- The paper introduces a novel temporal distance-based framework that extracts dense rewards from passive videos, enabling fine-grained progress evaluation.
- It employs a two-hot discretization scheme with exponentially weighted sampling to enhance temporal resolution and maintain numerical stability.
- The approach outperforms traditional dense rewards by achieving higher success rates and sample efficiency across diverse RL tasks, including cross-domain scenarios.
TimeRewarder: Learning Dense Reward from Passive Videos via Frame-wise Temporal Distance
Introduction and Motivation
The design of dense, informative reward functions remains a central challenge in reinforcement learning (RL) for robotics, where manual engineering is labor-intensive and often non-scalable. TimeRewarder addresses this by leveraging passive, action-free expert videos—both robot and human—to learn dense, step-wise reward signals. The core insight is to model task progress as a temporal distance prediction problem between video frames, enabling the derivation of proxy rewards that are both fine-grained and generalizable. This approach circumvents the need for action annotations or privileged environment access, facilitating scalable reward learning from diverse video sources.
Methodology
TimeRewarder consists of a progress model Fθ trained to predict normalized temporal distances between pairs of frames (ou,ov) from expert demonstration videos. The normalized distance duv=T−1v−u∈[−1,1] encodes both forward and backward progress, naturally penalizing suboptimal or regressive behaviors. The model is trained using a two-hot discretization scheme over K=20 bins for numerical stability, with an exponentially weighted sampling strategy that emphasizes short temporal intervals to enhance fine-grained temporal resolution.
During RL, the trained Fθ is frozen and used to compute step-wise rewards for agent rollouts by evaluating the predicted temporal distance between consecutive observations. The final reward combines this dense proxy with a sparse binary success signal from the environment:
rt=rTR(ot,ot+1)+α⋅rsuccess(ot)
where rTR is the predicted temporal distance and rsuccess is the binary success indicator.
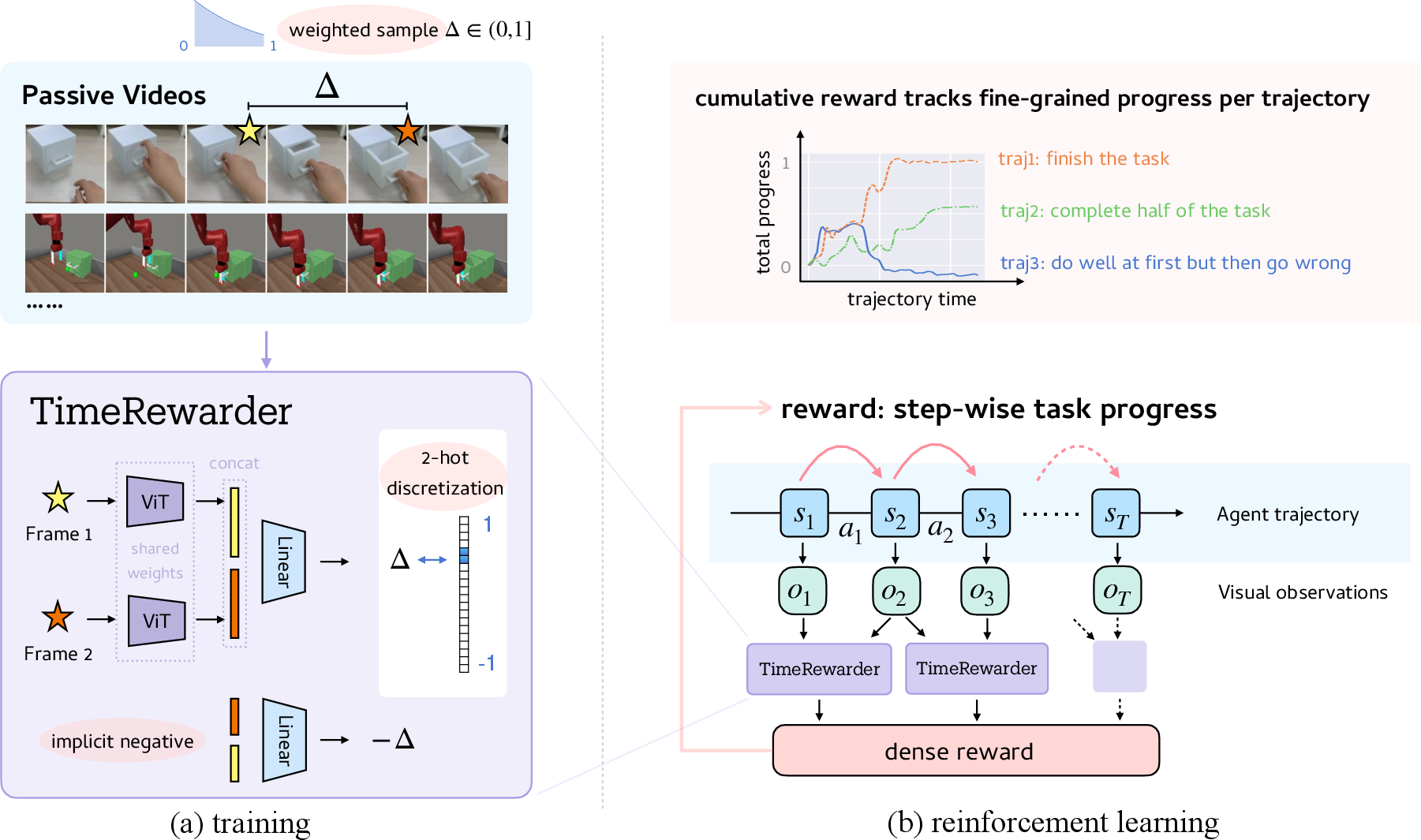
Figure 1: TimeRewarder framework: learns step-wise dense rewards from passive videos by modeling intrinsic temporal distances, enabling robust progress scoring and effective policy learning.
The theoretical justification is rooted in potential-based reward shaping, where the temporal distance aligns with the notion of progress toward task completion, and the antisymmetric structure of the objective ensures suboptimality awareness.
Experimental Evaluation
Task Progress Generalization
TimeRewarder is evaluated on ten challenging Meta-World manipulation tasks, using 100 action-free expert videos per task. The Value-Order Correlation (VOC) metric is used to assess the alignment between predicted values and true temporal order on held-out expert videos. TimeRewarder achieves the highest VOC scores, indicating strong temporal coherence and generalization to unseen trajectories.
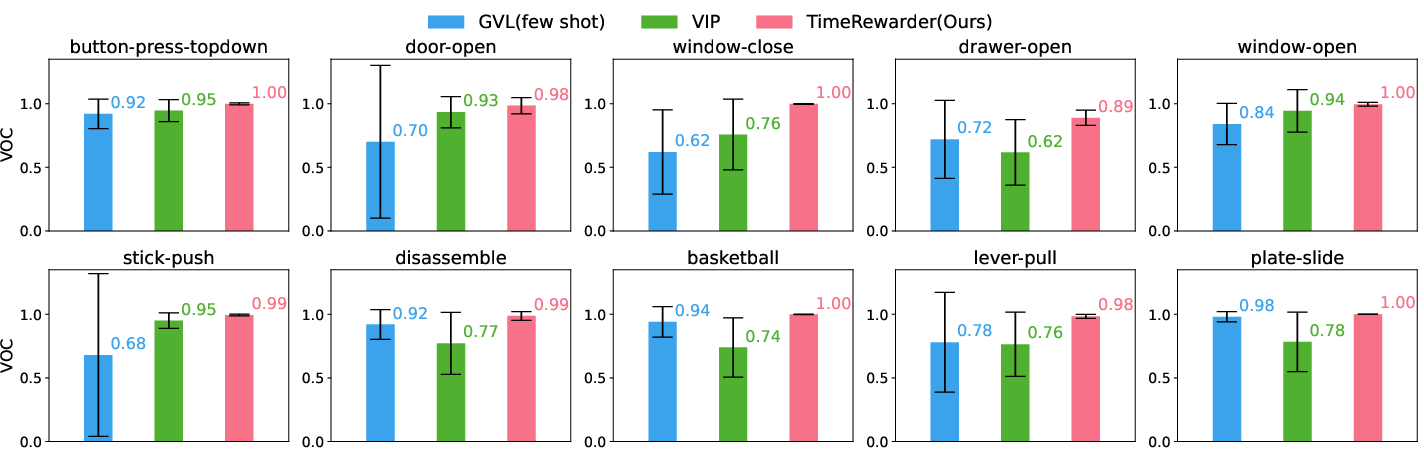
Figure 2: Value–Order Correlation (VOC) on held-out expert videos. Higher is better.
Suboptimal Behavior Identification
The model's ability to distinguish between successful and failed rollouts is visualized by plotting reward/value curves for representative trajectories. TimeRewarder provides temporally coherent and causally grounded feedback, accurately penalizing unproductive behaviors and rewarding meaningful progress, outperforming baselines such as VIP, PROGRESSOR, and Rank2Reward.
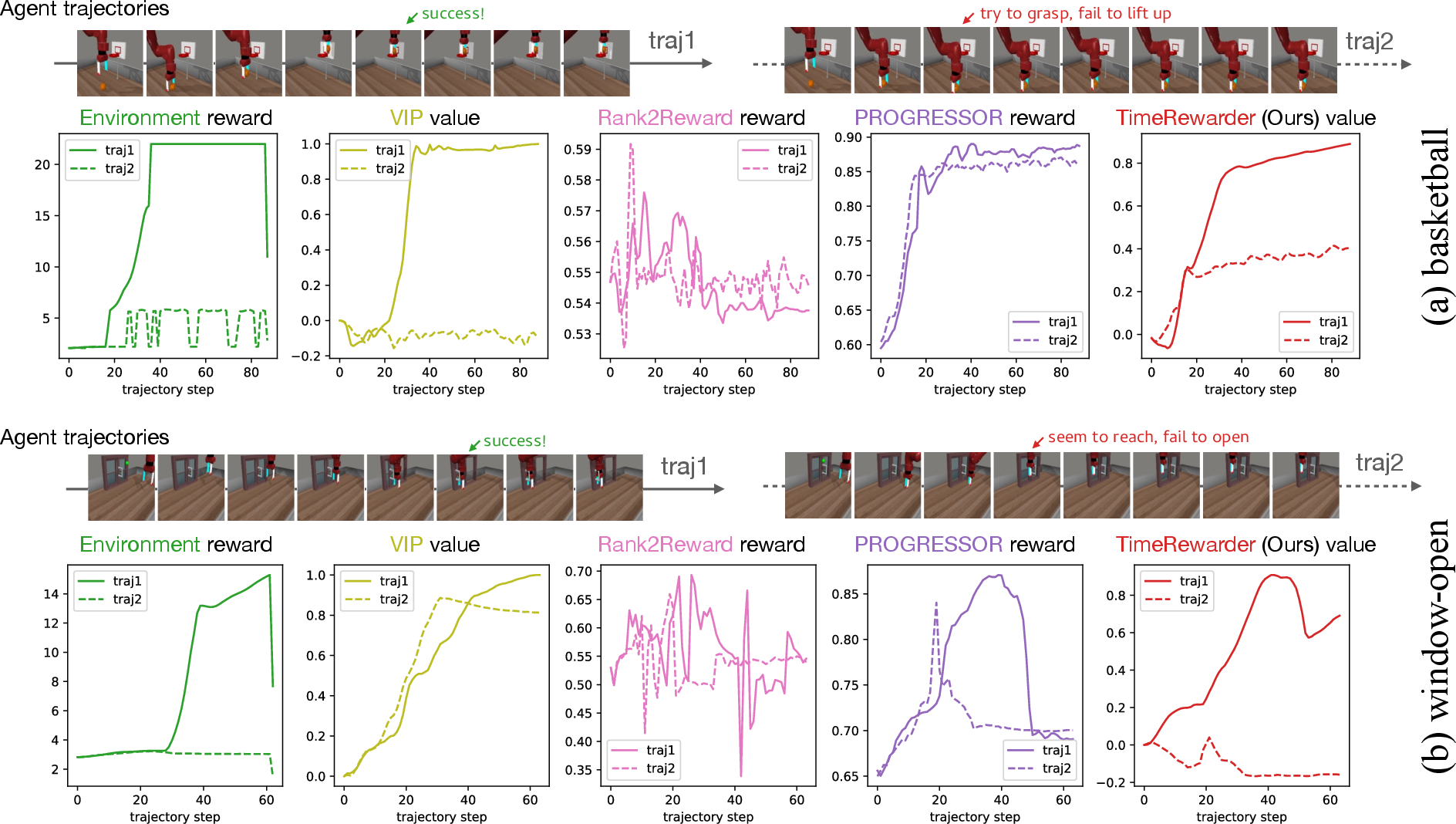
Figure 3: Reward/value curves on successful vs. failed rollouts for two tasks. TimeRewarder provides the most informative and temporally coherent feedback.
In RL experiments, TimeRewarder is integrated with DrQ-v2 and compared against eight baselines, including progress-based reward learning (VIP, PROGRESSOR, Rank2Reward), imitation-from-observation (GAIfO, OT, ADS), and privileged methods (BC, environment dense reward). TimeRewarder achieves the highest final success rate and sample efficiency on 9/10 tasks, and outperforms even the environment's manually designed dense reward in both metrics.
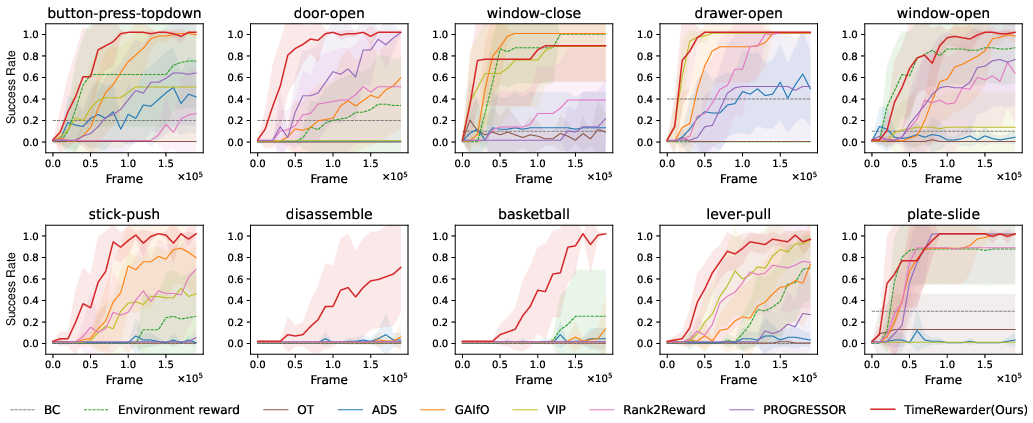
Figure 4: RL performance with sparse environment success signals and dense proxy rewards. TimeRewarder outperforms all baselines and even environment dense reward.
Cross-Domain Generalization
TimeRewarder demonstrates the ability to leverage cross-domain visual data by combining a single in-domain Meta-World demonstration with 20 real-world human videos per task. This combination substantially improves RL performance compared to using either source alone, highlighting the model's capacity to utilize diverse, unlabeled video data for reward learning.
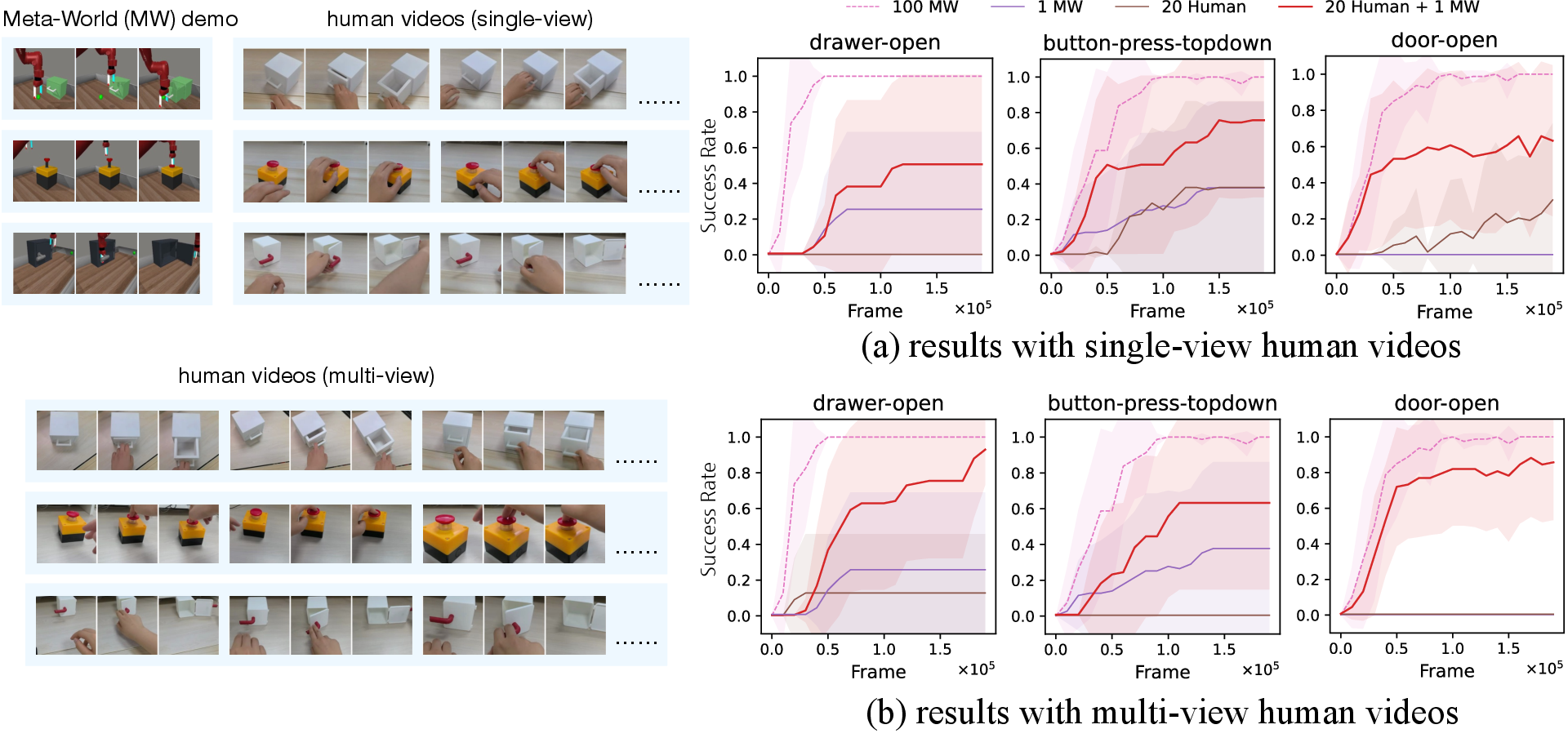
Figure 5: Cross-domain reward learning. TimeRewarder leverages human videos and a single in-domain demonstration to improve performance.
Ablation Studies
Ablation experiments confirm the necessity of each methodological component:
- Implicit negative sampling is critical for penalizing failures.
- Exponentially weighted sampling enhances fine-grained progress recognition.
- Two-hot discretization preserves sharp progress boundaries and prevents reward smoothing.
Alternative temporal modeling approaches (e.g., progress from initial frame only, single-frame input, order prediction) all underperform compared to the pairwise temporal distance formulation.
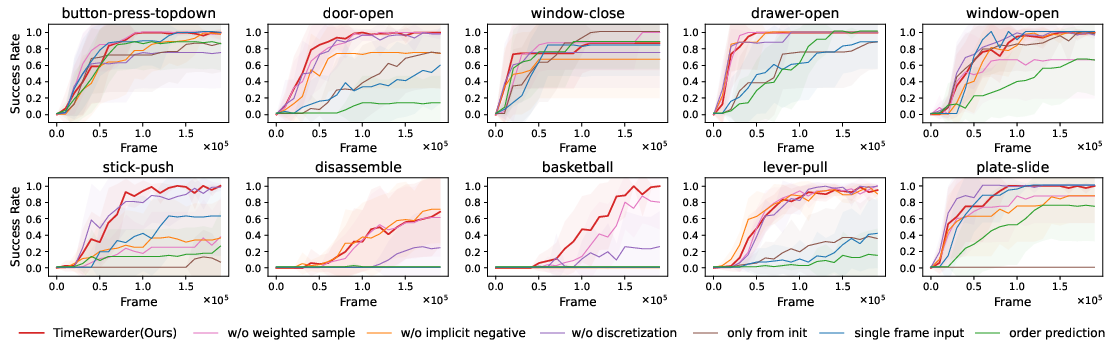
Figure 6: Ablation study results. Each component is necessary for optimal performance.
Implementation Considerations
- Visual Backbone: CLIP-pretrained ViT-B/16 is used for feature extraction, with both the encoder and linear head trainable during reward model training.
- Reward Model Training: 10,000 frame pairs per epoch, 100 epochs, Adam optimizer, learning rate 2×10−5.
- RL Integration: DrQ-v2 is used as the RL algorithm, with the reward model frozen during policy learning.
- Resource Requirements: Training the reward model is efficient due to self-supervised learning on passive videos; inference is lightweight and suitable for real-time RL.
- Scalability: The method is robust to diverse and cross-domain video data, and does not require online reward model updates during RL.
Implications and Future Directions
TimeRewarder demonstrates that dense, instructive reward signals can be reliably extracted from passive, action-free videos by modeling frame-wise temporal distances. The approach is robust to out-of-distribution behaviors, generalizes across domains and embodiments, and eliminates the need for manual reward engineering. The empirical finding that TimeRewarder can outperform environment-supplied dense rewards on both success rate and sample efficiency is notable and suggests that progress-based proxy rewards can be more effective than hand-crafted alternatives in complex manipulation tasks.
Limitations include challenges in tasks with frequent back-and-forth motions, where temporal distance may not fully capture nuanced progress. Future work may explore hierarchical or memory-augmented progress models to address such cases, as well as further scaling to in-the-wild video data for generalist skill acquisition.
Conclusion
TimeRewarder provides a principled and practical framework for learning dense, temporally coherent reward functions from passive videos. By directly modeling frame-wise temporal distances, it enables robust, scalable, and generalizable reward learning for RL in robotics, with strong empirical performance and promising cross-domain capabilities. This work advances the field toward reducing reliance on manual reward engineering and leveraging large-scale, diverse video data for autonomous skill acquisition.

