- The paper introduces an automated pipeline that converts real robot demonstrations into simulation environments using VLMs, 2D-to-3D models, and differentiable rendering.
- It implements controlled perturbations and dual evaluation methods—automated VLM scoring and crowdsourced human comparisons—to rigorously assess policy robustness.
- Key results reveal significant generalization challenges with policies showing marked sensitivity to background, color, and object pose changes across datasets.
RobotArena ∞: Scalable Robot Benchmarking via Real-to-Sim Translation
Motivation and Context
The evaluation of generalist robot policies—those capable of performing diverse tasks across varied environments—remains a bottleneck in robotics research. Real-world policy evaluation is fundamentally constrained by logistical, safety, and reproducibility issues, while existing simulation benchmarks are limited by their reliance on synthetic domains and lack of support for policies trained on real-world data. The absence of scalable, reproducible, and extensible evaluation protocols impedes progress toward robust, generalist robotic agents. RobotArena ∞ addresses these limitations by automating the translation of real-world robot demonstration videos into simulated environments, enabling large-scale, reproducible benchmarking of vision-language-action (VLA) policies with both automated and human-in-the-loop evaluation.

Figure 1: RobotArena ∞ provides a scalable and extensible robot benchmarking framework by automating environment construction and evaluation, leveraging real videos, VLMs, and crowdsourced human preferences.
Automated Reality-to-Simulation Translation
RobotArena ∞ introduces a fully automated pipeline for converting robot demonstration videos into simulation-ready environments. The pipeline leverages advances in VLMs for semantic scene understanding, 2D-to-3D generative models for asset creation, and differentiable rendering for camera and robot calibration. The process extracts five key elements from each demonstration: camera pose, 3D object meshes and poses, scene depth, background image, and robot control gains. This enables the construction of physics-consistent digital twins without manual intervention.
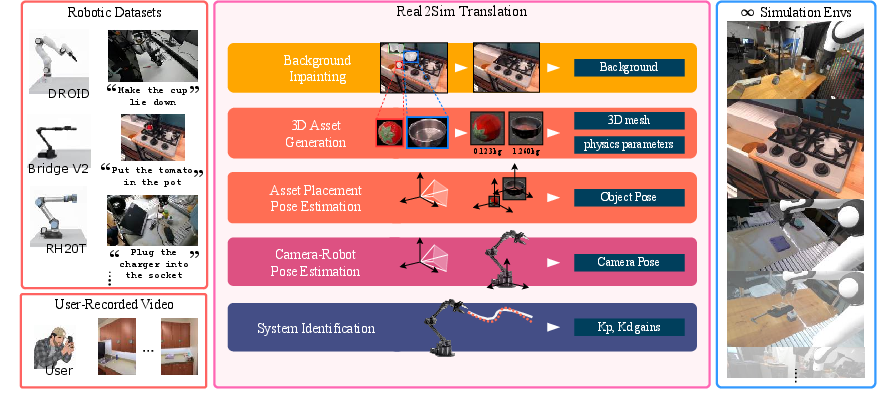
Figure 2: Automated video-to-simulation translation in RobotArena ∞; a demonstration frame is mapped to a corresponding simulated environment.
The pipeline includes:
- Robot-Camera Calibration: Differentiable rendering aligns the robot's URDF-based model with video frames by optimizing camera extrinsics using RGB, optical flow, and DINOv2 feature losses.
- Object Segmentation and 3D Reconstruction: Gemini VLM segments task-relevant objects, which are super-resolved and reconstructed into textured 3D meshes via Hunyuan-3D. Object poses are recovered by matching rendered views to image crops using MINIMA and monocular depth estimation.
- Background Inpainting: LaMa inpainting removes foreground objects to generate clean backgrounds for simulation.
- System Identification: PD controller gains are tuned via simulated annealing to match real and simulated end-effector trajectories, improving dynamic fidelity.

Figure 3: Background inpainting results; original images (top) and inpainted backgrounds (bottom) for simulation asset placement.
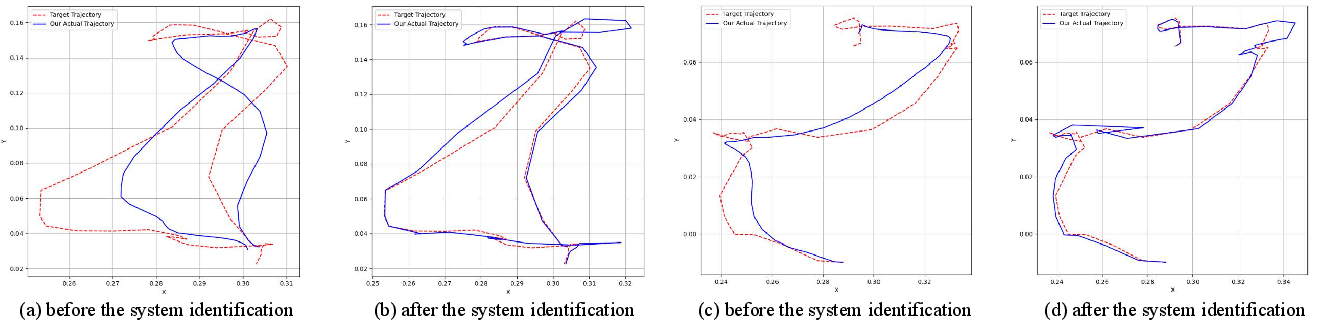
Figure 4: System identification aligns simulated (blue) and real (red) robot trajectories, improving simulation fidelity.
Controllable Environment Perturbations
To rigorously assess policy robustness and generalization, RobotArena ∞ introduces systematic perturbations along multiple axes:
- Background Change (ΔBG): Replaces scene backgrounds with diverse inpainted textures.
- Color Shift (ΔColor): Alters RGB channel configurations at varying intensities.
- Object Pose Change (ΔObjPose): Randomly permutes object locations within the scene.
These perturbations isolate policy dependencies on contextual, low-level, and spatial cues, enabling controlled evaluation of generalization under distribution shifts.

Figure 5: Background change example; original and perturbed backgrounds.

Figure 6: Color shift example; original and color-perturbed backgrounds.

Figure 7: Object position perturbation example; original and permuted object arrangements.
Evaluation Protocols: VLMs and Human Preferences
RobotArena ∞ supports two complementary evaluation strategies:
- Automated VLM Scoring: VLMs (e.g., Gemini) are prompted with shuffled video frames and task instructions to assign per-frame progress scores, with the mean score over the final 30% of frames best correlating with human judgments.
- Crowdsourced Human Preferences: Human annotators perform double-blind, pairwise comparisons of policy execution videos, providing both preference labels and free-form rationales. Global policy rankings are inferred using the Bradley–Terry model, with robust confidence intervals computed via sandwich variance estimation.
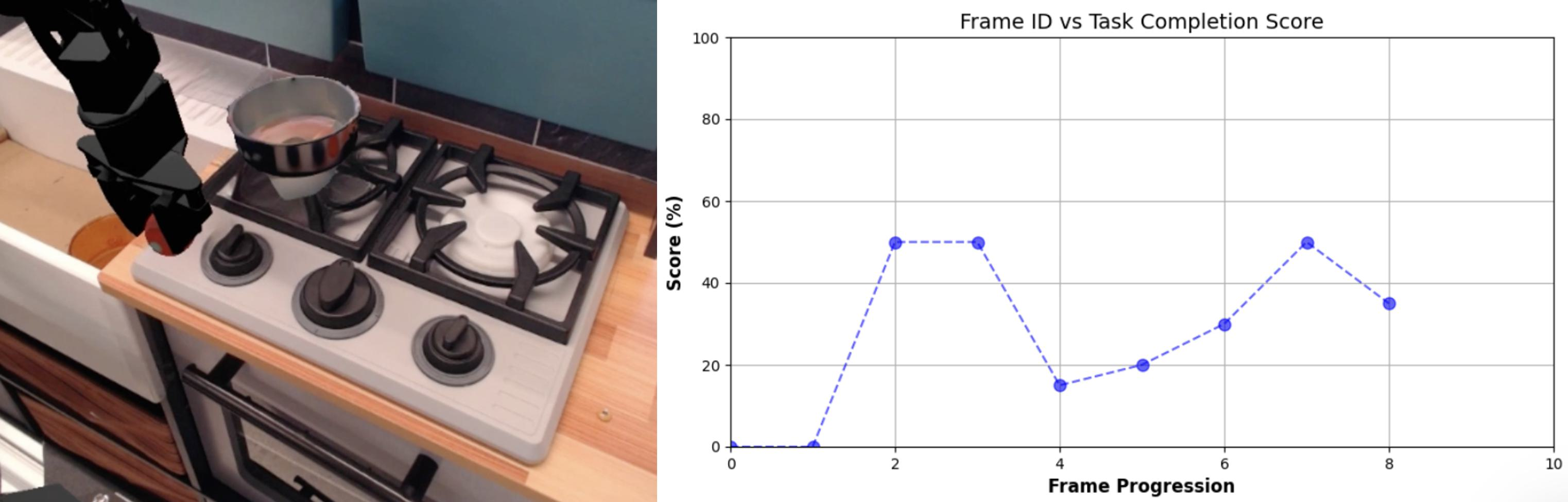
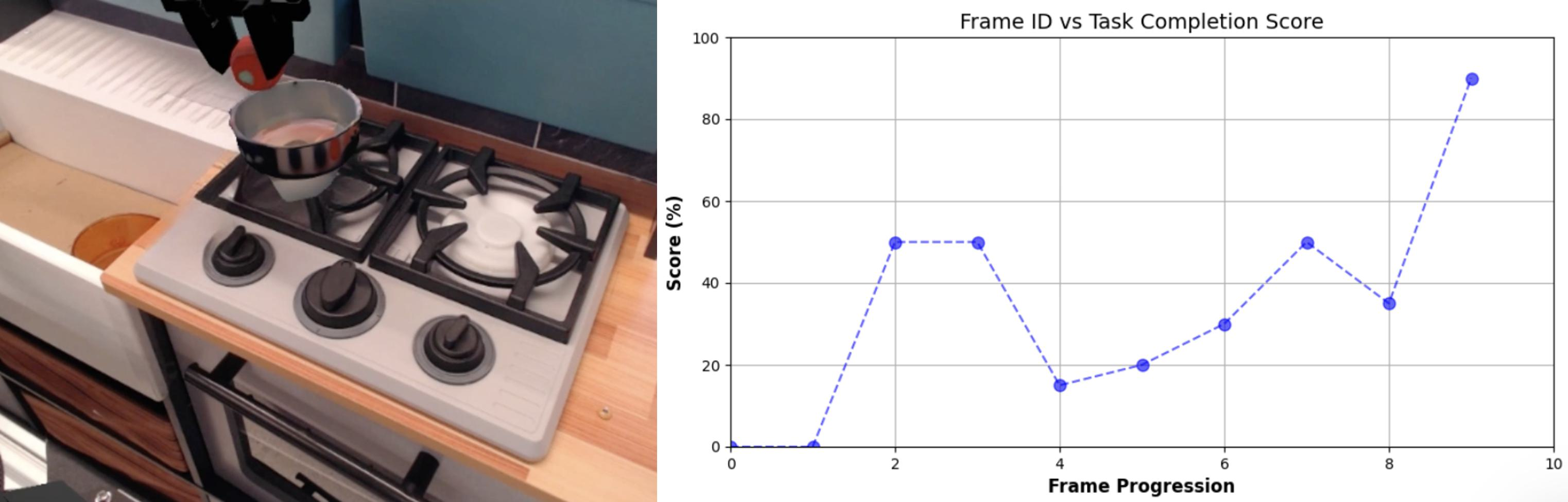
Figure 8: Example VLM-generated task evaluation curves; completion scores across execution frames.
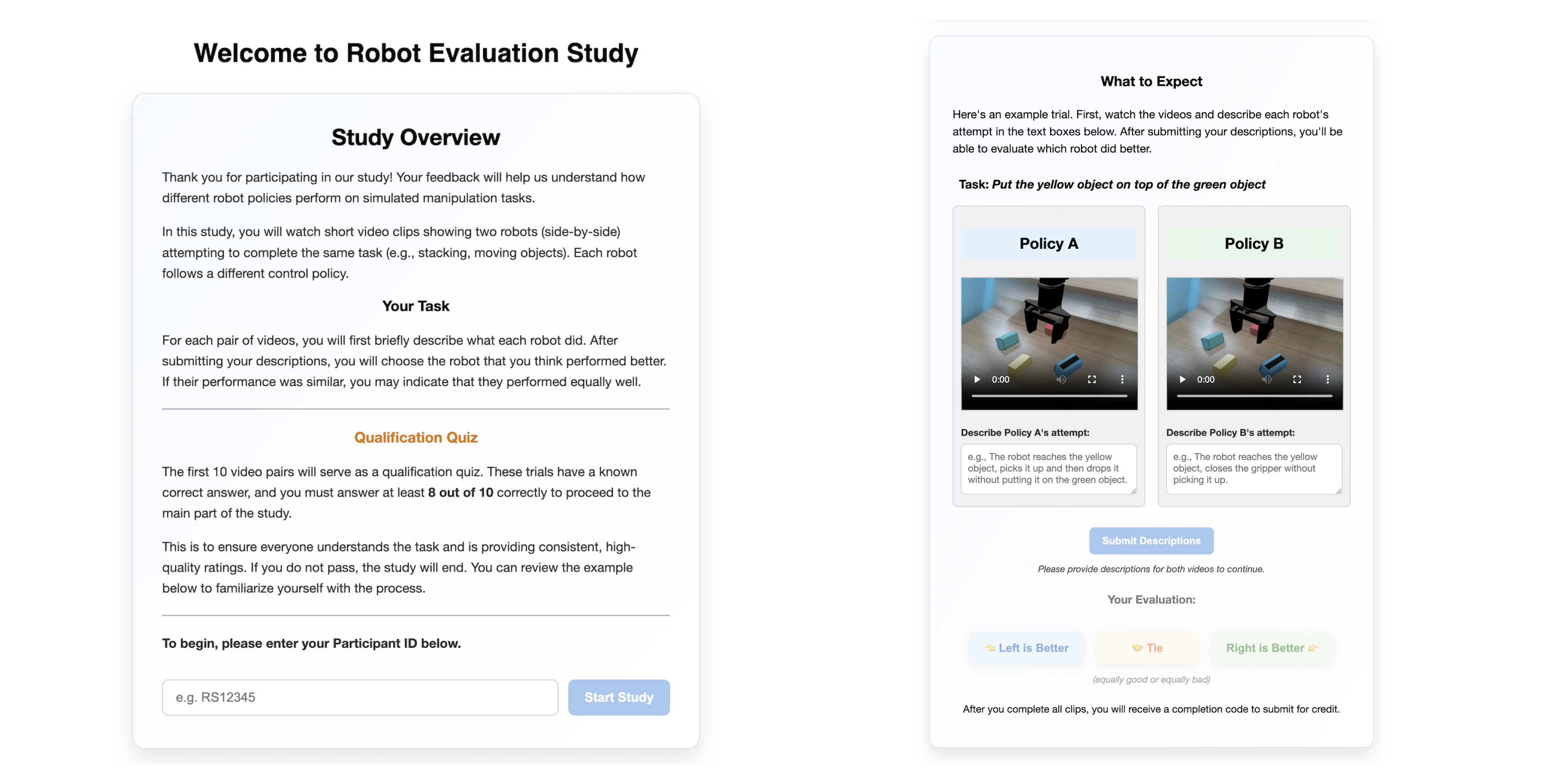
Figure 9: Human evaluation interface for pairwise policy comparison.
Benchmark Composition and Policy Evaluation
RobotArena ∞ aggregates environments derived from Bridge, DROID, and RH20T datasets, supporting both in-distribution and out-of-distribution evaluation. The benchmark includes over 100 nominal environments and hundreds of perturbations, with more than 7000 human preference pairs collected.

Figure 10: Simulation environments in RobotArena ∞ seeded from Bridge, RH20T, and DROID video demonstrations.
Candidate policies evaluated include Octo-Base, RoboVLM, SpatialVLA, and CogAct, representing diverse VLA architectures and training regimes.
Key Results and Insights
Automated and human evaluations reveal several critical findings:
- Cross-Dataset Generalization is Weak: Policies exhibit substantial performance degradation on environments derived from datasets not used in training, indicating specialization rather than true generalization.
- Model Architecture Matters: RoboVLM and CogAct consistently outperform Octo-Base and SpatialVLA across environments and perturbations.
- 3D Spatial Reasoning Improves Robustness: SpatialVLA demonstrates enhanced resilience to object position perturbations, attributable to explicit 3D modeling.
- VLM Backbone Strength Drives Robustness: Policies with stronger VLM backbones are less sensitive to color perturbations, relying more on structural cues.
- Sensitivity to Background Changes: All policies show sharp performance drops under background perturbations.
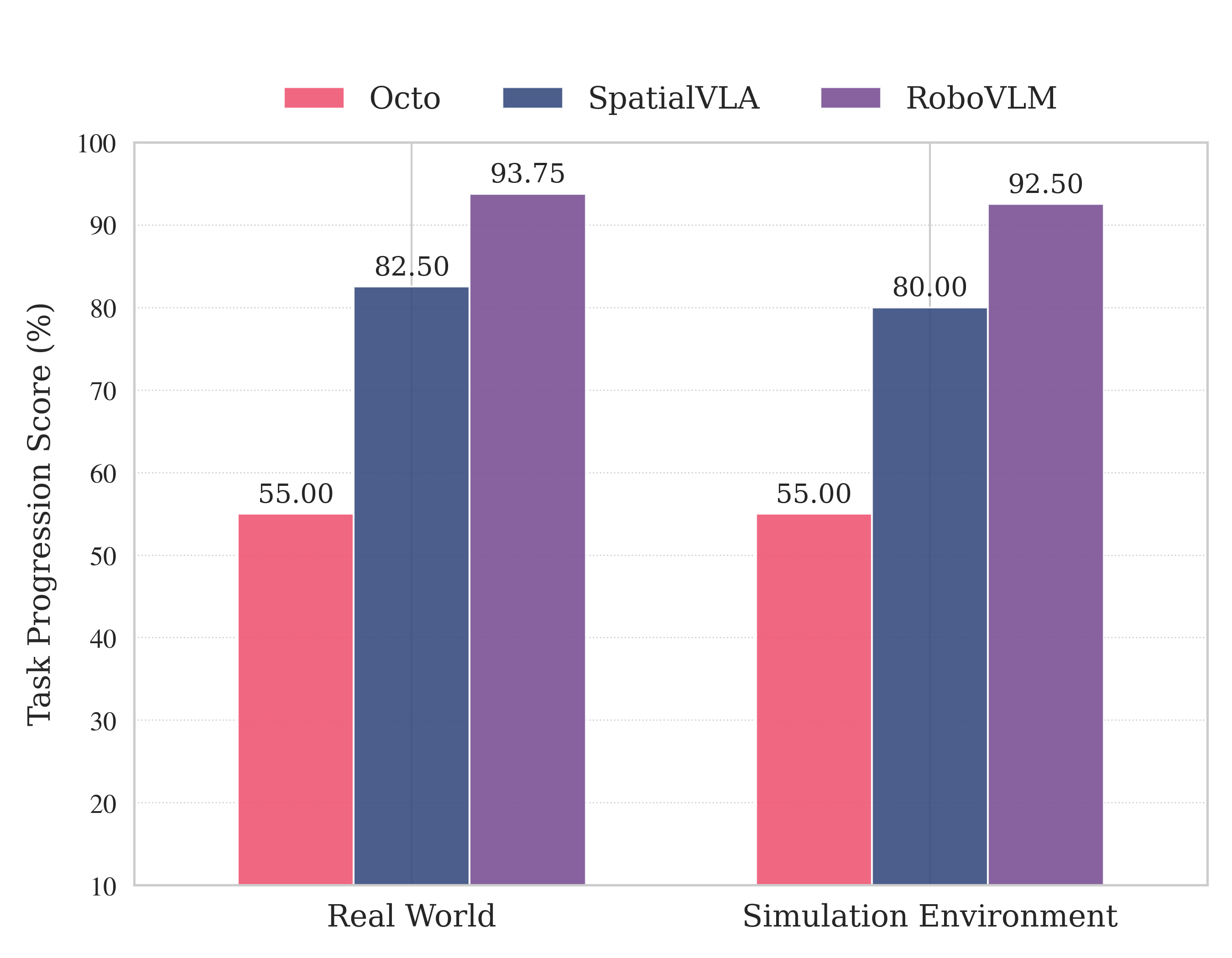
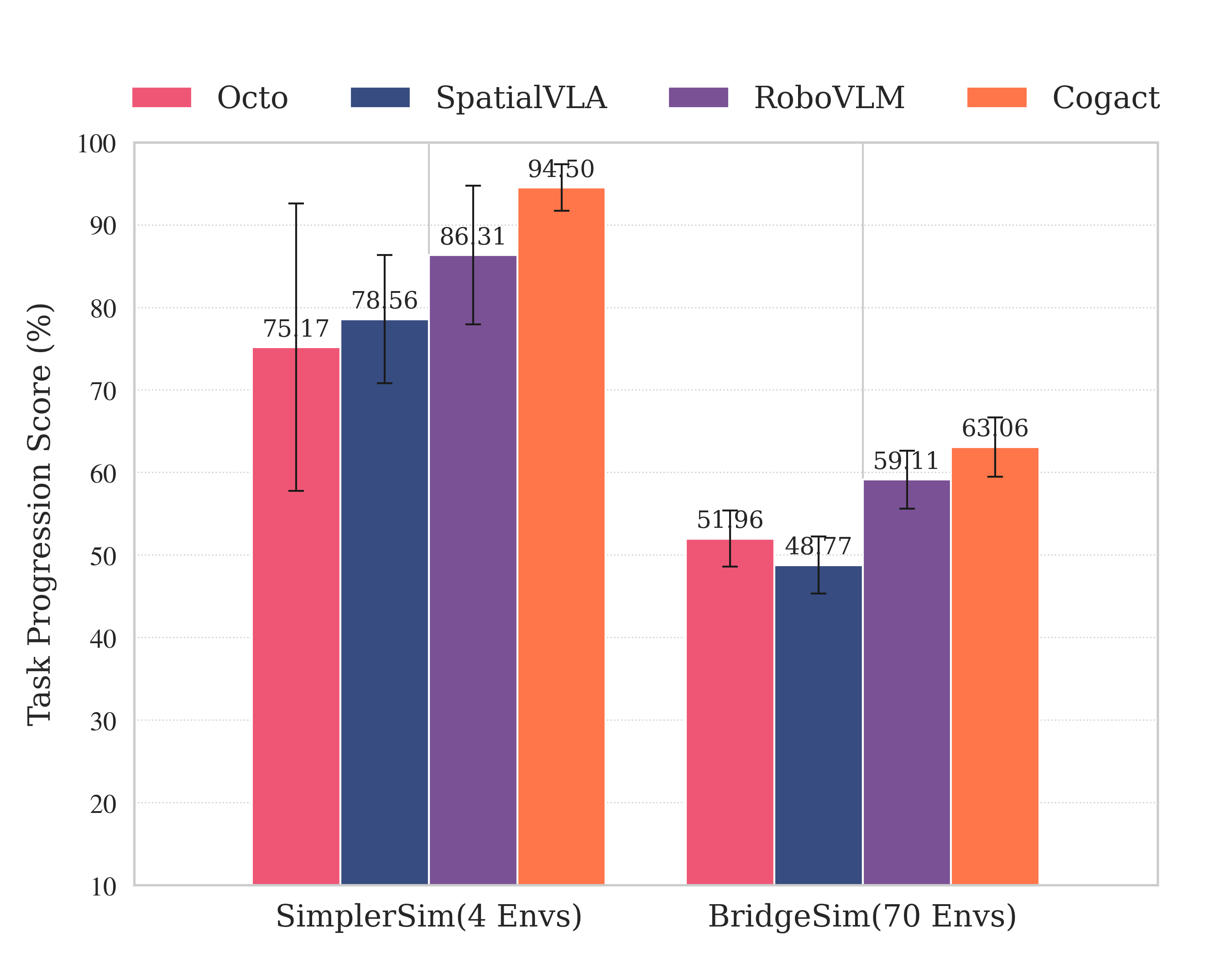
Figure 11: (Left) Validation of simulation-based robot evaluation against real-world robot evaluations; (Right) Task completion policy evaluation in RobotArena ∞ versus SIMPLER benchmark.
Relative policy rankings are consistent across automated and human evaluations, with RoboVLM and CogAct preferred over Octo and SpatialVLA. Notably, all policies achieve higher scores on the hand-crafted SIMPLER benchmark than on the more diverse and challenging BridgeSim environments, underscoring the increased difficulty and generality of RobotArena ∞.
Limitations and Future Directions
Current limitations include the absence of wrist-mounted camera inputs and incomplete modeling of fine-grained contact dynamics. The framework is poised to benefit from advances in physics engines, multi-view simulation, and automated asset generation. Future work will extend support for multi-view observations, improve contact modeling, and expand the diversity of tasks and environments.
Conclusion
RobotArena ∞ establishes a scalable, extensible, and reproducible protocol for benchmarking generalist robot policies via automated reality-to-simulation translation and crowdsourced human evaluation. The framework enables rigorous assessment of policy robustness and generalization, revealing significant cross-dataset failures and sensitivity to controlled perturbations. By releasing environments and evaluation code, RobotArena ∞ provides an open platform for the community to benchmark and advance the next generation of robotic foundation models. The approach sets a new standard for reproducible, large-scale evaluation in robotics, with implications for both practical deployment and theoretical understanding of generalist policy learning.