InstructX: Towards Unified Visual Editing with MLLM Guidance
Abstract: With recent advances in Multimodal LLMs (MLLMs) showing strong visual understanding and reasoning, interest is growing in using them to improve the editing performance of diffusion models. Despite rapid progress, most studies lack an in-depth analysis of MLLM design choices. Moreover, the integration of MLLMs and diffusion models remains an open challenge in some difficult tasks, such as video editing. In this paper, we present InstructX, a unified framework for image and video editing. Specifically, we conduct a comprehensive study on integrating MLLMs and diffusion models for instruction-driven editing across diverse tasks. Building on this study, we analyze the cooperation and distinction between images and videos in unified modeling. (1) We show that training on image data can lead to emergent video editing capabilities without explicit supervision, thereby alleviating the constraints imposed by scarce video training data. (2) By incorporating modality-specific MLLM features, our approach effectively unifies image and video editing tasks within a single model. Extensive experiments demonstrate that our method can handle a broad range of image and video editing tasks and achieves state-of-the-art performance.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces InstructX, a single AI system that can edit both images and videos by following natural language instructions (like “remove the person in the background” or “make the sky look like a sunset”). It combines two types of AI:
- A multimodal LLM (MLLM) that understands text and visuals (the “planner”).
- A diffusion model that actually edits and generates the image or video (the “artist”).
The goal is to make editing easy, accurate, and consistent across many tasks—without needing separate tools for images and videos.
What questions are the researchers asking?
In simple terms, the paper asks:
- How should we best connect a “smart understanding” model (MLLM) with a “visual editing” model (diffusion) so they work well together?
- Can we teach a model to edit videos even if we train mostly on images (since good video data is hard to find)?
- Is one unified system enough to handle many kinds of edits (add, remove, restyle, replace, etc.) across both images and videos?
How did they do it?
The two main parts
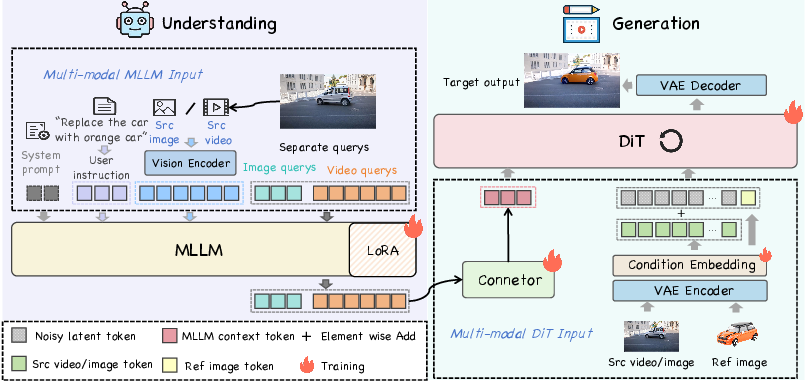
- Understanding module (MLLM): Think of this like a coach who reads your instruction and looks at the picture/video to decide what needs to change. (They use a model like Qwen2.5-VL.)
- Generation module (Diffusion Transformer, or DiT): This is the artist that actually edits the pixels to create the final image or video. (They use a model like Wan2.1.)
How the two parts talk to each other
- Learnable queries: Imagine placing a set of “smart sticky notes” into the understanding model that ask: “What exactly should we edit?” These notes collect the most important editing hints.
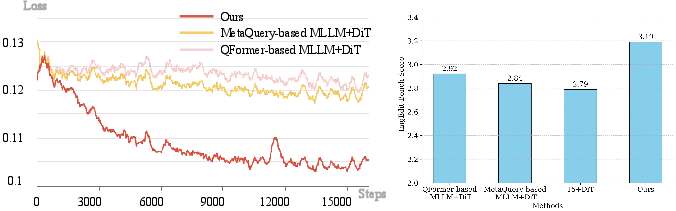
- Small connector (MLP): A tiny “translator” turns those hints into a form the artist can understand. The authors found a small, simple translator works better than a huge, complicated one when the coach (MLLM) is properly trained.
- Fine-tuning the MLLM (with LoRA): LoRA is like a lightweight plug-in that teaches the coach to focus on editing tasks without retraining everything from scratch.
Keeping the original look
- They mix in a compact “memory” of the original input (using a VAE encoding) so the edited result stays faithful to the source (same person, same scene, same style unless asked to change).
One model for images and videos
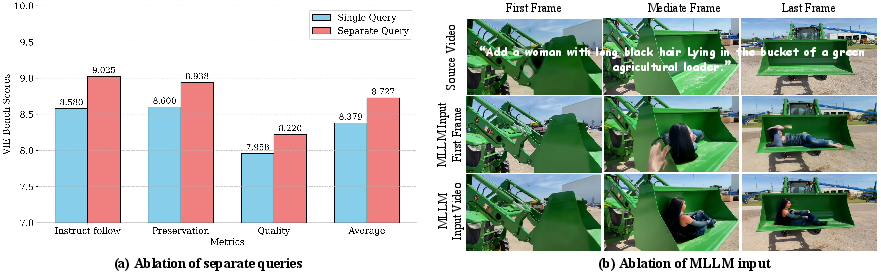
- The system uses different sets of learnable queries for images and videos (because videos carry motion and time). For videos, it shows the MLLM a handful of frames (e.g., 13) so it understands what changes must stay consistent over time.
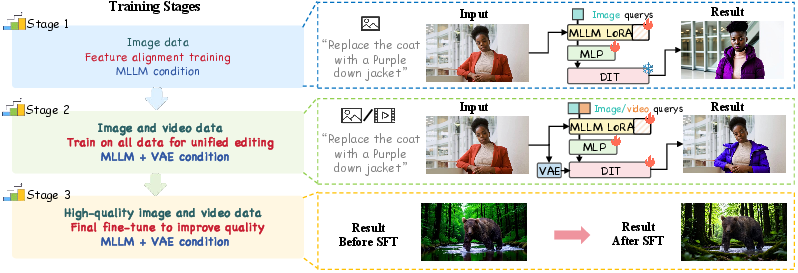
Training in three simple stages
Here’s a short, real-world analogy: first learn the language, then practice a lot, then polish.
- Stage 1 — Align: Teach the coach and artist to “speak the same language” so instructions turn into useful editing hints.
- Stage 2 — Mix and master: Train on both images and videos together. This both unifies the tasks and surprisingly helps the model learn video edits from image examples.
- Stage 3 — Polish: Fine-tune on a smaller set of high-quality examples to remove fake-looking or “plastic” textures and make results look natural.
What did they find, and why is it important?
Here are the key takeaways:
- Training mostly on images can unlock video editing skills. Even with little video data, the model learns to perform many video edits simply by mixing in image training. This is a big deal because quality video data is rare and expensive.
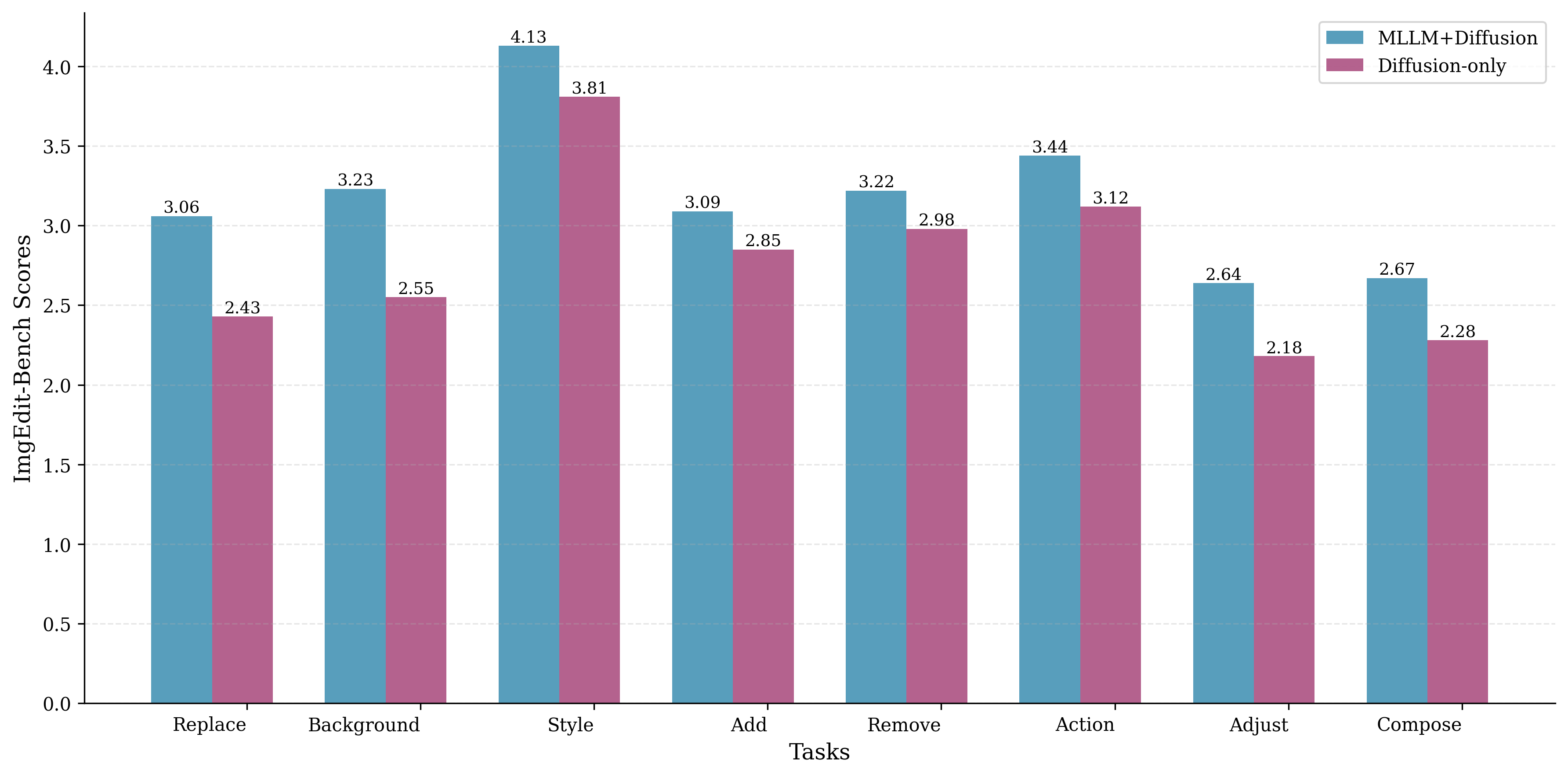
- Make the MLLM do the heavy lifting. When the understanding model is fine-tuned for editing (instead of being a frozen feature extractor), and you use a small connector, the system learns faster and performs better than designs that rely on a huge connector.
- Separate “sticky notes” for images and videos help. Using different learnable queries per modality (image vs. video) improves performance because the model can treat them according to their needs (e.g., motion in videos).
- Strong results across the board. InstructX performs at or above the level of many open-source systems for image and video editing, and it’s competitive with some top commercial tools. It follows instructions well, preserves the original content when needed, and produces high-quality results.
- New video editing benchmark (VIE-Bench). The authors also built a fair test set for instruction-based video edits and used an AI judge to score how well edits match instructions, preserve the source, and look good.
What could this mean in the real world?
- Easier, more reliable editing: One tool that understands your words and cleanly edits both images and videos reduces the need to learn multiple apps or pipelines.
- Better video editing with less data: Since good video datasets are scarce, the ability to learn from image data can accelerate progress for video tools.
- Consistent, instruction-following results: This helps creators, educators, marketers, and everyday users get edits that match exactly what they ask for.
- Path to future upgrades: Today, the system is limited by the generator it uses (it struggles with very high resolutions like 4K). But as generators improve, the approach should scale. Also, while image-trained video skills are impressive, they’re not a full replacement for real, high-quality video training—so adding better video data will push results even further.
Overall, InstructX shows a simple but powerful recipe: let the “coach” (MLLM) truly understand and plan the edit, keep the “translator” small, and train both images and videos together. This leads to a unified, instruction-friendly editor that works well on many visual tasks.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. These can guide actionable follow-up research.
- External dependence and reproducibility: The approach depends on proprietary or partially closed assets (e.g., GPT-4o for data and evaluation, possibly non-open Wan2.1-14B), making exact reproduction and fair comparison difficult. Clear open-source alternatives and replication scripts are not provided.
- Evaluation bias from MLLM judges: Most image/video metrics rely on MLLM-based evaluators (GPT-4o, Qwen2.5-VL-72B), which may introduce bias, reward hacking, or model–judge coupling effects. No calibration against large-scale human studies or classical metrics (e.g., FID/IS/FVD, warping-based temporal consistency) is reported.
- Limited scale and diversity of VIE-Bench: The newly proposed VIE-Bench has only 140 instances across eight categories. Its statistical power, category coverage (e.g., complex motion, long-form edits), and robustness to distribution shifts are not analyzed.
- Lack of temporal consistency diagnostics: Beyond VBench smoothness and aesthetic scores, the paper does not quantify temporal consistency with established measures (e.g., FVD, tLPIPS, optical-flow warping error) or human ratings of flicker and drift.
- Unclear generalization to long videos: The MLLM sees only 13 frames; the impact on long-duration videos, high-motion scenes, or edits that manifest late in the sequence is not assessed. Optimal frame sampling strategies and their trade-offs remain unexplored.
- Resolution constraints: The method is constrained by the pre-trained video DiT and struggles above 1080p. No pathway (e.g., progressive latent tiling, multi-scale training, SR-refinement) is evaluated for high-resolution editing.
- Emergent video capability from image training is under-quantified: Claims that image-only data imparts video capabilities are supported by examples, but not systematically quantified across tasks, motion regimes, and edit strengths; failure modes and limits of transfer remain unclear.
- Trade-off between edit strength and content preservation: A systematic analysis of how edit intensity affects identity/background preservation (in both images and videos) is missing; no explicit control or calibration curve is provided.
- Spatiotemporal control limitations: The method focuses on instruction-only editing; it does not support explicit spatial/temporal constraints (e.g., masks, trajectories, time ranges). How to incorporate such controls into the unified framework is open.
- Reference-based identity robustness: For reference-based edits, robustness to pose, lighting, occlusions, and multi-shot consistency is not deeply evaluated; identity leakage and drift over time remain uncharacterized.
- Connector and query design space is only partially explored: The paper adopts a two-layer MLP connector and fixed numbers of meta-queries (256 image, 512 video), but does not sweep connector depth/width, LoRA rank, query counts, or cross-attention vs. embedding replacement strategies.
- Layer selection and feature tapping in MLLM: Only last-layer hidden states via meta-queries are used; the benefit of tapping intermediate layers, multi-scale aggregation, or routing different layers to different DiT blocks is not studied.
- Full MLLM fine-tuning vs. LoRA: The paper fine-tunes MLLM via LoRA; the utility, cost, and risk of full-parameter fine-tuning (or selective unfreezing) are not compared, especially for alignment speed and ultimate edit quality.
- Alignment objective design: Feature alignment uses flow matching and LoRA; alternatives (e.g., contrastive alignment, distillation from T5-aligned spaces, RLHF for instruction following) are not compared.
- VAE feature fusion choices: The approach injects VAE features of source/reference into the noisy latent, but does not ablate fusion timings, locations, or normalization schemes, nor quantify potential artifacts (e.g., ghosting, over-preservation).
- Impact of mixed training ratios: The image:video sampling ratio (0.4:0.6) is fixed; the effect of mixing proportions on transfer, catastrophic interference, and final performance is not analyzed.
- Data quality and bias: Image instruction data is partly generated or filtered by GPT-4o and other sources; the paper does not audit instruction diversity, cultural/visual biases, or error/noise rates, nor study their impact on editing behavior.
- Robustness to instruction variability: Performance under ambiguous, adversarial, very long, or multilingual instructions is not evaluated; instruction parsing failures and safety constraints (e.g., harmful or disallowed edits) are not discussed.
- Edit compositionality and multi-step reasoning: The system’s ability to follow multi-hop or compositional edits (e.g., “remove A, replace B, then stylize in C style”) beyond short benchmarks is not stress-tested; no chain-of-thought editing analysis is provided.
- Long-range consistency across shots: Editing across shot boundaries or multi-scene videos (where scene cuts and varying contexts occur) is not evaluated, leaving open the question of cross-shot coherence.
- Computational efficiency and latency: Training/inference cost, memory footprint, throughput on standard hardware, and scalability with video length/resolution are not reported; practical deployment constraints are unknown.
- Safety, misuse, and watermarking: Risks of deepfake misuse, identity manipulation safeguards, watermark preservation/insertion, and content provenance are not addressed.
- Fairness of baseline comparisons: Closed-source baselines (Runway, Kling, Pika) may use different resolutions, lengths, or post-processing; normalization of inputs/outputs and runtime budgets is not detailed, complicating fair comparison.
- Failure case taxonomy: The paper shows successes but lacks a systematic taxonomy of failure modes (e.g., missed targets in clutter, motion-induced artifacts, over-smoothing), their frequencies, and mitigation strategies.
- Generalization across domains: No evaluation on specialized domains (medical, satellite, documents), non-photorealistic content, or extreme lighting/weather; domain adaptation strategies are untested.
- Stability under camera motion and occlusion: The system’s robustness to fast camera motion, heavy occlusion, or motion blur is not quantified; no targeted stress tests are reported.
- Unified vs. monolithic architectures: The paper adopts an external diffusion decoder; it does not compare against unified AR–diffusion transformers trained on the same data to determine when external decoders are preferable.
- Ethical dataset licensing and privacy: The legal/ethical status of training data (especially videos and references), privacy protections, and compliance with licensing are not discussed.
These gaps suggest concrete next steps: expand and human-validate evaluation, rigorously ablate connector/query/frame sampling choices, introduce spatiotemporal controls, study high-resolution and long-video scaling, audit data quality/biases, quantify transfer from images to videos, and assess safety and deployment viability.
Practical Applications
Overview
Below are practical, real-world applications that follow from the paper’s findings and innovations in InstructX—namely: MLLM-centered editing with learnable queries and a lightweight connector; mixed image–video training that transfers image editing skills to video; a three-stage training recipe; and an MLLM-based evaluation setup (VIE-Bench). Each application is categorized as Immediate (deployable now) or Long-Term (requires further work). Where relevant, we note sectors, potential tools/workflows, and assumptions/dependencies.
Immediate Applications
The items below can be deployed with current capabilities, assuming access to comparable open-source or licensed checkpoints (e.g., an MLLM like Qwen2.5-VL and a DiT-based image/video decoder such as Wan2.1), sufficient GPUs, and standard productization effort.
- Creative industries and marketing (media, advertising)
- Natural-language image/video edits at scale for campaigns
- Use cases: background swaps, style/tone changes, product colorways, localized variants, object removal/addition, reference-based swaps (e.g., “replace the handheld box with our new SKU”).
- Tools/workflows: “InstructX Creative Copilot” plugin for Adobe/CapCut; batch processing pipelines in DAM/MDM systems; prompt templates for brand-safe edits; MLLM-judge-based QC for instruction-following and preservation.
- Assumptions/dependencies: GPU-backed inference; brand kit/style prompts; guardrails for sensitive content; licensing for model weights and training data.
- A/B testing and rapid concept iteration
- Use cases: generate multiple stylistic variants from a single master asset; consistent color grading/tone harmonization across a campaign.
- Tools/workflows: templated “edit recipes” that pin preservation while varying style prompts; automated scoring using VIE-Bench-like criteria to pick winners.
- Assumptions/dependencies: good prompt engineering; preservation–edit tradeoff tuning.
- Post-production and VFX (film, episodic, UGC editing)
- Fast cleanup passes and localized edits
- Use cases: wire/object removal, prop swap, weather/time-of-day tone shift, background cleanup, sign/plate anonymization.
- Tools/workflows: NLE plugin with per-clip instruction prompts; frame-consistent local edits leveraging the model’s multi-frame MLLM input (13-frame context); VAE-conditioning for content preservation.
- Assumptions/dependencies: resolution limits (~≤1080p per paper); GPU memory; human-in-the-loop final QC.
- Style matching and continuity fixes
- Use cases: match the look of a reference shot or LUT-like style; enforce continuity in wardrobe/props via reference-based editing.
- Tools/workflows: reference image ingestion; shot-by-shot batch apply; automated preservation checks via MLLM judge.
- Assumptions/dependencies: reliable reference assets; clear legal rights for source material.
- E-commerce and retail
- Product imagery and video refresh at scale
- Use cases: background standardization, seasonal refresh (textures, palettes), packaging updates, model/in-scene product insertion via reference-based add/swap.
- Tools/workflows: storefront/DAM integration; SKU-linked edit recipes; auto-QA for product preservation and instruction-following.
- Assumptions/dependencies: strong preservation (VAE conditioning) to avoid product drift; PIM/DAM connector; legal approvals for edited imagery.
- User-generated content moderation/cleanup
- Use cases: remove PII/logos; normalize backgrounds; color-correct and stylize for marketplace standards.
- Tools/workflows: ingestion pipeline with instruction prompts and thresholds (VIE-Bench-like acceptance); human escalation on low confidence.
- Assumptions/dependencies: clear policy and audit logs.
- Public sector, compliance, and governance
- Rapid video redaction and anonymization
- Use cases: face/license plate removal, sensitive-logo/insignia removal, scene blurring, compliant releases of body-cam/CCTV footage.
- Tools/workflows: “Video Redact AI” service using instruction prompts (e.g., “blur all faces”), with MLLM-judge reports on preservation and edit completeness; export with provenance metadata.
- Assumptions/dependencies: human-in-the-loop oversight; legal policies; watermark/provenance tagging (e.g., C2PA) if required by regulation.
- Accessibility-focused edits
- Use cases: increase contrast, simplify backgrounds, enlarge text overlays, add instruction-driven captions positioning.
- Tools/workflows: predefined accessibility “edit packs” that can be executed via instructions.
- Assumptions/dependencies: org accessibility standards; testing with target user groups.
- Software and tooling (platform, SaaS, developer tools)
- Instruction-to-edit API/microservice
- Use cases: REST endpoints like /edit_image and /edit_video that accept instruction + assets (+ optional reference) and return edits.
- Tools/workflows: containerized inference; batch queues; basic governance (content filters, rate limiting); MLLM-based evaluator for acceptance tests.
- Assumptions/dependencies: GPU orchestration; model/license compliance.
- Connector kit for MLLM–diffusion integration
- Use cases: reproduce the paper’s LoRA-tuned MLLM + learnable queries + small MLP connector pattern with your choice of MLLM/decoder.
- Tools/workflows: lightweight SDK; scripts for Stage 1–3 training (alignment, mixed training, quality FT); reference configs for separate image/video queries.
- Assumptions/dependencies: compatible tokenizer/feature spaces; training data.
- Education and learning
- Rapid creation of teaching visuals and privacy-safe lecture videos
- Use cases: anonymize students; remove clutter; highlight objects/regions; unify style across course materials.
- Tools/workflows: LMS plugin; instructor prompt presets; batch processing of lecture assets.
- Assumptions/dependencies: school policies; consent for edits; compute access.
- Healthcare (with strict governance)
- De-identification and educational content creation
- Use cases: blur identifiable information in operating-room videos; generate stylized educational snippets; remove background clutter in clinics.
- Tools/workflows: hospital IT deployment with audit logs; human review; predefined redaction prompts.
- Assumptions/dependencies: HIPAA/GDPR compliance; domain-specific QA; institutional approvals.
- Research and academia
- Benchmarking and ablation studies
- Use cases: adopt VIE-Bench for instruction-based video editing evaluation; explore the paper’s ablations (LoRA vs frozen MLLM; query counts; connector size).
- Tools/workflows: standardized prompts; MLLM-judge evaluation pipelines; release of internal “golden sets.”
- Assumptions/dependencies: reproducibility (model weight availability); licensing for datasets used (NHR-Edit, X2Edit, GPT-Image-Edit, synthetic video data).
Long-Term Applications
These require improvements in model capacity (especially video DiTs), resolution, speed, robustness, and governance, plus broader dataset coverage and standardization.
- High-resolution and real-time video editing (media, live events)
- Vision: 4K–8K frame-accurate, low-latency instruction-driven edits; live broadcast cleanup (logo removal, tone shifts), dynamic overlays.
- Tools/workflows: streaming inference stacks; distillation and flow-matching acceleration; multi-GPU/memory-optimized decoding; on-device NPUs for prosumer cameras.
- Assumptions/dependencies: stronger pre-trained video DiTs; sparse/streaming attention; inference optimizations; cost-effective GPUs.
- Dynamic product placement and personalized ad insertion (media, advertising, sports)
- Vision: real-time insertion/swap of branded objects per viewer region; compliance-aware placement guided by instructions (e.g., “no alcohol brands in youth broadcasts”).
- Tools/workflows: ad decisioning + edit orchestration; real-time QC via MLLM judge; provenance tagging for disclosures.
- Assumptions/dependencies: robust scene-understanding; strong preservation; legal frameworks for personalized edits.
- Synthetic data engines for robotics/AV and CV research (robotics, autonomy)
- Vision: closed-loop, instruction-driven scene edits for domain randomization (weather, lighting, object distribution), improving sim-to-real.
- Tools/workflows: scenario generators that “edit” base footage to fill coverage gaps; evaluation via task-specific metrics.
- Assumptions/dependencies: scalable generation; fidelity checks; task-aligned labels/provenance.
- End-to-end unified models and multi-step edit agents (software, platforms)
- Vision: a single backbone unifying understanding and generation (less reliance on connectors), plus agents that decompose complex edit briefs into reliable sub-edits with verification (self-critique via MLLM judges).
- Tools/workflows: edit-planning chains; multi-turn prompting; rollback/versioning; automated failure detection and retries.
- Assumptions/dependencies: training stability; dataset breadth; agent safety guardrails.
- Multimodal expansion: audio, speech, 3D/AR/VR (entertainment, education, design)
- Vision: instruction-driven audiovisual edits (music/sfx swaps), speech-driven edits (“make the lighting warmer”), and 3D/video fusion (insert volumetric assets).
- Tools/workflows: unified pipelines that co-edit video, audio, and 3D; multimodal evaluators like VIE-Bench successors.
- Assumptions/dependencies: robust multimodal pretraining; spatial consistency in 3D; rights to audio/3D assets.
- Compliance, provenance, and policy frameworks (public sector, platforms, finance)
- Vision: standard disclosures for AI-edited content; robust watermarks/provenance (e.g., C2PA); edit-intent logging and audit trails; detection of malicious edits.
- Tools/workflows: “Compliance Edit API” that signs outputs, attaches instruction logs, and runs bias/safety checks on prompts.
- Assumptions/dependencies: regulatory consensus; watermark standards; low false-positive/negative in detection.
- Multilingual and culturally-aware instruction following (global marketing, education)
- Vision: precise edits from instructions in any language; culturally sensitive style/localization checks.
- Tools/workflows: multilingual prompt libraries; cultural risk classifiers integrated into the edit pipeline.
- Assumptions/dependencies: multilingual MLLMs with strong grounding; curated localization datasets.
- Collaborative co-creation and CI/CD for media (software, teams)
- Vision: version-controlled, multi-user editing with automated “unit tests” for edits (instruction-following, preservation, quality thresholds).
- Tools/workflows: Git-like media repos; PR-style review with MLLM-judge reports; continuous regression testing using VIE-Bench-like suites.
- Assumptions/dependencies: standard APIs; cost-effective batch evaluation; governance and access control.
- Healthcare-grade de-identification pipelines (healthcare)
- Vision: certified, fully automated de-ID for diverse clinical videos with auditability and measurable privacy guarantees.
- Tools/workflows: ensemble detectors + instruction-based editors; human verification dashboards; longitudinal QA.
- Assumptions/dependencies: regulatory certification; domain-specific robustness; privacy-risk assessment frameworks.
- Education at scale: adaptive and inclusive video content (education)
- Vision: auto-generate variants of lectures for different reading levels, visual needs (high contrast, simplified scenes), or languages; sign-language overlays via instruction.
- Tools/workflows: curriculum-linked prompt sets; learner-profile-aware pipelines; teacher-in-the-loop review.
- Assumptions/dependencies: pedagogical validation; localized content rights; reliable multimodal synthesis.
- Finance and enterprise governance (finance, legal)
- Vision: compliant marketing edits with automatic redaction (account numbers, IDs), audit logs, and approval workflows.
- Tools/workflows: integration with legal/brand review systems; rule-based blockers; auto-disclosures.
- Assumptions/dependencies: clear policy codification; tight access controls; traceability/provenance.
Notes on cross-cutting feasibility
- Compute and cost: video editing remains GPU-intensive; practical deployment needs batching, caching, acceleration (distillation, fewer diffusion steps), and SLA-aware scheduling.
- Model availability and licensing: applications depend on access to comparable MLLM and DiT weights, plus legal use of training data (including any synthetic pipelines).
- Safety and governance: instruction filters, misuse prevention (e.g., deepfake policies), watermarking/provenance, and human oversight are essential for high-stakes domains.
- Resolution and quality limits: current limitation near ≤1080p; 4K+ and real-time scenarios fall under long-term efforts.
- Data coverage and robustness: mixed image–video training is promising for emergent video capabilities but not a substitute for high-quality, diverse video data in the long run.
Glossary
- Autoregressive (AR): A generative modeling paradigm that predicts the next token (e.g., text or visual token) conditioned on previously generated tokens. "Typical integration paradigms include: (1) autoregressive visual generation~\cite{ar_diff_1,ar_diff_2,ar_diff_3} with discrete visual tokenizers~\cite{ar_2,ar_4}"
- CLIP text score: A metric derived from the CLIP model that measures alignment between textual prompts and visual content, often used for evaluation. "Prior work commonly uses the CLIP text score to assess textâvideo alignment"
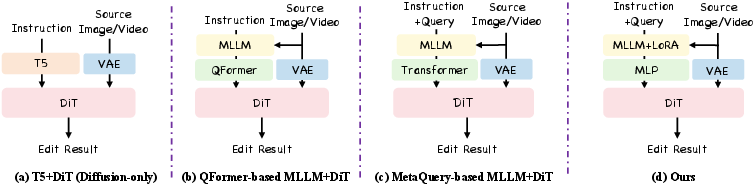
- Connector (MLLMâdiffusion connector): A learnable module that maps features from an understanding model (MLLM) to the conditioning space of a diffusion generator. "using a connector~\cite{conn_1,conn_2,conn_3} to bridge the understanding model and diffusion model is a strategy for rapid convergence"
- Content drift: Undesired deviation of edited content from the original target during propagation or consistency enforcement, especially in video. "which is prone to content drift and loss."
- DiT (Diffusion Transformer): A transformer-based architecture used as the core denoising generator in diffusion models. "The DiT serves as the generation module and connects to the MLLM via learnable queries and an MLP connector."
- Diffusion loss: The training objective used for visual generation in diffusion models, typically encouraging denoising consistency. "hybrid ARâdiffusion approaches that unify an autoregressive loss for text and a diffusion loss for vision within a single transformer"
- Diffusion model: A generative model that iteratively denoises random noise to produce images or videos. "interest is growing in using them to improve the editing performance of diffusion models."
- Feature alignment: The process of matching or adapting feature representations between different model spaces (e.g., MLLM text space and diffusion generation space). "(1) Feature alignment capability."
- Flow matching: A training objective that learns continuous transformations (flows) between data and noise distributions for generative modeling. "We use flowâmatching~\cite{flow} as the training objective in all stages."
- GAN (Generative Adversarial Network): A two-network generative framework where a generator competes against a discriminator to produce realistic outputs. "Earlier approaches~\cite{t_gan_1,t_gan_2,t_gan_3} primarily rely on GAN frameworks~\cite{gan}"
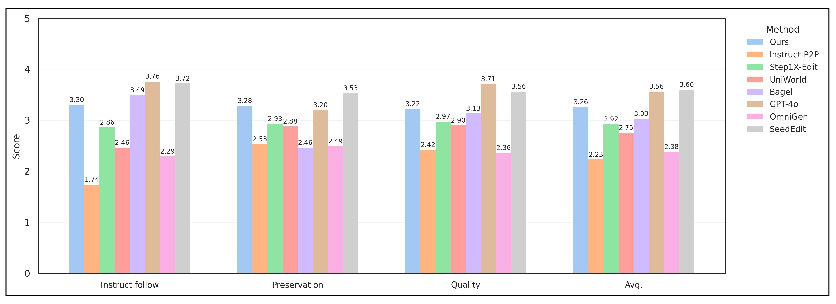
- GEdit-Bench: A benchmark for evaluating instruction-based image editing across multiple metrics. "For image editing, we compare different methods on two benchmarks: ImgEdit-Bench~\cite{imgedit} and GEdit-Bench~\cite{step1x}."
- ImgEdit-Bench: A benchmark dataset evaluating image editing quality and instruction-following via automated scoring. "Specifically, on ImgEdit-Bench, we use GPT-4.1~\cite{openai_gpt4o_image} to score the editing results on a 1-5 scale."
- Inpainting (Video inpainting): The task of filling in or restoring missing regions in videos with contextually consistent content. "Examples include video inpainting~\cite{inpaint_1,inpaint_2}, video try-on~\cite{tryon_1,tryon_2}, and video addition~\cite{add_1,add_2}."
- Instruction-following score (Q_SC): An evaluation metric quantifying how well the edited output adheres to the given instruction. "evaluate the edited results across three metrics: instruction-following score (QSC), perceptual-quality score (QPQ), and overall score (QO)."
- Latent: A compressed hidden representation used by generative models; in diffusion, a noisy latent is progressively denoised. "we add the VAE encoding of the original image/video to the noisy latent."
- Learnable queries: Trainable tokens appended to an MLLM input that extract task-specific information from the model’s hidden states. "we append a set of learnable queries to the MLLM input sequence to extract editing information"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that injects low-rank adapters into large models. "It uses the same learnable queries as MetaQuery, fine-tunes the MLLM LoRA, and employs a simple two-layer MLP as the connector"
- Metaâquery features: Compressed features produced by learnable queries that capture relevant editing guidance from an MLLM. "retain only the metaâquery features from the MLLM output."
- MetaQuery: A method that introduces learnable queries as an interface between MLLMs and diffusion models. "Recently, MetaQuery~\cite{meta_query} introduces a set of learnable queries that act as an interface between MLLM and diffusion models."
- Modality-specific features: Feature representations tailored to specific data modalities (e.g., images vs. videos) to improve unified modeling. "By incorporating modality-specific MLLM features, our approach effectively unifies image and video editing tasks within a single model."
- Multimodal LLM (MLLM): A LLM that can process and reason over multiple modalities such as text and vision. "With recent advances in Multimodal LLMs (MLLM) showing strong visual understanding and reasoning"
- One-shot: Learning or editing from a single example or instance. "Later, with the performance scale-up of video diffusion models, several downstream tasks emerge, leveraging pre-trained video diffusion models. ... Early research~\cite{fatezero,flatten,tunevid} primarily relies on zero-shot or one-shot approaches based on image diffusion models."
- Overall score (Q_O): A composite evaluation metric summarizing multiple aspects of editing performance. "evaluate the edited results across three metrics: instruction-following score (QSC), perceptual-quality score (QPQ), and overall score (QO)."
- Perceptual-quality score (Q_PQ): A metric assessing the visual quality of edited outputs from a human perceptual standpoint. "evaluate the edited results across three metrics: instruction-following score (QSC), perceptual-quality score (QPQ), and overall score (QO)."
- QFormer: A query-based encoder that compresses MLLM hidden states into a fixed-length representation for downstream modules. "The last hidden states of the MLLM are encoded by QFormer~\cite{qformer} into fixed-length representation (i.e., 256 tokens)"
- QWen2.5-VL-3B: A specific MLLM used for multimodal instruction embedding in the proposed system. "i.e., QWen2.5-VL-3B~\cite{Qwen2.5-VL}, to embed the editing instruction and source image/video."
- QWen2.5-VL-72B: A large multimodal model used as an automated judge for evaluation. "On GEdit-Bench, we employ Qwen2.5-VL-72B~\cite{Qwen2.5-VL} to evaluate the edited results across three metrics"
- Style transfer: Editing that changes the aesthetic style or tone of visual content while preserving structure. "segmentation and style transfer tasks absent from the video data but present in the image data."
- T5 text encoder: A text-only encoder from the T5 model family used to condition diffusion without multimodal understanding. "Instructions are encoded by the native T5 text encoder~\cite{t5} and fed directly into the diffusion model"
- VACE-Benchmark: A video creation and editing benchmark used for comparison. "existing benchmarks (e.g., UNICBench~\cite{unic} and VACE-Benchmark~\cite{vace}) primarily focus on targetâprompt rather than instructionâprompt evaluation"
- VAE (Variational Autoencoder): A generative model that encodes inputs into a latent distribution and decodes them back; here used to inject source-appearance consistency. "we add the VAE encoding of the original image/video to the noisy latent."
- VBench: A suite for evaluating video quality across dimensions such as smoothness and aesthetics. "In addition, we employ VBench~\cite{vbench} to evaluate video quality."
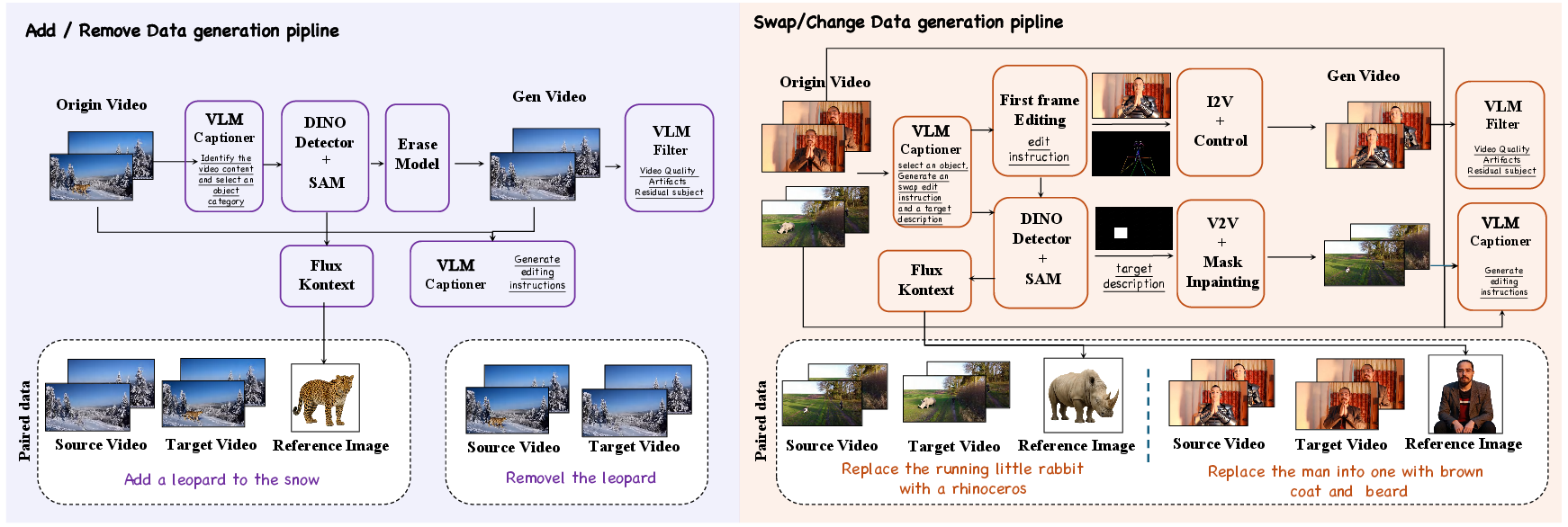
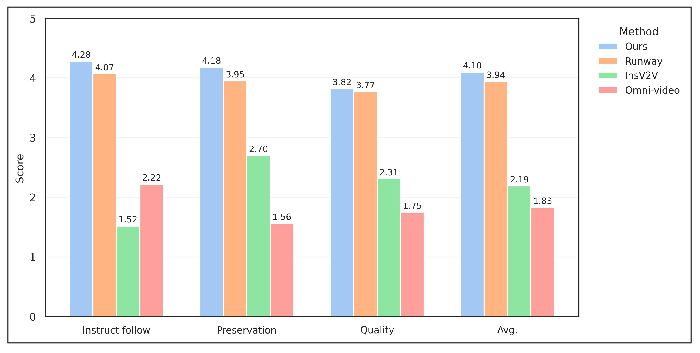
- VIEâBench: An instruction-based video editing benchmark introduced by the paper. "we introduce VIEâBench, which comprises 140 highâquality instances across eight categories"
- Video diffusion model: A diffusion-based generative model specialized for videos, enabling temporally consistent generation/editing. "Later, with the performance scale-up of video diffusion models, several downstream tasks emerge"
- Video try-on: A task that virtually transfers garments or accessories onto subjects in videos using generative models. "Examples include video inpainting~\cite{inpaint_1,inpaint_2}, video try-on~\cite{tryon_1,tryon_2}, and video addition~\cite{add_1,add_2}."
- Wan2.1â14B: A large diffusion decoder model used to generate edited outputs. "Wan2.1â14B~\cite{wan2.1} is used as the decoder for the edited output."
- Zero-shot: Performing a task without task-specific training examples, relying on generalization or pretraining. "Early works~\cite{fatezero,flatten,tunevid} perform video editing through zero-shot strategies"
Collections
Sign up for free to add this paper to one or more collections.