Region-Constraint In-Context Generation for Instructional Video Editing
Abstract: The In-context generation paradigm recently has demonstrated strong power in instructional image editing with both data efficiency and synthesis quality. Nevertheless, shaping such in-context learning for instruction-based video editing is not trivial. Without specifying editing regions, the results can suffer from the problem of inaccurate editing regions and the token interference between editing and non-editing areas during denoising. To address these, we present ReCo, a new instructional video editing paradigm that novelly delves into constraint modeling between editing and non-editing regions during in-context generation. Technically, ReCo width-wise concatenates source and target video for joint denoising. To calibrate video diffusion learning, ReCo capitalizes on two regularization terms, i.e., latent and attention regularization, conducting on one-step backward denoised latents and attention maps, respectively. The former increases the latent discrepancy of the editing region between source and target videos while reducing that of non-editing areas, emphasizing the modification on editing area and alleviating outside unexpected content generation. The latter suppresses the attention of tokens in the editing region to the tokens in counterpart of the source video, thereby mitigating their interference during novel object generation in target video. Furthermore, we propose a large-scale, high-quality video editing dataset, i.e., ReCo-Data, comprising 500K instruction-video pairs to benefit model training. Extensive experiments conducted on four major instruction-based video editing tasks demonstrate the superiority of our proposal.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ReCo, a new way to edit videos using only a text instruction (like “add a crown on the seal” or “turn this into a watercolor style”). Unlike many older methods, ReCo doesn’t need you to draw a mask or mark the exact area to change. It teaches an AI model to figure out where to edit and how to keep the rest of the video stable and natural.
Key Objectives
The researchers focus on two simple questions:
- How can the model find the right place in a video to edit when it only has a text instruction?
- How can the model change the chosen area without accidentally messing up other parts of the video or letting old content interfere with new content?
How It Works (in everyday language)
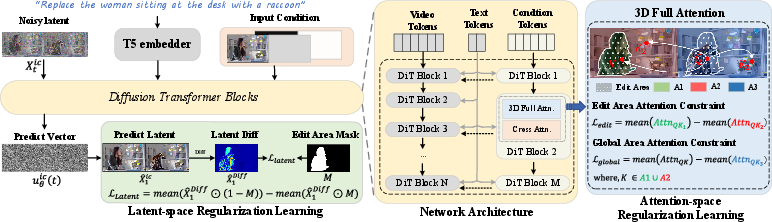
Think of video editing with AI as cleaning a noisy picture until it looks like the final edited version. ReCo uses a powerful “diffusion” model, which is like starting with a blurry, static-filled video and learning how to remove the noise step by step to reveal the edited result.
Here are the key ideas, explained simply:
- In-context generation: ReCo places the original video and the edited video side-by-side (like two panels next to each other) and trains the model to “clean” both at the same time. This helps the model understand what should stay the same and what should change.
- Latents: These are compressed “shadow versions” of a video that the model works on internally. Changing latents is like adjusting a hidden blueprint instead of directly editing pixels.
- Attention: This is the model’s “focus.” It decides which parts of the video influence each other. Good attention helps the model insert new things smoothly into the scene.
- Regularization: These are extra rules added during training to guide the model. Think of them as gentle penalties that teach the model to focus edits in the right spot and avoid weird side effects.
Two region-based rules that make ReCo precise
To keep changes in the right place and avoid unwanted interference, ReCo adds two smart rules:
- Latent-space regional rule
- Goal: Make big changes in the part that should be edited, and keep changes small elsewhere.
- Analogy: If you’re told to change the color of the car, this rule makes sure the “car blueprint” is adjusted a lot, while the background “blueprint” hardly moves.
- Attention-space regional rule
- Goal: When the model is creating a new object (like adding a hat), it should pay less attention to the old version of that spot in the source video and more attention to the new video’s own background.
- Analogy: If you replace a boy with a girl in a scene, the model should stop thinking too hard about the boy in the original video and instead focus on how the girl fits with the couch, lighting, and motion.
Together, these rules help ReCo:
- Pinpoint the correct editing region from just text,
- Keep the rest of the video stable,
- Blend changes naturally with the original background.
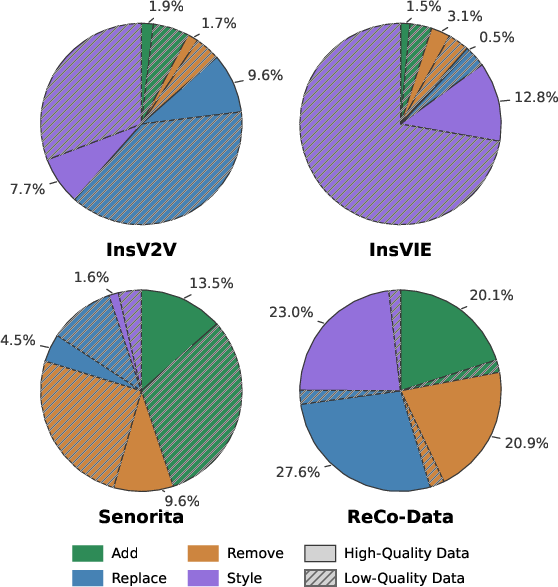
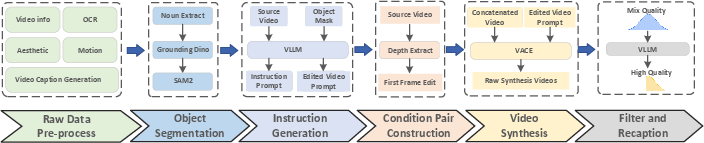
A large, high-quality training dataset: ReCo-Data
The team also built a huge dataset called ReCo-Data with 500,000 instruction-video pairs. It covers four major tasks:
- Add an object,
- Replace an object,
- Remove an object,
- Change the whole style of the video.
They carefully filtered and captioned this data so it’s high quality and balanced across tasks. This helps the model learn reliably and perform well in real cases.
Main Findings
ReCo was tested against several strong video editors on the four tasks above. The evaluation used an AI “judge” to score:
- Edit accuracy: Did the model follow the instruction and edit the right area while preserving the rest?
- Video naturalness: Do the edited objects look the right size, appearance, and move naturally?
- Video quality: Are there few visual glitches? Is the video stable over time?
Across all tasks, ReCo scored higher overall, meaning:
- It followed instructions more accurately,
- It kept backgrounds consistent,
- It produced cleaner, more stable videos,
- It blended new or changed objects smoothly into scenes.
In simple terms, ReCo made the right changes in the right place, and kept everything else looking good.
Why This Matters
- Easier video editing: You can edit videos with clear text instructions instead of drawing masks or using complex tools.
- More reliable results: The two region-based rules reduce mistakes like changing the wrong area or mixing old and new content.
- Practical uses: This can help creators, teachers, and filmmakers quickly tweak videos—adding items, replacing characters, removing unwanted objects, or applying artistic styles.
- Strong foundation: The large, clean dataset and the in-context training approach set a new baseline for future video editing systems.
In short, ReCo shows that smart guidance inside the model—where to change and where not to—makes text-based video editing both precise and natural.
Knowledge Gaps
Below is a concise, actionable list of the key knowledge gaps, limitations, and open questions that remain unresolved by the paper. These items are intended to guide future research directions.
- Training-time reliance on binary edit masks: Although the method claims no pre-specified masks at inference, the latent/attention constraints require masks during training; the paper does not quantify how mask quality (noise, boundary accuracy, temporal consistency) affects performance, nor how to remove this dependency via self-/weakly supervised region discovery.
- Mask construction details and robustness: The mask pipeline (segmentation → VAE encoding → k-means binarization) is under-specified; there is no analysis of sensitivity to segmentation errors, binarization thresholds, morphological operations (erode/dilate), or temporal mask propagation errors.
- Generalization beyond synthetic training data: ReCo-Data relies heavily on VLLM-generated instructions and VACE-synthesized videos; the domain gap to real, in-the-wild edits is unmeasured, including robustness to real motion, lighting, compression, and handheld camera artifacts.
- Evaluation bias and reproducibility: The benchmark uses a single VLLM (Gemini-2.5-Flash-Thinking) as the referee; there is no cross-check with human studies, no inter-rater agreement, no robustness across different VLM judges, and no reporting of prompt leakage or scoring variance.
- Lack of objective temporal/visual metrics: No standard metrics (e.g., FVD/KVD, LPIPS, CLIP-based edit alignment, optical-flow consistency, temporal LPIPS/warping error) are reported; thus, temporal stability and fidelity claims are not corroborated by quantifiable, replicable metrics.
- Potential train–test contamination: It is unclear whether the 480-pair evaluation set is strictly disjoint (content, scenes, prompts, style) from ReCo-Data; procedures for de-duplication and near-duplicate filtering are not described.
- Scalability to longer videos and higher resolutions: Training and evaluation are limited to ~5 s, 81 frames at 480×832; there is no evidence on performance for longer sequences, higher resolutions (1080p/4K), higher fps, or multi-shot edits.
- Multi-object and compositional edits: The method is evaluated on single-object or global style edits; it does not report performance for multi-object, multi-attribute, or compositional instructions (e.g., “replace A and B, recolor C, and slow down D”).
- Ambiguous or spatially-referential instructions: There is no analysis on grounding complex language (e.g., “the person on the left in the second row”), disambiguation across similar instances, or failure modes under ambiguous prompts.
- Motion-sensitive edits and occlusions: The approach does not explicitly model or evaluate challenging cases with fast motion, severe occlusions, motion blur, dynamic lighting, or non-rigid deformations.
- Attention-constraint design choices: The paper does not study which layers/heads receive attention regularization, how temporal vs spatial heads are affected, or whether per-layer/per-head weighting is beneficial; no ablations on where and how much to apply the constraint.
- Latent-constraint formulation and schedule: The latent discrepancy constraint uses one-step backward denoised latents and a mean-contrast objective; there is no ablation on timestep sampling, multi-step consistency, alternative discrepancy measures (e.g., contrastive losses, patch-wise ranking), or per-instruction adaptivity.
- Hyperparameter sensitivity: The trade-off weights λ1, λ2, mask sizes, and in-context concatenation choices lack sensitivity analyses; no guidance is provided for stable tuning across datasets or backbones.
- In-context concatenation artifacts and generality: Width-wise concatenation may induce boundary artifacts or bias attention near the seam; impacts of alternative layouts (vertical, tiled, multi-reference) or varying aspect ratios are not explored.
- Backbone dependence and portability: Results are reported only on Wan-T2V-1.3B with LoRA; the method’s portability to other T2V backbones, different VAEs/tokenizers, and training regimes (full fine-tune vs adapters) is untested.
- Video condition branch specification: The architecture, fusion strategy, and role of the video condition branch are under-detailed; there is no ablation to show its necessity or alternatives (e.g., ControlNet-style or cross-attention conditioning).
- Edit strength and user control: The system offers no explicit mechanisms to control edit intensity, regional falloff, or preservation strength; interactive refinement (e.g., iterative prompts, soft region hints) is not supported or evaluated.
- Global vs local multi-task interference: Joint training on local edits and global style transfer could cause conflicts; there is no analysis of task interference, curriculum strategies, or instruction-conditioned loss weighting.
- Identity and attribute preservation: For replace/edit tasks involving humans/animals, identity and attribute consistency (pose, expressions, apparel) are not explicitly measured or preserved with dedicated constraints.
- Physical/scene consistency: Shadows, reflections, contact dynamics, and scene–object interactions are not explicitly modeled; the approach may fail in edits requiring physically plausible integration.
- Robustness to instruction noise and adversarial prompts: There is no study of robustness to typos, slang, multilingual prompts, or adversarial/contradictory instructions.
- Computational efficiency and latency: Training uses 24×A800 GPUs; inference cost, throughput, and memory footprint (with in-context concatenation and attention regularization) are not reported; no speed–quality trade-off is characterized.
- Data construction biases and ethics: VLLM-written instructions and VACE-generated targets may encode stylistic or cultural biases; dataset provenance, licensing, and consent for sourced videos are not addressed.
- Benchmark release and standardization: Details about public release (data, code, evaluation scripts, masks) are scarce; without open artifacts, independent replication and fair comparison are difficult.
- Failure mode taxonomy and diagnostics: The paper lacks a systematic analysis of typical failures (region spillover, re-rendering backgrounds, temporal flicker), nor tools/metrics to diagnose and mitigate them.
- Extension to richer conditioning: Incorporating optional user masks, sketches, bounding boxes, reference images, or audio cues remains unexplored; it is unclear how ReCo would integrate such multi-modal guidance.
- Theoretical understanding of token interference: While attention suppression is motivated, there is no theoretical or empirical study of when suppression harms needed source cues (e.g., geometry, pose) versus when it helps, nor adaptive mechanisms to balance both.
Practical Applications
Practical Applications of ReCo (Region-Constraint In-Context Generation for Instructional Video Editing)
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations. Applications are grouped into immediate (deployable now) and long-term (requiring further research, scaling, or development), and organized by sector. Each bullet includes potential tools/workflows and notes on assumptions or dependencies.
Immediate Applications
These applications can be piloted or deployed with current capabilities (mask-free instruction-based editing; local and global edits; LoRA-based domain adaptation; 5-second, 480×832 videos; add/replace/remove/style tasks; ReCo-Data for training; VLLM-based evaluation).
Industry
- Media and entertainment (post-production and short-form content)
- Prompt-to-edit augmentation for social clips: “replace the coffee cup with a tea mug,” “add a confetti burst,” “apply cinematic teal-orange grade.”
- Tools/workflows: NLE plug-ins (Premiere/Final Cut/CapCut) offering “Instructional Edit” panels; batch edit servers for agencies.
- Assumptions/Dependencies: GPU inference; current clip length/resolution limits; legal guardrails for identity edits.
- VFX previsualization and quick look-dev
- Tools/workflows: “Previs with text prompts” module to mock object swaps and style in early production.
- Assumptions/Dependencies: Previs aesthetic acceptable; temporal stability sufficient for rough cuts.
- Advertising and A/B creative iteration
- Tools/workflows: Creative Variants Generator (“change product color,” “add seasonal branding,” “replace background with winter theme”).
- Assumptions/Dependencies: Brand safety review; accurate object localization without masks; QC loop.
- E-commerce and retail
- Background replacement and product relighting in product videos
- Tools/workflows: Prompt-driven “Replace backdrop with neutral studio gray,” “add soft rim light aesthetic.”
- Assumptions/Dependencies: Robustness across product categories; adherence to platform imaging policies.
- Quick compliance edits (remove logos, sensitive text, or faces)
- Tools/workflows: “Compliance Redactor” microservice for “remove all visible license plates/faces/logos.”
- Assumptions/Dependencies: Reliable identification via instruction; human-in-the-loop verification; provenance logging.
- Newsrooms and corporate communications
- Privacy-preserving edits (mask-free redaction)
- Tools/workflows: One-click “remove minor’s face” or “blur bystanders” via textual prompts.
- Assumptions/Dependencies: False-negative risk mitigation; audit trails; policy alignment (C2PA provenance).
- Creator economy and mobile apps
- One-tap stylization and object edits for reels/stories
- Tools/workflows: Mobile SDK with on-device or edge inference; “Replace pet collar color,” “anime style transfer.”
- Assumptions/Dependencies: Latency constraints; reduced model variants; battery/performance budgets.
- Compliance and safety
- Automated policy enforcement for content moderation
- Tools/workflows: Workflow to “remove offensive signs,” “remove gang signs,” “remove weapon depictions where prohibited.”
- Assumptions/Dependencies: Content detection paired with editing; governance and appeal mechanisms.
Academia
- Benchmarks and evaluation protocols for video editing
- Tools/workflows: Reuse the paper’s VLLM-based multi-dimensional rubric (Edit Accuracy, Naturalness, Quality) for standardized evaluation.
- Assumptions/Dependencies: VLLM (e.g., Gemini-2.5-Flash-Thinking) access and stability; rubric generality.
- Data for instruction-based editing research
- Tools/workflows: ReCo-Data (500K instruction-video pairs) as a clean training corpus; ablations on latent/attention region constraints.
- Assumptions/Dependencies: Dataset licensing/availability; domain coverage; reproducibility.
- Efficient adaptation with LoRA adapters
- Tools/workflows: Domain-specific LoRA packs (e.g., medical devices, sports broadcasts) for quick adaptation.
- Assumptions/Dependencies: Sufficient in-domain data; careful safety tuning for sensitive domains.
Policy and Governance
- Content provenance and disclosure workflows
- Tools/workflows: Automatic provenance tags (e.g., C2PA) appended when ReCo-style edits occur; “edited regions” logs.
- Assumptions/Dependencies: Integration with publishing pipelines; stakeholder agreement; watermarks resilient to re-encoding.
- Governance sandboxes for responsible video editing
- Tools/workflows: Policy testbeds evaluating risk controls (identity edits, political content) using ReCo’s mask-free editing.
- Assumptions/Dependencies: Access to constrained test datasets; red-team processes; alignment with local laws.
Daily Life
- Personal video cleanup and privacy
- Tools/workflows: “Remove background clutter,” “blur house number,” “replace loud T-shirt print.”
- Assumptions/Dependencies: Consumer-friendly UI; tutorial prompts; offline/on-device preference.
- Aesthetic stylization for memory videos
- Tools/workflows: “Vintage film style,” “soft pastel look,” “holiday theme” with temporal consistency.
- Assumptions/Dependencies: Acceptance of mild artifacts; defaults guided by safe prompt templates.
Long-Term Applications
These depend on scaling to higher resolutions, longer durations, robust real-time performance, hardened safety, expanded control interfaces, and broader regulatory integration.
Industry
- Broadcast-grade, long-form editorial pipelines
- Tools/products: “Broadcast ReCo” for hour-long content, 4K+ resolution, multi-shot continuity-aware edits.
- Assumptions/Dependencies: Memory-efficient DiTs; chunked or streaming inference with temporal anchoring; robust QC and rollback.
- Real-time/live video augmentation
- Tools/products: Live AR overlays and selective edits (e.g., “remove sponsor A, replace with sponsor B in live feed”).
- Assumptions/Dependencies: Sub-100ms latency; hardware acceleration; failsafes for mis-edits; multi-camera consistency.
- Studio-grade asset and scene understanding
- Tools/products: Edit graphs aware of object identity over time, continuity constraints across scenes, shot matching.
- Assumptions/Dependencies: Object tracking/ID across shots; structured scene graphs; deeper temporal reasoning.
- Cross-modal and 3D-aware content workflows
- Tools/products: 3D-consistent edits from multi-view uploads; propagation across camera angles.
- Assumptions/Dependencies: 3D reconstruction or cross-view correspondence; synchronized capture metadata.
Academia
- Generalized region-constraint paradigms beyond video
- Tools/workflows: Extending latent/attention regional constraints to audio-visual edits, 3D scenes, and robotics perception.
- Assumptions/Dependencies: Cross-modal token alignment; scalable attention regularization.
- Causality-aware and safety-constrained editing
- Tools/workflows: Training objectives that encode causal plausibility (e.g., physics of motion) and safety constraints (“no identity fabrication”).
- Assumptions/Dependencies: Grounded simulators/world models; policy-compliant datasets.
- Open, robust evaluation standards
- Tools/workflows: Community VLLM ensembles and human-in-the-loop protocols; adversarial benchmark suites for temporal coherence and scope precision.
- Assumptions/Dependencies: Access to multiple VLLMs; inter-rater reliability; funding for human studies.
Policy and Governance
- Regulatory frameworks for synthetic video editing at scale
- Tools/workflows: Standards for disclosure, consent, and record-keeping; mandated provenance and edit logs in broadcast/ads.
- Assumptions/Dependencies: Cross-jurisdictional harmonization; enforceable penalties; interoperable metadata formats.
- Misinformation resilience and auditability
- Tools/workflows: Dual pipelines: “editor” and “forensic detector” (watermarks, robust fingerprints) that survive transformations.
- Assumptions/Dependencies: Watermarking that withstands recompression, cropping; widespread adoption by platforms.
Daily Life
- On-device private editing assistants
- Tools/products: Smartphone-optimized models for local “remove sensitive items” without cloud upload.
- Assumptions/Dependencies: Hardware NPUs; distilled models; user education on limits.
- Interactive, multimodal editing (speech + gesture + sketch)
- Tools/products: “Point-and-say” editing on tablets/AR glasses: point to region, say “replace with lamp, warm tone.”
- Assumptions/Dependencies: Reliable multimodal alignment; AR ergonomics; robust spatial tracking.
Key Enablers from the Paper and How They Translate to Practice
- Mask-free, instruction-only video editing
- Practical impact: Reduces prep time and expertise needed; enables text-driven editing UIs.
- Assumptions: Model maintains accurate region localization without explicit masks across varied domains.
- Region-constraint regularization (latent and attention space)
- Practical impact: Better scope precision and background preservation; fewer unintended edits.
- Assumptions: Training masks are accurate; regularizers generalize to unseen content and longer clips.
- In-context joint denoising (source–target concatenation)
- Practical impact: Strong token interaction improves edit fidelity; supports add/replace/remove/style with one model.
- Assumptions: Concatenation design scales to higher resolutions and aspect ratios; memory management for deployment.
- LoRA-based efficient fine-tuning
- Practical impact: Lightweight domain-specific adapters (e.g., sports, product shots) for enterprise pipelines.
- Assumptions: Stable fine-tuning without catastrophic forgetting; clear governance of adapter ownership and use.
- ReCo-Data (500K high-quality instruction–video pairs)
- Practical impact: Strong foundation for training/edit generalization; reduces data cleaning cycles.
- Assumptions: Licenses allow commercial use; coverage of edge cases (occlusion, fast motion, crowded scenes).
Cross-Cutting Assumptions and Dependencies Affecting Feasibility
- Compute and latency: GPU/accelerator access; batching and streaming for longer clips; mobile/on-device constraints.
- Safety and compliance: Guardrails to prevent harmful or deceptive edits; provenance (C2PA) and watermarking in production workflows.
- Legal/policy: Consent for identity edits; IP/brand usage; jurisdiction-specific rules for political content and minors.
- Robustness and generalization: Performance on diverse domains, lighting, motion blur, and complex occlusions.
- Evaluation and QA: Reliance on VLLM-based scoring should be complemented by human review and task-specific metrics.
- Scaling limits: Current model setup trained on 5-second, 480×832 clips; long-form, 4K, multi-shot continuity requires further R&D.
- Data governance: Dataset biases, coverage gaps, and domain specificity; clear documentation and model cards for deployment.
Glossary
- Attention map: The matrix of attention weights indicating how strongly tokens attend to each other within a transformer block. "The similar regularization term is also performed on attention maps of DiT blocks, to suppress the concentration of tokens in the editing region on the tokens of the same region in source video."
- Attention-space regularization: A constraint applied to attention patterns to reduce reliance on source edit regions and strengthen coherence with the target’s background. "Attention-space regularization, which suppresses the attention of the target edit region towards the corresponding region in the source video, thereby mitigating inherent token interference, while simultaneously strengthening the attention on its own generated content."
- Binary latent mask: A binarized mask (1 for edit region, 0 otherwise) defined in latent space to distinguish editing from non-editing areas. "Let be the binary latent mask indicating the editing region (where denotes regions that should be edited)."
- ControlNet: An auxiliary network that conditions diffusion models with structured guidance signals (e.g., maps), often used to control generation. "Ditto learns the condition through a ControlNet manner."
- DDIM inversion: A technique that inverts the DDIM sampling process to recover a latent representation consistent with a given image or frame. "FateZero~\cite{2023fatezero} edits video frames via DDIM~\cite{2021ddimp} inversion."
- Diffusion inversion: Recovering latent noise or trajectory from a generated or real sample to enable editing or further conditioning. "exploit advanced text-to-video diffusion models for more accurate diffusion inversion."
- Diffusion Transformer (DiT): A transformer-based architecture for diffusion modeling that operates over latent representations. "we first review the training procedure of video DiT."
- Edit attention loss: A loss term that reduces attention from target edit-region queries to the source edit-region keys, encouraging novel content. "We define this as the edit attention loss :"
- Flow matching: A training framework that learns a velocity field transporting samples from a prior to the data distribution in continuous time. "Typically, most video DiT models are grounded in flow matching~\cite{flowmatch2022,flowmatchldm2024} theory, which provides a theoretically rigorous framework for learning continuous-time generative processes."
- Flow-matching diffusion loss: The objective used to train diffusion under flow matching by minimizing error between predicted and ground-truth velocity. "The whole framework is jointly optimized by the flow-matching diffusion loss and the two region-constraint regularization terms."
- Forward diffusion process: The process that mixes data latents with noise according to a schedule (e.g., Rectified Flow) to produce noised inputs for training. "via the forward diffusion process based on Rectified Flow"
- Geometric mean: A multiplicative average used to aggregate scores that accounts for proportional relationships between components. "by computing the geometric mean of all sub-dimension scores of each major perspective"
- Global attention loss: A loss term that reduces overall attention to the entire source video while increasing attention to the target video’s own context. "such type of constraint is formulated as the global attention loss :"
- In-context generation: Generating/editing by jointly conditioning on provided exemplars or related inputs (e.g., source-target pairs) without explicit region masks. "The In-context generation paradigm recently has demonstrated strong power in instructional image editing with both data efficiency and synthesis quality."
- Joint denoising: Simultaneous denoising of concatenated source and target inputs to learn coupled reconstruction/editing behavior. "Technically, ReCo width-wise concatenates source and target video for joint denoising."
- Latent discrepancy: The magnitude of difference between source and target latents, designed to be high in edit regions and low elsewhere. "The former increases the latent discrepancy of the editing region between source and target videos while reducing that of non-editing areas"
- Latent-space regional constraint: A loss that maximizes latent differences in edit regions and minimizes them in non-edit regions to focus edits and preserve backgrounds. "we introduce the latent-space regional constraint $\mathcal{L}_{\text{latent}$ to regulate DiT training."
- Logit-normal distribution: A distribution used to sample timesteps where values (after logistic transform) follow a normal distribution. "a timestep are sampled from a logit-normal distribution."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that injects low-rank adapters into model weights. "we exploit the Low-Rank Adaptation (LoRA) technique for efficient and stable video DiT fine-tuning."
- One-shot tuning: Adapting a model to new content using a single example, common when large paired datasets are unavailable. "Early approaches overcome this difficulty using one-shot tuning techniques"
- One-step backward denoised latent: A latent estimate recovered from a noised state and predicted velocity in a single backward step. "we first derive the one-step backward denoised latent "
- Pair-wise constraint: A regularization applied on paired source-target latents to encourage desired regional differences and similarities. "and further conducts a pair-wise constraint to increase the latent discrepancy of the editing region and decrease that of non-editing areas."
- Queries and Keys (Q/K): The attention mechanism’s components where queries attend to keys to form context-weighted representations. "tokens from the target editing region (queries ) should reduce their attention to the corresponding source editing region (keys )."
- Rectified Flow: A specific flow-matching formulation where trajectories are linear in time between noise and data latents. "based on Rectified Flow~\cite{flowmatchldm2024}:"
- Temporal coherence: The consistency of content across frames, critical for video editing without flickering or drift. "employ token-merging or similarity constraints to enhance temporal coherence."
- Token interference: Unwanted influence of tokens from source edit regions on target generation that can degrade edit fidelity. "token interference between editing and non-editing areas during denoising."
- Token merging: A technique that aggregates similar tokens to improve temporal consistency and reduce redundancy in video editing. "employ token-merging or similarity constraints to enhance temporal coherence."
- VAE (Variational Autoencoder): A generative encoder-decoder model that maps inputs to a latent distribution; used here to encode masks to latent resolution. "we first encode the editing mask via VAE~\cite{vae} and then apply -means clustering to binarize them."
- Vector field: A learned function that points in the direction of transport from prior to data at each point in latent space and time. "It aims to learn a vector field that smoothly transports samples from a simple prior distribution (e.g., a Gaussian ) to the target data distribution ."
- Velocity vector: The instantaneous derivative of the latent trajectory with respect to time used as the training target in flow matching. "The ground-truth velocity vector is calculated as:"
- Video condition branch: An explicit conditioning pathway that ingests the source video to calibrate the denoising process. "we employ an additional video condition branch that explores the condition learning on the source video."
- Video stylization: Global transformation of a video’s appearance (e.g., applying a style) rather than local object edits. "instance-level object adding, removing, and replacing, and the global video stylization."
- Vision-Language Large Model (VLLM): A multimodal large model used as an evaluator or assistant for instruction generation and scoring. "and ask the VLLM to give the rating"
- Width-wise concatenation: Joining source and target videos side-by-side (left-right) to create a single input for in-context training. "Technically, ReCo width-wise concatenates source and target video for joint denoising."
Collections
Sign up for free to add this paper to one or more collections.

