware acceleration (NPUs), chunk-size reduction for sub-500 ms latency.
- Dependencies/assumptions: Power/memory limits; safety/privacy benefits of on-device; requires compressing models beyond current H100 target.
- Healthcare and surgical AR (Healthcare, Medical Training)
- What: Training simulators and clinical AR overlays that substitute tools, anonymize identifiers, and add cues in surgeon POV video.
- Tools/workflows: Procedure-specific instruction sets; validated pipelines; high-resolution, low-latency hardware integration.
- Dependencies/assumptions: Regulatory approval; rigorous validation; high reliability across occlusions; provenance tracking; explicit disclosure of edits.
- Robot learning and sim2real via edited egocentric streams (Robotics)
- What: Use edited sequences to study affordances, generalize to novel objects, and generate counterfactual “what-if” training data with preserved hand dynamics.
- Tools/workflows: Closed-loop data engines that propose edits and retrain perception/policy models; integration with teleoperation logs.
- Dependencies/assumptions: Physical/causal consistency is limited (paper notes objects don’t yet alter the environment physically); requires 3D/physics-aware extensions.
- Multi-user, persistent world editing (AR Cloud, Enterprise Collaboration)
- What: Shared edits anchored to real-world coordinates and synchronized across multiple users’ first-person views.
- Tools/workflows: AR cloud services combining SLAM/scene graphs with instruction-guided editing; conflict resolution and versioning.
- Dependencies/assumptions: High-quality mapping and tracking; consistent hand/object identity across users; low-latency networking.
- Content authenticity, provenance, and watermarking standards (Policy, Standards Bodies)
- What: Default watermarking of edited frames and C2PA-style provenance for live and recorded egocentric edits.
- Tools/workflows: Inline watermark insertion; verifiable manifests that track instructions and timestamps.
- Dependencies/assumptions: Ecosystem adoption; robust watermarking against compression/resizing; user-facing disclosure norms.
- Agentic, context-aware AR editors (Software, Consumer AI)
- What: Personal AR assistants that learn user preferences and proactively apply/recommend egocentric edits during tasks.
- Tools/workflows: Integration with MLLMs, calendar/task context; safety layers for instruction gating.
- Dependencies/assumptions: Privacy preservation; robust instruction grounding; drift and hallucination control.
- High-resolution, physics-aware world editing (3D Vision, Simulation)
- What: Edits that cause physically plausible changes (e.g., cut objects, deform materials), with consistent lighting and contact effects.
- Tools/workflows: 3D scene reconstruction; differentiable physics and material models; joint video-3D consistency training.
- Dependencies/assumptions: Significant research in 3D-aware video models; compute and latency costs; safety implications.
- MEC/edge deployments for ultra-low latency (Telecom, Cloud)
- What: 5G multi-access edge computing to deliver <300 ms end-to-end editing for mobile AR.
- Tools/workflows: Telco-integrated GPU edge nodes; adaptive bitrate and chunk size control; SLA monitoring with EgoEditBench KPIs.
- Dependencies/assumptions: Telco partnerships; capex/opex for GPUs; robust failover.
- Domain-adapted training suites for egocentric understanding (Academia, Foundation Models)
- What: Use EgoEditData and EgoEditBench to pretrain and evaluate egocentric perception models (hand-object segmentation, tracking, language-grounded understanding).
- Tools/workflows: Benchmark-leveraged CI for research; public leaderboards; task-specific fine-tuning kits.
- Dependencies/assumptions: Continuous updates to counter dataset bias; consent and anonymization standards.
Notes on Feasibility and Cross-Cutting Dependencies
- Hardware/latency: EgoEdit-RT achieves ~855 ms first-frame latency and ~38 fps at 512×384 on a single H100 via cloud; on-device deployment requires further compression and hardware acceleration.
- Quality limits: Model may underperform on heavy occlusions, rare instructions, and strong structural scene edits; current FPS and resolution may be insufficient for some professional uses.
- Data/governance: Use of egocentric content raises privacy concerns; any deployment should include disclosures, consent flows, and provenance/watermarking.
- Integration stack: Successful products will pair EgoEdit(-RT) with camera calibration, SLAM (for anchoring), bandwidth adaptation, and safety layers (content moderation, instruction filtering).
- Licensing: Third-party components (Wan autoencoder, Qwen, SAM 2, dataset derivatives) and newly released assets must be used within their licenses and terms.
Glossary
- Attention-control methods: Techniques that modify attention weights in generative models to preserve source content while changing appearance. "Attention-control methods modify or reweight cross/self-attention to preserve content while changing appearance"
- Autoencoder: A neural network that compresses data into a latent representation and reconstructs it, enabling efficient generation in latent space. "latent space of a Wan 2.1 autoencoder"
- Autoregressive generation: Generating sequences chunk-by-chunk or frame-by-frame, conditioning each part on previously generated outputs. "Recent methods create autoregressive generators capable of generating long videos by predicting a chunk of frames at a time."
- Bidirectional model: A model that leverages both past and future context during generation or training. "CausVid distills a 50‑step bidirectional model into a 4‑step causal student using DMD, with chunk‑wise generation and KV caching."
- Causal distillation: Converting a slow bidirectional teacher into a fast causal student that generates in a forward-only manner. "Causal distillation converts slow bidirectional teachers into few‑step causal students."
- Channel-wise concatenation: Concatenating inputs along the channel dimension to avoid quadratic attention cost from longer token sequences. "EgoEdit uses channel-wise concatenation, where X and X are concatenated along channels before patchification"
- Classifier-free guidance: A sampling technique that blends conditional and unconditional model predictions to steer outputs without a classifier. "40 denoising steps with classifier-free guidance are required to produce a video, which corresponds to 80 model invocations (NFEs)."
- Cross attention: Attention mechanism that lets video tokens attend to text tokens for instruction conditioning. "Text conditions c are provided through cross attention layers placed after each self attention block."
- Diffusion forcing: A streaming strategy that assigns distinct noise levels to chunks so the model can denoise chunk‑by‑chunk autoregressively. "Diffusion forcing and its variants divide the video into chunks and assigning distinct diffusion noise levels so the model can denoise autoregressively chunk‑by‑chunk."
- DiT (Diffusion Transformer) model: A transformer-based diffusion architecture used for high-quality image/video generation and editing. "EgoEdit extends a video generation DiT model for video editing by performing channel-wise concatenation"
- DMD: A distillation method that compresses many diffusion steps into few steps while preserving quality via distilled guidance. "We follow DMD to compress the 40-step model with classifier-free guidance into a 4-step model with distilled guidance."
- Egocentric video editing: Editing first-person videos where the camera is worn or held by the user, requiring real-time and interaction-aware changes. "We focus on egocentric video editing."
- Egomotion: The motion of the camera (observer) in the scene, prominent in first-person videos. "due to complex hand-object interactions, frequent occlusions, and large egomotion."
- Euler solver: A numerical integrator used to solve ordinary differential equations during inference. "At inference time, an Euler solver integrates the learned ODE from X to X to produce a sample."
- Exocentric content: Third-person views with moderate motion and limited interaction, typical of standard video datasets. "targeted at exocentric content: third-person views with moderate motion, and low amounts of interaction."
- Exposure bias: The mismatch between training and inference in autoregressive models, leading to compounding errors. "Self‑Forcing addresses the exposure bias by rolling out the student at train time"
- First-frame latency: The time from starting generation to displaying the first edited frame for interaction. "EgoEdit possesses a first-frame latency of 855ms, which is sufficient but suboptimal for interactive usage."
- Flow Matching: A training framework that learns a velocity field to deterministically transform noise into data. "We train our generators with Rectified Flow flow matching, which learns a deterministic path from a noise distribution n to the data distribution d."
- Frame propagation methods: Approaches that edit the first frame and propagate the edit through the video sequence. "Frame propagation methods receive as input the first frame edited by EgoEdit for fair comparison."
- Grounded SAM: A segmentation approach that uses textual grounding to guide SAM for object masks. "Given the identified object name, Grounded SAM predicts an approximate object mask in each frame."
- Inversion-based methods: Editing techniques that reconstruct the source along the diffusion trajectory and then steer it via prompts. "Inversion-based methods reconstruct the source along the denoising trajectory and then steer it with the edit prompt"
- KV caching: Storing transformer key/value tensors to speed up autoregressive inference across chunks. "with chunk‑wise generation and KV caching."
- Latent frame: A video frame represented in the compressed latent space of an autoencoder. "we generate a chunk at a time, where each chunk is composed of three latent frames."
- Latent space: The compressed representation space where generative models operate for efficiency and quality. "trained on the latent space of a Wan 2.1 autoencoder"
- NFE (Number of Function Evaluations): The count of model invocations required during sampling. "which corresponds to 80 model invocations (NFEs)."
- ODE (ordinary differential equation): A mathematical formulation solved during sampling to transform noise into data. "integrates the learned ODE from X to X to produce a sample."
- Patchifier: A module that converts frames into patch tokens for transformer processing. "projects it to a sequence of tokens through a linear patchifier"
- Pick Score: An automated metric assessing perceived quality or preference in generated/edit results. "“PS” is Pick Score"
- Rectified Flow: A specific flow matching variant that learns a deterministic path from noise to data via a constant velocity field. "We train our generators with Rectified Flow flow matching"
- RoPE (Rotary Positional Embeddings): A positional encoding method that rotates embeddings to encode relative positions in transformers. "UNIC composes tasks via composite token sequences with task-aware RoPE and condition bias;"
- SAM 2: A segmentation model producing fine-grained, temporally consistent masks across video frames. "SAM 2 yields fine-grained and temporally consistent hand masks across the sequence."
- Self attention: Attention mechanism where tokens attend to other tokens in the same sequence. "placed after each self attention block."
- Self Forcing: A training scheme that rolls out the student autoregressively to learn self-correction and reduce exposure bias. "Self Forcing runs the causal model autoregressively on video streams and applies a DMD loss"
- Sequencewise concatenation: Concatenating source and target tokens along the sequence dimension, increasing attention cost. "Sequencewise concatenation patchifies the source and concatenates its patches with those of the target along the sequence dimension."
- Temporal consistency: The stability and coherence of edited content across frames over time. "and temporal consistency under typical egocentric scenarios"
- Transformer backbone: The core transformer network used as the primary architecture for generation/editing. "with a transformer backbone"
- VLM (Vision-LLM) score: An evaluation metric derived from a vision-LLM to assess edit faithfulness/quality. "according to VLM score on EgoEditBench and EditVerseBench"
Collections
Sign up for free to add this paper to one or more collections.

