Scaling Instruction-Based Video Editing with a High-Quality Synthetic Dataset
Abstract: Instruction-based video editing promises to democratize content creation, yet its progress is severely hampered by the scarcity of large-scale, high-quality training data. We introduce Ditto, a holistic framework designed to tackle this fundamental challenge. At its heart, Ditto features a novel data generation pipeline that fuses the creative diversity of a leading image editor with an in-context video generator, overcoming the limited scope of existing models. To make this process viable, our framework resolves the prohibitive cost-quality trade-off by employing an efficient, distilled model architecture augmented by a temporal enhancer, which simultaneously reduces computational overhead and improves temporal coherence. Finally, to achieve full scalability, this entire pipeline is driven by an intelligent agent that crafts diverse instructions and rigorously filters the output, ensuring quality control at scale. Using this framework, we invested over 12,000 GPU-days to build Ditto-1M, a new dataset of one million high-fidelity video editing examples. We trained our model, Editto, on Ditto-1M with a curriculum learning strategy. The results demonstrate superior instruction-following ability and establish a new state-of-the-art in instruction-based video editing.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making it easy to edit videos using simple text instructions, like “make the sky pink” or “change the person’s shirt to red,” and having a computer do the rest. The authors build a huge, high-quality training dataset and a new model so that video editing can follow instructions accurately, look good, and stay consistent across frames.
They call their data pipeline Ditto, their dataset Ditto-1M (one million examples), and their final model Editto.
What problem are they trying to solve?
- Editing videos with text instructions is much harder than editing single images. A video has many frames, and any change must stay consistent from start to finish (no flickering, no weird changes in identity or background).
- Good models need lots of high-quality “paired” examples (original video + instruction + edited video). These are extremely rare and expensive to make by hand.
- Past methods either produced limited, lower-quality edits or were too slow and costly to scale.
In simple terms: they want a way to create a huge amount of excellent training data cheaply and reliably, and then train a model that edits videos smoothly and correctly based on text commands.
Key goals in simple terms
- Build a massive dataset of edited videos that match text instructions and look great.
- Keep the motion and structure of the original video while applying the edit (no broken backgrounds or jumping styles).
- Make the process fast and affordable so it can scale to millions of examples.
- Train a model that can follow instructions well without always needing extra visual hints.
How did they do it? (Methods explained with everyday analogies)
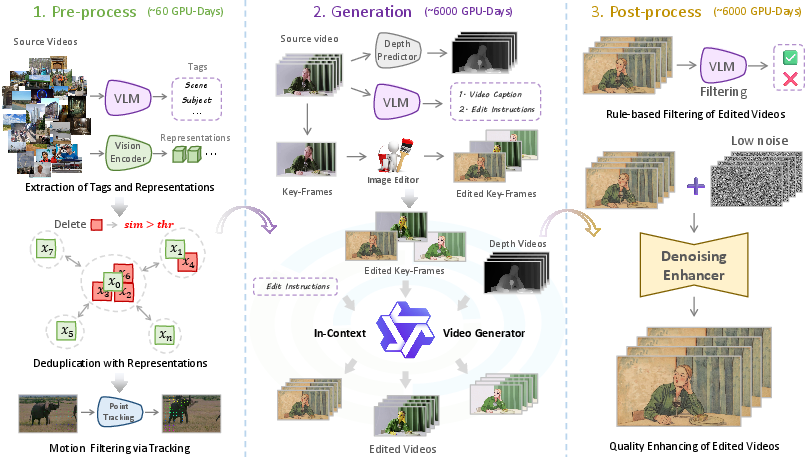
Think of their pipeline like a three-part “edit factory” that turns raw videos into polished, instruction-based edits:
- Step 1: Pick good source videos
- They use professional-looking clips from Pexels and remove duplicates.
- They only keep videos with real movement (like tracking “dots” across frames to measure motion), because edits are more meaningful when things move.
- Everything is standardized to the same resolution and frame rate.
- Step 2: Create smart, guided edits
- Write good instructions: A “smart assistant” (a Vision-LLM, or VLM) first describes the video, then invents a fitting edit instruction—for example, local edits (“make the car blue”) or global edits (“turn the scene into watercolor style”).
- Edit a key-frame: A top image editor changes one frame (like the “poster shot” of the video) according to the instruction. This frame becomes the “appearance guide” for the whole video.
- Add depth: They predict a “depth video,” which is like a rough 3D map of how far things are from the camera in each frame. This helps keep the shapes and motion consistent after editing.
- Generate the edited video: Using an “in-context” video generator, the model looks at the edited key-frame (appearance), the depth video (structure), and the text instruction (goal) to produce a full edited video that spreads the change across all frames smoothly.
- Step 3: Check and polish the result
- Automatic quality control: The same smart assistant checks if the edited video really follows the instruction, preserves the original scene’s motion and meaning, and looks clean. It also filters out unsafe content.
- Gentle cleanup: A special “fine denoiser” lightly removes small visual artifacts without changing the meaning or the style—like a quick touch-up pass.
To make this pipeline fast and scalable:
- They “distill” a big, slow model into a faster one (like an experienced teacher training a student).
- They “quantize” the model (compressing it to run faster with less memory).
- Together, these reduce costs to about 20% of the original while keeping high quality.
What are the main results, and why do they matter?
- They built Ditto-1M: over one million edited video examples at 1280×720, 101 frames, 20 FPS, covering both global style changes and local object edits. This is much larger and higher-quality than past datasets.
- They trained Editto, their instruction-based video editor. To teach it to rely on text alone:
- They used “modality curriculum learning,” like training wheels. At first, the model sees both the text instruction and the edited key-frame. Over time, they remove the visual hint, so the model learns to follow text by itself.
- Compared to other methods, Editto:
- Follows instructions better (videos match the text goals more closely).
- Stays temporally consistent (no flickering; style and identity are stable across frames).
- Looks more visually appealing.
- Human studies and automatic scores both show Editto is state-of-the-art among similar systems.
Why this matters:
- It pushes video editing closer to being as easy as telling a smart tool what you want.
- It opens the door for creators, educators, and small studios to make high-quality video edits quickly and cheaply.
- The dataset, model, and code are shared, helping the research community build even better tools.
What’s the bigger impact?
- Democratized video creation: More people can make polished video content by writing simple instructions, without deep editing skills.
- Faster workflows: Brands, filmmakers, teachers, and social media creators can produce various versions and styles quickly.
- Better research: A large, clean dataset and a strong baseline model encourage new ideas and improvements in video AI.
- Ethical and safe: Automatic filters help keep the dataset and outputs appropriate.
In short, the paper shows a practical, scalable way to build high-quality training data and a model that can smoothly, accurately edit videos from plain text, moving this technology from “almost there” to “ready for real-world use.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow-up research.
- Dataset domain bias: The source pool is limited to professional Pexels videos; impact on generalization to user-generated, handheld, low-light, noisy, or highly dynamic footage is not measured.
- Demographic and content coverage: No analysis of geographic, cultural, age, skin tone, attire, or scene diversity; fairness and representation across human-centric videos are unreported.
- Instruction diversity and distribution: Lacks quantitative breakdown (e.g., lexical diversity, edit categories, compositional complexity, locality vs. global edits, multi-step edits) and per-category performance.
- Imbalance of edit types: The dataset skews toward global edits (~700k) versus local edits (~300k); the effect of this imbalance on model performance (especially object-level insertion/removal/replacement) is not evaluated.
- Key-frame selection strategy: Criteria for choosing the anchor frame are unspecified; the sensitivity of outcomes to selection policy (e.g., mid-clip vs. high-motion vs. salient-object frames) remains unexplored.
- Handling of content emerging after the key frame: While the model claims to “handle newly emerging information,” there is no systematic evaluation of cases where edited objects appear, disappear, or undergo occlusion after the anchor frame.
- Depth guidance limitations: Reliance on predicted depth may fail on non-rigid motion, fast camera pans, specular/transparent surfaces, heavy occlusions, and dynamic backgrounds; robustness is not studied.
- Alternative structural signals: No ablation comparing depth-only guidance versus optical flow, scene flow, tracking features, or 3D reconstructions for better motion and geometry preservation.
- Masking and spatial targeting: The pipeline mentions VACE can use masks, but masks are not generated or leveraged in experiments; lack of spatially scoped edits may lead to spillover changes and is not quantified.
- Temporal enhancer details: The “temporal enhancer” is referenced but its architecture, training procedure, and ablations are missing; the specific contribution to flicker reduction and coherence is unknown.
- Distillation and quantization specifics: Absent details on teacher models, distillation objectives, bit-precision, latency/memory improvements, and quality trade-offs; per-sample generation time is not reported.
- Scalability economics: Despite the 12,000 GPU-day investment, practical per-sample cost, throughput, and scaling projections to 10M+ samples are not provided; carbon footprint and sustainability are unaddressed.
- Instruction generation reliability: A single VLM (Qwen2.5-VL) generates instructions; error modes (impossible, unsafe, physically implausible, or underspecified edits) and their prevalence are not analyzed.
- Circularity of evaluation: The same VLM family is used for instruction creation and quality filtering and contributes the “VLM score”; potential evaluator bias and overfitting to the judge’s preferences are not mitigated or quantified.
- Quality filtering calibration: Thresholds, false reject/accept rates, and inter-judge agreement for the VLM-based filter are not reported; no audit of the filter’s consistency across content types and styles.
- Safety and ethics: The safety filter categories are listed, but bias in filtering (e.g., disproportionate removal of certain cultures/attires), treatment of identifiable individuals, consent, and deepfake misuse mitigation are not explored.
- Licensing and release constraints: The legality of redistributing derived videos from Pexels under the Pexels License, and the completeness of release (source videos, instructions, edited videos, depth maps, metadata, prompts, and filters) are unclear.
- Curriculum learning schedule: The annealing schedule for dropping visual scaffolds is not specified; sensitivity analyses (schedule shape, pace, probabilistic mixing) and generalization impact are missing.
- Instruction-only robustness: The model’s behavior with purely textual instructions that are compositional, long, multilingual, or numerically precise (e.g., “add five red balloons”) is not benchmarked.
- Long-horizon temporal stability: Trained and evaluated on ~5-second clips (101 frames at 20 FPS); stability and drift on longer sequences (e.g., 30–120 seconds) are not assessed.
- Objective temporal metrics: Temporal consistency is measured via CLIP-F; no comparison with motion-aware metrics (e.g., warping error, flicker index, FVD/FVD-VideoEdit) or human perception of temporal artifacts.
- Edit faithfulness metrics: Beyond CLIP-T and VLM score, there is no category-specific edit accuracy metric (e.g., attribute-level correctness, spatial alignment, identity preservation) or evaluation on standardized video-edit benchmarks.
- Human study transparency: The user study (1,000 ratings) lacks details on protocol, rater demographics, inter-rater reliability, statistical significance, and test set composition; reproducibility is limited.
- Baseline breadth: Comparisons omit several recent instruction-video editing datasets/models (e.g., Señorita-2M, InstructVEdit, DreamVE) and don’t include stronger commercial or proprietary baselines where feasible.
- Generalization beyond training distribution: No analysis of out-of-distribution instructions, unusual scenes (underwater, extreme weather), or edge cases (extreme motion blur, rolling shutter).
- Identity and style preservation: Quantitative evaluation of identity consistency in human subjects and style continuity across frames is limited; failure rates on face/body edits are not reported.
- Edit locality control: Mechanisms to constrain edits to regions (e.g., per-object masks, bounding boxes, textual grounding) are not implemented/evaluated; unintended background changes are not measured.
- Multi-turn and iterative editing: The pipeline does not support or evaluate sequential edits (e.g., “now also change the background,” “undo last change”) common in interactive workflows.
- Audio-visual coherence: Audio is ignored; open question how edits (especially pacing, scene changes) might coordinate with audio and whether audio-aware editing or preservation is possible.
- Data contamination risks: Training on outputs from VACE and Wan2.2 may bake in their biases; evaluation could be in-domain, inflating perceived performance; isolation from generator-induced artifacts is not examined.
- Failure case taxonomy: There is no curated set of failure modes (e.g., ghosting, geometry breakage, color bleeding, temporal pop-in/out) with frequencies and root cause analyses to guide model improvements.
- Real-time/interactive feasibility: Latency, memory footprint, and throughput for interactive editing are not provided; it’s unclear whether Editto can meet production or creative tooling constraints.
- Extensibility to 3D-aware edits: The pipeline does not explore explicit 3D scene modeling (NeRFs, 3D Gaussian splats) to improve parallax edits, camera re-projection, or physically plausible object insertion.
- Transfer to other modalities: No experiments on integrating segmentation, pose, depth-from-motion, or textual grounding to enable targeted, multi-modal edits beyond keyframe + depth conditioning.
- Reproducibility details: Full training hyperparameters, data splits, augmentations, inference parameters, and code for prompts/filters are not documented; end-to-end reproducibility is uncertain.
Practical Applications
Immediate Applications
The following applications can be deployed with current tooling (as described in the paper) and modest engineering integration. Each item names sectors and notes key dependencies or assumptions.
- Instruction-driven video editing for creators and agencies (media, advertising, social media)
- What: Text-guided global and local edits (style changes, background replacement, object add/remove/modify) for short-form and long-form videos.
- Tools/workflows: Editto model exposed as a cloud API or NLE plugin (e.g., Adobe Premiere Pro, DaVinci Resolve, CapCut), batch edit queues, prompt templates for common edits.
- Dependencies/assumptions: GPU-backed inference; content rights; safety filtering; instruction quality; acceptance of 20 FPS/101-frame clips or stitching for longer videos.
- Dynamic creative optimization (marketing tech, A/B testing)
- What: Generate multiple instruction-conditioned variants of a base video (colorways, product placements, CTAs) for A/B testing at scale.
- Tools/workflows: Prompt libraries tied to campaign metadata; auto-metrics logging per variant; VLM-based QC to enforce brand and legal constraints.
- Dependencies/assumptions: Brand asset libraries; policy constraints (logo usage); VLM filter thresholds calibrated to minimize false positives/negatives.
- Privacy redaction and compliance edits (public sector, healthcare, enterprise IT)
- What: Text or mask-guided removal/blur/replace of faces, license plates, logos, badges in bodycam, retail, or clinical workflow videos.
- Tools/workflows: Detector → instruction-based edit pipeline; audit logs; human-in-the-loop verification for high-risk redactions.
- Dependencies/assumptions: Accurate detection/segmentation upstream; traceability (provenance) requirements; domain shift from Pexels-like footage.
- Localization and regulatory adaptation (media localization, e-commerce)
- What: Replace signage, add subtitles embedded in scene, swap region-specific imagery; remove restricted content per locale via instructions.
- Tools/workflows: Prompt templates per market; batch processing; VLM consistency checks for instruction fidelity.
- Dependencies/assumptions: Cultural review; language-specific typography; QA on temporal consistency around edited regions.
- Product video restyling and background control (e-commerce, fashion)
- What: Change colorways, textures, accessories; replace or clean backgrounds while preserving motion.
- Tools/workflows: SKU-linked prompt generation; controlled key-frame editing plus propagation; catalog integration.
- Dependencies/assumptions: Consistent product geometry across frames; rejection sampling to avoid identity drift.
- Real-estate and interior “virtual staging” in motion (proptech)
- What: Replace furnishings, adjust materials, change time-of-day/season in walkthrough videos.
- Tools/workflows: Object lists → per-room instruction sets; agent-based QC to reject geometry conflicts; client review UI.
- Dependencies/assumptions: Accurate depth and layout signals; disclosure requirements for staged media.
- Post-production acceleration for VFX previsualization (film/TV, game cinematics)
- What: Fast previsual edits for look-dev and style exploration without shot-specific tuning.
- Tools/workflows: Shot bins → instruction variants; editor “compare takes” panels; integration with storyboard tools.
- Dependencies/assumptions: Acceptable artifact rate for previz; handoff to traditional VFX for final shots.
- Dataset creation and benchmarking for academia (computer vision, generative modeling)
- What: Use Ditto-1M for training/evaluating instruction-following, temporal coherence, and modality curriculum learning.
- Tools/workflows: Open dataset + recipes; standardized metrics (CLIP-T, CLIP-F, VLM scores); ablation baselines.
- Dependencies/assumptions: License compliance; compute resources for fine-tuning; reproducibility of curated filtering.
- Synthetic-to-real stylization reversal and domain adaptation (vision research)
- What: Train models to translate stylized/synthetic sequences back to photo-real (sim2real bridging).
- Tools/workflows: Paired stylized↔original sequences from Ditto pipeline; curriculum training scripts.
- Dependencies/assumptions: Coverage of style variants; generalization beyond Pexels domain; task-specific evaluation.
- Agentic quality control for multimodal data pipelines (MLOps)
- What: Repurpose the VLM-based instruction generation and QC filter to other video generation/editing pipelines.
- Tools/workflows: Prompt banks; rule-based and learned thresholds; rejection sampling at scale; audit dashboards.
- Dependencies/assumptions: Access to capable VLM; safety taxonomy; budget for repeated passes on failures.
- Cost-efficient video generation at scale (cloud infrastructure, platform providers)
- What: Deploy distilled/quantized in-context generators plus temporal enhancers to cut inference cost by ~80% without sacrificing coherence.
- Tools/workflows: Autoscaling GPU clusters; mixed-precision/quantized inference; caching for repeated assets.
- Dependencies/assumptions: Licensing of teacher models; monitoring for flicker/identity drift; performance on longer clips.
Long-Term Applications
These applications likely require further research, scaling, or engineering, including longer-context modeling, real-time/edge deployment, audio-visual alignment, or stronger safety/provenance controls.
- Real-time, on-device instruction-based video editing (mobile, AR/VR)
- What: Voice-driven edits on live or recently captured footage on phones or AR glasses.
- Needed advances: Further distillation/quantization; streaming inference; efficient depth/segmentation on-device; thermal/power constraints.
- Dependencies/assumptions: High-end NPUs/GPUs; low-latency VLMs; robust safety gating on-device.
- Script-aware, multi-shot editorial assistants (film/TV, creator tools)
- What: Apply story-level instructions across multiple scenes with character/style continuity and shot-scale awareness.
- Needed advances: Long-context video modeling; identity tracking across shots; shot layout understanding; multi-turn instruction following.
- Dependencies/assumptions: Access to edit decision lists (EDLs); integration with asset management.
- Automated compliance and standards enforcement at broadcasters (policy-tech)
- What: Continuous monitoring and auto-editing to meet watershed rules, regional ad standards, sponsorship disclosures.
- Needed advances: High-accuracy content understanding; explainable QC; legally robust audit logs and provenance.
- Dependencies/assumptions: Regulatory acceptance; standardized watermark/provenance (e.g., C2PA).
- Privacy-by-default de-identification in sensitive video streams (public safety, healthcare)
- What: Always-on masking/replacement of PII with reversible tokens for authorized review.
- Needed advances: Near-zero false negative rates; reversible cryptographic overlays; robust temporal tracking under occlusion.
- Dependencies/assumptions: Policy frameworks; secure key management; oversight processes.
- Robotics and autonomous systems domain randomization via video-level edits (robotics, simulation)
- What: Generate photorealistic environmental variations from real captures to harden perception and control policies.
- Needed advances: Edit control tied to task curricula; guarantees on geometric/physical plausibility; integration with sim logs.
- Dependencies/assumptions: Labels preserved post-edit; evaluation protocols for sim2real gains.
- Education content personalization at scale (edtech)
- What: Adapt instructor videos (backgrounds, visual aids, language scaffolds) to learner profiles, accessibility needs, and cultural context.
- Needed advances: Fine-grained, pedagogy-aware edit planning; alignment with learning goals; audio/visual synchronization.
- Dependencies/assumptions: Consent and content rights; bias auditing; localized review.
- E-commerce “shoppable video” auto-authoring (retail tech)
- What: Convert raw product clips into platform-optimized videos with dynamic overlays, localized CTAs, and style harmony.
- Needed advances: Tight integration with catalog/price feeds; LTV-aware creative optimization; live A/B loops.
- Dependencies/assumptions: Accurate product metadata; attribution measurement; brand governance.
- Holistic multi-modal editing (audio, captions, gestures) with consistency guarantees (media tools)
- What: Joint edit of visuals, audio tracks, and subtitles from unified instructions (e.g., “make it rainy at dusk and adjust soundtrack accordingly”).
- Needed advances: Cross-modal generative alignment; lip-sync/phoneme preservation; causal temporal modeling.
- Dependencies/assumptions: Rights to music/voice; robust evaluation metrics for cross-modal coherence.
- Provenance and deepfake-risk mitigation ecosystems (policy, platform safety)
- What: Built-in watermarking and edit provenance for instruction-based edits; risk scoring for manipulated media.
- Needed advances: Tamper-resistant watermarks for video diffusion; standardized disclosure; detection models trained on Ditto-like edits.
- Dependencies/assumptions: Industry standards adoption; minimal quality impact from watermarking.
- Long-horizon, high-resolution video editing for broadcast and cinema (media engineering)
- What: Consistent edits over minutes at 4K+ with complex motion and lighting changes.
- Needed advances: Memory-efficient long-sequence modeling; better temporal enhancers; distributed inference pipelines.
- Dependencies/assumptions: Substantial compute budgets; robust failure recovery; advanced QC tools.
- Domain-specialized editing in scientific/medical videos (research, healthcare)
- What: Artifact removal, annotation overlays, or anonymization with domain guarantees (e.g., endoscopy, microscopy).
- Needed advances: Domain-tailored depth/geometry estimation; clinically validated QC; regulators’ acceptance.
- Dependencies/assumptions: Strict data governance; expert-in-the-loop validation; shifted training distributions.
- Intelligent agent orchestration for data curation across modalities (MLOps, foundation models)
- What: Generalize the VLM agent’s instruction/QC loop to curate multimodal synthetic datasets with targeted distributions.
- Needed advances: Program synthesis for diverse tasks; active learning loops; bias/coverage monitoring at scale.
- Dependencies/assumptions: Budget for large-scale rejection sampling; comprehensive safety taxonomies.
Cross-cutting assumptions and risks affecting feasibility
- Licensing and compliance: Pexels-derived training footage, third-party models (VACE, Wan2.2, Qwen-Image, VLMs) carry licenses and usage constraints.
- Compute and cost: While distillation/quantization reduce cost, high-quality, long-horizon, or batch deployments still require substantial GPU capacity.
- Domain shift: Ditto-1M emphasizes high-aesthetic, natural-motion content; performance may degrade on surveillance, egocentric, medical, or low-light domains without adaptation.
- Safety and misuse: Strong editing capability raises deepfake risks; deployments should include watermarking/provenance, safety filters, and human review for sensitive use.
- Technical limits: Temporal coherence can still falter under fast motion/occlusion; audio is not edited; current clips are 101 frames at 20 FPS—long-form support needs stitching or extended context models.
- QC dependence: VLM-based quality filters can be biased; thresholds require calibration and continuous monitoring.
Glossary
- AdamW optimizer: A variant of Adam that decouples weight decay from the gradient update to improve generalization. "The model is trained for approximately 16,000 steps using the AdamW optimizer~\citep{loshchilov2017adamw} with a constant learning rate of 1e-4"
- Annealing: Gradually reducing a training aid or constraint over time to encourage harder learning (e.g., less visual guidance). "As training progresses, we gradually anneal the visual guidance, compelling the model to learn the more difficult, abstract mapping from text instruction alone."
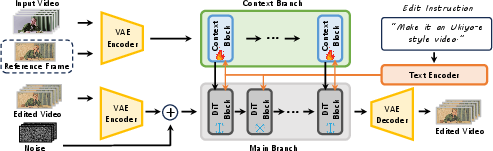
- Attention mechanism: A neural mechanism that weights and integrates information across inputs (e.g., text, images, depth) to guide generation. "By integrating these three modalities with the attention mechanism, VACE can faithfully propagate the edit defined in across the entire sequence"
- CLIP-F: A metric that measures inter-frame CLIP similarity to assess temporal consistency in videos. "CLIP-F calculates the average inter-frame CLIP similarity to gauge temporal consistency"
- CLIP-T: A metric that measures CLIP text-video similarity to evaluate instruction adherence. "CLIP-T measures the CLIP text-video similarity to assess how well the edit follows the instruction"
- CoTracker3: A point-tracking method for videos used to quantify motion via trajectories. "use CoTracker3~\citep{karaev2024cotracker3} to track these points, obtaining their trajectories."
- Context Branch: A network component that extracts spatiotemporal features from visual inputs to condition generation. "It consists of a Context Branch for extracting spatiotemporal features from the source video and reference frame"
- Curriculum learning: A training strategy that starts with easier tasks or stronger guidance and progressively increases difficulty. "We trained our model, Editto, on Ditto-1M with a curriculum learning strategy."
- DDIM inversion: A technique that inverts diffusion sampling to reconstruct latent states for editing or consistency. "Zero-shot techniques like TokenFlow~\citep{tokenflow2023} and FateZero~\citep{qi2023fatezero} use DDIM inversion and feature propagation to enforce the consistency of the edited video."
- Denoiser: A diffusion model component that removes noise during generation, often specialized into coarse and fine stages. "employs a coarse denoiser for structural and semantic formation under high noise, and a fine denoiser specialized in later-stage refinement under low noise."
- Depth-derived motion representation: A motion cue computed from depth that guides coherent video synthesis. "an in-context video generator that conditions on both a reference edited frame and a depth-derived motion representation."
- Depth video: A sequence of per-frame depth maps used to preserve geometry and motion during generation. "The predicted depth video acts as a dynamic structural scaffold, providing an explicit, frame-by-frame guide for the structure and geometry of the scene during the video generation."
- DiT-based: Based on Diffusion Transformers, a transformer architecture adapted for diffusion generative modeling. "a DiT-based~\citep{peebles2023dit} Main Branch that synthesizes the edited video under the joint guidance of the visual context and the new textual embeddings from the instruction."
- Distilled video model: A smaller, faster model trained to mimic a larger teacher, reducing cost while retaining quality. "our pipeline integrates a distilled video model with a temporal enhancer."
- Feed-forward Methods: End-to-end models that generate outputs in one pass without per-sample optimization or inversion. "Feed-forward Methods. These end-to-end models aim to overcome inversion-based limitations"
- Feature propagation: Transferring features across frames to maintain consistency in edited videos. "Zero-shot techniques like TokenFlow~\citep{tokenflow2023} and FateZero~\citep{qi2023fatezero} use DDIM inversion and feature propagation to enforce the consistency of the edited video."
- Flow matching: A generative training objective that learns a vector field to map noisy latents to clean data. "We train the model using the flow matching~\citep{lipman2022flowmatch} objective:"
- Generative prior: Learned distributional knowledge in a base model that helps produce realistic outputs. "To maintain the strong generative prior of the base model and ensure training efficiency"
- In-context video generator: A video model conditioned on rich visual prompts (images, masks, videos) to produce edits. "We select the in-context video generator VACE~\citep{jiang2025vace} as our backbone"
- Instruction Fidelity: A criterion assessing how accurately the edited video reflects the textual prompt. "Instruction Fidelity: whether the edit in accurately reflects the prompt ."
- Inversion-based Methods: Editing approaches that invert diffusion processes to enable consistent modifications, often computationally heavy. "Inversion-based Methods. These methods avoid paired video-text-edit data but are computationally intensive."
- Key-frame: A representative frame chosen as an anchor to define appearance for video-level editing. "We first select a key-frame from the source video as the anchor for the editing."
- Knowledge distillation: Transferring knowledge from a large teacher model to a smaller student to speed up inference. "we employ model quantization and knowledge distillation techniques~\citep{yin2025causvid}."
- Mixture-of-Experts (MoE): An architecture that routes inputs to specialized expert networks for improved performance. "Wan2.2's Mixture-of-Experts (MoE) architecture, which employs a coarse denoiser for structural and semantic formation under high noise, and a fine denoiser specialized in later-stage refinement under low noise."
- Modality curriculum learning (MCL): A curriculum strategy that transitions from visual-plus-text conditioning to text-only editing. "we introduce a modality curriculum learning (MCL) strategy."
- Model quantization: Reducing parameter precision to lower memory and compute cost with minimal quality loss. "we employ model quantization and knowledge distillation techniques~\citep{yin2025causvid}."
- Motion score: A quantitative measure of video dynamics based on tracked point displacements. "We then compute the average of the cumulative displacements of all tracked points over the entire video as the motion score of the video."
- Near-Duplicate Removal: A deduplication step that filters highly similar videos to ensure diversity. "Near-Duplicate Removal: To prevent dataset redundancy and ensure broad content diversity, we implement a rigorous deduplication process."
- Post-training quantization: Applying quantization after training to shrink the model and accelerate inference. "We apply post-training quantization to reduce the model's memory footprint and inference cost with minimal impact on output quality."
- Rejection sampling: Automatically discarding low-quality or instruction-mismatched samples via a judging agent. "We first use a VLM~\citep{bai2025qwen25vl} as an automated judge to perform rejection sampling."
- Spatiotemporal coherence: Consistency across space and time in video edits, avoiding geometry or motion artifacts. "This is combined with depth-guided video context to ensure spatiotemporal coherence, significantly improving the diversity and fidelity of generated edits."
- Spatiotemporal features: Features capturing both spatial content and temporal dynamics used to condition generation. "It consists of a Context Branch for extracting spatiotemporal features from the source video and reference frame"
- Temporal coherence: Smoothness and consistency of changes across frames without flicker or drift. "augmented by a temporal enhancer, which simultaneously reduces computational overhead and improves temporal coherence."
- Temporal enhancer: A component that stabilizes video generation over time, reducing flicker and artifacts. "our pipeline integrates a distilled video model with a temporal enhancer."
- Text-to-Video (T2V): Generative models that synthesize or refine video from textual inputs. "the state-of-the-art open-source Text-to-Video (T2V) model, Wan2.2~\citep{wan2025}."
- Vector field: The learned directional field in flow matching that maps noisy latents toward clean targets. "and is the model's predicted vector field pointing from to ."
- Video depth predictor: A model that estimates per-frame depth to preserve structure in generated videos. "we extract a dense depth video from with a video depth predictor ~\citep{chen2025videodepthany}."
- Vision-LLM (VLM): A multimodal model that jointly understands visual and textual inputs for tasks like instruction generation and filtering. "we deploy an autonomous Vision-LLM (VLM) agent."
- Visual prior: A strong visual reference (e.g., an edited frame) used to guide video generation toward target appearance. "the pipeline generates a high-quality edited reference frame that acts as a strong visual prior."
- Zero-shot techniques: Methods that perform tasks without task-specific training by leveraging model priors and inversion/control. "Zero-shot techniques like TokenFlow~\citep{tokenflow2023} and FateZero~\citep{qi2023fatezero} use DDIM inversion and feature propagation to enforce the consistency of the edited video."
Collections
Sign up for free to add this paper to one or more collections.